【AI】RAG的原理
目录
前言
上一篇博客中,介绍了大模型的幻觉是什么,以及为什么会产生幻觉,而且还介绍了可以减少模型出现幻觉的方法——RAG(Retrieval-Augmented Generation,检索增强生成)
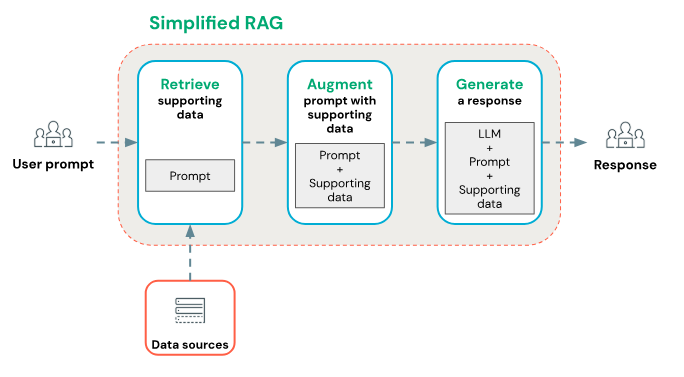
RAG的核心思想就是:让大模型在回答问题之前,先从外部知识库中检索信息,再基于这些信息生成更准确、更可控的回答。
一、为什么会有RAG
要理解RAG,必须要先理解普通大模型的局限。
- 大模型的信息不是实时的:模型训练完成之后,它的知识基本上就冻结了,如果你要问他某某公司最新公布的财报是多少,不借助外部信息的情况下,模型是不会知道这个内容的。
- 大模型容易产生幻觉:模型看起来回答得很自信,但其实是编出来的。尤其在涉及事实性问题、专业问答、企业知识库时,幻觉非常危险。
有人可能会思考,那我直接拿最新的企业数据进行微调不就可以解决这个问题了吗?
但是微调有几个问题:
- 成本高:训练、更新都贵;
- 不灵活:文档一更新,可能就得重新训练;
- 不适合频繁变化的数据;
- 难以溯源:回答来自模型参数,难明确指出“答案依据哪份文档”。
二、RAG完整流程

一个典型的RAG系统,通常分成两个阶段
阶段一:离线建库(准备知识)
这个阶段的目标是:把文档变成可检索的知识库。
①收集数据,数据来源可以是:产品手册、企业内部知识库、FAQ等等。
②文档切分,大模型和检索系统通常不直接处理整篇长文,而是把文档切成一个个小片段,叫做 chunk(切片/文本块)。
为什么要切片?
- 太长不利于检索;
- 用户问题通常只对应文档中的局部内容;
- 小块更容易匹配相关问题。
③向量化,每个 chunk 会被送入一个 Embedding 模型,转换成一串向量。
虽然两句话字面不一样,但语义接近,所以在向量空间里距离会比较近。
这一步是 RAG 的关键,因为后面的“检索相关内容”,很多时候就是在做向量相似度搜索。
④存入向量数据库,为检索做准备。
阶段二:在线问答
用户提问时,系统会执行以下流程:
①用户输入问题,比如:“公司的报销流程里,差旅费需要哪些凭证?”
②问题向量化,把用户问题也通过 Embedding 模型转成向量。
③检索相关文本,系统去向量数据库里找“和这个问题语义最接近”的几个 chunk。
例如找到:
- 《财务报销制度》第 3.2 节
- 《差旅报销 FAQ》第 2 条
- 《发票要求规范》第 1 页
这一步叫 Retrieval(检索)。
④将检索结果和问题一起交给大模型,
系统会构造一个 Prompt,类似这样:
- 用户问题是什么;
- 检索到的上下文有哪些;
- 要求模型只能根据提供的资料回答;
- 如果资料不足,就明确说不知道。
⑤大模型生成最终答案,模型不再“凭空想”,而是优先基于提供的资料组织答案。
这一步叫 Generation(生成)。
三、RAG和微调的区别
微调(Fine-tuning)
是把新知识“写进模型参数”里。
适合:
- 固定任务风格
- 特定领域语言习惯
- 输出格式定制
- 分类、抽取、生成风格优化
但不适合频繁更新的知识。
RAG
是把知识放在模型外部,需要时动态取用。
适合:
- 文档问答
- 企业知识库
- 实时更新信息
- 需要引用来源
- 事实准确性要求高的场景
总结
RAG 的核心价值,在于把“大模型的语言能力”和“外部知识库的事实能力”结合起来。
它不是让模型死记硬背更多知识,而是让模型学会在回答前先查资料。
因此,RAG 特别适合知识密集、事实要求高、数据需要持续更新的场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)