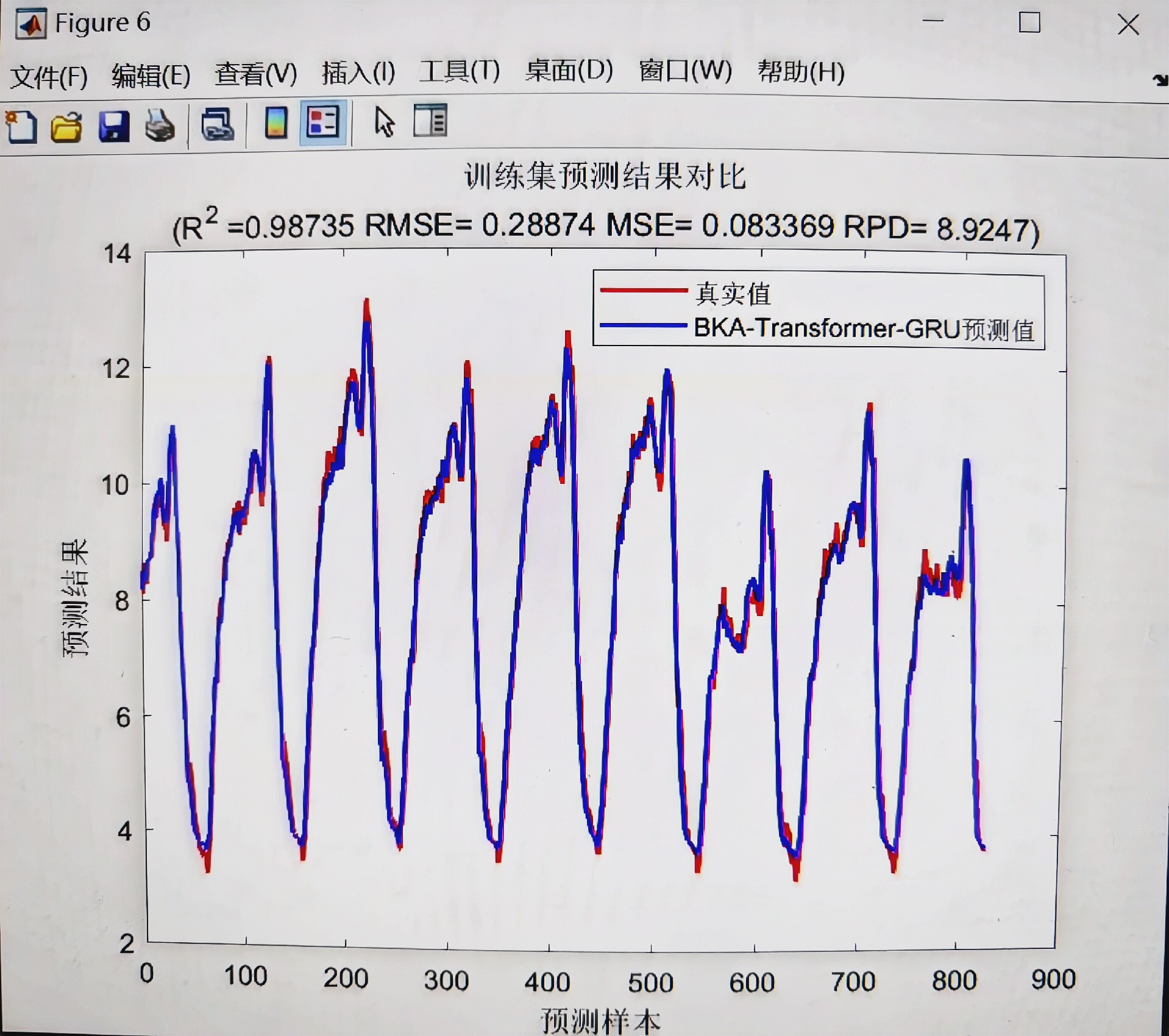
基于BKA - Transformer - GRU的数据回归预测探索
基于BKA-Transformer-GRU的数据回归预测 模型结合Transformer的全局注意力机制和GRU的短期记忆及序列处理能力 首先,采用Transformer自注意力机制捕捉数据的全局依赖性,并输出一个经过全局上下文编码的表示;然后,采用2024年最新优化算法黑翅鸢优化算法BKA优化门控循环逻辑单元GRU的隐含层神经元数目等,以避免模型陷入局部最优,提高模型泛化能力;最后,采用优化的GRU内部的记忆单元和门控机制捕捉数据中的短期依赖关系,进一步处理这个表示,捕捉其中的短期依赖关系,并输出最终的预测结果
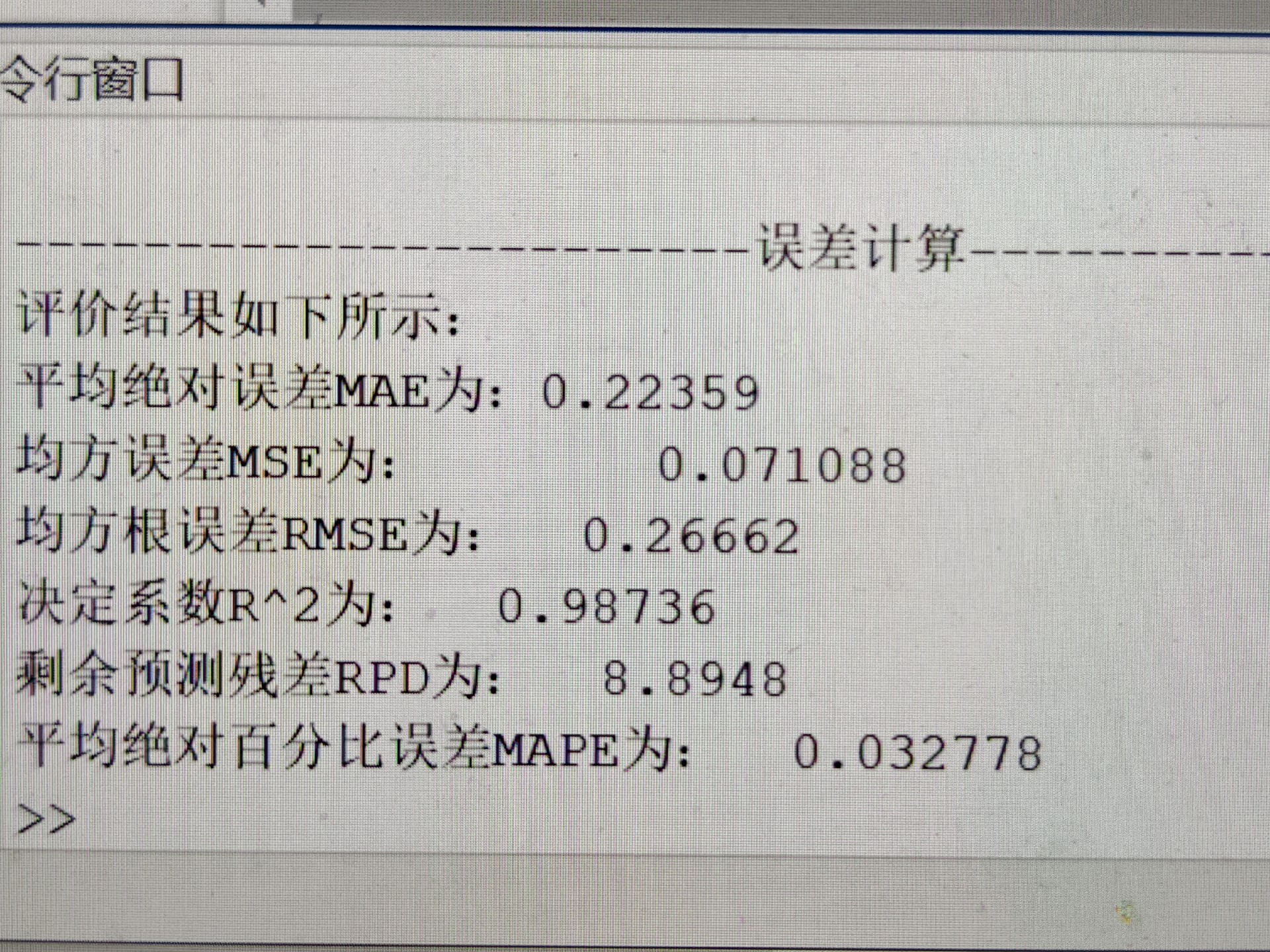
在数据预测领域,为了能更精准地把握数据特征,融合不同模型的优势成为了一个热门方向。今天咱就来唠唠基于BKA - Transformer - GRU的数据回归预测模型,这个模型巧妙结合了Transformer的全局注意力机制与GRU的短期记忆及序列处理能力。
Transformer的全局依赖性捕捉
Transformer的自注意力机制可谓是其核心亮点。它能够让模型在处理序列数据时,对序列中的每个位置都给予不同的关注程度,进而捕捉到数据的全局依赖性。下面简单用伪代码示意一下这个过程:
import numpy as np
def self_attention(query, key, value):
d_k = query.shape[-1]
scores = np.matmul(query, key.transpose(-2, -1)) / np.sqrt(d_k)
attention_weights = np.softmax(scores, axis=-1)
output = np.matmul(attention_weights, value)
return output
在这段代码里,query、key 和 value 是输入的特征矩阵。首先计算 scores,这一步通过矩阵乘法来衡量不同位置之间的相关性,再除以 sqrt(dk) 是为了防止梯度消失或爆炸。接着使用 softmax 函数得到注意力权重 attentionweights,最后根据这些权重对 value 进行加权求和,得到自注意力机制的输出 output。这个输出就是经过全局上下文编码的表示,它包含了整个序列的全局信息。
BKA优化GRU
到了2024年,新的黑翅鸢优化算法BKA闪亮登场啦。它被用来优化门控循环逻辑单元GRU的隐含层神经元数目等参数。为啥要这么做呢?因为传统的GRU在训练过程中,很容易陷入局部最优解,这样模型的泛化能力就会大打折扣。而BKA算法就像是给GRU找了个聪明的“导航员”,引导它跳出局部最优的陷阱。虽然这里没办法直接展示BKA算法的具体代码(毕竟是新算法,可能还比较小众未完全公开),但大致思路就是通过迭代搜索,在参数空间里找到最优的参数组合,就像在一片大森林里找到最适合模型生长的“宝地”。
GRU捕捉短期依赖关系
经过BKA优化后的GRU,内部的记忆单元和门控机制就能更好地发挥作用,来捕捉数据中的短期依赖关系啦。下面看看简单的GRU伪代码实现:
import numpy as np
def gru_cell(x_t, h_t_prev, W_z, W_r, W_h, b_z, b_r, b_h):
z_t = sigmoid(np.dot(x_t, W_z) + np.dot(h_t_prev, W_z) + b_z)
r_t = sigmoid(np.dot(x_t, W_r) + np.dot(h_t_prev, W_r) + b_r)
h_tilde = np.tanh(np.dot(x_t, W_h) + np.dot(r_t * h_t_prev, W_h) + b_h)
h_t = (1 - z_t) * h_t_prev + z_t * h_tilde
return h_t
def sigmoid(x):
return 1 / (1 + np.exp(-x))
在 grucell 函数里,xt 是当前时刻的输入,htprev 是上一时刻的隐藏状态。通过 zt(更新门)和 rt(重置门)来控制信息的流动,htilde 是候选隐藏状态,最后通过更新门来决定保留多少上一时刻的信息和加入多少当前时刻的新信息,得到当前时刻的隐藏状态 ht。这样一步步处理之前Transformer输出的全局编码表示,最终捕捉到数据中的短期依赖关系,并输出最终的预测结果。
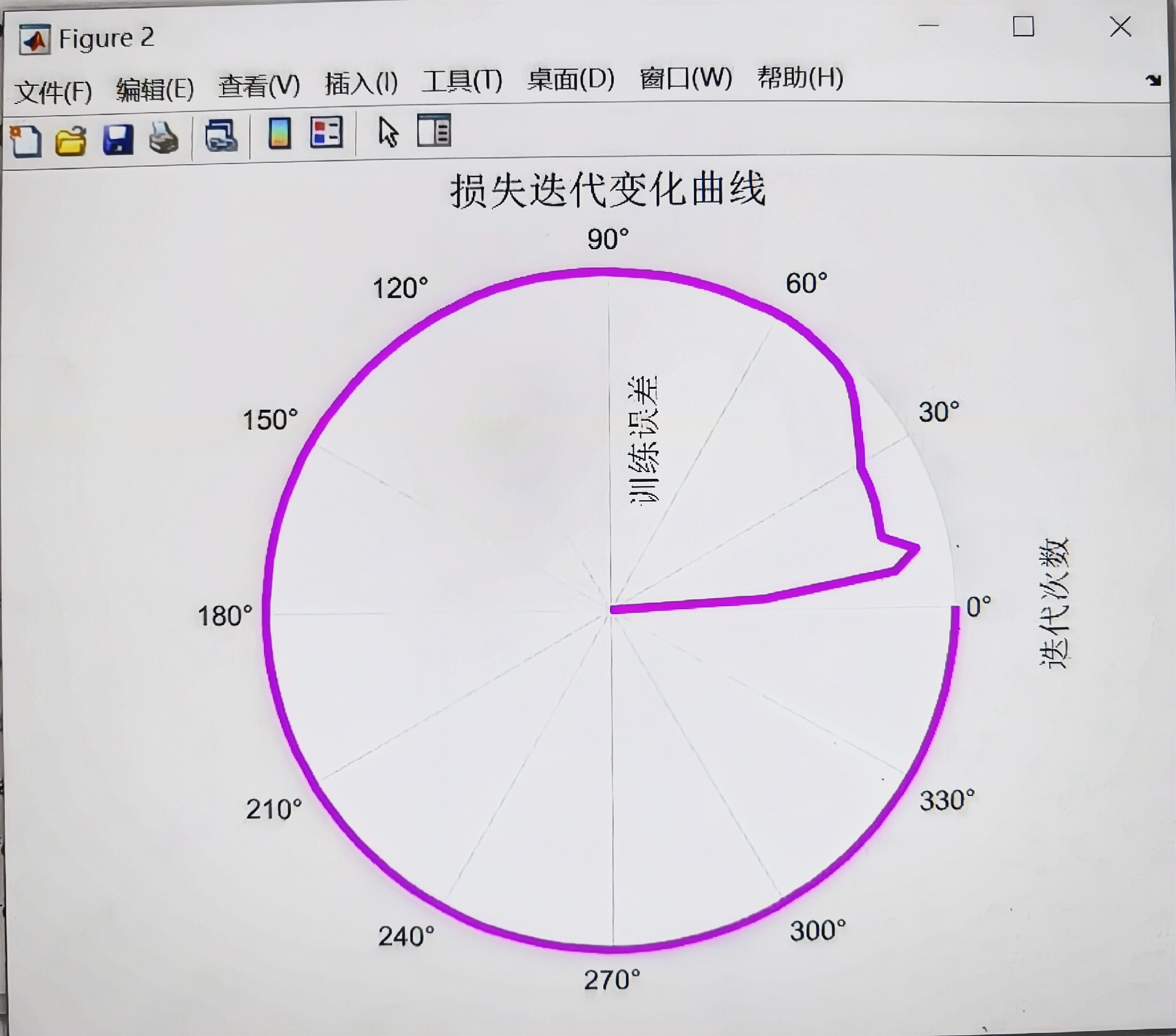
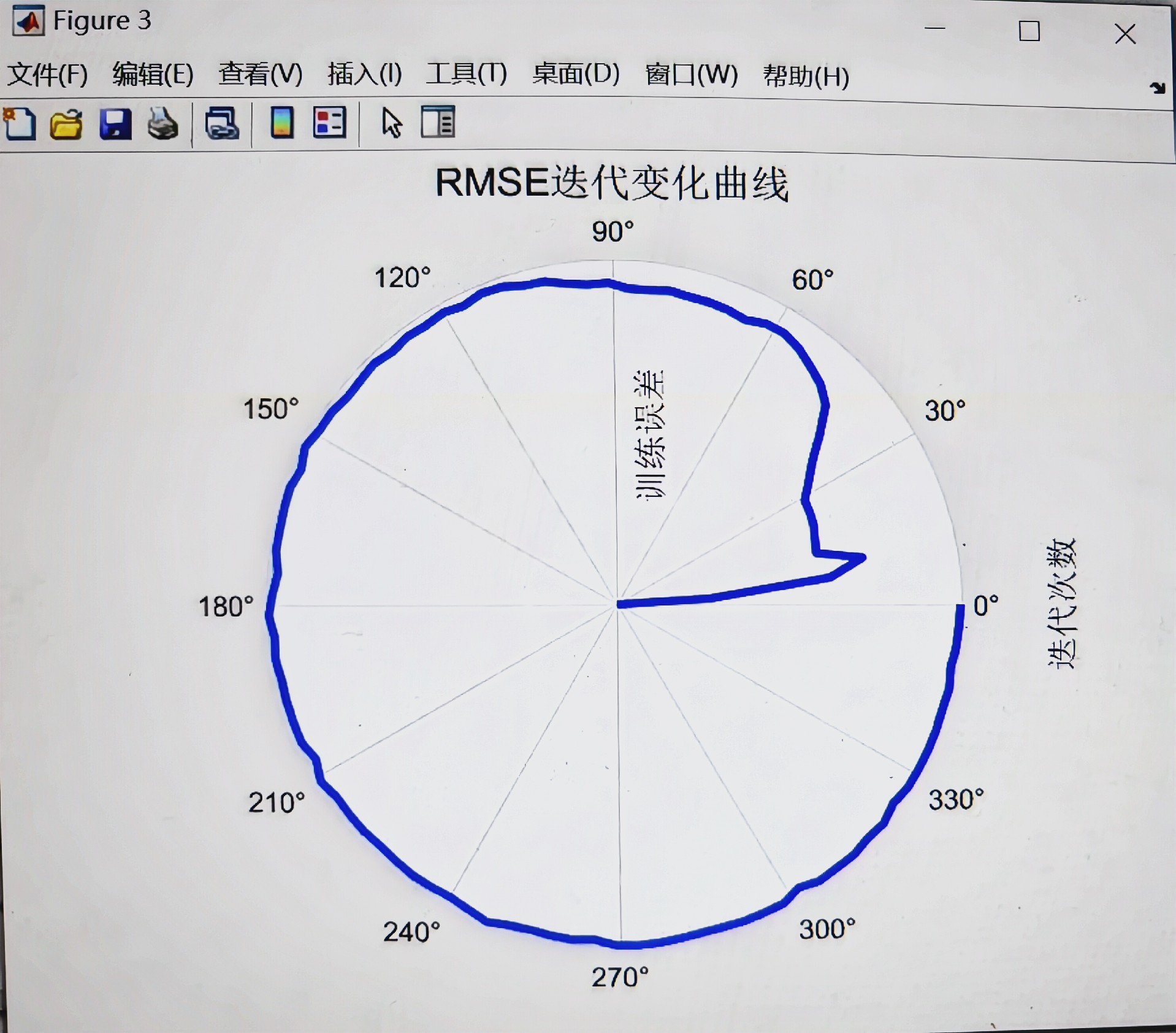
基于BKA-Transformer-GRU的数据回归预测 模型结合Transformer的全局注意力机制和GRU的短期记忆及序列处理能力 首先,采用Transformer自注意力机制捕捉数据的全局依赖性,并输出一个经过全局上下文编码的表示;然后,采用2024年最新优化算法黑翅鸢优化算法BKA优化门控循环逻辑单元GRU的隐含层神经元数目等,以避免模型陷入局部最优,提高模型泛化能力;最后,采用优化的GRU内部的记忆单元和门控机制捕捉数据中的短期依赖关系,进一步处理这个表示,捕捉其中的短期依赖关系,并输出最终的预测结果
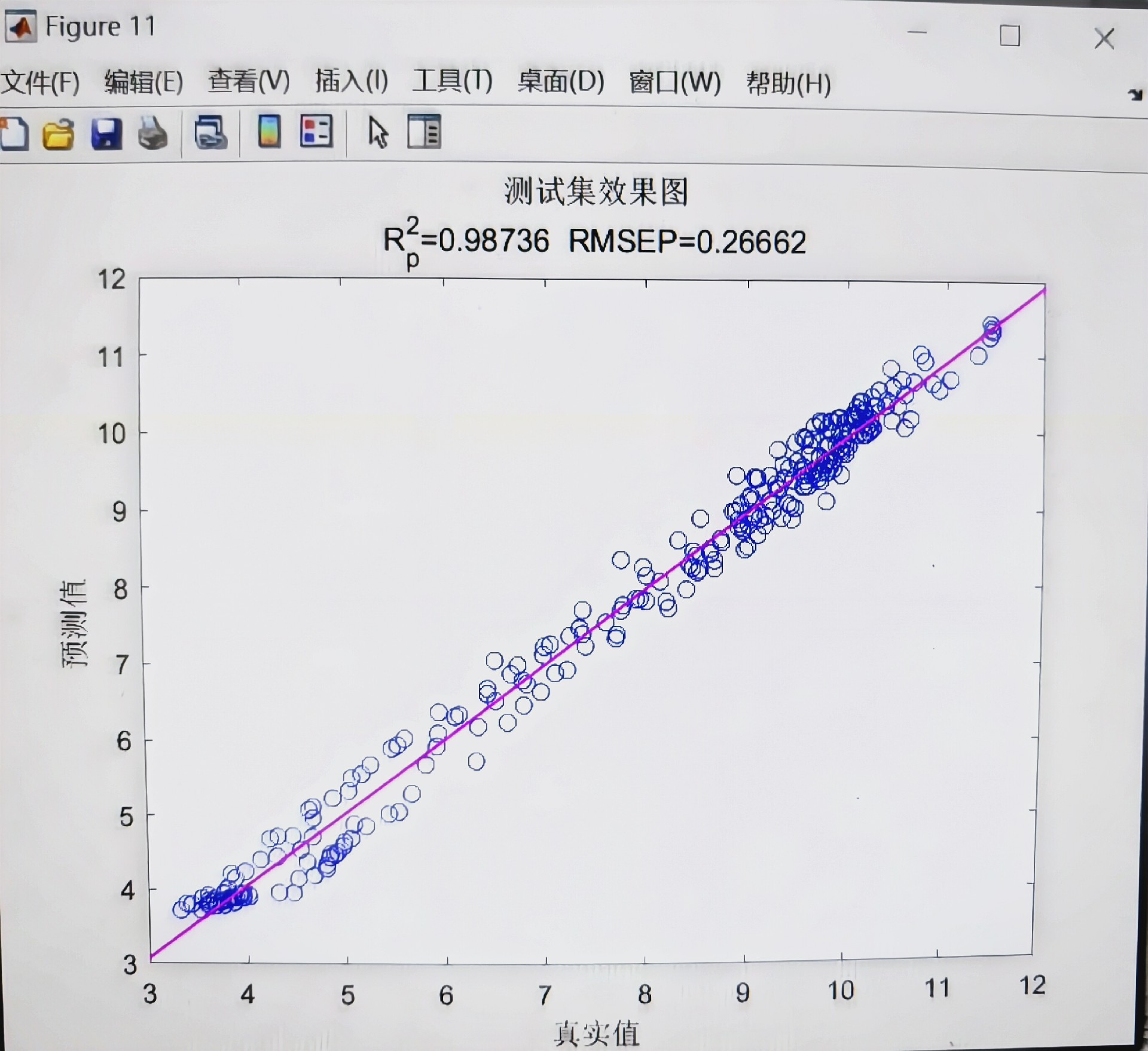
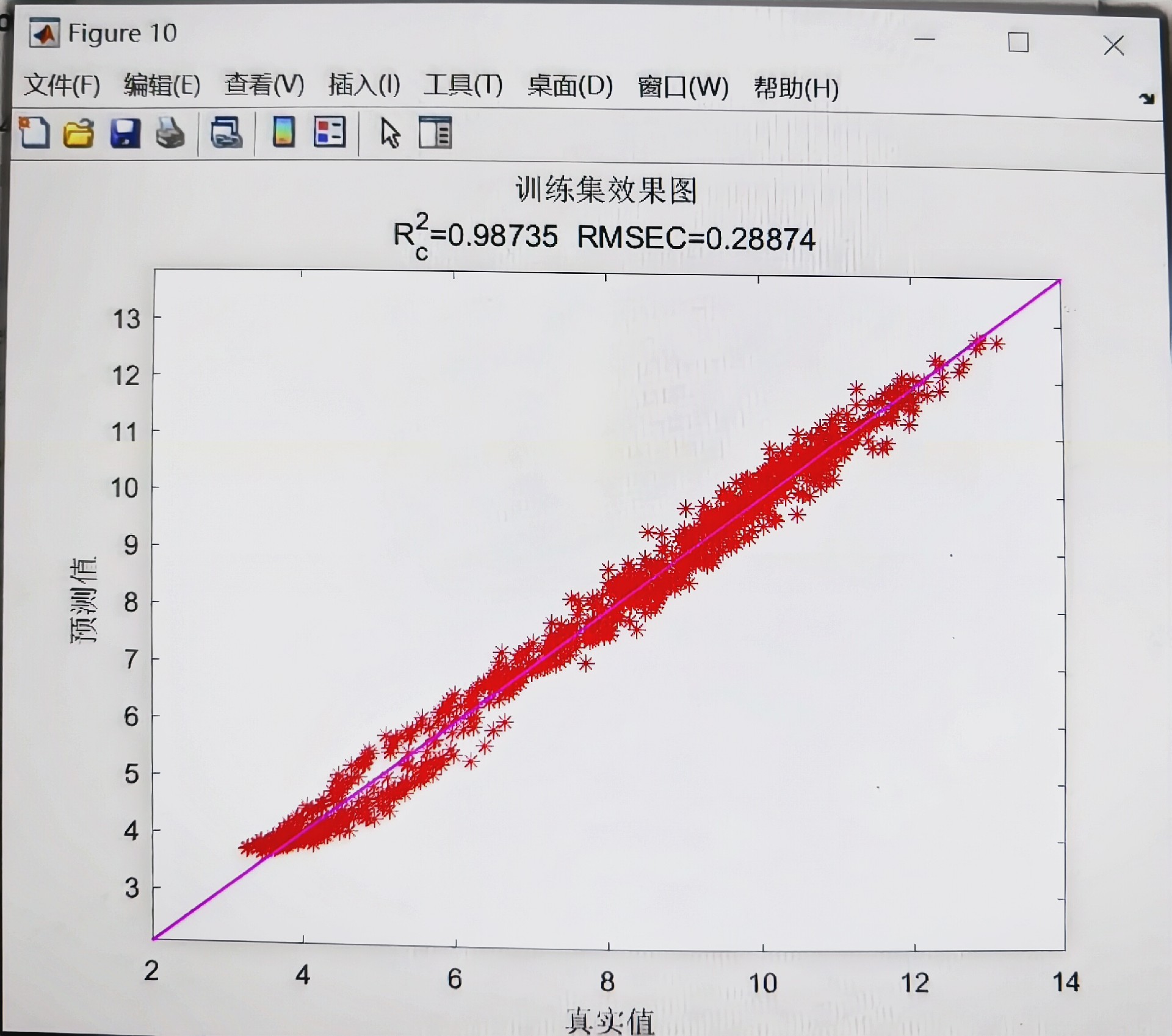
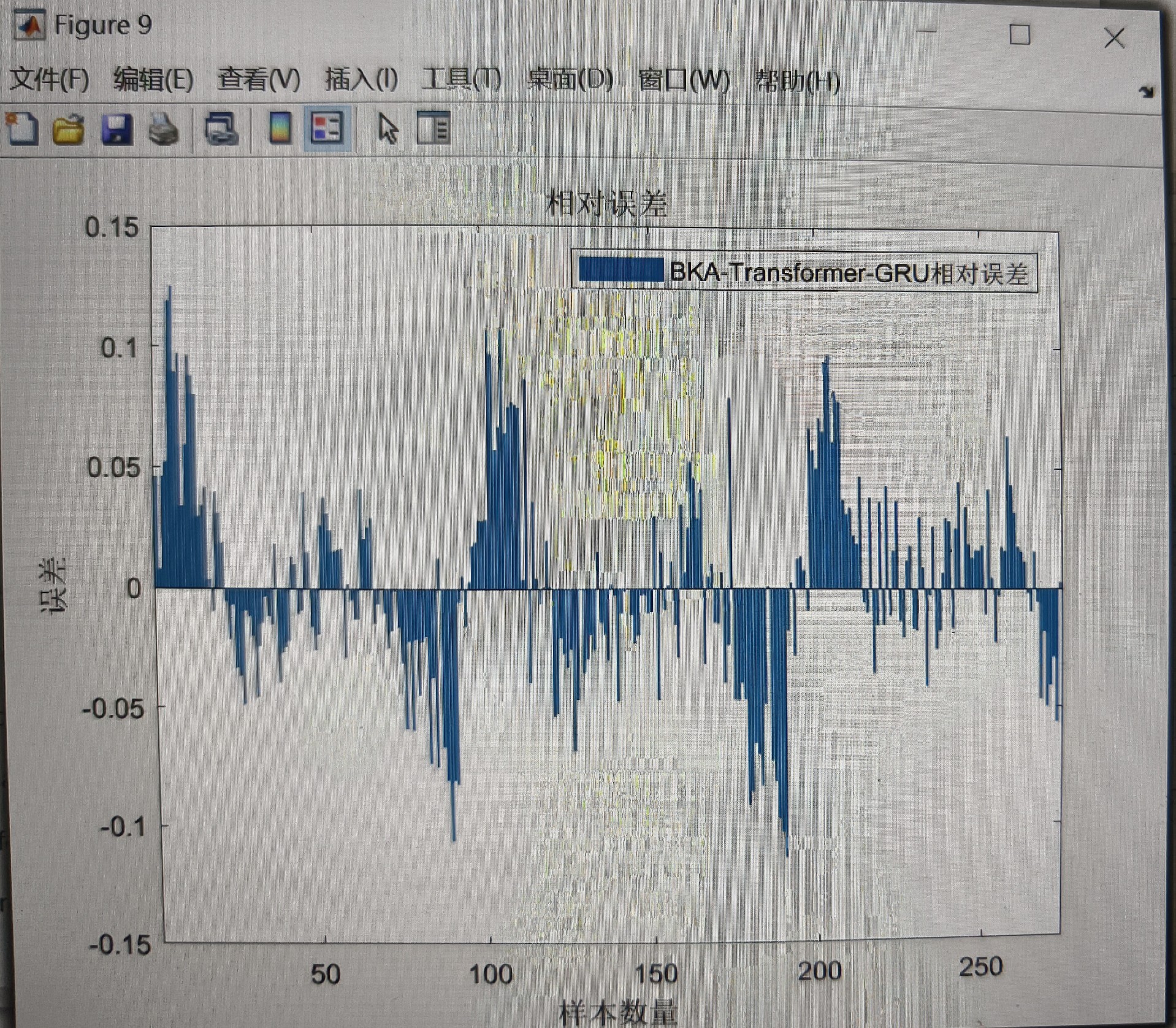
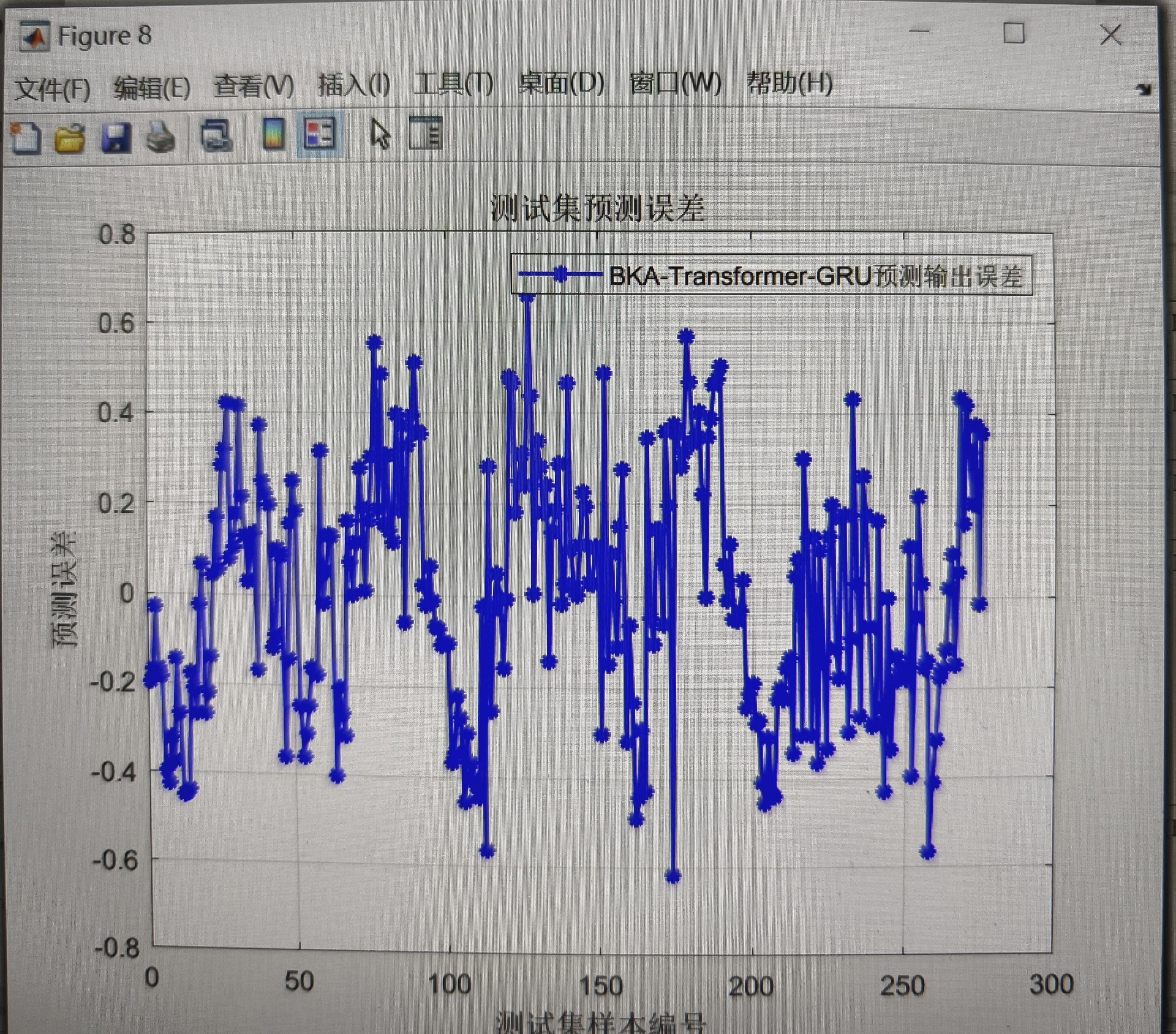
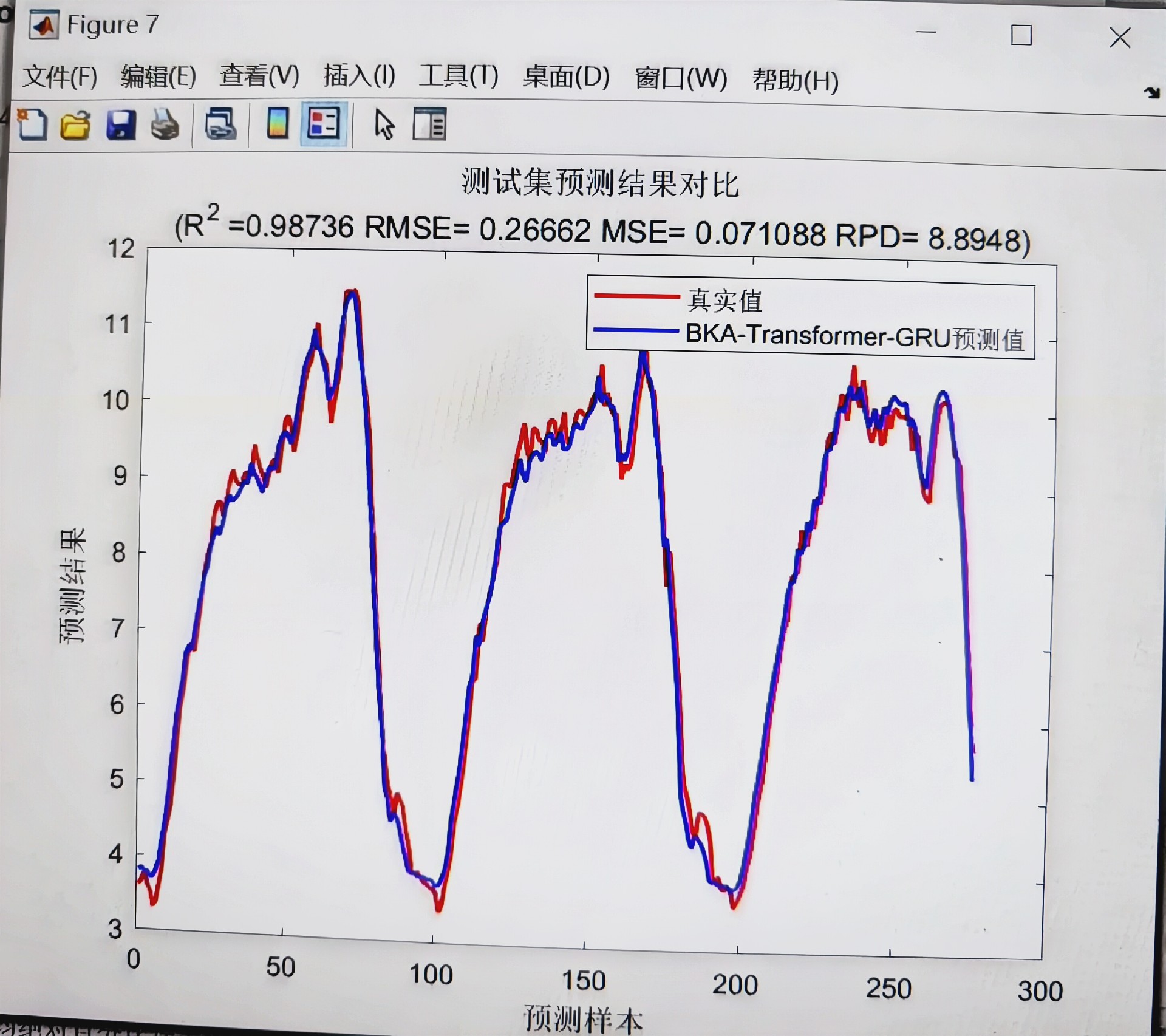
总的来说,这个基于BKA - Transformer - GRU的数据回归预测模型,充分发挥了各个部分的优势,有望在数据回归预测任务中取得不错的成绩。未来随着研究的深入,说不定还能进一步优化,在更多实际场景中大放异彩呢!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)