Gemma 4 谷歌开源的字节效率之王,全面支持文本、图像、视频和音频
Google DeepMind 正式发布 Gemma 4 系列开放权重模型——首次全面支持文本、图像、视频和音频,四种尺寸从手机芯片到工作站 GPU 全覆盖,并以 Apache 2.0 彻底开放商用。

开源社区下载量超 4 亿次,衍生变体超过 10 万个——Gemma 的崛起已然是大语言模型开放生态的一个缩影。而这一次,Gemma 4 带着突破性的多模态能力和极致的参数效率,向着所有「闭源旗舰」发起了正面挑战。
四款新模型,覆盖全硬件场景
Gemma 4 本次共推出四个尺寸版本,针对不同计算环境精心设计

其中「E」代表 Effective(有效参数)——E2B 和 E4B 通过Per-Layer Embeddings技术,让嵌入层的巨量参数只做快速查表,而非参与每次前向计算,从而大幅压缩实际推理成本。
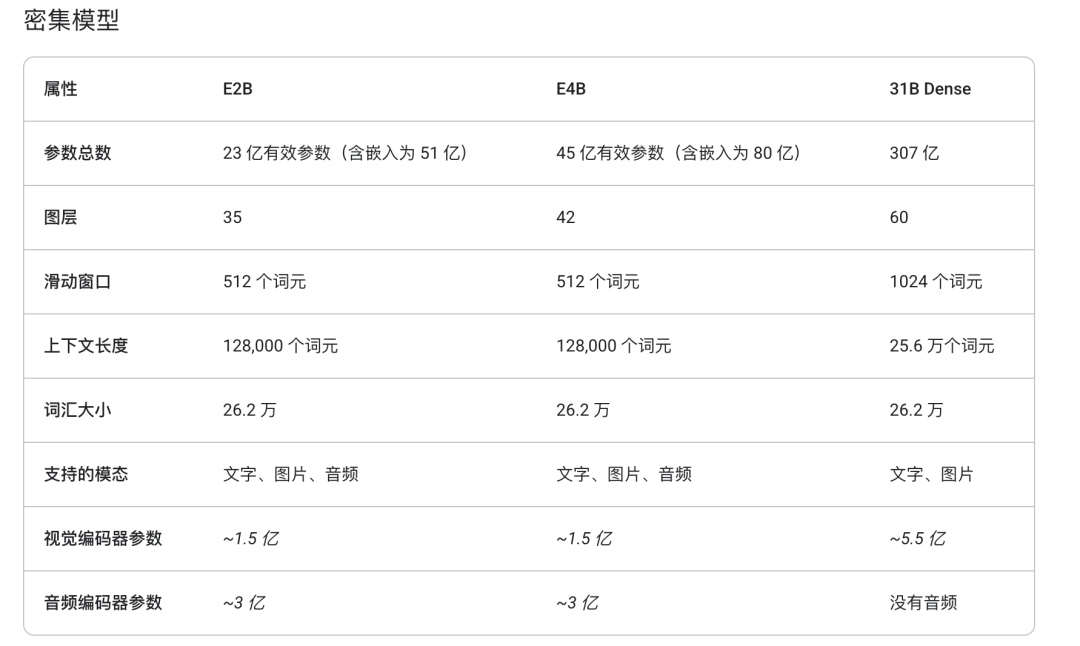
26B 则采用混合专家(MoE)架构,推理时仅激活其中 38 亿参数,速度接近一个纯 4B 模型。

基准测试:以小博大的实力
以下是几项关键基准测试结果(指令微调版本),对比 Gemma 3 27B:
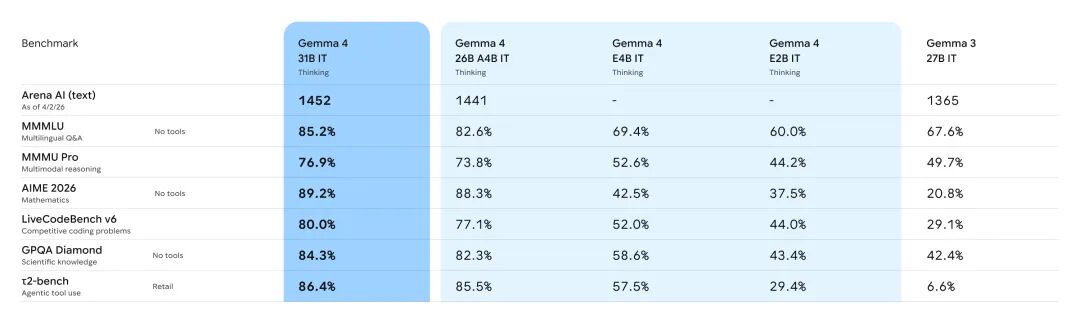
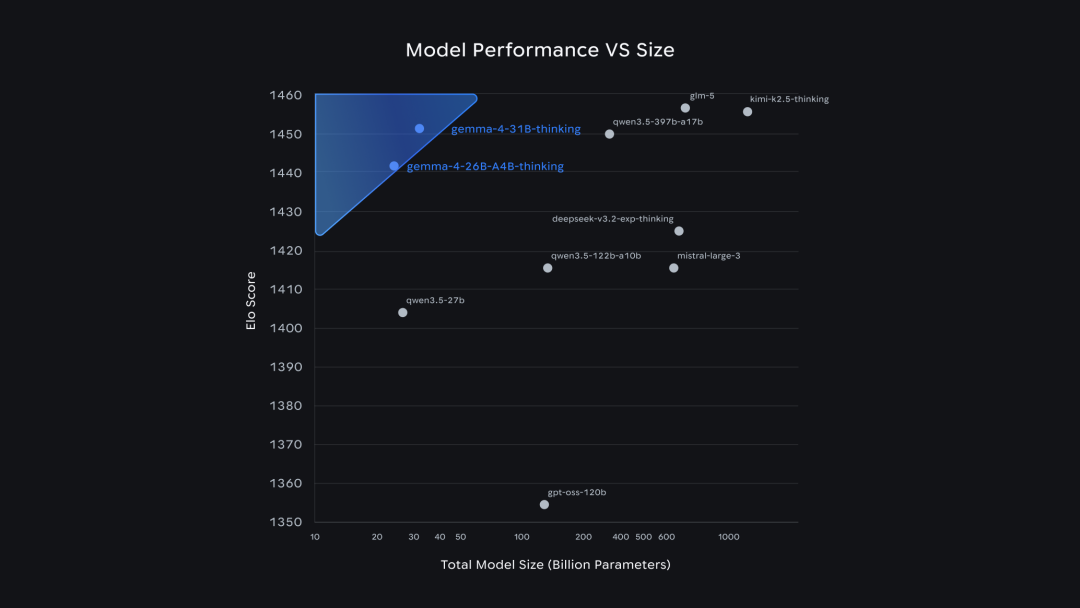
在竞技场排行榜(Arena AI)上,31B 版本位列开源模型全球第 3,26B MoE 排名第 6。
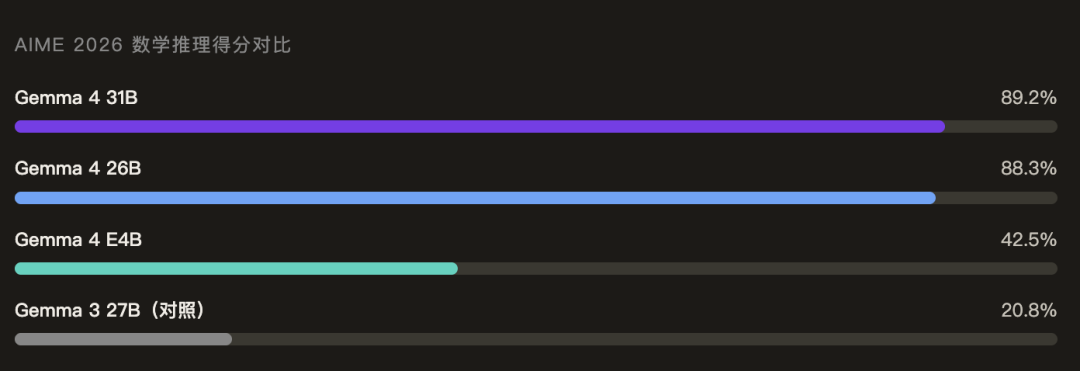
官方表示,Gemma 4 能够胜过参数量大 20 倍的竞争对手——这正是「字节效率之王」名号的由来。
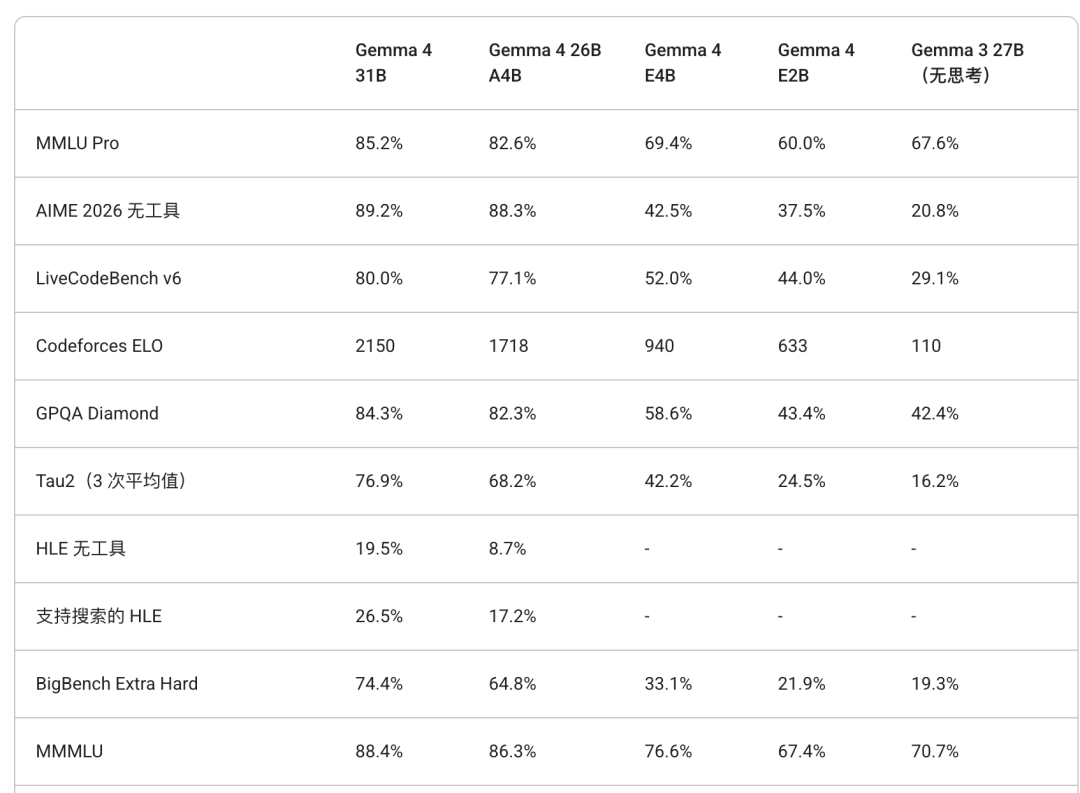
六大核心能力升级

在上下文窗口方面,Gemma 4 采用了混合注意力机制——局部滑动窗口注意力与全局注意力交织,最后一层始终保持全局注意力。全局层还引入了统一 K/V 和比例 RoPE(p-RoPE),在显著降低长上下文内存占用的同时,保留了深层语义感知能力。

Apache 2.0:真正的开放
Apache 2.0 开源许可
Gemma 4 采用商业友好的 Apache 2.0 协议发布,开发者可自由使用、修改、分发和商用,无需向 Google 支付任何许可费用,也没有复杂的使用限制。这是 Gemma 系列首次全面拥抱 Apache 2.0。
Google 表示,这一决定来自社区的直接反馈。他们认为构建 AI 的未来需要开放协作,而开发者需要对数据、基础设施和模型拥有完整的控制权与数字主权。
开发生态:工具链从第一天就就绪
Hugging Face Transformers,Ollama,vLLM,llama.cpp,LM Studio,MLX(Apple Silicon)
NVIDIA NIM,Keras,Unsloth,LiteRT-LM,Google AI Studio
Vertex AI,Android ML Kit,Docker
模型权重可从Hugging Face、Kaggle和Ollama直接下载。Android 开发者可通过 ML Kit GenAI Prompt API 在生产环境中部署 E2B/E4B,Qualcomm 和 MediaTek 均已完成硬件适配。

写在最后:开源 AI 的新基准线
Gemma 4 不只是一次参数升级,它重新定义了「开源模型能做什么」。当一个 31B 的开源模型开始在全球竞技场上挑战闭源旗舰,当一个能跑在树莓派上的 E2B 模型能够同时理解语音、图像和文字——开放 AI 的下一个时代,已经悄然开启。

对于开发者而言,Gemma 4 带来的核心价值是真正的本地化 AI 主权:数据不出本地、模型可自由微调、硬件按需选择。从 Android 手机到云端 TPU,从个人代码助手到企业级智能体工作流,Gemma 4 都在试图给出同一个答案——开放,也可以是最好的选择。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)