基于秃鹰搜索优化算法优化XGBoost的时间序列预测
基于秃鹰搜索优化算法优化XGBoost(BES-XGBoost)的时间序列预测 BES-XGBoost时间序列 采用交叉验证抑制过拟合问题 优化参数为迭代次数、最大深度和学习率 matlab代码, 注:暂无Matlab版本要求 -- 推荐 2016B 版本及以上 注:采用 XGBoost 工具箱,仅支持 Windows 64位系统
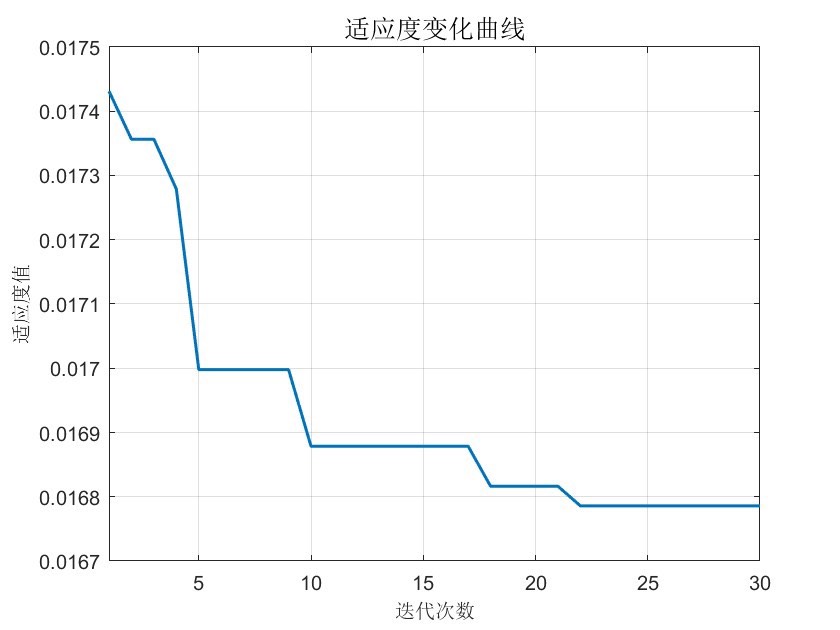
在时间序列预测领域,如何提升模型精度与效率一直是研究热点。今天咱们聊聊基于秃鹰搜索优化算法优化XGBoost(BES - XGBoost)来进行时间序列预测这一有趣的方向。
抑制过拟合:交叉验证的妙处
在构建预测模型时,过拟合是个让人头疼的问题。它会导致模型在训练集上表现出色,但在测试集上却不尽人意。咱们采用交叉验证的方法来抑制过拟合。简单来说,交叉验证就是将数据集分成多个子集,每次用一部分子集作为训练集,另一部分作为验证集,反复进行训练和验证,从而得到更可靠的模型性能评估。
优化参数:迭代次数、最大深度和学习率
- 迭代次数:它决定了模型训练的轮数。如果迭代次数太少,模型可能欠拟合,无法充分学习数据特征;而迭代次数过多,又容易导致过拟合。比如,咱们在BES - XGBoost模型中,通过秃鹰搜索优化算法来寻找合适的迭代次数,让模型在学习能力和泛化能力之间找到平衡。
- 最大深度:这个参数限制了决策树的深度。深度太浅,模型复杂度低,难以捕捉复杂的数据关系;深度太深,则可能陷入过拟合。想象一下,决策树就像一个知识图谱,深度就是图谱的层级,层级太少无法涵盖全面信息,层级太多又可能过度细化一些特殊情况。
- 学习率:它控制每次迭代时模型参数更新的步长。学习率过大,模型可能会错过最优解,在最优解附近来回震荡;学习率过小,模型收敛速度又会很慢,需要更多的迭代次数才能达到较好的效果。
Matlab代码示例及分析
下面咱们看看关键的Matlab代码,由于采用XGBoost工具箱,且仅支持Windows 64位系统,推荐2016B版本及以上。
% 假设已经准备好时间序列数据,存储在变量data中
% 划分训练集和测试集
trainRatio = 0.8;
trainSize = floor(trainRatio * size(data, 1));
trainData = data(1:trainSize, :);
testData = data(trainSize + 1:end, :);
% 加载XGBoost工具箱
addpath('path_to_xgboost_toolbox');
% 设置初始参数
params = ['eta=0.1'; 'max_depth=3'; 'objective="reg:squarederror"'];
% 这里开始假设秃鹰搜索优化算法寻找最优参数,暂时简单模拟
% 实际中秃鹰搜索优化算法会更复杂,这里只是示意
bestIterations = 50;
bestMaxDepth = 5;
bestLearningRate = 0.08;
params = ['eta=' num2str(bestLearningRate);'max_depth=' num2str(bestMaxDepth); 'objective="reg:squarederror"'];
% 训练BES - XGBoost模型
xgbTrain = xgboost('train', trainData(:, 1:end - 1), trainData(:, end), params, 'num_round', bestIterations);
% 预测
predictions = xgboost('predict', xgbTrain, testData(:, 1:end - 1));
% 评估预测结果
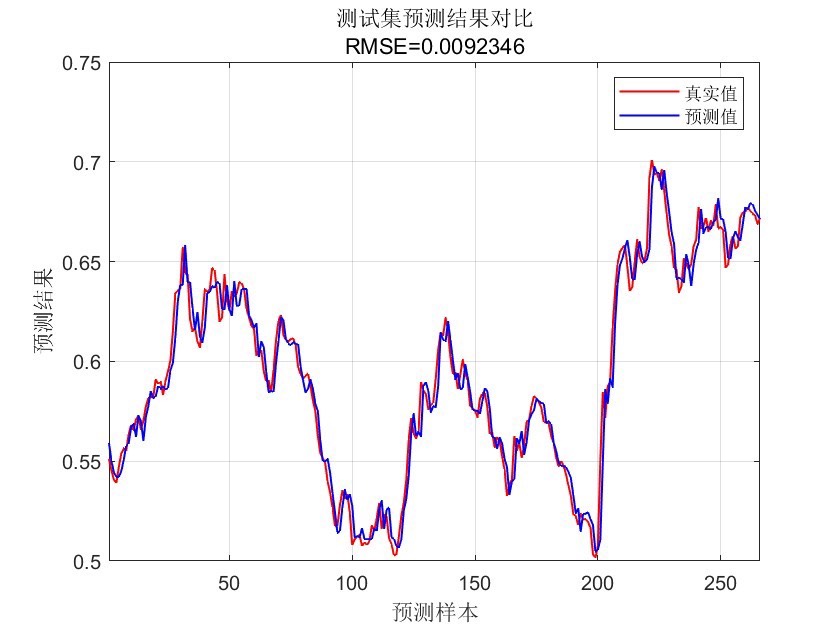
mse = mean((predictions - testData(:, end)).^2);
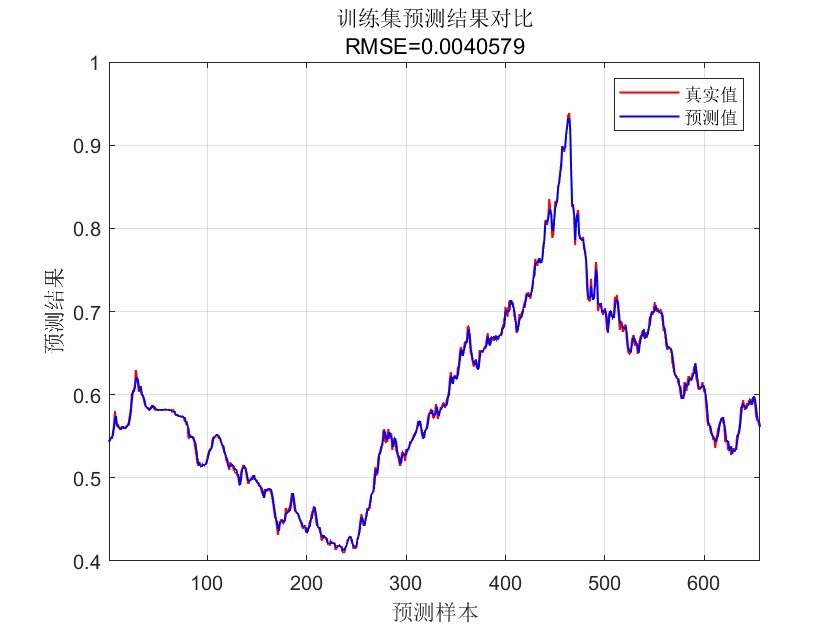
fprintf('均方误差MSE: %f\n', mse);代码分析
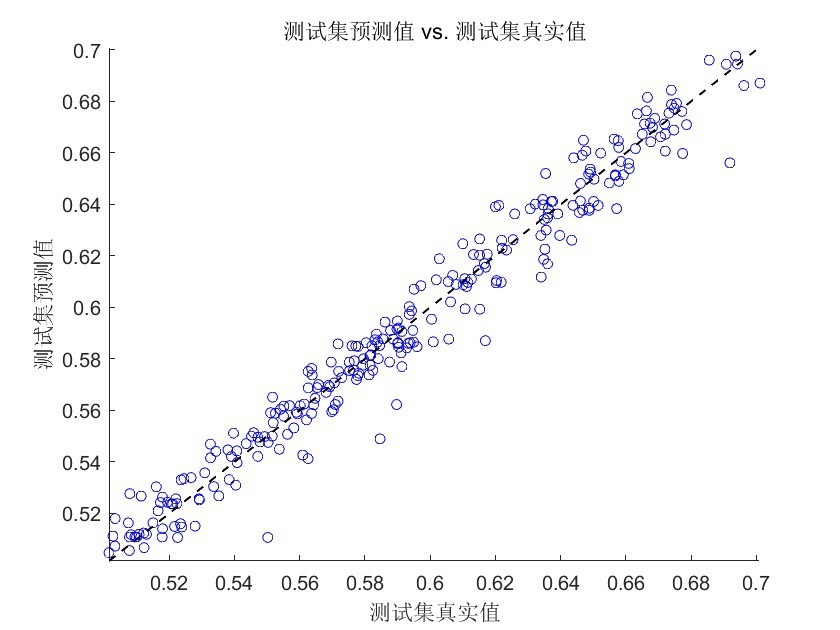
- 数据划分:首先,咱们按照80%的数据作为训练集,20%作为测试集的比例,将时间序列数据进行划分。
trainRatio定义了训练集比例,trainSize通过计算得到训练集的大小,从而分别提取出trainData和testData。 - 加载工具箱:通过
addpath函数加载XGBoost工具箱,这里要注意路径填写正确,指向实际的XGBoost工具箱所在目录。 - 参数设置与优化:开始设置了初始参数,像学习率
eta为0.1,最大深度max_depth为3 ,目标函数objective为均方误差回归。之后通过模拟的秃鹰搜索优化算法得到了更优的参数bestIterations、bestMaxDepth和bestLearningRate,并重新设置params参数。 - 模型训练与预测:利用
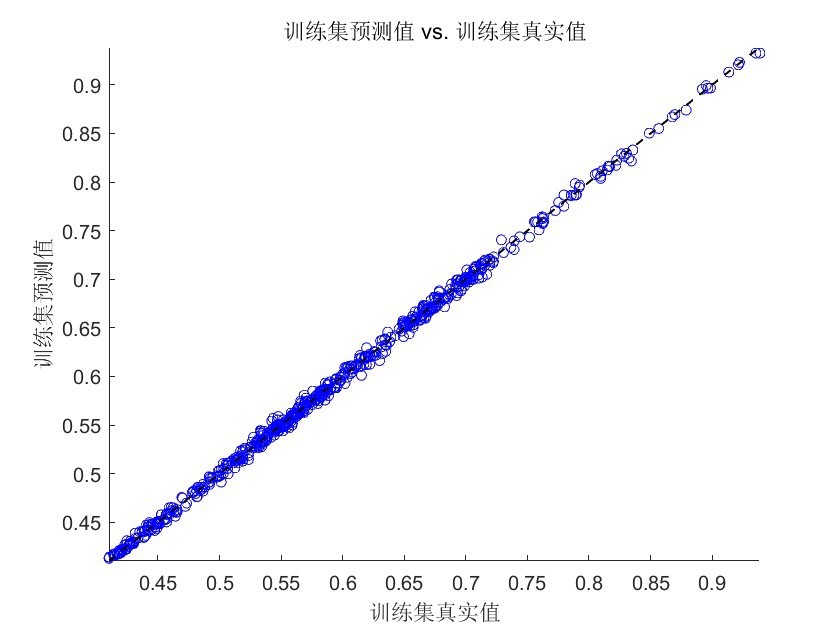
xgboost函数进行模型训练,传入训练数据的特征和标签,以及设置好的参数和迭代次数。训练完成后,使用训练好的模型对测试集数据进行预测。 - 结果评估:最后通过计算预测值与真实值的均方误差(MSE)来评估模型的预测性能,MSE越小,说明模型预测越准确。
通过基于秃鹰搜索优化算法优化XGBoost,并采用交叉验证抑制过拟合,我们能够在时间序列预测任务中取得更好的效果,Matlab代码为我们实现这一过程提供了有力工具。希望这篇博文能给大家在时间序列预测的研究与实践中带来一些启发。
基于秃鹰搜索优化算法优化XGBoost(BES-XGBoost)的时间序列预测 BES-XGBoost时间序列 采用交叉验证抑制过拟合问题 优化参数为迭代次数、最大深度和学习率 matlab代码, 注:暂无Matlab版本要求 -- 推荐 2016B 版本及以上 注:采用 XGBoost 工具箱,仅支持 Windows 64位系统

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)