M3STR (ACM MM2025)
动机:
现在的方法忽视了 MLLM 通过以视觉形式出现的结构化抽象来理解世界知识的关键能力。
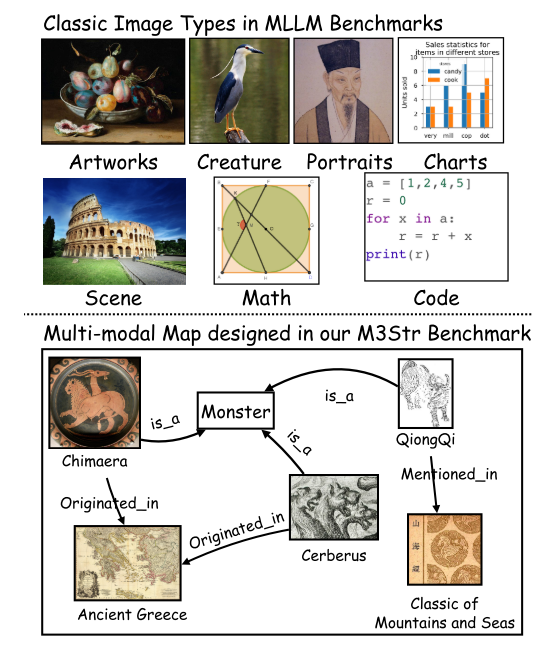
如图 1 所示,已经出现了许多系统设计的基准来评估 MLLM 的多维能力,其中包括有关自然场景、肖像、各种生物和从现实世界捕获的物体的图像。 其他一些 MLLM 基准也建立在包含数学代码和图表的合成图像上。 然而,现有的基准测试范式明显忽视了 MLLM 熟练程度的一个关键维度:对包含高度抽象结构化知识的视觉内容的理解和解释。 这种结构化表示——以思维导图和知识图谱(KG)为例,渗透到日常生活中。 与传统图像不同,这些构造同时编码具体的视觉实体和复杂的关系语义。 MLLM 不仅必须识别实体,还必须破译实体之间的关系拓扑结构和抽象连接,这将是抽象且难以理解的。
动机总结:
目前的基准测试(Benchmarks)主要集中在以下两类图像:
-
自然界实拍: 如风景、肖像、动植物。这些主要考验模型的视觉识别能力(这是什么?它在哪里?)。
-
合成图像: 如数学公式、基础图表、代码截图。这些考验模型的符号解析能力。
文中指出,现有的测试忽略了像思维导图和知识图谱这种高度抽象的内容。这类图像的特殊之处在于它们不仅是“画”,更是“逻辑”。
解决方法:
本文提出了一种新的MLLM评价视角,称为结构化知识的抽象视觉理解。
M3STR利用多通道知识图谱(MMKG)作为数据源,在图像输入中封装了不同的结构化人类知识。图1展示了图像样本的简单演示,在本文中称为多模式映射。
我们在M3STR基准测试中设计了三种类型的任务,分别称为计数、检测和完成。这些任务评估了MLLMS对多模式地图理解的不同方面。这三个任务被进一步扩展为几个细粒度的子任务,这些子任务专门针对实体和关系理解。
本文提出了一个合成多模态地图的管道,综合了结构化知识和多模态内容。首先,我们从一个大规模的MMKG中抽样子图实例。然后,我们制定特定的任务修改这些子图。 最后,我们使用可视化 API 将具有多模态信息的子图转换为图像。 此外,我们设计了一个特定于任务的提示模板来指导 MLLM。
Methodology
Preliminary
MLLM: 支持图像输入的通用MLLM可以表示为M,它可以基于图像-文本对输入生成答案A*,最大化下一个标记的预测概率。 这个过程被表示为
![]()
其中I、Q代表输入图像以及与该图像相关的文字提示(问题)。 我们的工作旨在构建一个由图像-文本对组成的基准数据集,以评估 MLLM 的抽象结构化知识理解和推理能力。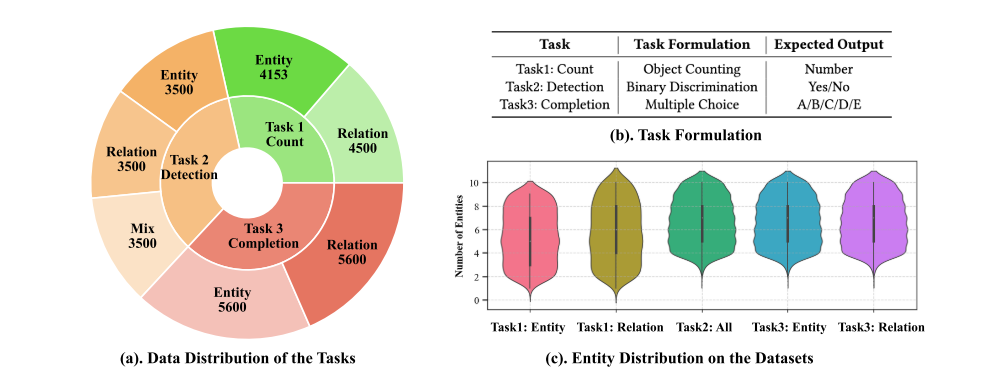
Benchmark Overview
(1)任务1:计数:此任务要求 MLLM 计算MMKG中实体和关系的数量。 该任务属于粗粒度对象识别,并评估 MLLM 对 MMKG 的表面识别。
(2) 任务2:检测:此任务要求MLLM 检测给定的MMKG 子图中是否存在事实异常,并回答“是”或“否”。 为了正确回答,MLLM 必须对 MMKG 中嵌入的常识信息表现出更高水平的判断。 通过理解 MMKG 的内容,模型必须使用二元分类输出来确定子图是否合理或包含错误。
(3) 任务3:完成:此任务要求模型根据本地上下文预测给定 MMKG 中缺失的实体/关系。 邻里信息将被提供,但答案将被屏蔽。 这样的任务设置类似于KG的经典研究课题知识图谱补全(KGC)。 成功预测丢失的组件表明 MLLM 理解当前 MMKG 并做出简单推理的能力。
Construction Process of M3STR
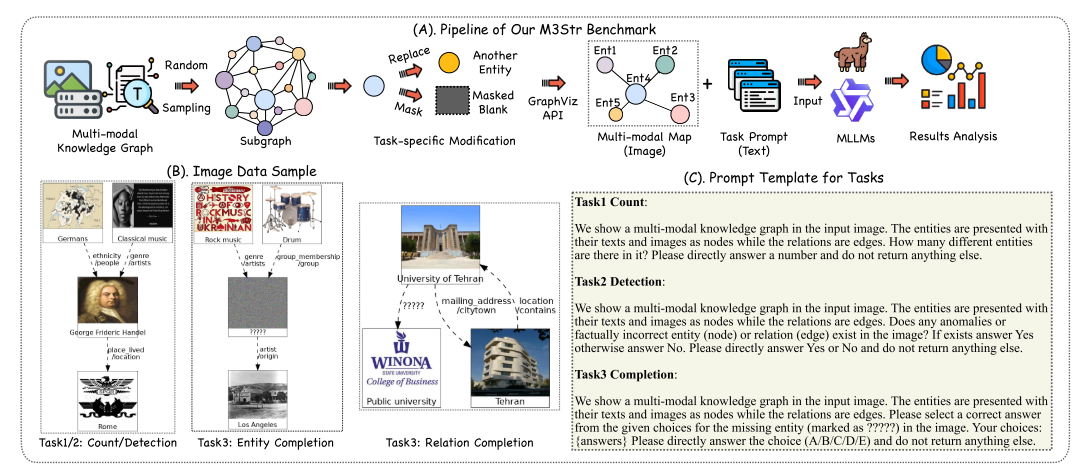
子图采样
为了评估MLLM的抽象视觉理解能力,需要(I,Q,A)形式的数据实例,它们分别是输入图像、文本提示和黄金答案。 此外,I 代表一个带有上下文信息的小型 MMKG。 因此,我们提取G′,子图来自给定的 MMKG
![]()
其中E',R'是子图G'的实体和关系子集。 T'表示子图G'中采样的三元组。 所有的集合都是原始KG的对应子集。 我们使用随机样本对给定的MMKG 进行随机采样。 给定起始实体𝑒和目标大小𝐾,子图通过以下方式获得:
![]()
其中 RandomSampler(·) 将从实体 𝑒 开始,进行迭代深度优先或广度优先搜索。 该过程持续进行,直到获得具有 𝐾 实体的子图,同时保留与这些实体关联的所有关系。 子图将在接下来的步骤中进一步修改。
数据实例构建
请注意,不同的任务有其特定的表述和设置。 因此,我们对G′进行进一步修改,将其转化为特定于任务的数据原型。 这个过程可以表示为:
![]()
其中 Modifier𝑡𝑎𝑠𝑘 (·) 是特定于任务的修改操作,A 是当前数据的黄金答案。
(1)对于计数任务,Modifier(·) 不会修改采样图。 相反,它只是简单地计算实体或关系的数量作为答案。 这是因为对象计数可以直接在原始子图上执行,无需进一步修改。
(2)对于检测任务,Modifier(·) 通过将其替换为当前子图中不存在的另一个实体来修改图中的实体或关系。 这会在子图中引入噪声和事实错误。 修改是以一定的概率进行的。 对于这些修改后的子图,黄金答案将是“是”,表明存在异常,而对于未更改的子图,它将是“否”。 这个过程类似于对比学习中的负采样。 我们通过手动破坏来构建负面实例。 总体正负样本比例控制在1:1。
(3)对于完成任务,Modifier(·) 使用虚拟占位符随机掩盖给定子图中的一个实体或关系。 然后,将被遮罩的对象视为黄金答案,同时从 MMKG 中采样其他四个潜在选项。 这允许模型根据上下文推断丢失的对象。
视觉翻译
最后,我们将修改后的子图 G′′ 转换为图像的视觉模态,这是通过可视化 API 实现的。 这个过程可以表示为:
![]()
在实践中,我们利用 GraphViz ,一个著名的图形可视化开源库。 请注意,子图 G'' 中实体的图像以及实体和关系的文本描述都在生成视觉表示时用作输入。 因此,我们获得了由子图 G′′ 的三种模态信息组成的语义丰富的图像 I:结构、实体的视觉信息以及实体的文本描述。 这些模态以最终视觉形式共存于单个图像中。 此外,我们为每个子任务准备了一个特定于任务的提示模板,该模板将作为问题 Q。对于完成任务,输入提示由五个选项的额外信息组成,以指导 MLLM 做出选择。 通过这种方式,我们在 M3STR 基准测试中为每个任务构建了数据实例(I、Q、A),旨在评估 MLLM 的抽象视觉理解和推理能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)