淘汰巨型提示词:解构Claude Code的OS微内核架构
写过长篇Prompt的人大概都有过这种绝望:你把几万字的需求、业务背景、接口定义和代码规范一股脑喂给大模型,期待它像神一样输出完美结果。但现实是,它不仅经常遗忘写在中间的关键指令,还会一本正经地胡说八道。
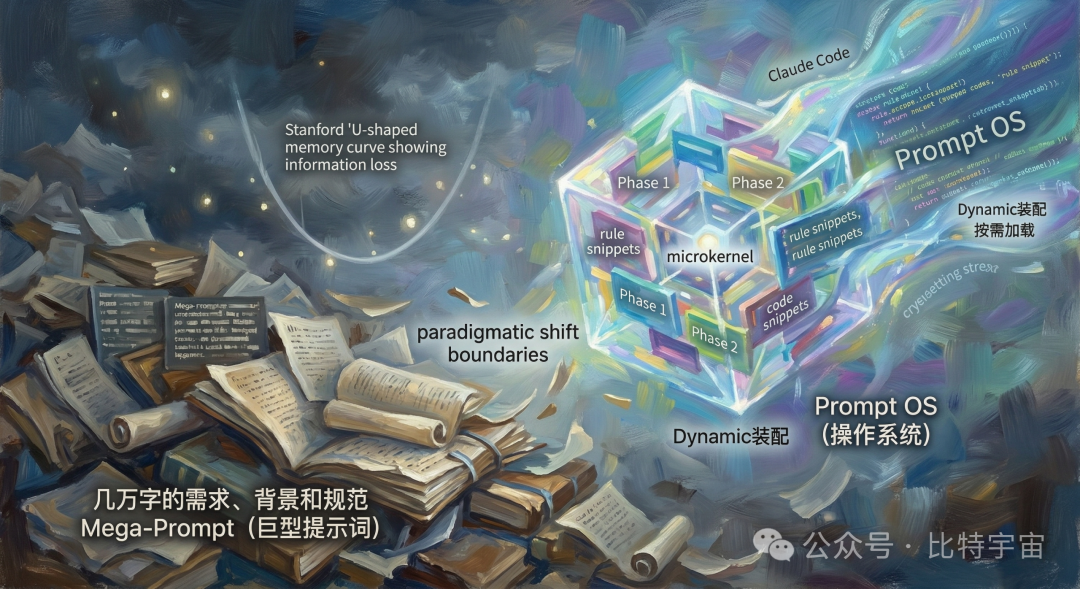
这不是你的表达能力有问题,而是大模型底层的物理法则出了问题。
最初,整个AI行业都陷入了一种对“超长上下文”的算力迷信,试图用“Mega-Prompt(巨型提示词)”解决一切复杂任务。但最近横空出世的Claude Code,彻底抛弃了这种“写小作文”的暴力美学。如果我们解剖其底层逻辑,会发现高级的提示词工程已经发生了一次悄无声息的范式转移——它不再是一段死板的静态文本,而是演变成了一个具备动态装配能力的“操作系统(OS, Operating System)”。
物理约束与“注意力稀释”的算力陷阱
要理解Claude Code为什么要打碎巨型提示词,必须先直面大语言模型(LLM)的底层物理与经济约束。
把上万行的系统级Prompt一次性喂给模型,本质上是在挑战Transformer架构的注意力极限。Stanford大学等机构的专项研究证实了长文本处理中的“U型性能曲线”现象:模型对Prompt首尾两端的信息保持着极高的敏感度,但对中间海量背景信息的提取能力呈现断崖式下跌。
这种现象在工程上被称为“注意力稀释(Attention Dilution)”。这并不是指网络安全领域的恶意数据投毒,而是指模型在庞杂的输入噪音中,迷失了当前最紧迫的核心任务。

此外,算力成本的账本同样冷酷。在频繁的多轮API交互中,每一次完整的状态回传都在极其低效地消耗KV Cache(键值缓存,用于存储已计算的历史Token特征以加速推理)。让一个Agent在执行简单的“修改变量名”任务时,依然背负着数万Token的“全局系统设计原则”上下文,这在工程和经济学上都是一种灾难。
提示词操作系统的“微内核”与JIT按需加载
从一线工程实践来看,Claude Code给出的解法堪称优雅:用空间维度的“分层状态机”换取注意力机制的精确度。它将庞大的系统提示词打碎,构建了一个类似于现代计算机操作系统的“微内核(Microkernel)”架构。
在这个体系中,Agent不再读取一段包含所有Phase(阶段)规则的静态大文本。相反,它拥有一个底层的守护进程(Daemon)。当系统进入特定工作流(如代码检索、依赖分析、代码编写、编译测试)时,调度引擎仅“激活”并向模型注入当前Phase专属的约束规则和工具列表。
这种机制完美契合了软件工程中的JIT(Just-In-Time,动态即时编译)理念。在需求分析阶段,模型只看到如何判断用户意图的提示词;当确认需要调用外部工具时,系统动态装配特定的 ,强制要求模型遵守严苛的搜索语法约束。这种极简的、按需加载的局部上下文,彻底清除了多余的噪音,使得大模型在单次交互中的指令遵循能力逼近物理极限。
这也是为什么Claude Code能够在极其复杂的工程目录中游刃有余的原因。它的提示词不是写给模型“看”的文章,而是编译给引擎“执行”的代码流。
核心争议:局部最优如何避免全局失明?
此时,一个极其尖锐的架构质疑必然浮出水面:如果每次只给模型加载局部的“微内核”提示词,这种动态按需加载机制,会不会导致Agent彻底丧失对整个项目的全局视野?
这是任何分步调度系统都无法回避的悖论。假设Agent在编写某个子模块时,由于上下文被动态切分,忘记了项目首字母大写的命名规范或底层数据库表结构,局部最优的闭环最终会导致全局架构的编译崩塌。

Claude Code的工程防御体系在此展现了深思熟虑的设计。它并没有通过无限扩张当前窗口来解决全局记忆问题,而是引入了外部记忆挂载与强锚点机制。
一方面,系统深度整合了MCP(Model Context Protocol,模型上下文协议)。
MCP就像是Agent的外部硬盘总线,允许模型在需要时,通过标准化接口主动、定向地从本地文件系统甚至远端服务器“抽取”全局依赖关系,而不是被动地在长Prompt中盲人摸象。
另一方面,通过类似 CLAUDE.md 这样的全局状态锚点(State Anchor)文件,系统在每一次上下文重置、微内核切换时,都会在Prompt的头部强行注入极其精简的全局约束字段(如当前的架构原则、必须避开的技术红线)。这种“全局微量锚点 + 局部深度指令”的双线调度,成功在降低注意力噪音与维持全局视野之间找到了平衡点。
路由容错与状态机的防御性降级
坦白说,这套动态操作系统的运转极其依赖一个脆弱的前提:大模型作为底层引擎,其意图识别和路由决策能力必须足够精准。
如果大模型在复杂的上下文跳转中“迷路”了呢?比如,Agent本该进入“代码编译错误修复”的状态,却错误地调取了“新功能需求拆解”的子提示词。这种状态机级别的误判,可能引发不可逆的级联崩溃。

为了对抗这种由模型幻觉带来的熵增,高阶的提示词系统必须内建防御性降级协议。在Claude Code的范式中,工具的使用策略拥有高于通用语言输出的绝对优先级。当引擎检测到工具调用的置信度低于特定阈值,或者连续产生不可编译的代码时,系统不会允许Agent继续凭借幻觉强行推进,而是强制截断当前的思维链(Chain of Thought)。
它会退回到上一个可靠的状态节点,甚至直接抛出异常请求人类开发者介入。宁可承认当前的认知流断裂,也不允许输出一段未经确凿验证的错误代码。这种“真实性高于叙事张力”的设计哲学,是保障Agent不会在代码库中引发灾难的最后一道防线。
结语
从最初基于正则匹配的死板问答,到精心雕琢的Few-shot模板,再到今天以Claude Code为代表的动态装配范式,提示词工程的性质已经发生了根本性改变。
未来,传统的“提示词工程师”——那些试图用优美的自然语言写出冗长长文来祈求大模型表现良好的人——或许终将边缘化。取而代之的,将是具备严密工程思维的“认知流架构师”。他们不再撰写文章,而是配置状态机;他们不去猜测模型的喜好,而是利用OS级别的分层控制、工具约束和降级协议,在算力与幻觉的物理边界上,构建出真正能在工业界落地的智能体基座。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)