【开源】在浏览器里跑YOLOv8目标检测!ONNX Runtime Web实战指南
前言
你是否想过不需要安装任何软件,直接在浏览器里就能运行YOLOv8目标检测?就像打开网页刷视频一样简单。
这不是天方夜谭,借助 ONNX Runtime Web 技术,我们真的可以在浏览器中运行复杂的深度学习模型进行实时推理。今天要介绍的QuickInfer-web就是这样一个开源项目。
为什么需要在浏览器运行AI模型?
传统的AI推理通常需要:
- 安装Python环境和各种依赖
- 配置CUDA驱动和GPU支持
- 部署模型服务到服务器
这个过程对于非技术人员来说门槛较高。而浏览器端推理的优势在于:
| 对比项 | 传统部署 | 浏览器推理 |
|---|---|---|
| 安装配置 | 需要安装Python、PyTorch等 | 无需安装,打开即用 |
| 环境配置 | 依赖版本冲突头疼 | 浏览器自带环境 |
| 跨平台 | 需要编译支持 | Windows/Mac/Linux/手机通用 |
| 分享协作 | 部署服务或打包 | 直接发链接 |
技术架构
QuickInfer-web 基于以下技术栈构建:
前端:原生 JavaScript + Vite 构建
推理引擎:ONNX Runtime Web 1.24.3
AI模型:YOLOv8 (ONNX格式)
后端支持:WASM (CPU) / WebGPU / WebGL
三种推理后端对比
| 后端 | 性能 | 兼容性 | 推荐场景 |
|---|---|---|---|
| WASM | 中等 | 所有现代浏览器 | 通用推荐,默认选项 |
| WebGPU | 最佳 | Chrome/Edge (桌面) | 高性能需求 |
| WebGL | 中高 | 所有主流浏览器 | 兼容性平衡 |
支持的模型规模
项目内置了YOLOv8全系列模型,满足不同设备和场景需求:
| 模型 | 参数量 | 模型大小 | 推荐场景 |
|---|---|---|---|
| YOLOv8n | 3.2M | ~12MB | 移动端/低配设备 |
| YOLOv8s | 11.2M | ~43MB | 日常使用 |
| YOLOv8m | 25.9M | ~99MB | 精度要求较高 |
| YOLOv8l | 43.7M | ~167MB | 桌面端使用 |
| YOLOv8x | 68.2M | ~260MB | 高精度场景 |
核心功能实测
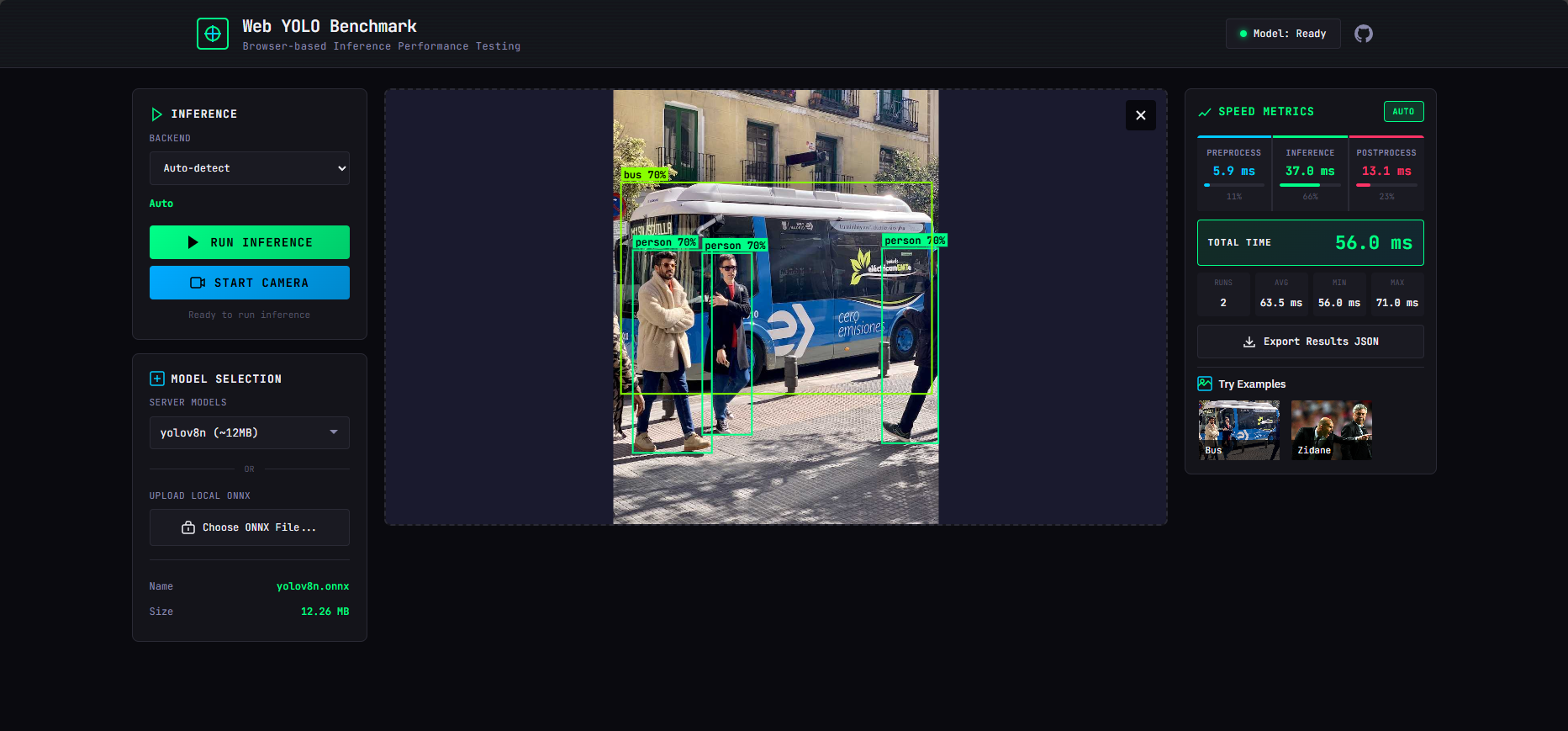
1. 图片目标检测
上传任意图片,选择模型和后端,点击运行即可得到检测结果。预处理、推理、后处理各阶段耗时一目了然。
操作流程:
1. 选择模型大小(默认YOLOv8n)
2. 选择推理后端(WASM/WebGPU/WebGL)
3. 上传图片或拖拽图片到上传区域
4. 点击 "Run Inference" 运行检测
2. 手机摄像头实时推理
这是我认为最有意思的功能——用手机浏览器打开网页,直接调用摄像头进行实时目标检测。
实测在手机Chrome上效果流畅,15FPS的推理速度配合实时预览,基本可以做到所见即检测。
支持的摄像头能力:
- Android Chrome (推荐)
- iOS Safari (需要iOS 14+)
- 桌面端摄像头通用
3. 性能指标可视化
每次推理后,系统会展示详细的性能数据:
- 预处理时间:图片 resize、归一化、Tensor转换
- 推理时间:模型前向传播耗时
- 后处理时间:NMS、框绘制
还会统计多次运行的平均值、最小值、最大值,方便你评估性能稳定性。
部署自己的模型
项目支持接入自定义ONNX模型,只需修改环境变量:
# .env 或 .env.github
VITE_MODELSCOPE_REPO=your-username/your-model-repo
VITE_MODELS=[{"name":"your-model.onnx","size":"~50MB"}]
模型文件需要上传到 ModelScope 并确保支持 CORS 跨域访问。
本地开发
如果你是开发者,可以克隆项目本地运行:
git clone https://github.com/ckfanzhe/quickinfer.git
cd quickinfer
npm install
npm run dev
然后访问 https://localhost:5173 即可。
部署到GitHub Pages也很简单:
npm run build:github
生成的文件在 dist 目录,直接推送即可自动部署。
性能表现参考
以下是不同设备、不同后端的YOLOv8n推理耗时对比(仅供参考):
| 设备 | 浏览器 | 后端 | 推理耗时 |
|---|---|---|---|
| iPhone 14 | Safari | WebGL | ~45ms |
| 小米12 | Chrome | WebGL | ~38ms |
| MacBook M1 | Safari | WebGPU | ~15ms |
| 桌面PC (RTX3060) | Chrome | WebGPU | ~8ms |
注:实际性能受图片尺寸、模型大小、系统负载等因素影响
适用场景
- 快速验证模型效果 - 不需要搭环境,直接测试ONNX模型
- 边缘设备部署演示 - 给客户展示AI能力,无需安装任何软件
- 移动端原型开发 - 测试模型在手机浏览器的运行效果
- 前端性能对比 - 量化不同后端在不同场景的推理速度
项目总结
QuickInfer-web 作为一个开源项目,提供了:
- ✅ 纯前端实现,无需后端服务
- ✅ 支持多种推理后端(WASM/WebGPU/WebGL)
- ✅ 支持手机浏览器实时推理
- ✅ 完整的性能指标可视化
- ✅ 支持自定义模型接入
- ✅ 开源免费,可自由扩展
GitHub地址:ckfanzhe/quickinfer
在线体验:QuickInfer-web
如果你对浏览器端AI推理感兴趣,这个项目值得研究。技术实现不复杂,但思路很有启发性——把计算放到边缘,浏览器就是最好的边缘计算节点。
有任何问题欢迎评论区交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)