从手动到自动,从耗时到高效:AI+MCP日志诊断技术实践
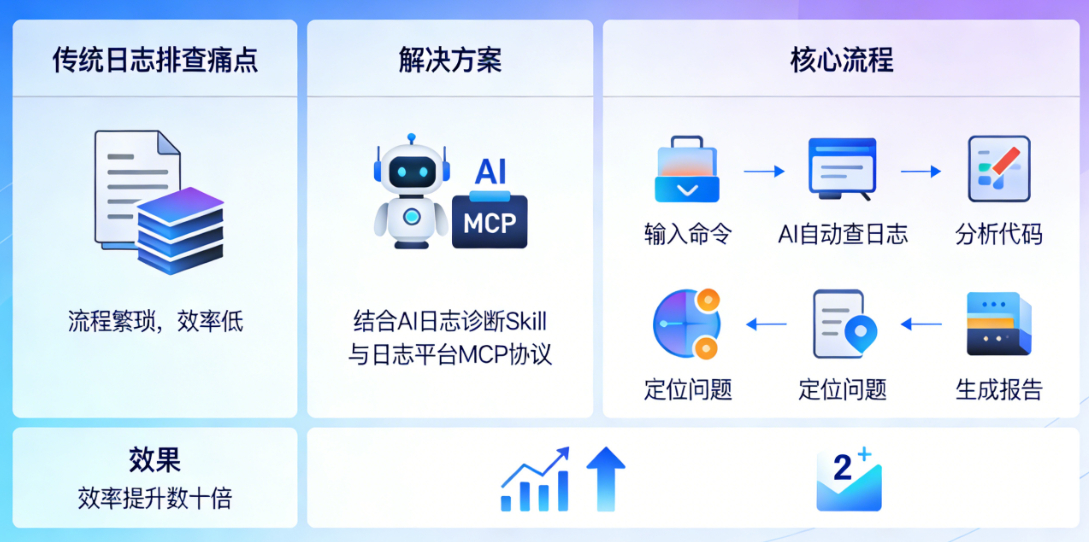
在后端开发的日常工作中,BUG排查是绕不开的核心环节,而日志分析则是定位BUG的关键手段。但很多开发者都有过这样的困扰,排查一个简单的BUG,往往要在日志平台和IDE之间反复切换,耗费大量时间在无效操作上。从输入traceId搜索日志,到从几十上百条日志中筛选关键信息,再到复制类名、方法名去IDE中查找对应代码,结合逻辑分析问题,若一次定位不准,还要重复上述流程。这种固定且繁琐的操作,不仅降低了开发效率,还容易因疲劳导致细节遗漏,让简单的BUG排查变得耗时费力。
为了解决这个痛点,我们尝试将AI与日志平台的MCP协议相结合,开发出日志诊断Skill,实现了BUG排查全流程的自动化。本文将详细分享这一技术的设计思路、核心原理、安装配置方法、实战案例以及实践中的思考,希望能为后端开发者提供参考,帮助大家摆脱繁琐的日志排查工作,将更多精力投入到核心业务开发中。
一、痛点拆解:日志排查为何如此耗时?
在深入讲解技术实现之前,我们先仔细拆解日志排查的完整流程,看看时间到底消耗在了哪里。一个典型的BUG排查流程,通常包含以下几个步骤:
第一步,日志检索。开发者拿到BUG反馈后,首先需要打开日志平台,输入traceId或相关关键词,发起日志查询请求。这个过程本身并不复杂,但如果关键词不够精准,或者日志量过大,就需要反复调整查询条件,耗时往往在几分钟甚至十几分钟。
第二步,关键日志筛选。日志查询完成后,通常会返回几十上百条甚至更多的日志记录,开发者需要逐行浏览,筛选出与BUG相关的关键日志。这一步完全依赖人工判断,不仅耗时,还容易因为日志信息繁杂而遗漏关键节点,导致排查方向走偏。
第三步,代码定位与逻辑分析。找到关键日志后,需要将日志中的类名、方法名、参数等信息复制出来,切换到IDE中找到对应的代码文件,再结合业务逻辑分析问题原因。这个过程中,频繁在日志平台和IDE之间切换,上下文切换的成本很高,很容易打断思路,影响排查效率。
第四步,反复验证。如果一次分析没有找到根因,就需要回到日志平台,重新检索日志、筛选信息、定位代码,重复上述流程,直到找到问题所在。这种反复验证的过程,往往会消耗大量的时间和精力。
更关键的是,这个排查流程虽然繁琐,但逻辑固定,不需要太多创造性思维,属于典型的重复性工程劳动。既然是重复性劳动,就有被自动化替代的可能。于是,我们开始思考,如何利用AI技术,结合日志平台的能力,实现BUG排查全流程的自动化。
二、技术探索:从初步设想到达成闭环
在探索自动化排查方案的过程中,我们经历了两次思路迭代,最终形成了AI + MCP的技术方案,实现了日志排查的全流程闭环。
2.1 初步设想:Cursor + MCP的尝试与局限
最初在思考解决方案时,我们首先想到的是利用现有工具进行组合。当时,我们尝试将Cursor与日志平台的MCP协议结合,计划将日志平台接入Cursor,再搭建一个代码知识库,让AI帮助我们自动查询日志、分析代码。
这个思路的核心的是利用AI的自然语言处理能力和代码分析能力,结合MCP协议获取日志数据,从而替代人工完成日志检索和代码定位的工作。但在实际测试过程中,我们发现这个方案存在两个明显的缺陷。
第一个缺陷是日志查询的动态性问题。日志查询依赖具体的环境、应用和时间范围,这些信息都是动态变化的,无法提前静态预置到代码知识库中。AI在查询日志时,无法灵活适配不同的查询场景,导致日志查询的准确性和灵活性不足。
第二个缺陷是代码交互的流畅性问题。这种方案虽然能实现日志查询和代码分析的基本功能,但无法做到丝滑地读代码、改代码。AI分析出问题后,开发者仍需要手动切换到IDE中修改代码,无法实现“查询-分析-修复”的无缝衔接,自动化程度不够高。
由于这两个核心缺陷,我们放弃了这个初步设想,开始寻找更优的技术方案。
2.2 思路突破:Skill + MCP的闭环实现
后来,在使用Claude Code的过程中,我们接触到了Skill的概念,这让我们的思路瞬间清晰起来。Claude Code中的Skill,本质上是一套自定义命令,开发者可以在项目中定义Skill的行为规范,描述AI应该如何执行这个命令的每个步骤,当AI收到对应命令时,会自动加载并执行,实现特定的功能。
我们意识到,日志平台有MCP协议提供的日志查询服务,Claude Code有Skill提供的自定义命令能力,将两者结合起来,就能实现BUG排查的全流程自动化。具体来说,就是通过Skill定义AI的排查流程,让AI自动调用MCP协议获取日志数据,再结合代码分析问题根因,最终生成诊断报告,形成“查日志→找关键信息→扫描代码→定位问题→生成报告”的完整闭环。
确定这个思路后,我们在相关技术人员的帮助下,开始着手开发日志诊断Skill,也就是/log-diagnosis命令。经过多次测试和优化,这个Skill最终能够稳定运行,实现了BUG排查的自动化,大幅提升了排查效率。
三、核心技术解析:MCP协议与日志诊断Skill
日志诊断Skill能够实现自动化排查,核心依赖于两个关键技术:日志平台的MCP协议和Claude Code的Skill机制。下面我们分别详细解析这两个技术的核心原理,帮助大家理解整个自动化排查流程的底层逻辑。
3.1 MCP协议:让AI能够“直接调用”日志平台
MCP的全称是Model Context Protocol,即模型上下文协议,它是日志平台推出的一套标准化工具调用协议,核心作用是让AI能够直接调用日志平台的能力,无需人工在日志平台上手动查询日志,实现日志数据的实时获取。
3.1.1 MCP协议的工作原理
MCP协议的本质是一套标准化的通信协议,它允许Claude Code通过SSE(Server-Sent Events)长连接与MCP Server进行通信,从而实时获取日志数据。SSE长连接的优势在于,能够实现服务器向客户端的单向实时推送,当日志数据更新时,MCP Server会主动将新的日志数据推送给Claude Code,确保AI能够获取到最新的日志信息,无需频繁发起查询请求。
简单来说,MCP协议相当于在AI和日志平台之间搭建了一座“桥梁”,让AI能够像人类一样,直接操作日志平台查询日志,而无需人工干预。这种方式不仅节省了人工查询的时间,还能确保日志查询的准确性和实时性。
3.1.2 MCP的核心工具与鉴权流程
MCP协议提供了一系列核心工具,用于实现日志查询、统计等功能,其中最常用的工具包括logsQuery(日志查询工具)、logSqlQuery(SQL日志查询工具)、countLogTool(日志统计工具)等。这些工具能够满足不同场景下的日志查询需求,比如简单的关键词查询、复杂的SQL查询以及日志数量统计等。
为了保证日志数据的安全性,MCP协议采用了严格的鉴权流程,只有通过鉴权的AI才能调用日志平台的能力。鉴权流程主要分为三个步骤:
第一步,获取secretKey。开发者需要在日志管理后台申请secretKey,具体路径是进入日志管理后台→日志权限→我的应用→生成密钥。secretKey是开发者的唯一身份标识,用于后续获取accessToken。
第二步,获取accessToken。通过调用acquireTokenTool工具,传入secretKey,即可获取accessToken。accessToken的有效期为1小时,最多同时存在5个,确保了鉴权的安全性和时效性。
第三步,调用MCP工具。获取accessToken后,AI在调用logsQuery、logSqlQuery等MCP工具时,需要携带accessToken,通过鉴权后才能成功获取日志数据。
3.2 日志诊断Skill:给AI一份“排查操作手册”
日志诊断Skill(/log-diagnosis)是运行在Claude Code中的自定义诊断命令,它的核心作用是给AI定义一套完整的BUG排查流程,告诉AI每一步该做什么、先做什么后做什么、遇到什么情况怎么处理,让AI能够自动完成整个排查过程。
3.2.1 Skill的工作原理
Claude Code支持通过特定目录定义自定义Skill,具体来说,就是在项目的.claude/skills/目录下(Cursor则是在.cursor/skills/目录下),创建日志诊断Skill的目录,并在目录中创建SKILL.md文件,用于描述Skill的行为规范。当开发者输入/log-diagnosis命令时,Claude会自动加载SKILL.md文件,按照文件中定义的流程执行排查操作。
日志诊断Skill的完整执行链路如下,每一步都由AI自动完成,无需人工干预:
-
用户输入命令:开发者只需输入
/log-diagnosis {环境} {代码分支} {诉求},其中环境是必填项(如测试环境、预发环境、生产环境),代码分支是可选项(留空则使用当前分支),诉求描述是包含traceId或告警信息的问题描述,用自然语言书写即可。 -
加载Skill规范:Claude收到命令后,自动加载
.claude/skills/log-diagnosis/SKILL.md文件,读取其中定义的排查流程。 -
获取环境配置:读取
.diagnosis/config.json文件,获取当前环境的配置信息,包括secretKey、accessToken等。 -
管理accessToken:检查accessToken是否过期,如果过期则自动调用
acquireTokenTool工具刷新accessToken,确保能够正常调用MCP工具。 -
确定日志时间范围:从用户提供的traceId中,提取第9-16位的16进制时间戳,计算出对应的日志时间范围,确保日志查询的精准性。
-
拉取全量日志:调用日志平台的MCP工具,分页拉取全量日志,最多拉取20页,确保不遗漏任何关键日志。
-
代码联动分析:切换到用户指定的代码分支,结合日志中的关键词,检索对应的代码文件,分析代码逻辑。
-
综合分析根因:结合上游服务日志、当前服务日志以及代码逻辑,综合分析BUG的根因。
-
生成诊断报告:将排查结果整理成诊断报告,可以生成飞书文档或本地Markdown文件,方便开发者查看和分享。
-
恢复原始分支:排查完成后,自动恢复到开发者原始的代码分支,避免影响后续开发工作。
3.2.2 Skill的核心能力
日志诊断Skill之所以能够大幅提升排查效率,核心在于它具备以下四个关键能力,这些能力解决了人工排查过程中的核心痛点:
第一,Token自动管理。accessToken的有效期只有1小时,人工维护容易忘记刷新,导致无法正常查询日志。Skill能够自动检查accessToken的有效期,过期后自动刷新,无需人工干预,确保日志查询的连续性。
第二,分页全量拉取。人工查询日志时,往往会因为疏忽只查看第一页日志,导致遗漏关键信息。Skill会严格执行分页拉取操作,直到拉完所有日志(最多20页),确保不遗漏任何关键日志节点,提高根因定位的准确性。
第三,跨服务分析。很多BUG并不是单一服务导致的,可能涉及上下游多个服务的交互。Skill能够自动识别上下游服务,拉取关联服务的日志进行交叉验证,帮助开发者快速定位跨服务的问题。
第四,代码联动。日志中出现的类名、方法名,Skill能够直接在代码中精确定位,无需开发者手动复制、切换IDE查找,实现了日志与代码的无缝衔接,大幅减少了上下文切换的成本。
3.2.3 queryString语法规则
在日志查询过程中,需要使用queryString来指定查询条件,Skill支持一套简单易懂的queryString语法规则,方便AI生成精准的查询条件。具体语法规则如下:
-
格式:
{field} {操作符} "{值}" {连接符} {field} {操作符} "{值}" -
操作符:
=表示精确匹配,≈表示模糊匹配(类似SQL中的like)。 -
连接符:
AND/OR/NOT,用于连接多个查询条件。 -
示例:
-
trace_id = "a1b2c3d4e5f6789012345678abcdef01"(精确匹配某个traceId的日志) -
trace_id = "xxx" AND log_level = "ERROR"(查询某个traceId的错误日志) -
endpoint ≈ "/api/your-endpoint" AND log_level = "ERROR"(查询某个接口的错误日志) -
message ≈ "timeout"(模糊查询包含timeout关键词的日志)
需要注意的是,时间范围只能通过start/end参数控制,不要写在queryString中,避免查询条件出错。
四、实操指南:日志诊断Skill的安装与配置
了解了MCP协议和日志诊断Skill的核心原理后,下面我们详细介绍Skill的安装与配置步骤,帮助大家快速上手使用。Skill的安装配置主要分为两个部分:安装日志平台MCP和安装日志诊断Skill,同时需要进行简单的配置,确保Skill能够正常运行。
4.1 安装日志平台MCP
MCP的安装需要根据使用的工具(Claude Code或Cursor)进行操作,两种工具的安装步骤略有不同,具体如下:
4.1.1 Claude Code安装MCP
在Claude Code的命令行中执行以下命令,按需安装对应环境的MCP Server(测试环境、预发环境、生产环境):
1. 测试环境:claude mcp add --transport sse log-mcp-t1 https://{your-t1-aigw-domain}/api/v1/mcp/log-mcp/sse
2. 预发环境:claude mcp add --transport sse log-mcp-pre https://{your-pre-aigw-domain}/api/v1/mcp/log-mcp/sse
3. 生产环境:claude mcp add --transport sse log-mcp-prd https://{your-prd-aigw-domain}/api/v1/mcp/log-mcp/sse
安装完成后,重启Claude Code,执行/mcp命令,确认MCP Server的连接状态正常,若显示连接成功,则说明MCP安装完成。
4.1.2 Cursor安装MCP
Cursor安装MCP的步骤相对简单,具体如下:
-
打开Cursor的设置界面(Setting)。
-
在设置界面中,点击Tools & MCP选项,然后点击添加MCP Server。
-
输入MCP Server的URL,MCP Server的名称可以任意填写,建议根据环境命名(如log-mcp-t1、log-mcp-pre),方便区分。
-
建议按需安装MCP Server,避免额外消耗token,以下是示例配置:
{
"mcpServers": {
"log-mcp-t1": {
"url": "https://{your-t1-aigw-domain}/api/v1/mcp/log-mcp/sse"
},
"log-mcp-pre": {
"url": "https://{your-pre-aigw-domain}/api/v1/mcp/log-mcp/sse"
},
"log-mcp-prd": {
"url": "https://{your-prd-aigw-domain}/api/v1/mcp/log-mcp/sse"
},
"log-mcp-oversea-prd": {
"url": "https://{your-oversea-aigw-domain}/api/v1/mcp/log-mcp/sse"
}
}
}
- 配置完成后,返回设置界面,即可看到MCP Server已经连接成功。
4.2 安装日志诊断Skill
日志诊断Skill的安装非常简单,只需将log-diagnosis目录放到项目的对应目录下即可,Claude Code和Cursor的目录路径略有不同,具体如下:
4.2.1 Claude Code安装Skill
将log-diagnosis目录放到项目的.claude/skills/目录下,目录结构如下:
your-project/
└── .claude/
└── skills/
└── log-diagnosis/
├── SKILL.md # 技能行为规范(核心文件)
├── README.md # 使用说明
└── reference.md # 附录:时间脚本、queryString示例等
4.2.2 Cursor安装Skill
将log-diagnosis目录放到项目的.cursor/skills/目录下,目录结构如下:
your-project/
└── .cursor/
└── skills/
└── log-diagnosis/
├── SKILL.md # 技能行为规范(核心文件)
├── README.md # 使用说明
└── reference.md # 附录:时间脚本、queryString示例等
4.3 配置.diagnosis/config.json
日志诊断Skill运行时,需要读取.diagnosis/config.json文件中的配置信息,该文件可以自动创建,也可以手动创建。
-
自动创建:首次调用
/log-diagnosis命令时,Skill会自动引导开发者创建该文件,并一步步指示开发者输入secretKey,完成配置。 -
手动创建:在项目根目录下创建
.diagnosis/config.json文件,目录结构如下:
your-project/
└── .diagnosis/
└── config.json
文件中的字段说明如下:
-
secretKey:唯一需要人工填写的字段,需要在日志平台后管申请,用于获取accessToken。
-
accessToken:首次使用时,由AI自动调用
acquireTokenTool工具获取,过期后会自动刷新,无需人工维护。 -
accessTokenExpireAt:从
acquireTokenTool返回值中自动填充,用于记录accessToken的过期时间。 -
fields:调用
logFields工具自动获取,用于记录日志中的字段信息,方便AI进行日志分析。
配置完成后,日志诊断Skill就可以正常运行了。
五、实战案例:用AI一键定位隐蔽的SQL BUG
理论结合实践才能更好地理解技术的价值,下面我们分享一个实际工作中的实战案例,看看日志诊断Skill如何一键定位一个隐蔽的SQL BUG,感受其带来的效率提升。
5.1 案例背景
某搜索接口在测试环境反馈没有返回数据,开发者拿到反馈后,没有像往常一样手动排查日志,而是直接使用日志诊断Skill,输入一条命令,就让AI全程接管排查工作。
输入的命令如下:/log-diagnosis T1 feature/your-branch trace_id: "your-trace" 为什么最终没有返回数据
这条命令中,T1是测试环境,feature/your-branch是代码分支,trace_id: "your-trace"是关键的日志检索信息,“为什么最终没有返回数据”是诉求描述,用自然语言书写即可。输入命令后,开发者无需进行任何操作,只需等待AI生成诊断报告。
5.2 AI自动排查过程
Skill触发后,AI按照预设的流程,自动完成了以下排查步骤:
第一步,推算日志时间范围。AI从用户提供的traceId中,提取第9-16位的16进制时间戳,推算出日志的时间范围为当天全天,确保能够获取到该次请求的完整日志。
第二步,刷新accessToken。AI检查发现当前的accessToken已经过期,自动调用acquireTokenTool工具,传入secretKey,获取了新的accessToken,确保能够正常调用MCP工具查询日志。
第三步,拉取全量日志。AI调用日志平台的MCP工具,分2页拉取了该traceId对应的完整日志,共73条,确保没有遗漏任何关键日志。
第四步,提取请求入参。AI从日志中自动提取出该次请求的入参信息,如下所示:
{
"assembleByOrg": true,
"channelType": "MANUAL",
"orderNo": "your-order-no",
"status": 1,
"ticketNo": "your-ticket-no"
}
第五步,还原调用链路。AI通过分析日志,自动还原了该请求的完整调用链路,明确了请求的流转过程,为后续的根因分析提供了基础。
第六步,识别关键节点。AI在日志中发现了一个关键节点:resultList is empty,也就是SQL查询返回了空结果。这说明问题不在业务逻辑层,而在DB层,排查方向瞬间聚焦到了SQL查询上。
第七步,提取查询DTO和SQL。AI从日志中提取到了toSearchDTO的组装结果,以及ORM框架打印的实际执行的SQL语句,这是定位问题的关键线索。
提取的toSearchDTO组装结果如下:
{
"channelType": "MANUAL",
"customerTag": 1,
"deliveryMode": "某配送方式",
"orderStatus": "8010",
"orderType": "0",
"productCategoryIds": [29],
"status": 1,
"ticketSource": 67,
"ticketTypeId": 5802
}
提取的实际执行的SQL语句如下:
SELECT a.id, a.pid, a.name, a.mode, a.status, a.org_id, a.org_ids,
a.ticket_group_id, a.tenant_id, a.is_del, a.channel_types
FROM your_type_table a
LEFT JOIN your_relation_table b
ON b.tenant_id = 1 AND a.id = b.type_id AND b.type = 3 AND b.is_del = 0
WHERE a.tenant_id = 1 AND a.mode = 2 AND a.is_del = 0
AND a.status = 1
AND (a.channel_types IS NULL OR a.channel_types = '' OR FIND_IN_SET('MANUAL', a.channel_types) > 0)
AND (b.root_id is null or b.root_id in (29))
AND (a.order_types IS NULL OR a.order_types = '' OR FIND_IN_SET('0', a.order_types) > 0)
AND (a.delivery_modes IS NULL OR a.delivery_modes = '' OR FIND_IN_SET('某配送方式', a.delivery_modes) > 0)
AND (a.ticket_sources IS NULL OR a.ticket_sources = '' OR FIND_IN_SET(67, a.ticket_sources) > 0)
AND (a.customer_tag IS NULL OR a.customer_tag = 1) ← BUG 在此
5.3 根因分析与修复方案
AI通过分析SQL语句,很快发现了问题所在:其他字段都处理了IS NULL和= ''(空字符串代表“不限制”)两种情况,唯独customer_tag字段只判断了IS NULL,遗漏了空字符串''的情况。
我们可以通过对比其他字段的写法,更清晰地看到这个问题:
其他字段(正确写法):AND (a.order_types IS NULL OR a.order_types = '' OR FIND_IN_SET('0', a.order_types) > 0)
customer_tag字段(错误写法):AND (a.customer_tag IS NULL OR a.customer_tag = 1)
而实际情况是,数据库中customer_tag字段的值都为空字符串(未配置),按照业务语义,空字符串应该代表“不限制”,即所有请求都应该匹配,但由于代码中遗漏了对空字符串的判断,导致所有请求都被过滤掉了,最终返回空结果。
找到根因后,AI自动在代码中定位到了对应的MyBatis Mapper XML文件,并给出了具体的修复方案:
问题代码:
<if test="customerTag != null">
and (a.customer_tag IS NULL OR a.customer_tag = #{customerTag})
</if>
修复后代码:
<if test="customerTag != null">
and (a.customer_tag IS NULL OR a.customer_tag = '' OR a.customer_tag = #{customerTag})
</if>
只需在判断条件中增加a.customer_tag = ''的判断,就能解决这个问题。
5.4 效率对比
这个BUG的隐蔽性非常高,SQL语法正确,逻辑上也“看起来”没问题,只有对比其他字段的写法,才能发现customer_tag字段独自遗漏了空字符串的处理。这类细节差异,人工排查时很容易忽略,通常需要花费1-2小时甚至更久才能定位到根因。
而使用日志诊断Skill,从输入命令到获取诊断报告,全程只花费了几分钟时间,AI自动完成了日志拉取、关键信息提取、代码定位、根因分析和修复方案建议等所有操作,效率提升了数十倍。更重要的是,AI不会因为疲劳或疏忽遗漏关键细节,定位的准确性也更高。
六、效率提升关键点:用好日志诊断Skill的技巧
日志诊断Skill虽然强大,但要想充分发挥其作用,实现效率最大化,还需要掌握一些实用技巧。结合我们的实践经验,总结出以下四个关键要点:
6.1 优先使用traceId拉取日志
traceId是单次请求的唯一标识,通过traceId拉取日志,能够精准获取该次请求的完整链路日志,包括上下游服务的日志,比关键词搜索精确得多。因此,在排查BUG时,只要有traceId,就优先使用traceId进行日志检索,能够大幅减少日志筛选的时间,提高排查效率。
6.2 关注关键日志节点
在日志分析过程中,一些关键日志节点能够帮助我们快速判断数据在哪一层丢失,缩小排查范围。比如toSearchDTO finished(DTO组装完成)、search begins(查询开始)、resultList is empty(查询结果为空)、search finished(查询完成)等,这些节点能够清晰地反映出请求的流转状态和数据变化,是定位问题的重要线索。
6.3 重视SQL打印日志
ORM框架打印的SQL日志是定位DB层问题的黄金线索,它直接反映了最终执行的查询条件,AI能够从中发现肉眼难以察觉的差异,比如字段判断遗漏、条件错误等。因此,在开发过程中,建议开启ORM框架的SQL打印功能,方便后续排查问题。
6.4 确保分页拉完所有日志
日志平台一次通常只返回部分日志数据,如果只查看第一页日志,很容易遗漏关键信息,导致排查方向走偏。日志诊断Skill会严格执行分页拉取操作,直到拉完所有日志(最多20页),但在手动排查时,开发者需要注意这一点,确保不遗漏任何关键日志。
七、技术思考:AI时代,工程师的核心竞争力
日志诊断Skill的落地,不仅解决了日志排查耗时的痛点,更让我们对AI时代工程师的核心竞争力有了新的思考。这一技术的本质,是一次对重复性工程劳动的自动化尝试,而背后的思路,值得在更多场景中延伸。
7.1 识别“固定流程”是自动化的起点
不是所有工作都适合AI接管,但凡是“步骤固定、信息来源明确、输出格式可预期”的重复性工作,都值得尝试用Skill + MCP的方式来自动化。排查BUG是一个典型的例子,类似的还有代码审查、性能分析报告生成、告警巡检等。
工程师的核心价值之一,就是识别出这些固定流程,将其转化为可自动化的能力,从而解放自己的时间,投入到更具创造性的工作中。比如代码审查中,一些固定的代码规范检查(如命名规范、注释规范),就可以通过Skill定义流程,让AI自动完成,减少人工审查的时间。
7.2 Skill的本质是“给AI写操作手册”
很多人误以为Skill是在“训练模型”,其实不然。Skill文件本质上是给AI写的一份清晰的操作手册(SOP),它不需要改变模型的底层逻辑,只需要告诉AI每一步该做什么、遇到什么情况怎么处理、有哪些约束条件。
Skill文件写得越细、约束越明确,AI的执行质量就越稳定。比如在日志诊断Skill中,我们明确规定“禁止只查第一页就下结论”“必须分页拉完所有数据”,这些约束条件确保了AI排查的准确性,避免了因疏忽导致的问题。这和写给人看的技术文档本质上是一回事,都是通过明确的规范,确保操作的一致性和准确性。
7.3 AI擅长发现“横向对比”类的BUG
在本次实战案例中,我们发现了一个有意思的规律:AI在处理“同类字段逻辑不一致”这类问题时,表现往往比人工更好。原因在于AI没有“先入为主”的经验偏见,不会因为“这段代码看起来没问题”就跳过,它会对所有字段做同等的审查,通过横向对比,发现其中的差异。
这类横向对比类的BUG,人工排查时很容易因为思维定式而遗漏,而AI的“客观视角”恰好能够弥补这一不足。因此,在后续的开发和排查工作中,我们可以充分利用AI的这一优势,将一些需要横向对比的工作交给AI来完成,提高工作效率和准确性。
7.4 工程师的核心竞争力:将经验转化为AI能力
AI时代,工程师的核心竞争力不再只是“能写代码”,更是“能把自己的经验和流程转化成可复用的AI能力”。日志诊断Skill的开发,正是基于我们多年来排查BUG的经验,将这些经验转化为Skill的操作规范,让AI能够替代人工完成排查工作。
未来,随着AI技术的不断发展,会有更多的重复性工作被AI接管,而工程师需要做的,就是不断总结自己的经验,将其转化为可自动化的能力,同时专注于核心业务的创新和技术难点的突破,实现自身价值的提升。
八、总结
日志诊断Skill的落地,是AI与工程实践深度结合的一次成功尝试。它通过MCP协议让AI能够直接调用日志平台的能力,突破了AI只能处理静态上下文的限制,实现了动态日志数据的实时获取;通过Skill机制给AI定义了完整的排查流程,将一次性对话变成了可复用的工程化能力。两者相结合,实现了BUG排查全流程的自动化,大幅提升了开发效率,减少了重复性劳动。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)