一文吃透机器学习:从三要素到模型评估,这篇全讲明白了
手把手带你理解特征工程、过拟合、梯度下降和评价指标,附代码示例
你有没有遇到过这种情况:学了一大堆机器学习算法,但拿到一个真实问题还是不知道怎么下手?或者调参调了半天,模型效果就是上不去?其实,很多初学者都忽略了一个关键——机器学习不只是一堆算法的堆砌,而是一套完整的方法论。今天,我就用最通俗的语言,把机器学习从理论到实践的完整知识体系讲清楚。这篇文章涵盖了数据、特征工程、模型训练、评估优化、求解算法和评价指标,几乎是你入门机器学习需要的所有核心内容。
一、机器学习的三要素
任何机器学习方法都可以拆解为三个部分:模型、策略和算法。用一个生活中的例子来理解:你想学会预测明天的天气。模型就是你脑子里用来判断天气的规则(比如“如果晚上有晚霞,明天就是晴天”);策略是你用来评判这个规则好不好的标准(比如连续一周预测正确的次数);算法则是你具体怎么调整规则来让准确率变高的方法(比如根据每天的预测错误去修改规则)。这三者缺一不可,构成了机器学习的完整骨架。
模型是我们要学习的规律,用数学语言描述的一个参数系统。比如最简单的线性回归模型:房价 = 系数1 × 面积 + 系数2 × 卧室数 + 常数。这里的系数就是需要从数据中学习的参数。
策略是选取最优模型的评价准则。我们通常用一个“损失函数”来度量模型预测的好坏,损失越小模型越好。比如用预测值和真实值之差的平方作为损失。
算法是选取最优模型的具体计算方法。给定训练数据和损失函数,我们需要一个算法去找到使损失最小的那组参数。最常用的就是梯度下降法。
有了这个基本框架,我们再来看看机器学习具体有哪些类型。
二、机器学习的主要分类
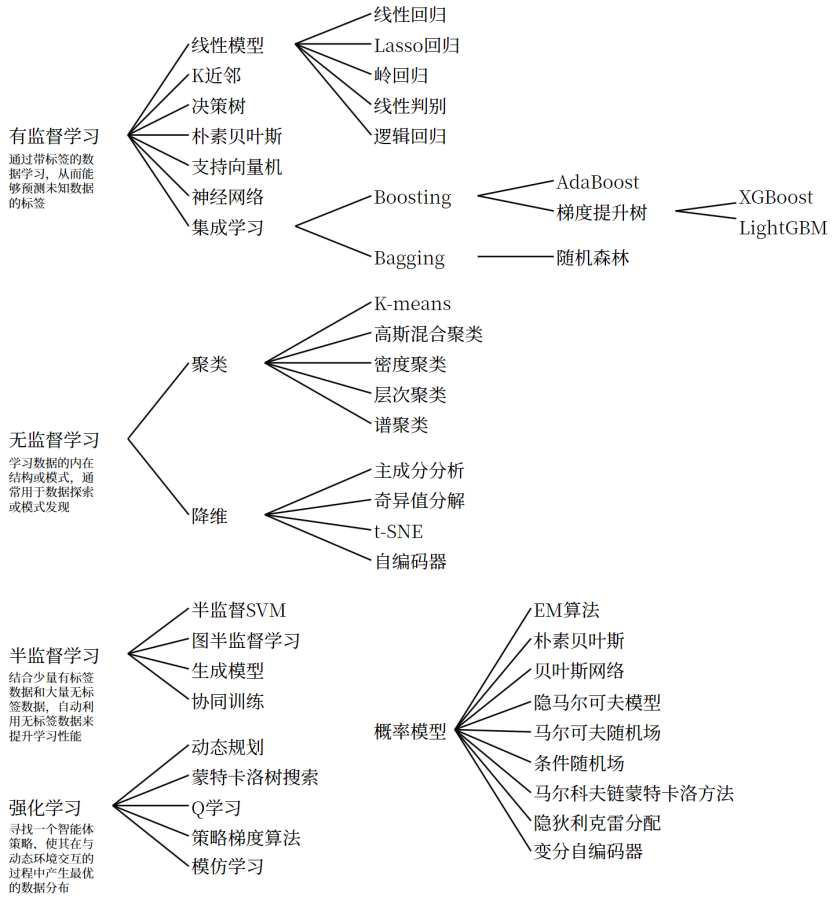
按照有无监督信号,机器学习可以分为三类:有监督学习、无监督学习和强化学习。
有监督学习是最常见的类型。它的特点是训练数据既有特征又有标签。比如你给模型一大堆房屋数据,每一条都标注了最终成交价格,模型通过学习这些“标准答案”来掌握房价的规律。有监督学习又分为回归(预测连续值,如房价、温度)和分类(预测离散类别,如猫/狗、垃圾邮件/正常邮件)。常见的算法包括线性回归、逻辑回归、决策树、支持向量机、神经网络、K近邻,还有集成学习(如随机森林、XGBoost、LightGBM、AdaBoost、梯度提升树等)。这些算法各有特点,但背后的逻辑都是通过带标签的数据学习,从而能够预测未知数据的标签。
无监督学习则完全不提供标签,让模型自己去发现数据中的结构或模式。最典型的应用是聚类,比如把相似的客户自动分成不同的群体,不需要事先知道每个客户属于哪一类。K-means、高斯混合聚类、密度聚类、层次聚类、谱聚类都是常用的聚类算法。此外,降维(主成分分析PCA、t-SNE、自编码器等)也是无监督学习的重要分支,常用于数据探索或模式发现。
半监督学习介于两者之间,只提供少量有标签的数据和大量无标签的数据,自动利用无标签数据来提升学习性能。常见的半监督学习方法包括半监督SVM、EM算法、图半监督学习、生成模型等。
强化学习则是一种不同的范式。智能体通过与环境交互,获得延迟的回报,不断改进行为,最终在动态环境中产生最优策略。Q学习、策略梯度算法、蒙特卡洛树搜索、马尔科夫链蒙特卡洛方法(MCMC)等都是强化学习的代表。
三、建模流程:从原始数据到可用模型
一个典型的监督学习项目,通常包含以下步骤。我们用一个房价预测的例子来串联整个流程。
首先是收集数据。你需要收集用于训练和测试的数据集,确保数据能代表实际问题的不同方面。比如你要预测房价,就需要收集房屋的面积、卧室数、所在街区、是否学区、是否售出等信息。
然后是数据清洗。去除脏数据和不可用的数据,比如处理缺失值、删除重复记录、修正异常值。这一步虽然枯燥,但往往决定了模型质量的上限。
接下来是特征工程(后面会详细展开)。对数据进行转换和格式化,使其适合机器学习模型训练。比如把“海淀”“朝阳”这样的文本变成数值编码。
选择算法也非常重要。根据任务类型(分类、回归、聚类等)和数据特征来选择合适的机器学习算法。房价预测属于回归问题,可以选择线性回归、决策树回归或随机森林等。
模型训练就是用训练数据集来训练模型,让模型从数据中学习规律或模式。这一步通常只需要调用一行代码,但背后是优化算法在迭代更新参数。
模型评估使用测试数据集评估模型性能,判断是否达到预期目标。我们会计算各种指标,比如均方误差、准确率等。
模型优化是在确保模型有较好性能的基础上,进一步提高效果,比如调整超参数、增加正则化、进行特征选择等。
最后是模型部署,将训练好的模型放到生产环境中,并实时监控它的表现。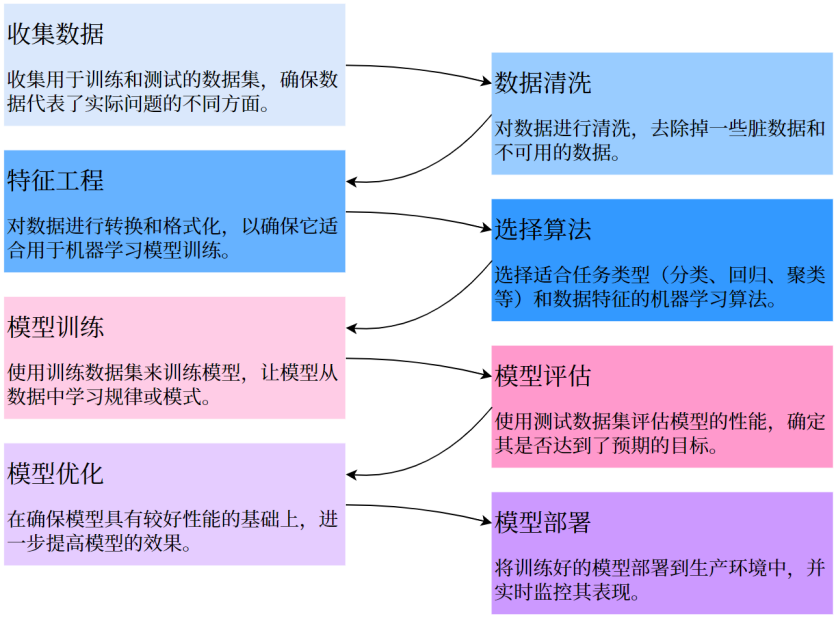
四、特征工程详解
在机器学习圈子里流传着一句话:数据和特征决定了模型的上限,而算法只是逼近这个上限。特征工程就是对原始数据进行处理、转换和构造,生成更有效的特征,从而提高模型性能。
4.1 特征选择
特征选择是从原始特征中挑选出与目标变量关系最密切的特征,剔除冗余、无关或噪声特征。这样做可以减少模型复杂度、加速训练、降低过拟合风险。特征选择不会创建新特征,也不会改变数据结构。
常用的特征选择方法有三类:
过滤法基于统计测试(如卡方检验、相关系数、信息增益)来评估特征与目标的关系,选择最相关的特征。
包裹法使用模型本身来评估特征重要性,比如递归特征消除(RFE)。
嵌入法则利用模型自带的特征选择机制,如决策树的特征重要性、L1正则化的特征选择(Lasso会自动把不重要的系数变为0)。
一个最简单的特征选择方法是低方差过滤。如果一个特征的所有样本值几乎相同(方差很低),那它对预测的影响微乎其微,可以直接去掉。在sklearn中,一行代码即可实现:
from sklearn.feature_selection import VarianceThreshold
var_thresh = VarianceThreshold(threshold=0.01)
X_filtered = var_thresh.fit_transform(X)4.2 特征转换
特征转换是对数据进行数学或统计处理,使其更适合模型的输入要求。常见操作包括:
归一化将特征缩放到特定范围(通常是0到1之间),适用于对尺度敏感的模型,如KNN和SVM。标准化通过减去均值并除以标准差,使特征分布具有均值0、标准差1。对数变换则能把有偏态的分布(如收入、价格)转化为更接近正态的形态。
对于类别变量,我们需要进行编码。独热编码将类别型变量转换为二进制列,适合无序类别特征(如颜色:红、绿、蓝 → 100,010,001)。标签编码将类别映射为整数,适合有序类别特征(如小、中、大 → 1,2,3)。目标编码用每个类别对应的目标变量的平均值来替换类别,频率编码则用类别出现的频率来替换。
4.3 特征构造
特征构造是基于现有特征创造出新的、更有代表性的特征。这通常是特征工程中最能体现创造力的部分。比如,将年龄和收入相乘得到“收入年龄指数”;从日期中提取“星期几”、“是否周末”、“月份”等;在时间序列中计算滑动窗口的平均值、最大值、标准差等统计特征。
4.4 特征降维
当特征数量非常大时(比如图像数据每个像素就是一个特征),我们可能需要在保持数据本质信息的前提下减少特征数量。这就是降维。降维和特征选择的区别在于:特征选择是挑选原有特征的子集,而降维会创造出新的低维特征。
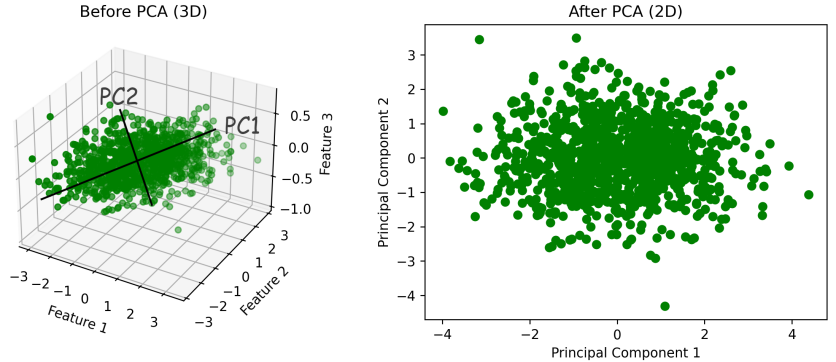
主成分分析(PCA) 是最经典的线性降维方法。它通过线性变换将原始特征映射到一个新空间,使得新特征(主成分)尽可能保留数据的方差。PCA特别适合数据存在线性相关性的情况。比如三维数据中,如果大部分变化只发生在二维平面上,PCA可以自动找出这个平面并把数据投影上去,丢掉那个几乎没有变化的维度。
线性判别分析(LDA) 是一种监督降维方法,它通过最大化类间距离与类内距离的比率来降维,适合分类问题。t-SNE则是一种非线性降维技术,特别适合将高维数据可视化到二维或三维空间。自编码器用神经网络实现降维,可以学习到非常复杂的非线性映射。
我们来看一个PCA的实际例子。假设我们生成一个三维数据集,其中有两个主成分方向和一个噪声方向。使用PCA将3维数据降维到2维:
import numpy as np
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 构造三维数据
n_samples = 1000
component1 = np.random.normal(0, 1, n_samples)
component2 = np.random.normal(0, 0.2, n_samples)
noise = np.random.normal(0, 0.1, n_samples)
X = np.vstack([component1 - component2,
component1 + component2,
component2 + noise]).T
# 标准化后应用PCA
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_standardized)降维后数据从3维变成2维,但大部分变化信息被保留,可视化效果也更清晰。
4.5 特征相关性分析
在特征工程中,我们经常需要分析特征与目标变量之间、特征与特征之间的相关性。皮尔逊相关系数衡量两个变量的线性相关性,取值范围[-1,1]。接近1表示正相关,接近-1表示负相关,接近0表示不相关。比如分析广告投放与销售额的关系:
import pandas as pd
advertising = pd.read_csv("data/advertising.csv")
# 计算各特征与Sales的皮尔逊相关系数
print(X.corrwith(y, method="pearson"))
# 输出可能为:TV 0.78, Radio 0.58, Newspaper 0.23这个结果说明TV广告投放与销售额有较强的正相关关系,而报纸广告的相关性很弱。
斯皮尔曼相关系数则用于衡量两个变量之间的单调关系(不一定线性),适用于非线性关系或数据不符合正态分布的情况。它的计算基于变量的等级而不是原始值。例如学习时长与考试成绩的数据,即使不是严格的线性关系,斯皮尔曼相关系数也能很好地捕捉到正相关趋势。
五、模型评估和模型选择
5.1 损失函数
损失函数用来衡量模型一次预测的偏差程度,记作L(Y, f(X))。常见的有:
- 0-1损失函数:预测正确为0,错误为1。
- 平方损失函数:(Y - f(X))²。
- 绝对损失函数:|Y - f(X)|。
- 对数似然损失函数:常用于逻辑回归和分类问题。
5.2 经验误差与泛化误差
给定训练数据集T={(x1,y1),...,(xn,yn)},模型在训练集上的平均损失叫做经验误差(也叫经验风险)。我们的直觉是让经验误差最小,这叫经验风险最小化(ERM)。但只追求训练误差小是不够的,模型还需要在未见过的数据上表现好,即泛化误差小。
5.3 欠拟合与过拟合
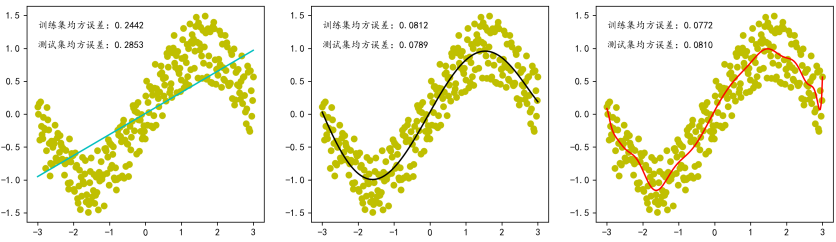
这是初学者最容易混淆的两个概念。欠拟合是指模型连训练数据都没学好,训练误差和测试误差都很大。模型太简单,就像一个学生只背了公式但不会灵活运用。过拟合则相反,模型在训练数据上表现完美,但在测试数据上一塌糊涂。模型太复杂,把训练数据中的随机噪声也学进去了,就像学生把练习题的答案背得滚瓜烂熟,但题目稍微一改就傻眼了。
用一个实际的例子来演示。我们用多项式函数去拟合带噪声的sin(x)数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 生成数据
X = np.linspace(-3, 3, 300).reshape(-1, 1)
y = np.sin(X) + np.random.uniform(-0.5, 0.5, 300).reshape(-1, 1)当使用1次多项式(一条直线)拟合时,模型欠拟合,训练和测试误差都很大。使用5次多项式拟合时,模型恰到好处,训练和测试误差都较小。使用20次多项式拟合时,模型过拟合,训练误差极低但测试误差反而升高。
过拟合的常见原因:模型复杂度过高、参数太多、训练数据不足、特征过多、训练时间过长。欠拟合的原因:模型复杂度过低、特征不足、训练不充分、正则化过强。
解决过拟合的方法:减少模型复杂度、增加训练数据、使用正则化、交叉验证、早停。解决欠拟合的方法:增加模型复杂度、增加特征、增加训练时间、减少正则化强度。
5.4 正则化
正则化是限制模型复杂度、防止过拟合的利器。它的做法是在损失函数中加一个额外的惩罚项,惩罚大的参数值。
L1正则化(Lasso回归)加入参数绝对值之和:Loss = 原Loss + λ∑|ω|。L1会使部分参数变为0,产生稀疏解,自动进行特征选择。
L2正则化(岭回归)加入参数平方和:Loss = 原Loss + λ∑ω²。L2会使所有参数变小但不会归零,模型更平滑。
ElasticNet结合了L1和L2,通过参数α控制两者的比例。
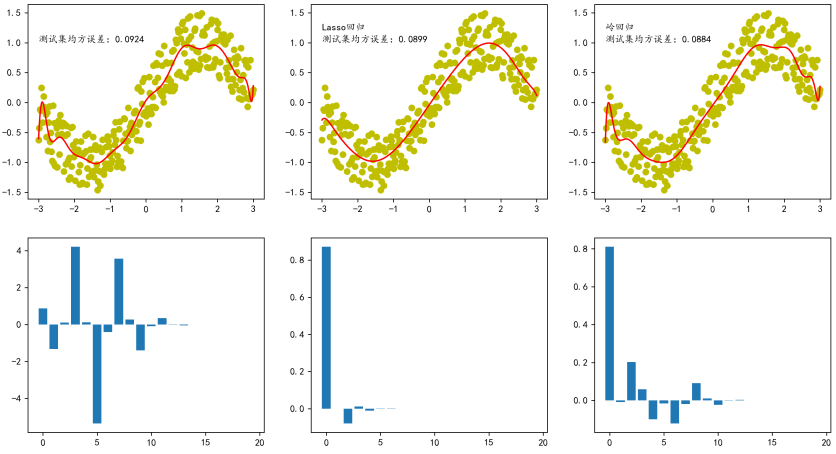
我们再用多项式拟合的例子来看正则化的效果。用20次多项式拟合(容易过拟合),分别用普通线性回归、Lasso(L1)和Ridge(L2)来训练:
from sklearn.linear_model import Lasso, Ridge
# 普通线性回归(过拟合)
model = LinearRegression()
model.fit(X_poly, y)
# L1正则化
lasso = Lasso(alpha=0.01)
lasso.fit(X_poly, y)
# L2正则化
ridge = Ridge(alpha=1)
ridge.fit(X_poly, y)观察学到的20个系数:普通线性回归的系数很大且杂乱;Lasso回归的许多系数变成了0;Ridge回归的系数整体变小了但都不为0。正则化系数λ是一个超参数,需要在训练前设定,较大的λ会强制模型更简单,较小的λ则更灵活。
5.5 交叉验证
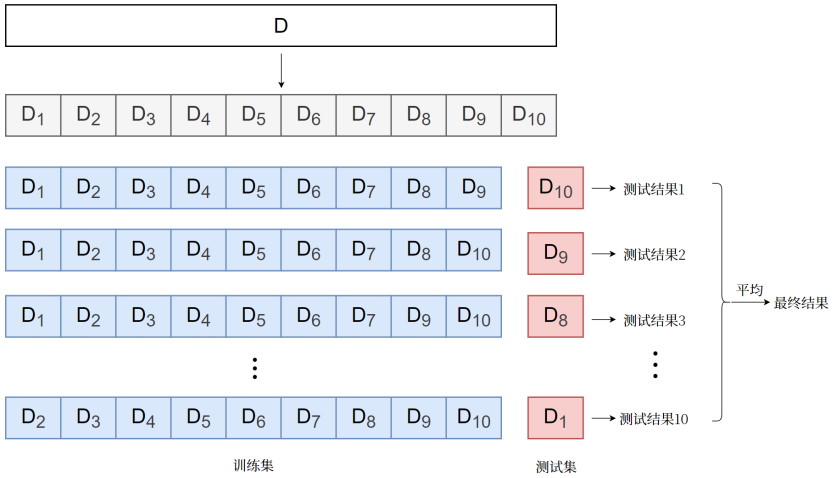
交叉验证是一种更可靠的模型评估方法。它通过多次划分数据集,取平均性能来减少单次划分的偶然性。
最简单的简单交叉验证(Hold-Out)只做一次训练集/验证集划分,结果可能不稳定。k折交叉验证将数据均匀分成k份,每次用k-1份训练、1份验证,重复k次后取平均。k通常取5或10。留一交叉验证(LOO)每次留一个样本做验证,计算成本极高,适用于小数据集。
六、模型求解算法
正则化后的损失函数本质上是一个最优化问题:找到使目标函数最小的参数。这个问题的求解算法可以分为两类。
6.1 解析法
如果目标函数可以用数学公式直接求出最优参数的表达式,这种方法叫做解析法。例如线性回归的最小二乘法可以直接解出β = (X^T X)^{-1} X^T y。加入L2正则化后,岭回归的解析解是β = (X^T X + λI)^{-1} X^T y。解析法的优点是精确、高效,但要求目标函数可导且导数方程有解析解,当特征维度很大时矩阵求逆的计算量极大。
6.2 梯度下降法
大多数情况下我们无法得到解析解,这时候就需要迭代算法,其中梯度下降法是最简单、最经典的方法。核心思想是:沿着损失函数的负梯度方向更新参数,因为负梯度方向是函数下降最快的方向。更新公式为 θ_{k+1} = θ_k - α ∇L(θ_k),其中α是学习率(步长)。
梯度下降法有三种主要变体:
- 批量梯度下降(BGD):每次迭代使用全部训练数据计算梯度,稳定但计算开销大。
- 随机梯度下降(SGD):每次随机选一个样本计算梯度,速度快但更新方向波动大,容易震荡。
- 小批量梯度下降(MBGD):每次使用一小批样本(如32或64个)计算梯度,兼顾稳定性和速度,是最常用的方法。
以一个简单的例子理解梯度下降。我们要求函数J(x) = (x² - 2)²的最小值(即找到√2)。从x=1开始,学习率α=0.1,梯度J'(x)=4x³-8x。第一次更新:x = 1 - 0.1×(4-8)=1.4。第二次:x=1.4 - 0.1×(-0.224)=1.4224。经过多次迭代,x会越来越接近1.4142。
def J(x):
return (x**2 - 2)**2
def gradient(x):
return 4*x**3 - 8*x
x = 1
alpha = 0.1
while J(x) > 1e-30:
grad = gradient(x)
x = x - alpha * grad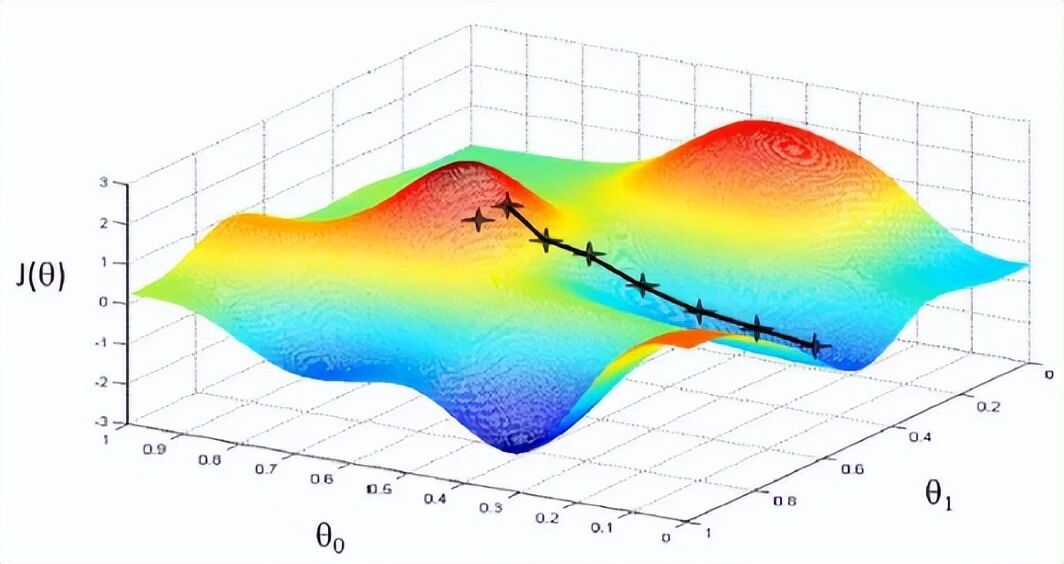
\在Lasso回归中,L1正则化的梯度是λ·sign(ω_j),当ω_j很小且穿过0时会直接变成0,从而产生稀疏性。在岭回归中,L2正则化的梯度是2λω_j,相当于每次更新时都对ω_j进行“衰减”,但不会归零。
除了梯度下降法,牛顿法和拟牛顿法利用二阶导数信息,收敛速度更快但计算复杂度更高,适合中小规模的凸优化问题。
七、模型评价指标
模型训练完成后,我们如何评价它的好坏?不同的问题类型需要不同的评价指标。
7.1 回归问题的评价指标
- 平均绝对误差(MAE):MAE = (1/n)∑|y_i - f(x_i)|。对异常值不敏感,解释直观。
- 均方误差(MSE):MSE = (1/n)∑(y_i - f(x_i))²。会放大较大误差,对异常值敏感。
- 均方根误差(RMSE):RMSE = √MSE。量纲与目标变量一致,便于直观理解。
- R²(决定系数):R² = 1 - ∑(y_i - f(x_i))² / ∑(y_i - ȳ)²。衡量模型对目标变量的解释能力,越接近1越好。
7.2 分类问题的评价指标
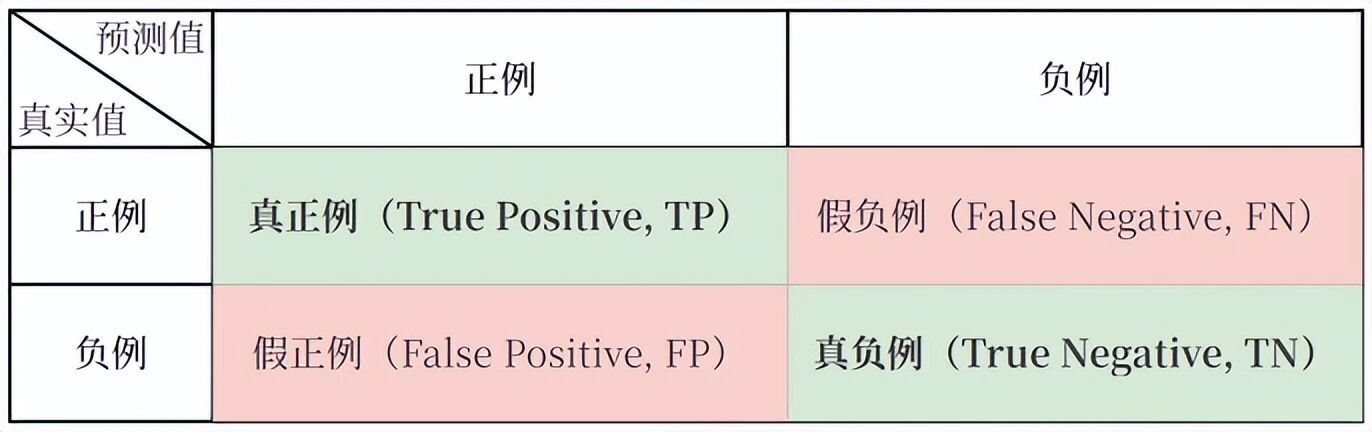
分类问题的评价体系基于混淆矩阵。对于二分类,混淆矩阵是一个2×2表格:
- TP(真正例):实际为正,预测为正
- FN(假负例):实际为正,预测为负
- FP(假正例):实际为负,预测为正
- TN(真负例):实际为负,预测为负
基于混淆矩阵,我们可以计算出一系列指标:
准确率(Accuracy) = (TP+TN) / (TP+TN+FP+FN)。即所有预测正确的比例。但当数据不平衡时(如99%是负例),准确率会失真。
精确率(Precision) = TP / (TP+FP)。预测为正例的样本中实际为正例的比例。又叫查准率。在垃圾邮件过滤中,精确率低意味着正常邮件被误判为垃圾邮件,这是不能容忍的。
召回率(Recall) = TP / (TP+FN)。实际为正例的样本中被预测为正例的比例。又叫查全率。在癌症筛查中,召回率必须高,宁可误诊也不能漏掉真正的患者。
F1分数 = 2 × (Precision × Recall) / (Precision + Recall)。精确率和召回率的调和平均,当两者都重要时使用。
使用sklearn可以轻松计算这些指标:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
y_true = ["猫", "猫", "猫", "猫", "猫", "猫", "狗", "狗", "狗", "狗"]
y_pred = ["猫", "猫", "狗", "猫", "猫", "猫", "猫", "猫", "狗", "狗"]
# 准确率
acc = accuracy_score(y_true, y_pred) # 0.7
# 精确率(指定正例为"猫")
prec = precision_score(y_true, y_pred, pos_label="猫") # 5/(5+2)=0.714
# 召回率
rec = recall_score(y_true, y_pred, pos_label="猫") # 5/(5+1)=0.833
# F1分数
f1 = f1_score(y_true, y_pred, pos_label="猫") # 0.769更方便的是使用classification_report一次性输出所有分类指标:
from sklearn.metrics import classification_report
report = classification_report(y_true, y_pred, target_names=["猫", "狗"])
print(report)ROC曲线和AUC是评估二分类模型性能的另一个重要工具。ROC曲线以假正例率(FPR)为横轴,真正例率(TPR,即召回率)为纵轴,展示不同分类阈值下模型的表现。曲线越靠近左上角,模型性能越好。AUC是ROC曲线下的面积,取值在0.5到1之间。AUC=0.5表示模型和随机猜测差不多,AUC=1表示完美分类器。AUC对数据不平衡不敏感,因此在很多实际问题中比准确率更可靠。
from sklearn.metrics import roc_auc_score
# y_true是真实标签(0/1),y_score是预测为正例的概率
auc = roc_auc_score(y_true, y_proba)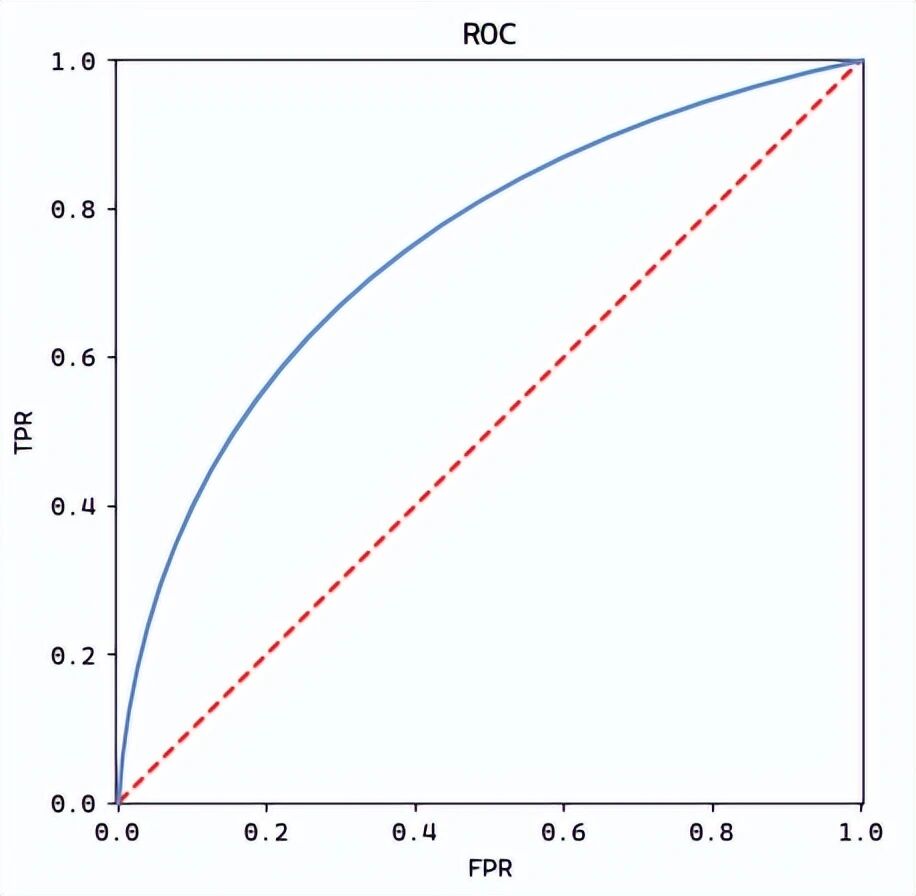
八、总结与展望
到这里,我们已经走完了机器学习从理论到实践的完整路径。让我们回顾一下核心内容:
机器学习方法由模型、策略、算法三要素构成。模型是数学表达,策略是评价准则,算法是求解方法。
按学习方式,机器学习分为有监督学习、无监督学习、半监督学习和强化学习。有监督学习需要标签,无监督学习不需要标签,强化学习通过与环境交互学习。
特征工程是提升模型性能的关键,包含特征选择、特征转换、特征构造和特征降维。低方差过滤、相关系数分析、PCA是常用技术。好的特征往往比复杂的模型更有效。
模型评估要关注欠拟合和过拟合。欠拟合是模型太简单,过拟合是模型太复杂。正则化(L1/L2)和交叉验证是防止过拟合的利器。
模型求解最常用的是梯度下降法,通过沿着负梯度方向迭代更新参数来找到最优解。学习率的选择至关重要。
评价指标因任务而异:回归任务常用MSE、RMSE、MAE、R²;分类任务常用混淆矩阵、准确率、精确率、召回率、F1分数、ROC和AUC。选择哪个指标取决于具体的业务目标。
机器学习不是一蹴而就的技能,它需要在实践中不断打磨。当你下次拿到一个实际问题时,希望你能按照这个框架一步步推进:理解问题 → 收集数据 → 特征工程 → 选择模型 → 训练评估 → 优化部署。每走一步,你都清楚地知道自己在做什么、为什么这么做。
最后送你一句话:数据是燃料,特征是引擎,模型是驾驶员。没有好的数据,一切无从谈起;没有好的特征,模型跑不起来;没有好的模型,到不了目的地。三者缺一不可,但最重要的永远是——动手实践。光看不练,永远只是纸上谈兵。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)