【机器学习实战】从KNN到逻辑回归:带你硬核打通心脏病预测全流程与算法底层逻辑
摘要: 机器学习可以划分监督学习+无监督学习+强化学习+生成模型等。其中监督学习占据大头,而监督学习依靠预测结果为离散数据还是连续数据,又划分成分类和回归两大问题。
前面以医疗费用为例,介绍过回归问题,主要介绍了线性回归、岭回归、Lasso以及多项式回归,详情可见:保姆级入门|医疗费用预测全流程实战:从 EDA 到线性回归/岭回归/Lasso/多项式回归,附完整代码 + 原理详解-CSDN博客
而本文则记录了分类算法的完整实战历程,以经典的“心脏病预测(二分类任务)”数据集为例,依然是从零开始走通了数据分析(EDA)、特征工程、模型构建与评估的全流程,还横向对比了K近邻(KNN)与逻辑回归(Logistic Regression)的性能差异。
引言:心脏病是全球致死率最高的疾病之一,精准、快速的早期诊断对降低病死率至关重要。传统的心脏病诊断依赖医生的临床经验和人工分析生理指标,存在主观性强、效率低等问题。机器学习算法能够基于患者的临床特征(如年龄、血压、胆固醇水平、心电图指标等)构建分类模型,实现心脏病的自动化预测,为临床诊断提供客观、高效的辅助决策依据。
在众多机器学习分类算法中,K 近邻(K-Nearest Neighbor, KNN)和逻辑回归(Logistic Regression)是两类经典且适用于医疗分类场景的核心算法:
- KNN 以其简单直观、无需训练过程的特性,成为快速验证特征有效性的基准算法;
- 逻辑回归则以可解释性强、能输出概率结果的优势,成为医疗场景中极具实用价值的模型(医疗决策中,概率结果可辅助医生判断风险等级)。
本文先深入剖析这两种算法的核心原理、特性及在心脏病预测场景中的适配性,再基于实际数据集进行详细的全流程分析。
一、核心算法原理解析:
在进入代码实战前,我们先搞懂本次项目使用的两大核心算法。
1. K 近邻算法 (K-Nearest Neighbors, KNN)
1.1 核心思想与原理:
“近朱者赤,近墨者黑”
KNN 是一种非常直观的非线性分类器。当输入一个未知的新病人数据时,KNN 会在多维空间中计算这个病人与训练集中所有已知病人的“距离”(通常是欧氏距离)。然后找出距离最近的K个邻居,看看这K个人里是有病的多数还是没病的多数,通过“少数服从多数”来决定当前病人的预测结果。
以心脏病预测为例,其核心步骤为:
- 距离计算:常用欧几里得距离(适配标准化后的数值型特征),计算公式为
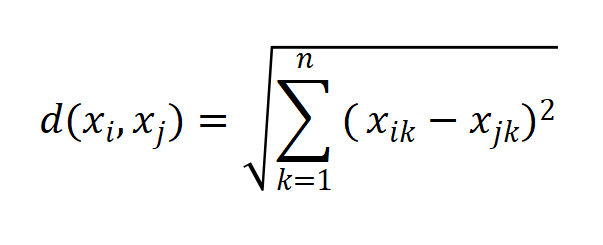
、
为两个患者样本,n为特征维度(如年龄、血压、胆固醇等),
表示第i个样本的第k个特征值。
2. 邻居选取:对所有训练样本的距离排序后,选取前K个距离最小的样本;
3. 类别表决:统计K个邻居的心脏病诊断结果(0=无病,1=有病),取占比最高的类别作为当前样本的预测结果。
1.2 关键参数与核心特性
- 核心参数 K:K的取值直接决定模型性能:
- K过小(如K=1):模型易过拟合,对噪声样本敏感(比如一个异常的无病样本可能误判为有病);
- K过大(如K=20):模型易欠拟合,距离较远的无关样本会稀释近邻的有效信息;
- 最优K需通过遍历验证(如本文遍历K=1~20),结合测试集准确率确定。
- 惰性学习特性:KNN 无显式训练阶段,所有计算都在预测时完成。优点是对新增样本适配性强(无需重新训练),缺点是预测速度随训练集规模增大而显著降低;
- 数据预处理敏感性:由于依赖距离计算,特征的量纲差异会主导距离结果(如胆固醇数值范围 [125,554]远大于年龄[29,77]),因此必须对数值型特征做标准化(均值为 0、标准差为 1);分类特征(如胸痛类型、心电图结果)需做独热编码(避免模型误将“胸痛类型 1/2/3”的数值大小理解为特征重要性)。
1.3 适配心脏病预测的优势与局限
- 优势:原理简单易懂,无需假设数据分布(心脏病数据集的特征无明确分布规律),可快速作为基准模型验证特征有效性;
- 局限:预测速度慢(若数据集扩大到万级样本,效率显著下降),无法直接输出类别概率(需额外处理),对高维特征易出现“维度灾难”。
2. 逻辑回归 (Logistic Regression)
2.1核心思想与原理
给数据画一条“一刀切”的概率直线。
虽然名字里有“回归”,但它其实是工业界最常用的线性分类器。它会在高维空间中寻找一个最优的超平面(直线)试图将两类数据切开。它通过线性方程计算出一个特征加权和,然后巧妙地引入 Sigmoid 激活函数,将这个结果压缩到[0,1]的区间内,转化为“患病概率”。
优点: 极其强大的可解释性,我们可以直观看到哪个生理特征(权重)对患病影响最大;预测速度极快。
缺点: 只能处理线性可分的数据,面对极其复杂的非线性数据分布时显得无力。
以心脏病预测为例,其核心步骤为:
- 线性拟合:构建特征与“患病对数几率”的线性关系:
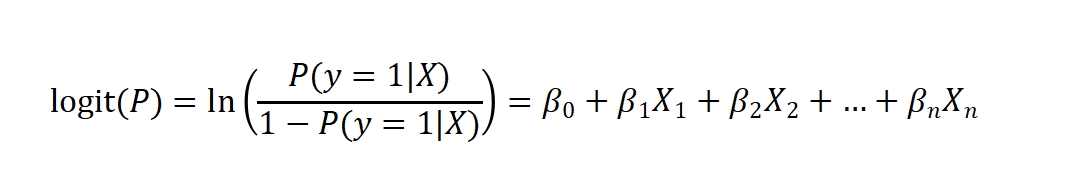
其中P(y=1|X)为样本 X被预测为“有病(y=1)”的概率,为偏置项,
为各特征的权重系数(如年龄、血压等特征的权重)。
2. 概率映射:通过 Sigmoid 函数将线性输出转换为[0,1]区间的概率:
3. 类别判定:设定阈值(默认 0.5),概率≥0.5 则预测为“有病(1)”,否则为“无病(0)”;医疗场景中可灵活调整阈值(如降低至 0.3),提升有病样本的召回率(减少漏诊)。
2.2 关键特性与可解释性(医疗场景核心优势)
- 强可解释性:权重系数
直接反映特征与患心脏病风险的相关性:
- 权重的绝对值越大,特征对结果的影响越显著。
- 高效训练:通过极大似然估计(MLE)优化权重,最小化预测概率与真实标签的偏差,收敛速度快,训练效率高;
- 数据假设:假设特征与“对数几率”呈线性关系,若非线性关系显著,需手动构造交互特征或多项式特征补充。
2.3 适配心脏病预测的优势与局限
- 优势:可解释性强(能明确告知医生哪些特征是患病的关键因素),输出概率结果(可量化患病风险),模型轻量化、训练/预测速度快,适合医疗场景的快速部署;
- 局限:对非线性特征拟合能力弱(需依赖特征工程),易受异常值影响(需预处理),无法直接处理高维稀疏特征(需特征筛选)。
二、实验设计与验证
基于上述算法原理,本文将以心脏病数据集为基础,完成数据预处理(独热编码、标准化)、模型训练与多维度评估(准确率、精确率、召回率、AUC、混淆矩阵),对比 KNN 与逻辑回归在心脏病预测任务中的性能,验证两类算法的实际应用效果。数据集及代码已上传:基于KNN和逻辑回归的心脏病预测项目:CSDN博文备份 - AtomGit | GitCode
1. 数据集基本信息
本次使用的心脏病数据集包含 14 个字段,涵盖患者的临床生理特征和最终诊断结果,具体字段说明如下:
|
字段名 |
含义 |
数据类型 |
备注 |
|
age |
年龄 |
数值型 |
患者年龄(岁) |
|
sex |
性别 |
分类型 |
1=男性,0=女性 |
|
cp |
胸痛类型 |
分类型 |
0-3(4 种不同胸痛类型) |
|
trestbps |
静息血压 |
数值型 |
静息时血压(mm Hg) |
|
chol |
血清胆固醇 |
数值型 |
血液胆固醇含量(mg/dl) |
|
fbs |
空腹血糖 |
分类型 |
1=>120mg/dl,0=≤120mg/dl |
|
restecg |
静息心电图结果 |
分类型 |
0-2(3 种心电图结果) |
|
thalach |
最大心率 |
数值型 |
运动测试最大心率 |
|
exang |
运动诱发心绞痛 |
分类型 |
1=有,0=无 |
|
oldpeak |
运动相较静息的 ST 段压低 |
数值型 |
反映心脏缺血严重程度 |
|
slope |
ST 段变化斜率 |
分类型 |
0-2(3 种变化趋势) |
|
ca |
主要血管数 |
分类型 |
0-3(血管造影检测数量) |
|
thal |
地中海贫血检测结果 |
分类型 |
1/2/3(3 种类型) |
|
target |
心脏病诊断结果 |
分类型 |
1=患病,0=无病(目标变量) |
2. 数据集加载与初步分析
import numpy as np ##导入Numpy,支持数学运算
import pandas as pd ##导入Pandas,支持数据分析
import matplotlib.pyplot as plt ##导入matplotlib中的pyplot模块,用于绘图和数据可视化
from matplotlib import rcParams ##导入rcParams用于设置matplotlib图像格式
from matplotlib.cm import rainbow ##从Matplotlib的colormap模块导入rainbow颜色映射,用于给图像添加彩虹色彩
import warnings ##导入warnings库,用于控制警告信息显示
warnings.filterwarnings('ignore') ##忽略掉所有警告
from sklearn.model_selection import train_test_split ##导入数据集划分测试集和训练集的库
from sklearn.preprocessing import StandardScaler
##导入标准化工具,对数据进行标准化处理(均值为0,标准差为1的正态分布),防止不同数据单位过大产生影响
from sklearn.neighbors import KNeighborsClassifier
###从sklearn.neighbors模块中导入K近邻分类器,用于基于距离进行分类
from sklearn.svm import SVC
###从sklearn.svm模块中导入向量机分类器,用于高维数据分类任务
from sklearn.tree import DecisionTreeClassifier
###从sklearn.tree模块中导入决策树分类器,用于构建树结构进行分类
from sklearn.ensemble import RandomForestClassifier
###从sklearn.ensemble模块中导入随机森林分类器,用于集成多棵决策树提高准确率
# 导入数据集
dataset = pd.read_csv('dataset.csv')
#查看数据集信息
dataset.info()
#查看数据集基础描述
dataset.describe()导入相应的库以及数据集,并查看数据集信息和描述。
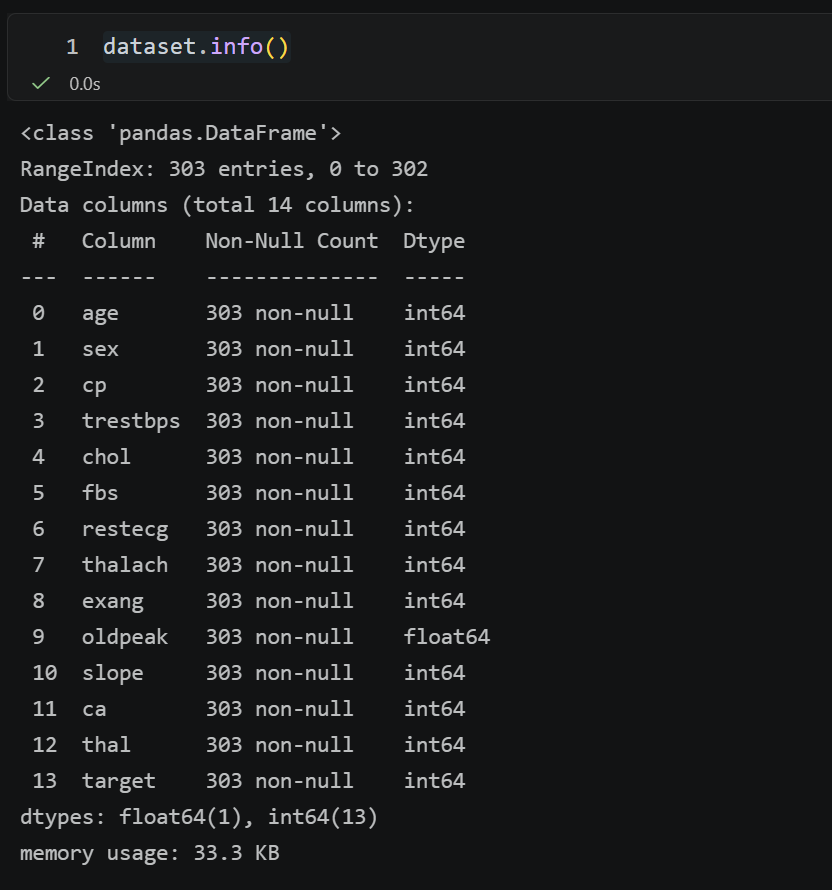
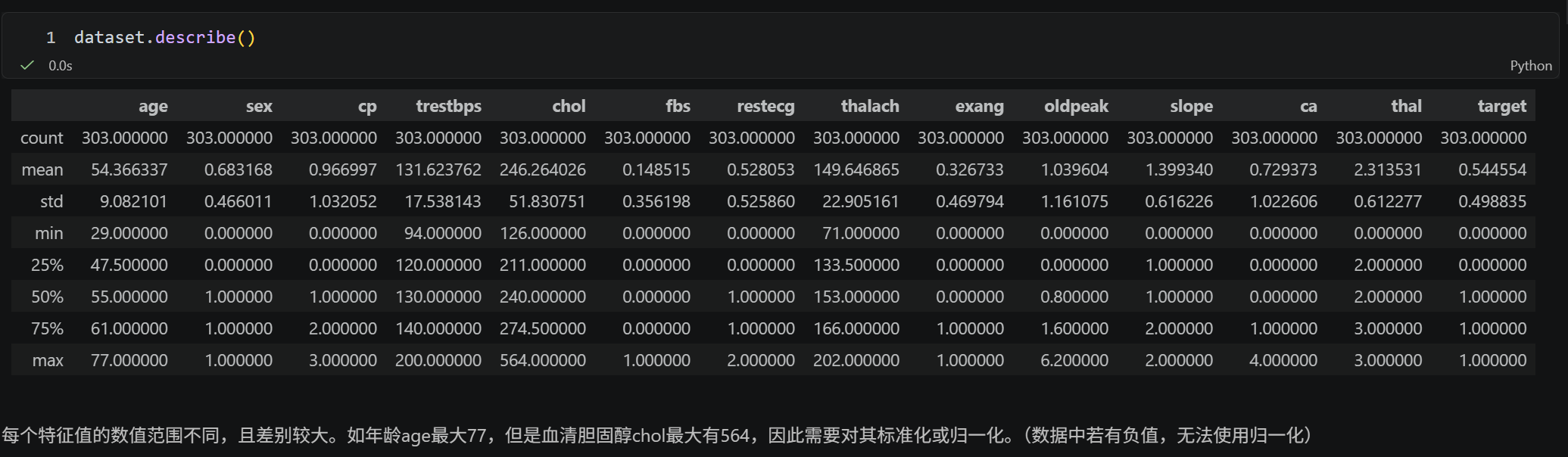
核心发现:
- 数据集无缺失值,无需填充;
- 数值型特征量纲差异大(如 chol 最大值 564,age 最大值 77),需标准化;
- 分类型特征为数字编码(如 sex=1/0),无数值意义,需独热编码。
KNN算法由于属于惰性学习,没有显性学习,因此对数据尤为敏感,需要对数据进行高质量处理。因此接下来先对数据进行分析。
三、数据预处理:从可视化到特征工程
数据预处理是提升模型效果的核心步骤,本次流程包含相关性分析、分布分析、独热编码、标准化四部分。
1. 相关性分析(热力图)
通过皮尔逊相关系数分析特征与目标变量的关联程度,皮尔逊相关系数公式:
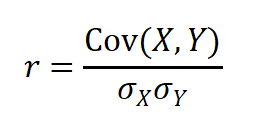
其中,Cov(X,Y)为协方差,为 X/Y 的标准差,结果范围[-1,1],绝对值越大相关性越强。
计算皮尔逊相关系数pearson correlation,公式为(协方差)/(X的标准差*Y的标准差),本质上是对协方差求标准化。
协方差是反映数据相关性的,Cov>0,正相关;Cov<0,负相关。但是受单位和量纲影响太大,因此对其做标准化后可以比较数据间相关性。
皮尔逊相关系数是对协方差做标准化,使得结果不受单位和量纲影响,均处于[-1,1]之间。当|r|=1,完全相关;|r|=0,完全无关;0<|r|<1,线性相关。
import seaborn as sns ##导入seaborn库,基于matplotlib的高级可视化工具,可以绘制美观的统计图表
import matplotlib.pyplot as plt ##导入pyplot模块,用于绘制图表
plt.figure(figsize=(20,14)) #设置画布,宽20英寸,高14英寸
corr = dataset.corr()
##计算皮尔逊相关系数pearson correlation,公式为(协方差)/(X的标准差*Y的标准差),本质上是对协方差求标准化。
##协方差:反映数据相关性,Cov>0,正相关;Cov<0,负相关。但是受单位和量纲影响太大,因此对其做标准化后可以比较数据间相关性
##皮尔逊相关系数对协方差做标准化,使得结果不受单位和量纲影响,均处于[-1,1]之间。当|r|=1,完全相关;|r|=0,完全无关;0<|r|<1,线性相关
"""
viridis":渐变绿色调,视觉舒适。
"magma":暗色调渐变,风格现代。
"plasma":鲜艳明亮的渐变色。
"coolwarm":蓝红对比色,适合正负相关。
"cividis":色盲友好配色。
"rocket" 或 "mako":seaborn自带的高级配色。
"""
sns.heatmap(
corr, ##传入皮尔逊相关系数作为热力图数据来源
annot=True, ##在每个格子上显示相关系数数值
fmt='.2f', ##格式化数据,保留2位小数
cmap='viridis', ##配色方案
)
plt.show()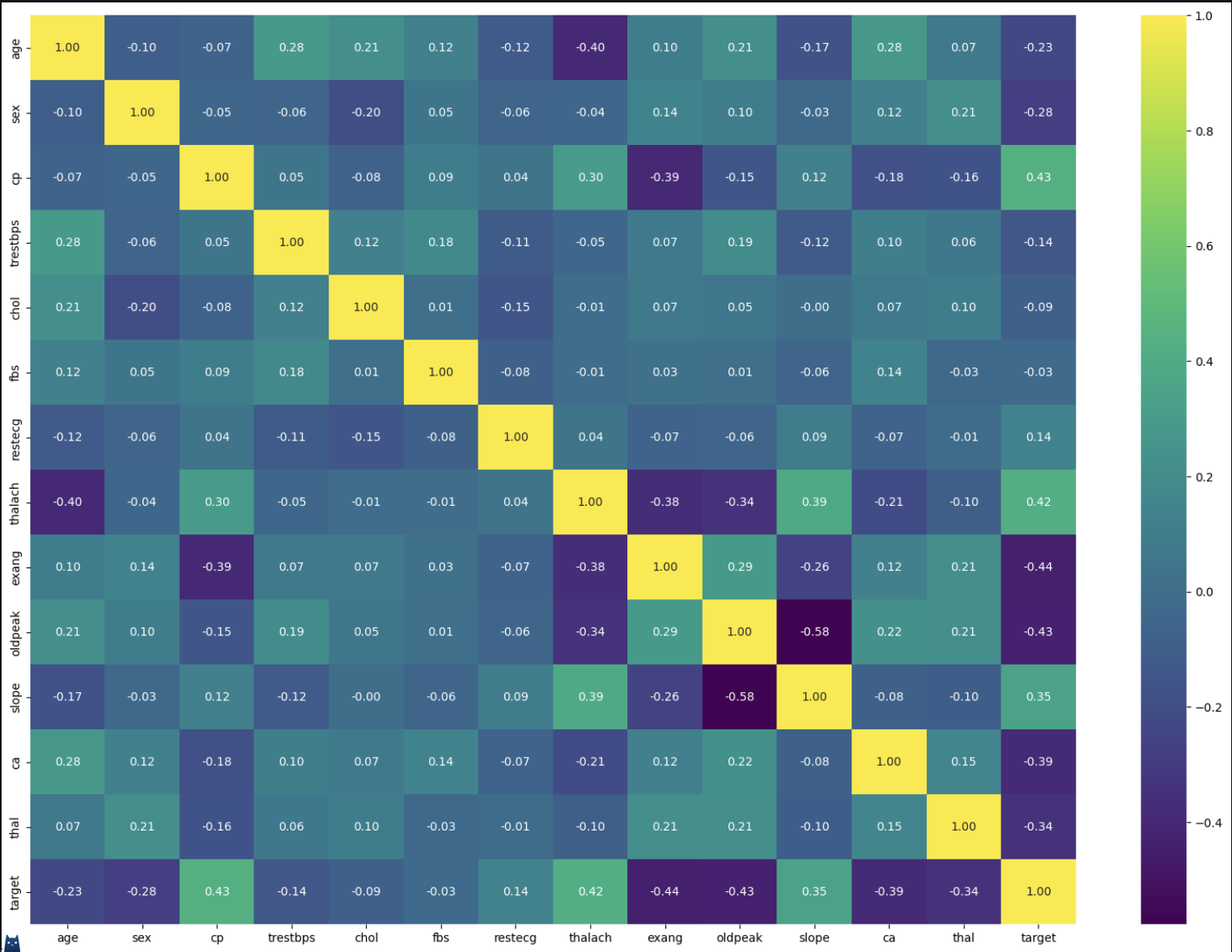
关键结论:
thalach(最大心率)、cp(胸痛类型)与 target 正相关性强;oldpeak(ST 段压低)、exang(运动心绞痛)与 target 负相关性强。
2. 数据分布分析
(1)特征分布直方图
import matplotlib.pyplot as plt
#plt.figure(figsize=(15,10)) ##设置画布大小,下面一句同时设置了画布大小,这句可以删除
dataset.hist(figsize=(15,10)) ##调用.hist()函数,给数据集中每一列自动绘制一个直方图,同时规定了画布大小
plt.tight_layout() ##自动调整子图间距,防止重叠
plt.show()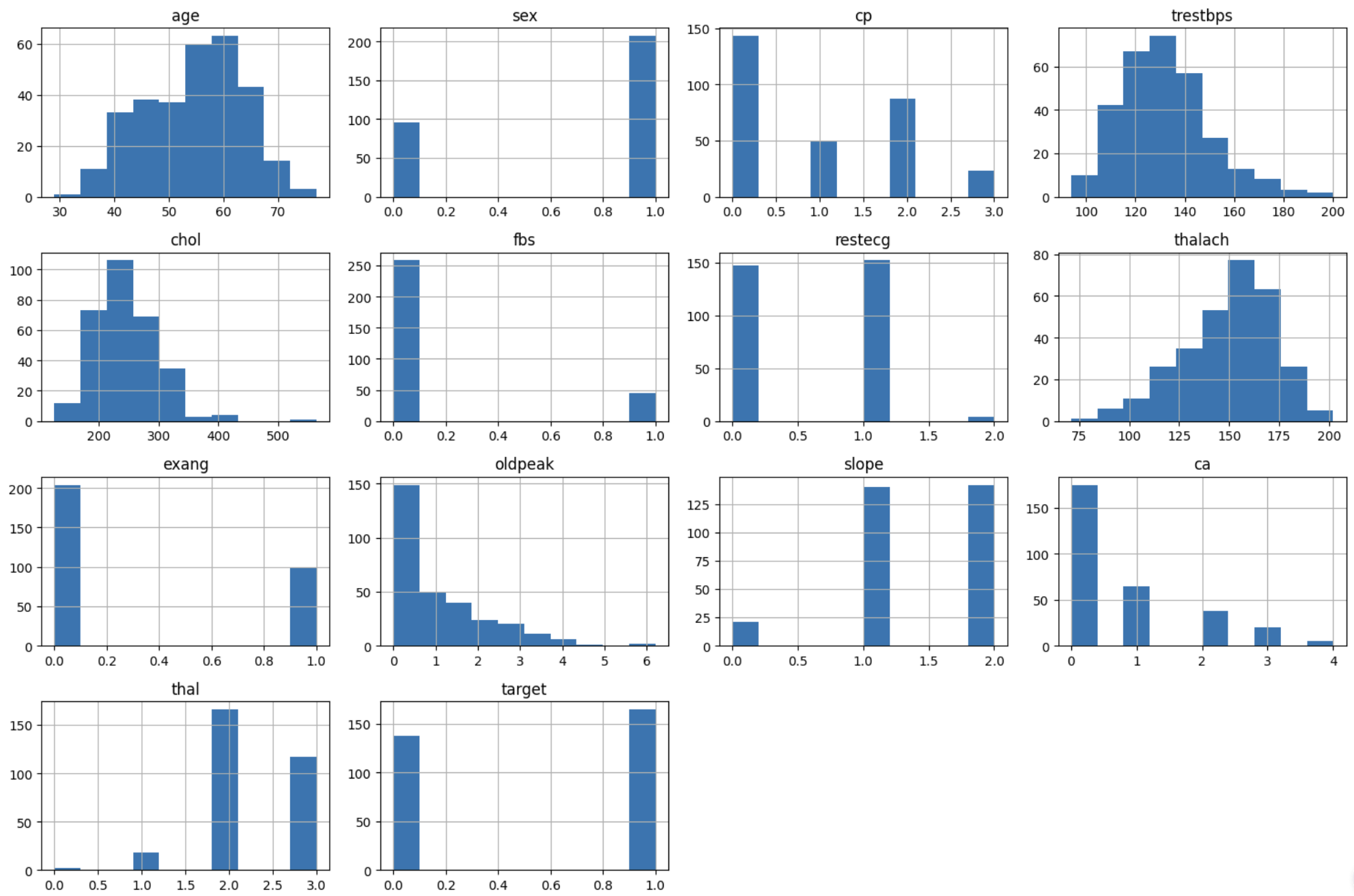
可直观看到各数值特征的分布形态(如 age 呈正态分布,chol 右偏分布)。
(2)目标变量均衡性分析
##设置画布大小,rcParams为matplotlib全局参数配置工具,统一设置画布大小
rcParams['figure.figsize']=8 ,6
plt.bar( ##绘制柱状图bar()
dataset['target'].unique(), ##对target列数据去重,并将唯一值作为x轴(这里就是0和1)
dataset['target'].value_counts(), ##统计target列数据各有多少个0和1作为y轴
color = ['red','green'] ##柱子颜色,类别0为red,类别1为green
)
plt.xticks([0,1]) ##强行设置x轴数值仅为0和1
plt.xlabel('Target Classes') ##x轴标签名
plt.ylabel('Count') ##y轴标签名
plt.title('Count of each Target Class') ##图表标题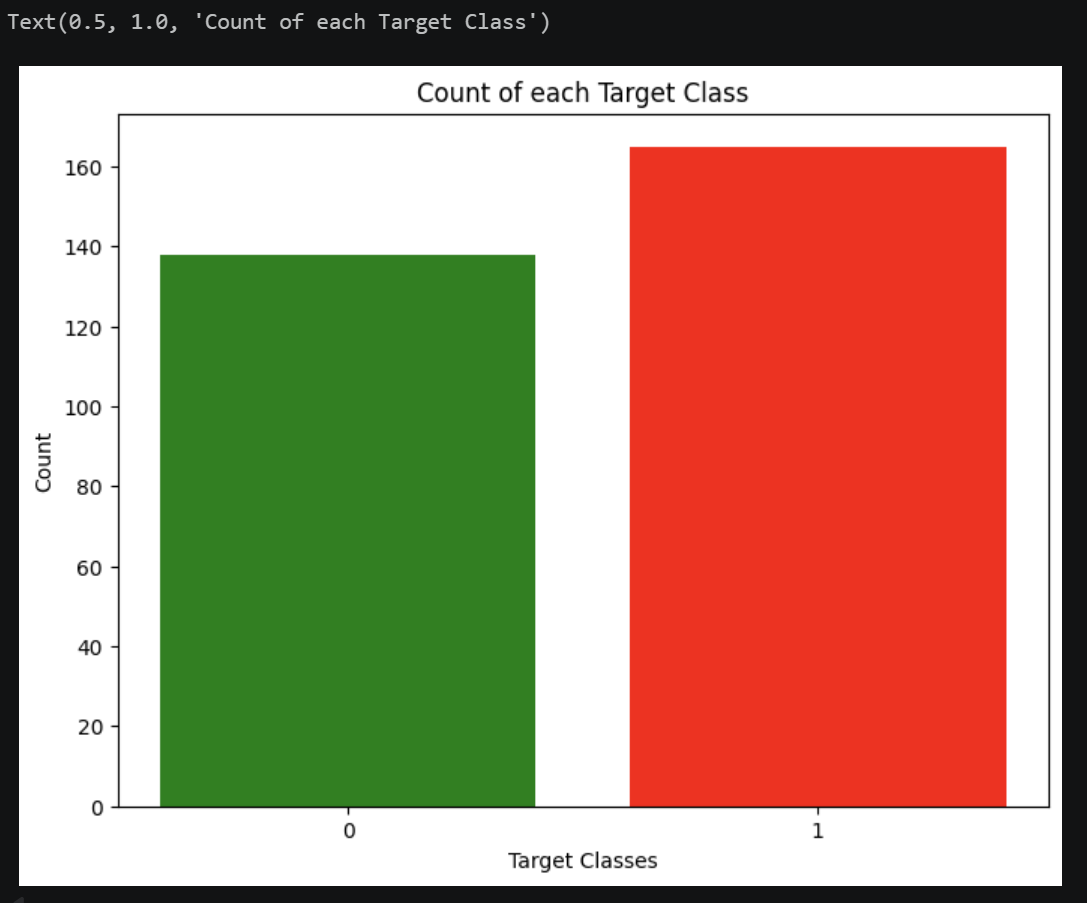
结果显示:患病(1)与无病(0)样本数量接近均衡,无需做过采样/欠采样处理。
3. 独热编码(分类特征处理)
刚刚统计出来的分类特征(如 sex、cp)的数字仅代表类别,无大小意义,为防止模型认为其1,2,3有大小之分,需通过独热编码将其转换为二进制特征(001,010,100):
dataset = pd.get_dummies(dataset,columns=['sex','cp','fbs','restecg','exang','slope','ca','thal'],dtype=int)
##对dataset数据进行独特编码(get.dummies()),columns=[]为指定需要编码的列
dataset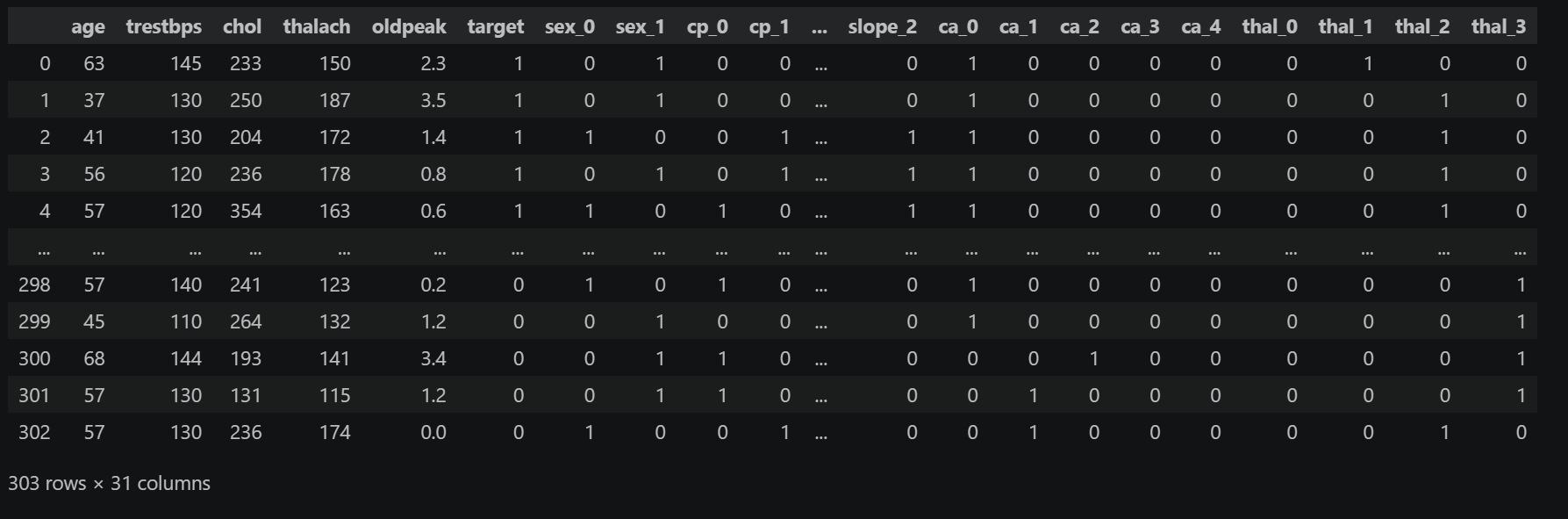
编码后,原 1 个分类列会扩展为多个二进制列(如 sex 扩展为 sex_0、sex_1),保证每个类别独立成特征。
4. 标准化(数值特征处理)
数值特征量纲差异大(如 chol 最大值 564,age 最大值 77),需标准化为均值 0、标准差 1 的分布,公式:
其中,为均值,
为标准差。
注:后面代码运行时,.fit()函数就是在计算
和
;.transform()函数在用.fit()计算完的值代入计算
。知道这个关系,会对后面理解训练集和测试集使用不用的处理有帮助。
!!!关键注意点:需先划分训练集/测试集,再对训练集拟合标准化器!
仅用训练集的均值/标准差转换测试集,防止数据泄露:
这里需要格外注意,对原始数据进行标准化、归一化等操作前,一定得先进行数据集划分,因为模型在计算均值、标准差等数据时是计算所有数据的,这样在之后预测时
数据集划分后,数据处理操作只能对训练集执行,那训练集的结果(
但刚刚提到的独热编码是可以放在划分数据集之前的,因为独热编码没有进行.fit()运算操作,只是单纯把数据由十进制变成二进制。同时,提前对所有数据进行独热编码也可以保证之后划分完数据集,训练集和测试集特征个数一致(比如胸痛分1,2,3,4四种类型,若训练集中四种情况都包含,但测试集没有类型4,则预测时就会报错。提前独热编码,则缺失的类型会被赋值全0,保证个数一致)
#1.划分训练集和测试集
x = dataset.drop(['target'],axis=1) ##将target列删除,将剩余列作为特征数据x
y = dataset['target'] ##将target列作为标签数据y
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.33,random_state=0)
x_train = x_train.copy() ##为了避免后续标准化时对原数据集造成影响,先对训练集和测试集进行复制
x_test = x_test.copy()
#2.数据再处理(标准化)
#再对数值型特征进行标准化处理,这一步要放在数据集划分之后,防止数据泄露(即测试集信息泄露到训练集中)
sc = StandardScaler() ##实例化StandardScaler对象
columns_to_scale = ['age','trestbps','chol','thalach','oldpeak']
##因为标准化后数据类型从int变为float,所以需要重新赋值
x_train[columns_to_scale] = x_train[columns_to_scale].astype(float)
x_test[columns_to_scale] = x_test[columns_to_scale].astype(float)
x_train.loc[:, columns_to_scale] = sc.fit_transform(x_train[columns_to_scale])
##测试集数据只能用训练集数据进行转换,不能重新fit,否则会泄露测试集信息
x_test.loc[:, columns_to_scale] = sc.transform(x_test[columns_to_scale]) 这里数据经过标准化后从原本的int类型变成float型,因此需要做一次重新赋值以免报错。同时为防止数据泄露,这里只能对训练集进行.fit()运算。对于测试集只能使用训练集.fit()运算后的结果直接.transform()转换。这就是刚刚说的.fit()和.transform()运算的底层逻辑区别。
数据处理完后,分别使用KNN和逻辑回归进行运算。
四、K 近邻(KNN)模型:
1. KNN 核心原理
KNN(K-Nearest Neighbors)是惰性学习算法(无训练过程),核心逻辑:
1. 距离度量:计算待预测样本与训练集中所有样本的距离(默认欧式距离);
2. K 值选择:选取距离最近的 K 个样本;
3. 投票机制:K 个样本中占比最高的类别即为预测结果。
欧式距离公式(两个样本、
):
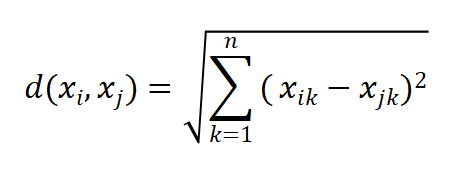
2. K 值调优:寻找最优邻居数
K 值是 KNN 的核心超参数:K 过小易过拟合,K 过大易欠拟合。本次遍历 K=1~20,选取准确率最高的 K 值:
#1.创建KNN模型,寻找最佳K值
knn_scores = [] ###创建一个空列表,用于存放不同K值所对应的准确率
for k in range(1,21): ###遍历k值从1到20
knn_classifier = KNeighborsClassifier(n_neighbors=k) ##创建k近邻分类器,设置邻居数为k
knn_classifier.fit(x_train,y_train) ##用训练集训练数据
knn_scores.append(knn_classifier.score(x_test,y_test)) ##计算测试集中的准确率,并加在列表中
print("标准化数据下,各K值的准确率:", knn_scores)
best_k = knn_scores.index(max(knn_scores)) + 1
print(f"当前状态下,准确率最高的 K 值应该是: {best_k},最高准确率为: {max(knn_scores):.2f}")
knn = KNeighborsClassifier(n_neighbors=best_k) ##创建KNN模型,n_neighbors参数表示K值,这里设为遍历后最佳K值
##绘图
plt.plot([k for k in range(1,21)],knn_scores,color='red') #绘制k值为1到20对应的准确率,线条颜色为red
for i in range(1,21):
plt.text(i,knn_scores[i-1],(i,knn_scores[i-1]))
##在对应的点上添加文字,plt.text(x坐标,y坐标,显示的文本),knn_scores[]是一个列表,从0开始记,因此i-1是正确的索引位置
plt.xticks([i for i in range(1,21)]) ##设置x轴为1到20
plt.xlabel('Number of Neighbors(k)') ##设置x轴名称
plt.ylabel('scores') ##设置y轴名称
plt.title('K Neighbors Classifier scores for different K values')
plt.show()
#2.训练模型
knn.fit(x_train,y_train) ##使用训练数据训练KNN模型,fit()方法会根据训练数据学习模型参数
#3.预测测试集
y_pred = knn.predict(x_test) ##使用测试数据进行预测,predict()方法会根据训练好的模型参数对测试数据进行预测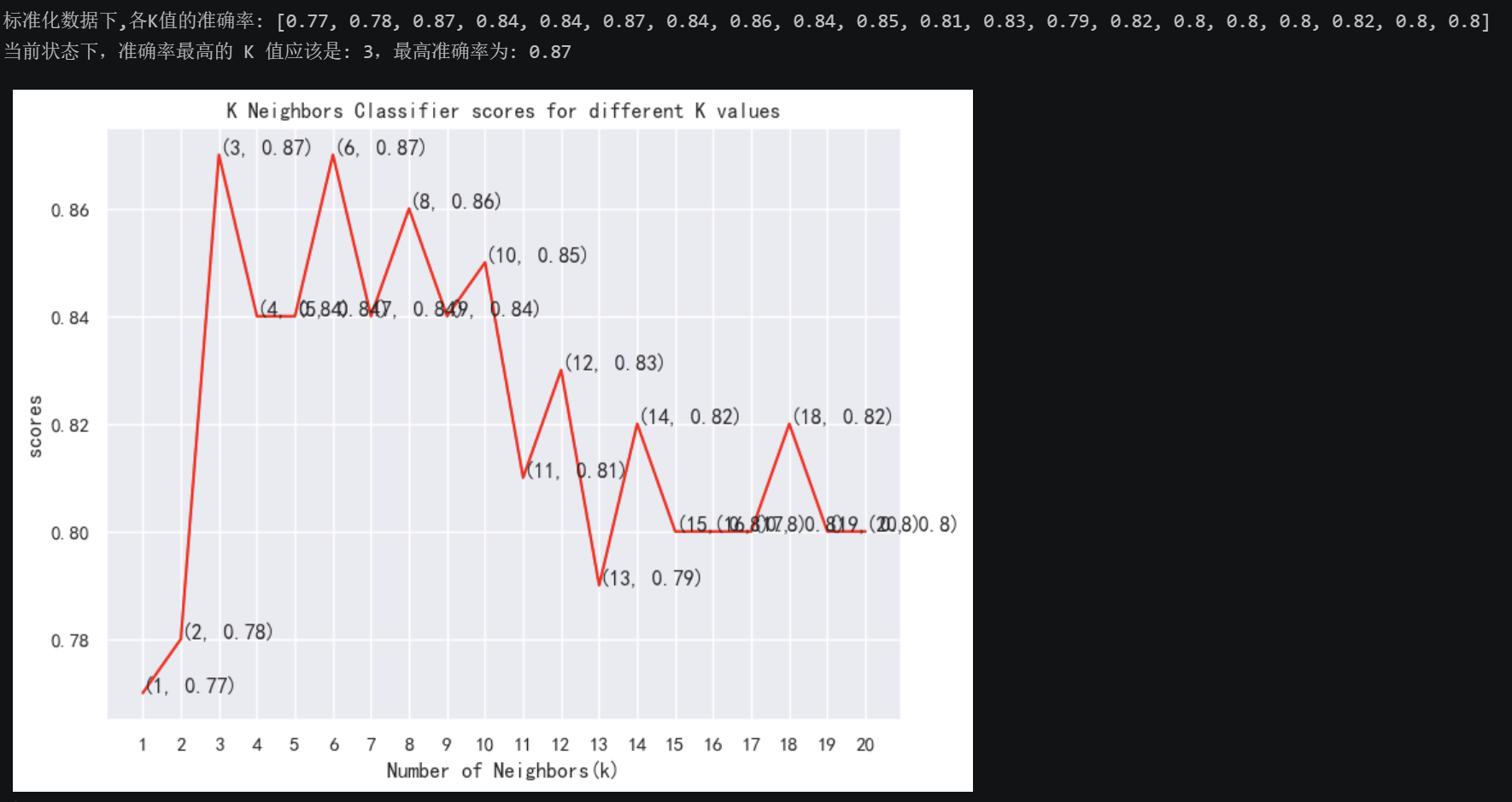
通过遍历1~20的K值,可以看出在K=3和K=6时,准确率最高,为0.87。因此选取最小K=3
3. KNN 模型评估(医疗场景重点)
模型评估需结合医疗场景需求(优先减少漏诊),核心指标:准确率、混淆矩阵、精确率/召回率/F1、ROC-AUC。
####模型评估
from sklearn.metrics import (
confusion_matrix, accuracy_score,
classification_report, roc_auc_score,roc_curve, auc
)
# 1) 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("=== 混淆矩阵 ===")
print(cm)
# 2) 分类准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"\n分类准确率 (Accuracy): {accuracy:.2f}")
# 3) 分类报告(含精确率、召回率、F1,医疗场景必备)
print("\n=== 分类报告 ===")
print(classification_report(y_test, y_pred, target_names=['无病(0)', '有病(1)']))
# 4) AUC(二分类模型核心评估指标)
y_pred_proba = knn.predict_proba(x_test)[:, 1] # 获取预测为"有病(1)"的概率
# 计算 ROC 曲线的 FPR, TPR 和 阈值
# y_test 是真实标签,y_pred_proba 是预测概率
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
# 重新计算一下 AUC 面积 (用于图例展示)
roc_auc = auc(fpr, tpr)
# 开始绘图
plt.figure(figsize=(8, 6))
# 绘制模型的 ROC 曲线
# color 设为深橙色,lw 设为线宽2,label 里写上 AUC 分数
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC 曲线 (AUC = {roc_auc:.2f})')
# 绘制对角基准线 (纯瞎猜的线)
# navy色,线宽2,dashed代表虚线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
# 美化图表
plt.xlim([0.0, 1.0]) # 设置X轴范围
plt.ylim([0.0, 1.05]) # 设置Y轴范围(稍微宽一点点,防止曲线压线)
plt.xlabel('假阳性率 (False Positive Rate / 误报率)') # X轴标签
plt.ylabel('真阳性率 (True Positive Rate / 召回率)') # Y轴标签
plt.title('KNN模型 ROC 曲线 (心脏病分类)') # 图表标题
plt.legend(loc="lower right") # 图例放在右下角
plt.grid(True) # 开启网格线,方便查看数值
plt.show()
# 5) 规范绘制混淆矩阵热力图
plt.figure(figsize=(6, 5))
sns.heatmap(
cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['无病(0)', '有病(1)'],
yticklabels=['无病(0)', '有病(1)']
)
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('KNN模型混淆矩阵(心脏病分类)')
plt.show()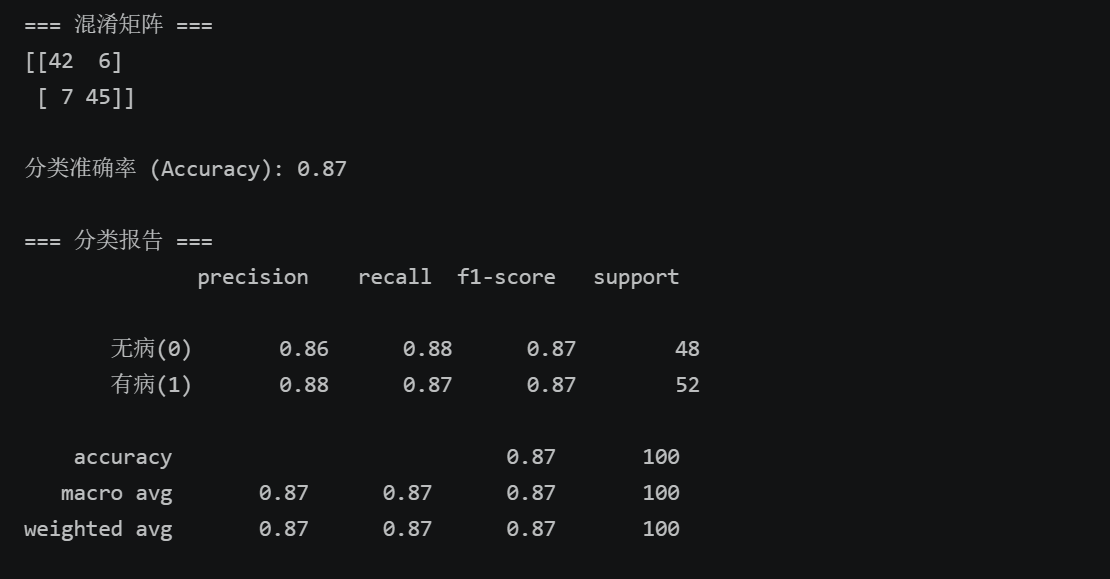
注释:
对于分类问题,我们不能只关注一个“准确率(Accuracy)”就结束,尤其是医疗领域。需要针对不同场景因地制宜,比如对于医疗场景来说,“有病被预测为没病”(召回率)是最需要关注的点,宁愿牺牲“没病被预测为有病”(精确率)也需要优先满足召回率。
因此我们需要加入混淆矩阵、分类报告(包含精确率、召回率、F1分数)以及一个高阶指标AUC。
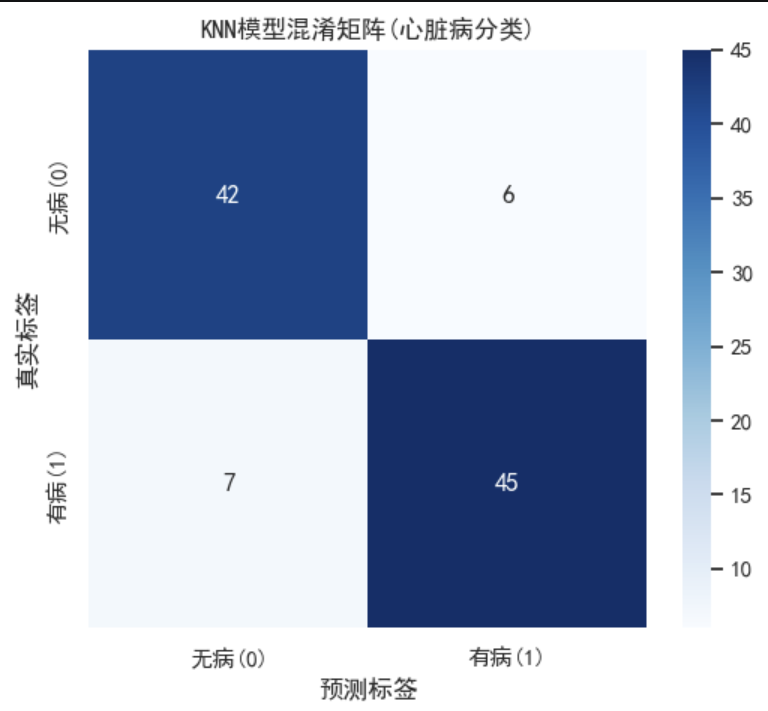
(1)混淆矩阵:(Confusion Matrix)
这是所有指标的基石,本质上是一个2X2的矩阵,将模型的预测情况和真实情况进行交叉对比,分成四类:
- TP(True Positive):真阳性,实际有病,预测有病;
- TN(True Negative):真阴性,实际无病,预测无病;
- FP(False Positive):假阳性,实际无病,预测有病;
- FN(False Negative):假阴性,实际有病,预测无病。
P和N代表了预测的结果,TF是对预测结果的判别。对于医疗场景来说,FN就是最危险的情况,要尽可能的少。
(2)四大核心指标 (由混淆矩阵衍生)
通过 classification_report,打印出了以下三个关键指标加上整体的准确率:
-
准确率 (Accuracy):
-
公式: Accuracy = (TP + TN)/(TP + TN + FP + FN)
-
解释: 所有预测对的样本(真阳 + 真阴)占总样本的比例。
-
局限性: 如果你的数据集极度不平衡(比如 99 个无病,1 个有病),模型只要全部闭眼猜“无病”,准确率就能高达 99%,但它连唯一的那个病人都没找出来,这个模型其实是废的。
-
-
精确率 (Precision / 查准率):
-
公式: Precision = TP/(TP + FP)
-
解释: 只要模型说“这人有病”,他真正有病的概率有多大?
-
场景: 如果精确率低,说明模型喜欢“瞎报警”(FP 高)。
-
-
召回率 (Recall / 查全率 / 灵敏度):
-
公式: Recall = TP/(TP + FN)
-
解释: 在所有真正有病的人里面,模型成功找出了多少个?
-
医疗场景的绝对核心: 在心脏病预测中,召回率比精确率重要得多! 我们宁愿错杀(False Positive,让人多做个胸透确诊),也绝对不能放过(False Negative,让有病的人以为自己健康而回家猝死)
-
-
F1-Score (F1分数):
-
公式: F1 = 2 *(Precision * Recall)/(Precision + Recall)
-
解释: 精确率和召回率往往是鱼与熊掌不可兼得(抓得越严,漏报越少,但误报就会增加)。F1 分数是它俩的调和平均数,用来综合评估模型的能力,是一个非常全面的“和事佬”指标。
-
(3)高阶指标:AUC (Area Under Curve)
-
定义: AUC 是 ROC 曲线下的面积,它的取值范围一般在 0.5 到 1 之间。0.5 代表模型跟抛硬币瞎猜一样,1 代表完美模型。
-
目的: 前面的指标(比如准确率)都是基于一个固定阈值(默认概率 > 50% 就判为有病)算出来的。而 AUC 衡量的是:无论我把阈值调得多高或多低,模型把真正的病人排在健康人前面的综合能力有多强。
-
只要 AUC 大于 0.8,说明模型已经具备了相当不错的分类区分能力;大于 0.9 就是极其优秀的模型了。
-
同时,这里引出ROC曲线(Receiver Operating Characteristic Curve),在二分类模型中,逻辑回归模型最终输出的其实不是直接的1或者0,而是1和0的概率值,再通过概率是否超过阈值进行1和0的判定。这样阈值的严格和宽松程度直接影响了结果,因此ROC曲线画的就是模型“从严格到宽松”的所有阈值下,表现出的动态变化轨迹,真正反映了模型的能力。
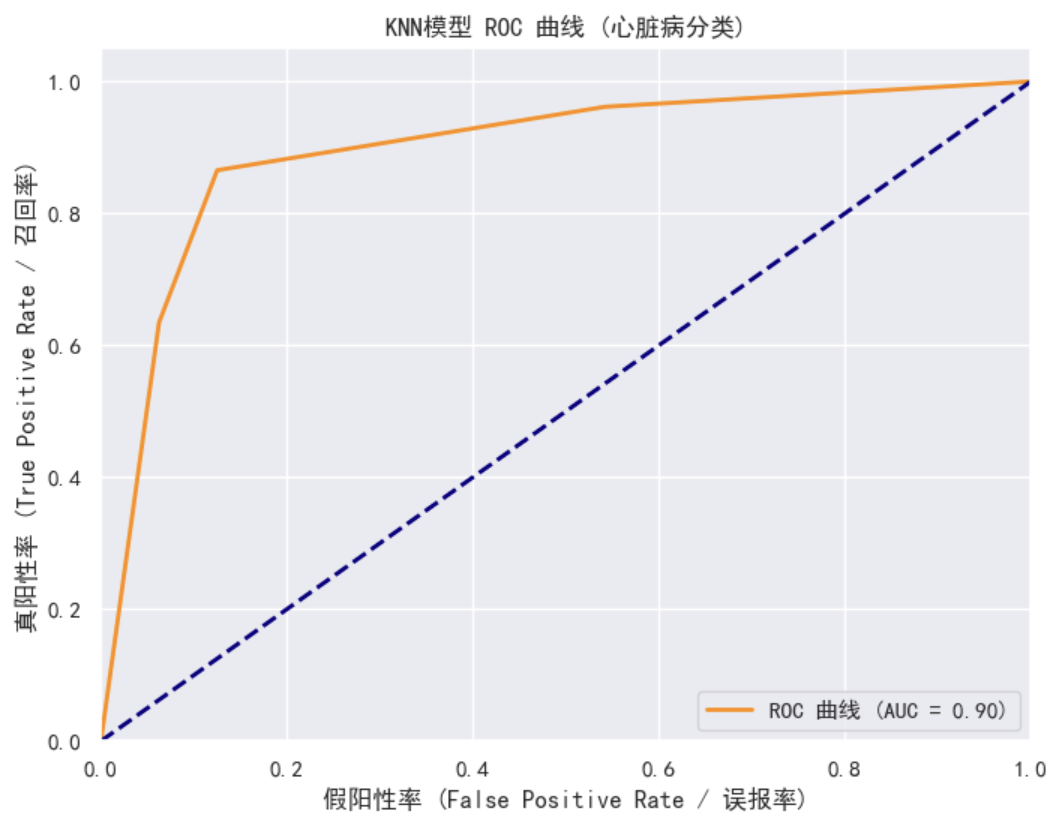
注:看ROC曲线,主要找其“拐点”,曲线拐点越靠近左上角越好。即模型能在最小的误判下找到最多的正确情况。
同时,ROC曲线下方面积即代表AUC值,完全理想的模型AUC=1(即没有一个误判情况下找到所有正解),纯瞎猜(抛硬币)AUC=0.5
4. KNN 结果解读
- 最优 K 值为3时,测试集准确率达 87%;
- 召回率(真阳性率)约 87%,说明模型能有效识别出患病患者(漏诊率低),符合医疗场景需求;
- AUC 值约 0.90,说明模型区分患病/无病样本的能力优秀。
五、逻辑回归模型:
1. 逻辑回归核心原理
逻辑回归是针对二分类问题的线性模型,核心是将线性回归的连续输出通过Sigmoid 函数映射到 [0,1] 区间,代表样本属于正类(患病)的概率。
(1)Sigmoid 函数
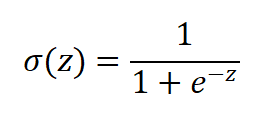
其中,Z=W0+W1X1+W2X2+....+WnXn(线性回归输出,W0为偏置,Wi为特征权重)。
(2)核心逻辑
- 若
,预测为正类(1,患病);
- 若
,预测为负类(0,无病);
- 通过最小化对数似然损失函数求解最优权重Wi。
5.2 逻辑回归模型训练与权重解读
#导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
#导入模型评估指标
from sklearn.metrics import precision_score, recall_score, f1_score,roc_auc_score,classification_report
#初始化逻辑回归模型,设置随机种子和最大迭代次数
log_reg = LogisticRegression(random_state=0,max_iter=1000)
#在训练集上训练
log_reg.fit(x_train,y_train)
#在测试集上测试
log_reg_score = log_reg.score(x_test,y_test)
#打印逻辑回归准确率
print(f'逻辑回归的准确率为:{log_reg_score*100:.2f}%')
#打印出权重
feature_names = x.columns
df = pd.DataFrame({
"特征":feature_names,
"权重":log_reg.coef_[0]
})
print('\n','各个特征权重表:')
print(df.to_string(
index=False, ##隐藏索引
col_space={'特征':10,'权重':12}, #设置每列列宽
formatters={
'特征':'{:<10}'.format, ##特征列:左对齐(<),占10个字符宽
'权重':'{:>12.6f}'.format ##权重列:右对齐(>),占12个字符宽,小数点后6位
},
justify='center' ##设置整表内容居中对齐
))
#打印出偏置
print("偏置:",log_reg.intercept_)
#模型评估
y_pred = log_reg.predict(x_test) #预测测试集的标签,y_pred输出一堆0,1结果
y_pred_proba = log_reg.predict_proba(x_test)[:,1] #预测测试集的概率,通过predict_proba()调用sigmoid函数,将线性输出转换为概率值
#使用sigmoid函数将线性输出转换为概率值,切片[:,1]表示只取预测为"有病(1)"的概率
#计算并打印精确率、召回率、F1分数和AUC分数
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
auc = roc_auc_score(y_test, y_pred_proba)
print('\n','模型评估:')
print(f'精确率:{precision:.2f}')
print(f'召回率:{recall:.2f}')
print(f'F1分数:{f1:.2f}')
print(f'AUC分数:{auc:.2f}')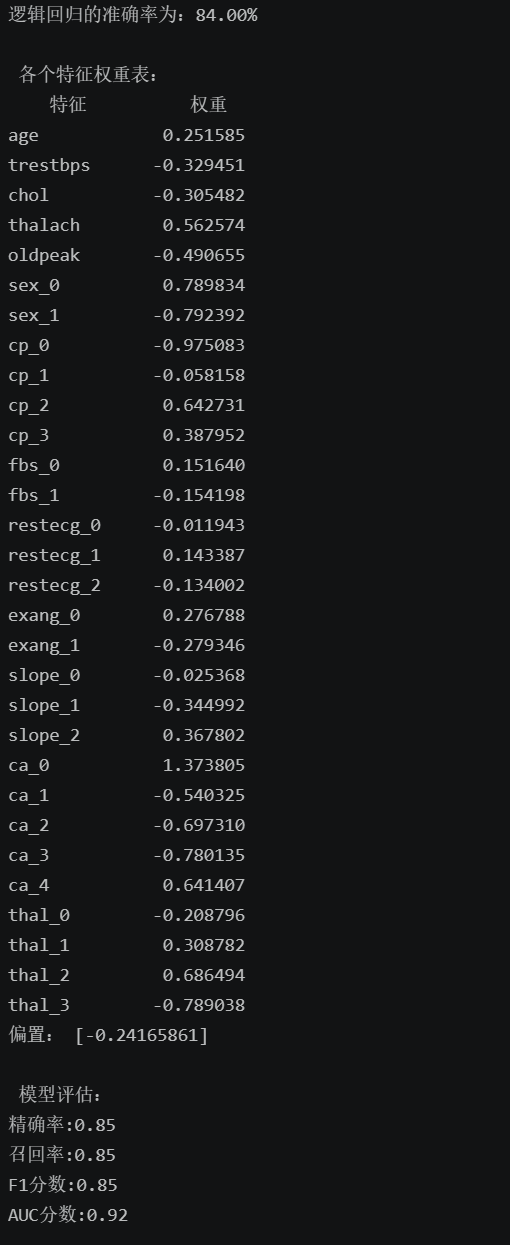
5.3 特征权重解读(医疗视角)
- 权重为正:该特征值越大,患病概率越高(如 thalach 权重为正,说明最大心率越高,患病概率越高);
- 权重为负:该特征值越大,患病概率越低(如 oldpeak 权重为负,说明 ST 段压低越严重,患病概率越高);
- 权重绝对值越大:特征对患病结果的影响越强(如 cp_2(胸痛类型 2)权重最大,说明该类型胸痛与心脏病关联最强)。
5.4 阈值调整(医疗场景优化)
默认阈值 0.5 适合通用场景,但医疗中需优先降低漏诊率(提升召回率),可调整阈值至 0.3:
#调整阈值
print("\n=== 默认阈值 (0.5) 的评估结果 ===")
print(classification_report(y_test, y_pred, target_names=['无病(0)', '有病(1)']))
# --- 调整阈值为 0.3 ---
custom_threshold = 0.3
y_pred_custom = (y_pred_proba >= custom_threshold).astype(int)
print(f"\n=== 自定义阈值 ({custom_threshold}) 的评估结果 ===")
print(classification_report(y_test, y_pred_custom, target_names=['无病(0)', '有病(1)']))
# 对比一下混淆矩阵
print("\n[默认 0.5 混淆矩阵]:")
print(confusion_matrix(y_test, y_pred))
print(f"\n[调整为 {custom_threshold} 混淆矩阵]:")
print(confusion_matrix(y_test, y_pred_custom))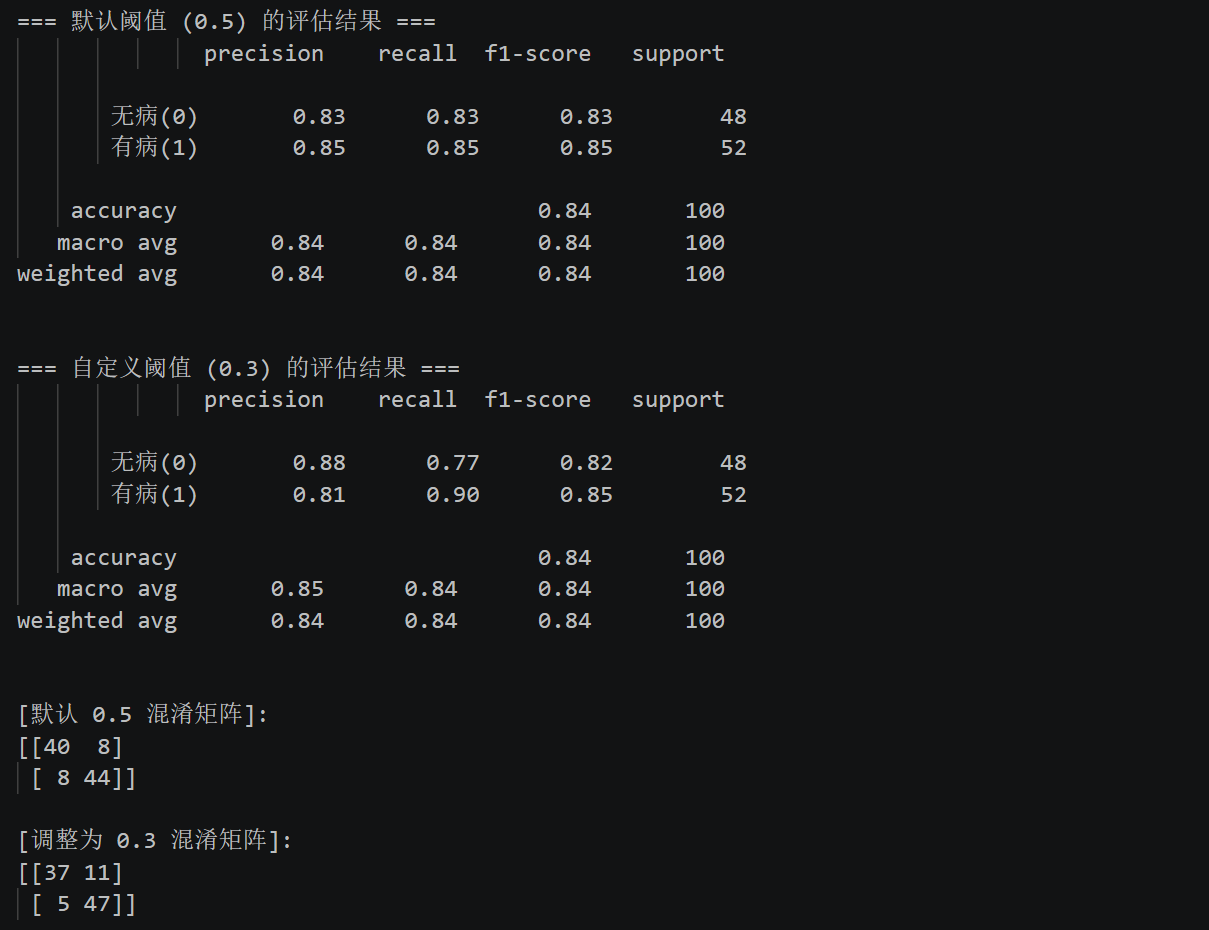
5.5 逻辑回归结果解读
- 基础准确率约 84%,略低于 KNN,但可解释性远优于 KNN;
- 阈值调整为 0.3 后,召回率提升至 90%(漏诊率仅 10%),虽精确率略有下降,但符合医疗场景“宁可误判,不可漏诊”的核心需求;
- AUC 值约 0.92,比KNN略高,说明模型区分能力优秀。
六、深度 Q&A:
在实操过程中,我不断反思算法的底层逻辑,整理出以下几个核心洞见:
Q1:为什么逻辑回归听起来更“高级”,但在这个项目里准确率却跑不过基础的 KNN?
这完美印证了“没有免费的午餐”定理。逻辑回归是线性分类器,只能切直线;而 KNN 是非线性分类器。这组心脏病数据的病理特征之间极可能存在复杂的非线性交互作用(比如“单独年龄大没事,但年龄大且血压高就极其危险”)。KNN 凭借灵活的距离判定吃到了这份红利,而逻辑回归受限于线性本质,无法捕捉这些弯弯绕绕。
Q2:逻辑回归、感知机与神经网络到底是什么血脉关系?
它们可以说是同宗同源的进化史:
- 感知机:第一代,用“阶跃函数”一刀切,输出绝对的 0 和 1,数学上不可导,难优化。
- 逻辑回归:引入 Sigmoid 激活函数,输出平滑且可导的概率。从数学结构上看,它等价于一个“没有隐藏层、只有一个输出神经元的微型神经网络”。
- 深度神经网络:就是由成百上千个“逻辑回归(神经元)”堆叠、折叠而成。量变引起质变,从而打破了线性限制,获得了解决非线性问题的能力。
Q3:为什么逻辑回归敢用高级的“牛顿法”求权重,而神经网络只能老老实实“梯度下降”?
- 逻辑回归参数极少,且它的损失函数(对数损失)是一个完美的凸函数(像一个平滑的大碗,只有一个绝对坑底)。计算二阶导数(海森矩阵)成本极低,所以算法可以直接一步“跨”到谷底。
- 而神经网络动辄几千万参数,不仅海森矩阵大到无法存入内存,其损失空间更像连绵的群山(非凸优化),用牛顿法极易冲进错误的坑里,所以只能用一阶的梯度下降慢慢试探。
既然线性模型在这个数据集上的潜力已经被榨干,下一篇实战,将介绍更高级的SVM,贝叶斯以及随机森林。
希望这篇硬核记录对大家有所启发,欢迎在评论区一起交流探讨!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)