R3A: Reliable RTL Repair Framework with Multi-Agent Fault Localization and Stochastic Tree-of-Though
⑤ R3A: Reliable RTL Repair Framework with Multi-Agent Fault Localization and Stochastic Tree-of-Thoughts Patch Generation
可译为:
《R3A:一种可靠的 RTL 修复框架,结合多智能体故障定位与随机思维树补丁生成》
更详细、学术一点的翻译:
《R3A:一种可靠的 RTL 修复框架,采用多智能体故障定位以及基于随机 Tree-of-Thoughts 的补丁生成方法》
词语拆解:
- Reliable RTL Repair Framework
可靠的 RTL 修复框架 - Multi-Agent Fault Localization
多智能体故障定位
意思是由多个 agent 协同分析,找出 RTL 代码中最可能出错的位置。 - Stochastic Tree-of-Thoughts
随机化思维树
Tree-of-Thoughts 是一种让模型以树状分支方式探索多种推理路径的方法;
stochastic 表示其中带有随机采样或随机探索机制。 - Patch Generation
补丁生成 / 修复补丁生成
整体理解:
这篇标题表达的是一个更完整、更先进的修复框架:
- 先用多智能体来做故障定位;
- 再用随机化的思维树推理生成多个候选补丁;
最终实现更可靠的 RTL 修复。
一、这篇论文到底在研究什么
这篇论文研究的是:能不能更可靠地用大语言模型自动修复 RTL(寄存器传输级)硬件代码里的 bug。作者认为,传统 RTL 自动修复方法虽然严谨,但修复能力受限;而直接用 LLM 虽然灵活,但结果不稳定。所以他们想解决一个核心矛盾:
传统方法太“死”,LLM 太“飘”,有没有办法让 LLM 既灵活又可靠?
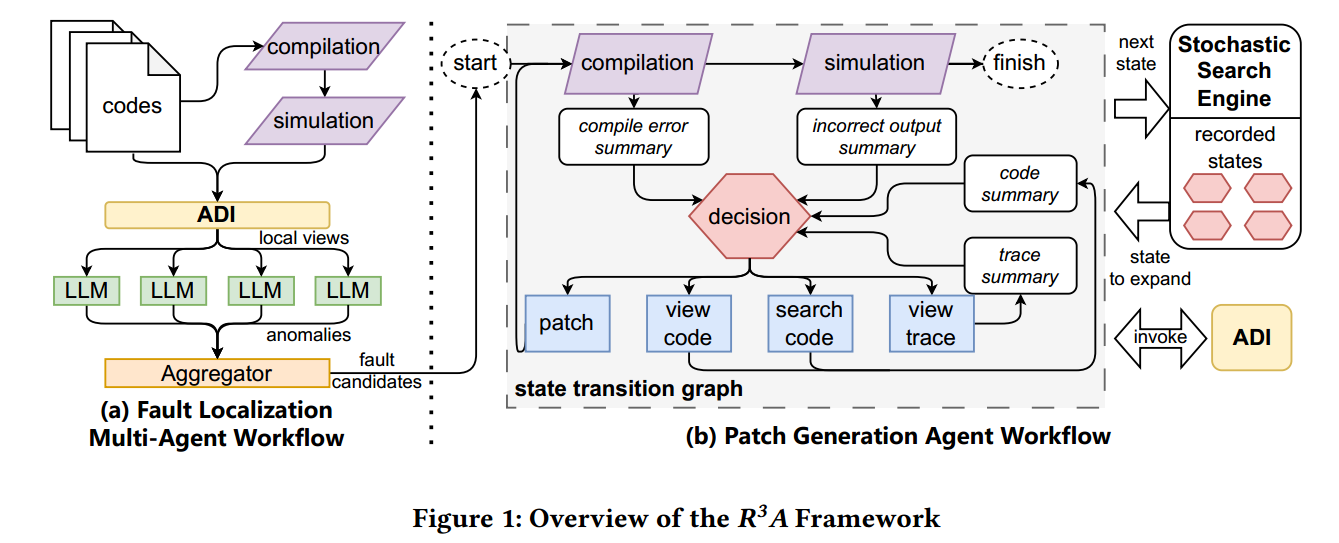
论文提出的答案是一个框架,叫 R³A。这个框架不是单纯让 LLM 一次性吐出补丁,而是把整个修 bug 过程做成一个带搜索的 agent 系统,并且分成两步:
- 先做故障定位,缩小可疑代码范围
- 再做补丁生成,反复试错,直到找到能通过测试的修改方案
二、作者为什么觉得这个问题难
作者在引言里讲了两个主要难点。
1. LLM 本身有随机性,不可靠
LLM 生成答案是采样出来的,同样的问题多问几次,答案可能不同。对于写代码这件事,有时这反而是优点,因为可以多试几种修法;但在 RTL 调试里,这会变成问题,因为硬件验证非常强调稳定和正确。作者把这个问题概括为:LLM 有随机性,不能保证每次都给出正确修复。
2. RTL 代码和波形太长,输入上下文很差
RTL 设计通常层次多、代码长,而且波形数据按周期展开,非常冗长。LLM 面对这种长而稀疏的信息时,很容易注意力分散,看到很多表面异常,却抓不住真正的根因。作者认为,直接把整份 RTL 和波形都塞给模型,不仅低效,而且会导致输出不稳定。
所以这篇论文的本质,是在解决两个问题:
- 怎么让 LLM 修 bug 更稳定
- 怎么让 LLM 看到更聚焦、更有用的上下文
三、R³A 的核心思想是什么
论文的核心思想可以概括成一句话:
先用多智能体找到“哪里可能错了”,再用带随机搜索的 Tree-of-Thoughts 去试探“怎么改才对”。
作者把整个框架分成三部分:
- 多智能体故障定位
- 随机 Tree-of-Thoughts 补丁生成
- ADI(Agent-Debugger Interface)接口层,负责让 agent 能看代码、看波形、调用编译/仿真工具
论文第 3 页 Figure 1 是总览图。左边是 fault localization,右边是 patch generation。这个图其实就是整篇论文的骨架。
四、第一部分:故障定位是怎么做的
作者提出的是一种 multi-agent anomaly detection,也就是“多智能体异常检测”。
它为什么需要多智能体
因为完整 RTL 设计太大,单个 LLM 很难一次看完并准确定位。于是作者把大问题拆成多个小问题:把 RTL 代码切成一段一段,每段交给一个 agent 去判断“这段代码和当前错误有没有关系”。
具体流程
论文第 5 页 Figure 3 讲得很清楚,流程大致是四步: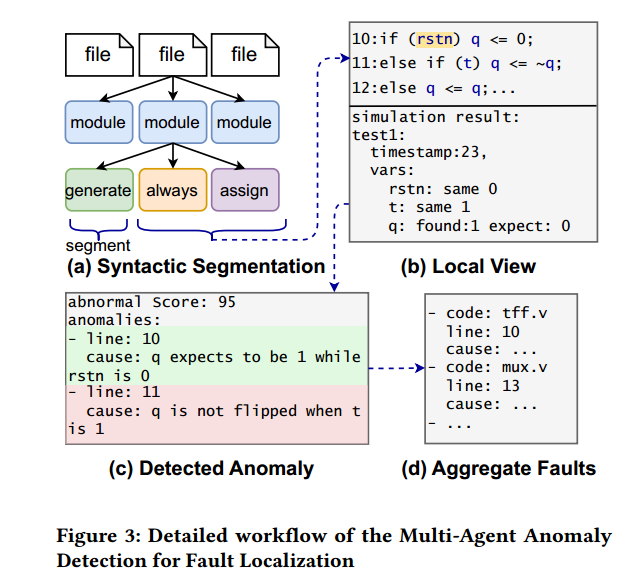
第一步:代码分段
作者先把完整 RTL 设计按语法结构拆分。做法是基于 AST 递归切分,直到得到一些较小但语法完整的代码片段。
第二步:构造 local view
每个代码片段会和相关错误信息组合起来,比如:
- 编译或 lint 报错
- 仿真结果
- 波形不一致信息
这样就形成一个“局部视图”,也就是 agent 的输入。
第三步:每个 agent 独立分析
每个 local view 给一个 LLM agent,让它判断这段代码是不是可疑,并给出异常位置和原因。
第四步:聚合和筛选
把多个 agent 的结果收集起来,保留高分异常,再做排序和过滤,得到最终的 fault candidates,也就是可能出错的位置。
这一部分的意义
它不是直接找出唯一正确的 bug 行,而是给后续补丁生成提供较好的起点。作者也承认,这些 candidates 可能不完全准确,但至少能帮助 patch generation agent 聚焦。并且后续 agent 不会被严格限制在这些位置上,它仍然可以发现候选点之外的问题。
你可以怎么理解它
这有点像:
- 一个大项目代码太多
- 先让几个人分别检查不同模块
- 每个人报出自己怀疑的地方
- 最后汇总成一份“重点排查清单”
这份清单不一定百分百对,但能显著减少盲查成本。
五、第二部分:补丁生成是怎么做的
这是整篇论文最核心的技术点。
作者不是让 LLM 一次输出最终补丁,而是把修复过程定义成一个搜索问题。论文第 3 页 Figure 2 和第 4 页的算法是这里的关键。
1. 补丁生成为什么是搜索问题
作者把一个调试状态定义成二元组:
- 代码状态 c
- 对话历史 h
也就是说,一个状态不只是“当前代码长什么样”,还包括“agent 之前已经看过什么、问过什么、试过什么”。这样,bug 修复就不是一次生成,而是在很多状态之间移动。
初始状态是原始代码加初始对话。之后 agent 不断:
- 看代码
- 查波形
- 搜索片段
- 打补丁
- 编译仿真
- 再根据结果继续想
每走一步,就形成一个新状态。多个新状态连起来,就是一棵搜索树。目标就是在这棵树里,找到一个能让所有测试通过的状态。
2. 什么叫 stochastic Tree-of-Thoughts
Tree-of-Thoughts 本质上是:不是只走一条推理路径,而是保留多个思路分支,像树一样探索。作者这里加了一个关键改造:不是单纯 BFS 或 DFS,而是随机地、按启发式概率去选择下一个扩展状态。
为什么不直接 BFS/DFS?
- BFS 太平均,容易在浅层浪费太多时间
- DFS 太冒进,容易沿着一条错误方向越走越远
作者希望的是一种平衡:
- 好的状态多给机会继续扩展
- 但差一些的状态也不是完全放弃
- 保留探索和利用之间的平衡
3. 启发式函数在干什么
论文第 4 页给了一个 heuristic function,用来给每个状态打分。大意是:
一个状态如果具有这些特点,就更值得继续扩展:
- 已经通过了更多 testbench
- agent 获得了更多有用查询信息
而这些情况会被惩罚:
- 还有编译错误没解决
- 消耗 token 太多
- 非法工具调用太多
- 已经打了太多 patch,说明可能越改越乱
所以这个函数本质是在估计:
从这个状态继续搜下去,成功修好 bug 的希望大不大。
接着作者用 softmax 把分数变成概率。分数越高,被选中继续扩展的概率越大,但不是 100%。这就形成了“随机但有偏好”的搜索策略。
4. 算法过程怎么理解
Algorithm 1 的流程可以这样记:
- 初始只有一个或少数几个状态
- 每轮从当前状态集合里,按概率抽一个出来
- 回到该状态对应的代码版本
- 让 agent 继续从这个状态往下调试
- 得到一个新状态
- 如果测试全过,就停止
- 否则把新状态加入状态集合,继续搜
作者还提到一个 freshness penalty,就是某个状态刚被扩展过后,会临时降低它的吸引力,避免算法总盯着同一个状态不放。
5. 这部分的本质贡献
这部分最重要的贡献,不是提出了一个特别复杂的公式,而是把 LLM 的随机性从“缺点”变成了“搜索空间中的资源”。
通常大家会说 LLM 不稳定,所以多跑几次试试。作者进一步说:
既然它会随机,那不如把这种随机性组织成一棵有策略的搜索树。
这就是这篇论文最有意思的思想。
六、ADI 是什么,它为什么重要
ADI 全称是 Agent-Debugger Interface。你可以把它理解成:
一个在 LLM 和硬件调试环境之间的翻译层/中间层。
LLM 本身不擅长直接操作 EDA 工具,也不适合处理特别冗长原始输出,所以 ADI 负责做几件事:
- 帮 agent 获取聚焦后的代码视图和波形视图
- 帮 agent 搜索相关片段
- 帮 agent 调用编译、仿真、lint 等工具
- 把工具输出整理成适合 LLM 理解的文本反馈
这一步很关键,因为如果没有这个中间层,LLM 很容易把大量时间浪费在工具链细节上。作者明确说,他们不想让 LLM 去负责配置编译和仿真,而是希望它专注于“理解 bug 和想修法”。
七、实验是怎么做的
数据集
作者使用的是 RTL-repair dataset,这是一个常见的 RTL 修复基准,包含多种 buggy RTL 设计。
对比方法
作者拿自己的方法和四类基线比:
- RTL-repair:传统符号修复方法
- SWE-Agent:通用软件 agent
- MEIC
- UVLLM:面向 RTL 的 LLM 方法
模型与环境
- 底层模型用的是 DeepSeek-V3
- 工具上使用 Verilator 做 lint 和 simulation
- 还加了基于 Yosys 处理结果的额外 lint 检查
评价指标
一个 case 通过,表示修复后的波形和 golden reference 一致。
他们还用了 pass@k 来衡量可靠性,也就是在给定次数独立重试下,至少成功一次的概率。论文设置里每次重试有时间和 token 预算限制。
八、实验结果说明了什么
1. 总体修复能力很强
论文第 6 页 Table 3 显示,在 32 个 benchmark 中:
- RTL-repair 修好 16 个
- SWE-Agent 修好 15 个
- MEIC 修好 12 个
- UVLLM 修好 20 个
- R³A 修好 29 个
这是论文最重要的结果。作者据此声称:
- 相比其他 LLM 方法,多修了很多 bug
- 相比传统方法,也明显更强
2. 简单 case 大家都还行,难点在复杂 case
作者说前 17 个 benchmark 比较简单,通常只有一个模块一个文件,LLM 很容易理解。
真正拉开差距的是后 15 个复杂案例,它们往往:
- 多模块
- 多文件
- bug 藏得更深
- 可能要结合 lint、波形和层次结构分析
也就是说,R³A 的优势主要体现在复杂 RTL 设计上,而不是简单教学例子上。
3. 可靠性结果
论文结论部分给出的整体结果是:
- 90.6% 的 bug 能在给定时间限制内修复
- 平均 pass@5 = 86.7%
- 平均 pass@1 = 75.0%
这说明它不是偶尔蒙对一次,而是在多次独立运行下都有较高成功率。
九、消融实验说明了什么
这一部分很值得讲,因为它能证明作者的方法不是“堆模块碰巧有效”。
作者做了五种设置比较:
- naive:直接让 LLM 修
- agent:有 agent 流程,但没有 tree-of-thoughts
- BFS:有树搜索,但用 BFS
- fix-only:只有补丁生成搜索,没有故障定位
- full:完整方法
结果
full 最可靠
Figure 4 显示,full setting 的 pass@1 分布最好,说明完整方法最可靠。
stochastic ToT 比 BFS 和普通 agent 更好
作者认为,这证明随机 Tree-of-Thoughts 确实提升了可靠性,因为它比 BFS 更能兼顾探索和利用,也比一直往前冲的普通 agent 更不容易走进死路。
multi-agent fault localization 也有贡献
对比 fix-only 和 full,说明故障定位能提升整体可靠性。不过作者也很诚实,指出在个别 benchmark 上,局部视图有时会带来噪声,反而略微降低 pass@1。
Figure 5 的含义
第 6 页 Figure 5 比较了时间和 token 使用情况:
- BFS 用时很多,但 token 没充分用起来,说明过度探索浅层
- 普通 agent 反而容易一条路走太深,消耗更多 token,但缺少探索
- full setting 介于两者之间,更平衡
所以这部分实验其实是在证明:
作者的方法好,不只是因为“试得更多”,而是因为“试得更聪明”。
十、这篇论文的优点
1. 问题抓得很准
作者抓住了 LLM 做 RTL 修复时最关键的两个现实问题:随机性和长上下文。这个问题定义得很清楚。
2. 方法设计有层次
不是直接一句“我们用 agent 修 bug”,而是把流程拆成:
- 缩小上下文
- 搜索修复路径
- 中间接口适配工具链
整体结构比较完整。
3. 消融实验比较有说服力
它不仅证明“full 很强”,还解释了为什么比 naive、BFS、普通 agent 更强。
4. 很符合 RTL 调试的实际流程
真实工程里本来也不是“一次看全局然后直接改对”,而是:
- 看线索
- 缩小范围
- 编译仿真
- 反复试错
R³A 的流程和人类工程师工作方式很接近。
十一、这篇论文的局限和可质疑点
这部分如果老师让你“批判性阅读”,你就可以讲这些。
1. 数据集规模不算大
实验 benchmark 总数是 32 个,这对于验证框架可行性够用,但对证明泛化能力还不算特别强。
2. 依赖特定工具链和接口工程
这个方法不是“只靠模型”就能跑起来,它很依赖 ADI、Verilator、Yosys 等工程配套。所以它的成功有相当一部分来自系统工程整合。
3. 启发式函数需要人工设计
状态评分函数不是自动学出来的,而是人工设定的指标和系数。这样做更可控,但也意味着方法效果可能依赖经验调参。
4. 还不能解决所有类型 bug
作者自己也承认,一些算法性错误或者涉及复杂时序/周期内延迟的问题,他们的方法仍然难以修复,比如某些 pairing 和 i2c 相关案例。
5. 对底层模型能力仍有依赖
虽然论文强调 test-time scaling 和框架设计,但底层用的是 DeepSeek-V3。如果底层模型弱很多,框架收益可能会下降。
十二、你可以怎么总结这篇论文
你可以用下面这段话概括整篇:
这篇论文提出了一个名为 R³A 的 RTL 自动修复框架,目标是提高 LLM 修复 RTL bug 的可靠性。它的核心做法是:先通过多智能体异常检测对大规模 RTL 代码进行局部分析,得到可疑故障位置;再把补丁生成建模成搜索问题,利用带启发式函数的随机 Tree-of-Thoughts 在多个代码状态和对话状态之间进行探索,从而更稳定地找到可通过测试的补丁。实验表明,该方法在 RTL-repair 基准上显著优于传统方法和其他 LLM 方法。
十三、问“这篇文章最核心的创新是什么”
你可以答:
最核心的创新有两个。第一,它没有把 LLM 的随机性当成纯缺点,而是把随机性组织成一个受控搜索过程,也就是 stochastic Tree-of-Thoughts。第二,它针对 RTL 输入过长的问题,引入多智能体局部分析做 fault localization,从而改善输入质量。
十四、如果问“这篇文章相比已有工作强在哪里”
你可以答:
相比传统 RTL APR,它不受固定模板限制,修复空间更灵活;相比直接用 LLM 或普通 agent,它通过启发式随机搜索提高了可靠性;相比只靠 lint 或 tracing 的方法,它还加入了多智能体局部故障定位,因此在复杂多文件案例里表现更好。
我觉得这篇论文的价值不只是把 LLM 用到了 RTL 修复上,更重要的是它提出了一种“让 LLM 在工程任务里变得更可靠”的思路。它不是单纯追求更强模型,而是通过故障定位、接口设计和搜索策略把模型纳入一个受控框架。这种思路对其他代码修复和自动化调试任务也有借鉴意义。不过它的实验规模还有限,而且较依赖工程接口和人工设计的启发式函数,泛化能力仍需要进一步验证。
十六、最后帮你压成最短背诵版
一句话
这篇论文提出 R³A,通过多智能体故障定位 + 随机 Tree-of-Thoughts 搜索修复,提高 LLM 自动修复 RTL bug 的可靠性。
三个关键词
可靠性、故障定位、搜索式补丁生成。
三个贡献
多智能体 fault localization、stochastic ToT patch generation、ADI 调试接口。
实验结论
在 RTL-repair benchmark 上,R³A 修复 29/32 个 bug,整体修复率 90.6%,平均 pass@5 为 86.7%。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)