具身智能导航架构深度解析:从端到端到世界模型的技术演进
0. 引言
具身智能(Embodied AI)导航是机器人学与人工智能交叉领域的核心研究方向,其目标是让机器人能够像人类一样理解自然语言指令、感知复杂环境,并自主规划和执行导航任务。随着大语言模型(LLM)和视觉语言模型(VLM)的快速发展,具身导航领域在2023-2025年间经历了深刻的技术变革。本文将系统性地梳理当前主流的五大技术流派,深入分析各流派的核心算法原理、代表性工作以及实际应用场景,帮助读者全面理解这一前沿领域的技术脉络。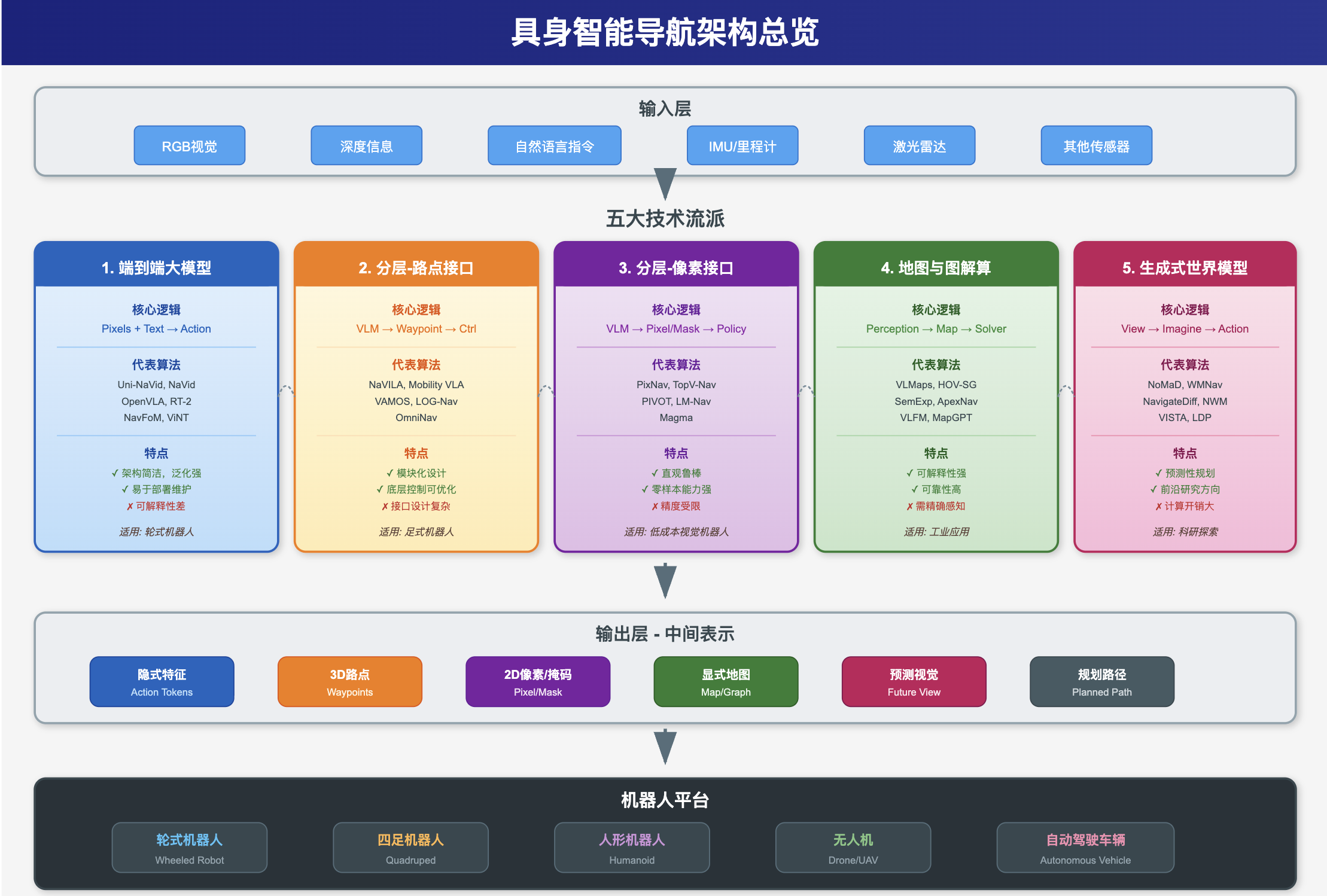
具身智能导航的技术架构按照网络设计逻辑和控制接口方式,可以划分为五个主要流派:端到端大模型流派、分层架构路点接口流派、分层架构视觉像素接口流派、地图与图解算流派,以及生成式与世界模型流派。每个流派都有其独特的设计哲学和适用场景,下文将逐一进行深入剖析。
1. 端到端大模型流派(End-to-End Foundation Models)
1.1 核心设计理念
端到端大模型流派的核心设计理念可以用一个简洁的公式概括:Pixels + Text → Action Tokens。这一流派主张将感知、理解、规划和控制整合到一个统一的神经网络中,模型直接从原始视觉输入和自然语言指令生成底层控制信号,中间不存在显式的物理坐标或路点等中间表示。这种设计哲学强调"大数据出奇迹"和模型的通用性,试图通过海量数据训练让模型自动学习从感知到行动的完整映射关系。
端到端方法的优势在于其概念简洁性和部署便利性。由于不需要设计复杂的中间表示和模块间接口,整个系统可以进行端到端的梯度优化,理论上能够学习到更加统一和协调的策略。此外,这种架构也更容易从大规模互联网数据中进行预训练,然后迁移到机器人导航任务上。
1.2 代表性算法详解
1.2.1 Uni-NaVid:统一视频导航模型
Uni-NaVid是北京大学和智源研究院联合提出的视频驱动视觉语言动作(VLA)模型,代表了端到端导航的最新进展。该模型的核心创新在于将多种导航子任务——包括视觉语言导航(VLN)、目标物体导航(ObjectNav)、具身问答(EQA)和人物跟踪——统一到一个单一的模型框架中。
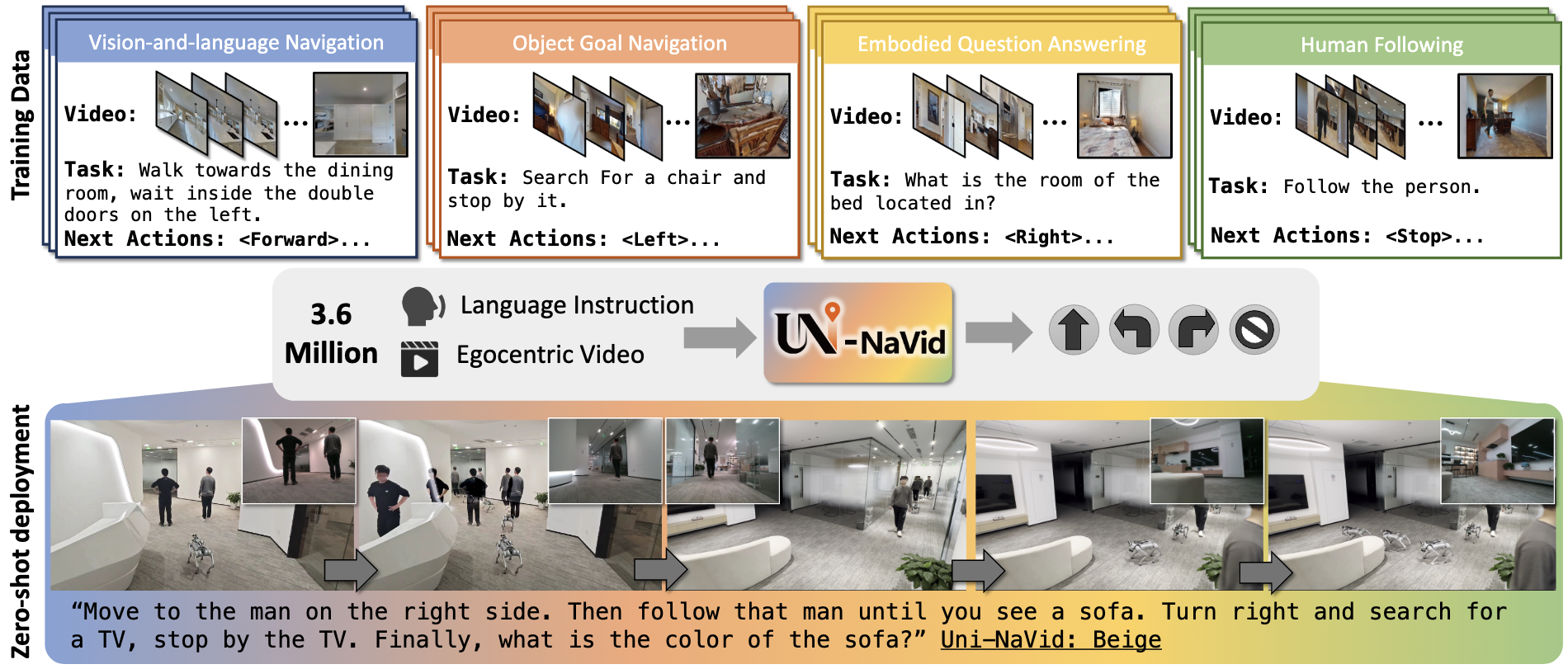
Uni-NaVid的技术架构采用了创新的在线Token合并策略(Online Token Merging),该策略能够在保持信息完整性的同时显著压缩视觉Token的数量。这一设计使得模型能够以约5Hz的推理频率运行,并支持多步动作预测,从而实现非阻塞式的实时部署。模型处理单视角RGB视频帧和自然语言指令,通过提取和合并视觉Token来维持紧凑的信息表示。
在训练数据方面,Uni-NaVid整合了360万个导航样本,覆盖四种核心导航子任务。通过这种大规模多任务联合训练,模型展现出显著的任务协同效应(Task Synergy),即不同任务之间的知识可以相互促进。实验结果表明,Uni-NaVid在多个导航基准测试中达到了最先进的性能水平,并且具备出色的仿真到真实(Sim-to-Real)泛化能力。
1.2.2 NaVid:无地图视频导航
NaVid是另一个具有代表性的端到端导航模型,其最大的特点是完全摒弃了传统导航系统中常用的地图和深度输入。该模型仅依赖单目RGB相机的实时视频流进行导航决策,这种设计模拟了人类的导航方式——人类在陌生环境中导航时,通常也不会构建精确的几何地图,而是依靠对环境的视觉记忆和空间推理。
NaVid的技术创新体现在其对历史观测信息的处理方式上。模型将历史视频帧作为时空上下文(Spatio-temporal Context)进行编码,这种设计有效地缓解了里程计噪声对导航决策的影响。在训练方面,NaVid使用了51万个导航样本和76.3万个大规模网络数据进行联合训练,这种混合训练策略使模型能够同时学习导航控制知识和丰富的视觉语义知识。
1.2.3 NavFoM:导航基础模型
NavFoM(Navigation Foundation Model)代表了端到端导航基础模型的最新探索方向。与之前的模型不同,NavFoM被设计为能够跨越不同机器人形态(包括四足机器人、无人机、轮式机器人)和不同任务类型(视觉语言导航、目标搜索、自动驾驶)进行统一部署,无需针对特定任务进行微调。
NavFoM的训练数据规模达到了惊人的800万个导航样本,模型采用统一的架构处理来自不同相机配置和导航场景的多模态输入。其技术核心包括标识符Token(Identifier Tokens)机制,用于捕获相机视角信息和任务时序上下文;以及动态采样策略,用于在Token长度约束下优化性能。这种设计使NavFoM能够作为真正通用的导航基础模型,适应多样化的机器人平台和应用场景。
1.2.4 ViNT:视觉导航Transformer
ViNT(Visual Navigation Transformer)是伯克利大学提出的视觉导航预训练模型,采用Transformer架构学习导航可供性(Navigational Affordances)。该模型使用通用的目标到达(Goal-reaching)目标函数进行训练,这使其能够在零样本设置下泛化到多种不同的环境和机器人平台。
ViNT的架构设计包括EfficientNet CNN用于编码视觉观测和目标图像,以及Transformer模块用于时序建模和动作预测。模型以具身无关(Embodiment-agnostic)的方式预测动作,这意味着同一个预训练模型可以直接部署到不同类型的机器人上。此外,ViNT还支持通过提示调优(Prompt-tuning)技术适配不同的任务规格,如GPS路点或转向指令。
1.2.5 RoboTron-Nav:感知规划预测统一框架
RoboTron-Nav是ICCV 2025上发表的统一导航框架,其核心创新在于将感知(Perception)、规划(Planning)和预测(Prediction)三个任务进行深度整合。该框架采用多任务协作策略,将导航任务与具身问答(EQA)任务联合训练,使模型能够更好地理解复杂的语言指令和视觉场景。
RoboTron-Nav的技术亮点包括自适应3D感知历史采样策略(Adaptive 3D-aware History Sampling),该策略能够在长距离导航过程中优化历史观测的利用效率,避免冗余信息的干扰。通过整合大语言模型的推理能力,RoboTron-Nav能够理解多样化的命令并做出准确的导航决策。在CHORES-S基准测试的目标导航任务中,RoboTron-Nav达到了81.1%的成功率,创造了新的最先进性能记录。
1.2.6 OpenVLA与RT-2:开源与闭源VLA对比
OpenVLA是一个拥有70亿参数的开源视觉语言动作模型,代表了开源社区在VLA领域的重要突破。该模型整合了Llama 2 7B语言模型与DINOv2和SigLIP视觉编码器,在近100万条机器人轨迹数据上进行微调训练。OpenVLA的架构将输入处理为视觉、语言和离散化动作Token的序列,实现了端到端的机器人控制。
值得注意的是,尽管OpenVLA的参数量仅为RT-2-X的七分之一,但其在通用操作任务上的成功率却显著超越了这个闭源大模型。这一结果表明,通过精心设计的训练策略和数据选择,开源模型完全可以在实际性能上与大型闭源模型相竞争。OpenVLA的开源特性(包括预训练代码、微调框架、模型权重和训练数据)为学术研究和工业应用提供了重要的基础设施支持。
RT-2(Robotic Transformer 2)是Google提出的视觉语言动作模型,其核心贡献是证明了互联网规模的视觉语言知识可以有效迁移到机器人控制任务中。RT-2通过将机器人动作表示为语言Token,使预训练的VLM能够直接输出控制指令。
1.2.7 CLIP-RT与其他轻量化方案
CLIP-RT提出了一种基于自然语言监督的机器人策略学习方法,允许非专业用户通过简单的语言反馈(如"把手臂向右移")来收集训练数据。该模型仅有10亿参数,但在成功率上比70亿参数的OpenVLA高出24%,展示了高效模型设计的潜力。在LIBERO基准测试中,CLIP-RT实现了93.1%的成功率,同时保持了很高的推理吞吐量。
Vi-LAD通过知识蒸馏技术,将大型VLM的注意力模式迁移到轻量级网络中,实现了在资源受限设备上的端到端部署。这种方法在保持模型性能的同时大幅降低了计算开销。
TrackVLA专门针对动态目标跟踪场景设计,能够在复杂环境中持续追踪移动目标并执行相应的导航动作。
OctoNav追求通用型导航能力,试图用单一模型解决多种类型的导航任务,体现了端到端流派对模型统一性的极致追求。
1.3 技术特点与局限
端到端大模型流派的主要优势包括:系统架构简洁,易于部署和维护;可以利用大规模预训练数据,具备较强的泛化能力;不需要显式的环境建模,对传感器误差有一定的鲁棒性。然而,这一流派也存在明显的局限:模型决策过程缺乏可解释性;对于需要精确几何推理的任务,纯端到端方法可能表现不佳;在安全关键场景中,难以提供形式化的安全保证。
二、分层架构:路点接口流派(Hierarchical - Waypoint Interface)
2.1 核心设计理念
分层架构路点接口流派的核心逻辑是VLM Brain → Local Planner/Controller,即"大脑只负责指路,小脑负责走路"。这种设计将高层次的语义理解和规划与底层的运动控制解耦,高层模块(通常是VLM或LLM)负责理解任务指令并输出中层表示(如路点坐标),而低层控制器则负责执行具体的运动控制。

这种分层设计的优势在于模块化和可维护性。高层规划模块可以利用大语言模型的强大推理能力,而底层控制器则可以采用经过充分验证的传统控制方法或强化学习策略。这种架构特别适合足式机器人(如四足机器人和人形机器人)以及长距离导航场景,因为这些场景中底层运动控制的复杂性使得纯端到端方法难以胜任。
2.2 代表性算法详解
2.2.1 NaVILA:足式机器人导航VLA
NaVILA是专门为足式机器人设计的视觉语言动作模型,采用创新的两级框架架构。上层模块将自然语言指令翻译为中层动作命令(如"向前移动75厘米"),而不是直接预测底层关节角度;下层模块则采用基于强化学习训练的视觉运动策略来执行这些中层命令。
这种设计的关键创新在于中层动作表示的引入。相比于直接预测低层关节控制信号,中层动作命令更加抽象和语义化,这使得上层VLM更容易学习从语言指令到动作的映射。同时,下层的强化学习控制器可以专注于解决复杂的运动控制问题,如保持平衡、避障和地形适应。
NaVILA的另一个技术亮点是其训练数据的构建方式。研究团队整合了多种数据源,包括真实世界的人类行走视频和仿真环境中的机器人导航数据,通过这种多源数据融合,模型能够学习到更加鲁棒的导航策略。在VLN-CE-Isaac基准测试中,NaVILA的性能显著优于不使用仿真预训练路点预测器的方法。
2.2.2 Mobility VLA:长距离多模态导航
Mobility VLA是针对长距离室内导航场景设计的分层VLA系统,其核心创新在于引入了多模态指令导航与示范游览(MINT,Multimodal Instruction Navigation with demonstration Tours)任务范式。在这一范式中,机器人利用预先录制的示范视频来理解环境布局,然后根据用户的多模态指令(包含自然语言和图像)执行导航任务。
Mobility VLA的技术架构包含两个关键组件:高层策略利用长上下文视觉语言模型处理示范视频和用户指令,识别目标位置对应的帧;低层策略则基于拓扑图(Topological Graph)生成实时的机器人动作。拓扑图是一种轻量级的环境表示,它将环境抽象为一系列关键位置节点和它们之间的连接关系,相比于精细的几何地图,拓扑图更加紧凑且易于维护。
在真实世界836平方米的测试环境中,Mobility VLA展现出了出色的多模态指令执行能力,能够准确响应诸如"我应该把这个放回哪里?"这样的复杂查询。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 23
23 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)