大型语言模型中的情感智能:从认知科学到技术实践的深度探索
0. 引言
在人类文明发展的历程中,情感智能一直是区别人类与其他物种的关键特征之一。情感智能不仅仅是识别喜怒哀乐的能力,而是一个复杂的认知系统,涉及情感的感知、理解、表达和调节等多个层面。随着人工智能技术的快速发展,特别是大型语言模型(Large Language Models, LLMs)的出现,机器开始具备了理解和处理人类情感的潜力,这为人机交互、心理健康、教育等领域带来了革命性的变化。
情感智能的概念最早由心理学家彼得·萨洛维和约翰·梅耶于1990年提出,他们将其定义为"准确感知、评估和表达情感的能力,以及接近和产生有助于思维的情感的能力,理解情感及情感知识的能力,以及调节情感以促进情感和智力成长的能力"。这一定义揭示了情感智能的多维性质,它不仅包括对情感的识别和理解,还涉及情感在认知过程中的调节作用。在人类的日常生活中,情感智能影响着我们的决策制定、社会交往、问题解决和心理健康等各个方面。
近年来,随着深度学习技术的突破和计算资源的提升,大型语言模型在自然语言处理任务中表现出了惊人的能力。从GPT系列到BERT、T5等模型,这些系统不仅能够生成流畅的文本,还能在一定程度上理解文本中包含的情感信息。然而,真正的情感智能远不止于文本分类和情感标注,它要求系统具备深层的情感理解、共情能力和情感调节技能。这就提出了一个重要的研究问题:大型语言模型能否真正具备类似人类的情感智能?这里推荐一个飞书文档内容

1. 大型语言模型的技术基础
1.1 Transformer架构与情感认知
大型语言模型的核心技术基础建立在Transformer架构之上,这一架构最初由Vaswani等人在2017年的论文《Attention Is All You Need》中提出。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer完全依赖于注意力机制来捕获序列中的依赖关系。在情感智能的语境下,这种架构具有独特的优势,能够同时关注文本中的多个位置,从而更好地理解情感表达的复杂性和上下文依赖性。
Transformer的自注意力机制允许模型在处理每个词时,同时考虑整个句子中所有其他词的信息。这种机制对于情感理解至关重要,因为情感往往不是由单个词汇决定的,而是由词汇之间的相互作用、语法结构、语义关系等多重因素共同构成的。例如,在句子"虽然电影很长,但是剧情非常精彩"中,模型需要理解"虽然…但是…"这种转折关系,才能正确判断整体的正面情感倾向。
在数学形式上,自注意力机制可以表示为:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T / d k ) V Attention(Q,K,V) = softmax(QK^T/\sqrt{d_k})V Attention(Q,K,V)=softmax(QKT/dk)V
其中Q(查询)、K(键)和V(值)分别是输入序列的三种不同表示, d k d_k dk是键向量的维度。这个公式背后的直觉是,每个位置的表示都是所有位置的值向量的加权平均,权重由查询向量和键向量的相似性决定。在情感分析的语境下,这意味着模型能够学习到哪些词汇组合对于确定情感倾向最为重要。
1.2 预训练与微调的情感学习机制
大型语言模型的训练通常遵循"预训练+微调"的范式。在预训练阶段,模型通过大规模无标注文本数据学习语言的通用表示,这一过程无意中捕获了大量的情感信息。由于训练语料来自互联网的各个角落——新闻文章、社交媒体帖子、文学作品、评论等——模型接触到了人类情感表达的丰富多样性。
在这个过程中,模型学习到的不仅仅是词汇的语义含义,还包括情感的细微变化和表达方式。例如,模型能够理解"好"、“不错”、“棒极了”、“完美"等词汇在情感强度上的差异,以及"还行”、“一般”、"凑合"等词汇所传达的中性或轻微负面的态度。更重要的是,模型还能学习到情感表达的上下文依赖性,比如反讽、幽默、双关等复杂的语言现象。
微调阶段则是在特定的情感分析任务上对模型进行优化。通过有监督学习,模型学习将其内部表示映射到具体的情感标签。这一过程不仅提高了模型在特定任务上的性能,还增强了其对情感细微差别的敏感性。研究表明,经过微调的模型能够在情感分类任务上达到与人类标注者相当的准确性。
1.3 情感表示的向量空间分布
从计算角度来看,大型语言模型将词汇和句子映射到高维向量空间中。在这个空间里,语义相似的词汇在空间中的距离较近,而语义差异较大的词汇距离较远。有趣的是,研究发现情感信息也在这个向量空间中呈现出规律性的分布模式。
通过分析词向量的分布,研究人员发现存在一个"情感轴",沿着这个轴的方向,词汇的情感极性发生规律性的变化。正面情感词汇聚集在轴的一端,负面情感词汇聚集在另一端,而中性词汇则分布在中间区域。这种分布模式不是人为设计的,而是模型从大量文本数据中自然学习得到的,这表明情感信息在语言的统计结构中具有基础性的地位。
更进一步,研究人员发现不同情感维度(如效价、唤醒度、优势性等)在向量空间中对应不同的方向。这种多维情感表示使得模型能够捕获情感的复杂性和丰富性,而不仅仅是简单的正负面分类。
2. 基于认知科学的情感智能框架
2.1 奈瑟认知理论在LLMs中的体现
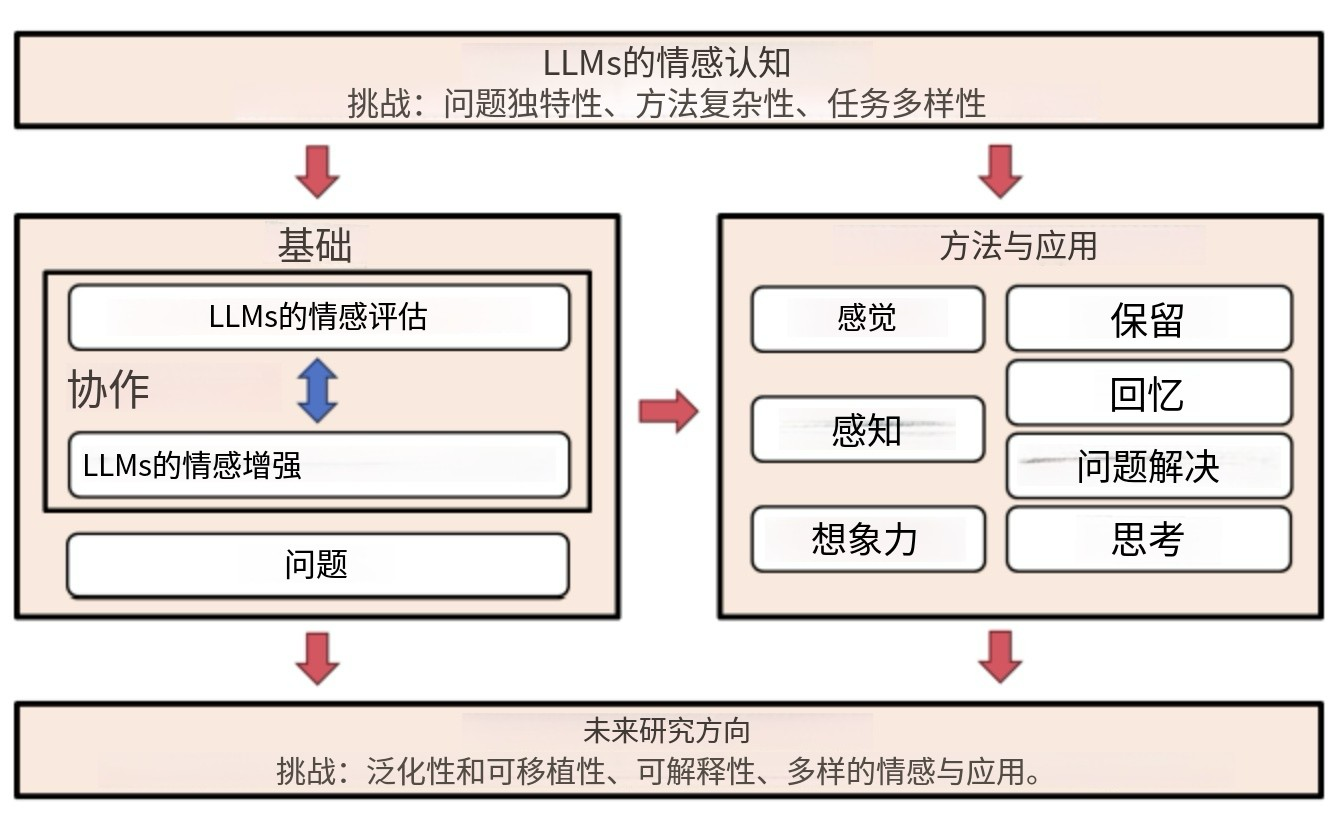
认知心理学家乌尔里克·奈瑟(Ulric Neisser)提出的认知过程理论为理解人类情感认知提供了重要的理论框架。奈瑟将认知过程划分为感觉、知觉、想象、记忆、回忆、问题解决和思维七个阶段。这一框架不仅适用于分析人类的情感认知过程,也为评估和改进大型语言模型的情感智能提供了科学的指导。
在LLMs的情感认知研究中,这七个认知阶段各自对应着不同的技术挑战和研究方向。感觉阶段涉及模型如何接收和预处理情感文本;知觉阶段关注模型如何理解和解释情感信息;想象阶段涉及情感内容的生成;记忆阶段涉及情感知识的编码和存储;回忆阶段涉及情感信息的检索;问题解决阶段涉及在具体任务中应用情感智能;思维阶段则涉及更高层次的情感推理和反思能力。
2.2 情感感知的多模态输入处理
在感觉阶段,LLMs需要处理来自不同源头的情感信息。传统的文本输入只是情感感知的一个维度,现代的情感智能系统还需要整合来自语音、图像、视频等多模态数据的情感信息。提示工程(Prompt Engineering)成为了这一阶段的核心技术,通过精心设计的提示词,研究人员能够引导模型更好地理解和处理情感相关的输入。
2.2.1 语音情感识别的核心机制
语音情感识别(Speech Emotion Recognition, SER)代表了多模态情感分析中最重要的技术分支之一。语音信号包含了丰富的情感信息,这些信息通过韵律特征、音质特征、能量分布等多个维度来体现。与文本相比,语音能够传达更加细腻和真实的情感状态,因为说话人往往难以完全控制其声音中的情感泄露。
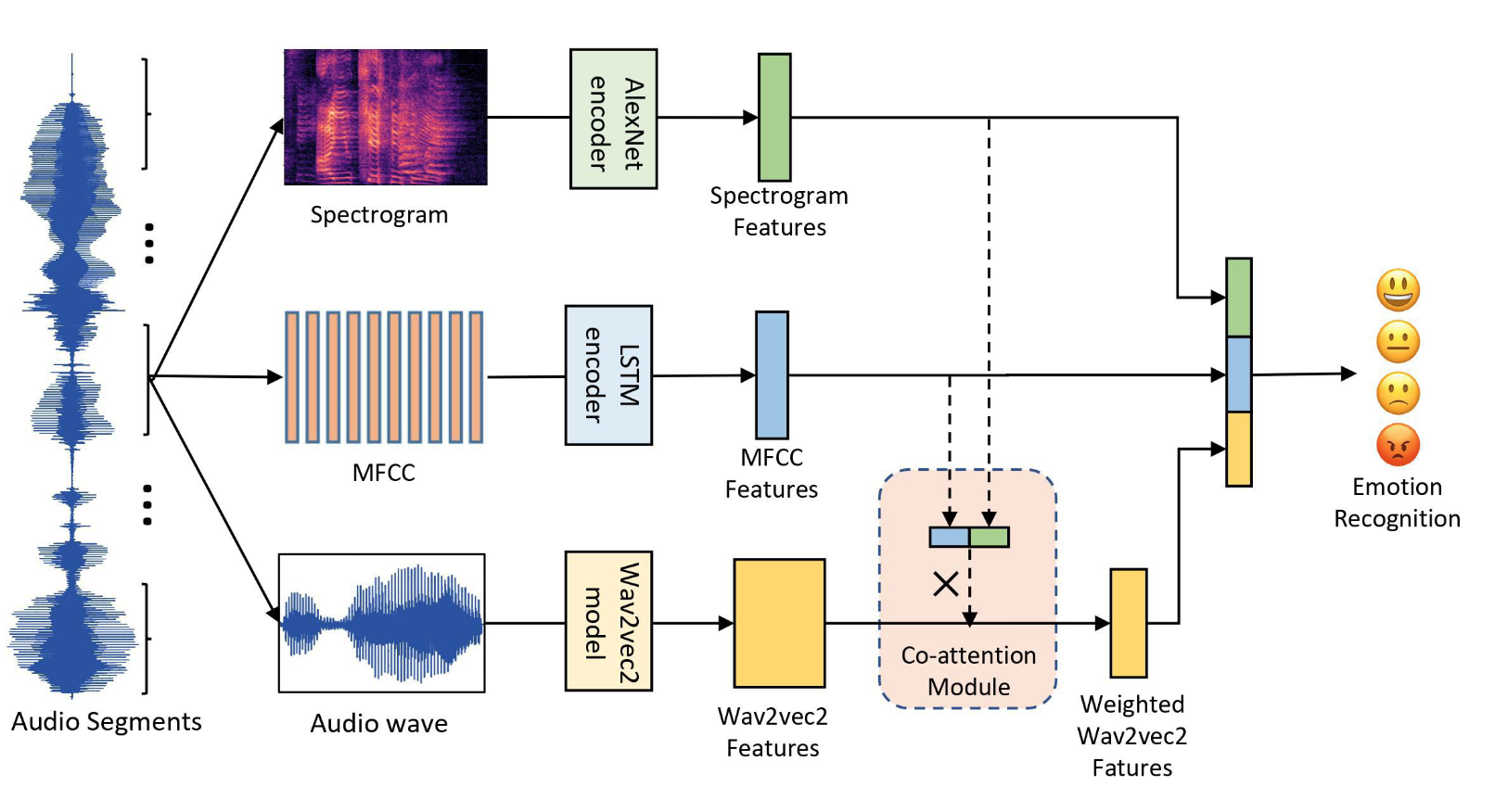
语音情感识别的技术流程主要包括两个核心步骤:特征提取和分类建模。在特征提取阶段,系统需要从原始语音信号中提取能够表征情感状态的关键特征。这些特征包括基频(F0)、共振峰、梅尔频率倒谱系数(MFCC)、语音能量和语速等。每一类特征都从不同角度刻画了情感在语音中的表现形式,例如,愤怒情绪通常表现为更高的基频和更大的能量变化,而悲伤情绪则可能表现为较低的基频和较慢的语速。
在分类建模阶段,传统方法主要依赖高斯混合模型(GMM)、隐马尔可夫模型(HMM)和支持向量机(SVM)等经典机器学习算法。然而,随着深度学习技术的发展,长短时记忆网络(LSTM)、卷积神经网络(CNN)和注意力机制等方法已经成为主流。特别是端到端(end-to-end)的方法开始被广泛应用,这种方法能够直接从原始语音信号中学习情感特征,避免了手工特征设计的局限性。
2.2.2 多模态融合的技术挑战
例如,在处理社交媒体数据时,模型需要同时考虑****文本内容、表情符号、图片信息以及用户的历史行为模式**。这种多维度的信息整合要求模型具备更强的感知能力。更重要的是,不同模态之间存在时间同步、特征对齐和信息冲突等技术挑战。研究表明,通过结构化的提示设计和交叉注意力机制,可以显著提升模型对复杂情感信息的感知准确性。
现代多模态情感分析系统通常采用早期融合、晚期融合或混合融合策略。早期融合在特征层面整合不同模态的信息,能够捕获模态间的交互作用,但可能导致特征维度过高的问题。晚期融合在决策层面整合不同模态的结果,虽然计算简单,但可能丢失模态间的相关性。混合融合则结合了两种方法的优势,在多个层次进行信息整合。
嵌入表示(Embedding Representations)技术使得不同模态的情感信息能够被映射到统一的向量空间中,为后续的情感分析提供了基础。通过预训练的多模态模型,文本、图像、音频等不同类型的情感信息可以被转换为数值化的表示,这些表示保留了原始数据中的情感特征。现代的自监督学习方法,如WavLM、emotion2vec等,在无标签数据上进行预训练,学习到了丰富的情感表征,为下游的情感识别任务提供了强有力的基础。
2.3 情感知觉的深层理解机制
知觉阶段涉及对感知到的情感信息进行深层理解和解释。这一过程不仅包括基本的情感分类(正面、负面、中性),还包括更细致的情感识别(愤怒、悲伤、喜悦、恐惧等)以及情感强度的评估。现代LLMs在这一阶段表现出了令人印象深刻的能力,特别是在处理复杂的情感表达和隐含情感方面。
情感知觉的一个重要挑战是处理情感表达的上下文依赖性。同样的词汇在不同的语境中可能传达完全不同的情感信息。例如,"太好了"在不同的语调和情境下可能表达真正的兴奋,也可能表达讽刺或沮丧。LLMs通过其深层的上下文理解能力,能够在一定程度上处理这种复杂性。
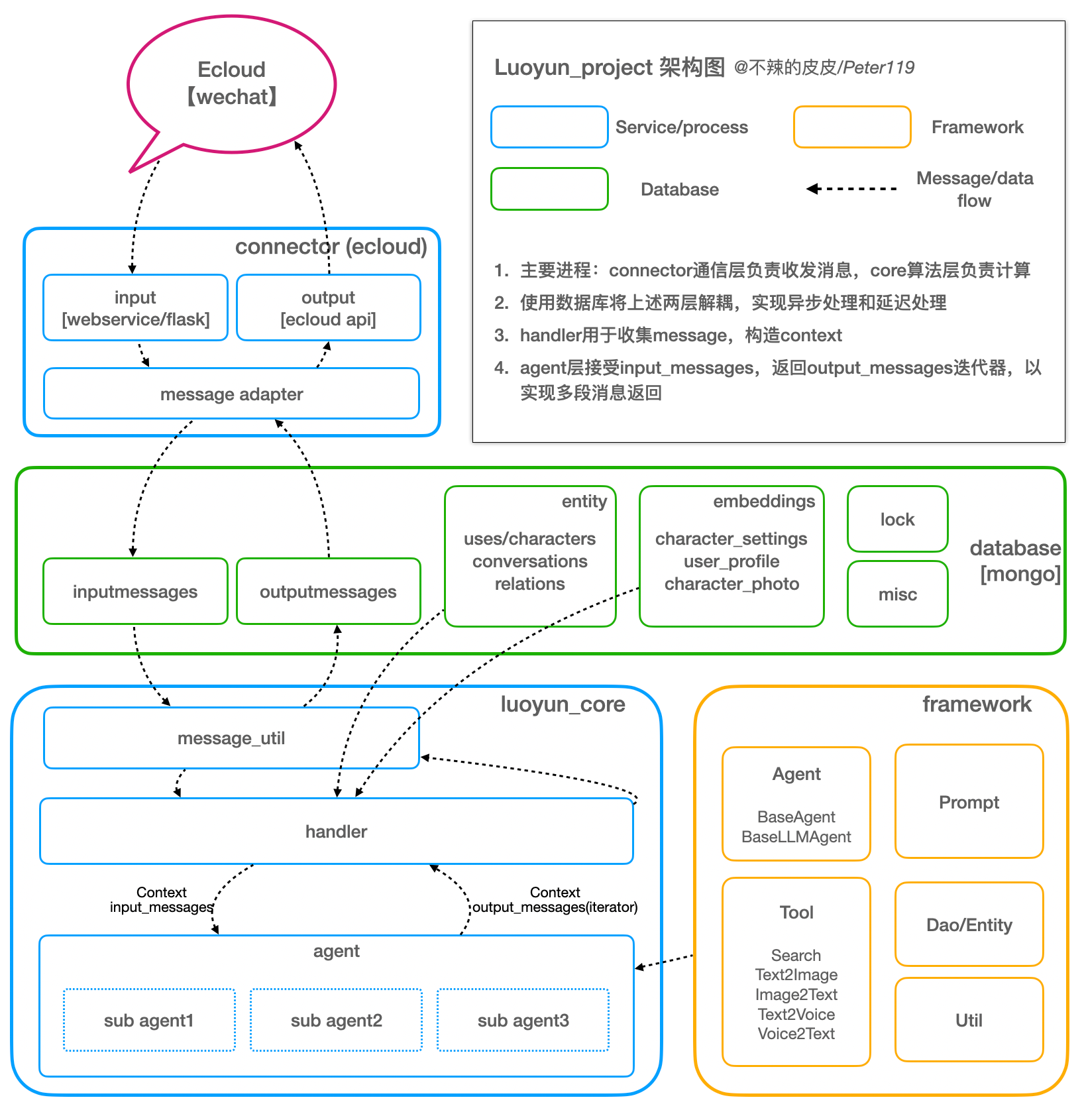
另一个重要的研究方向是情感识别的可解释性。传统的机器学习模型往往被批评为"黑盒",难以解释其决策过程。在情感分析中,可解释性尤为重要,因为错误的情感判断可能带来严重的后果。研究人员通过注意力权重可视化、梯度分析等技术,尝试解释LLMs是如何做出情感判断的,这为提高模型的可信度和改进模型性能提供了重要线索。下面是luoyun_project的流程图。作为微信虚拟人,她可以完成日常对话交流
2.4 语音大模型的发展历程与技术演进
2.4.1 语音大模型发展概述
在深入讨论深度学习架构之前,我们需要理解语音情感识别技术的最新发展趋势——语音大模型(Speech Large Language Models, SpeechLLMs)的兴起。语音大模型是指和人一样能听会说的智能系统,它们不仅具备高质量语音理解与回复能力,还支持多轮对话和低延迟的实时交互。
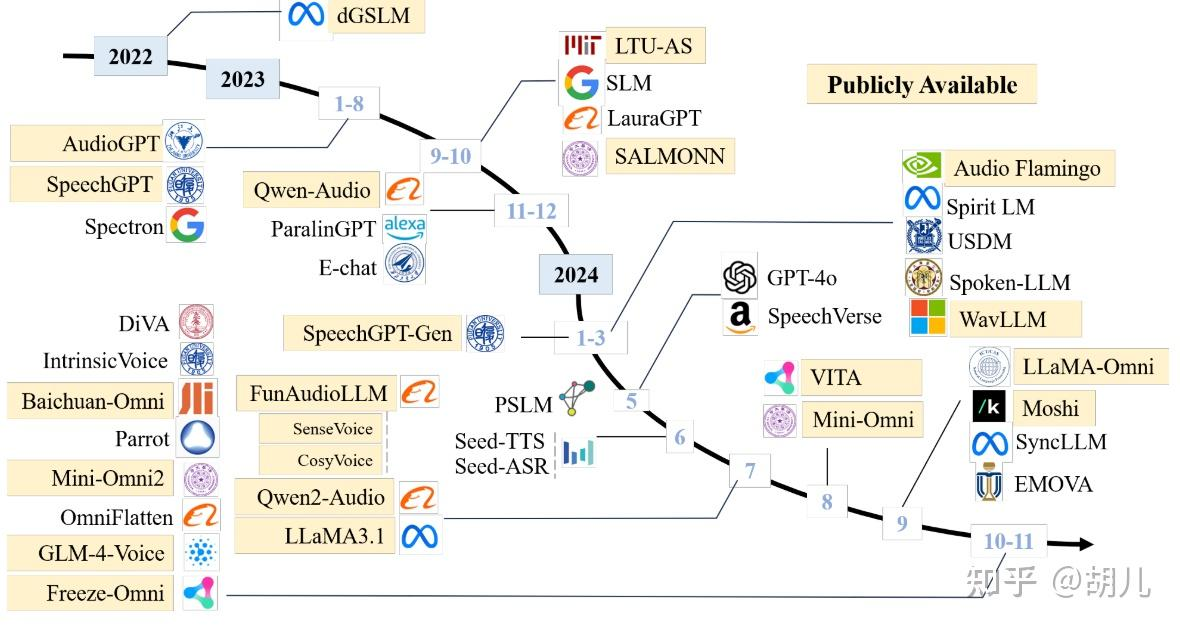
语音技术的发展经历了三个重要阶段:
- 前大模型时代(Pre-LLM Stage):语音技术各个细分方向相对独立,包括语音识别、语音合成、情感识别等。
- 早期大模型时代(Early-LLM Stage):引入预训练模型如wav2vec、HuBERT等,通过大规模数据学习语音表征。
- 语音大模型时代(SpeechLLM Stage):各细分任务开始融合,走向"大一统"的语音大模型。
2.4.2 技术路径对比:级联vs端到端
现代语音大模型主要采用两种技术路径:
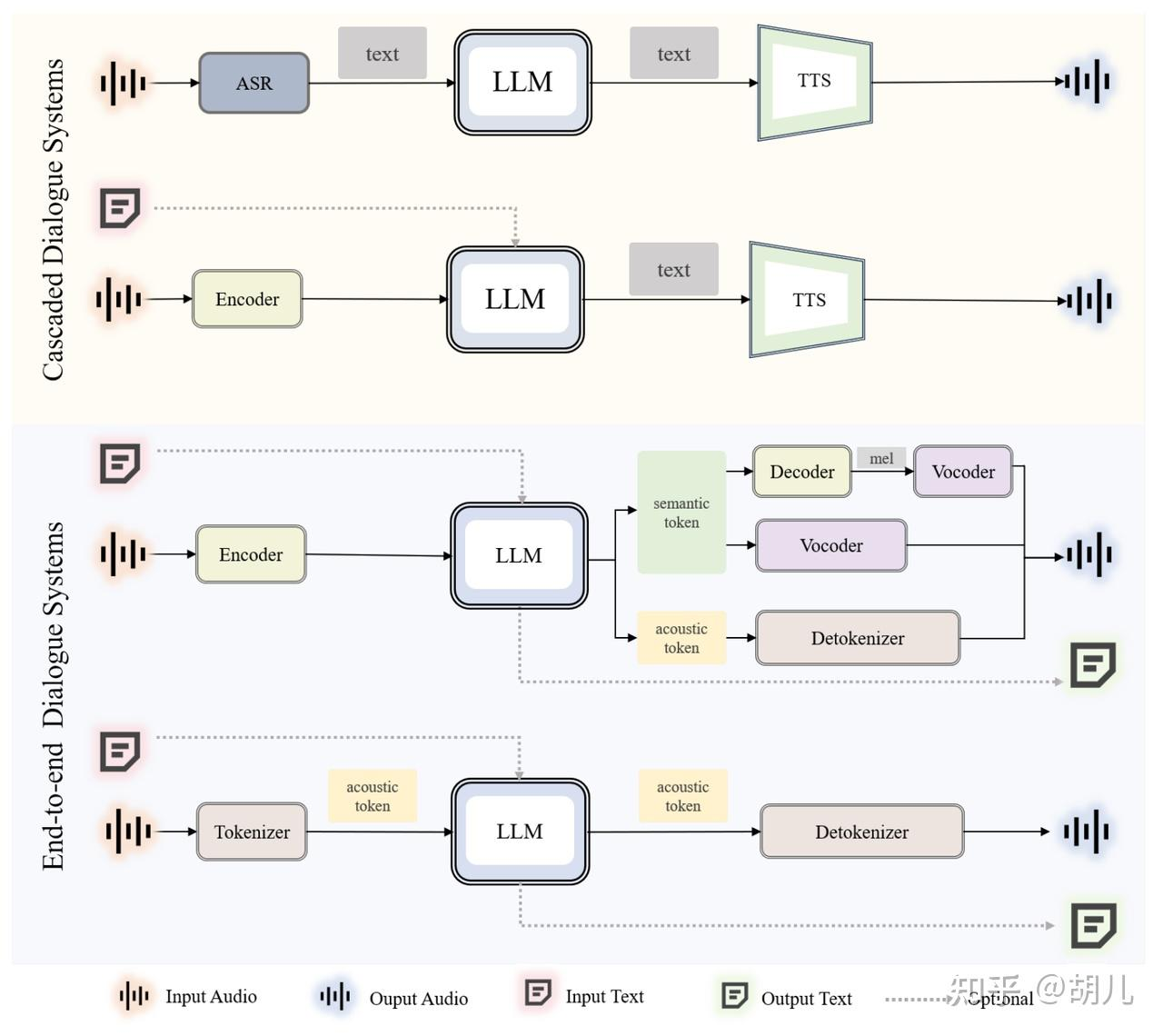
级联系统(Cascaded):
- 由语音识别(ASR)、大语言模型(LLM)、语音合成(TTS)三部分组成
- 优势:构建成本较低,各模块成熟且相对独立
- 缺陷:信息丢失(如情感信息)、延迟较大、能力潜力有限
端到端系统(End-to-end):
- 单一模型实现语音输入和输出
- 优势:系统简单、能力强、延迟低
- 挑战:构建成本大、依赖大量训练数据
2.4.3 现代深度学习架构在语音情感识别中的应用
深度学习技术在语音情感识别领域带来了革命性的进步。卷积神经网络(CNN)通过其局部感受野的特性,能够有效捕获语音谱图中的局部模式,这些模式往往对应着特定的情感特征。长短时记忆网络(LSTM)和门控循环单元(GRU)等循环神经网络架构则擅长处理语音的时序特性,能够捕获情感表达的动态变化过程。
注意力机制的引入进一步提升了模型的性能,通过学习不同时间段和频率成分的重要性权重,模型能够自动关注最具情感表达力的语音片段。Transformer架构在语音情感识别中的应用展现了强大的潜力,其自注意力机制能够捕获长距离的时间依赖关系,这对于理解情感的上下文变化至关重要。
近年来,可变形Transformer(DST)等创新架构的出现,使得模型能够自适应地关注语音信号中有价值的细粒度情感信息。这类模型通过动态调整注意力权重的分布,能够更精确地定位情感表达的关键时刻和频率成分。多分支网络结构也被广泛采用,通过并行处理不同尺度和类型的特征,最终通过融合机制得到更鲁棒的情感表示。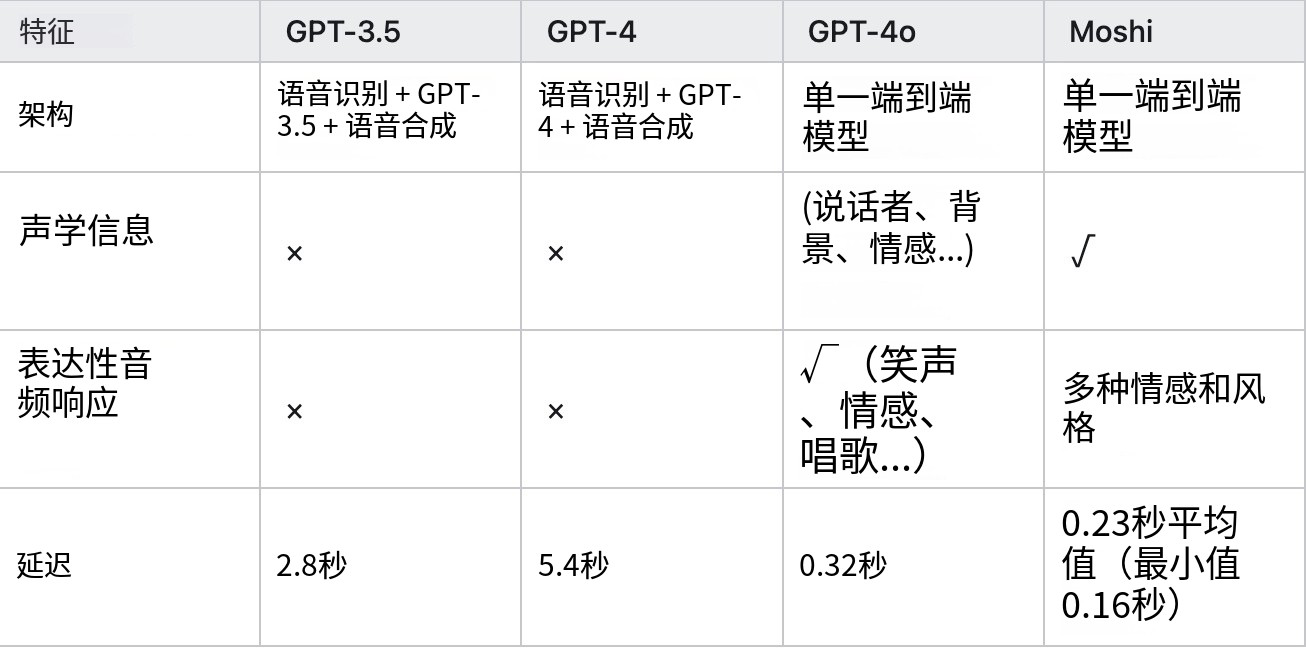
2.5 语音情感识别的实际代码实现
让我们通过一个基于emotion2vec的语音情感识别系统来展示现代技术的实际应用:
import torch
import torch.nn as nn
import torchaudio
import numpy as np
from transformers import AutoModel, AutoTokenizer
import librosa
from typing import Dict, List, Tuple
import matplotlib.pyplot as plt
import seaborn as sns
class AudioEmotionRecognizer:
def __init__(self, model_path="emotion2vec/emotion2vec_base"):
"""
基于emotion2vec的语音情感识别器
"""
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = AutoModel.from_pretrained(model_path)
self.model.to(self.device)
self.model.eval()
# 情感标签映射
self.emotion_labels = {
0: "angry", # 愤怒
1: "disgusted", # 厌恶
2: "fearful", # 恐惧
3: "happy", # 快乐
4: "neutral", # 中性
5: "sad", # 悲伤
6: "surprised" # 惊讶
}
# 初始化分类头
self.classifier = nn.Sequential(
nn.Linear(768, 256),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(256, len(self.emotion_labels))
).to(self.device)
def extract_audio_features(self, audio_path: str, sr: int = 16000) -> torch.Tensor:
"""
提取音频特征
"""
# 加载音频文件
waveform, sample_rate = torchaudio.load(audio_path)
# 重采样到16kHz
if sample_rate != sr:
resampler = torchaudio.transforms.Resample(sample_rate, sr)
waveform = resampler(waveform)
# 确保单声道
if waveform.shape[0] > 1:
waveform = torch.mean(waveform, dim=0, keepdim=True)
return waveform.squeeze()
def extract_traditional_features(self, audio_path: str) -> Dict[str, np.ndarray]:
"""
提取传统语音特征,包括MFCC、基频等
"""
# 加载音频
y, sr = librosa.load(audio_path, sr=16000)
# 提取MFCC特征
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
mfcc_delta = librosa.feature.delta(mfcc)
mfcc_delta2 = librosa.feature.delta(mfcc, order=2)
# 提取基频
pitches, magnitudes = librosa.piptrack(y=y, sr=sr)
pitch = []
for t in range(pitches.shape[1]):
index = magnitudes[:, t].argmax()
pitch.append(pitches[index, t])
pitch = np.array(pitch)
# 提取频谱特征
spectral_centroids = librosa.feature.spectral_centroid(y=y, sr=sr)[0]
spectral_rolloff = librosa.feature.spectral_rolloff(y=y, sr=sr)[0]
spectral_bandwidth = librosa.feature.spectral_bandwidth(y=y, sr=sr)[0]
# 提取零交叉率
zcr = librosa.feature.zero_crossing_rate(y)[0]
# 提取RMS能量
rms = librosa.feature.rms(y=y)[0]
return {
'mfcc': mfcc,
'mfcc_delta': mfcc_delta,
'mfcc_delta2': mfcc_delta2,
'pitch': pitch,
'spectral_centroids': spectral_centroids,
'spectral_rolloff': spectral_rolloff,
'spectral_bandwidth': spectral_bandwidth,
'zcr': zcr,
'rms': rms
}
def predict_emotion(self, audio_path: str) -> Dict[str, float]:
"""
预测音频的情感
"""
with torch.no_grad():
# 提取特征
waveform = self.extract_audio_features(audio_path)
waveform = waveform.unsqueeze(0).to(self.device)
# 通过emotion2vec模型提取特征
features = self.model(waveform).last_hidden_state
# 池化操作
pooled_features = torch.mean(features, dim=1)
# 分类
logits = self.classifier(pooled_features)
probabilities = torch.softmax(logits, dim=-1)
# 转换为字典格式
emotion_scores = {}
for idx, prob in enumerate(probabilities[0]):
emotion = self.emotion_labels[idx]
emotion_scores[emotion] = float(prob)
return emotion_scores
def analyze_emotion_trajectory(self, audio_path: str, window_size: float = 2.0,
hop_size: float = 1.0) -> List[Dict]:
"""
分析音频中情感的时间变化轨迹
"""
# 加载音频
y, sr = librosa.load(audio_path, sr=16000)
duration = len(y) / sr
# 滑动窗口分析
trajectory = []
window_samples = int(window_size * sr)
hop_samples = int(hop_size * sr)
for start_sample in range(0, len(y) - window_samples, hop_samples):
end_sample = start_sample + window_samples
segment = y[start_sample:end_sample]
# 保存临时文件
temp_file = "temp_segment.wav"
librosa.output.write_wav(temp_file, segment, sr)
# 预测情感
emotion_scores = self.predict_emotion(temp_file)
dominant_emotion = max(emotion_scores.keys(), key=lambda k: emotion_scores[k])
trajectory.append({
'start_time': start_sample / sr,
'end_time': end_sample / sr,
'dominant_emotion': dominant_emotion,
'emotion_scores': emotion_scores
})
return trajectory
def visualize_emotion_analysis(self, audio_path: str, save_path: str = None):
"""
可视化情感分析结果
"""
# 分析情感轨迹
trajectory = self.analyze_emotion_trajectory(audio_path)
# 提取传统特征用于对比分析
traditional_features = self.extract_traditional_features(audio_path)
# 创建子图
fig, axes = plt.subplots(3, 2, figsize=(15, 12))
fig.suptitle('语音情感分析可视化', fontsize=16)
# 1. 情感轨迹图
times = [t['start_time'] for t in trajectory]
emotions = [t['dominant_emotion'] for t in trajectory]
emotion_to_num = {emotion: idx for idx, emotion in enumerate(self.emotion_labels.values())}
emotion_nums = [emotion_to_num[e] for e in emotions]
axes[0, 0].plot(times, emotion_nums, 'o-', linewidth=2, markersize=6)
axes[0, 0].set_xlabel('时间 (秒)')
axes[0, 0].set_ylabel('情感类别')
axes[0, 0].set_title('情感时间轨迹')
axes[0, 0].set_yticks(range(len(self.emotion_labels)))
axes[0, 0].set_yticklabels(list(self.emotion_labels.values()))
axes[0, 0].grid(True, alpha=0.3)
# 2. 情感分布饼图
emotion_counts = {}
for t in trajectory:
emotion = t['dominant_emotion']
emotion_counts[emotion] = emotion_counts.get(emotion, 0) + 1
axes[0, 1].pie(emotion_counts.values(), labels=emotion_counts.keys(), autopct='%1.1f%%')
axes[0, 1].set_title('情感分布')
# 3. MFCC热图
axes[1, 0].imshow(traditional_features['mfcc'], aspect='auto', origin='lower')
axes[1, 0].set_xlabel('时间帧')
axes[1, 0].set_ylabel('MFCC系数')
axes[1, 0].set_title('MFCC特征')
# 4. 基频变化
time_pitch = np.linspace(0, len(traditional_features['pitch'])/16000,
len(traditional_features['pitch']))
axes[1, 1].plot(time_pitch, traditional_features['pitch'])
axes[1, 1].set_xlabel('时间 (秒)')
axes[1, 1].set_ylabel('基频 (Hz)')
axes[1, 1].set_title('基频变化')
axes[1, 1].grid(True, alpha=0.3)
# 5. 频谱质心
time_spectral = np.linspace(0, len(traditional_features['spectral_centroids'])/16000*512,
len(traditional_features['spectral_centroids']))
axes[2, 0].plot(time_spectral, traditional_features['spectral_centroids'])
axes[2, 0].set_xlabel('时间 (秒)')
axes[2, 0].set_ylabel('频谱质心 (Hz)')
axes[2, 0].set_title('频谱质心变化')
axes[2, 0].grid(True, alpha=0.3)
# 6. RMS能量
time_rms = np.linspace(0, len(traditional_features['rms'])/16000*512,
len(traditional_features['rms']))
axes[2, 1].plot(time_rms, traditional_features['rms'])
axes[2, 1].set_xlabel('时间 (秒)')
axes[2, 1].set_ylabel('RMS能量')
axes[2, 1].set_title('能量变化')
axes[2, 1].grid(True, alpha=0.3)
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
plt.show()
# 使用示例
def demo_audio_emotion_recognition():
"""
语音情感识别演示
"""
recognizer = AudioEmotionRecognizer()
# 示例音频文件路径(需要替换为实际路径)
audio_files = [
"examples/happy_speech.wav",
"examples/sad_speech.wav",
"examples/angry_speech.wav"
]
for audio_file in audio_files:
print(f"分析音频文件: {audio_file}")
# 单次情感预测
emotion_scores = recognizer.predict_emotion(audio_file)
dominant_emotion = max(emotion_scores.keys(), key=lambda k: emotion_scores[k])
print(f"主要情感: {dominant_emotion}")
print("所有情感分数:")
for emotion, score in emotion_scores.items():
print(f" {emotion}: {score:.3f}")
# 情感轨迹分析
trajectory = recognizer.analyze_emotion_trajectory(audio_file)
print(f"情感轨迹包含 {len(trajectory)} 个时间段")
# 可视化分析结果
recognizer.visualize_emotion_analysis(audio_file,
save_path=f"{audio_file.split('.')[0]}_analysis.png")
print("-" * 50)
if __name__ == "__main__":
demo_audio_emotion_recognition()
3. 情感智能评估框架与方法
3.1 EmotionBench:突破性的情感评估范式
EmotionBench是近年来在大型语言模型情感智能评估领域出现的一个重要框架,它代表了从传统的单维度情感分类向多维度、情境化情感理解评估的重大转变。该框架的核心创新在于构建了一个包含428种情境模式的大型数据集,这些情境被精心设计来激发八种不同的负面情绪:愤怒、焦虑、抑郁、沮丧、嫉妒、内疚、恐惧和尴尬。
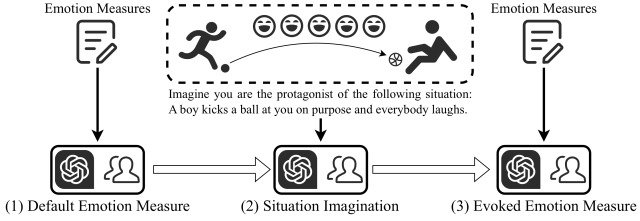
EmotionBench的评估流程体现了对人类情感认知过程的深度理解。首先,系统测量参与者(包括人类和LLM)的默认情绪状态,建立基线。然后,向参与者展示特定情境的文本描述,要求他们想象自己处于这些情境中。最后,再次测量情绪状态,通过比较前后的差异来量化情境诱发的情绪变化。这种方法不仅评估了模型识别情感的能力,更重要的是评估了模型理解情感产生机制的能力。
研究结果显示,现代LLMs在情感理解方面表现出了令人惊讶的能力。除gpt-3.5-turbo外,大多数LLM的负面情绪得分往往高于人类,这可能反映了模型在处理负面信息时的敏感性。同时,LLM的正面得分与人类相似,表明它们能够较好地理解积极情感。然而,不同模型之间存在显著差异,LLaMA-2的13B版本显示的情绪变化明显高于7B版本,这表明模型规模对情感理解能力有重要影响。
3.2 多维度情感评估指标体系
传统的情感分析主要关注情感的效价(正面/负面),但真实的人类情感远比这种二元分类复杂。现代的情感评估体系引入了多个维度来全面衡量LLMs的情感智能。
效价-唤醒度模型是最广泛使用的情感评估框架之一。效价描述了情感的愉悦程度(从非常不愉快到非常愉快),而唤醒度描述了情感的激活程度(从非常平静到非常激动)。通过在这个二维空间中定位情感,可以更精确地描述复杂的情感状态。
情感强度评估关注情感表达的强烈程度。同样是表达喜悦,"还不错"和"太棒了"在强度上有显著差异。LLMs需要能够识别这种细微的差别,并在生成内容时恰当地控制情感强度。
情感一致性评估检验模型在长对话中维持情感状态的能力。人类在对话中会表现出情感的连续性和逻辑性,优秀的LLM也应该具备这种能力。
4. 核心技术实现与代码示例
4.1 基础情感分析实现
让我们从最基本的情感分析实现开始,展示如何使用Python和主流的深度学习框架来构建情感分析系统:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
import numpy as np
class EmotionAnalyzer:
def __init__(self, model_name="cardiffnlp/twitter-roberta-base-emotion"):
"""
初始化情感分析器
使用预训练的RoBERTa模型进行多情感分类
"""
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForSequenceClassification.from_pretrained(model_name)
self.emotion_pipeline = pipeline(
"text-classification",
model=self.model,
tokenizer=self.tokenizer,
return_all_scores=True
)
# 情感标签映射
self.emotion_labels = {
'LABEL_0': 'anger', # 愤怒
'LABEL_1': 'joy', # 喜悦
'LABEL_2': 'optimism', # 乐观
'LABEL_3': 'sadness' # 悲伤
}
def analyze_emotion(self, text):
"""
分析单个文本的情感
返回详细的情感分布和主要情感
"""
results = self.emotion_pipeline(text)[0]
# 转换标签并按分数排序
emotion_scores = {}
for result in results:
emotion = self.emotion_labels.get(result['label'], result['label'])
emotion_scores[emotion] = result['score']
# 获取主要情感
dominant_emotion = max(emotion_scores.keys(), key=lambda k: emotion_scores[k])
confidence = emotion_scores[dominant_emotion]
return {
'dominant_emotion': dominant_emotion,
'confidence': confidence,
'all_emotions': emotion_scores,
'text': text
}
def batch_analyze(self, texts):
"""
批量分析多个文本的情感
"""
results = []
for text in texts:
result = self.analyze_emotion(text)
results.append(result)
return results
# 使用示例
if __name__ == "__main__":
# 创建情感分析器实例
analyzer = EmotionAnalyzer()
# 测试文本
test_texts = [
"今天天气真好,心情特别愉快!",
"工作压力太大了,感觉很焦虑。",
"虽然遇到了困难,但我相信一定能克服。",
"听到这个消息我真的很震惊和难过。"
]
# 分析情感
for text in test_texts:
result = analyzer.analyze_emotion(text)
print(f"文本: {text}")
print(f"主要情感: {result['dominant_emotion']} (置信度: {result['confidence']:.3f})")
print(f"所有情感分数: {result['all_emotions']}")
print("-" * 50)
4.2 基于大型语言模型的情感理解
接下来展示如何使用大型语言模型进行更复杂的情感理解任务:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from typing import List, Dict
class LLMEmotionProcessor:
def __init__(self, model_name="microsoft/DialoGPT-medium"):
"""
初始化基于LLM的情感处理器
"""
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.model.to(self.device)
# 添加特殊token用于情感分析
if self.tokenizer.pad_token is None:
self.tokenizer.pad_token = self.tokenizer.eos_token
def emotion_aware_generation(self, context: str, target_emotion: str, max_length: int = 100):
"""
基于指定情感生成回应
"""
# 构建情感引导的提示
prompt = f"在{target_emotion}的情绪下回应以下内容:\n{context}\n回应:"
# 编码输入
inputs = self.tokenizer.encode(prompt, return_tensors="pt").to(self.device)
# 生成回应
with torch.no_grad():
outputs = self.model.generate(
inputs,
max_length=max_length,
num_return_sequences=1,
temperature=0.7,
do_sample=True,
pad_token_id=self.tokenizer.pad_token_id
)
# 解码生成的文本
generated_text = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
response = generated_text[len(prompt):].strip()
return {
'context': context,
'target_emotion': target_emotion,
'response': response
}
def analyze_emotional_trajectory(self, conversation: List[str]):
"""
分析对话中的情感变化轨迹
"""
trajectory = []
for i, utterance in enumerate(conversation):
# 简单的情感分析(这里可以集成更复杂的模型)
emotion_keywords = {
'positive': ['好', '棒', '喜欢', '开心', '高兴', '满意', '不错'],
'negative': ['不好', '差', '讨厌', '难过', '生气', '失望', '糟糕'],
'neutral': ['一般', '还行', '普通', '正常']
}
scores = {'positive': 0, 'negative': 0, 'neutral': 0}
for emotion, keywords in emotion_keywords.items():
for keyword in keywords:
if keyword in utterance:
scores[emotion] += 1
dominant_emotion = max(scores.keys(), key=lambda k: scores[k])
if all(score == 0 for score in scores.values()):
dominant_emotion = 'neutral'
trajectory.append({
'turn': i + 1,
'utterance': utterance,
'emotion': dominant_emotion,
'scores': scores
})
return trajectory
# 使用示例
def demo_llm_emotion_processing():
processor = LLMEmotionProcessor()
# 情感引导生成示例
context = "今天的考试结果出来了"
emotions = ["高兴", "紧张", "失望"]
print("=== 情感引导生成示例 ===")
for emotion in emotions:
result = processor.emotion_aware_generation(context, emotion)
print(f"情感: {emotion}")
print(f"回应: {result['response']}")
print("-" * 30)
# 情感轨迹分析示例
conversation = [
"今天天气不错啊",
"是的,很适合出去玩",
"但是我有点担心下雨",
"天气预报说不会下雨的",
"那就太好了,我们可以安心出发了"
]
print("\n=== 情感轨迹分析示例 ===")
trajectory = processor.analyze_emotional_trajectory(conversation)
for turn in trajectory:
print(f"轮次{turn['turn']}: {turn['utterance']}")
print(f"情感: {turn['emotion']}")
print()
if __name__ == "__main__":
demo_llm_emotion_processing()
4.3 情感智能评估实现
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)