强化学习理论7 大总结
使用书本shttps://arxiv.org/pdf/2412.05265
学习路径

基本定义
一个智能体用三个变量来描述:
内部状态——当前生成的内容“我爱”
策略——下一个词选择什么“你”“他”
动作——选择“你”
状态更新函数——拼接上旧字段“我爱你”
强化学习的目标是找到一个策略Π最大化这个公式,基于初始状态和策略,找到一个策略,使得逐步生成的动作状态分布的奖励累计最大。
最优策略就是下面的简写:p0是数据集中所有的问题,VΠ就是刚刚的奖励估计,也就是说,要求对于数据集的每个问题都找到最大的奖励

Reward TO GO——奖励衰减
对于没有尽头的游戏或者需要即时奖励的游戏

马尔可夫决策过程MDP
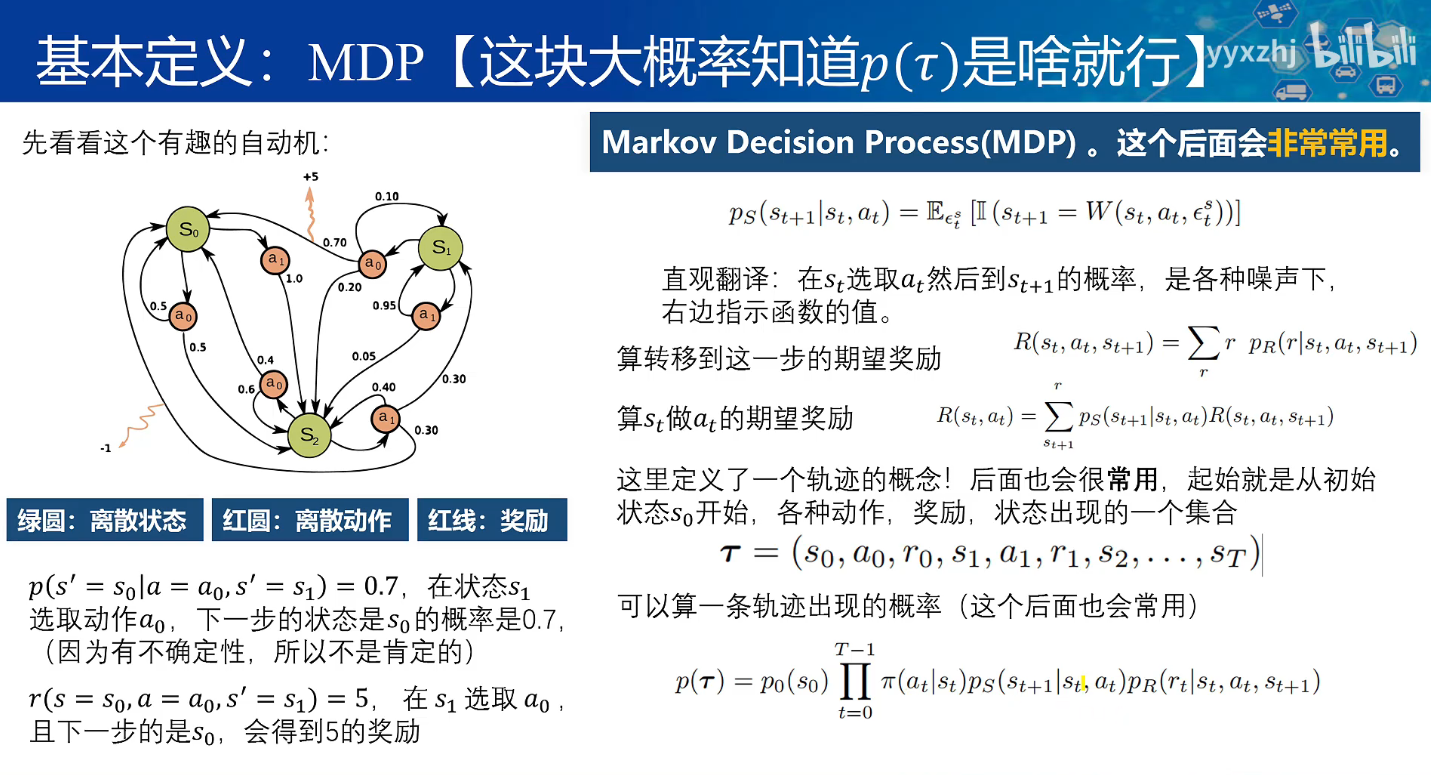
在强化学习中,一种常见的情况是采取动作后转移的状态是有概率的,有可能执行了a0却返回了s0,因此需要一个环境转移函数,描述在特定动作下,执行某个动作转移到另一个状态的概率。
描述这个状态转移函数 p(st+1∣st,at)是局部的、即时的,只关心当前状态和当前动作(也就是马尔可夫性)。
轨迹概率 p(τ) 是全局的、累积的,它把所有时间步的策略选择和状态转移连乘起来,所以看起来“依赖历史动作”,其实是依赖策略在每个时间步的选择过程。
这一系列环境转移,描述出来就是“轨迹”也就是τ=(S0,a0,s1,a1,s2,a2...st)一连串动作-状态序列
这条轨迹的出现概率就是这个p(τ)
总结而言,强化学习就是在不确定的环境(由转移函数描述)中,通过试错产生一系列状态和动作的序列(轨迹 τ ),并计算这些轨迹发生的概率 p(τ) 以及对应的总回报,从而优化策略的过程。
基于价值的强化学习
这里考虑两种价值
首先是状态价值,在处于状态S时,将来所能获得的奖励之和的期望值(状态价值):

状态行动价值是处于S并采取a时,未来的获得的奖励之和(后果价值):

在DP过程中,我们从一个状态s出发,在多个行动a中选择一个,智能体会获得一个确定的即时奖励r,并且到达下一个确定的状态s‘。
通过DP的思想,我们得到了强化学习的核心方程——贝尔曼最优方程,其描述了当前时刻状态s于下一个时刻状态s’,两者的状态最优价值之间的关系,从而允许我们逆推迭代,得到预估的最优状态值,从而选择当前时刻的动作

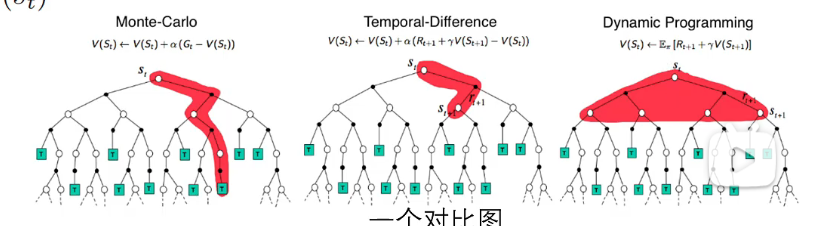
📊 基础公式 与 贝尔曼最优方程
这张图其实是强化学习最基础、最重要的几个概念的“公式速查表”,分为四大部分:
1️⃣ Value Function(状态价值函数)

2️⃣ State-Action Function / Q-Function(动作价值函数)

3️⃣ Advantage Function(优势函数)

4️⃣ Bellman’s Equations(贝尔曼迭代方程)→ 核心!

动态规划估计
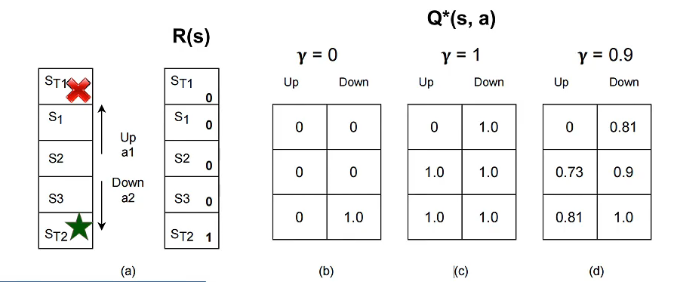
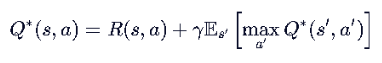
在这个例子中,根据更新公式,不同的奖励·折扣会极大影响收敛。
上面这个例子实际上是一个DP问题,因为其状态转移是肯定的,但在真实环境中,往往这种转移是有概率发生的,因此需要“蒙特卡洛估计”
(对V/对Q都可以更新)蒙特卡洛估计
-
2.2 动态规划(DP):
- 假设你知道整个 MDP 模型 → 知道 p(s′∣s,a)和 R(s,a)
- 可以直接用贝尔曼方程迭代求解 → “理论推导型”
-
2.3 蒙特卡洛(MC):
- 不知道模型! 只能跟环境交互 → 做个动作,得到下一个状态和奖励 (s′,r)
- 必须靠“实际跑轨迹”收集数据 → “实验统计型”
- 正如图中强调:“这个假设对后面思路很重要,我们只能是做个动作,然后得到环境的反馈”
📌 这正是强化学习最核心的设定:Model-Free(无模型) —— 不依赖环境内部机制,只靠交互学习。

📐 蒙特卡洛怎么估计 V(s)?【试到终点求均值 更新迭代】
回顾定义:
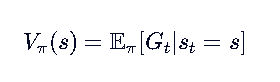
![]()
Gt是从当前这一步到终止状态的所有奖励!
意思是:从状态 s 开始,按策略 π 行动,未来总回报 G_t 的期望值。
但既然我们不知道期望是多少,那就:
- 初始化一个随机的 V(s) (比如全设为0)
- 让智能体按照当前策略 π 去玩很多轮游戏(episode)
- 在每一轮游戏中,每当访问到状态 s,就记录下从那一刻起直到 episode 结束所获得的实际总回报 G_t
- 把所有这些 G_t 加起来求平均 → 就是 V(s) 的估计值!
或者更工程化一点,用增量更新公式(图中给出):
🔄 同样适用于 Q(s, a)
Q 函数的定义是:
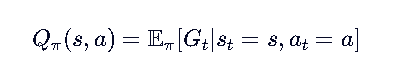
所以做法完全一样:
- 记录所有在状态 s 执行动作 a 后,后续得到的实际总回报 G_t
- 对这些 G_t 取平均 → 得到 Q(s, a)
- 也可以用增量更新:
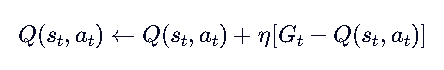
🧭 有了 Q,就能改进策略!
图中最后一行:
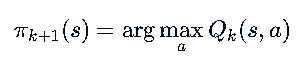
意思是:
我们用当前的 Q 估计值,在每个状态下选那个看起来最好的动作 → 得到新策略 π_{k+1}
这其实是一个策略迭代的过程:
- 用当前策略 π_k 去采样,估计 Q_k
- 用 Q_k 贪心地更新策略 → π_{k+1}
- 再用 π_{k+1} 去采样,重新估计 Q_{k+1}
- 重复… 直到收敛到最优策略!
⚠️ 注意:这里有个隐含前提 —— 要保证探索(exploration),否则可能陷入局部最优。比如可以用 ε-greedy 策略。
一言蔽之
这是一个交叉更新的过程,一开始VQ都是0,然后让模型随机探索地图,每次到达st开始记录从这里到结束的实际值Gt,然后用Gt-Qt乘以更新步长η去更新在st的估计值Qt。
更新到完全收敛,会得到每个状态下最优的动作a,这就是更新后的策略,接下来,按照这个新策略重新更新Qt,再更新Π,交替执行。
| 特性 | 动态规划 (DP) | 蒙特卡洛 (MC) |
|---|---|---|
| 是否需要模型 | ✅ 需要 | ❌ 不需要 |
| 更新时机 | 每一步都可更新(bootstrapping) | 必须等 episode 结束才更新 |
| 方差 | 低 | 高(因为依赖完整轨迹) |
| 偏差 | 无偏(如果模型准确) | 无偏(只要采样足够多) |
| 适用场景 | 小规模、已知模型 | 大规模、未知模型、真实环境 |
(对V更新)时序差分法
从上表看出,蒙特卡洛是基于随机采样更新策略的,这样的方差很大,也很耗时间。
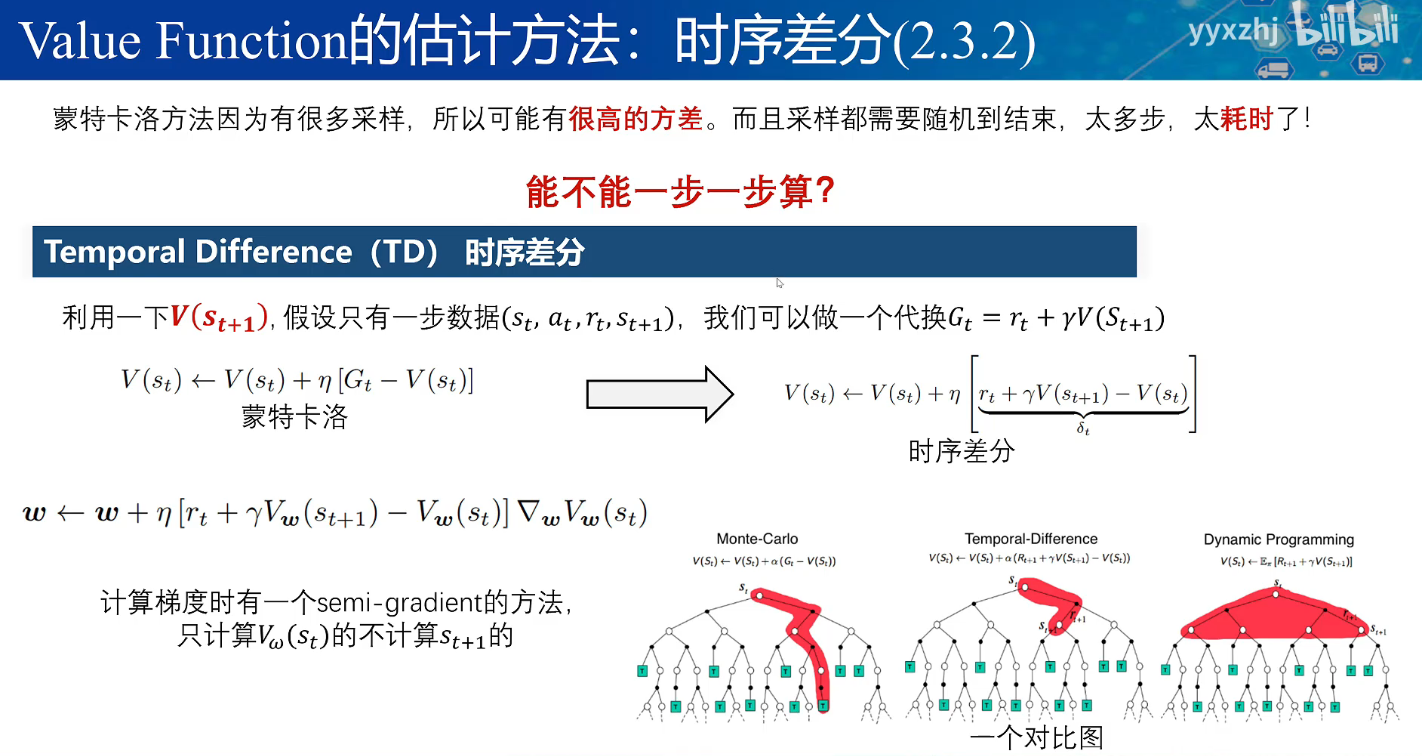
为此,我们可以将Gt截止到下一步就更新,这样的更新就更加稳定,也更快。
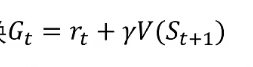
这是一个交叉更新的过程,一开始VQ都是0,然后让模型随机探索地图,每次到达st开始记录从这里到结束的实际值Gt,然后用Gt-Qt乘以更新步长η去更新在st的估计值Qt。
更新一段时间后,会得到每个状态下较优的动作a(不用等收敛,否则太久了),这就是更新后的策略,接下来,按照这个新策略重新更新Qt,再更新Π,交替执行。
总结一下,
对于蒙特卡洛,是要走到终点才更新策略,时序差分是走一步就更新策略,而动态规划需要遍历所有的状态,得知准确的状态转移情况才能执行。
更普遍的,可以选择前n步使用蒙特卡洛(真实估计),后面到终止状态使用时序差分,每次更新一步。
| 项 | 含义 | 来源 |
|---|---|---|
rt,rt+1,...,rt+n−1 |
从 t 到 t+n-1 的实际获得的奖励 | 👉 蒙特卡洛风格 —— 依赖真实环境反馈 |
| γnV(st+n) | 对未来从 t+n 开始的回报的估计值 | 👉 TD 风格 —— 用当前学到的 V 函数“猜”剩下的部分 |

(对Q更新)SARSA法
前面对V的更新方法很优秀,但是
🅰️ 如果你只更新 V(s) :【只存储了状态】
- 你知道什么:你知道站在某个位置 s 大概能得多少分。
- 你不知道什么:你不知道具体往哪个方向走能拿到这个分。
- 例如:你知道站在“悬崖边”分值很低(危险),但你不知道是“向左跳”安全还是“向右跳”安全,除非你有环境模型。
- 如何决策(选动作):
- 必须依赖模型:你需要知道 p(s′∣s,a) 和 R(s,a) ,然后做一个一步前瞻计算:
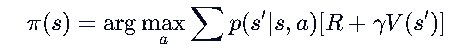
🅱️ 如果你更新 Q(s,a) :【Q是状态-动作价值,存储了当前状态对应的最优动作,可以直接得到】
- 你知道什么:你直接知道在状态 s 下,做动作 a1,a2,a3... 分别能得多少分。
- 如何决策(选动作):
- 不需要模型! 直接查表取最大值:
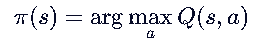
在Q领域,对应时序差分的方法是SARSA

⚠️ 注意:这里有个隐含前提 —— 要保证探索(exploration),否则可能陷入局部最优。比如可以用 ε-greedy 策略。
举个例子:

假设你用的是 ε-greedy 策略(这是最常用的):
- 以概率 1−ϵ :选择当前 Q 值最大的动作 → 即 “上”
- 以概率 ϵ :随机选择一个动作(左、右、上、下等概率)
| 情况 | 概率 | ||
|---|---|---|---|
| 贪婪选择 | 1−ϵ | 上 | 2.3 |
| 随机探索 | ϵ/4 | 左 | 0.5 |
| 随机探索 | ϵ/4 | 右 | -1.0 |
| 随机探索 | ϵ/4 | 下 | 0.1 |
(对Q更新)Q-LEARNING法 贪婪
SARSA有个弊端,就是每次选择动作时,只能选当前策略下的Q,不能用以前的Q。这就导致了可能以前的Q比现在的价值高,但受限于策略,不能使用。这时候就需要Q-LEARNING了,这个策略的更新公式是:
![]()
![]()
用上一题的例子:

你不需要“知道”未来的最优动作 Q 是多少。
你只需要:
- 查当前的 Q 表。
- 取最大值。
- 假设那就是最优的。
- 更新。
- 重复无数次。
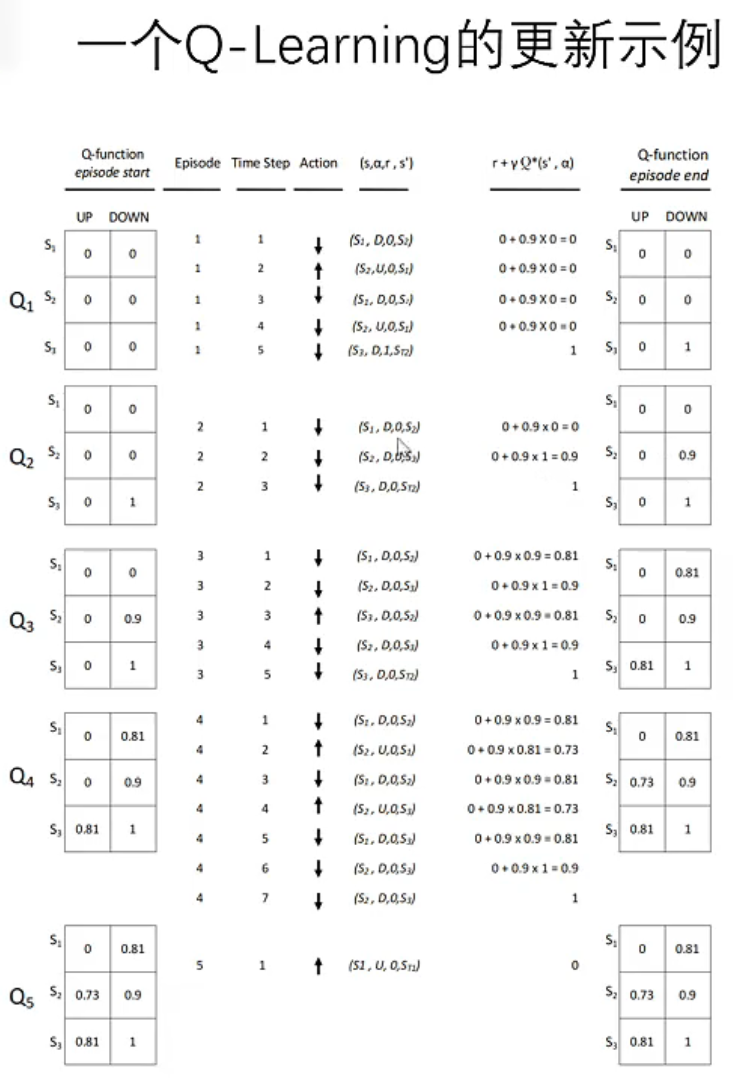
| 维度 | 蒙特卡洛 (MC) | 时序差分 (TD) -> SARSA | 时序差分 (TD) -> Q-Learning |
|---|---|---|---|
| 更新对象 | V 或 Q | 专门用于 Q (也有 V 的变体但少见) | 专门用于 Q |
| 目标值构成 | 真实全程回报 Gt |
r+γQ(s′,实际动作) | r+γmaxaQ(s′,a) |
| 策略类型 | On-Policy (通常) | On-Policy (评估的就是当前行为策略) | Off-Policy (评估的是最优策略,行为可以是随机的) |
| 对待探索 | 包含在采样中 | 谨慎:知道你会乱动,所以避开风险 | 乐观:假设你以后不乱动了,直取最优 |
| 典型场景 | 棋盘游戏(局短) | 机器人控制(需安全) | 游戏 AI(追求高分,可重试) |
总结:【策略】-【问题】-【新策略】
首先介绍了强化学习的基本概念,智能体的 当前状态、动作、策略、状态转移函数,以及强化学习的目的。
接着介绍了奖励函数Gt的设定和折扣因子
然后开始讲 状态价值函数V(当前状态价值) 状态行动价值Q(做了这个动作后的价值) 最优函数 贝尔曼迭代方程(最优QV迭代)
【DP】开始讲MDP马尔可夫决策过程,如何基于已知的环境迭代出最优的策略
【MC】但对于环境未知且会变化的情况,就需要蒙特卡洛采样法了,这是一种【从st试到重点求Gt的方案】,每次到终点了更新一次策略
【TD】但到每次到终点太久了,因此考虑每走一步迭代一次,这就是时序差分方法
【MIX】还有一种混合算法,前n步使用蒙特卡洛,后续Gt使用时序差分
【SARSA】上面都是基于V的优化,V的参数不含动作,因此无法得到当前状态下应该如何做,这就需要SARSA了,一种基于Q的更新方式,他的更新逻辑和时序差分一致,但是需要ε-贪心策略保证一定的随机性,我们举了个例子。
【QLEARNING】但sarsa只能选择当前策略下的动作Q,而不是直接找最大预估值Q,这就需要QLEARNING算法了,尽管这个Q是预估的,不准确的,但是会在更新后趋于稳定。
基于策略梯度的算法
先混个眼熟,学完你就知道这个公式的优美之处了:

基于Q的学习存在几个问题:
很难映射到连续动作空间
有可能发散
学习Q与预期收益无关系 等
那我们能否直接学习策略Π呢?
Policy Gradient 是强化学习中从“价值驱动”转向“策略驱动”的关键转折点

整体目标:我们想直接优化策略 π(a|s)
每个策略都有一组权重参数控制,其实最简单的线性回归也是一种策略,其中的参数就是矩阵[a,b],斜率和偏移。
这里也一样,我们把这组控制策略的参数整体命名为θ,那么我们的优化目标实际上就是找到一个(一组参数)θ使得该策略能在任何状态下都能拿到最高分。
这就是这个式子:![]() =》
=》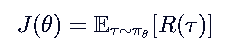
意思是:“用当前策略 π_θ 去跑很多条轨迹 τ,算平均总奖励 R(τ),我们希望这个平均值越大越好。”
怎么优化 J(θ)?→ 用梯度上升!
我们把θ当作一个变量看待,这样就可以类比二次函数找极值点的问题,只需要求出导数,不断迭代即可。在矩阵中,也有对应的导数,雅可比或黑塞(二阶导)。我们不考虑这么多,就按照普通参数来考虑。
既然要最大化 J(θ),那就求梯度 ∇_θ J(θ),然后往梯度方向更新 θ:
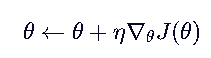
这个和梯度下降有区别,梯度下降是为了找到误差最小的点,因此是减号,我们的优化目标是使得“在多条轨迹下,这个θ主导的策略能获得最多的累计奖励”,因此优化方向是加号。
如何求导?
问题来了,
J(θ) 是个期望,没法直接求导!
于是开始了一系列“魔法操作”——其实都是为了把这个期望梯度变成可以采样的形式。


问题:上面的公式方差太大!
因为 R(τ) 是整个轨迹的总回报,它包含了很多噪声。比如某次运气好得了高分,不代表某个动作真的好。
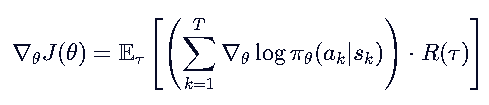
✅ 解决方案1:用 未来回报Gk 替代 全程回报Rt
定义:
![]()
→ 从时刻 k 开始的未来折现回报
于是公式变成: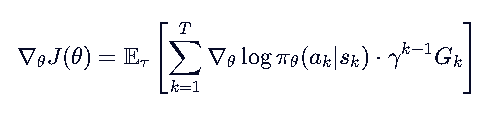
R(τ) 是整条轨迹的总回报,而 Gt 是“从时刻 t 开始”的未来回报。使用 Gt 后, t 时刻的动作只由它产生的后果(未来奖励)来评估,去除了过去无关奖励的干扰,显著降低了方差。(直观理解:你现在的决策无法改变历史,所以历史奖励对你的梯度更新没有指导意义,只会增加噪声。)
R(τ) 包含了所有时刻的奖励。如果你在 t=1 做了一个好动作,但在 t=50 因为运气不好得了低分,整个 R(τ) 都会很低。这会导致 t=1 的好动作也被“惩罚”,梯度方向变得混乱,训练极不稳定。
✅ 解决方案2:引入 Baseline(基线)[优势函数的CALLBACK]
虽然用了 Gk ,但方差仍然可能很大(比如某些状态本身就好/坏,导致所有动作的 Gk 都高/低)。
基线是什么:比如数据如下,如果以0为基线,那么计算的方差老大了,如果我们使用均值V(S)作为基线,方差一下就降下来了。
我们引入一个只依赖于状态 sk 的基线函数 b(sk) ,并减去它,只要 b(sk) 不依赖于动作 ak ,就不会改变梯度的期望!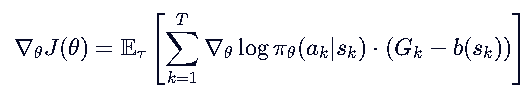
这是证明:
这个b(sk)选谁呢?
常用选择: b(sk)=V(sk) —— 状态价值函数‘
现在我们有: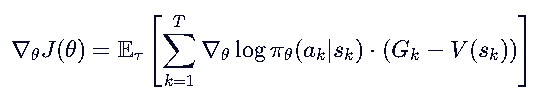
注意!!!
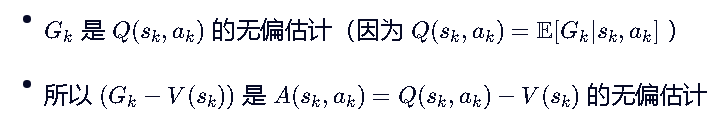
所以我们也可以写成:
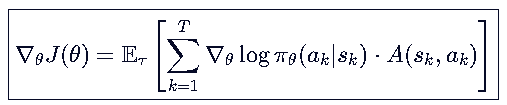
优势函数是衡量当前动作相对于平均表现的好坏的,当做的更好,A(s,a)>0,就更新θ权重矩阵,让这个动作发生得更多。
如果忘记了优势函数的定义,这里也再次给你:

但在原书的迭代过程中会涉及一个ω的更新,这个ω是来自于。
这个也很好理解,我们看到之前这张图,当Π(θ)改变后,状态价值V(s)必然改变,因此也需要更新,而ω就是控制的参数。也就是说,这是一个教学相长的过程,θ和ω交替更新!
你是不是想到了什么?这就是Actor-Critic模型的雏形。其中,Actor是PolicyModel,Critic是ValueModel(baseline就是基准)。
| 步骤 | 公式 | 特点 | 算法名称 |
|---|---|---|---|
| 1️⃣ 原始 | 高方差,包含历史噪声 | — | |
| 2️⃣ 因果优化 | 去掉历史,仍高方差 | REINFORCE | |
| 3️⃣ 引入 Baseline | 降方差,无偏 | REINFORCE with Baseline | |
| 4️⃣ 优势函数 | 最低方差(理想),相对评估 | Actor-Critic, PPO, A3C |
另一种表达形式
前面使用的是轨迹采样,有时候我们需要类似(s,a)的采样,本身轨迹就是一系列sa的序列,很好代换。
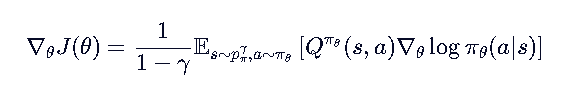
其中:
- ρ_π^γ(s):折扣状态下访问状态 s 的期望次数
- p_π^t(s₀ → s, t):从 s₀ 出发走 t 步到 s 的概率
整理捋一遍
将对Q的优化转为对策略派的优化,优化策略就是优化权重矩阵θ,目标是使得当前策略在多条轨迹下,这个θ主导的策略能获得最多的累计奖励”,方案是梯度上升,但是由于期望没有梯度,我们巧妙转换了这个公式。
但是用这个梯度公式更新,方差很大,于是我们考虑用未来回报Gt代替全程奖励Rt,防止前期奖励扩大方差。
但方差还是很大,于是我们考虑更改基线,引入基线函数,进而推导出优势函数下的梯度公式。
这个公式的直观理解也很清晰:
优势函数是衡量当前动作相对于平均表现的好坏的,当做的更好,A(s,a)>0,就更新θ权重矩阵,让这个动作发生得更多。
最后,我们补充了一个教学相长的更新模式,也就是AC模型的前身。
A2C模型
我们刚才推导的 REINFORCE with Baseline中,ω控制的V价值模型采用蒙特卡洛的更新方式,如果 ω 是通过 时序差分误差 (TD Error) 来更新的,那么它在数学结构上就已经 等价于 Actor-Critic 算法 了。
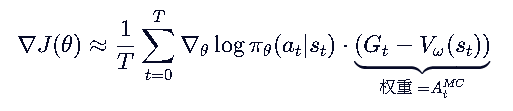
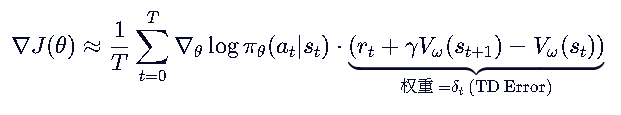


GAE的优化
但又有新问题了,
- MC 方法(如 REINFORCE):无偏但高方差
- TD 方法(如 A2C):低方差但有偏
→ 我们想要一个既不太偏、也低方差的优势估计!
GAE 的核心思想:
通过引入参数 λ ,对 任意步数的估计优势 按照合理的置信度加和,作为奖励项。
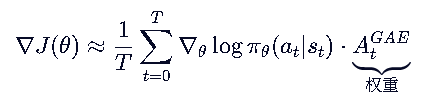

指的是 【前n步使用TD,后用MC】 的情况下的优势估计
当n=1时,就是单步的时序差分TD,可信度极高,极其稳定,但偏差极大
当n->∞时,就是蒙特卡洛MC,可信度较低,极其不稳定,但偏差极低
为了无论多少步,都能适用这个公式,我们构建一个 奖励估计和,把所有的步数的情况考虑进来
这个肯定不准,因为他把置信度低的 和 置信度高的优势估计加一起了,因此我们需要根据置信度为这个奖励估计和设计折扣因子:
展开看的清楚:
![]()
前面这个λ就是我们引入的折扣因子。
当 λ=0 ,这个奖励估计和就退化为 AC模型(单步 TD),只剩下步长为1时的奖励了。
当 λ=1 ,退化为 REINFORCE (MC),只剩下趋于无穷的蒙特卡洛奖励了。
一般地,我们选择 λ≈0.95 ,它在保持低方差的同时极大地减少了偏差,成为 PPO、TRPO、SAC 等现代 SOTA 算法的标准配置。
GAE通过λ构建了一个收敛的级数和,每一项是不同步长的优势估计(内部用γ确定折扣因子,综合了前i步为TD,后面为MC的情况)。他不依赖n,直接从1加到无穷,但是由于其是收敛的,一定可以得到一个值,作为最终的奖励权重。
大总结
所有的策略梯度算法都在更新两个模型——θ控制的策略模型,和ω控制的价值模型。
基于前文,我们知道传统的V模型有单步更新的时序差分TD模型,和走完更新的蒙特卡洛MC模型
而Π策略模型有【未来回报Gk 替代 全程回报Rt】和【基线模型】两种。
那么对于Reinforce With BaseLine而言,采用基线模型和蒙特卡洛方案
但太慢了
于是将对ω的更新改为单步的时序差分模型,这就是Actor-Critic模型
但这样偏差太大了,于是考虑综合偏差和方差的优势,
提出了GAE
GAE不管前n步是什么,直接将所有可能的步数加在一起,成为一坨奖励估计和,然后添加一个置信度因子λ,当λ趋于0,就是TD,趋于1就是MC,一般用0.95。这种情况下,求和后是一个收敛的级数,一定是个合适的奖励值。
策略梯度 (Policy Gradient)
│
├── REINFORCE (Monte Carlo Policy Gradient)
│ └── 无 baseline → 高方差
│
├── REINFORCE with Baseline
│ ├── Baseline = 常数 → 降一点方差
│ └── Baseline = V_w(s) → 显著降方差,但仍需 MC 更新 V_w
│
└── Actor-Critic Methods
├── A2C (Advantage Actor-Critic)
│ └── 用 TD error δ_t 作为优势 → 单步更新,低方差
│
└── A3C / PPO / TRPO 等
└── 使用 GAE 作为优势估计 → 平衡偏差与方差再总而言之,
所有基于策略梯度的方法(REINFORCE, Actor-Critic, PPO, TRPO, SAC...)都共享同一个数学本质:
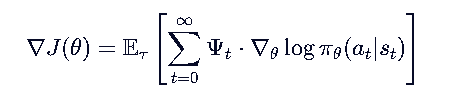

不同的算法,区别仅在于 的定义方式!
| 方法 | 特点 | 偏差/方差 | 是否需回合结束 | |
|---|---|---|---|---|
| REINFORCE (MC) | 蒙特卡洛,无偏但高方差 | 高方差,无偏 | 需要 | |
| MC with Baseline | 减去基线降低方差 | 方差↓,仍无偏 | 需要 | |
| Advantage Function | 理论最优,但 Q 难估计 | 理论上最佳 | 不一定 | |
| TD Residual (1-step AC) | 单步,低方差 | 有偏,方差极低 | 不需要 | |
| ✅ GAE (Generalized Advantage Estimation) | 多步 TD 误差加权平均,平衡偏差与方差 | 偏差-方差trade-off最优 | 不需要 |
REINFORCE (MC)
MC with Baseline
Advantage Function
TD Residual (1-step AC)
GAE
这一族统称为策略模型
你可以认为这已经非常完美了,我们已经找到一个让更新又稳又准还很快的方法,但实际上还差得远!
TRPO
现在有个问题,前面的优化函数出问题了:
![]()
![]()
别忘这个式子:
意思是:“用当前策略 π_θ 去跑很多条轨迹 τ,算平均总奖励 R(τ),我们希望这个平均值越大越好。”
1. 致命伤:数据不够用(无法采样)
- J(θ) 的定义:是在新策略 πθ 下,智能体去环境里跑出来的平均回报。
- 现实情况:
- 你现在手里只有旧策略 θk 采集到的一批数据(轨迹)。
- 如果你要计算 J(θ) (其中 θ≠θk ),你就必须让智能体穿上新策略 θ 的衣服,重新去环境里跑一遍,收集新数据。
- 后果:每一步都要尝试一个新的 θ 。每试一个 θ 都要去环境里跑几千步收集数据,那训练成本是天文数字!
2. 次要伤:梯度难算
- 即使你有无限算力去采样, J(θ)对 θ 的梯度本身就需要通过采样来估计。
- 加上复杂的 KL 约束后,求解这个带约束的非线性优化问题会变得异常困难,因为目标函数 J 和约束函数 KL 都是黑盒(需要通过采样估算),没有解析形式。
因为我们要考虑,如何找一个近似J(θ)的优化函数,使其能利用旧策略数据而不探索新策略来优化,且计算量小。
我们知道![]()
那么新旧策略的差距就是(在GAE下)![]()
关键转换:期望代换 将策略差距换成旧数据能算的形式
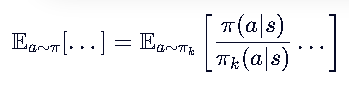
我们定义优化代理目标 L(θ,θk)
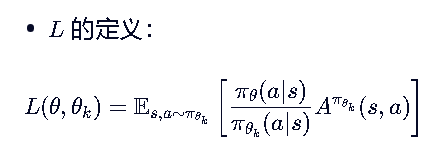
- 妙处:注意期望符号下面的采样分布是 πθk (旧策略)!
- 这意味着什么?
- 把“在新策略下采样”强行变成了“在旧策略下采样”
- 不需要让智能体去环境里跑新数据。只需要把旧数据里的动作概率 πθk 和新策略的概率 πθ 做个比值加权,就能“假装”这是新策略的数据。
这步期望的更换是有代价的,以损失一定的误差为代价:
原因:旧策略 πk 可能经常去状态 A,新策略 π 可能经常去状态 B。
我们在旧数据(状态 A 多)上算出来的 L ,不能完全代表新策略在真实环境(状态 B 多)下的表现。
我们需要补一个误差项:
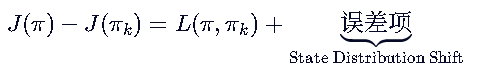
给出承诺:误差是可以控制的
![]()
这是全篇最重要的结论!
- 作者证明了这个“误差项”的大小,和新旧策略的差异程度(TV 距离)成正比。
- C 是一个常数(跟优势函数的最大值有关)。
- TV 是策略差异。(理解为KL散度一样可以,他们都是衡量概率分布差异的工具)
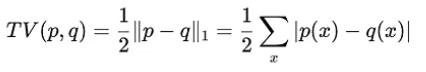
那么:“真实回报 J 等于 代理目标 L 减去 一个风险惩罚。”
“如果你让新策略和旧策略别差太多(TV 很小),那么风险惩罚就很小。”
“只要 L 提升得足够多,且 TV 足够小,那么 J 一定会提升!”
我们的目标就是最大化L的同时约束住TV别太大!
那我们就可以引出核心的优化公式:

通过Pinsker 不等式![]() ,我们可以证明,工程上 KL 更好算且等价于TV。
,我们可以证明,工程上 KL 更好算且等价于TV。
局部近似
上面这个式子![]() 是一个非线性优化问题。
是一个非线性优化问题。![]() 是一个复杂的函数,直接求解非常困难,尤其是在高维参数空间中。
是一个复杂的函数,直接求解非常困难,尤其是在高维参数空间中。
为了解决这个问题,TRPO 采用了“局部近似”的策略:
我们只关心 πk 附近的一个小区域内(信任区域)的策略更新。在这个小区域内,我们可以用一阶泰勒展开来近似 ![]() 。
。
但是,最大化 会导致 δ 趋向于无穷大(因为这是一个线性函数,没有上界),这会直接崩溃。因此我们对δ做了约束(在局部近似后,原先对TV的约束改为对δ的约束)。然而,这仍然会引发策略崩溃。
策略崩溃 Policy Collapse【δ与Π不对应,对δ约束不足,需要用KL散度约束】
前面我们用GAE解决了方差 vs 偏差的问题
(如何更准地估计“这个动作好不好”)
仅靠 GAE + SGD 会发生什么?

或者,你理解为,在st状态,你突然给你喜欢的女生一个吻,那好感动就会增加很多,于是你认为所有女生都可以这样攻略,于是到大街上找到人就上去嘬一口,这种偶然获得的高奖励会很大程度带偏你的谈恋爱策略,如果没有朋友警告你“下次不能这样了”,那么每次到这个状态st,你必定选择亲吻女生,那后面的更新一定是恶性循环。
而问题就出在这一步:
![]()
它隐含了一个假设:只要参数变化量 δ 很小,那么策略分布 和
的变化也很小,网络就不会崩溃。这个对δ的约束就是你的朋友,然而他不够强势。
在深度神经网络中,参数空间δ和分布空间Π的关系是极度非线性且各向异性的。
👉 崩溃的原因:
当你用普通 SGD 时,你以为自己只迈了一小步(参数变化小),但实际上在分布空间里,你已经狂奔了一公里(分布剧变)。
这个朋友约束不了你,你需要一个更严厉的约束!
那么既然单独约束δ不行,能否通过直接约束策略Π解决呢?
KL散度——计算分布之间的误差(策略网络最严厉的父亲)
这个约束就是KL散度约束,它限制了新策略 π 和旧策略 πk 之间的差异不能太大。
请注意,我们约束的对象仍然是θ,只是更改了约束条件,因为只有θ能够被更新。
KL散度![]() 也是一个非线性函数。同样地,我们在 πk 附近对它进行二阶泰勒展开,得到:
也是一个非线性函数。同样地,我们在 πk 附近对它进行二阶泰勒展开,得到:
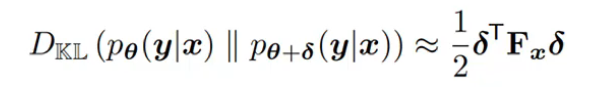

其中,Fx是Fisher信息矩阵,它实际上就是KL散度的二阶导数(Hessian矩阵)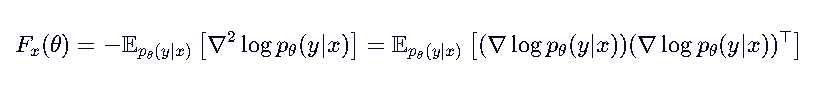
- 左边:负的对数似然的 Hessian 矩阵的期望 → 衡量“曲率”,即分布对参数变化的敏感度。
- 右边:得分函数(score function) ∇logpθ 的外积的期望 → 更常用,因为它只需要一阶导数,且可以通过蒙特卡洛采样估计。
因此,原来的约束 就近似等价于
。为了简化,我们可以把 1/2 吸收到 ϵ 中,得到
。
现在,我们把目标函数和约束都近似好了:
目标函数:最大化
约束条件:
我们可以将问题重写为:
至此,我们成功将之前 对δ的约束 转为了对策略分布的约束!
我们约束的目标
好,我们现在有一个带约束的优化目标:我们要通过解这个约束方程,得到θ()
我们面临两个巨大挑战:
⚠️ 挑战 1:F_k 是巨大的矩阵
- 如果神经网络有百万级参数,F_k 就是 10⁶ × 10⁶ 的矩阵。
- 存储它?不可能。
- 求逆它?O(n³) 复杂度,计算不可行。
⚠️ 挑战 2:我们不需要精确解,只需要一个“足够好”的方向
- 在 RL 中,数据 noisy、环境非平稳,追求全局最优无意义。
- 我们只希望每一步都“安全地往好处走”,而不是“完美地走到终点”。
→ 所以,我们不直接求解 δ = argmax ...,而是设计一个迭代算法,在每次迭代中逐步逼近这个最优方向。
最终经过一通计算,得到这个迭代式: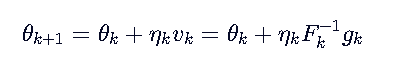
【具体如何从得到上面这个迭代式的过程放在最后面,初学者没必要在这里搞懂】
ηk是学习率。但是后面这一坨就很恶心了。Fk是一个很大的矩阵,求逆对于计算机太复杂了O(n^3)。我们考虑做个代换:
令:
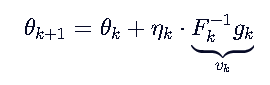
按理来说,求解v_k还是需要求F_k逆和g_k,但这是对于解析解来说的(准确的值)。
但换一个角度,我们可以迭代无数次v,使得v越来越接近满足这个等式:F⋅v=g,这就是数值解(越来越接近准确的值)
这个方法叫做:共轭梯度法(Conjugate Gradient, CG)。通过迭代(通常只需 10-20 次)来逼近解的,而且收敛速度非常快。
CG算法要求输入一个能计算Fx的函数,他会自动迭代出x的值。
难点就是如何写一个不依赖F,却能计算Fx的函数!
核心就是四个字——“维度坍缩”!

一般计算Fx我们想到的都是Xx,这样的运算量太大了。
但是如果我们先运算,就会完全不一样,其输出就是一个标量!
然后再用这个标量 ,这样就还原为了向量,也就是Fx的值!
| 步骤 | 操作 | 输入维度 | 输出维度 | 内存占用 |
|---|---|---|---|---|
| 错误做法 | [M]×[M] | [M,M] (矩阵) | 4 TB (爆显存/内存) ❌ | |
| 正确做法 1 | [M]×[M] | [1] (标量) | 8 Bytes (极小) ✅ | |
| 正确做法 2 | 标量 |
[1]×[M] | [M] (向量) | 4 MB (很小) ✅ |

那这个向量如何计算呢?未来的所有数据我们是无法遍历的。但我们可以用样本均值代替期望,概率论应该学过。

我们只要把这个结果传给CG函数,就能迭代解出一个v。
有了v我们就能更新θ了!!!
这个方法就叫TRPO!
从策略更新到TRPO
【减小方差和偏差】
策略更新使用J(θ)作为优化函数,意思是:“用当前策略 π_θ 去跑很多条轨迹 τ,算平均总奖励 R(τ),我们希望这个平均值越大越好。”
优化策略网络最重要的就是找一个稳定的奖励估计函数,方差和偏差都要小。
前面的【回报截断】【基线模型】【A2C】我们都在减小方差和偏差,
到GAE,我们完成的是引入λ,使得估计方差和偏差变小。
【优化优化函数】
但基于J(θ)的更新具有难采样的问题,我们打算用另一个优化函数优化θ,也就是L(θ,θ_k)。他近似J(θ)但具有计算量小,且只需要旧数据预测的能力。
我们的引入过程是注意到期望代换,但是要补偿期望代换,因此引入误差项,接着证明误差是可控的,与TV/KL成正比。进而将优化目标转为,增大L(θ,θ_k)的情况下约束住TV。
L(θ,θ_k)是非线性的,我们考虑用局部近似泰勒展开,问题转为最大化 ,但会导致 δ 趋向于无穷大。于是为δ加约束,但是还是发生策略崩溃。
【加强约束】
原因SGD对δ约束不足(δ和Π非一一对应),容易策略崩溃,因此引入更强的约束KL散度
为了转换约束,我们采用CG算法得到FIM,从而允许更新θ。为了给CG算法一个解Fx的函数,我们使用维度坍缩,也就是交换律解决。
PPO——用TV等效ρk约束步长,保证可微可SGD
TRPO很复杂是吧,PPO的优化就简单多了。【无需计算TV约束,可用SGD梯度下降】
我们先看到TRPO的优化公式:
你会发现难点有两个,一个是无法直接更新非线性的L(θ,θ_k),必须局部近似做一坨代换。此外,最后这个恶心的约束条件逼迫TRPO必须进行CG算法解决Fx的问题。
有没有能简化这种约束,且能直接使用SGD的优化方式的优化函数呢?
我们注意到: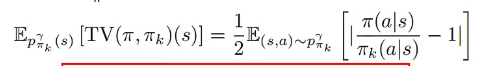
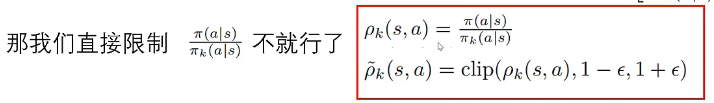

这是他的优化目标公式:
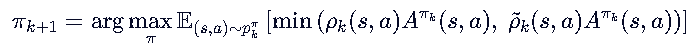
可以理解为ρk是“新旧策略在某个状态-动作对上的概率比值”。它反映的是“新策略相对于旧策略,有多倾向于选择某个动作”。你干脆理解为更新的步长。
我们限制TV的根本原因就是为了限制更新步长别太大,因此我们可以直接把之前对TV的约束改为对ρ的约束。通过clip函数,当ρ在合适的区间[1±ε]时正常使用ρXA(A是优势函数,意味着往哪个方向优化),超过安全区后就截断,以最大或最小值ρXA输出,从而实现步长的约束。
举个例子:![]()


更巧妙的是,这个优化目标函数可微,意味着完全可以通过SGD更新,不需要像TRPO一样用局部近似。![]()
TRPO 要求解一个带约束的优化问题,而这个约束是非线性的,所以需要用二阶泰勒展开近似 KL 散度,把问题变成一个二次规划问题。
而 PPO 不需要这样做,因为:
PPO 的目标函数已经是“可微的”: min 函数和 clip 函数虽然在边界处不可导,但在实际实现中,我们可以通过自动微分(Autograd)处理,或者用平滑的近似。
总结:用“截断 + min”代替“约束 + 二阶优化”,从而在保持稳定性的同时,大幅降低计算复杂度。
从策略更新到PPO
【减小方差和偏差】
策略更新使用J(θ)作为优化函数,意思是:“用当前策略 π_θ 去跑很多条轨迹 τ,算平均总奖励 R(τ),我们希望这个平均值越大越好。”
优化策略网络最重要的就是找一个稳定的奖励估计函数,方差和偏差都要小。
前面的【回报截断】【基线模型】【A2C】我们都在减小方差和偏差,
到GAE,我们完成的是引入λ,使得估计方差和偏差变小。
【优化优化函数】
但基于J(θ)的更新具有难采样的问题,我们打算用另一个优化函数优化θ,也就是L(θ,θ_k)。他近似J(θ)但具有计算量小,且只需要旧数据预测的能力。
我们的引入过程是注意到期望代换,但是要补偿期望代换,因此引入误差项,接着证明误差是可控的,与TV/KL成正比。进而将优化目标转为,增大L(θ,θ_k)的情况下约束住TV。
L(θ,θ_k)是非线性的,我们考虑用局部近似泰勒展开,问题转为最大化 ,但会导致 δ 趋向于无穷大。于是为δ加约束,但是还是发生策略崩溃。
【加强约束】
原因SGD对δ约束不足(δ和Π非一一对应),容易策略崩溃,因此引入更强的约束KL散度
为了转换约束,我们采用CG算法得到FIM,从而允许更新θ。为了给CG算法一个解Fx的函数,我们使用维度坍缩,也就是交换律解决。
【简化TV约束、实现SGD】
TRPO太麻烦了,PPO直接将对TV的约束等价为对ρk的约束,采用“clip截断+min函数”将约束条件内化到优化函数中,这样就避免了二阶优化,同时实现了可微,允许用SGD优化。
大语言模型(LLM)的强化学习
一、核心定义:状态(s)、动作(a)、奖励(R)
对于LLM而言,需要对应RL的三个重要概念:状态(s)、动作(a)、奖励(R)
1. 状态(s):输入的Prompt,比如“写一首关于春天的诗”。
2. 动作(a):输出的Token序列,动作 a 是模型生成的Token序列,比如“春天来了,万物复苏,花开满园。”
3. 奖励(R):衡量动作质量的函数,奖励 R(s,a) 只在序列结束时计算,比如生成完“春天来了,万物复苏,花开满园。”后,才给这个完整的回答打分。
二、优化目标:最大化期望奖励
1. 基本优化目标
目标:最大化生成的句子的期望奖励。
![]()

2. 基于next-token prediction的乘法原理分解
【生成这个句子 a 的可能性】
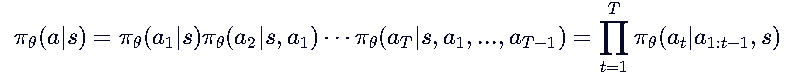
三、状态转移函数:从 st−1 到 stst
1. 状态转移函数的定义
【选下一个词的概率】(0或1)
在已生成的Token序列 (比如“春天来了,万物复苏”)下,生成下一个Token
(比如“花开”)后,新的Token序列
(比如“春天来了,万物复苏,花开”)的概率一定是1或0。
在LLM中,状态转移函数是确定的:
公式:
四、奖励函数的特殊设计:只在序列结束时计算
【当前步骤的奖励】
1. 奖励函数的定义
定义:在LLM中,奖励函数 R(st,at) 通常只在序列结束时计算,
当 t<T 时,生成还未结束,奖励为0。
当 t=T 且 时,生成结束,计算整个序列的奖励 R(s,a1,...,aT)。
公式: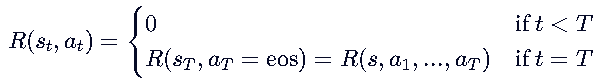 '
'
五、优化目标的重新定义
重新定义:结合状态转移函数,优化目标可以重新定义为:
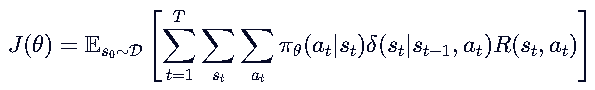
![]() ——【生成这个句子 a 的可能性】
——【生成这个句子 a 的可能性】![]() ——【选下一个词的概率】
——【选下一个词的概率】![]() ——【当前步骤的奖励】
——【当前步骤的奖励】![]() ——【对每个Token求和】
——【对每个Token求和】![]() ——【对所有可能的状态和动作求和】
——【对所有可能的状态和动作求和】
直观含义是:求和所有可能生成的句子的每一个token,每个token的选取概率是【生成这个句子 a 的可能性】*【选下一个词的概率】*【当前步骤的奖励】,因此套三层求和。
六、KL散度约束:防止策略偏离过大
1. KL散度约束的作用
作用:KL散度约束是为了防止策略 πθ 偏离参考策略 πref 过大,从而保证生成的文本不会“跑偏”。
公式:![]()

七、总结:RL for LLM的核心流程
- 输入Prompt:用户输入Prompt s ,作为状态 s0 。
- 生成动作:模型根据策略 πθ(at∣st) ,自回归生成Token序列 a=[a1,a2,...,aT] 。
- 计算奖励:当生成结束( aT=eos )时,计算整个序列的奖励 R(s,a) 。
- 优化目标:最大化期望奖励 J(θ) ,同时通过KL散度约束防止策略偏离过大。
- 更新策略:根据奖励和KL散度,更新策略 πθ ,使其生成更高质量的文本。
我们核心讨论的点就在于如何最大化奖励J(θ)。
GRPO——Clip机制+相对优势
GRPO的核心动机:为什么要“去价值网络”?
前面的TRPO和PPO都是更新双模型的,一个策略模型,一个价值估计模型(隐藏在GAE的优势估计中),每次更新完策略模型后,都需要同步更新价值估计模型。
在标准PPO中,计算优势函数 A(s,a) 需要一个价值网络 V(s) 来做基线(Baseline),这带来了两个问题:
- 双倍参数开销:需要同时训练策略网络(Policy)和价值网络(Value),内存和计算成本高。
- 训练不稳定:价值网络拟合不准会直接影响策略更新的方向。
GRPO的解决思路:
既然我们最终的目标是让模型生成“奖励更高”的文本,为什么不直接用同一组输入(Prompt)下,不同输出(Token序列)之间的相对奖励差异来代替复杂的 A(s,a) 计算呢?
这就是GRPO的“Group Relative”思想:在同一组Prompt下,让表现好的Token序列“拉高”表现差的Token序列的梯度,而不是去拟合一个全局的 V(s) 。
直观而言:
GRPO的目标不是让学生“考满分”,而是让学生“比班里平均水平考得好”。
对于每个Token,如果它出现在“高分学生”的序列里,它就会得到正向激励;如果它出现在“低分学生”的序列里,它就会被惩罚。
从PPO到GRPO
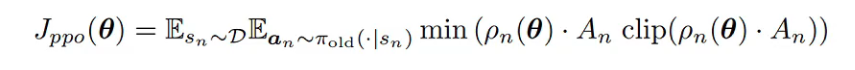
其中:
如果LLM使用PPO训练,就需要持续更新bn这个基线函数,时间空间开销都是两倍,我们考虑用蒙特卡洛采样直接估计A。
GRPO具体过程:【前面提到的RL for LLM核心流程】


轨迹奖励函数 R(s,a) 是固定的,不参与训练更新。
在 LLM 中,生成是自回归的,每个 token 依赖于前面的 token。所以 ρ 需要基于当前 token 的条件概率,而不是整个序列的概率。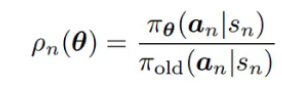 =》
=》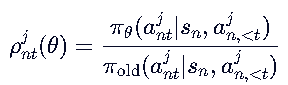

对比前面LLM的优化函数,能发现不少区别,我们解释一下:+KL约束
首先,KL约束之前我们讲PPO就说过了,将其用“CLIP截断+min”解决了。
其次,为什么 GRPO 的优化函数有 1/N 和 1/J ?
因为 GRPO 的优化目标是一个期望(Expectation)的蒙特卡洛估计
1. 1/N:对 Prompt 的期望进行估计
理论上的优化目标:我们希望优化模型在所有可能的 Prompt 上的表现。但我们只能通过蒙特卡洛采样实现,因此用这 N 个 Prompt 的平均值来近似整个期望。
2. 1/J :对回答的期望进行估计
理论上的优化目标:对于每一个 Prompt sn ,我们希望优化模型在所有可能的回答上的表现。用这 J 个回答的平均值来近似这个期望。
至于括号内的不同,则是工程实践上的差异,原本的LLM使用的其实是在追求绝对的“好”,而GRPO是追求相对的“好”,这种指导方向上的差异就决定了二者肯定不一样,LLM的优化函数适合理论推导,他需要遍历所有情况,所有的prompt所有的回答,这是不可能的。而我们用的GRPO采用“CLIP截断+min”内化了KL散度约束,并通过“蒙特卡洛采样”解决了需要遍历所有情况的问题,是工程实践中的标杆!
DAPO
一、DAPO:给“剪贴板”动个手术(不对称剪贴)
1. 它是啥?
DAPO 是对 PPO 里的 Clip 函数 做了微调。
2. 背后的痛点

PPO 原来的 Clip 是对称的(比如 clip(ρ, 0.8, 1.2))。这就像给模型设了个“紧箍咒”:
- 如果模型想变好(优势是正的),它最多只能把概率提高 20%。
- 如果模型想变差(优势是负的),它最多只能把概率降低 20%。
这其实不太公平!我们更希望模型大胆地变好,而不是被限制住。
3. DAPO 怎么改的?
它把 Clip 改成了不对称的:
- 上限放宽一点(比如
1 + 0.28):鼓励模型大胆探索好的动作,让原本很少被选的优质回答能获得更高的概率。 - 下限收紧一点(比如
1 - 0.2):惩罚坏动作要狠一点。
4. 好处
防止模型陷入“熵崩塌”(Entropy Collapse)——也就是防止模型变得越来越死板,只会说那几句最保险的话,不敢创新了。
GSPO
1. 它是啥?
GSPO 是把强化学习的优化粒度从“整句话”细化到了“每一个字(Token)”。
2. 背后的痛点

传统方法(比如 PPO)是“句子级”的:
- 一句话生成完了,得到一个总分。
- 然后用这个总分去更新这句话里每一个字的生成概率。
这很不合理!比如一句话是“今天天气真好,我要去跑步”,如果总分高,难道是因为“跑步”这个词特别好?还是因为“天气”这个词特别好?传统方法把功劳平均分给了所有字,这叫信用分配不均。
3. GSPO 怎么改的?
它做了一件很暴力但有效的事:每个 Token 都算一次奖励和更新。
- 它定义了一个新的概率比
,这个比值是基于整句话的,但被应用到了每一个 Token 上。
- 优化目标
里,那个
就代表它要对这句话里的每一个 Token 都算一遍梯度。
4. 好处
- 训练更快:因为每个 Token 都在参与更新,信息利用率变高了。
- 效果更细:模型能学到具体哪个词用得好,哪个词用得不好,而不是只看整句话的结果。
| 算法 | 核心改动 | 想解决的问题 |
|---|---|---|
| DAPO | Clip 不对称(上松下紧) | 防止模型太保守,鼓励大胆探索好答案 |
| GSPO | 从“句子级”改成“Token 级” | 解决“整句奖励”导致的信用分配不均,训练更精细 |
| 维度 | PPO | GRPO |
|---|---|---|
| 优势函数计算 | ||
| 网络结构 | 双网络(策略网络 + 价值网络) | 单网络(仅策略网络) |
| 计算开销 | 高(需要训练和推理价值网络) | 低(无需价值网络) |
| 适用场景 | 通用强化学习任务 | LLM对齐(RLHF),尤其是资源受限场景 |
| 稳定性 | 依赖价值网络的拟合精度 | 依赖组内采样的多样性,稳定性稍弱但效率更高 |
所有双模型策略网络的运行过程就和GAE的原型Baseline模型一致,交替更新,教学相长
补充证明
从 到
到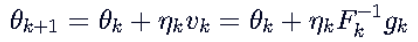







AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 38
38 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)