【IEEE TGRS (2026)】WESSP-Mamba:基于小波先验注入的 Mamba 图像超分网络深度解析

在高光谱图像(Hyperspectral Image, HSI)的处理任务中,超分辨率重建(HSI-SR)是提升遥感图像空间分辨率的重要技术 。近年来,基于状态空间模型(如 Mamba)的架构因其线性的计算复杂度,在序列建模中展现出显著优势 。然而,将 Mamba 应用于高光谱图像超分时,网络在特征提取过程中容易出现空间-光谱细节丢失的问题 。
近期,发表于遥感领域顶级期刊 IEEE TGRS (2026) 的论文《Wavelet-Enhanced Spatial-Spectral Prior Injection Mamba Network for Hyperspectral Image Super-Resolution》(WESSP-Mamba)针对这一问题提出了一种改进架构。该研究引入了离散小波变换(DWT)提取结构先验,并通过跨层注入机制指导 Mamba 主干网络的特征重建 。
本文将深入拆解 WESSP-Mamba 的底层设计逻辑,探讨其核心模块的运作机制,进行客观的评判性分析。论文目前还未开源代码,我在文末复现核心模块的代码供参考。
一、 核心动机:Mamba 在高光谱超分中的固有局限性
在 HSI-SR 任务中,现有的基于 Mamba 的模型通常面临以下两个结构性问题:
- 展平操作导致的结构信息流失: Mamba 模型在处理二维或三维图像数据时,需要将其展平为一维序列进行扫描 。在这个降维过程中,高光谱图像中原本相邻的空间-光谱物理结构(如边缘和高频纹理)容易受到破坏 。
- 因果扫描的感受野限制: 尽管许多视觉 Mamba 模型引入了多向扫描(如四向扫描),但其本质上仍依赖因果序列建模 。对于空间距离较远的像素,模型需要较长的序列扫描才能建立依赖关系,这限制了其捕捉全局空间特征的能力 。
研究思路: 为缓解上述问题,作者提出在 Mamba 主干网络之外,利用离散小波变换提取一份包含丰富细节的“空间-光谱先验(SSPrior)”。随后,在 Mamba 逐层提取深层特征的过程中,将该先验信息注入其中,以补充丢失的高频结构信息 。
二、 核心架构拆解:先验提取与跨层注入
WESSP-Mamba 的整体架构(对应论文 Fig. 1)采用了“单次提取,多次注入”的策略。网络主要分为上方的先验提取支路和下方的 Mamba 深层特征提取主干 。
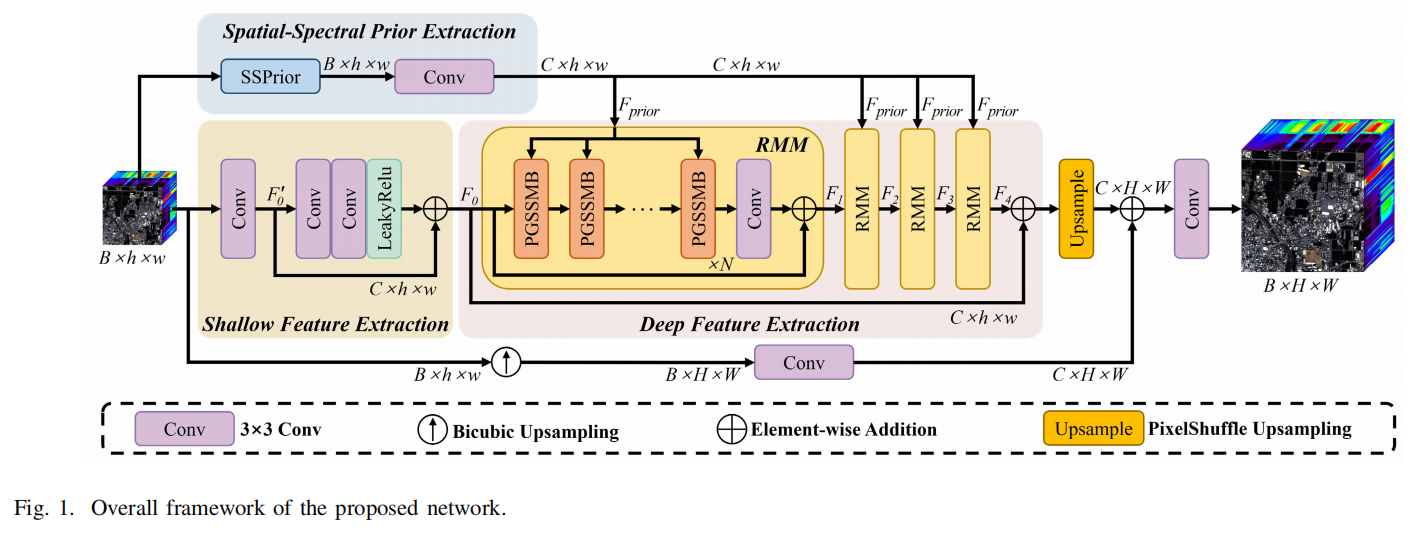
1. SSPrior 模块:基于小波变换的频域特征分离 (对应论文 Fig. 3)
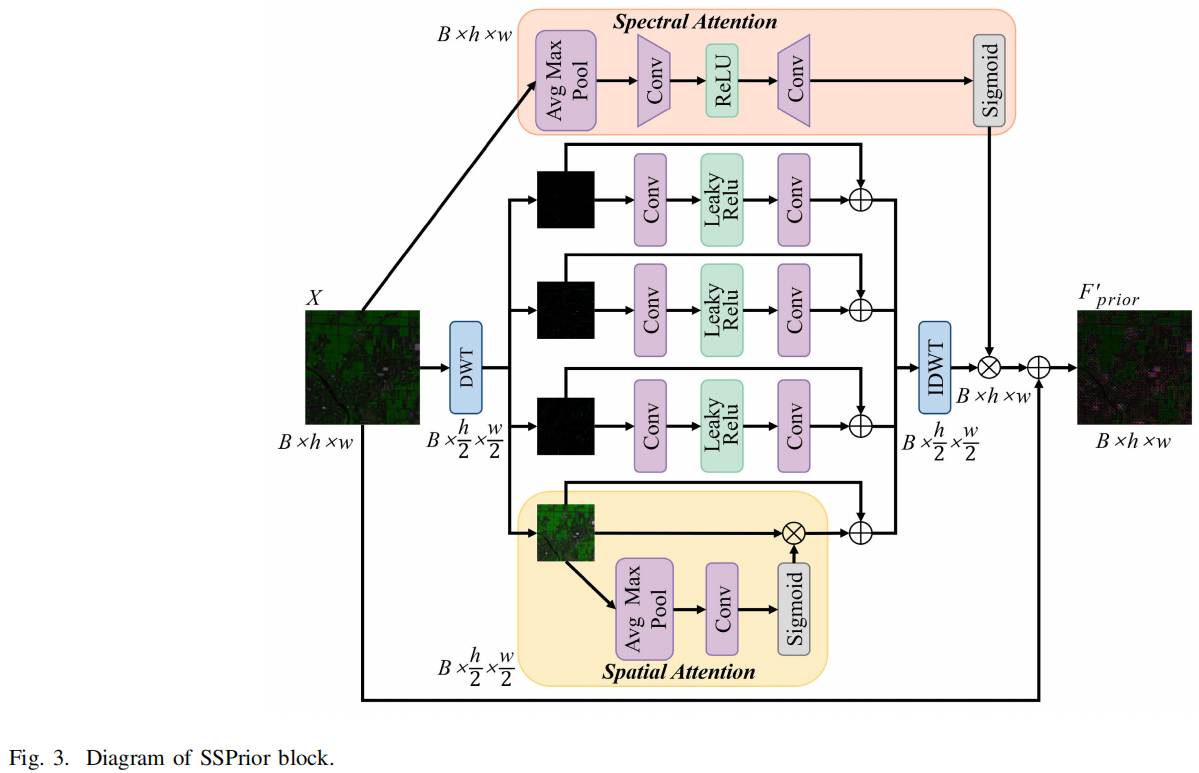
为提取结构先验,模型采用了离散小波变换 (DWT) 对输入图像进行多尺度分解 。
低频与高频的差异化处理: 输入图像经 DWT 分解为四个子带。对于包含图像主要结构的低频分量 (LL),模块使用空间注意力机制(Spatial Attention)来聚焦具有代表性的结构区域 ;对于包含边缘和细节的高频分量 (LH, HL, HH),则采用残差卷积层进行纹理特征的提取 。
空间-光谱联合表征: 处理后的频域特征通过逆小波变换 (IDWT) 还原为空间域特征。同时,模块对原始输入图像进行全局自适应池化和卷积,生成光谱维度的注意力权重。两者相乘后,得到最终的空间-光谱先验特征 FpriorF_{prior}Fprior 。
2. SRM 模块:引入洗牌机制扩展感受野 (对应论文 Fig. 2)
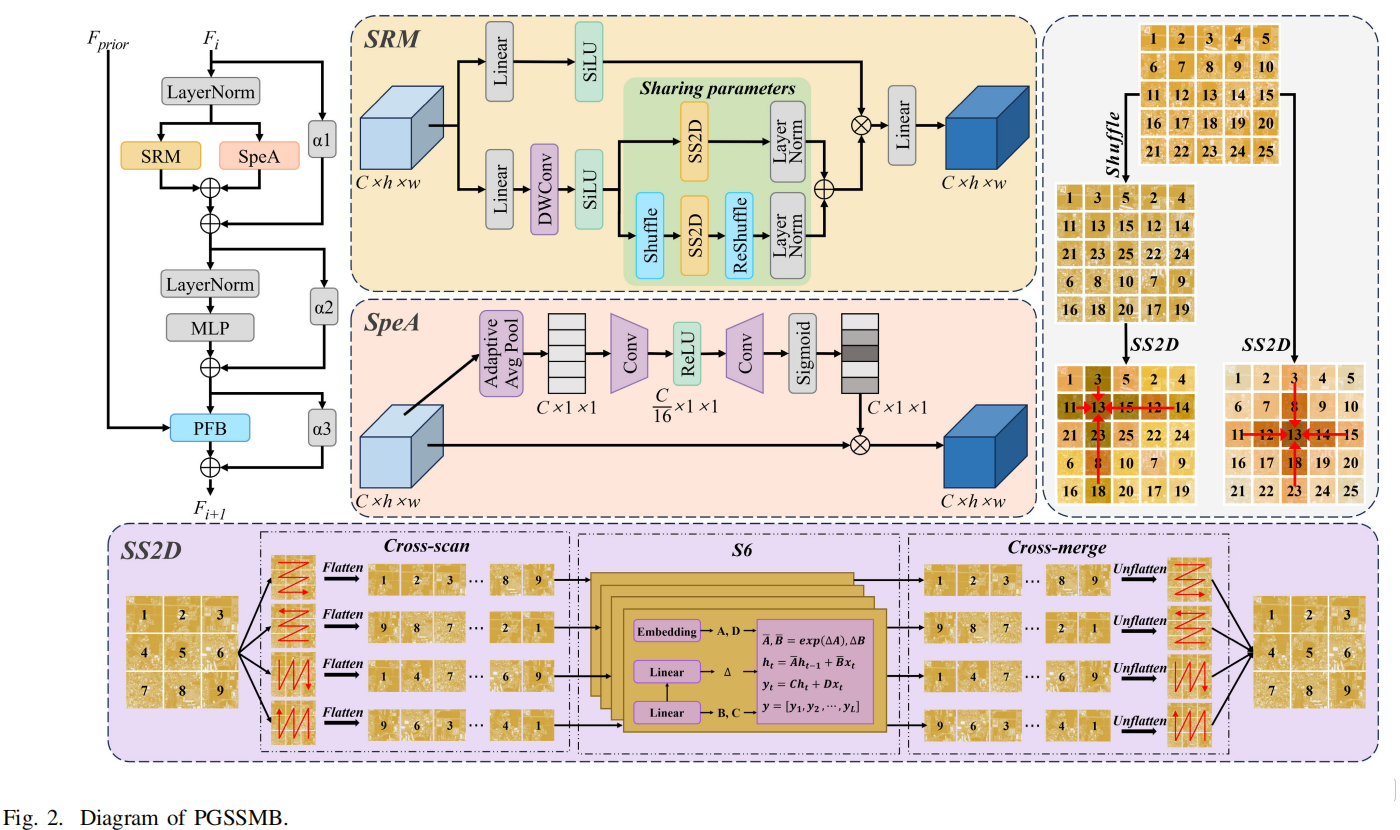
为了克服 Mamba 因果扫描在捕捉长程依赖时的局限,作者在主干网络中设计了 SRM (Shuffle-Reshuffle Mamba) 模块 。
并联的 Shuffle 分支: 在特征提取路径中,除了标准的 SS2D 扫描分支外,作者并联了一个采用全局交叉扰动策略的 Shuffle 分支 。
工作机制: Shuffle 操作重组了空间特征的像素排列(如图 2 右侧所示),使得原本在物理空间上距离较远的像素被重排到相邻位置。当这些重排后的像素输入 SS2D 进行扫描时,Mamba 能够更直接地建立长程空间依赖 。随后,通过 ReShuffle 操作将像素恢复至原始位置。两者结果相加,提升了模块的全局感知能力 。
3. PFB 模块:特征的自适应融合 (对应论文 Fig. 4)
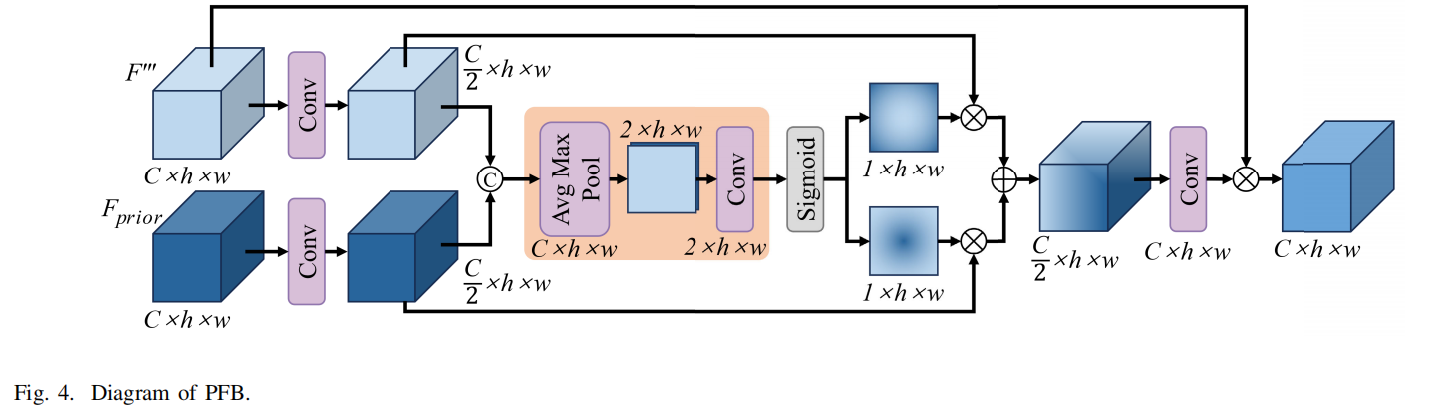
在提取了先验特征和深层特征后,如何将两者有效融合是关键。直接相加或拼接可能导致冗余信息的累积 。
空间选择机制: PFB (Prior Fusion Block) 模块首先对深层特征和先验特征进行卷积降维 。随后,将两者拼接并分别进行全局平均池化和最大池化,生成一对空间注意力掩码 w1w_1w1 和 w2w_2w2 。
自适应融合: 融合过程可表示为 Fw=Fm1⊙w1+Fm2⊙w2F_{w} = F_{m1} \odot w_1 + F_{m2} \odot w_2Fw=Fm1⊙w1+Fm2⊙w2 。该机制使得网络能够在不同空间位置自适应地决定保留深层语义信息还是补充高频先验信息,实现了平滑的特征注入 。
三、 评判性分析与改进方向
从实验结果来看,WESSP-Mamba 在 Chikusei、Houston 和 Pavia Centre 三个数据集上均取得了较好的客观评价指标(如 PSNR、SSIM),并在模型参数量和计算量(FLOPs)上保持了较好的平衡 。但在实际应用和算法设计层面,仍有以下几个方面值得探讨:
1. 固定小波基的非自适应性 论文在提取先验信息时使用的是标准的离散小波变换(DWT)。然而,DWT 的基函数是固定的(例如常用的 Haar 或 Daubechies 小波),无法根据输入的高光谱图像数据分布进行自适应调整 。在面对不同传感器采集的、具有不同噪声分布特性的遥感图像时,固定的频率分离方式可能无法获得最优的特征表达 。 可以考虑引入可学习的频域滤波器(如基于傅里叶域的全局滤波器),使网络能够通过反向传播自动学习最适合当前数据集的频率分离边界。
2. 理论复杂度与实际推理时间的差异 尽管基于 Mamba 的模型通常具有较低的理论计算复杂度(FLOPs),但在实际推理中,这并不总是等同于更快的运行速度。根据论文提供的 Table IV ,WESSP-Mamba 的推理时间(1.2745s)长于部分 CNN 模型(如 SSPSR 的 0.5466s)和 Transformer 模型(如 MSDformer 的 0.7381s)。
原因分析: 网络中包含大量的分支结构、特征穿插(如 Shuffle/ReShuffle)、DWT/IDWT 变换以及跨层注意力计算。这些操作增加了显存访问成本(Memory Access Cost, MAC)和系统调度开销,从而延长了实际推理耗时 。在对实时性要求较高的遥感监测任务中,如何优化内存访问逻辑是未来的改进重点。
四、 核心模块 Pytorch 代码实现
由于本文未开源代码,以下我提供 SRM(洗牌 Mamba 模块)和 SSPrior(空间-光谱先验提取模块)的这两个核心结构的 PyTorch 代码复现,封装成可插拔模块。
1. 洗牌重组模块 (Shuffle-Reshuffle Mamba, SRM)
通过 einops 库实现空间像素的重排,以扩大 SS2D 的感受野。
import torch
import torch.nn as nn
from einops import rearrange
# 假设环境已安装 Mamba 的底层算子,此处使用占位类表示标准的SS2D操作
class SS2D_Core(nn.Module):
def __init__(self, dim):
super().__init__()
# 实际运行请替换为mamba_ssm库中的相关模块
self.conv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim)
def forward(self, x):
return self.conv(x)
class SRM_Block(nn.Module):
def __init__(self, dim, shuffle_group=2):
super().__init__()
self.dim = dim
self.g = shuffle_group # 定义Shuffle 的网格大小
# 门控信号生成分支
self.gate = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.SiLU()
)
# 特征提取前置操作
self.feat_proj = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim), # DWConv
nn.SiLU()
)
# 两个并行的 SS2D 扫描路径
self.ss2d_standard = SS2D_Core(dim)
self.ss2d_shuffle = SS2D_Core(dim)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.out_proj = nn.Conv2d(dim, dim, kernel_size=1)
def forward(self, x):
B, C, H, W = x.shape
# 1. 生成门控信号 z
z = self.gate(x)
# 2. 特征投影
feat = self.feat_proj(x)
# 3. 路径 A: 标准的 SS2D 扫描
out_std = self.ss2d_standard(feat)
out_std = rearrange(out_std, 'b c h w -> b h w c')
out_std = self.norm1(out_std)
out_std = rearrange(out_std, 'b h w c -> b c h w')
# 4. 路径 B: Shuffle -> SS2D -> ReShuffle
# 将空间划分为网格并打乱像素排列,建立远距离依赖
feat_shuffled = rearrange(feat, 'b c (h g1) (w g2) -> b c (g1 h) (g2 w)', g1=self.g, g2=self.g)
out_shf = self.ss2d_shuffle(feat_shuffled)
# ReShuffle 恢复原始的像素位置
out_shf = rearrange(out_shf, 'b c (g1 h) (g2 w) -> b c (h g1) (w g2)', g1=self.g, g2=self.g)
out_shf = rearrange(out_shf, 'b c h w -> b h w c')
out_shf = self.norm2(out_shf)
out_shf = rearrange(out_shf, 'b h w c -> b c h w')
# 5. 特征相加与门控调制
out_fused = out_std + out_shf
out = self.out_proj(out_fused * z) # 结合门控信号
return out
2. 空谱先验模块 (SSPrior Block)
该代码基于论文描述的频域分离、注意力机制以及特征还原的整体计算图。DWT/IDWT 使用第三方库pytorch_wavelets。
import torch
import torch.nn as nn
# 离散小波变换库 pip install pytorch_wavelets
from pytorch_wavelets import DWTForward, DWTInverse
class SpatialAttention(nn.Module):
"""
空间注意力模块:用于低频特征,聚焦宏观结构区域
"""
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size=7, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
y = torch.cat([avg_out, max_out], dim=1)
return self.sigmoid(self.conv(y)) * x
class SSPrior(nn.Module):
"""
空谱先验模块
剥离了多波段光谱冗余,使用真实的 DWT/IDWT 算子
"""
def __init__(self, in_channels, wave='haar'):
super().__init__()
# 1. 初始化小波变换算子
# J=1 表示进行1级小波分解
self.dwt = DWTForward(J=1, mode='zero', wave=wave)
self.idwt = DWTInverse(mode='zero', wave=wave)
# 2. 低频处理: 空间注意力
self.spatial_attn = SpatialAttention()
# 3. 高频处理: 针对 LH, HL, HH 三个方向的高频子带,分别构建残差卷积
self.hf_convs = nn.ModuleList([
nn.Sequential(
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
) for _ in range(3)
])
# 4. 通道注意力 (适配医学图像,替代原论文的高光谱注意力)
# 为防止 in_channels 过小导致除以 4 为 0,加入简单的通道数保护
mid_channels = max(in_channels // 4, 1)
self.ca = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, mid_channels, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, in_channels, kernel_size=1),
nn.Sigmoid()
)
def forward(self, x):
# 1. 离散小波变换 DWT
# yl: 低频分量 (LL),形状为 (B, C, H/2, W/2)
# yh: 高频分量列表。yh[0] 的形状为 (B, C, 3, H/2, W/2)
# 其中的 3 代表三个方向的高频分量:LH (水平), HL (垂直), HH (对角线)
yl, yh = self.dwt(x)
# 2. 低频处理
yl_processed = self.spatial_attn(yl)
# 3. 高频处理
high_freqs = yh[0] # 取出第一级的高频张量 (B, C, 3, H/2, W/2)
hf_processed_list = []
# 分别对 LH, HL, HH 进行特征提取与残差连接
for i in range(3):
hf_component = high_freqs[:, :, i, :, :] # 提取单方向的高频,形状 (B, C, H/2, W/2)
hf_out = self.hf_convs[i](hf_component) + hf_component # 残差卷积
hf_processed_list.append(hf_out.unsqueeze(2)) # 恢复维度以便拼接
# 重新将处理后的三个高频分量拼接回原始形状 (B, C, 3, H/2, W/2)
yh_processed = [torch.cat(hf_processed_list, dim=2)]
# 4. 逆离散小波变换 IDWT
# 将处理后的低频和高频重组,恢复到原图尺寸 (B, C, H, W)
spatial_prior = self.idwt((yl_processed, yh_processed))
# 5. 通道注意力获取与特征相乘,最后加上全局残差
channel_weights = self.ca(x)
out = (spatial_prior * channel_weights) + x
return out
# ---------- 测试 ----------
if __name__ == "__main__":
# 模拟一个 Batch=2, Channel=32, H=128, W=128 的特征图
dummy_input = torch.randn(2, 32, 128, 128)
# 实例化模块
model = SSPrior(in_channels=32)
# 前向传播
output = model(dummy_input)
print(f"输入特征维度: {dummy_input.shape}")
print(f"输出特征维度: {output.shape}")

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)