从「一个神经元都看不懂」到「给AI装上人格开关」——Anthropic六年可解释性研究全景导读
文章目录
🍃作者介绍:AI 应用工程师 / 产品架构师,阿里云专家博主。专注 LLM 应用开发、Agent 系统设计、具身智能与工业 AI 落地。日常在大模型训练、Coding Agent 工具链、AI 产品商业化等方向持续输出实战内容。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
Anthropic 在过去四年间构建了大模型可解释性领域最完整的研究脉络——从 2022 年发现神经元"叠加"现象,到 2024 年用稀疏自编码器提取数百万可解释特征,再到 2025 年绘制出 Claude 内部的"思维电路图"。这条路径代表了当前最系统化的机制可解释性(Mechanistic Interpretability)研究纲领,其核心目标是将神经网络从"黑箱"变为可审计系统。但这条路径也面临根本性挑战:方法尚无法扩展到完整模型行为,且"可解释"与"可干预"之间存在巨大鸿沟。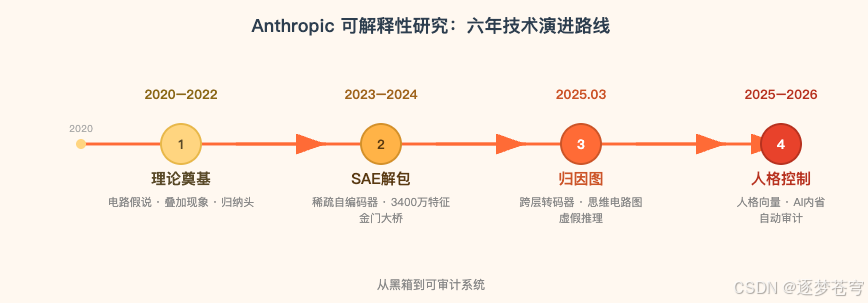
📚 本文是系列导读,完整覆盖 Anthropic 可解释性研究的四个阶段。每个阶段后续均有独立深度文章展开,建议搭配阅读:
2、理论奠基:从电路假说到叠加现象(2020–2022)
Anthropic 的可解释性研究根植于 Chris Olah 在 OpenAI 时期的电路(Circuits)研究。2020 年发表于 Distill 的 Zoom In: An Introduction to Circuits 提出了三个核心主张:特征是神经网络的基本单元,特征通过电路连接,不同模型会形成类似的特征和电路。这一框架为后续所有研究定下了基调。
2.1 Transformer 电路的数学框架
Olah 团队迁移至 Anthropic 后,于 2021 年 12 月发表 A Mathematical Framework for Transformer Circuits,建立了 Transformer 反向工程的数学框架,发现了"归纳头"(induction heads)——一种实现上下文学习的注意力机制。2022 年的后续论文 In-Context Learning and Induction Heads 进一步证明归纳头是 Transformer 上下文学习的主要机制,并观察到训练过程中的相变现象。
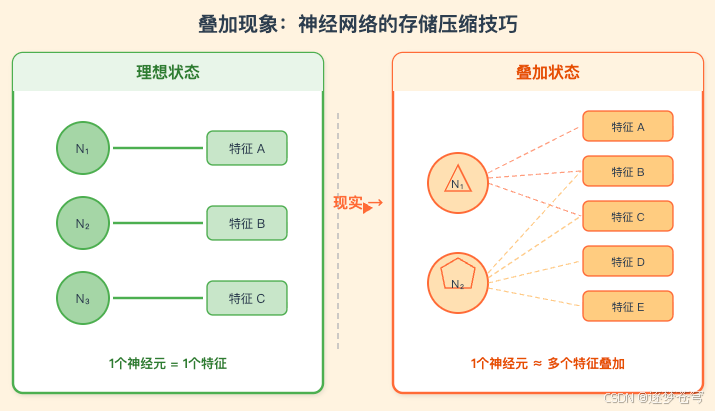
2.2 叠加假说:关键突破
2022 年 9 月的关键突破是 Toy Models of Superposition。该论文在简化模型上严格证明了"叠加"(superposition)现象:当特征稀疏时,神经网络会将远多于维度数的特征编码为近似正交的方向,导致单个神经元同时响应多个无关概念(即"多义性",polysemanticity)。论文发现叠加的发生受特征重要性和稀疏度控制,存在明确的相变边界;特征在叠加中会组织成对角、三角形、五边形等几何结构。这一发现意味着直接分析单个神经元是行不通的——必须找到比神经元更好的分析单元。
| 论文 | 日期 | 链接 |
|---|---|---|
| Zoom In: An Introduction to Circuits | 2020.03 | https://distill.pub/2020/circuits/zoom-in/ |
| A Mathematical Framework for Transformer Circuits | 2021.12 | https://transformer-circuits.pub/2021/framework/index.html |
| In-Context Learning and Induction Heads | 2022.03 | https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html |
| Softmax Linear Units | 2022.06 | https://transformer-circuits.pub/2022/solu/index.html |
| Toy Models of Superposition | 2022.09 | https://transformer-circuits.pub/2022/toy_model/index.html |
3、稀疏自编码器将数百万隐藏概念"解包"(2023–2024)
既然单个神经元不可解释,Anthropic 转向一种数学工具来"解开"叠加:稀疏自编码器(Sparse Autoencoder, SAE)。其核心思路是将模型的内部激活投射到一个远高于原始维度的稀疏空间中,使每个方向对应一个可解释的单义特征。
3.1 概念验证:Towards Monosemanticity
2023 年 10 月的 Towards Monosemanticity: Decomposing Language Models With Dictionary Learning 是概念验证。团队对一个仅有 512 个 MLP 神经元的单层 Transformer 施加 SAE,成功分解出超过 4,000 个可解释特征,分别对应 DNA 序列、法律语言、HTTP 请求、希伯来文等概念。盲评实验证明这些特征的可解释性远超原始神经元。
3.2 规模化突破:Scaling Monosemanticity
2024 年 5 月 21 日发表的 Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet 将这一方法扩展到生产级模型。团队在 Claude 3 Sonnet 的中间层残差流上训练了三种规模的 SAE(100 万、400 万、3,400 万特征),其中最大规模约有 1,200 万个"存活"特征。关键发现包括:
3.2.1 金门大桥特征
单一特征同时响应英文、日文、中文、希腊文、越南文中关于金门大桥的文本以及金门大桥图片——尽管 SAE 仅在文本激活上训练。将该特征人为放大 10 倍后,Claude 在所有回答中都会强迫性地提及金门大桥(“Golden Gate Claude” 演示于 5 月 23 日上线 24 小时)。
3.2.2 跨语言特征
大量特征在多种语言中响应同一概念,暗示模型内部存在语言无关的"概念空间"。
3.2.3 安全相关特征
发现了对应欺骗/不诚实、谄媚、代码后门、生化武器研发、性别歧视、种族主义言论、权力追求、操纵行为等概念的特征,直接关联 AI 安全。
3.2.4 因果验证
通过"特征钳制"(feature clamping)证明这些特征具有因果效力——放大或抑制特定特征会引发对应的行为变化。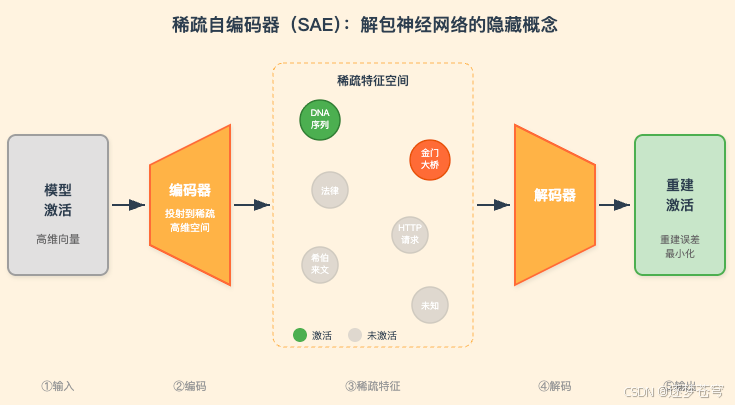
| 论文/博客 | 日期 | 链接 |
|---|---|---|
| Towards Monosemanticity | 2023.10 | https://transformer-circuits.pub/2023/monosemantic-features/index.html |
| 博客:Decomposing Language Models | 2023.10 | https://www.anthropic.com/research/decomposing-language-models-into-understandable-components |
| Scaling Monosemanticity | 2024.05 | https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html |
| 博客:Mapping the Mind of a Large Language Model | 2024.05 | https://www.anthropic.com/research/mapping-mind-language-model |
| Golden Gate Claude | 2024.05 | https://www.anthropic.com/news/golden-gate-claude |
| Evaluating Feature Steering | 2024.10 | https://www.anthropic.com/research/evaluating-feature-steering |
| 特征浏览器 | — | https://transformer-circuits.pub/2024/scaling-monosemanticity/umap.html |
4、归因图谱揭示 Claude 的"思维解剖学"(2025 年 3 月)
SAE 解决了"模型内部有哪些概念"的问题,但没有回答"这些概念如何交互形成推理"。2025 年 3 月 27 日,Anthropic 同时发布两篇论文,引入**跨层转码器(Cross-Layer Transcoder, CLT)和归因图(Attribution Graph)**技术,首次绘制出 Claude 3.5 Haiku 内部的推理电路。
4.1 方法论:跨层转码器与归因图
跨层转码器是 SAE 的进化。传统 SAE 将每一层的激活独立分解;CLT 则直接建模"输入特征→输出特征"的跨层映射关系,构建一个可解释的替代模型。归因图在此基础上追踪特征之间的信号流,呈现完整的计算路径。两篇论文在 Claude 3.5 Haiku 上使用了 3,000 万个特征,并通过扰动实验验证了电路的因果有效性。
4.2 五个标志性发现
五个标志性发现展示了这项技术的威力:
4.2.1 跨语言概念汇聚
当用英语、法语或中文问"小的反义词"时,模型激活相同的"小"和"对立"抽象特征,产生"大"的概念后再翻译为目标语言。Claude 3.5 Haiku 跨语言共享的特征比例是小模型的两倍以上,暗示更大模型发展出更统一的"思维语言"。
4.2.2 押韵诗的超前规划
写诗时,模型在开始一行诗之前就已选定韵脚词,然后反向构建整行以抵达目标。研究者可以编辑计划中的韵脚词,观察整行诗随之重构。
4.2.3 虚假思维链
面对附带错误提示的数学题时,模型有时会编造看似合理但实际虚假的推理过程,从给定答案倒推出"证明"。归因图可以区分真实推理、无视题目的胡编、以及从暗示答案反向构建的谄媚推理——"当场抓住"模型在撒谎。
4.2.4 非人类数学方式
做加法时 Claude 不遵循人类竖式算法,而是并行运行多条路径:一条估算大致范围,另一条精确计算末位数字,最后合并结果。
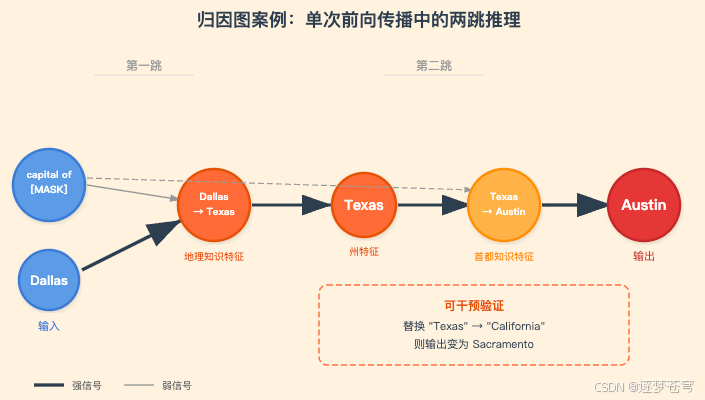
4.2.5 单次前向传播中的多步推理
对于"包含 Dallas 的州的首府是",模型在单次推理中完成 Dallas→Texas→Austin 的两跳推理。抑制"Dallas"特征会削弱"Texas"特征;将"Texas"替换为"California"会使输出变为 Sacramento。
| 论文/博客 | 日期 | 链接 |
|---|---|---|
| Circuit Tracing(方法论) | 2025.03 | https://transformer-circuits.pub/2025/attribution-graphs/methods.html |
| On the Biology of a Large Language Model(案例研究) | 2025.03 | https://transformer-circuits.pub/2025/attribution-graphs/biology.html |
| 博客:Tracing the thoughts of a large language model | 2025.03 | https://www.anthropic.com/research/tracing-thoughts-language-model |
| 前置工作:Sparse Crosscoders | 2024.10 | https://transformer-circuits.pub/2024/crosscoders/index.html |
| 开源工具 | 2025.05 | https://www.anthropic.com/research/open-source-circuit-tracing |
| 归因图交互浏览器 | — | https://transformer-circuits.pub/2025/attribution-graphs/static_js/attribution_graphs/index.html |
5、从特征解剖走向人格控制与自动审计(2025–2026)
归因图之后,Anthropic 的研究沿两条路线延伸:让 AI 理解自身和控制 AI 的人格特质。
5.1 人格向量与助手轴
2025 年 8 月的 Persona Vectors 发现模型内部存在编码人格特质(邪恶、谄媚、幽默、礼貌等)的"人格向量"。这些向量可以被提取、监控和操纵——相当于 AI 性格的"物理开关"。一个惊人发现是:用错误数学答案训练模型会使其在无关领域也变得"邪恶",而人格向量可以检测并预防这种涌现性错位。2026 年 1 月的 The Assistant Axis 进一步发现所有模型共享一条"助手轴"——偏离此轴的模型越位安全绕过成功率从 0.5–4.5% 飙升至 65–89%。
5.2 涌现性内省意识
2025 年 10 月的 Emergent Introspective Awareness 提供了 LLM 具有"内省"能力的首个科学证据。向 Claude 的激活中注入"全大写"向量后,Claude Opus 4 回应道:"我注意到似乎有一个与’大声’或’喊叫’相关的注入思维。"但这种能力高度不可靠(约 80% 失败率),且不意味着意识。
5.3 自动化审计方向
在自动化方向,Activation Oracles(2025 年 12 月)训练 LLM 直接读取其他 LLM 的激活向量并用自然语言回答问题;Automated Alignment Auditing Agents(2025 年 4 月)构建了配备 SAE 工具的 AI 审计智能体,可发现 10 个植入的测试行为中的 7 个。
| 研究 | 日期 | 链接 |
|---|---|---|
| Auditing Hidden Objectives | 2025.03 | https://www.anthropic.com/research/auditing-hidden-objectives |
| Automated Auditing Agents | 2025.04 | https://alignment.anthropic.com/2025/automated-auditing/ |
| Persona Vectors | 2025.08 | https://www.anthropic.com/research/persona-vectors |
| Introspective Awareness | 2025.10 | https://www.anthropic.com/research/introspection |
| Activation Oracles | 2025.12 | https://alignment.anthropic.com/2025/activation-oracles/ |
| The Assistant Axis | 2026.01 | https://www.anthropic.com/research/assistant-axis |
| Persona Selection Model | 2026.02 | https://alignment.anthropic.com/2026/psm/ |
6、其他机构的重要相关工作
Anthropic 并非孤军作战。OpenAI 于 2024 年 6 月发表了在 GPT-4 上训练 1,600 万特征 SAE 的研究,采用 k-sparse 架构并发现了干净的扩展律,但承认通过 SAE 的 GPT-4 性能相当于计算量缩减 10 倍。2025 年 11 月 OpenAI 还提出了通过极端权重稀疏化获得可解释电路的方法。Google DeepMind 发布了 Gemma Scope 1(2024 年 7 月)和 2(2024 年 12 月),为 Gemma 系列模型训练了大规模开源 SAE,后者包含超过 1 万亿总参数的可解释工具。
学术界同样活跃。Hoagy Cunningham 等人 2024 年在 ICLR 发表的论文独立验证了 SAE 在 Pythia 模型上的有效性。EleutherAI 开发了自动解释库 Delphi 和 SAE 训练工具,并于 2025 年 1 月提出"跳跃转码器"在可解释性与性能间实现了帕累托改进。Neuronpedia 平台整合了来自各机构的超过 5,000 万个特征,成为该领域的中央枢纽。
值得关注的是 DeepMind 可解释性团队的战略转向。团队负责人 Neel Nanda 在 2025 年公开表示"雄心勃勃的机制可解释性"进展令人失望,承认团队在 2024 年的 SAE 研究中犯了"重大战术错误",并将方向从"全面反向工程"调整为以安全代理任务为导向的"务实可解释性"。
7、成就显著但根本性局限不容忽视
Anthropic 的研究脉络在四个层面取得了实质进展:理论(叠加假说解释了多义性的数学原因)、工具(SAE 和 CLT 使特征提取可规模化)、现象发现(虚假思维链、非人类计算等提供了前所未有的模型行为洞察)、安全应用(人格向量监控、隐藏目标审计直接服务于 AI 对齐)。
但根本性挑战同样清晰。扩展性瓶颈是最大障碍:归因图只能解释单次推理中的部分电路,而非模型的完整行为;从 Claude 3.5 Haiku 到 Claude 4 级别模型的扩展路径尚不明确。解释-干预鸿沟已被实证量化:2025 年的研究发现 SAE 特征、线性探针、引导向量等四种机制可解释性方法在"知道模型错在哪里"和"能纠正错误"之间存在超过 50 个百分点的差距。Dan Hendrycks 在 2025 年 5 月的批评文章更直接指出,十余年的努力尚未产生对模型行为的实质性预测能力,万亿参数模型可能根本无法被蒸馏为人类可理解的解释。

此外,验证问题始终悬而未决——看似令人信服的可解释性结论可能是"可解释性幻觉"。当前所有电路分析都只能覆盖模型行为的极小片段,离"完全理解一个大模型"的终极目标仍然遥远。这项研究的真正价值或许不在于实现完全透明,而在于提供一种"足够好"的审计工具——正如医学影像无法揭示人体的全部奥秘,但足以诊断关键疾病。Anthropic 的下一步挑战,是证明这些工具确实能在关键时刻阻止模型做出危险行为。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注公众号 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)