SAM3 完全解读:当分割模型开始真正理解你在说什么
论文:SAM 3: Segment Anything with Concepts
arXiv: 2511.16719 | Meta Superintelligence Labs | 2025.11
一、任务定义:从 PVS 到 PCS,一次范式迁移
要理解 SAM-3 的意义,必须先把两个任务定义说清楚,因为这是整篇论文的出发点。
可提示视觉分割(Promptable Visual Segmentation,PVS) 是 SAM-1 和 SAM-2 所做的事情:给模型一个空间提示(点、框或粗略 mask),模型返回单个物体的分割结果。这是一个纯粹的几何任务,模型不需要理解"这是什么",只需要根据局部纹理和边界画出轮廓。
可提示概念分割(Promptable Concept Segmentation,PCS) 是 SAM-3 提出的新任务:给定图像或视频(≤30 秒),以及一个概念提示——简短名词短语(如 "yellow school bus")、图像示例(正样本或负样本边界框)、或两者的组合——模型要找出场景中所有匹配该概念的实例,返回它们的分割 mask 和唯一身份 ID,在视频中还要跨帧保持身份一致。
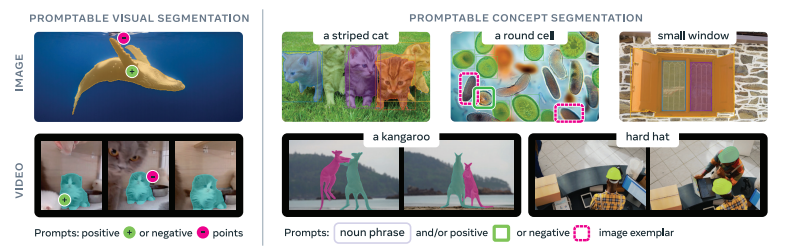
论文对 PCS 的文本输入有一个明确约束:只接受简单名词短语(Noun Phrases),即一个名词加可选修饰语,如 "red apple"、"striped cat",而不支持长描述句或需要推理的查询。这个设计是故意的,它让模型聚焦在对原子视觉概念的识别上,而不是语言理解上。当然论文也展示了通过外接多模态大语言模型(MLLM)来处理更复杂语言提示的可能性。
这个区别听起来很微妙,但工程影响是巨大的。PVS 里"用户找物体,模型画轮廓"的分工彻底改变了:现在模型必须自己找物体,而且要找全,还要保持身份区分。
二、歧义:开放词汇任务天然存在的难题
论文专门花了篇幅讨论歧义问题,我觉得这一段非常值得认真读。
开放词汇意味着任何名词短语都是合法输入。这就带来了几类歧义:
- 多义词(polysemy):"mouse" 可以是鼠标,也可以是老鼠
- 主观描述词:"cozy"、"large" 这类形容词没有客观边界
- 边界歧义:"mirror" 到底包不包括镜框?
- 遮挡和模糊:物体被部分遮挡时,边界的定义本身就不清晰
- 不可视觉定位的短语:"brand identity" 根本无法在图像中定位
面对这些问题,SAM-3 的策略是:在评估层面,每个测试样本由三位标注员独立标注,评测时对比所有 ground truth 选最优分(oracle accuracy);在模型层面,内置了歧义处理模块,对存在多种合理解释的提示可以输出多个候选 mask;在交互层面,用户可以通过添加正负示例来引导模型消歧。
这种承认歧义存在然后处理它的思路,比强行定义一个唯一答案要成熟得多。
三、模型架构:一个检测器 + 一个追踪器,共享同一个骨干
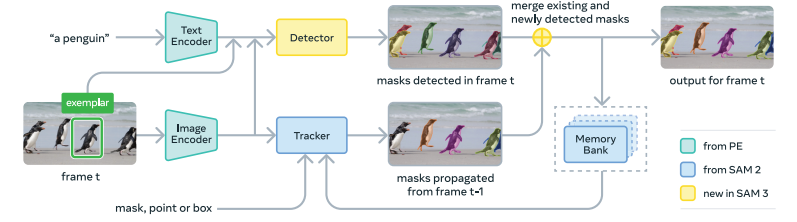
SAM-3 的整体架构由三部分组成:感知编码器(Perception Encoder,PE)作为共享骨干、图像级检测器(Detector)、以及视频追踪器(Tracker)。论文明确指出,检测器和追踪器的职责天然对立:检测器必须是身份无关的(identity agnostic),而追踪器的核心任务恰恰是在视频里区分身份。所以两者解耦,由同一个骨干分别驱动。
3.1 感知编码器(Perception Encoder)
PE 是整个系统的"感官"(上图中绿色部分),它对图像进行编码,输出无条件的视觉 token——注意这里"无条件"的意思是,这批 token 不依赖任何提示,纯粹是图像本身的视觉表示。论文强调 PE 对图像只编码一次,这批 token 随后被检测器和追踪器共同使用,避免重复计算。
PE 采用视觉-语言对齐的设计,图像和文本 embedding 在同一空间里,这是后续文本提示和视觉特征做交叉注意力的基础。
3.2 检测器(Detector):DETR 范式 + 定制化改造
检测器的主干是 DETR(Detection Transformer),但针对开放词汇概念分割做了多项关键修改。流程如下:
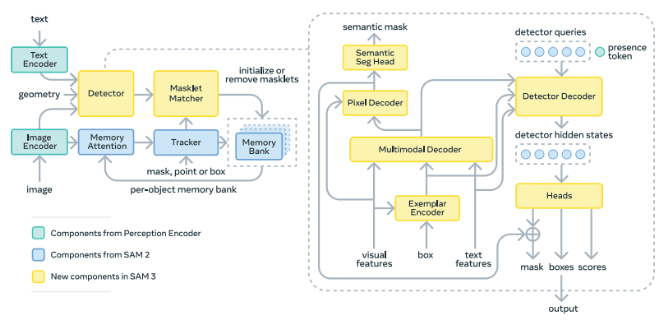
第一步:编码提示
图像被 PE 编码后,文本提示也经过 PE 的文本编码器变成文本 token;如果有图像示例(image exemplars),则经过专门的示例编码器(exemplar encoder)进行编码。示例编码器的工作方式是:对每个示例(一个边界框 + 一个正/负标签),分别提取位置 embedding、标签 embedding(正/负),以及ROI 池化的视觉特征,三者拼接后经过一个小型 Transformer 处理,最终与文本 token 拼接在一起,统称为"提示 token(prompt tokens)"。
第二步:融合编码器(Fusion Encoder)
论文正文把这一步称为 "fusion encoder",但在架构图里标注为 Multimodal Decoder——它在代码里对应的是 TransformerEncoderFusion,是一个 6 层的 Transformer 编码器,d_model=256,dim_feedforward=2048。
它的职责是:接收来自 ViT Neck 的无条件视觉特征(visual features),通过对 prompt tokens(text + exemplar + geometry)做交叉注意力,把提示信息融入视觉特征,使其变成"条件化的视觉特征"——即知道当前在找什么的特征表示。
第三步:DETR 解码器
融合后的图像特征进入 DETR 风格的解码器。解码器内有一组可学习的目标 queries(object queries),它们与条件化图像特征做交叉注意力,搜索所有可能的目标位置。每个 object query 在每个解码层都会预测:
- 一个二分类 logit(该位置是否与提示概念匹配)
- 一个相对于上一层预测的边界框偏移量(遵循 Deformable DETR 的迭代细化策略)
论文提到,训练时使用了来自 DAC-DETR 的双重监督(Dual supervision)以及 Align Loss,mask head 的设计参考了 MaskFormer。此外还有一个语义分割头,对图像中每个像素输出一个二值标签,表示该像素是否对应提示概念。
在注意力机制上,论文用了Box-Region-Positional Bias(来自 PlainDETR)来帮助 attention 聚焦在每个目标的边界框区域,但并没有采用近期 DETR 模型流行的 Deformable Attention,而是坚持用了普通的 Vanilla Attention。
3.3 存在头(Presence Token/Head):最关键的创新点之一
问题的根源在于:DETR 的每个 object query 需要同时完成两件事——识别(what)和定位(where)。这两件事的需求是矛盾的:
- 识别需要看全局上下文,"图像里有没有猫"这个判断需要扫描整张图
- 定位需要关注局部特征,"这只猫的边界在哪里"是个局部几何问题
把这两个目标强行塞给同一个 query,会导致 query 在两件事之间相互干扰。极端情况下会出现"幻觉检测"——即便图像里根本没有目标物体,query 也会从某个复杂纹理里强行生成一个预测。
SAM-3 的解法是引入一个全局存在 token(global presence token),该 token 在进行定位前,会先对整幅图像进行全局注意力,学习回答一个二值问题:
- 存在 token 只负责回答一个问题:
p(NP is present in input),即"这个概念存在于图像中吗?",输出一个 0~1 的标量 - 每个 object query 只负责在"存在"的条件下定位:
p(q_i is a match | NP is present in input)
最终每个检测的置信度 = 存在分数 × 局部 query 分数。
这个设计的好处是显而易见的:假设你输入提示 "unicorn"(独角兽),存在 token 的输出接近 0,那么无论 object queries 在图像里找到什么相似的纹理,最终所有检测分数都会被压到接近零,从而避免误检。论文的消融实验也验证了这一点,存在头显著提升了模型在 IL_MCC(图像级 Matthews Correlation Coefficient)指标上的校准性能。
这其实是一种非常优雅的条件分解,把一个难以优化的联合概率拆成了两个更容易学习的条件概率之积。
3.4 图像示例与交互性
SAM-3 对图像示例的支持方式很有意思,和 SAM-1/2 里"视觉提示"的语义完全不同:
- SAM-1/2 中,框住一只狗 → 分割这一只狗
- SAM-3 中,框住一只狗(正样本)→ 检测图像中所有狗
示例以(边界框,标签)对的形式输入,标签是正(positive)或负(negative)。正样本告诉模型"我要找这种东西",负样本告诉模型"不是这种,排除掉"。多个示例可以联合使用,也可以单独使用,也可以和文本提示混用。
交互式地修正当前检测结果时,用户可以通过添加正/负示例来引导模型,这种方式在模型初次遗漏了某些实例、或者目标概念比较罕见时特别有用。
3.5 追踪器与视频架构
追踪器继承自 SAM-2 的 Transformer 编码器-解码器架构,并与检测器共享同一个 PE 骨干。每一帧的处理遵循以下公式:
M_hat_t = propagate(M_{t-1}) # 追踪器传播上一帧的 masklet
O_t = detect(I_t, P) # 检测器在当前帧找新目标
M_t = match_and_update(M_hat_t, O_t) # 匹配并更新
追踪器的内部结构包括:
- 提示编码器(prompt encoder)
- mask 解码器(mask decoder,双向 Transformer)
- 记忆编码器(memory encoder)
- 记忆库(memory bank):存储过去帧及初始检测帧的目标外观特征
记忆编码器是一个 Transformer,对当前帧的视觉特征做自注意力,同时对记忆库中的空间记忆特征做交叉注意力。
为了处理歧义,追踪器对每帧每个目标预测三个候选 mask 及其置信度,选最高置信度的作为该帧的预测。
一个细节:推理时,记忆库只保留目标确信存在的帧的特征,这可以防止遮挡帧的噪声污染记忆表示。
匹配与更新(Match-and-Update)
IoU-based 匹配函数将传播的 masklet 与当前帧的检测结果关联。未被匹配的新检测会生成新的 masklet,代表新进入场景的对象实例。
为了处理拥挤场景和遮挡带来的歧义,论文引入了两个消歧策略:
-
时序检测分数(masklet detection score):统计一个 masklet 在过去若干帧中被检测器匹配到的次数,如果分数持续低于阈值,则抑制(suppress)该 masklet。这可以清理掉"幻影" masklet。
-
周期性再提示(periodic re-prompting):用检测器的高置信度结果定期替换追踪器自己的预测,刷新记忆库中的参考帧。这防止了追踪漂移——追踪器的预测误差积累得越来越大,直到完全偏离真实目标的问题。
实例级精修(Instance Refinement with Visual Prompts)
获得初始 mask 或 masklet 集合后,用户还可以对单个 mask 进行精修:给出正/负点击,模型的 mask 解码器据此预测调整后的 mask,并在视频中跨帧传播得到精修后的 masklet。这保留了 SAM-2 精细交互的能力。
3.6 训练阶段
论文把训练分为四个递进阶段:
- 感知编码器(PE)预训练
- 检测器预训练
- 检测器精调(fine-tuning)
- 追踪器训练(冻结 PE 骨干)
追踪器训练时冻结 PE 的设计,既保留了视觉表示的稳定性,又降低了端到端联合训练的复杂度。
四、数据引擎:SAM-3 性能跃升的真正基础
论文标题之所以说"doubles the accuracy",背后的关键不只是架构创新,数据引擎才是真正的决定因素。这部分论文写得非常详细,我觉得是整篇论文最有工程价值的部分。
4.1 数据引擎的核心思路
整个数据引擎是一个人类 + AI 协同的迭代标注流程,其核心逻辑是:让 AI 承担那些 AI 已经能做好的验证工作,把人力集中在 AI 出错的"困难案例"上。论文声称这使得标注吞吐量翻倍。
数据流程的标准步骤是:
- 媒体采集:从大规模媒体库中挖掘图像/视频,依托一个精心构建的本体(ontology)引导采集
- 名词短语(NP)生成:AI 模型为每段媒体提出描述视觉概念的名词短语,包括难负例(hard negatives)
- 候选 mask 生成:用当前版本的 SAM-3 为每个 NP 生成候选 mask
- Mask 质量验证(Mask Verification,MV):标注员(或 AI 验证器)判断每个 mask 的质量和与 NP 的相关性
- 穷举性验证(Exhaustivity Verification,EV):检查图像中该 NP 对应的所有实例是否都被 mask 覆盖
- 人工修正:未通过 EV 的样本交给人工,手工增删或修改 mask
4.2 四个阶段
阶段一:纯人工验证(Phase 1: Human Verification)
用简单的图像描述器和解析器随机采样图像和 NP 提案。初始 mask 由 SAM-2 配合一个现成的开放词汇检测器生成。验证完全由人工完成。这一阶段产出了 430 万图像-NP 对,构成初始 SA-Co/HQ 数据集。训练出第一版 SAM-3,作为后续阶段的 mask 提案模型。
阶段二:人工 + AI 验证(Phase 2: Human + AI Verification)
使用阶段一收集的人工接受/拒绝标签,精调 Llama 3.2 模型来分别执行 MV 和 EV 任务,创建"AI 验证器"。AI 验证器接收(图像,短语,mask)三元组,输出多选项质量评级。这让人力可以专注于 AI 验证器不确定的困难案例。
同时,NP 提案步骤升级为基于 Llama 的流程,会主动生成对 SAM-3 有对抗性的难负例,即那些长得像目标但实际上不是的概念短语。阶段二给 SA-Co/HQ 新增了 1.22 亿图像-NP 对,SAM-3 在这一阶段更新了 6 次。
阶段三:规模扩展与域扩展(Phase 3: Scaling and Domain Expansion)
覆盖 15 个不同数据集来源的 15 个视觉域。"域"在论文里的定义是一个独特的文本和视觉数据分布。引入了基于 Wikidata 构建的 SA-Co 本体(ontology),包含 2240 万节点、17 个顶层类别、72 个子类别,用于挖掘长尾和细粒度概念,扩展了 NP 的多样性和难度。这一阶段 SAM-3 迭代了 7 次,AI 验证器迭代了 3 次,新增 1950 万图像-NP 对。
阶段四:视频标注(Phase 4: Video Annotation)
将数据引擎扩展到视频。视频场景的特殊挑战(运动、遮挡、新实例进入)需要额外处理:数据挖掘流程加入了场景/运动过滤器、内容均衡、排序和定向搜索。视频帧通过随机采样或按目标密度采样的方式送入图像标注流程,masklet 由 SAM-3(视频版)生成,并经过去重和去除无效 mask 的后处理。人力优先分配给包含密集目标和追踪失败的视频片段。最终产出 SA-Co/VIDEO:52,500 段视频,467,000 个 masklet。
4.3 最终数据规模
| 数据集 | 规模 |
|---|---|
| SA-Co/HQ(高质量图像) | 520 万图像,400 万唯一 NP,5200 万 mask |
| SA-Co/SYN(合成图像,无人工) | 3800 万 NP,14 亿 mask |
| SA-Co/VIDEO(视频) | 52,500 段视频,24,800 唯一 NP,134,000 视频-NP 对 |
| SA-Co/EXT(外部数据集) | 15 个外部数据集,用本体流程补充难负例 |
视频平均帧数为 84.1 帧,采样帧率 6fps。
五、SA-Co 基准:一个超过 50 倍密度的新评测集
SAM-3 同期开源了 SA-Co(Segment Anything with Concepts)评测基准,规模远超现有基准:207,000 个唯一概念,121,000 张图像和视频,超过 300 万个媒体-短语对,所有对都带有难负例标签。这比现有最大的同类基准多出 50 倍以上的概念数量。
SA-Co 有四个评测分集:
- SA-Co/Gold:7 个视觉域,每个图像-NP 对由 3 位独立标注员标注,用于衡量人类表现基线
- SA-Co/Silver:10 个视觉域,每个图像-NP 对单人标注
- SA-Co/Bronze 和 SA-Co/Bio:9 个已有数据集,其中部分用 SAM-2 将边界框转换为 mask
- SA-Co/VEval:视频评测集,3 个视觉域,单人标注
评测指标的设计哲学
论文指出,传统的 AP(Average Precision)不考虑模型校准,这使得模型在实际使用中难以部署——你不知道以什么阈值截断才能得到合理的结果。SAM-3 的指标设计出发点是模拟真实下游用途:
- 只评估置信度 ≥ 0.5 的预测,强制要求模型有良好的校准性
- pmF1(positive micro F1):评估定位能力,仅在包含至少一个 ground truth mask 的正样本对上计算
- IL_MCC(Image-Level Matthews Correlation Coefficient):评估分类能力,即图像级别的"该概念是否存在"二分类,不考虑 mask 质量
- cgF1(classification-gated F1):主要指标,定义为
cgF1 = 100 × pmF1 × IL_MCC,要求定位和分类同时好
这个指标体系把"找得到"(pmF1)和"知道找没找到"(IL_MCC)同时纳入考量,符合真实应用场景的需求——在计数、筛选等任务里,"确认不存在"和"找得到"一样重要。
六、实验结果
6.1 图像 PCS
SAM-3 在 LVIS 基准上的零样本 mask AP 达到 48.8,而当前最优方法为 38.5,提升超过 10 个百分点。在自家的 SA-Co 基准上,SAM-3 对所有基线方法的超越幅度均在 2 倍以上。
6.2 视频 PCS
论文同样报告了 SAM-3 在视频概念分割上相对基线 2 倍的性能提升。
6.3 保持 PVS 能力
SAM-3 在改进 PCS 的同时,并未牺牲 PVS 能力——在可提示视觉分割任务上也优于 SAM-2。这说明两个任务的联合训练是互相促进的,而不是产生了竞争。
6.4 推理速度
在 H200 GPU 上,SAM-3 处理单张图像(100+ 个检测目标)仅需 30ms。视频模式下延迟随追踪目标数量线性增长,约 5 个并发目标时可维持接近实时的性能。
6.5 SAM-3 + MLLM 的组合使用
由于 SAM-3 只接受简单名词短语,对于更复杂的语言查询(如"找出所有坐在椅子上的人"),可以外接一个 MLLM 先将复杂查询分解为 SAM-3 可处理的名词短语,再调用 SAM-3 执行分割。论文展示了这种组合的有效性,证明 SAM-3 作为视觉感知模块具有很强的可组合性。
七、几个精妙的的设计选择
读完论文,有几个地方让我觉得值得单独提出来讨论。
1. 为什么限制文本只能是名词短语?
这个约束看起来像是一个限制,但实际上是一个非常务实的工程决策。它把语言理解的责任从 SAM-3 身上剥离掉,让模型专注在视觉识别这件事上,并且为评测基准的构建提供了清晰边界。当你需要更复杂的语言能力时,外接 MLLM 就好。这种"模块化"思维我觉得比"大一统"更有实用价值。
2. 检测器和追踪器为什么要保持解耦?
论文的原话是:检测器必须是 identity agnostic(身份无关),而追踪器的核心任务是 separate identities in the video(区分身份)。这两个目标如果共享参数,会产生训练目标上的冲突。解耦设计让每个模块都能专注在自己的优化目标上,这是模块化架构在这里的另一个体现。
3. 存在头的本质
存在头(Presence Token)的本质是把 p(概念存在于图像 AND 位置 = q_i) 分解为 p(概念存在于图像) × p(位置 = q_i | 概念存在于图像),前者是全局问题,后者是局部问题,用条件概率分解来匹配两种不同空间尺度的问题,这是一个很经典的概率建模思路。
4. 数据引擎里引入难负例(hard negatives)的重要性
论文专门强调了用本体系统生成难负例的重要性。正是因为训练数据里有大量"看起来像但实际不是"的对抗性样本,模型才能学会在推理时抑制假阳性,存在头的校准能力才得以发挥。这提醒我们:在开放词汇任务里,你如何构建负样本可能比正样本更重要。
论文链接:https://arxiv.org/abs/2511.16719
代码:https://github.com/facebookresearch/sam3
演示:https://segment-anything.com

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)