从 VLA 到人形全身控制,仅用1/10的数据量,实现40%性能反超

面向人形机器人灵巧移动操作的 VLA 模型
——质量+配比≫规模?
目录
01 核心突破:从“混合训练”到“拆分学习”,破解体貌差异难题
上图来源于PSI联合英伟达等团队最新提出的Ψ0,展示了在配备Dex3-1灵巧手的Unitree G1人形机器人平台上完成擦拭桌面、放置瓶子等一系列任务。
与GR00T N1.6、π0.5等通过大规模混合数据端到端训练的思路不同,Ψ0的核心在于将学习过程解耦,以解决人类视频与人形机器人数据在动作分布上的本质差异问题。
通过“语义学习”与“控制学习”的分阶段范式,Ψ0在多个长程灵巧操作任务上的整体成功率,相比数据量超十倍的GR00T N1.6等基线模型提升了40%以上。
这一结果揭示了数据质量与配比的重要性可能超越规模的简单堆砌。当然,该方法性能高度依赖预训练数据质量,且长程任务执行仍需任务拆解,距离端到端自主推理尚有距离。
01 核心突破:从“混合训练”到“拆分学习”,破解体貌差异难题
传统人形机器人控制模型普遍采用人类数据与机器人数据混合训练的方式,但这种思路存在本质缺陷:
人类与机器人在运动学特征、动作频率、自由度等方面存在不可调和的差异,单一模型同时学习两种截然不同的动作分布,必然导致效率低下和性能妥协。
即使引入领域自适应或数据融合技术,也难以解决复杂长时任务中的精准控制问题。
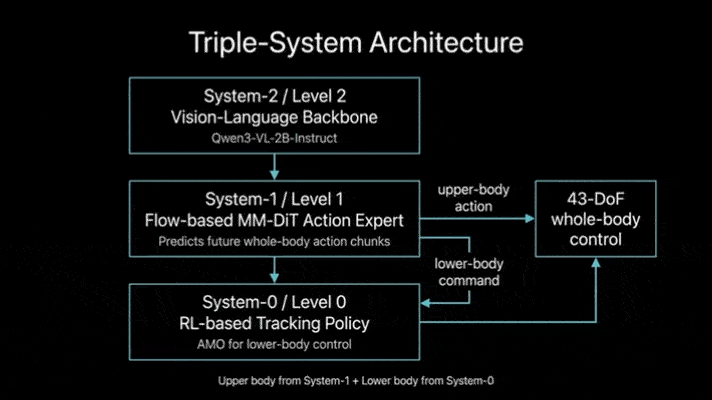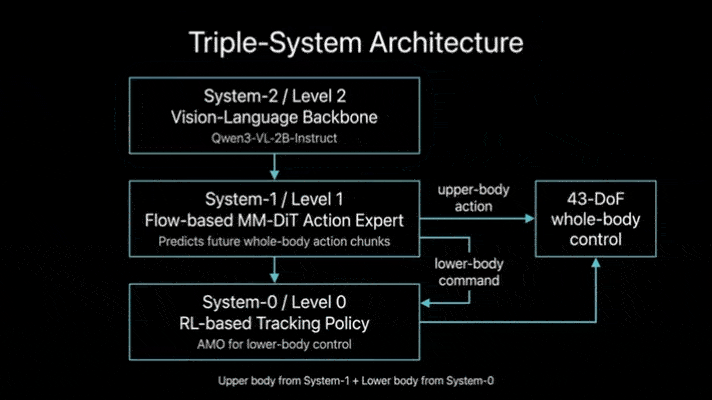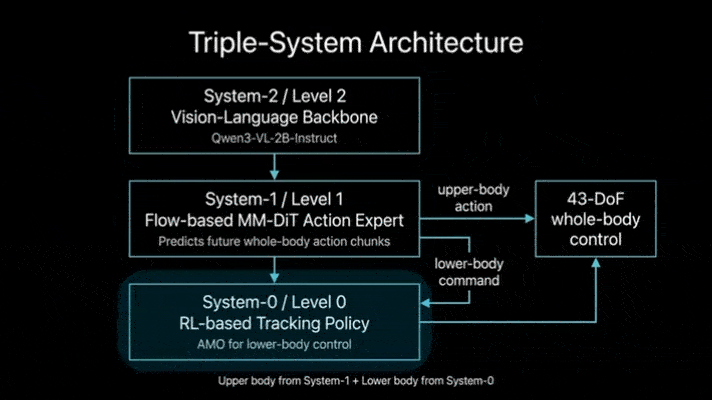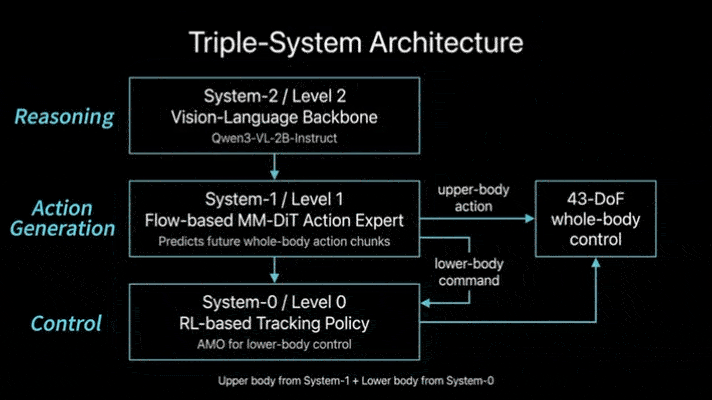
Ψ₀的核心创新在于拆分学习流程与功能定位,构建“视觉-语言骨干网络+动作专家+底层控制器”的三级架构,让不同模块专注处理专属任务:
-
视觉-语言骨干网络(VLM):基于Qwen3-VL-2B-Instruct预训练,专注从人类第一视角视频中学习任务语义和视觉-动作关联,无需直接适配机器人关节控制;
-
动作专家:采用多模态扩散Transformer(MM-DiT),仅通过机器人数据训练,专门学习关节空间的精准动作序列生成;
-
底层控制器:复用成熟的RL-based跟踪策略(AMO),负责将高层动作指令转化为15自由度的下肢关节角度,保障运动稳定性。
这种设计彻底摆脱了“用单一模型适配异质数据”的困境,既充分利用了人类视频的丰富任务先验,又通过专门训练确保了机器人控制的精准性,实现了“数据价值最大化”与“控制精度最优化”的平衡。
02 数据高效之道:少而精的训练配方,重构数据利用逻辑
在大模型 scaling 思维主导的当下,Ψ₀反其道而行之——
证明“数据质量×利用方式”远比单纯的数量堆砌更重要。
其训练流程分为三个阶段,每个阶段都有明确的目标与数据适配策略:

预训练:从人类第一视角视频中提取通用先验
预训练阶段的核心目标是学习“任务是什么”和“动作与视觉的关联”,而非直接学习机器人动作。
研究选用EgoDex数据集(约829小时人类第一视角操作视频)和少量人形机器人数据(Humanoid Everyday,31小时)。
采用统一的动作表示空间——将人类手部与机器人末端执行器的动作都编码为48自由度的任务空间向量,包含手腕位姿和指尖位置等关键信息。
为降低计算成本,模型仅需预测单步动作而非长序列,同时通过FAST tokenizer将连续动作转化为离散令牌(平均压缩至20个令牌),大幅提升训练效率。
预训练的核心公式聚焦于动作令牌的自回归预测:
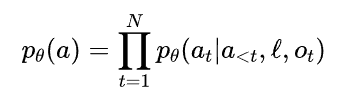
该公式表示模型在给定历史动作、任务指令 () 和当前观测 (
) 的情况下,逐步预测后续动作令牌的概率,本质是让模型学习“看到什么场景、收到什么指令时该做什么动作”的通用逻辑。
后训练:用机器人数据适配关节控制
预训练完成后冻结VLM参数,动作专家单独通过Humanoid Everyday数据集(约300万帧真实机器人数据)进行后训练。
这一阶段的核心是让模型学习“机器人该如何动”,直接在关节空间生成36自由度的动作序列(包含手部、手臂、躯干姿态及运动速度等)。
动作专家采用流匹配(flow-matching)训练目标:
其中是添加高斯噪声()后的动作,模型需要学习从含噪动作中恢复真实动作的映射关系。这种设计让动作专家能更好地捕捉机器人的运动动力学特征,生成平滑且符合物理约束的动作序列。
微调:少量任务数据实现快速适配
针对具体任务,仅需用80条 teleoperation 轨迹(约对应少量小时级数据)微调动作专家,即可让模型快速掌握长时复杂任务。
这种“预训练学通用→后训练学适配→微调学专属”的流程,使得Ψ₀的总机器人数据量仅为30小时,不足传统方法的1/10,却实现了更优性能。
03 关键技术支撑:从训练到部署的全链路优化
Ψ₀的实用性能不仅依赖架构创新,还得益于多项针对性技术优化,解决了从模型训练到真实场景部署的核心痛点:
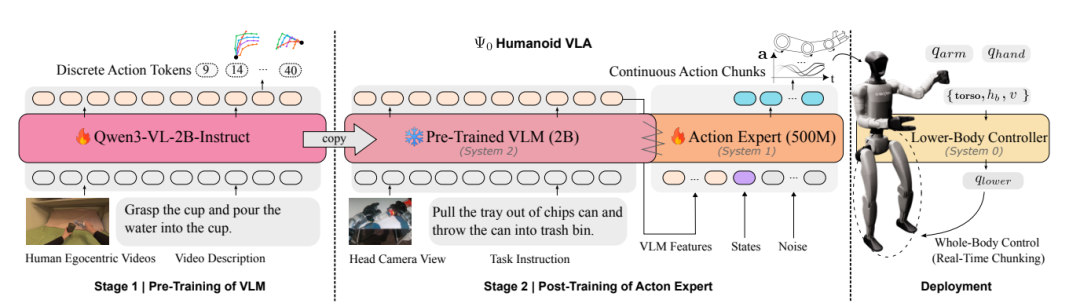
▲图|模型的训练与部署流程
MM-DiT:更高效的动作生成架构
相比传统扩散Transformer(DiT),MM-DiT通过双调制设计和联合注意力机制,实现视觉-语言特征与动作特征的深度融合。
在每个Transformer块中,时间条件特征分别调制动作特征和视觉-语言特征,随后两类特征进行全局联合注意力计算,大幅提升了“指令-视觉-动作”的关联精度。
消融实验显示,MM-DiT在双臂协调任务中的整体成功率比传统DiT高10%以上,尤其在精细操作任务中优势明显。
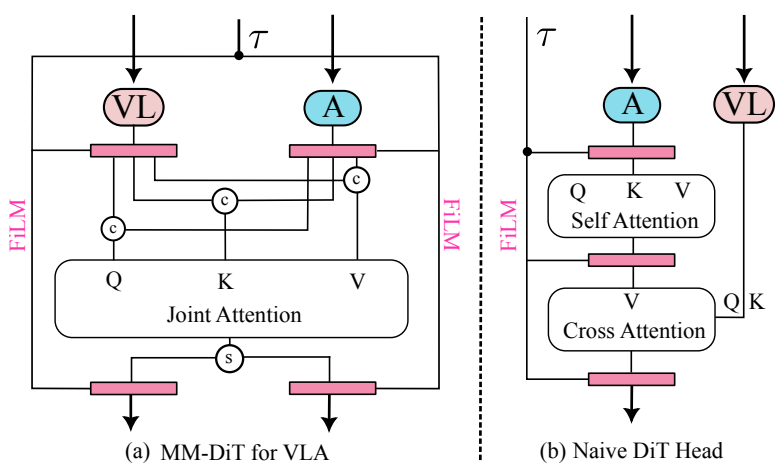
▲图|面向视觉 - 语言 - 动作模型的 MM-DiT 架构
训练时实时动作分块(RTC):解决部署延迟难题
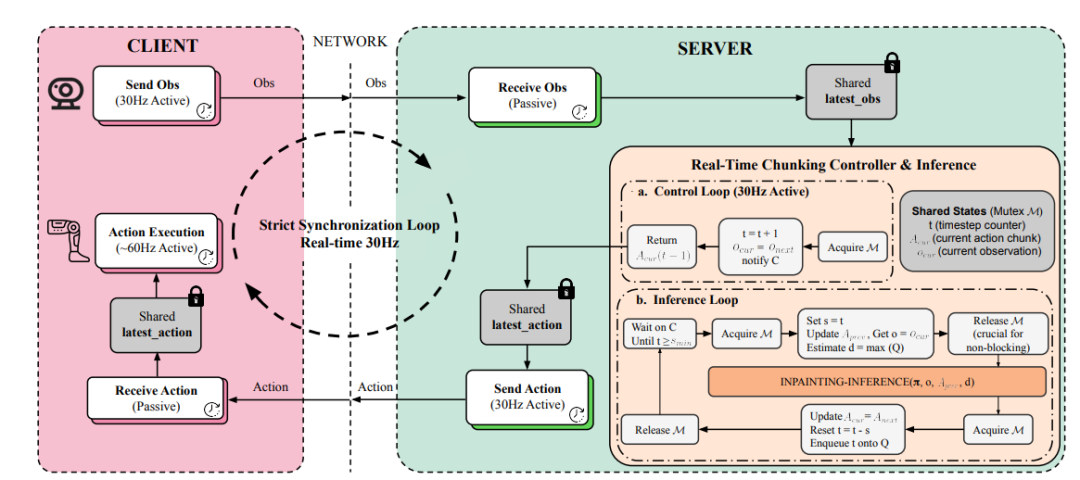
▲图|实时动作分块系统设计
大模型的推理延迟会导致机器人动作卡顿或抖动,这是制约VLAs落地的关键问题。
Ψ₀采用训练时实时动作分块技术,在训练过程中随机屏蔽部分动作令牌,让模型学习基于已执行动作生成后续连贯序列。
部署时,通过异步推理机制——控制线程(30Hz)负责动作执行,推理线程提前计算下一段动作分块,确保动作切换无缝衔接,彻底消除了“思考-执行”间隙导致的抖动。
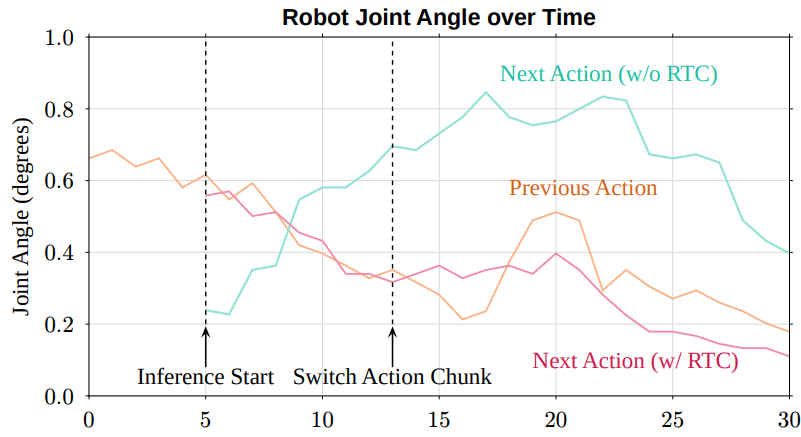
▲图|实时动作分块效果展示
定制化遥操作 pipeline:保障数据质量
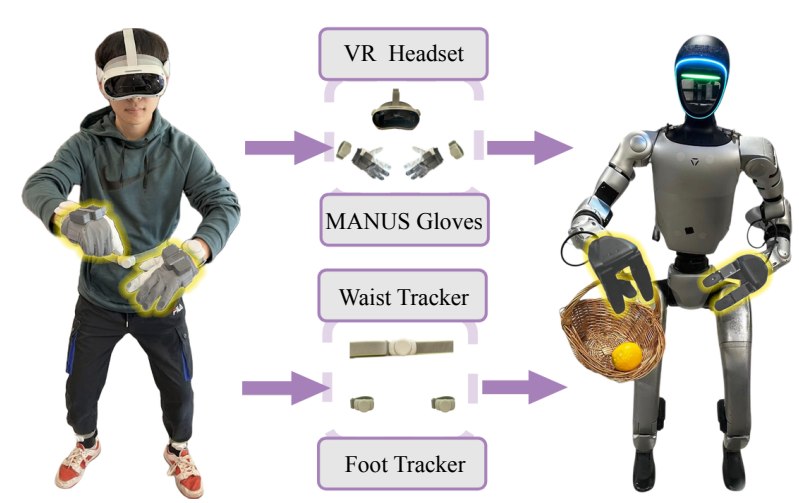
▲图| 真实机器人遥操作设备搭建
高质量的微调数据是精准控制的前提。
Ψ₀设计了单操作者全身体控方案:
通过PICO头显和手腕追踪器捕捉上半身姿态,MANUS数据手套获取手指精细动作,腰部和足部追踪器提供移动指令,再通过多目标逆运动学求解器转化为机器人关节配置。
这种方案既保障了操作的灵活性与精准性,又避免了多操作者协同的复杂性,采集的数据更符合真实任务场景的动作逻辑。
04 实测性能:8项长时任务验证,刷新通用操作上限
团队在Unitree G1人形机器人平台(配备Dex3-1灵巧手)上,针对8项长时复杂任务进行实测,涵盖取水、清洁、搬运、倾倒等日常场景,每项任务包含3-5个子任务,单任务步数超过2000步(30Hz采样),全面考验模型的长时规划与精准控制能力。

▲图|真实世界任务设置
核心测试结果
-
整体成功率:平均比第二名基线模型(GR00T N1.6)高40%以上,在“推购物车+取物”“拉托盘+扔垃圾”等需要全身协调的任务中成功率达到90%;
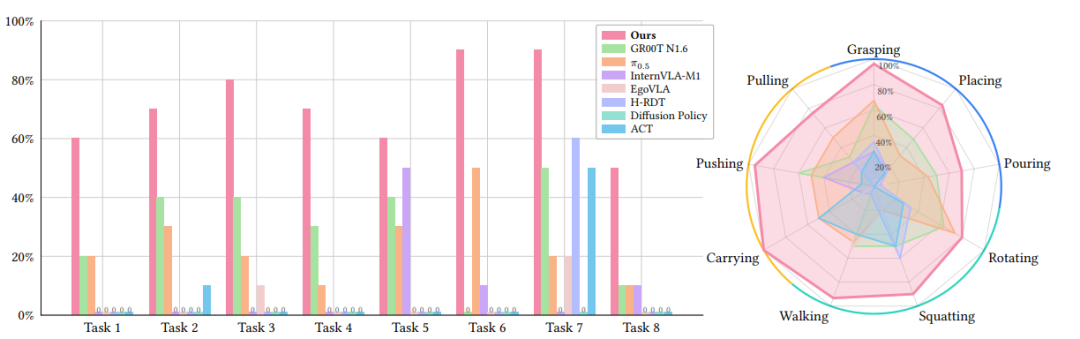
▲图|真实世界基准测试结果
-
技能覆盖:在抓取、放置、旋转、行走、深蹲等9类核心技能中,均保持最高成功率,尤其在“精细手指操作”(如拧水龙头)和“双臂协同”(如搬箱子)任务中优势显著;
-
数据效率:仅用30小时机器人数据,性能超过使用10倍以上数据的传统模型,证明其数据利用效率的优越性。
对比其他基线模型(π0.5、InternVLA-M1、EgoVLA等),Ψ₀的优势集中体现在三个方面:
长时任务的稳定性(无中途失效)、动作执行的流畅性(无抖动或碰撞)、跨任务的泛化性(无需大幅调整即可适配不同场景)。
05 局限性与未来趋势
尽管Ψ₀展现出强大的性能,但仍存在明显的技术边界与改进空间:

▲图|人形机器人全身运动操作任务展示
-
数据规模局限:受计算资源限制,未验证更大规模人类视频或机器人数据的增益效果,后续可探索进一步 scaling 的潜力;
-
硬件依赖:当前性能基于Unitree G1平台实现,其有效载荷能力限制了重载操作任务的适配,需在更强大硬件平台上验证泛化性;
-
动态环境适配:未充分考虑动态干扰(如物体移动、外部碰撞),在非结构化动态场景中的鲁棒性有待测试;
-
多任务联合优化:目前采用单任务微调策略,多任务联合训练时性能会下降,需探索更高效的多任务学习机制。
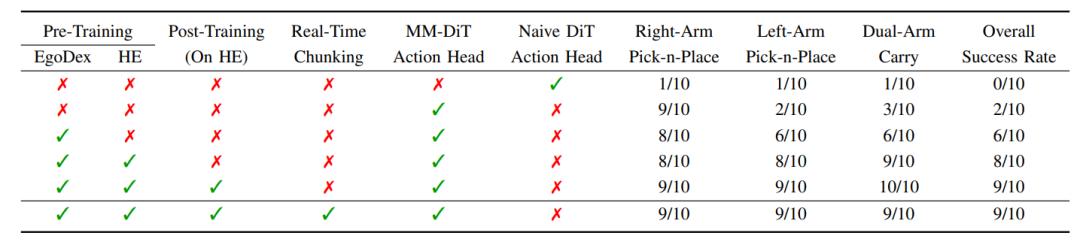
▲图|消融实验结果
从行业发展视角看,Ψ₀证明无需依赖海量机器人数据,通过合理拆分学习流程、优化数据利用方式,就能实现高精度的全身操作。这种思路为资源有限的研究团队提供了可行路径,也为行业从“数据堆砌”转向“技术创新驱动”提供了重要参考。
未来,随着动态环境适配、多模态融合等技术的补充,这种“拆分学习+少而精数据”的思路或有望成为通用人形机器人控制的主流范式。
Ref:
论文题目:Ψ₀: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
论文地址:https://arxiv.org/pdf/2603.12263v1.pdf
项目地址:https://psi-lab.ai/Psi0

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)