网络基础概念
·
目录
一.协议
1.计算机中的协议
从应用的角度出发,协议可理解为 “ 规则 ” ,是数据传输和数据的解释的规则。
计算机与计算机之间通过网络实现通信时事先达成的一种约定或规范。是不同的厂商设备,不同的
CPU, 不同的操作系统的计算机,只要遵循相同的协议就能够实现通讯。
2.OSI 七层参考模型(标准模型)
(Open System Interconnect),即开放式系统互联
全称为开放式通信系统互连参考模型,是国际标准化组织 ( ISO ) 提出的一个试图使各种计算机在世界范围内互连为网络的标准框架OSI 将计算机网络体系结构划分为七层,每一层实现各自的功能和协议,并完成与相邻层的接口通信。即每一层扮演固定的角色,互不打扰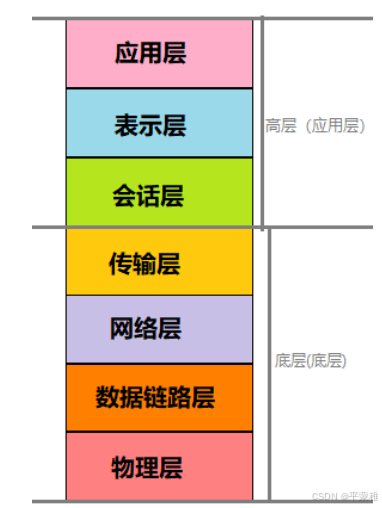 协议的分层 - 掌握网络采用分而治之的方法设计,将网络的功能划分为不同的模块,以分层的形式有机组合在一起。网络体系结构即指网络的层次结构和每层所使用协议的集合
协议的分层 - 掌握网络采用分而治之的方法设计,将网络的功能划分为不同的模块,以分层的形式有机组合在一起。网络体系结构即指网络的层次结构和每层所使用协议的集合
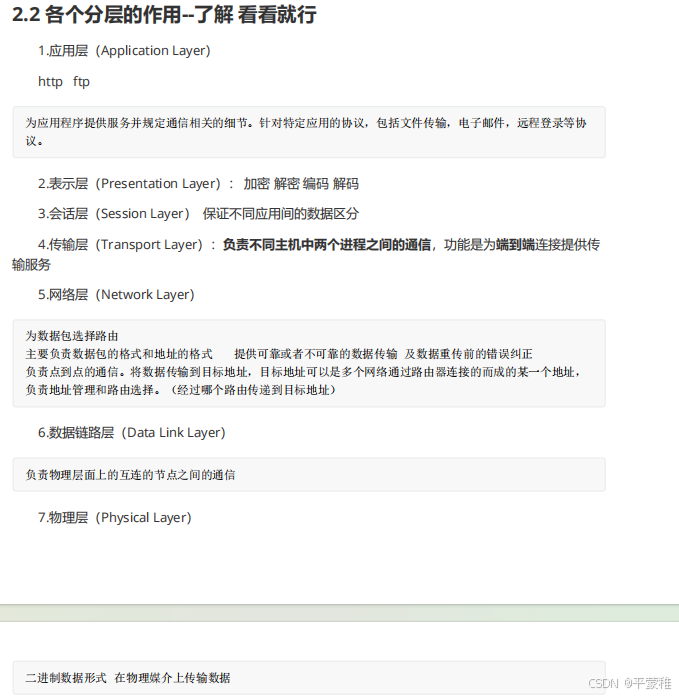
二.TCP/IP模型4层模型-掌握
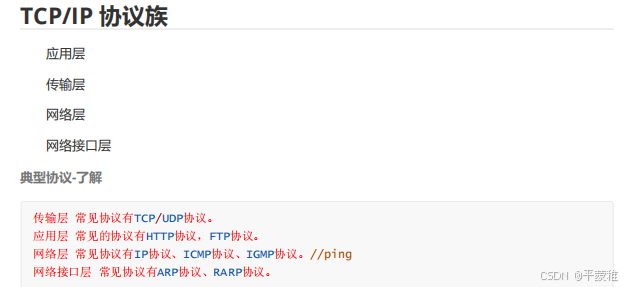
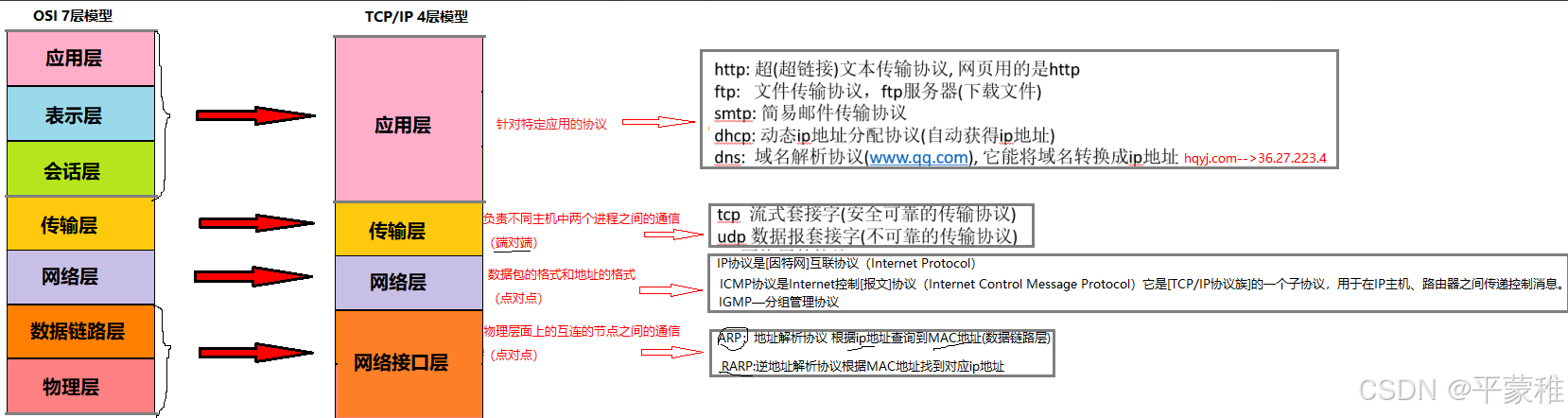

三.数据包传输
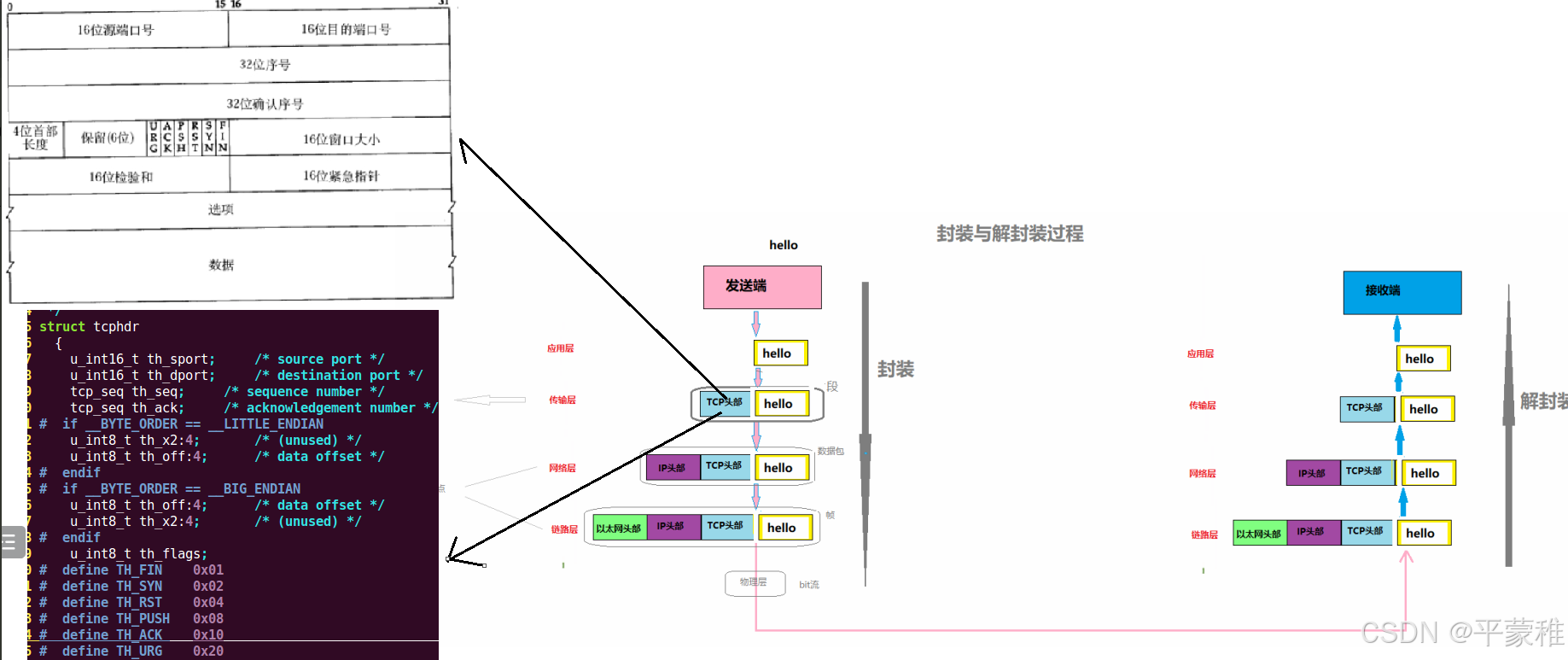
1.封装与解封
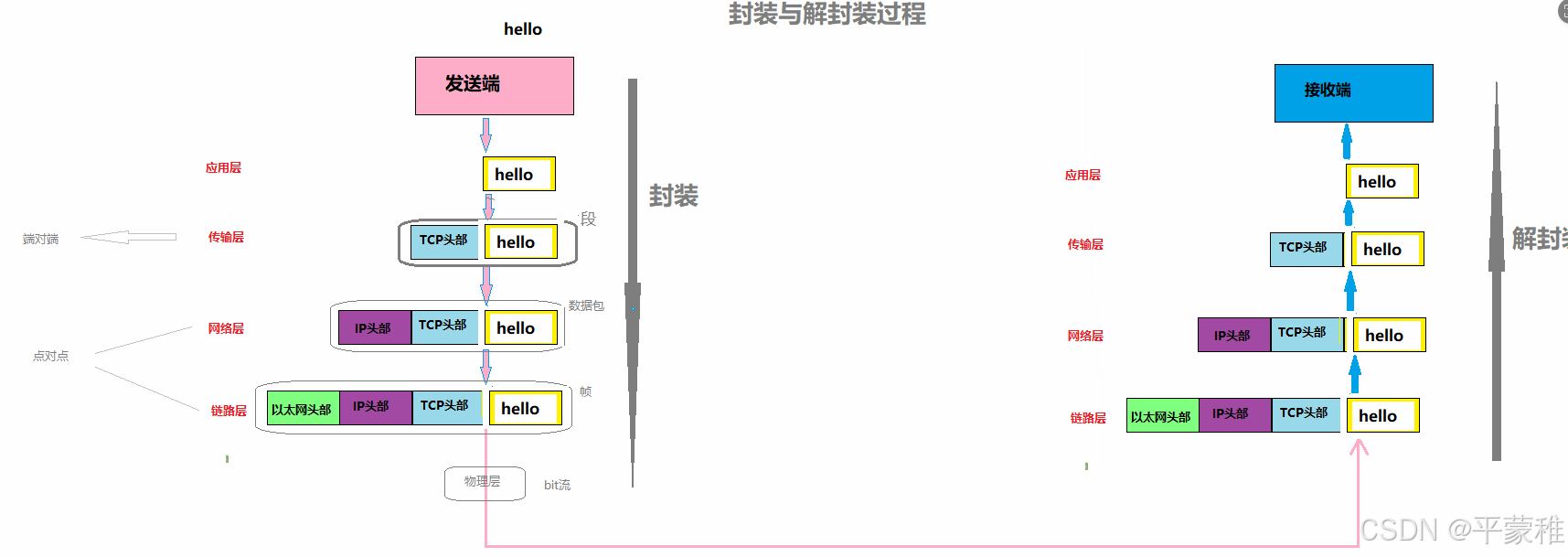
2.七层模型端对端输出
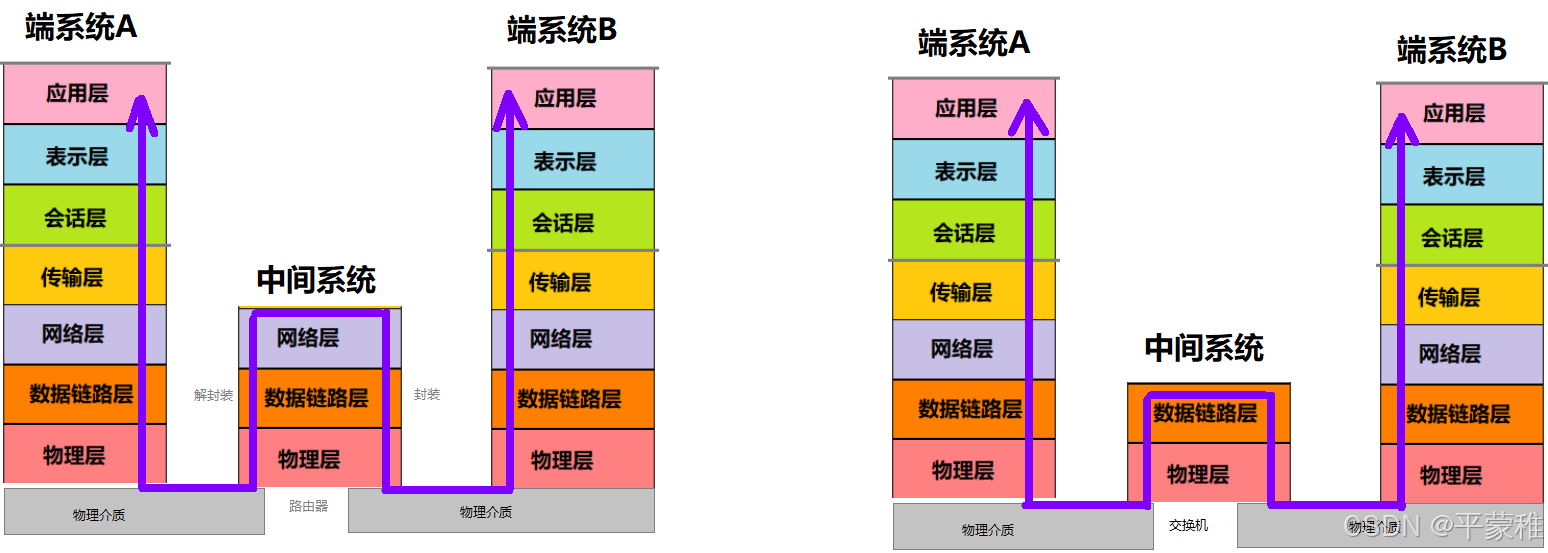

四.通信模型
B/S模式
浏览器 () / 服务器 ( server ) 模式。只需在一端部署服务器,另外一端使用每台 PC 都默认配置的浏览器即可完成数据的传输。
C/S 模式 client server
传统的网络应用设计模式,客户机 (client)/ 服务器 (server) 模式。需要在通讯两端各自部署客户机和服务器来完成数据通信。
五.通信基知
1.通信要素
协议 本地地址 本地端口 远程地址 远程端口
2.ip地址
(1)ip
含义:
主机在网络中的地址,主机要与其他机器通信必须具有的一个 IP 地址 ( 主机身份证 )ip 地址具有唯一性 192.168.1.10
表示形式
(1)点分十进制 ("192.168.0.11" 字符串) //char ip[16]="192.168.0.11";(这是默认ipv4(32位))(2)整型 (网络通信使用的网络格式地址)192. 168. 0. 11二进制 1100 0000 1010 1000 00000000 0000 1011十六进制 c 0 a 8 00 0 b1 byte == 8 bit 8 个二进制位1 个十六进制 == 4 个二进制位2 个十六进制 == 8 个二进制位 == 1 字节
查看 ipifconfig修改 ipsudo ifconfig eth0 192.168.8.xx ( xx 的范围是 1 - 254 )
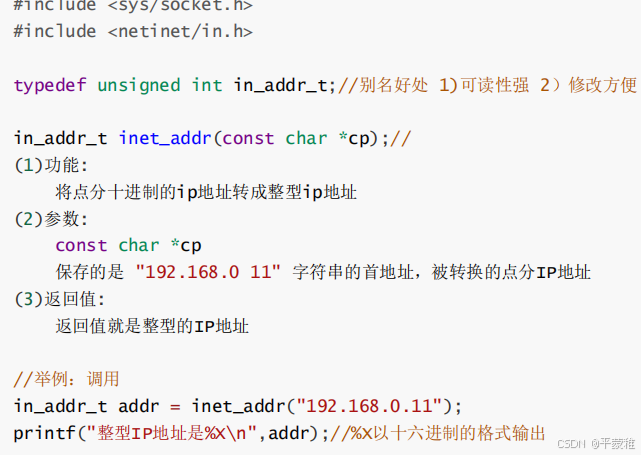
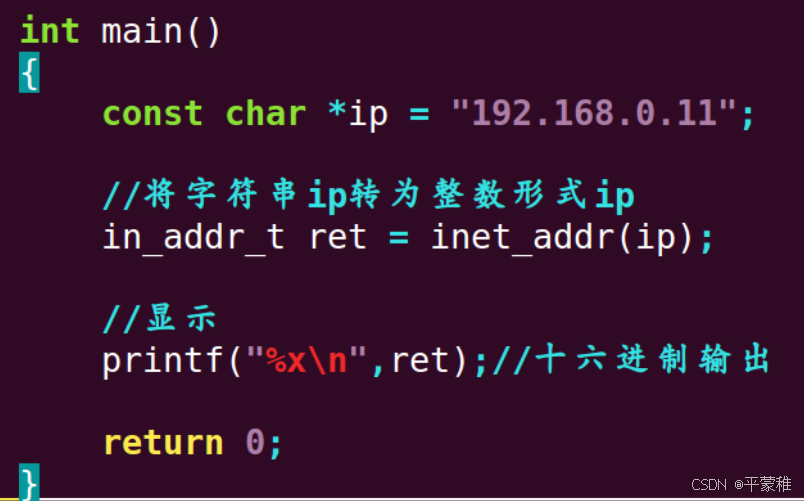
(2)ip转化
点分十进制IP转整型IP
实例:
整型IP转点分十进制字符串IP
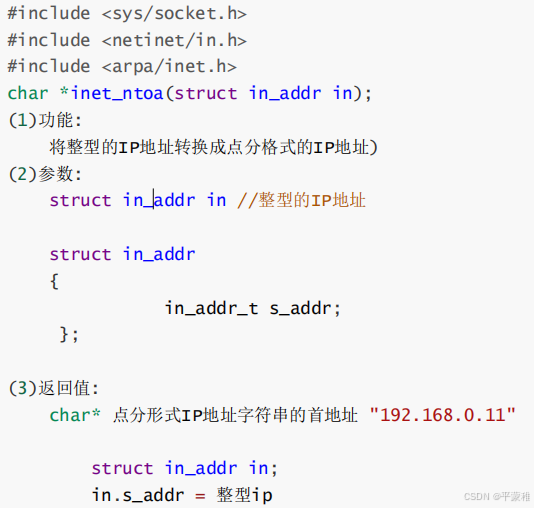
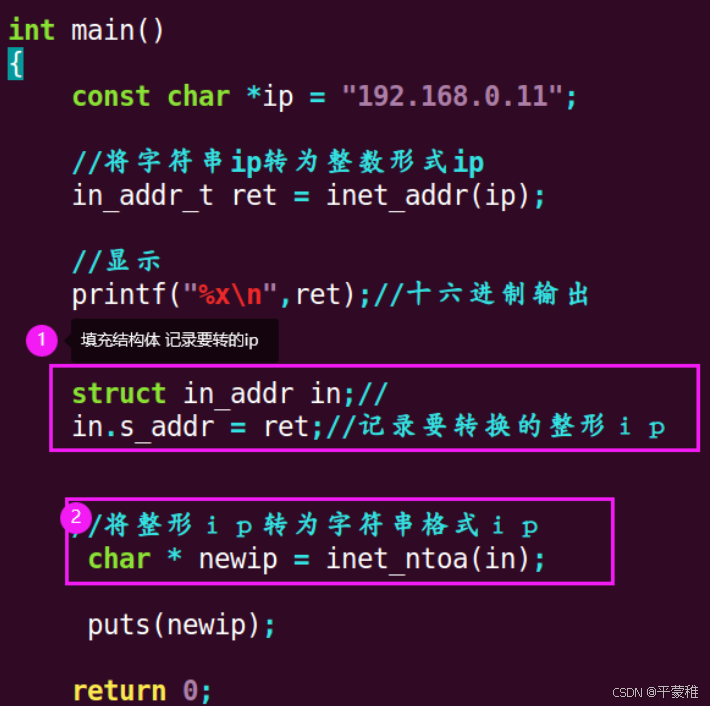
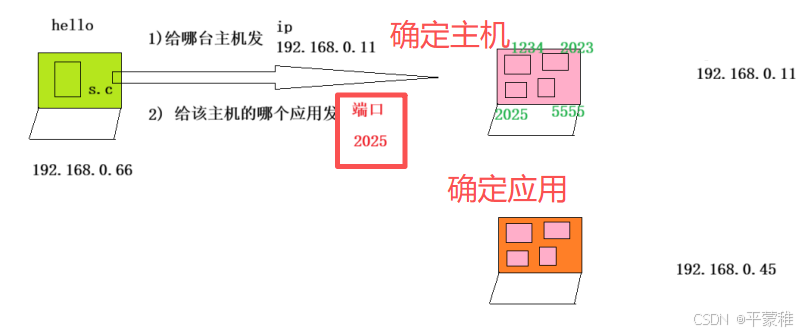
(3)端口号
功能:区分不同的网络应用--掌握

3.字节序
(1)概念:
字节序,顾名思义字节的顺序,大于一个字节类型的数据在内存中的存放顺序
1 )主机字节序( Host Byte Order): 主机字节序是指特定主机体系结构所采用的字节序。不同的计算机 小端存储体系结构可能采用不同的字节序2 )网络字节序( Network Byte Order ): 网络字节序是一种标准化的字节序 在网络通信中,为了保证不 大端存储同主机之间数据的正确传输和解析,通常会采用统一的网络字节序。通常会将数据在发送前转换为网络字节序目前在各种体系的计算机中通常采用的字节存储机制主要有两种: Big - Endian 和 Little - Endian// 鸡蛋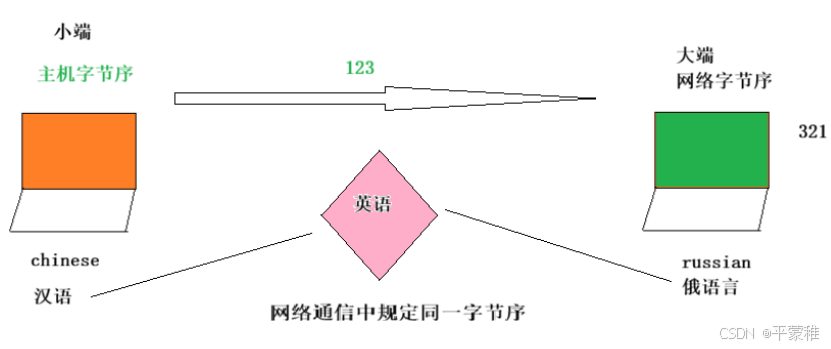
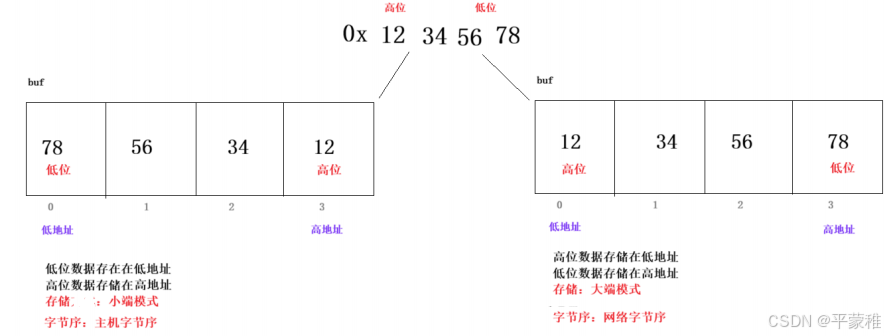
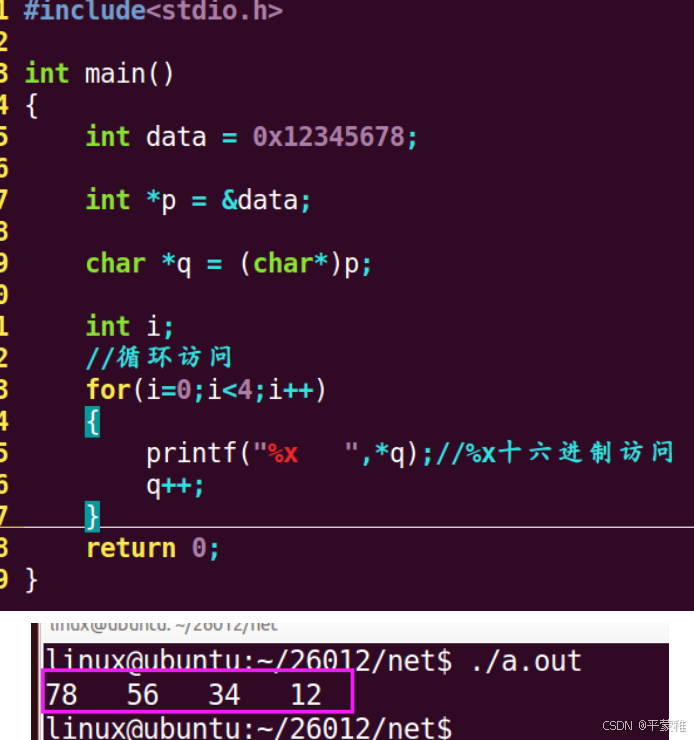
(2)测试本机处理器大小端模式--重点
方法一.*q %x(强转)
方法二:
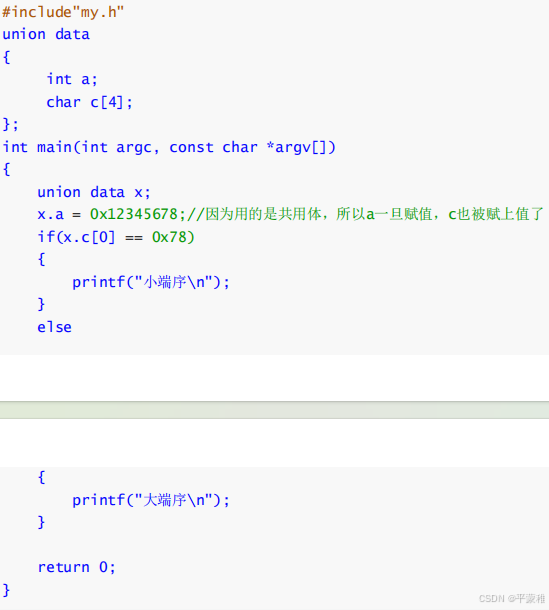
(3)字节序转换(端口转换)
主机字节序转网络字节序主机字节序 ----> 网络字节序 本质上就是 小端模式 -----> 大端模式h //host 主机n //network 网络s //short 短整型l //long 长整型htons () // 将主机字节序的短整型转换为网络字节序htonl () // 将主机字节序的长整型转换为网络字节序
网络字节序转主机字节序网络字节序 ----> 主机字节序 本质上就是 大端模式 -----> 小端模式h //host 主机n //network 网络s //short 短整型l //long 长整型ntohs () // 将网络字节序的短整型转换为主机字节序ntohl () // 将网络字节序的长整型转换为主机字节序
4.套接字理解
套接字(socket)
API application progress interface
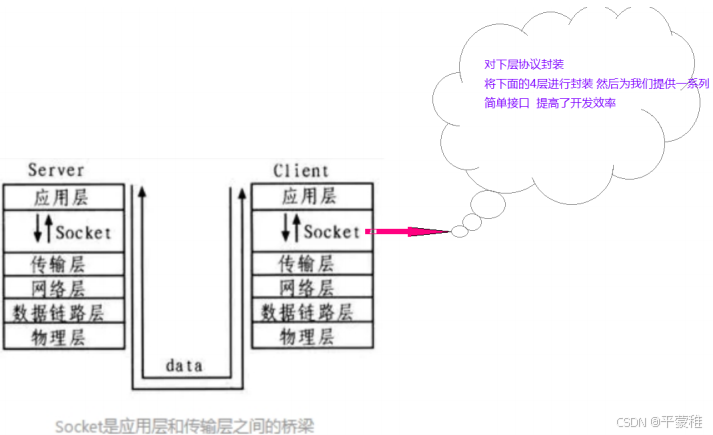
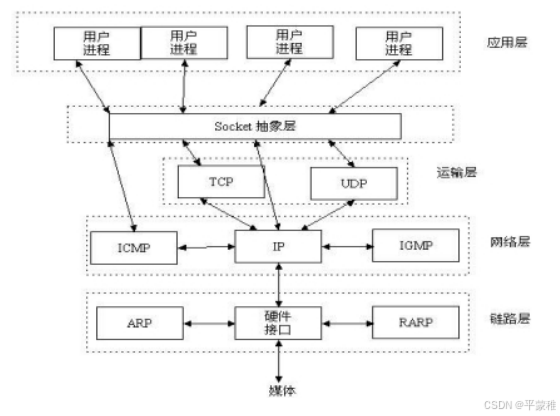
套接字通信原理(全双工)
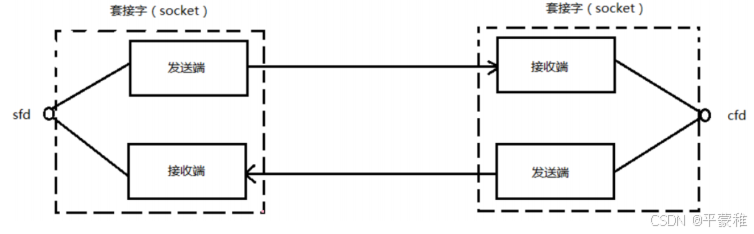
为 TCP/IP 协议设计的应用层编程接口称为 socket API 。
应用层和传输层之间的一个抽象层 是 特殊的 IO 接口 , Linux 下,用于表示进程间网络通信的特殊文
件类型
套接字分类
标准套接字SOCK_STREAM 流式套接字 TCP --SOCK_DGRAM 数据报套接字 UDP --原始套接字 // 开发的是更底层的应用需要使用原始套接字来实现SOCK_RAW 原始套接字
六.UPD通信
1.概要
UDP(User Datagram Protocol)用户数据报协议UDP的优点: 快,比TCP稍快的传输协议UDP的缺点: 不可靠,不稳定 因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。UDP优点:随时发送数据,处理简单高效。
适用:无需创建连接,所以 UDP 开销较小,数据传输速度快,实时性较强。多用于对实时性要求较高的通信场合,如视频会议、电话会议等
2.套接字API
Linux 提供了一系列的套接字(Socket)API,用于在网络编程中创建和管理套接字,实现网络通信
图解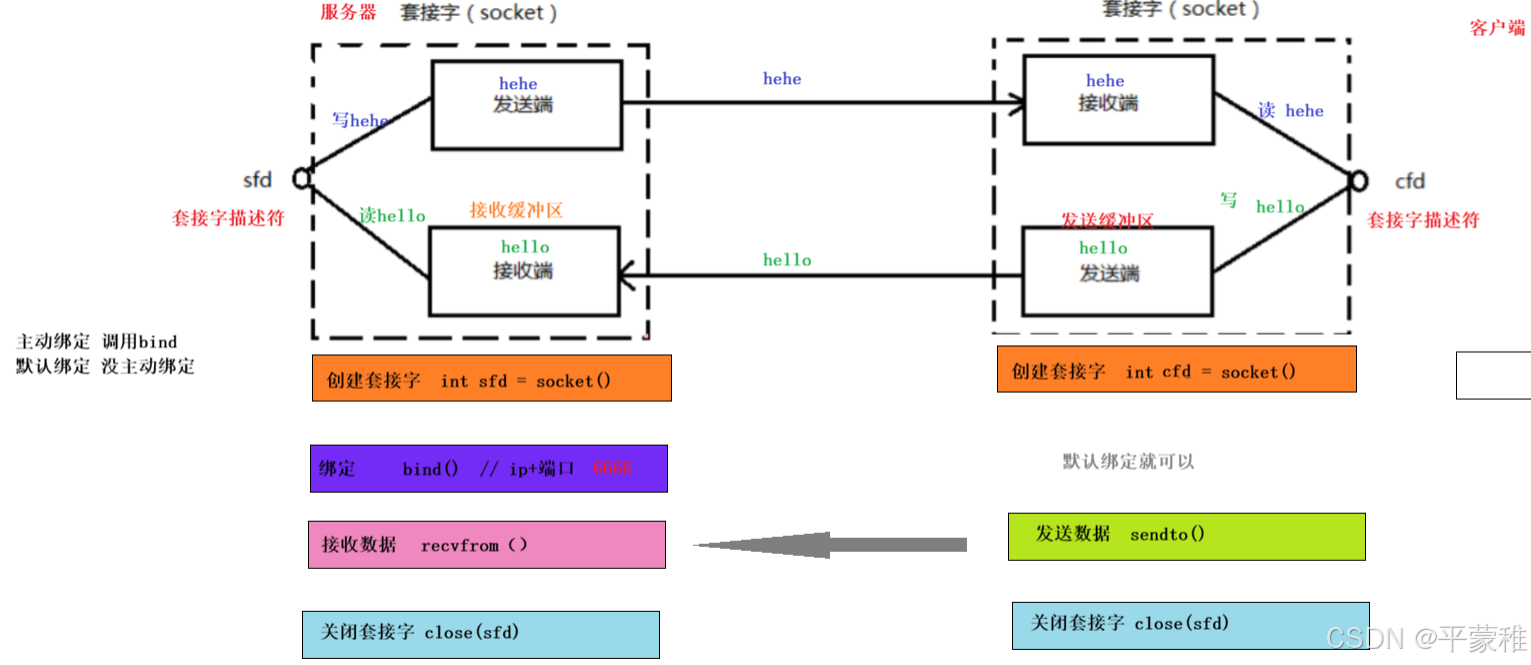
(1)socket创建套接字
示例创建套接字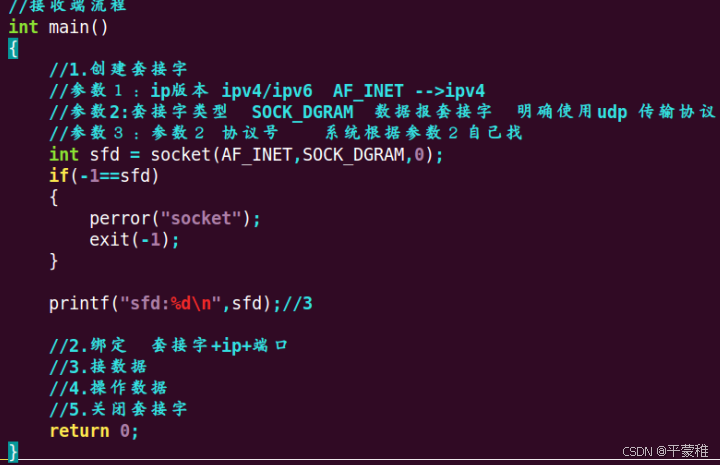

(2)bind绑定
地址信息 =ip+ 端口 + 协议族 (ip 类型 )bind 地址信息+套接字int bind ( int sockfd , const struct sockaddr * addr , socklen_t addrlen );• 功能:绑定• 参数 1 : socket 返回值• 参数 2 : 地址信息• 参数 3 :参数 2 的大小• 返回值:成功 0 失败 - 1
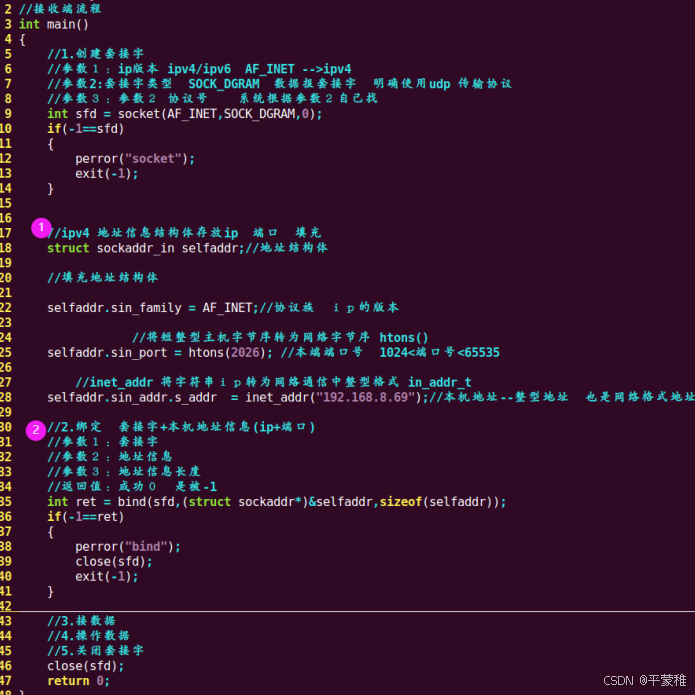
(3)recvfrom接收数据
size_t=unsigned intssize_t recvfrom ( int sockfd , void * buf , size_t len , int flags , struct sockaddr* src_addr , socklen_t * addrlen );功能:接受数据参数 1 : socket 返回值参数 2 :存放收到的数据参数 3 :参数 2 的大小参数 4 :如果没有数据到来 阻塞等待还是不等待 0 表示阻塞 MSG_DONTWAIT 不等待参数 5 :发送方的地址信息参数 6 :发送方地址信息长度 ** 注意:传的实参必须初始化 **返回值:成功返回收到的字节数 失败 - 1 ssize_t 有符号整型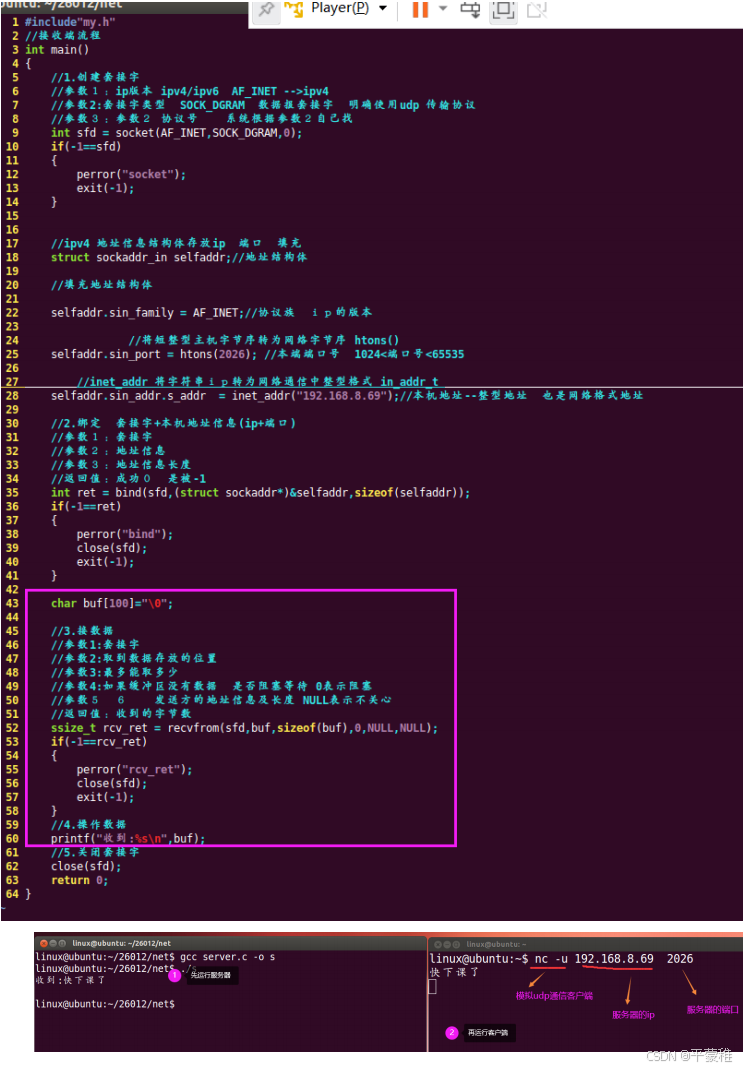
(4)close(套接字)
(5)模拟客户端
客户端: nc - u 192.168 . 0.11 8888//192.168.0.11 8888 服务器端的 ip 和端口
(6)注意
bind(关心 最后两个参数就都接收 不关心就都NULL 不能一个NULL 另一个接收的 会段错误接收数据 不关心地址信息 NULL NULL)
INADDR_ANY
就是指定地址为 0.0.0.0 的地址 任意地址,也可只写一个0INADDR_ANY 已经定义为一个网络字节序的常量 最好使用标准的 INADDR_ANY 常量而不是直接用0 来替代它// 让服务器端计算机上的全部网卡的 IP 地址均可以做为服务器 IP 地址,也即监听外部客户端程序发送到服务器端全部网卡的网络请求例如:填充本地地址信息struct sockaddr_in s ;s . sin_family = AF_INET ; //IPV4s . sin_port = htons ( 49160 )s . sin_addr . s_addr = INADDR_ANY ; // 绑定服务器所有网卡 ip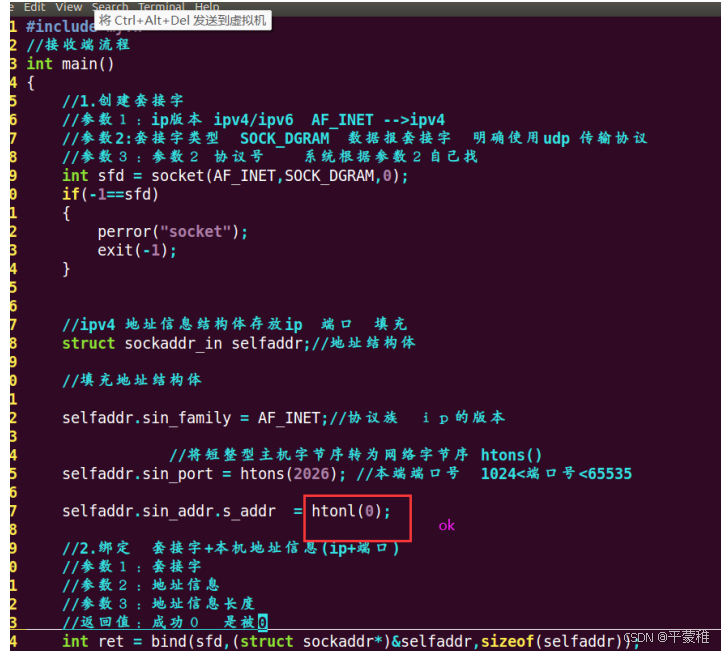
(7)综合使用案例
不关心对方地址:
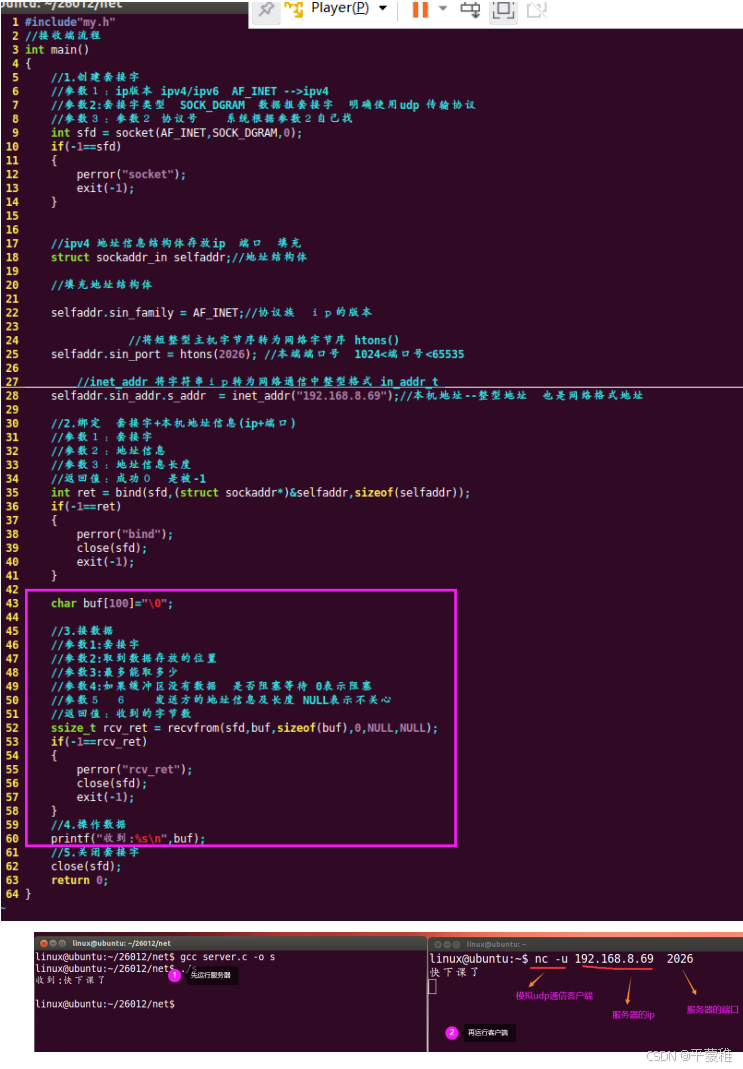
关心:
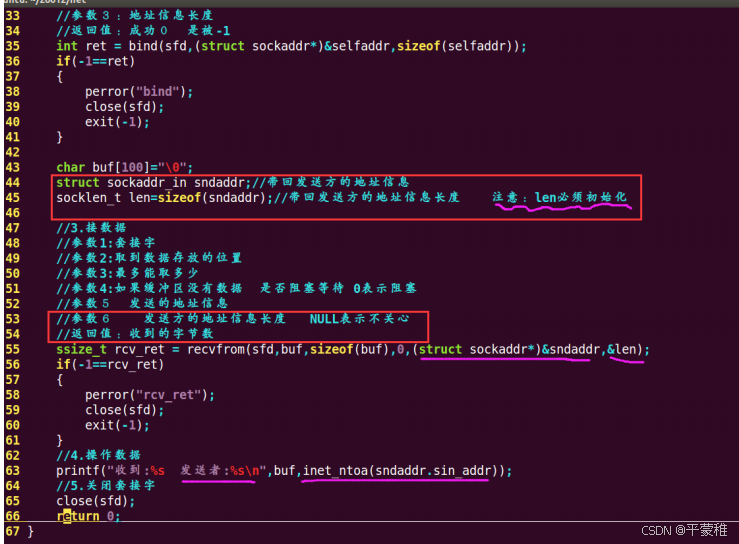
(8)sendto函数发送数据
ssize_t sendto ( int sockfd , const void * buf , size_t len , int flgs , const structsockaddr * dest_addr , socklen_t addrlen );功能:发送数据给对方参数 1 : socket 返回值参数 2 :存放要发送的数据参数 3 :参数 2 的大小参数 4 :套接字缓存满 阻塞还是不阻塞 0 表示阻塞 MSG_DONTWAIT 不阻塞参数 5 :接收方的地址信息参数 6 :参数 5 的大小返回值:成功返回发送的字节数 失败 - 1
七.TCP通信
1.基知:
(1)概念
- TCP ( Transmission Control Protocol )传输控制协议TCP 的优点: 可靠,稳定TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口控制、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。TCP 的缺点: 慢,效率低,占用系统资源高,易被攻击 TCP 在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的 CPU 、内存等硬件资源。 而且,因为 TCP 有确认机制、三次握手机制,这些也导致 TCP 容易被人利用,实现 DOS 、 DDOS 等攻击。
(2)如何选用TCP及UDP传输协议
什么时候应该使用 TCP :当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用在日常生活中,常见使用 TCP 协议的应用如下(都是基于 tcp 协议工作的): 浏览器,用的 HTTPOutlook ,用的 POP 、 SMTPQQ (腾讯 QQ )主要使用 TCP 协议进行大部分的通信,包括消息传输和文件传输。 TCP 提供了可靠的、按序交付的数据传输,这对于即时消息和文件传输非常重要。什么时候应该使用 UDP :当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用 UDP 。比如,日常生活中,常见使用 UDP 协议的应用如下: QQ 语音 QQ 视频
TCP特点
面向连接 传输层协议能提供可靠的 数据无丢失 数据无失序 数据无重复到达适用于传输质量要求高以及传输大量数据的情况
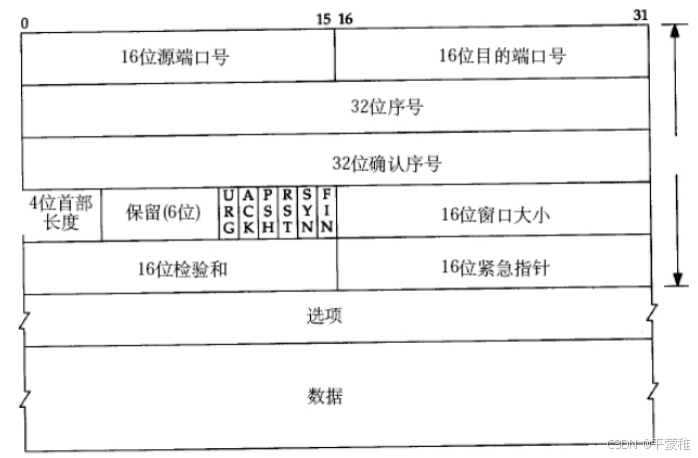
(3)TCP报文段格式
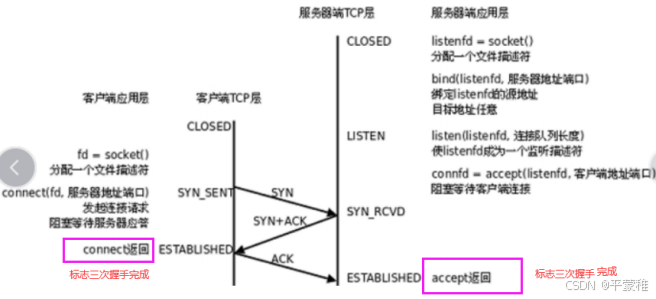
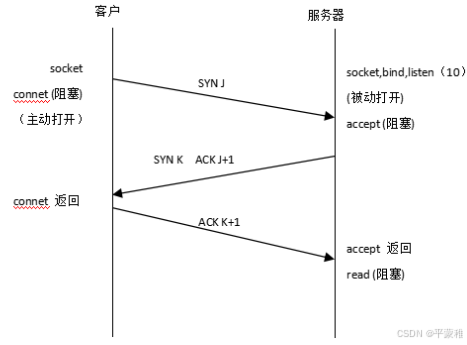
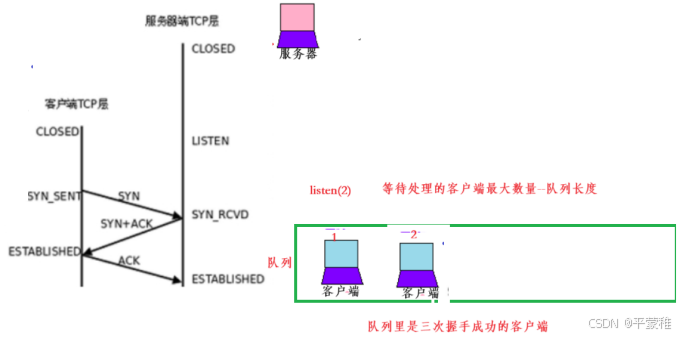
2.TCP连接(三次握手)
(1)过程
服务器必须准备好接受外来的连接。这通过调用socket、 bind和listen函数来完成,称为被动打开(passive open)。第一次握手:客户通过调用connect函数进行主动打开。这引起客户TCP发送一个SYN标志位(表示请求连接)并进入SYN_SENT状态,等待服务器的确认。第二次握手:服务器必须确认客户的SYN,同时自己也得发送一个SYN请求服务器向客户发送SYN请求和对客户SYN的ACK(表示确认/应答),此时服务器进入SYN_RCVD状态。第三次握手:客户收到服务器的SYN+ACK。向服务器发送确认ACK 发送完毕,客户服务器进入ESTABLISHED状态,完成三次握手。状态变化时序图: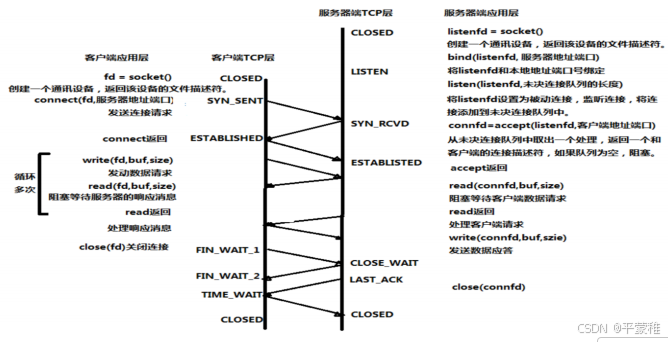
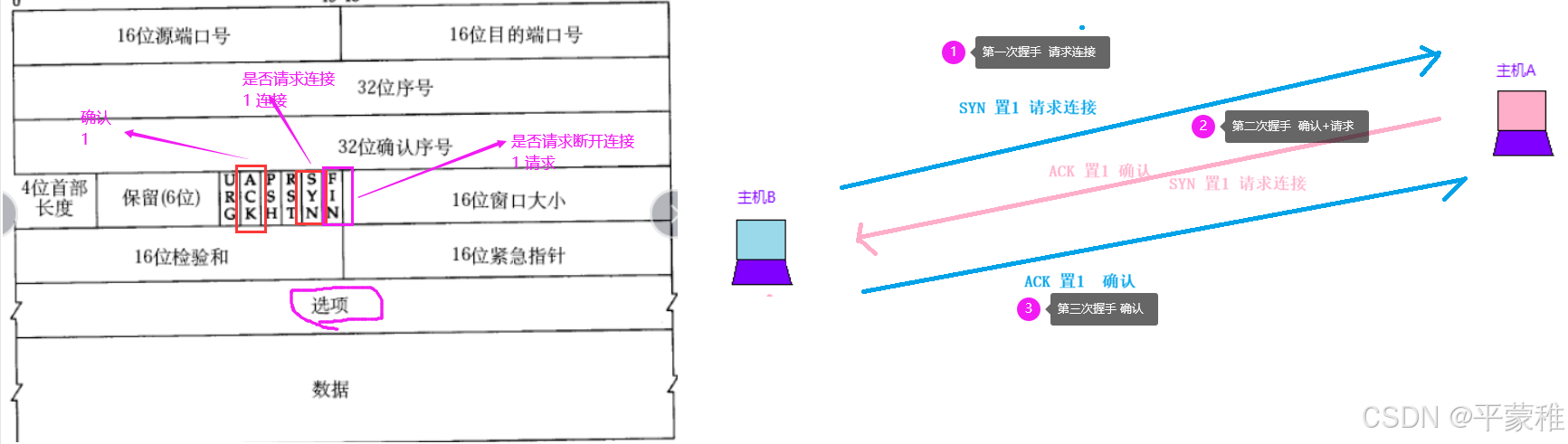
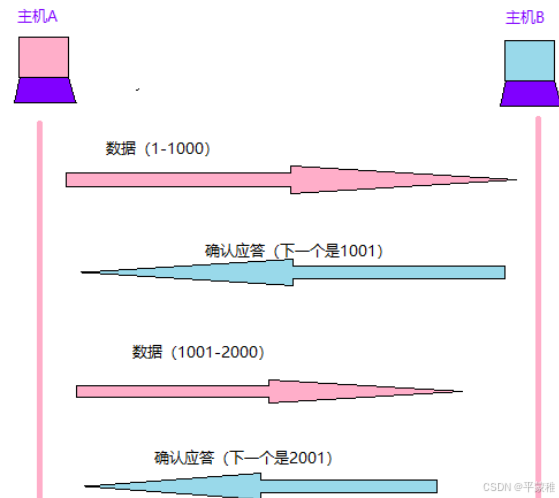
(2)TCP通信流程-确认应答的数据传输
在 TCP 中,当发送端数据到达接受主机时,接收端主机会返回一个已收到的消息的通知。这个消息叫做确认应答(ACK , PositiveAcknowledgement )。当发送端将数据发出之后会经过特定的时间间隔等待对端的 ACK 。如果有 ACK ,说明数据已经成功到达对端,再发送下一个数据。
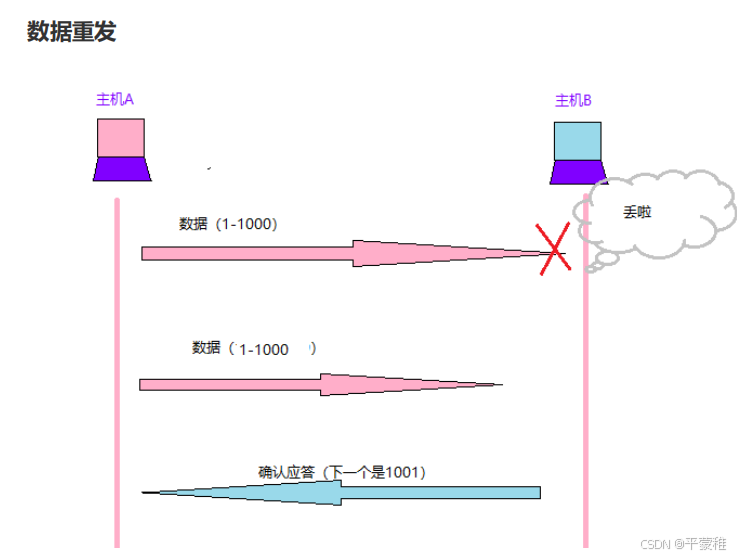
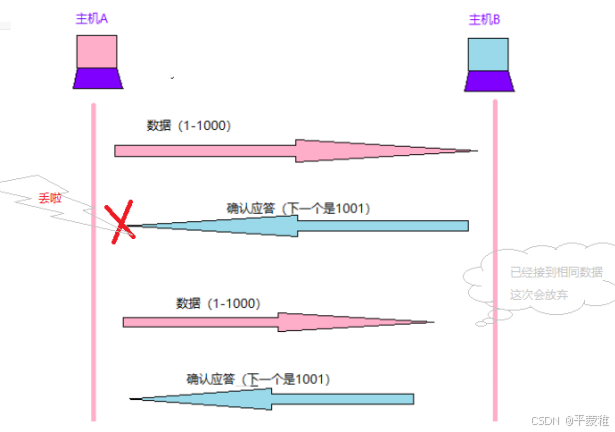
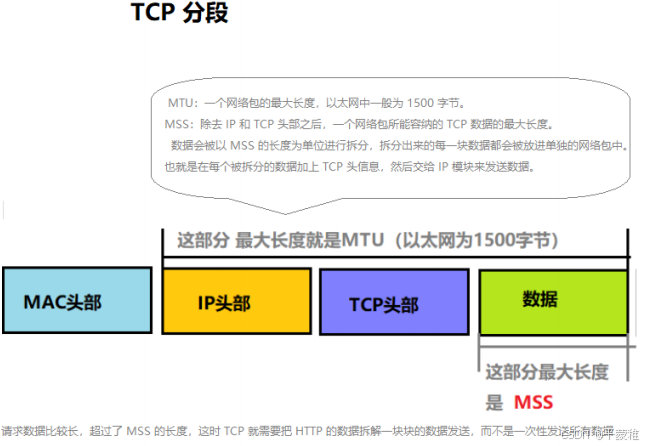
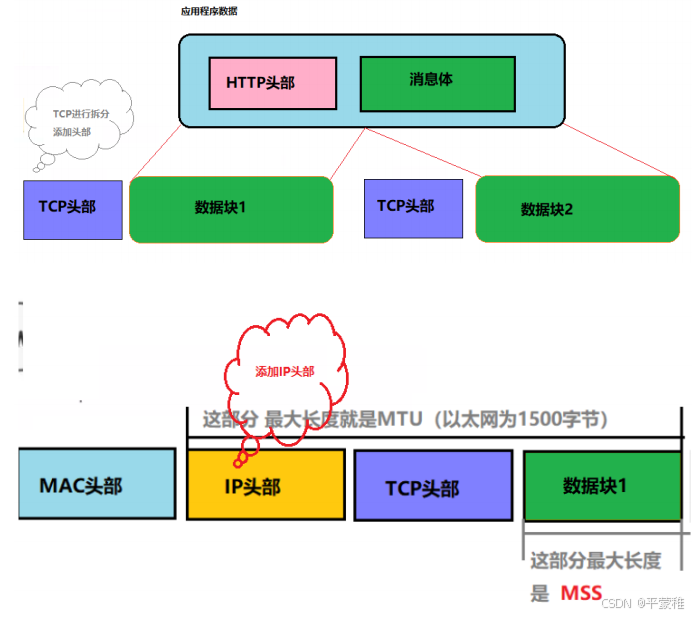
(3)TCP分段
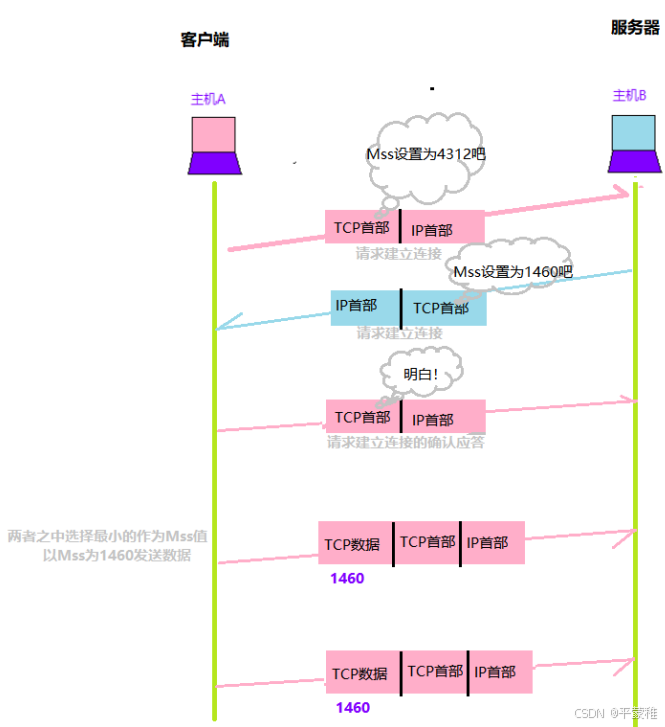
握手时协商MSS值-了解:假如 TCP 不分段的话 , 需要传输一大份数据的时候 , 有可能数据丢失了 , 那么 TCP 就得传输整份完整的数据 , 而分段的话 , 丢失了哪一块就传哪一块 , 提高了效率 .MSS (最大消息长度):发送数据包的单位。 MSS 位于 TCP 首部的可选项中 , MSS 选项用于在 TCP 连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度TCP 传输数据时,以 MSS 的大小将数据进行分割发送。MSS 是在三次握手时,通信双方就需要协商 MSS 值 [ TCP 最大报文段值 ] ,取两端主机能够适用的 MSS 的最小值。以太网报文最大值 MTU [ Maximum Transmission Unit ], 通常为 1500 字节MSS = TCP 数据部分, MTU = TCP 数据部分 + TCP 首部 + IP 首部;最理想情况下: MSS + TCP首部+IP首部 = MTU MSS = MTU - tcp头部20字节 - IP头部20字节 = 1460字节假设 MTU = 1500 byte ,那么 MSS = 1500 - 20 ( IP Header ) - 20 ( TCP Header ) = 1460 byte ,如果应用层有 2000 byte 发送,那么需要两个切片才可以完成发送,第一个 TCP 切片 = 1460 ,第二个 TCP 切片 = 540 。
3.断开连接(四次挥手)
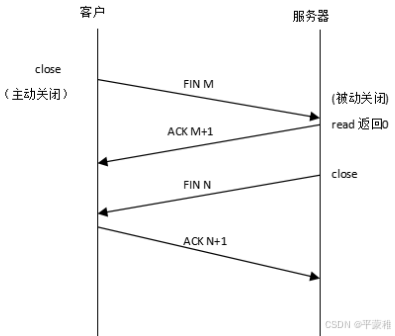
(1)TCP四次挥手连接终止过程
第一次挥手:假设客户端打算关闭连接,发送一个 TCP 首部 FIN 被置 1 的 FIN 报文给服务端。第二次挥手:服务端收到以后,向客户端发送 ACK 应答报文。第三次挥手:等待服务端处理完数据后,向客户端发送 FIN 报文。第四次挥手:客户端接收到 FIN 报文后回一个 ACK 应答报文。服务器收到 ACK 报文后,进入 close 状态,服务器完成连接关闭。客户端在经过 2MSL ( linux 操作系统中大概 1 分钟)一段时间后,自动进入 close状态,至此客户端也完成连接的关闭
为什么挥手需要四次?关闭连接时,客户端发送 FIN 报文,表示其不再发送数据,但还可以接收数据。服务端收到 FIN 报文,先回一个 ACK 应答报文,服务端可能还有数据需要处理和发送,等到其不再发送数据时,才发送FIN 报文给客户端表示同意关闭连接。从上面过程可知,服务端通常需要等待完成数据的发送和处理,所以 服务端的 ACK 和 FIN 一般都会分开发送,从而比三次握手多了一次
4.TCP通信模型(图解)
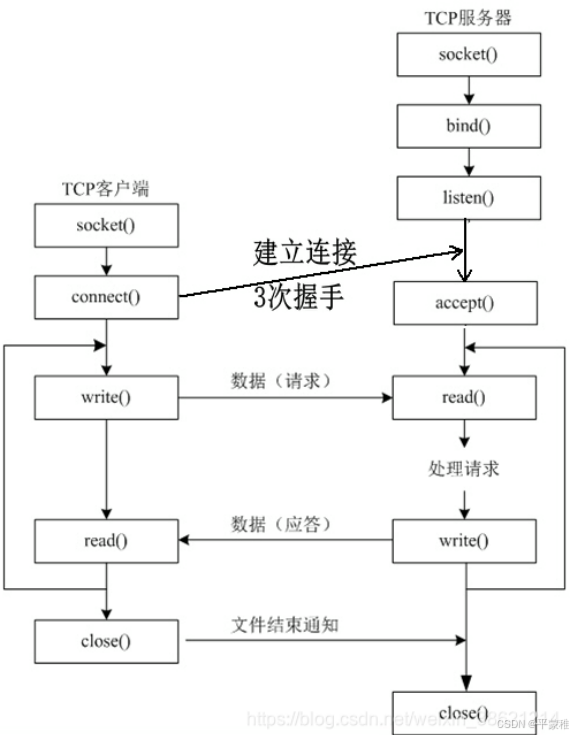
5.🔺套接字API-重点
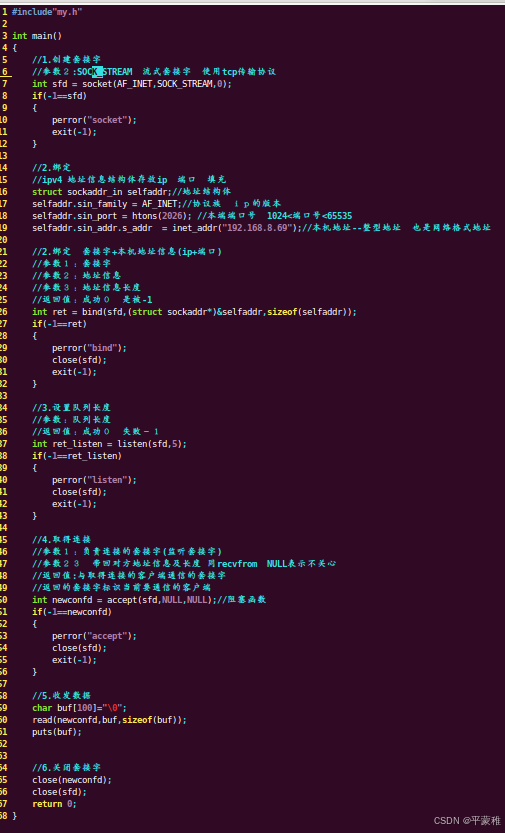
(1)服务器端
图解:
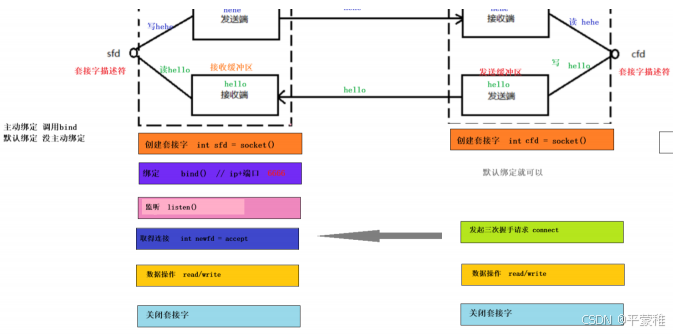
listen监听
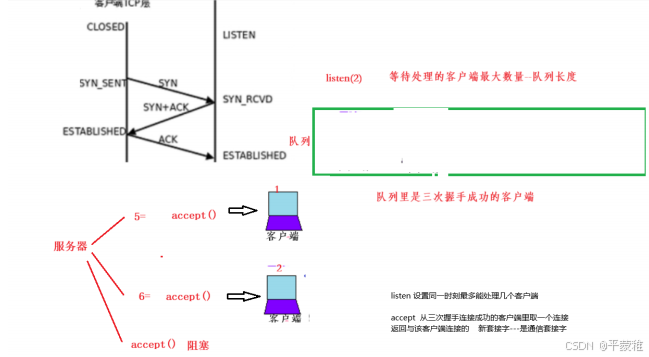
#include <sys/types.h> /* See NOTES */• #include < sys / socket . h >• int listen ( int sockfd , int backlog );• 功能:监听(将未连接的套接字 sockfd 转为被动连接的套接字 指示内核应接受该套接字的连接请求)• 参数 1 : 成功创建的 TCP 套接字 socket 函数返回值• 参数2 : 等待队列长度(未决连接的队列长度)// 该队列虽然已经完成了三次握手,但服务器端还没有执行 accept 接受连接 这些连接处于已连接(established )状态• 返回值:成功 0 失败 - 1
未决连接队列 / 未处理的连接队列 / 已连接队列 : 客户端已经成功连接服务器,但是服务器还没有接收的连接称为未决连接当第三次握手完成了,这个连接就变成了 ESTABLISHED 状态 , 将其放入未决连接队列中调用 accept 已完成连接队列的队头将返回给进程 如果队列为空 则继承睡眠 直到队列中放入一项才唤醒
图解
accept接收
#include <sys/types.h> /* See NOTES */• #include < sys / socket . h >• int accept ( int sockfd , struct sockaddr * addr , socklen_t * addrlen );• 功能:从未决连接队列中取出一个进行处理 , 返回连接描述符(阻塞等待客户端连接 并取得对方地址信息)// accept 用于从指定套接字的连接队列中取出第一个连接,并返回一个新的套接字用于与客户端进行通信 原来的套接字仍然处于监听状态• 参数:• sockfd : 处于监听状态的套接字• addr : 对方的地址信息 不关心可以传递 NULL• addlen : 对方地址信息长度 传递的参数必须初始化 不关心可以传递 NULL• 返回值:成功会返回一个与客户端连接的新的套接字 失败 - 1
实例 :服务器端实现 --不关心对方地址信息
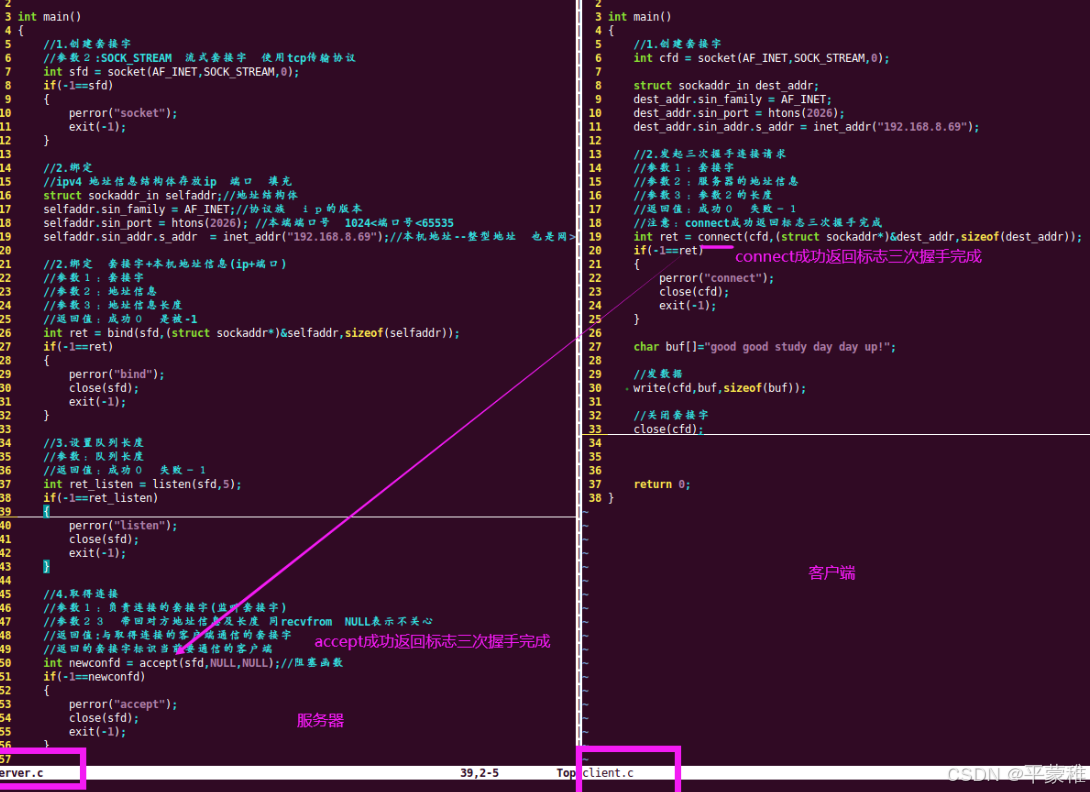
(2)客户端connect
#include <sys/types.h> /* See NOTES */• #include < sys / socket . h >• int connect ( int sockfd , const struct sockaddr * addr , socklen_t addrlen );• 功能:客户端连接服务器 ( 发起连接请求 完成三次握手 )• 参数:• sockfd : 套接字 socket 函数返回值• addr : 服务器端地址信息• addrlen : 服务器端地址信息长度// 默认是一个阻塞操作• 返回值:成功 0 失败 - 1
实例:
(3)send(发送数据)
ssize_t send ( int sockfd , const void * buf , size_t len , int flags ); //write// 数据发送到套接字发送缓冲区 真正的发送数据是协议来完成的。参数:sockfd :套接字文件描述符。buf :要发送的数据缓冲区的指针。len :要发送的数据长度。flags :传输控制标志,通常设置为 0 。如果套接字缓冲区满 --- 阻塞返回值:返回实际发送的字节数。失败 - 1 。
(4)recv(接收数据)
ssize_t recv ( int sockfd , void * buf , size_t len , int flags ); //read 阻塞函数参数:sockfd :套接字文件描述符。buf :接收数据的缓冲区指针。len :最多接收多少字节的数据。flags :接收标志,通常设置为 0 。如果套接字缓冲区没有数据 -- 阻塞返回值:返回接收到的字节数。如果返回值为 0 ,表示连接已关闭;如果返回值为 - 1 ,表示发生错误。
实例:
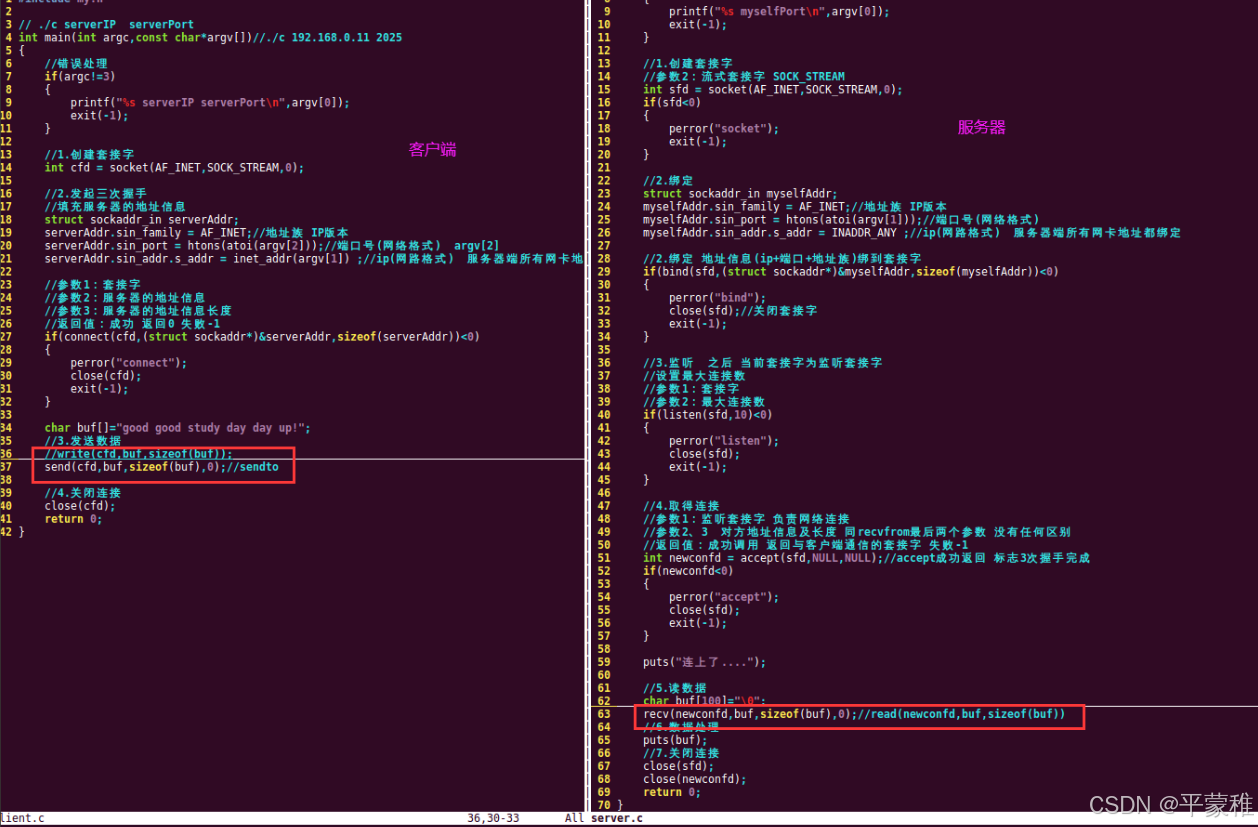
(5)补充
1.ping
两台主机想要链接需要放到同一网络下(可用ping来测试对方是否在线)
ping 192.168.8.22 #功能:查看对方主机是否在线
Ping www . baidu . com ( 110.242 . 68.4 ) 56 ( 84 ) bytes of data .64 bytes from 110.242 . 68.4 : icmp_req = 1 ttl = 51 time = 24.2 ms64 bytes from 110.242 . 68.4 : icmp_req = 2 ttl = 51 time = 23.9 ms64 bytes from 110.242 . 68.4 : icmp_req = 3 ttl = 51 time = 23.9 ms64 bytes from 110.242 . 68.4 : icmp_req = 5 ttl = 51 time = 24.2 ms64 bytes from 110.242 . 68.4 : icmp_req = 6 ttl = 51 time = 25.0 ms64 bytes from 110.242 . 68.4 : icmp_req = 7 ttl = 51 time = 24.1 ms64 bytes from 110.242 . 68.4 : icmp_req = 8 ttl = 51 time = 24.9 msttl 的初始值是 64 或者 128每经过一个路由器, ttl 的值就 - 1ttl = 51 //ping 命令在执行过程中,传输数据包经过路由器的个数现在 ttl 值是 51 , 经过了 64 - 51 = 13 个路由器
可能出现问题:
没有显示网卡(eth0)sudo ifconfig eth0 up // 启动网卡 eth0sudo ifconfig eth0 192.168 . 8. xxx // 修改 ip xxx 范围 :1~254ping不通1 )多等一会2 ) 关闭防火墙 win11 火绒 3603 ) 关闭网络服务 sudo service network - manager stop// 如果 ip 频繁改变 配置 ip 为静态/ etc / network / interfaces4 )两台机器连接同一个 vifi
2.bind报错以及原因
bind: Address already in use原因:1) 服务器程序重复执行2)ctrl+c 退出服务器端就会报错: bind: Address already in use解决: 1)等待1min 2)bind上边调用setsockoptsetsockopt 设置套接字选项功能。函数原型: int setsockopt ( int sockfd , int level , int optname , const void * optval ,socklen_t optlen );// 设置 套接字的 选项功能参数 1 : 套接字描述符。参数 2 : 选项所属协议层。SOL_SOCKET : // 基于套接字参数 3 : 选项名称。SO_REUSEADDR 地址复用参数 4 : 保存选项值。参数 5 : 选项值的长度。返回值: 成功: 0失败: - 1
例如:int on = 1 ;setsockopt ( sockfd , SOL_SOCKET , SO_REUSEADDR , & on , sizeof ( on ));SO_REUSERADDR可以使地址端口马上重用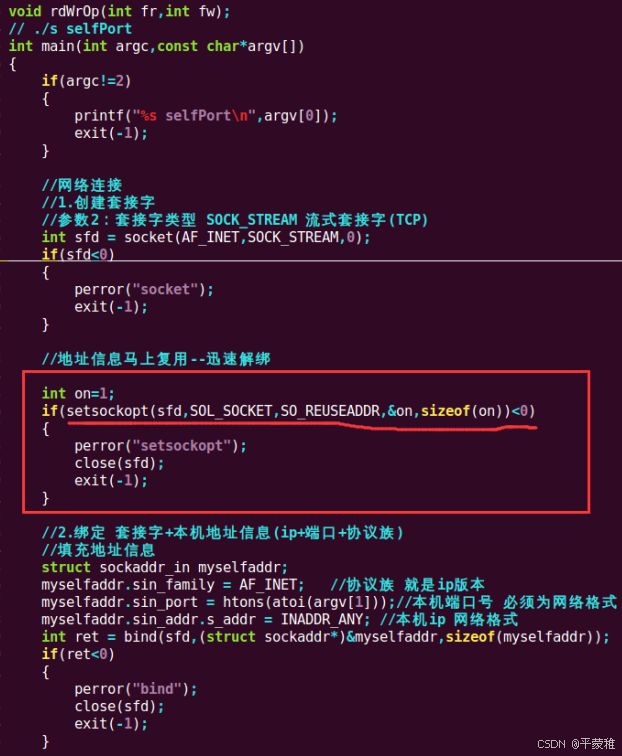
3.如何判断网络连接中对方是否下线????
read / recv 立即返回 返回值为0
read函数返回值> 0 实际读到的字节数= 0 普通文件 - 》到达文件末尾套接字文件 -> 对端下线< 0 出错
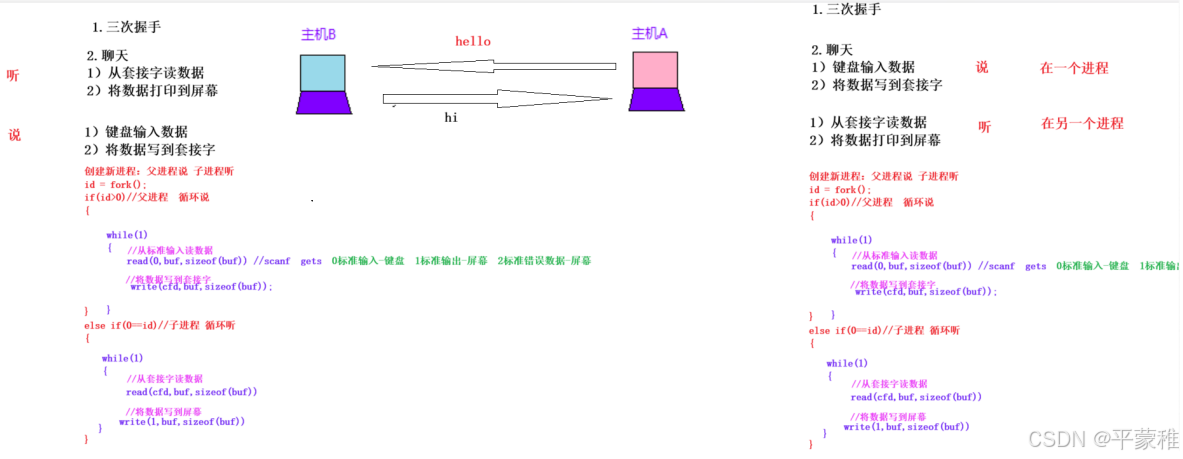
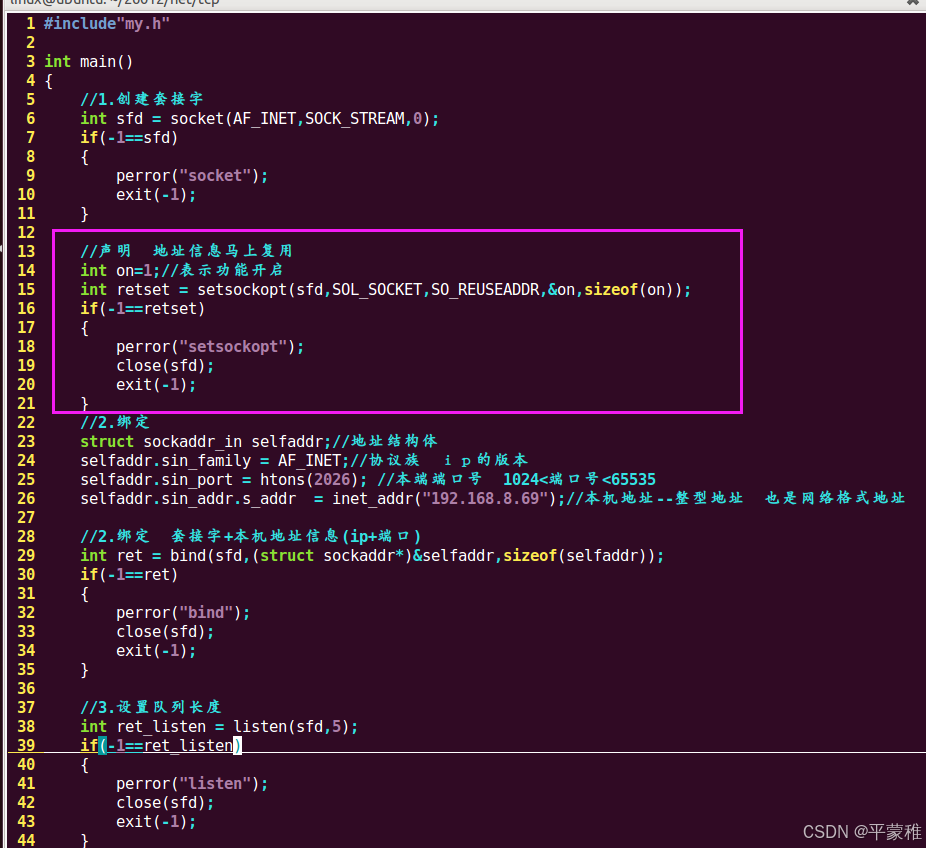
(6)练习两台机器聊天
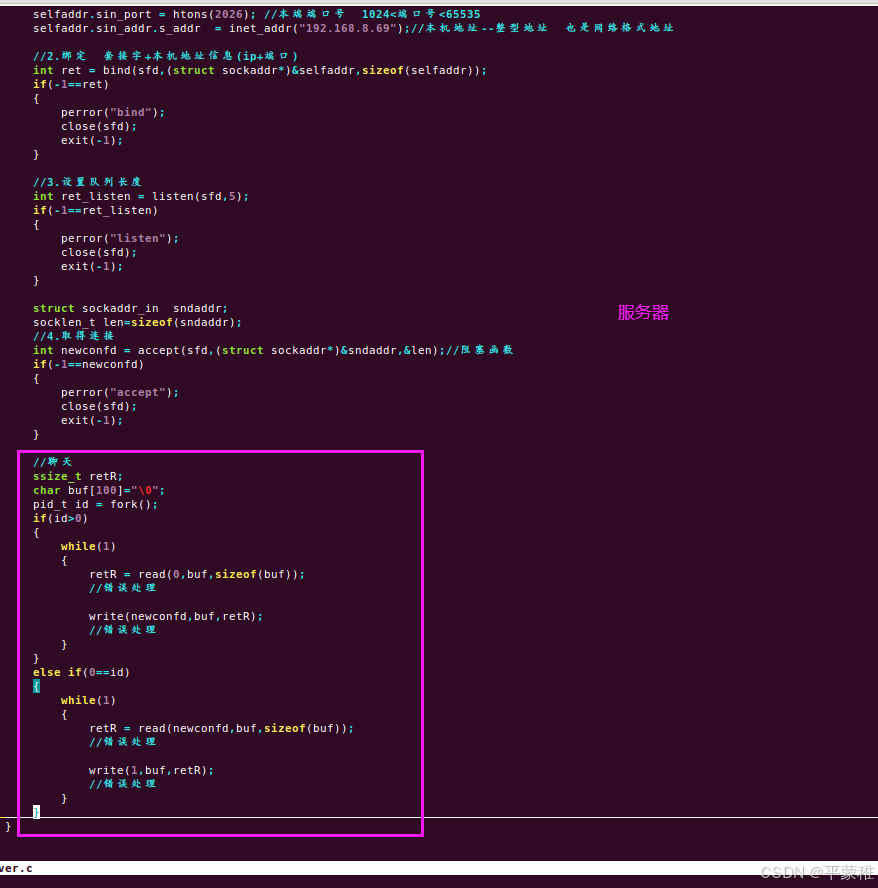
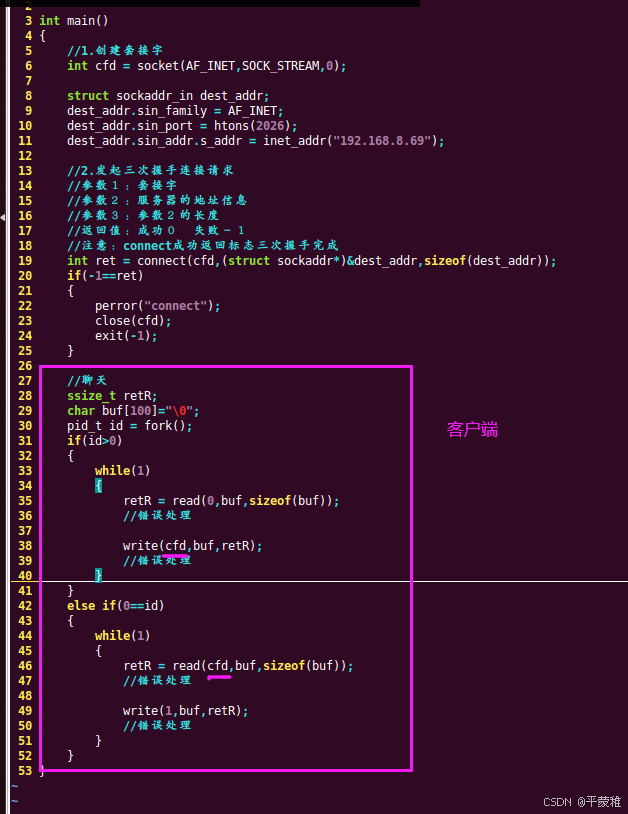
八.IO复用
1.why
为什么需要 I / O 多路复用?场景:一个服务器需要同时处理多个客户端的连接(例如聊天室、游戏服务器等)。如果为每个客户端都创建一个线程 / 进程来处理,当客户端数量非常多时(成千上万),会消耗大量的系统资源(内存、上下文切换开销),效率低下。I / O 多路复用 就是为了解决这个问题:用一个进程 / 线程来同时监视多个文件描述符(如网络套接字socket),一旦某个描述符就绪(可读、可写或发生异常),就能够通知程序进行相应的读写操作。 这样就用单进程 / 单线程实现了并发处理多个 I / O 请求的能力,极大地提升了程序的效率。总结:( 1 ) 多线程和多进程并发服务器,当客户端连接数量特别多的时候,消耗的资源特别大,效率低。( 2 ) 当客户端连接的时候创建线程,断开的时候,销毁线程,频繁的创建和销毁,占用系统开销大。( 3 ) I / O 多路复用可以帮助我们解决上面的问题,既能实现服务器支持多客户端,又能节省资源,降低系统开销。常见的 I / O 多路复用有三种: select ( 基于轮询模式 ) 、 poll 、 epoll ( 基于事件编程 )
2.🔺概念与原理
🔺概念
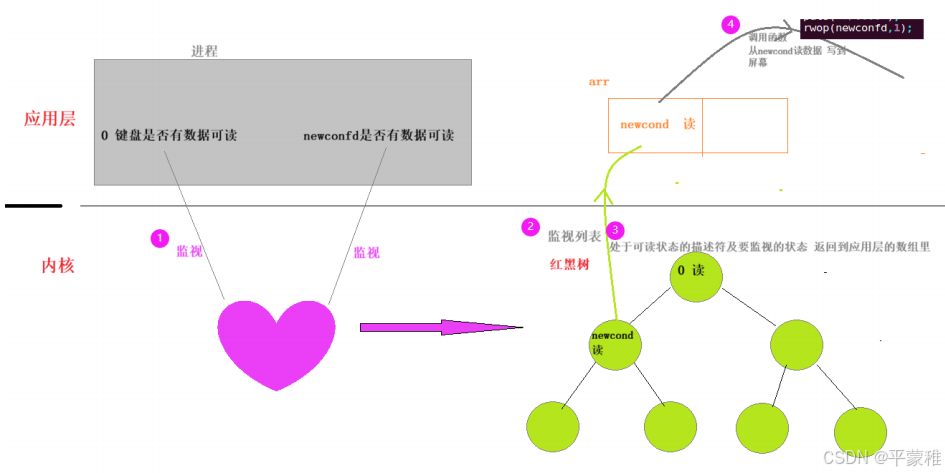
是 linux 内核实现 一个进程(线程)同时监控若干个文件描述符读写情况,这种读写模式称为多路
复用 :其最大优势是系统开销小(不必维护这些线程和进程)(不再由应用程序自己监视文件描述符,取而代之由内核替应用程序监视文件。)
原理:
实现套接字异步通信:IO 多路复用的核心思想是通过一个监听器(如 select 、 poll 、 epoll 等)来管理多个 I / O 操作。程序将需要监听的文件描述符(如套接字)注册到监听器上,并告诉监听器关注的事件类型(如读就绪、写就绪)。当任何一个文件描述符准备好时,监听器会通知程序,程序再根据具体的事件进行处理。
3.实现epoll
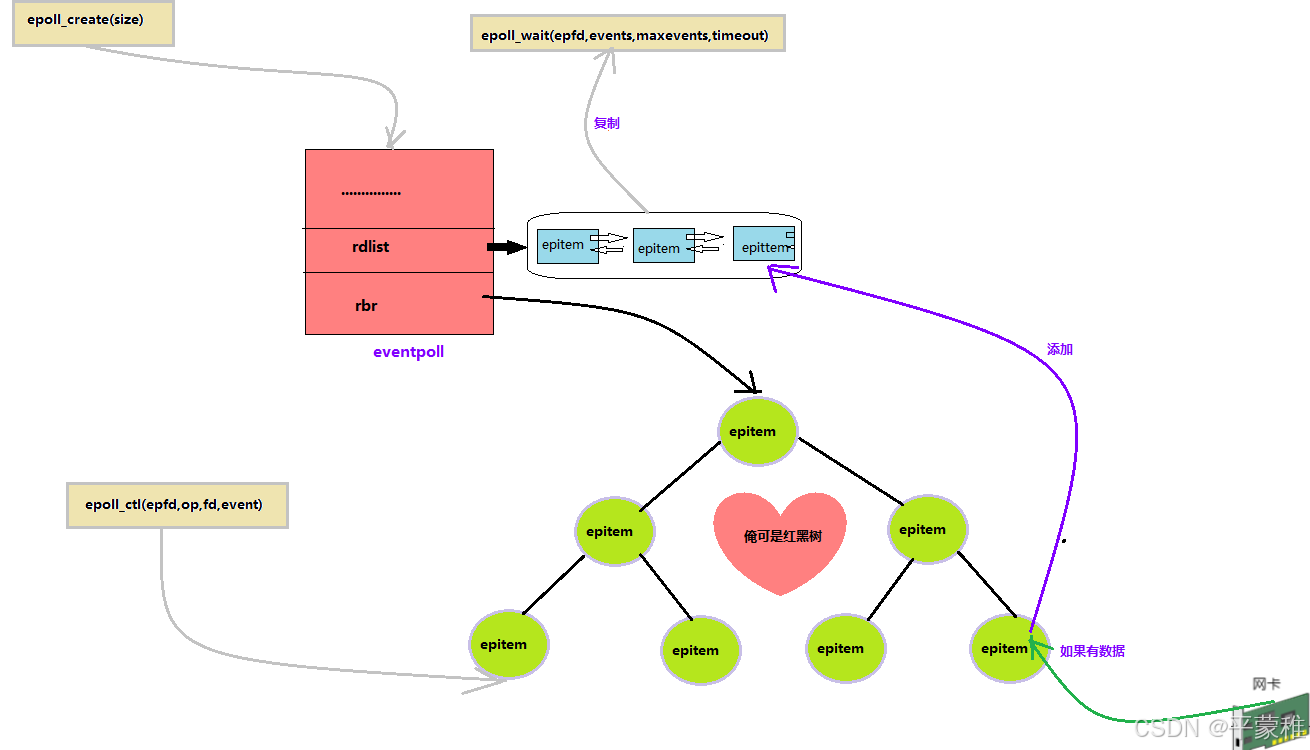
epoll全名 eventpoll
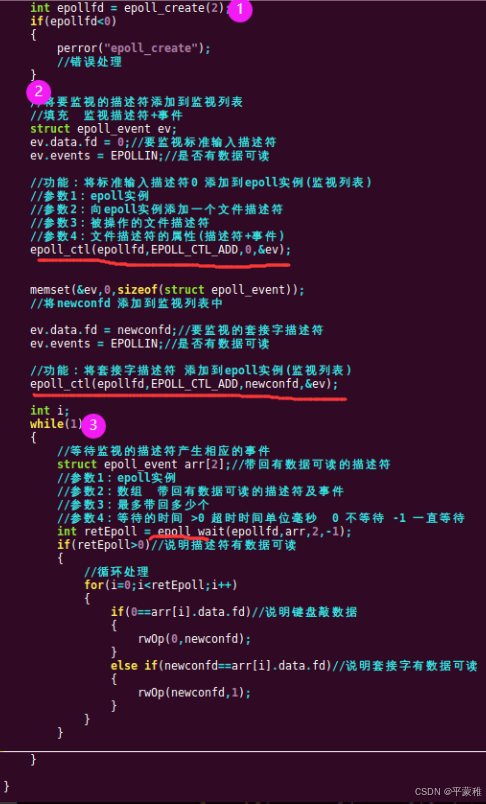
1.epoll_create
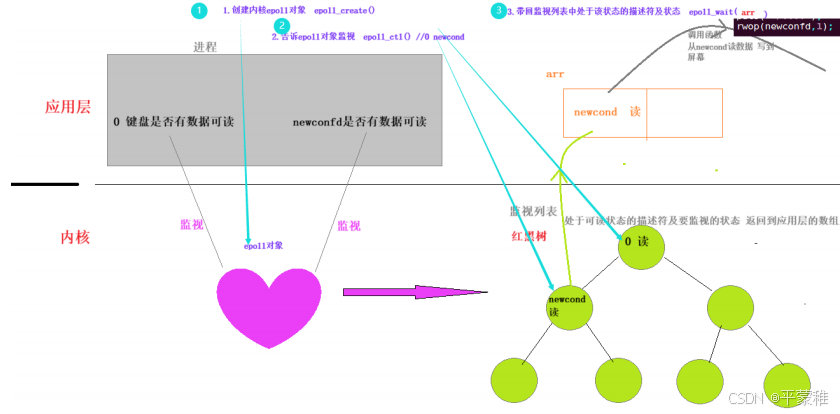
#include <sys/epoll.h>int epoll_create ( int size );功能:创建一个 epoll ( 内核创建红黑树 初始化就绪队列 ) 实例 , 用于管理多个文件描述符的事件参数: eventpoll 能够监听的最大文件描述符个数 内核没有实际使用(在 linux 2.6 . 8 版本后被忽略,大于0即可)返回值:> 0 eventpoll 的文件描述符- 1 出错示例:int epollfd = epoll_create ( 5 );
2.🔺epollctl
int epoll_ctl ( int epfd , int op , int fd , struct epoll_event * event );功能:将一个文件描述符添加 / 删除 / 修改到 epoll 的监视列表中参数 1 : epoll_create 的返回值参数 2 :指定对文件描述符的操作类型EPOLL_CTL_ADD : 向 epoll 实例中添加一个文件描述符及其事件EPOLL_CTL_DEL : 从 epoll 实例中删除一个文件描述符EPOLL_CTL_MOD : 修改已经注册在 epoll 实例中的文件描述符的事件参数 3 :需要操作的文件描述符参数 4 :文件描述符的属性返回值:成功返回 0 ,失败返回 - 1struct epoll_event{uint32_t events ; // 表示关注的事件类型epoll_data_t data ; // 用户数据,一般只用其 fd 这个成员,填入要监视的文件描述符};// 用户数据,可以存储文件描述符或其他自定义数据// 是一个联合体,可以存储以下几种类型之一typedef union epoll_data{void * ptr ;int fd ; //// 要监视的文件描述符uint32_t u32 ;uint64_t u64 ;} epoll_data_t ;常用的事件集合:EPOLLIN :可读事件。(包括对端 SOCKET 正常关闭)EPOLLOUT :可写事件。同时设置多个事件用 ‘ | ’ 链接,如 EPOLLIN | EPOLLOUT示例:struct epoll_event ev ;ev . data . fd = 0 ; // 例如要监视 0ev . events = EPOLLIN ; // 监视该套接字是否有数据可读epoll_ctl ( epollfd , EPOLL_CTL_ADD , socketfd , & ev );
3.epollwait
int epoll_wait ( int epfd , struct epoll_event * events , int maxevents , inttimeout );功能:等待监听的所有的 fd 产生相应的事件参数 1 : epoll_create 的返回值参数 2 :出参 epoll_event 数组的首地址( epoll 把发生的事件的集合从内核复制到 events 数组中)events不可以是空指针,内核只负责把数据复制到这个 events 数组中,不会去帮助我们在用户态中分配内存)参数 3 : epoll_event 数组的长度(最多返回的事件数量)参数 4 : > 0 是超时时间,单位毫秒, - 1 :为阻塞等待, 0 :为不阻塞 立即返回返回值:成功返回要处理的 fd 的个数,超时返回 0 (表示等待指定的毫秒数后返回,即使没有事件发生),失败返回 - 1总结:返回有多少文件描述符就绪,时间到时返回 0 ,出错返回 - 1// 执行完 epoll_wait 之后, epoll 会把所有需要处理的 fd 复制到 events 数组中,用户可以通过遍历 events组,来依次处理事件
实例:
4.epoll的两种触发方式--了解
epoll 有两种触发方式: LT( 水平触发 ) 和 ET( 边缘触发 )LT( 水平触发)全称 level-triggered ET全称 edge-triggeredLT:默认的读取方式,当 epoll 通过 epoll_wait 通知某个 fd 需要读取数据时,如果你没有读取或只读取了一部分,下次调用epoll_wait 时,会将这个 fd 再次返回给你, LT 模式下,文件描述符可以是阻塞的或非阻塞的容错性较好,不易丢失事件。更易于编程和理解。可以用于多线程程序中,多个线程可以共享同一个 epoll 文件描述符ET:高速读取模式,当 epoll 通过 epoll_wait 通知你某个 fd 需要读取数据时,如果你没有读取或只读取了一部分,下次调用epoll_wait 时,内核默认你知道这个 fd 需要读取数据,不会将这个 fd 再次返回给你,当网络中再有一次数据发送到这个fd 时,才会将这个 fd 返回给你, ET 模式下,文件描述符必须是非阻塞的效率更高,因为它减少了事件的重复通知。需要更加小心地处理每次通知,确保处理所有的数据,否则可能会丢失未处理完的数据。更适合单线程或者每个线程使用独立 epoll 文件描述符的场景。
5.🔺select poll epoll的区别(重点)
epoll:0 newconfd(500) 可读select: 0 1 2 3 4 。。。500 轮询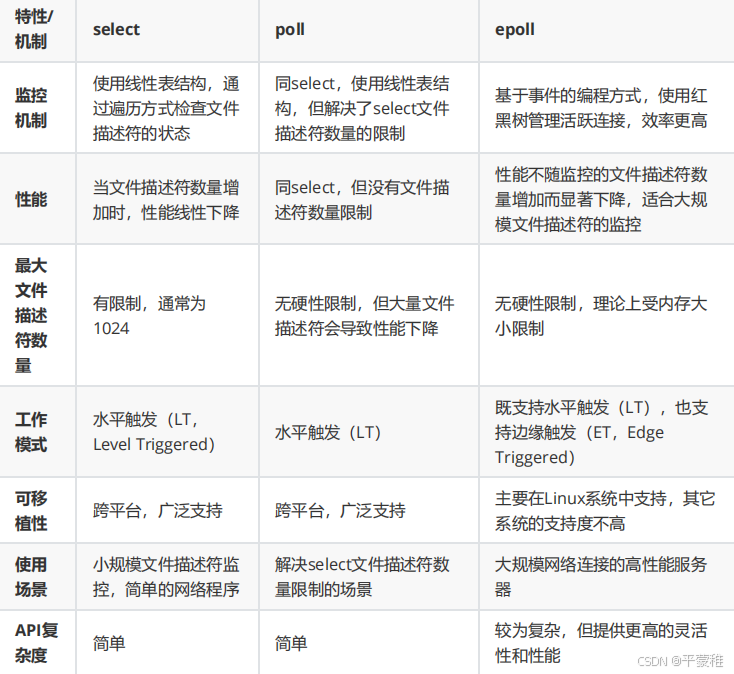
6.epoll优缺点
优点:epoll 是 Linux 系统中一种高效的 I/O 事件通知机制,它是 select/poll 的改进版本,属于 Linux 特有的 I/O 多路复用技术。高效性: epoll 使用了红黑树和事件链表两种数据结构来管理文件描述符,这使得它在大量文件描述符的情况下具有更高的性能。相比 select 和 poll , epoll 可以避免轮询和线性扫描带来的性能开销,因此在大规模并发的场景下性能更好。可扩展性: epoll 支持水平触发( LT , Level - Triggered )和边缘触发( ET , Edge - Triggered )两种工作模式,同时也支持多种操作系统事件类型,包括读、写、错误等。这种灵活性使得 epoll 能够更好地适应各种场景的需求。内核与用户空间交互少: 在 epoll 中,内核只需要向用户空间传递已经就绪的事件,而不需要传递整个事件列表,因此与 select 和 poll 相比,内核与用户空间之间的数据交换更少,减少了系统调用的开销。
缺点:Linux 特定: epoll 是 Linux 特有的系统调用,因此不具有跨平台特性。如果需要编写跨平台的代码,可能需要使用其他多路复用机制,如 select 或 poll 。资源消耗: epoll 使用红黑树来管理文件描述符,当文件描述符数量较大时,红黑树的维护会带来额外的内存开销。此外,epoll 会为每个文件描述符分配一个事件结构体,如果需要管理大量文件描述符,可能会消耗较多的内存。复杂性: 相对于 select 和 poll , epoll 的使用可能稍微复杂一些综上所述,尽管 epoll 在性能和扩展性方面具有明显的优势,但也需要权衡其对系统资源的消耗以及使用上的复杂性。在合适的场景下,选择适当的 I / O 多路复用机制是很重要的。
7.epoll工作原理
通过调用 epoll_create () 函数创建并初始化一个 eventpoll 对象。通过调用 epoll_ctl () 函数 内核把被监听的文件描述符封装成 epitem 对象 ( 每个节点里都有一个epoll_event 结构体成员 ) 并且添加到 eventpoll 对象的红黑树中进行管理红黑树:它是一个基于平衡二叉搜索树的数据结构,每个红黑树节点代表一个文件描述符,并且包含了该文件描述符所关注的事件类型(读、写等)。红黑树按照文件描述符大小进行排序通过调用 epoll_wait () 函数等待被监听的文件描述符事件发生当被监听的文件事件发生时(如套接字接收到数据),内核会把文件描述符对应 epitem 对象添加到eventpoll 对象的就绪队列 rdlist (内核维护) 中。并且把就绪队列的文件列表复制到 epoll_wait () 函数的 events 参数中。唤醒调用 epoll_wait () 函数被阻塞(睡眠)的进程当应用程序不再需要监视某个文件描述符时,可以使用 epoll_ctl 函数并指 EPOLL_CTL_DEL 操作来将其从 epoll 实例中删除。
九.服务器
1.服务器模型
服务器数目至少 一个或多个 代码大 处理客户端请求客户端数目多 代码少 向服务器发请求
比喻: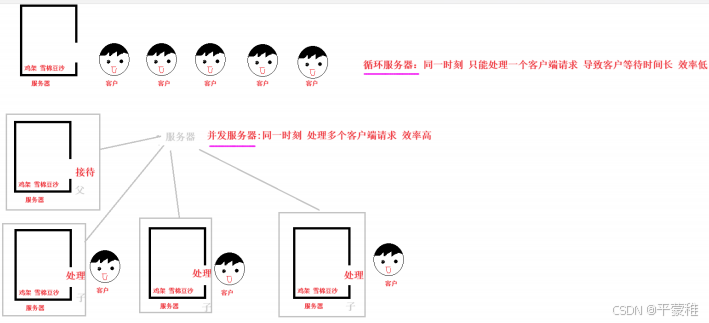
2.TCP循环服务器
同一时刻 只能响应一个客户端请求 依次处理每个客户端 后边的客户端必须等待前面的处理完 效率低 等待时间长
3.TCP并发服务器
同一时刻 能响应多个客户端请求 同时处理多客户端 创建进程或线程 让新进程或线程处理客户端 原来进程负责连接客户端 效率高
(1)图解
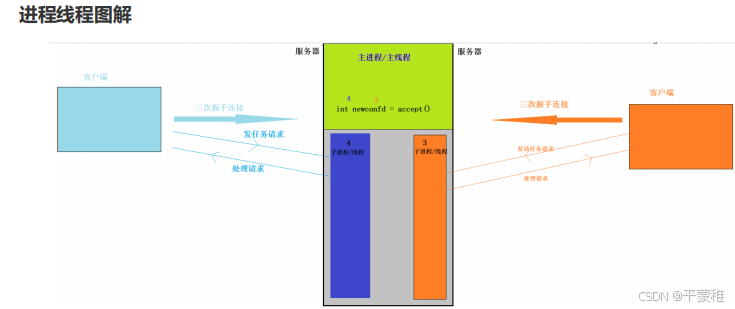
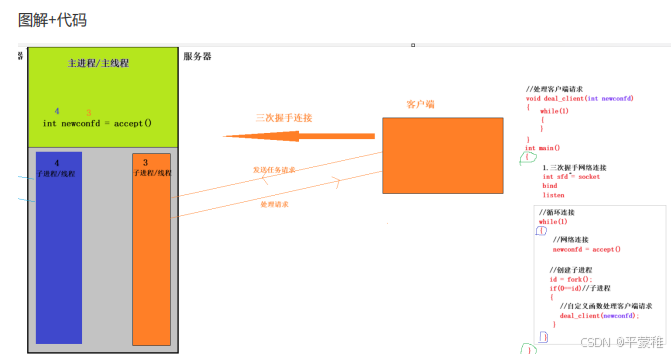
(2)多进程并发
1. 创建套接字 int listenfd = socket2. 绑定 bind3.listen4.while ( 1 ){// 取得客户端连接int confd = accept ( listenfd )// 创建子进程服务客户端id = fork ();if ( 0 == id ) // 子{dealClient ( confd ); // 处理客户端请求}}void dealClient ( int confd ){while ( 1 ) // 循环处理客户端请求{}}
实例: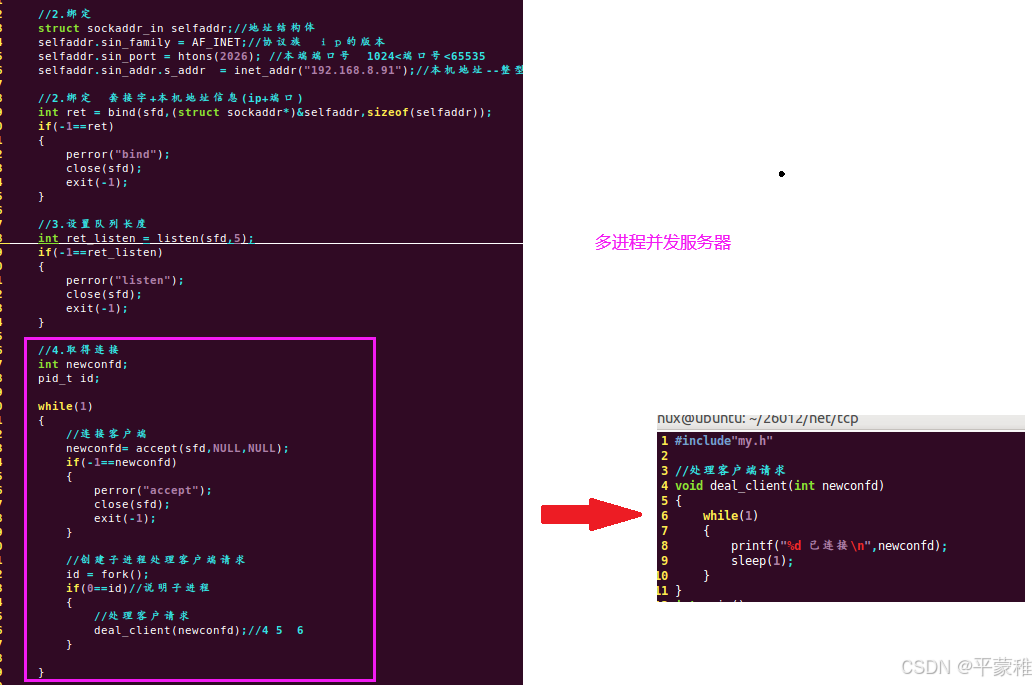
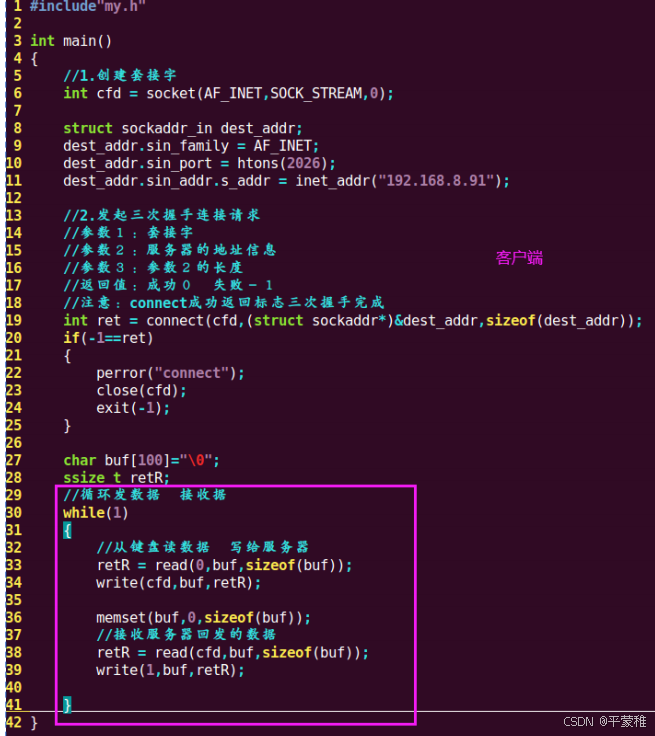
编译运行:
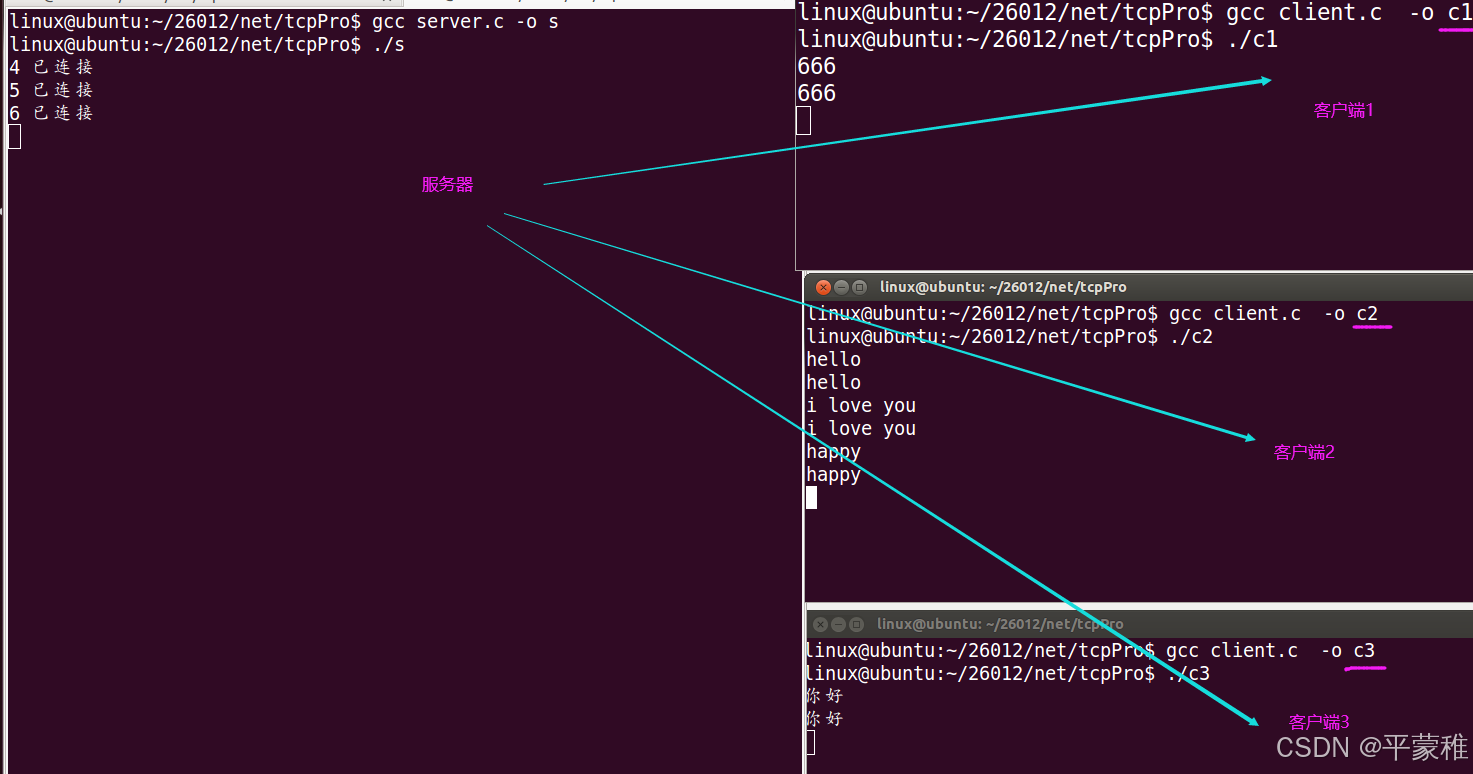
使用多进程并发服务器时要考虑以下几点:1. 父进程最大文件描述个数 ( 父进程中需要 close 关闭 accept 返回的新文件描述符 )2. 系统内创建进程个数 ( 与内存大小相关 )3. 进程创建过多是否降低整体服务性能 ( 进程调度 )
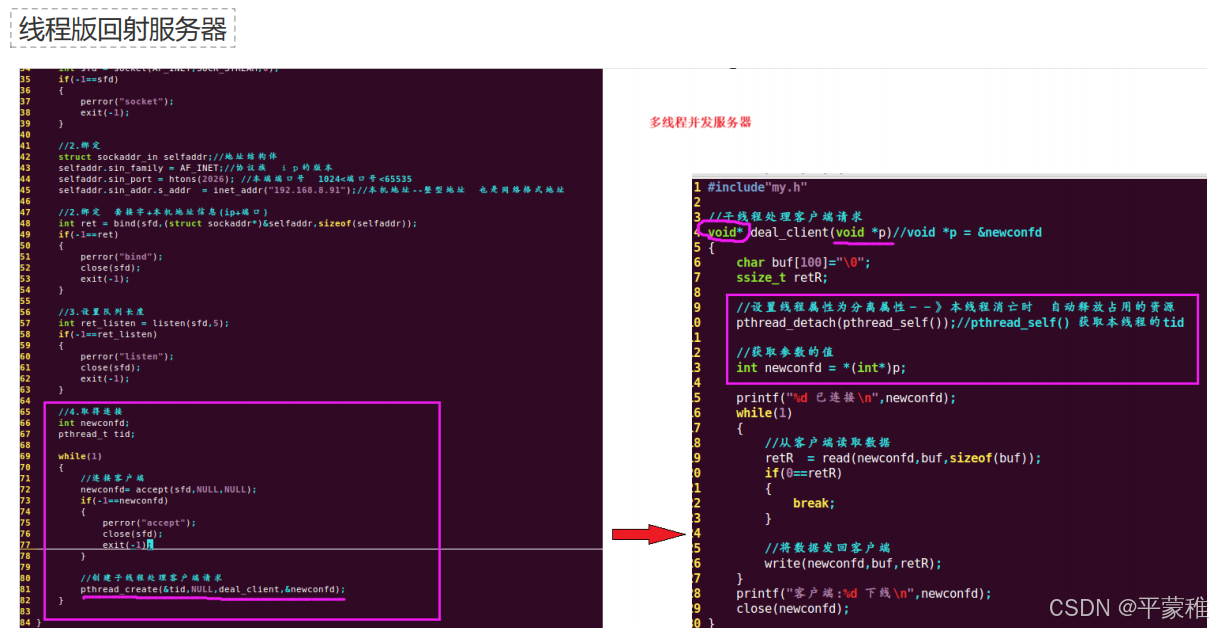
(3)🔺多线程并发重点

十.心跳检测机制(保活机制)
1.思考
如何测试服务器与客户端是否保持连接?read /recv 返回 0 只是指示远端正常关闭了连接,意味着你可以检测到这一状态,但并不代表网络本身完全不可用或所有网络故障都能被捕捉到。 非客户端关闭都是看不到的。心跳包主要也就是用于长连接的保活和断线处理。一般的应用下,判定时间在30 - 40 秒比较不错。如果实在要求高,那就在6 - 9 秒。
2.🔺心跳检测机制作用(保活机制)
( 1 ) 可以帮助我们知道服务器和客户端是否处于连通状态( 2 ) 心跳包可以帮助我们实现长连接,即使服务器出现问题,客户端自动重新请求连接 长连接 ( 连接之后,一直保存连通状态,心跳 ) 和短连接 ( 频繁的连接和断开 )
具体实现:
心跳包是由客户端定时发送数据给服务器端的,服务器端接收到心跳包后会对其进行回应。如果心跳包发送失败或者长时间没有得到回应,就说明连接出现了问题,需要及时进行处理。客户端 定期 ( 每隔 0.1 秒 ) 给服务器发送 1 包数据,服务器收到后回应,如果客户端检测到,发送了多包数据,服务器仍然没有回应,说明,服务器出问题了,客户端重连,直到服务器恢复为止
流程:
服务器功能: 等待客户端连接一旦有客户端发送connect, 回应ok客户端功能: 连接成功后,每隔 0.1秒钟发送"connect", 接收服务器的"ok"如果长时间收不到ok, 客户端重新连接服务器
3.设置TCP属性--了解
要考虑到一个服务器通常会连接多个客户端,因此由用户在应用层自己实现心跳包,代码较多 且稍显复杂,而利用TCP / IP 协议层为内置的 KeepAlive 功能来实现心跳功能则简单得多。 不论是服务端还是客户端,一方开启KeepAlive 功能后,就会自动在规定时间内向对方发送心跳包, 而另一方在收到心跳包后就会自动回复,以告诉对方我仍然在线。TCP 协议层默认并不开启 KeepAlive 功能我们需要手工开启 KeepAlive 功能并设置合理的 KeepAlive 参数。设置 SO_KEEPALIVE 属性使得我们在 2 小时以后发现对方的 TCP 连接是否依然存在。keepAlive = 1 ; // 开启属性setsockopt ( listenfd , SOL_SOCKET , SO_KEEPALIVE ,( void* ) & keepAlive ,sizeof ( keepAlive ));
4.总结
1)心跳包( 如何测试服务器与客户端是否保持连接 )常用的解决方法就是在程序中加入心跳机制。在接收和发送数据时个人设计一个守护进程 ( 线程 ) ,定时发送心跳包,客户端 / 服务器收到该小包后,立刻返回相应的包即可检测对方是否实时在线。2 )设置 TCP 属性 TCP 协议自带属性可以设置
十一.线程池
1.图解
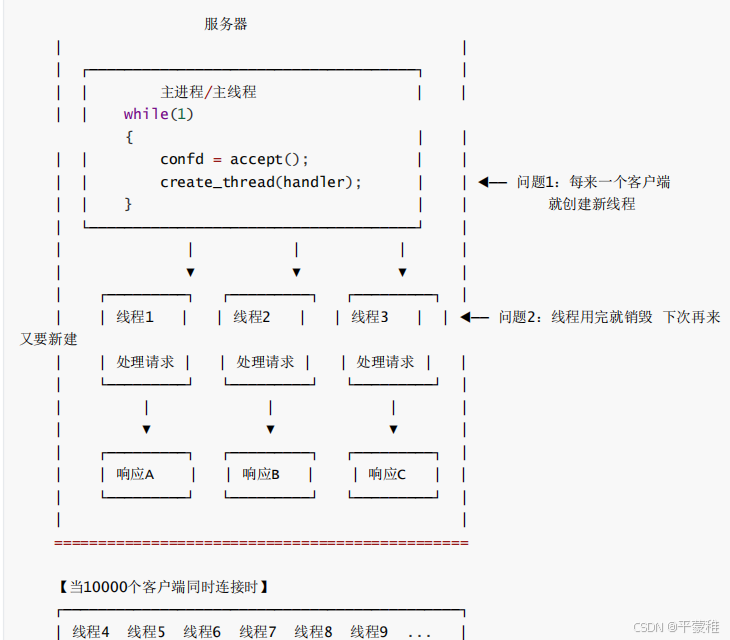
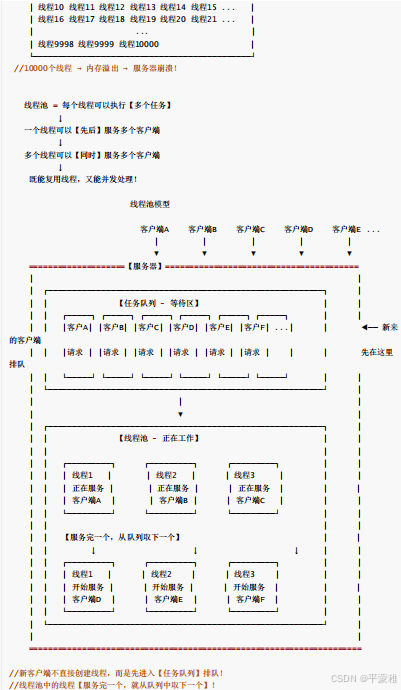

2.使用线程是如何防止出现大的波峰-重点
问法2 :如果 10000 个客户端请求处理 服务器? 12306 –> 10.1
答:意思是如何防止客户端涌来,方法是使用线程池,线程池具有可以同时提
高调度效率和限制资源使用的好处
解释: // 假设处理客户请求的时间不长,当大量客户陆续接入的时候,那么服务器对每个客户都将做这样的处理:创建线程 -> 处理客户请求 -> 销毁线程;由于每个客户请求的处理时间都不长,而创建线程和销毁线程需要花费较大的系统开销,所以当大量客户接入的时候服务器将花费大量的时间在创建和销毁线程上面,从而影响服务器性能。线程池作用:多线程并发服务器,频繁的创建和摧毁线程,浪费系统开销线程池,提前就已经创建好了多个线程,处于休眠状态 ( 阻塞等待 ),有任务的时候,自动唤醒线程,没有工作任务,再次休眠用休眠和唤醒来替换创建和摧毁
3.🔺线程池作用(面试问题)
1. 降低资源消耗。通过重复利用已创建的线程降低线程创建、销毁线程造成的消耗。2. 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。3. 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配、调优和监控4.什么样的需求,会选择使用线程池呢?大量的执行任务, 每个任务要执行的时间不要太长,不要太耗时,选择线程池效率会高5.线程池的底层原理?任务使用 链表+任务队列来管理 (先进先出)
4..线程池应用场景介绍-了解
1. 网购商品秒杀2. 云盘文件上传和下载3. 12306 网上购票系统等总之,只要有并发的地方、任务数量大或小、每个任务执行时间长或短的都可以使用线程池 ;
但是要注意要创建合理的线程池大小
十二.TCP粘包问题
1.基知
长连接:
Client 方与 Server 方先建立通讯连接,连接建立后不断开, 然后再进行报文发送和接收。短连接:
Client 方与 Server 每进行一次报文收发交易时才进行通讯连接,交易完毕后立即断开连接。
2.何时考虑粘包问题(长连接)
1 )短连接:利用 tcp 每次发送数据,就与对方建立连接,然后双方发送完一段数据后,就关闭连接,这样就不会出现粘包问题( TCP 连接断开后,该连接对应的接收缓冲区数据会被内核彻底清除。下 次重连是一个全新的连接,拥有全新的缓冲区,不能读到上次残留的数据 )粘包问题通常出现在长连接中,因为长连接会持续保持连接状态,多个数据包可能会在同一个连接上连续发送,导致接收端无法准确判断数据包的边界,从而可能出现数据粘连在一起的情况。2 )在流传输中出现, UDP 不会出现粘包,因为它有消息边界( UDP 首部里有个 UDP 长度 记录数据长度)TCP 是一种流协议 (stream protocal) 。 这就意味着 从应用层角度看 数据是以字节流的形式传递给接 收者的 ,字节流可以理解为一个双向的通道里流淌的数据,这个 数据 其实就是我们常说的二进制数据,简单来说就是一大堆 01 串。这些 01 串之间 没有任何边界 没有固定的 “ 报文 ” 或 “ 报文边界 ” 的概念。因此,读取 TCP 数据时我们 无法预知在一次指定的读操作中会返回多少字节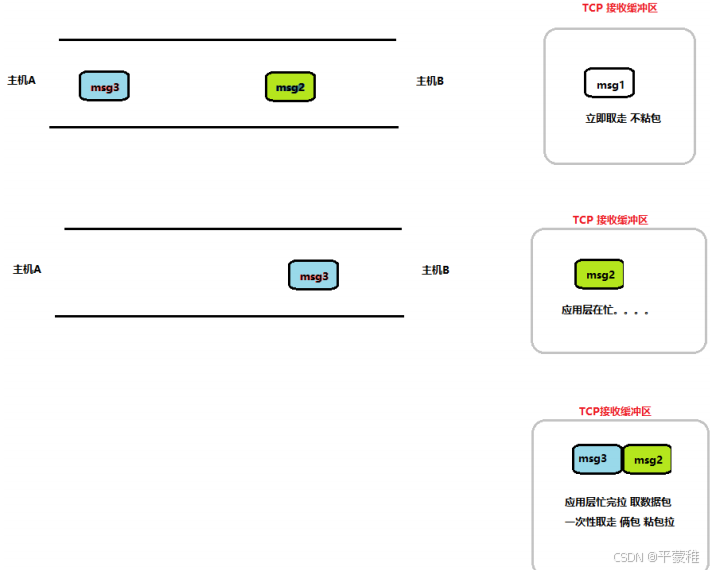
3.案例与解决方法
案例:
客户端 write 写操作两次 , 产生 2 个数据包 ; 假设 "abc" , "def"服务端 read 读一次 , 可能读到 "abcdef" 或许是 "abcd" , 后面的 "ef" 在下次被读取到 .
解决办法:
解决方法1 :可以在每个数据包前 , 加一个 长度为 4 字节的字段 .案例 :发送方 : 数据包 1 , 2 , 3 . 大小不固定 , 变长 . 每次发送数据包时 , 在头部先加长度为 4 字节的字段 .接收方 : 每次接受数据时 , 先固定读 4 个字节 , 解析后得到数据包 1 的长度 , 然后再读取 , 当读取的数据达到这个长度时 , 就说明数据包 1 已经接收完成 . 重复后面的操作…解决方法2 、发送端将每个数据包封装为固定长度(不够的可以通过补 0 填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。解决方法3 、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开
十三.抓包工具Wireshark-会用
用来获取网络数据封包,包括HTTP、TCP、UDP等网络协议包
1.步骤:
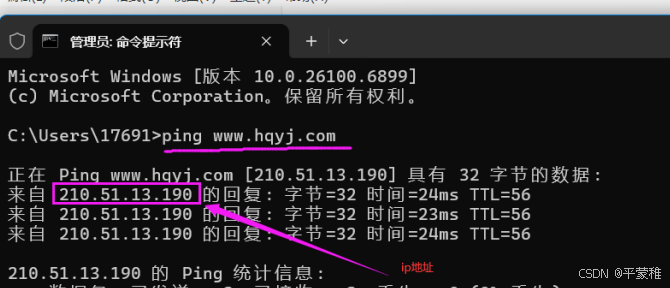
获取对方ip
wireshark是捕获机器上的某一块网卡的网络包,当你的机器上有多块网卡的时候,你需要选择一个网卡。直接双击上面的某个网卡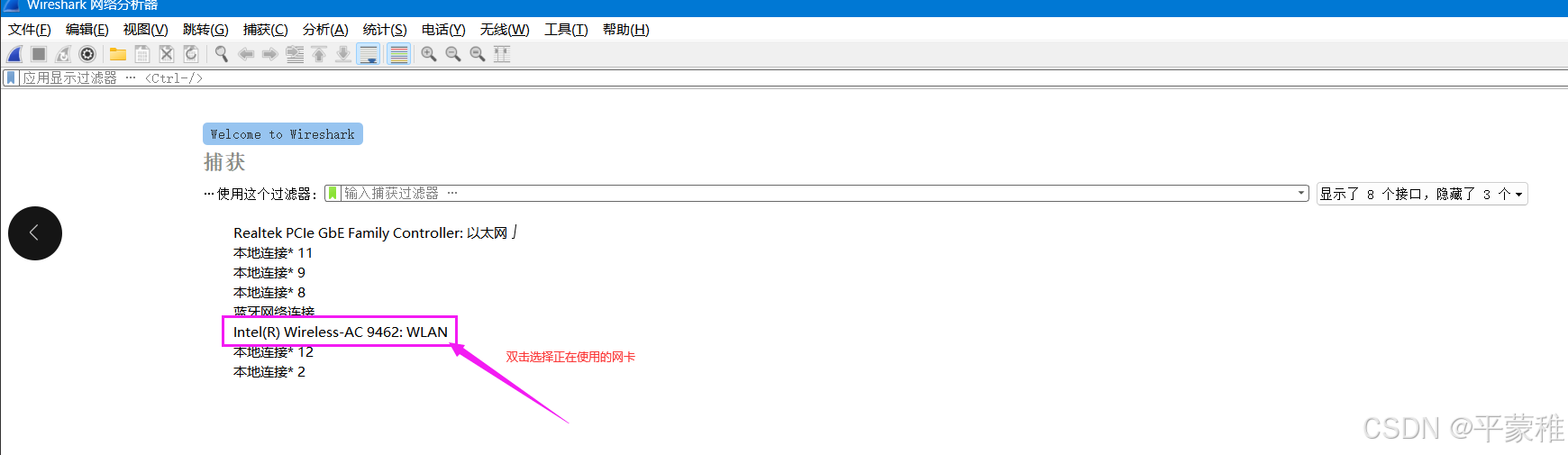
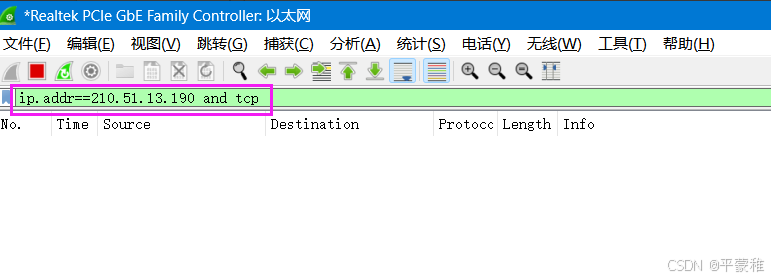
在显示过滤器中输入:例如: ip . addr == 210.51.13.190 andtcp 回车点击捕捉按钮打开浏览器搜索框输入里输入 www . hqyj . com 回车 点击第一个链接(华清)
2.Wireshark窗口
WireShark 主要分为这几个界面:Display Filter( 显示过滤器 ) ,用于过滤。Packet List Pane( 封包列表),显示捕获到的封包,有源地址和目标地址,端口号。颜色不同,代表Packet Details Pane(封包详细信息 ), 显示封包中的字段。Dissector Pane(16进制数据 ) 。Miscellanous(地址栏,杂项 ) 。
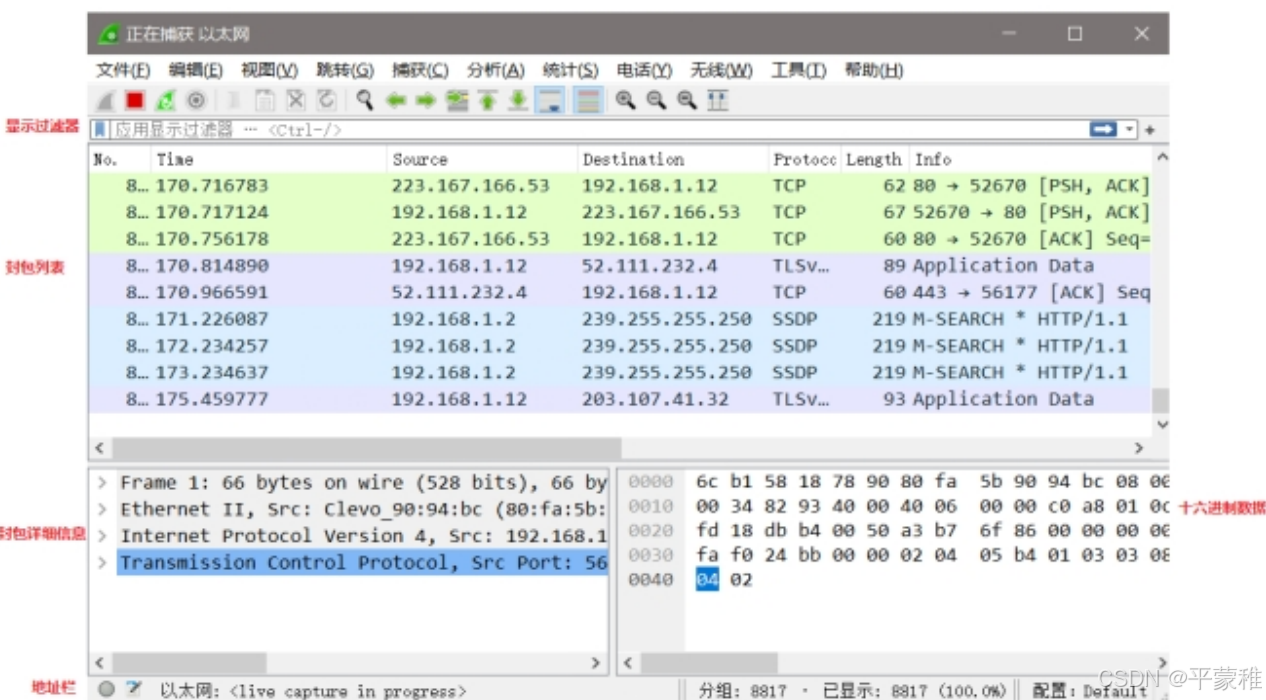

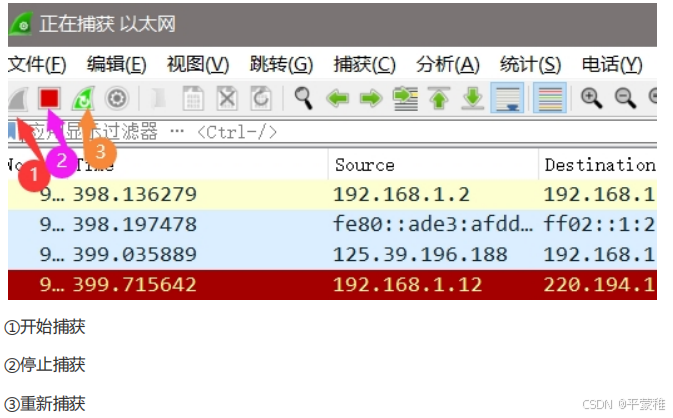
3.常用按钮
4.过滤表达式
(1)协议过滤
直接输入协议进行过滤tcp ,只显示 TCP 协议的数据包列表http ,只查看 HTTP 协议的数据包列表icmp ,只显示 ICMP 协议的数据包列表oicq , 只显示 oicq 协议的数据包列表
(2)ip过滤
ip . src == 192.168 . 1.108 显示源地址为 192 . 168.1 . 108 的数据包列表ip . dst == 192.168 . 1.108 , 显示目标地址为 192 . 168.1 . 108 的数据包列表ip . addr == 192.168 . 1.108 显示源 IP 地址或目标 IP 地址为 192 . 168.1 . 108 的数据包列表
(3)端口过滤
tcp . port == 80 , 显示源主机或者目的主机端口为 80 的数据包列表。tcp . srcport == 80 , 只显示 TCP 协议的源主机端口为 80 的数据包列表。tcp . dstport == 80 ,只显示 TCP 协议的目的主机端口为 80 的数据包列表。// 也可以将上面的 tcp 改成 udp
(4)抓到的包
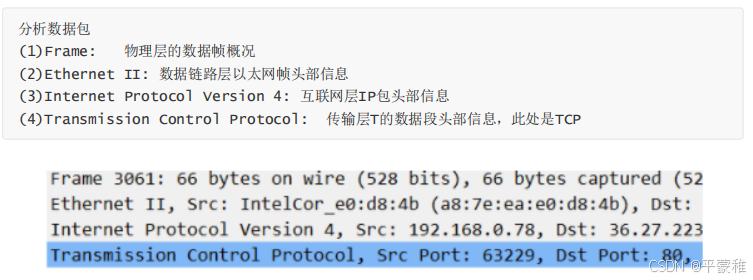
十四.抓包分析TCP协议-了解
1.含义
TCP 是一种面向连接(连接导向)的、可靠的基于字节流的传输层通信协议。 TCP 将用户数据打包成报文段,它发送后启动一个定时器,另一端收到的数据进行确认、对失序的数据重新排序、丢弃重复数据。
2.特点
1. TCP 是面向连接的运输层协议2. 每一条 TCP 连接只能有两个端点3. TCP 提供可靠交付的服务4. TCP 提供全双工通信。数据在两个方向上独立的进行传输。因此,连接的每一端必须保持每个方向上的传输数据序号。5. 面向字节流。面向字节流的含义:虽然应用程序和 TCP 交互是一次一个数据块,但 TCP 把应用程序交下来的数据仅仅是一连串的无结构的字节流
3.TCP与IP
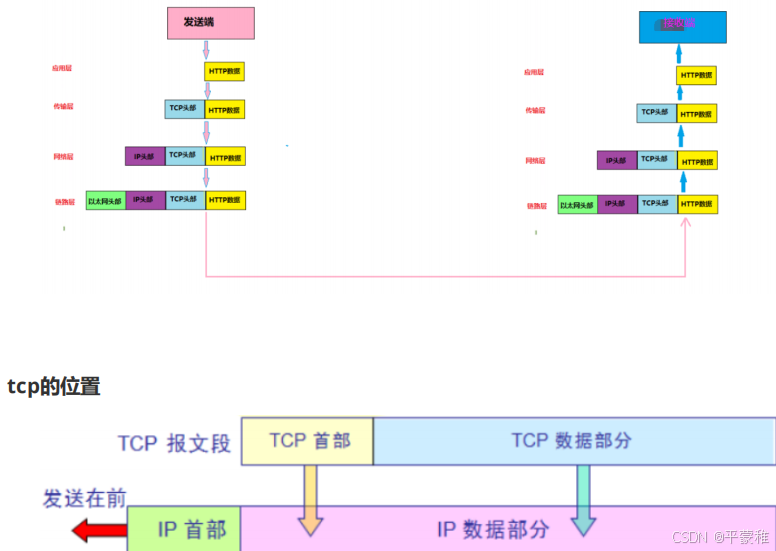
4.TCP首部格式

1. 源端口号:数据发起者的端口号, 16bit2. 目的端口号:数据接收者的端口号, 16bit3. 序号: 32bit 的序列号,由发送方使用 TCP 协议使用序列号来标识发送和接收的数据段。发送方为每个数据段分配一个唯一的序列号,接收方根据序列号来重新组装数据段,保证数据的顺序性4. 确认序号: 32bit 的确认号,是接收数据方期望收到发送方的下一个报文段的序号,因此确认序号应当是上次已成功收到数据字节序号加 15. 首部长度:首部中 32bit 字的数目,可表示 15 * 32bit = 60 字节的首部。一般首部长度为 20 字节。如何计算 TCP 首部长度?通过数据偏移控制字段计算???//TCP 首部的长度是通过数据偏移控制字段来表示的,其表示 TCP 数据段部分相较于整个 TCP 报文起始位置的偏移量大小,这个偏移量是以 4 字节单位计算的// 所以 TCP 首部的长度 = 数据偏移控制字段的值 * 4 字节// 首都长度占 4 位,从 0000 到 1111, 也就是从 0 到 15 ,代表最大长度是 15 个 4 字节( 32bit )即 60 字节11. 同步比特 SYN :在建立连接是用来同步序号。 SYN = 1 , ACK = 0 表示一个连接请求报文段。 SYN = 1 ,ACK = 1 表示同意建立连接。12. 终止比特 FIN : FIN = 1 时,表明此报文段的发送端的数据已经发送完毕,并要求释放传输连接。13. 窗口:用来控制对方发送的数据量,通知发放已确定的发送窗口上限。14. 检验和:该字段检验的范围包括首部和数据这两部分。由发端计算和存储,并由收端进行验证。
wireshark捕获到的TCP包中的每个字段
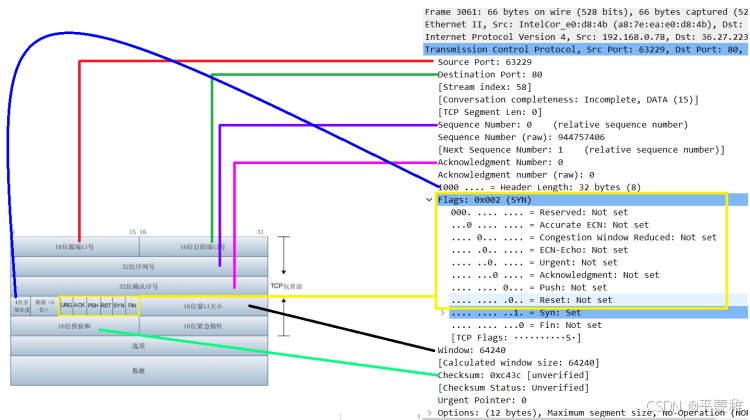
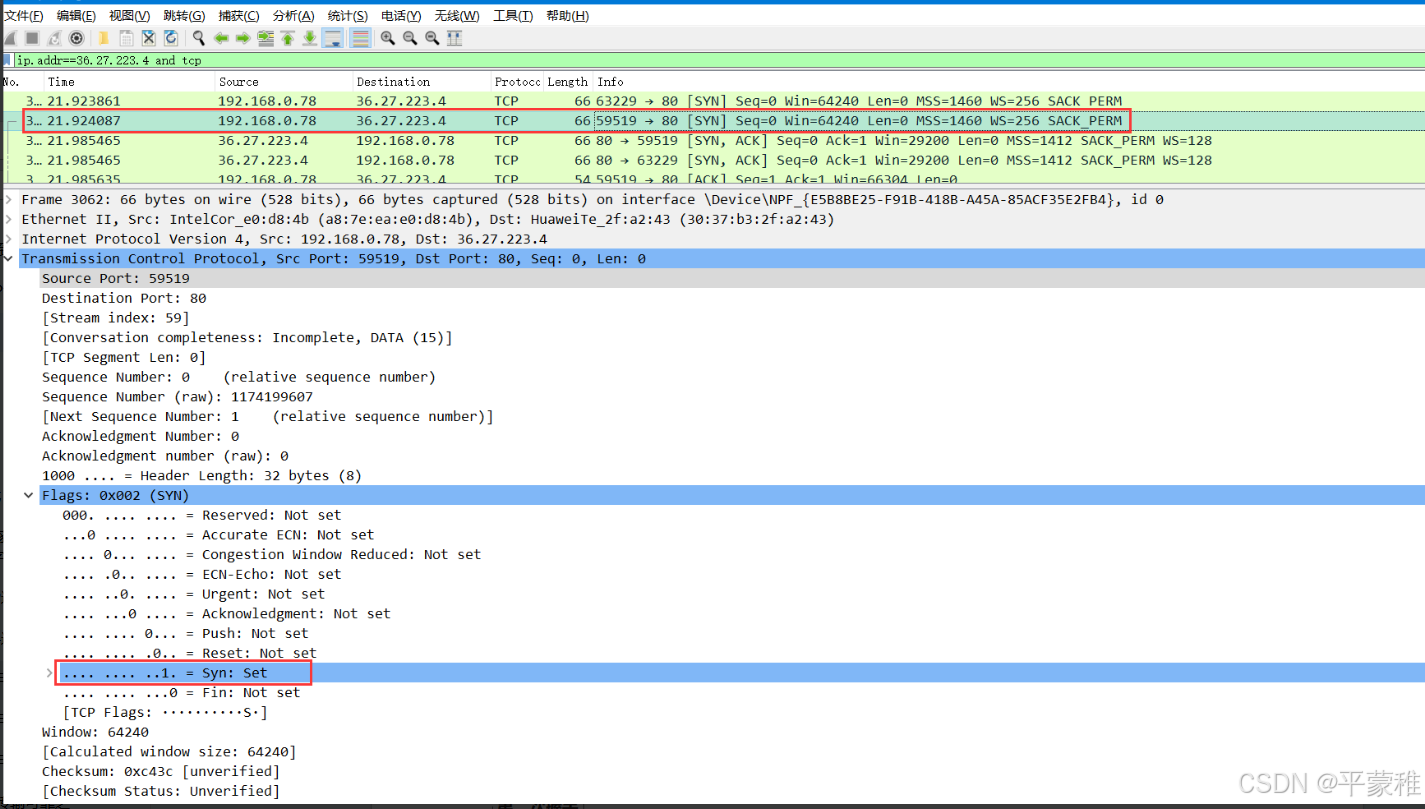
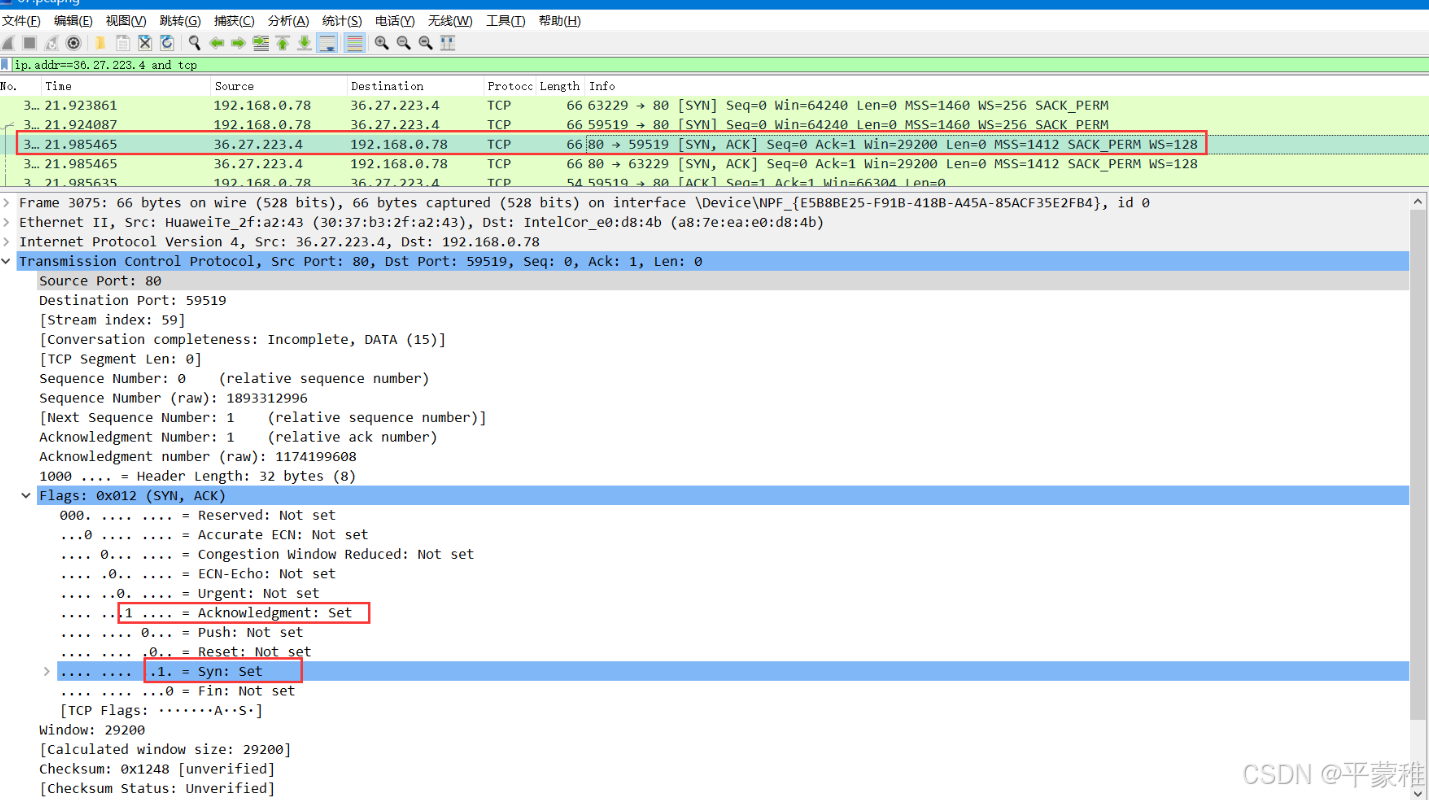
5.抓包分析TCP连接过程
(1)滑动窗口
定义:滑动窗口是发送方和接收方在数据传输过程中动态调整的一种机制,用于管理传输过程中可以发送和接收的数据量大小。应用和优势:流量控制:通过滑动窗口, TCP 可以动态地调整数据的发送速率,从而避免过度拥塞网络或者接收方缓冲区溢出。传输效率:滑动窗口使得 TCP 能够在不同网络条件下进行高效的数据传输,同时保持网络的稳定性和吞吐量。错误恢复:滑动窗口机制也有助于 TCP 在发生丢包或者网络错误时进行快速的恢复,通过重传机制确保数据的完整性和正确性。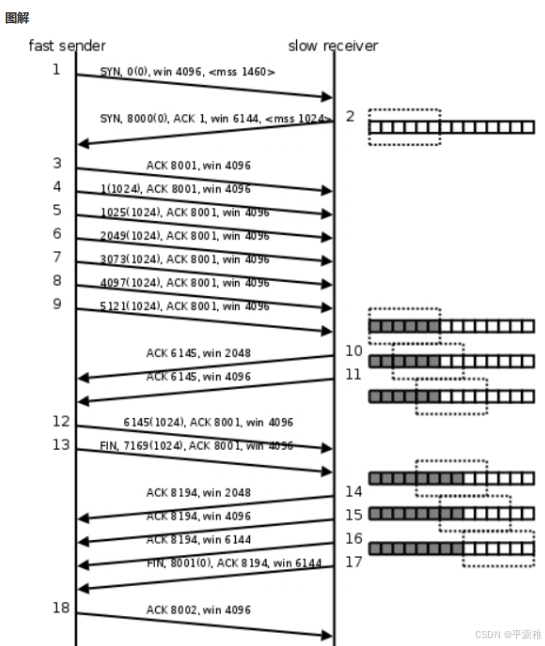
6.抓包分析TCP断开连接过程(四次挥手)
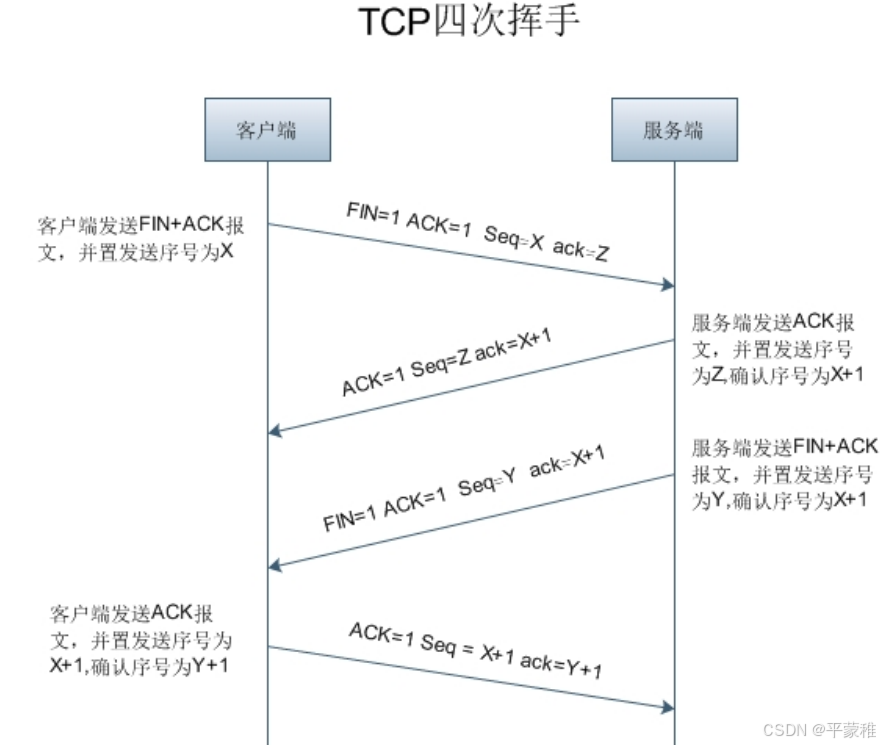
第一次挥手: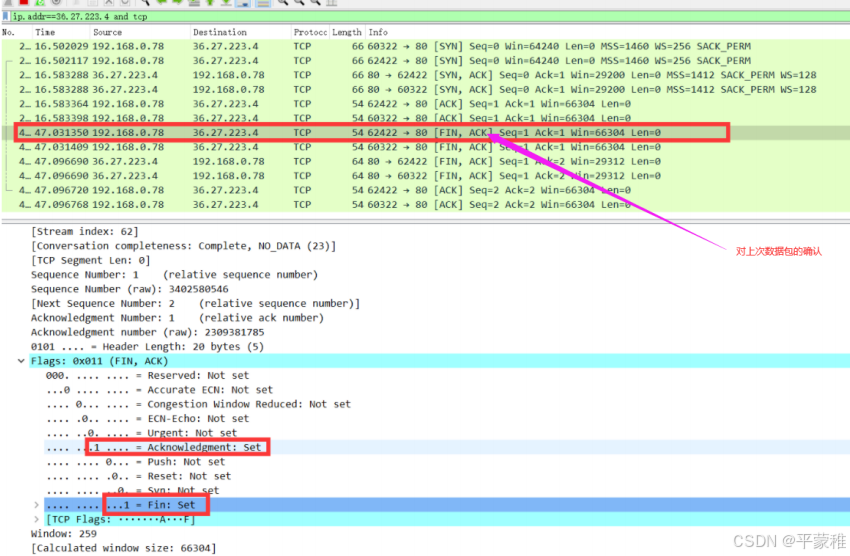 第二三次挥手
第二三次挥手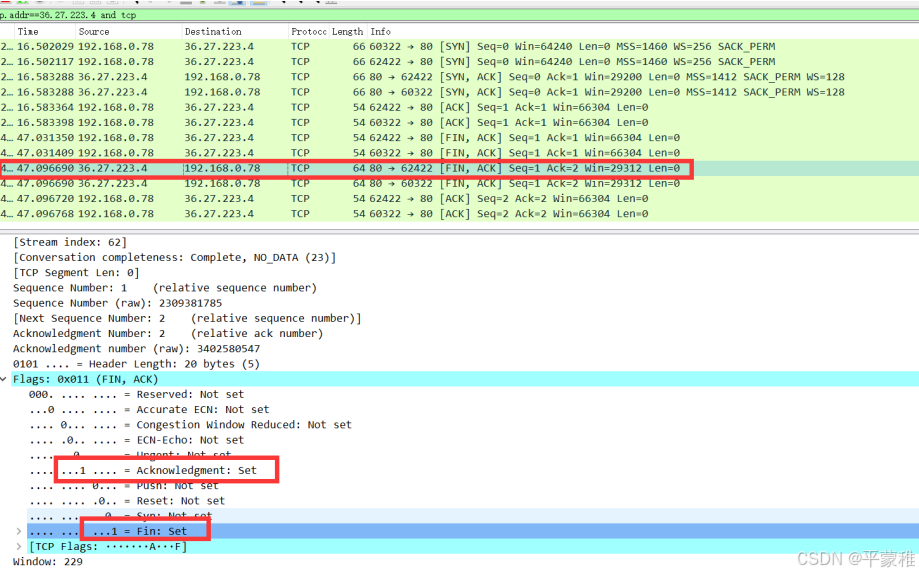 第二次挥手第三次挥手合并了原因:当被挥手端第一次收到挥手端的 “FIN” 请求时,并不会立即发送 ACK ,而是会经过一段延迟时间后再发送 ( 等待本端数据处理完毕 ) ,但是此时被挥手端也没有数据处理,就会向挥手端发送 “FIN " 请求,这里就可能造成被 挥手端发送的“FIN” 与 “ACK” 一起被挥手端收到,导致出现 “ 第二、三次挥手 ” 合并为一次的现象,也就最终呈现出“ 三次挥手 ”第四次挥手
第二次挥手第三次挥手合并了原因:当被挥手端第一次收到挥手端的 “FIN” 请求时,并不会立即发送 ACK ,而是会经过一段延迟时间后再发送 ( 等待本端数据处理完毕 ) ,但是此时被挥手端也没有数据处理,就会向挥手端发送 “FIN " 请求,这里就可能造成被 挥手端发送的“FIN” 与 “ACK” 一起被挥手端收到,导致出现 “ 第二、三次挥手 ” 合并为一次的现象,也就最终呈现出“ 三次挥手 ”第四次挥手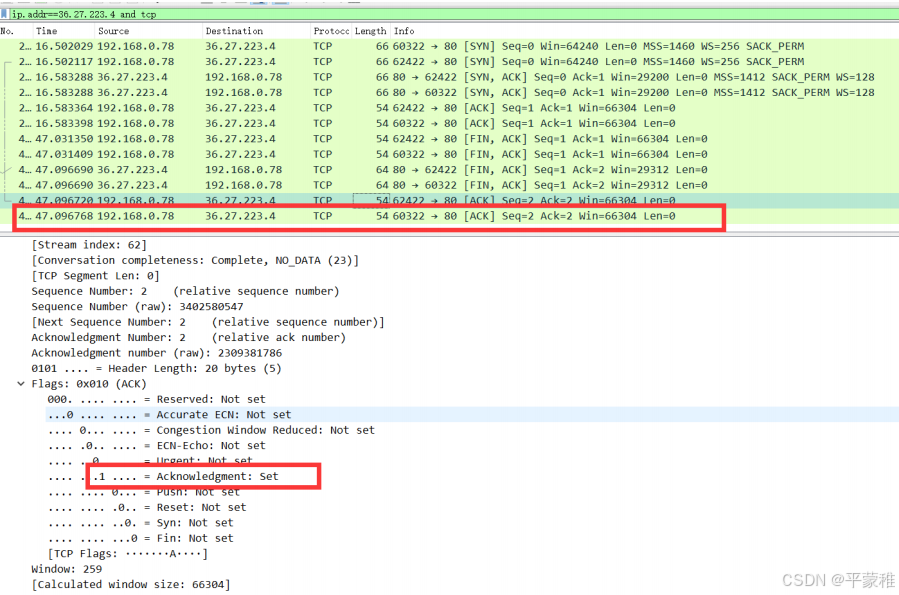
十五.TCP和UDP区别-重点
UDP ( User Datagram Protocol )是一种在计算机网络中使用的传输层协议,与 TCP 一样属于传输层的两个主要协议之一。不同于 TCP 的面向连接特性, UDP 是一种无连接的、简单的协议,它主要用于支持实时性要求高、对数据可靠性要求较低的应用。无连接性: UDP 协议不需要在通信开始之前建立连接,通信双方可以直接开始传输数据。这使得 UDP 的传输过程更加轻量和快速,但也导致了数据传输过程中的不可靠性。不可靠性: UDP 不提供数据的可靠传输,这意味着发送的数据包可能会在传输过程中丢失、重复、乱序等。UDP 不执行像 TCP 那样的序列号和确认号机制,也不会进行自动重传。简单: UDP 头部相对较短,仅包含源端口、目的端口、长度和校验和等基本信息,这使得 UDP 在处理速度上更快。实时性: 由于 UDP 的无连接性和不可靠性,它更适用于那些需要实时性、低延迟的应用,如实时音视频传输、在线游戏等。广播和多播: UDP 支持广播和多播,使得一个主机可以向多个目标主机发送相同的数据。应用场景: 由于 UDP 的特性,它适用于那些对数据完整性和可靠性要求较低的应用,例如音频和视频流传输、DNS 查询、实时通信等。
16 位源端口、目的端口:用来标识源端和目标端的应用进程。16 位 UDP 长度:该字段表示 UDP 首部和 UDP 数据的字节长度。该字段的最小值为 8 字节(发送 0 字节的 UDP 数据报是 OK 的)。16 位 UDP 校验和:UDP 校验和覆盖了 UDP 首部和 UDP 数据。 UDP 的校验和是可选的,而 TCP 的校验和是必需的
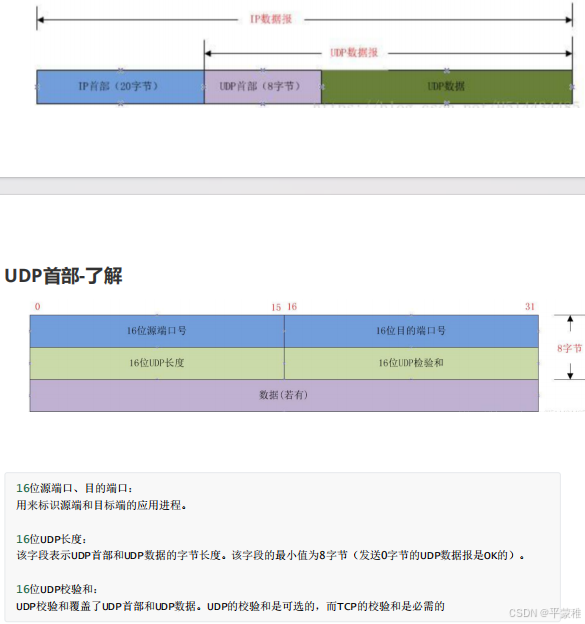
TCP和UDP的区别--重点

十六.IP
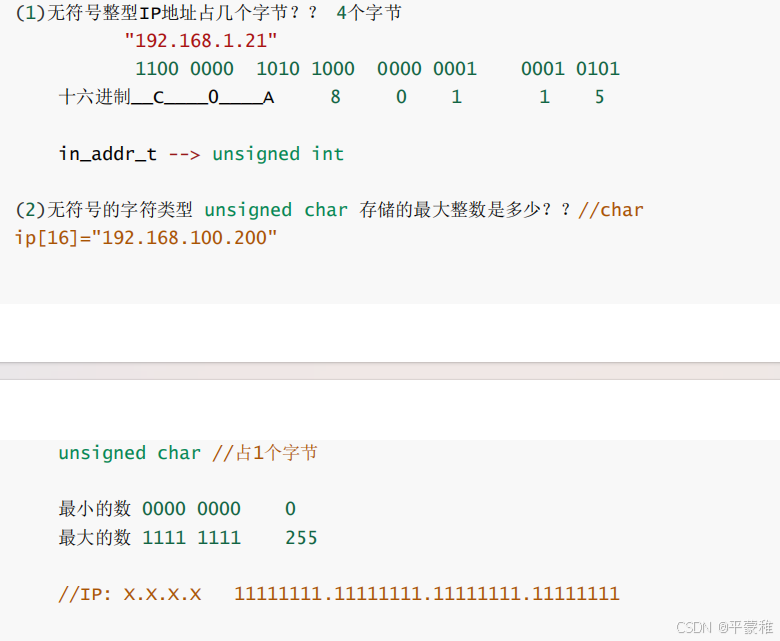
1.IP地址组成
2. 如何划分网络地址和主机地址
(1)组成
192.168 . 1.21IPv4 分为两部分:网络地址和主机地址网络地址:标明具体的网段主机地址:标明具体的某个节点,也就是某个网络中特定的计算机的号码
(2)子网掩码
子网掩码的组成 子网掩码的表示方法
子网掩码的表示方法 实例:1 ) 子网掩码由连续的 1 和 0 组成2 ) 子网掩码都是 左全是 1 右全是 0
实例:1 ) 子网掩码由连续的 1 和 0 组成2 ) 子网掩码都是 左全是 1 右全是 0
(3)作用与应用
作用:
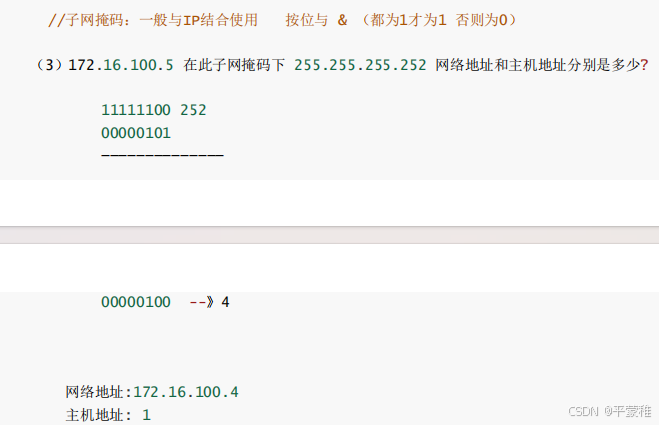
子网掩码(Subnet Mask)又叫网络掩码、地址掩码,必须结合IP地址一起对应使用子网掩码和IP地址做“与”运算,分离出IP地址中的网络地址和主机地址(按位与结果是网络地址)
应用:
分离出IP地址中的网络地址和主机地址
网络地址应用:如何判断两个 IP地址是否是相同网段?如果两个 IP 地址,网络地址相同,就说明在同一个网段网络地址相同的话,就证明是相同网段 通信 --- 通过交换机(工作在数据链路层) 不通过网关网络地址不同的话,就证明不是相同网段 通信 --- 需要通过网关(路由器:工作在网络层)网关 : 核心作用是 “ 跨网络转发数据 ” ,是不同网络(如局域网和互联网)之间的出入口 当访问另一个 网络中的主机时,就要通过网关 ( 通常是路由器 )
应用3 重点笔试题
能连接多少台主机 ??? 笔试题 ( 重点 )某一网络子网掩码为 255.255.255.248 则该网络能连接 (C) 台主机。 --- 重点[A] 255 台 [B] 16 台 [C] 6 台 [D] 8 台1 )连多少台主机 需要知道 掩码能形成多少个编号2 )掩码为 0 的 bit 位是主机位 主机位用来形成编号标识主机3)255.255.255.248 转为二进制 11111111 11111111 11111111 11111000说明低 3bit 位是主机位 可以形成编号 标识主机4 ) 3bit 主机位 能形成多少个 ( 编号 ) 整数111 –>7000–>0110–>6011–>3101–>5010–>2001–>1100–>4注意:主机位全为 1 的 表示广播地址 不能用来标识主机 7不能用主机位全是0 不能标识主机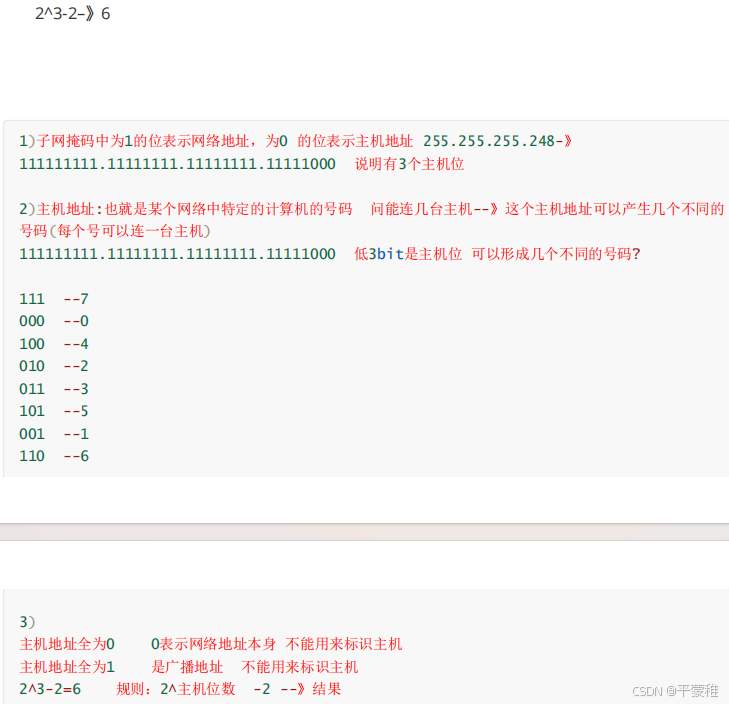


3.IP地址分类




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)