LangChain记忆模块:大模型对话上下文管理
1、Memory综述
1.1 Memory的价值
在我们与大模型进行交互时都会进行多轮交互,在后一次对话的时候模型需要知道你之前问题的内容,这就是有一定的上下文记忆能力。但是,模型自身并不具备记忆上下文内容的能力,只会依赖用户自身的输入去产生输出。
那么应该如何实现模型的记忆能力呢?
为了实现这个记忆功能,需要额外的模块来保存用户与模型对话的上下文信息,当用户下一次请求时,把历史信息一同输入给模型,让模型产生最终输出。这就是我们今天的内容——Memory,用于存储用户与模型交互的历史信息。
1.2 Memory的理解
Memory是LangChain用于多轮对话中保存与管理上下文信息的组件。它可以能够使记住用户说过什么,从而实现对话的上下文感知能力。这也为构建智能体提供了基础。
如果一个对话链使用了Memory模块,会和该模块交互几次呢?
✅️:会和Memory模块交互两次(读取+写入)具体来说
- 收到用户的输入时,从记忆组件中查询相关历史信息,拼接历史信息与用户的输入给到提示词传给大模型;
- 返回响应之前,自动将大模型返回的内容写入记忆组件,用于下次查询。
❓️如果不使用Memory模块,还能实现拥有记忆吗?
✅️:可以,每轮对话的内容都通过messages变量重复加入到对话列表,强行让大模型具备上下文记忆能力。如下代码所示,模型的回答加入到AIMessage,用户的输入加入HumanMessage中。
def chat_with_model(answer):
# 提供提示词模版
prompt_template = ChatPromptTemplate.from_messages(messages = [
("system","你是一个人工智能助手"),
("human","{question}")
])
while True:
chain = prompt_template | chat_model
response = chain.invoke(input = {"question":answer})
print(f"模型回复:{response.content}") #输出大模型响应
user_input = input("还有其他问题吗?(输出‘退出’时结束会话") #继续获取用户问题
if user_input == "退出":
break
# 将上述新生成的消息存放在提示词模版的消息列表中
prompt_template.messages.append(AIMessage(content=response.content))
prompt_template.messages.append(HumanMessage(content=user_input))2、Memory使用
2.1 Memory模块设计思路
关于如何保留交互的记忆,有以下四种思考的角度:
- 只保留一个聊天消息列表;
- 只返回最近交互的K条消息;
- 返回过去K条消息的简单摘要;
- 在保留的完整聊天记录的基础上,最近的K条完整返回,时间过早地记录只返回摘要。
2.2 ChatMessageHistory
ChatMessageHistory是存储与管理对话消息的基础类,他直接操作消息对象(AIMessage、HumanMessage)是其余记忆组件的底层工具。
示例1:记忆存储
from langchain_classic.memory import ChatMessageHistory
# 1、ChatMessageHistory实例化
history = ChatMessageHistory()
# 2、添加相关消息进行存储
history.add_user_message("你好")
history.add_ai_message("很高兴认识你,我叫小e")
# 3、打印存储的消息
print(history.messages)
示例2:对接LLM
from langchain_openai import ChatOpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 创建大模型实例
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
history.add_user_message("你好我是小明")
history.add_ai_message("我是小e,一个人工智能助手")
history.add_user_message("我叫什么")
response = chat_model.invoke(history.messages)
print(response.content)输出:你刚刚提到你叫小明。
2.3 ConversationBufferMemory
ConversationBufferMemory是基础的对话记忆组件,专门用于按照原始顺序存储完整的对话历史。它支持两种返回格式,当return_messages为真时返回消息对象列表,为假(默认)时返回拼接的纯文本字符串。
示例1:以字符串方式返回存储的信息
from langchain_classic.memory import ConversationBufferMemory
# 1、实例化
memory = ConversationBufferMemory()
# 2、存储信息 inputs对应用户消息 outputs对应ai消息
memory.save_context(inputs={"input":"你好,我叫夏雪"},outputs = {"output":"很高兴认识你"})
memory.save_context(inputs={"input":"帮我回答1+2"},outputs = {"output":"3"})
# 3、获取存储的信息
print(memory.load_memory_variables({})) # 返回的字典结构的key叫history
示例2:以消息列表方式返回存储信息
from langchain_classic.memory import ConversationBufferMemory
# 1、实例化
memory = ConversationBufferMemory(return_messages=True)
# 2、存储信息 inputs对应用户消息 outputs对应ai消息
memory.save_context(inputs={"input":"你好,我叫夏雪"},outputs = {"output":"很高兴认识你"})
memory.save_context(inputs={"input":"帮我回答1+2"},outputs = {"output":"3"})
# 3、获取存储的信息
print(memory.load_memory_variables({})) # 返回的消息列表结构的key叫history
print('\n')
print(memory.chat_memory.messages) # 返回消息列表的另一种方式
示例3:结合LLM以及提示词模版 PromptTemplate
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains import LLMChain
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
prompt_template = PromptTemplate.from_template(
template = """
你可以与人类对话。
当前对话: {history}
人类问题: {question}
回复:
"""
)
# 提供memory实例
memory = ConversationBufferMemory()
# 提供chain
chain = LLMChain(llm = chat_model,prompt = prompt_template,memory=memory)
response = chain.invoke({"question":"1+1=?"})
print(response)
继续追问刚才的问题:
response = chain.invoke({"question":"我刚才的问题是什么?"})
print(response)
示例4:显式设置memory的key值
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains import LLMChain
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
prompt_template = PromptTemplate.from_template(
template = """
你可以与人类对话。
当前对话: {chat_history}
人类问题: {question}
回复:
"""
)
# 提供memory实例
memory = ConversationBufferMemory(memory_key="chat_history") # 通过memory_key修改memory数据的变量名
# 提供chain
chain = LLMChain(llm = chat_model,prompt = prompt_template,memory=memory)
response = chain.invoke({"question":"1+1=?"})
print(response)
示例5:使用ChatPromptTmplate
# 1.导入相关包
from langchain_core.messages import SystemMessage
from langchain_classic.chains.llm import LLMChain
from langchain_classic.memory import ConversationBufferMemory
from langchain_core.prompts import MessagesPlaceholder,ChatPromptTemplate,HumanMessagePromptTemplate
from langchain_openai import ChatOpenAI
# 2.创建LLM
llm = ChatOpenAI(model='gpt-4o-mini')
# 3.创建Prompt
prompt = ChatPromptTemplate.from_messages([
("system","你是一个与人类对话的机器人。"),
MessagesPlaceholder(variable_name='history'),# 消息列表
("human","问题:{question}")
])
# 4.创建Memory
memory = ConversationBufferMemory(return_messages=True)
# 5.创建LLMChain
llm_chain = LLMChain(prompt=prompt,llm=llm, memory=memory)
# 6.调用LLMChain
res1 = llm_chain.invoke({
"question": "中国首都在哪里?"
})
print(res1,end="\n\n")
res2 = llm_chain.invoke({
"question": "我刚刚问了什么"
})
print(res2)
通过这个输出我们可以看到,使用ChatPromptTemplate时,用户的第一次输入交互就直接进入了history而不是等到一轮交互结束将用户输入与模型回答统一放入history。这是由于LangChain为了保障对话的一致性所设计的。
| 特性 | PromptTemplate | ChatPromptTemplate |
|---|---|---|
| 历史存储时机 | 仅执行后存储 | 执行前存储用户输入 + 执行后存储输出 |
| 首次调用显示 | 仅显示问题(历史仍为 空字符串) | 显示完整问答对 |
| 内部消息类型 | 拼接字符串 | List[BaseMessage] |
2.4 ConversationChain
ConversationChain是对ConversationBufferMemory和LLMChain进行了封装。
示例1:使用PromptTemplate
from langchain_classic.chains.conversation.base import ConversationChain
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains import LLMChain
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
prompt_template = PromptTemplate.from_template(
template = """
你可以与人类对话。
当前对话: {history}
人类问题: {input}
回复:
"""
)
# # 提供memory实例
# memory = ConversationBufferMemory()
# # 提供chain
# chain = LLMChain(llm = chat_model,prompt = prompt_template,memory=memory)
# 创建conversationChain实例
chain = ConversationChain(llm = chat_model,prompt = prompt_template)
response = chain.invoke({"input":"1+1*2+2=?"})
print(response)
response = chain.invoke(input={"input":"我刚才的问题是什么?"})
print(response)
示例2:使用默认的提示词模版
from langchain_classic.chains.conversation.base import ConversationChain
from langchain_core.prompts import PromptTemplate
from langchain_classic.chains import LLMChain
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
# prompt_template = PromptTemplate.from_template(
# template = """
# 你可以与人类对话。
# 当前对话: {history}
# 人类问题: {input}
# 回复:
# """
# )
# # 提供memory实例
# memory = ConversationBufferMemory()
# # 提供chain
# chain = LLMChain(llm = chat_model,prompt = prompt_template,memory=memory)
# 创建conversationChain实例 内部提供了默认的提示词模版 变量为input history
chain = ConversationChain(llm = chat_model)
response = chain.invoke({"input":"李白姓李"})
print(response)
response = chain.invoke(input={"input":"刚才我们谈论的诗人是谁?"})
print(response)
2.5 ConversationBufferWindowMemory
在上面的介绍中我们知道ConversationBufferMemory能够无限的将历史对话填充到history中。会导致内存量十分大,这样带来的后果就是tokens消耗大。
ConversationBufferWindowMemory模块会保存一段时间内对话交互的列表,及使用最近的K个进行交互,这样就省了一些缓存区。他同样使用return_messages参数控制输出格式。
示例1:设置窗口大小存储数据
# 1.导入相关包
from langchain_classic.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=2)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手"})
memory.save_context({"input": "你的生日是哪天?"}, {"output": "我不清楚"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
示例2:返回消息构成的上下文记忆
# 1.导入相关包
from langchain_classic.memory import ConversationBufferWindowMemory
# 2.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=2, return_messages=True)
# 3.保存消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 4.读取内存中消息(返回消息内容的纯文本)
print(memory.load_memory_variables({}))
示例3:结合LLM、Chain的使用
from langchain_classic.memory import ConversationBufferWindowMemory
# 1.导入相关包
from langchain_core.prompts.prompt import PromptTemplate
from langchain_classic.chains.llm import LLMChain
# 2.定义模版
template = """以下是人类与AI之间的友好对话描述。AI表现得很健谈,并提供了大量来自其上下文的具体细节。如果AI不知道问题的答案,它会表示不知道。
当前对话:{history}
Human: {question}
AI:
"""
# 3.定义提示词模版
prompt_template = PromptTemplate.from_template(template)
# 4.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 5.实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=1)
# 6.定义LLMChain
conversation_with_summary = LLMChain(
llm=llm,
prompt=prompt_template,
memory=memory,
verbose=True,
)
# 7.执行链(第一次提问)
response1 = conversation_with_summary.invoke({"question":"你好,我是孙小空"})
# 8.执行链(第二次提问)
response2 =conversation_with_summary.invoke({"question":"我还有两个师弟,一个是猪小戒,一个是沙小僧"})
# 9.执行链(第三次提问)
response3 =conversation_with_summary.invoke({"question":"我今年高考,竟然考上了1本"})
# 10.执行链(第四次提问)
response4 =conversation_with_summary.invoke({"question":"我叫什么?"})
print(response4)
当把memory中参数k=1设置为k=3后:

3、其余Memory
3.1 ConversationTokenBufferMemory
ConversationTokenBufferMemory是在token数量控制维度进行选择性保留对话结果。
示例:设置最大token大小为20
因为涉及到token的计算,该方式需要大模型的加入。
#1.导入相关包
from langchain_classic.memory import ConversationTokenBufferMemory
from langchain_openai import ChatOpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationTokenBufferMemory对象
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=20 # 设置token上限 默认值为2000
)
# 添加对话
memory.save_context({"input": "你好吗?"}, {"output": "我很好,谢谢!"})
memory.save_context({"input": "今天天气如何?"}, {"output": "晴天,25度"})
# 查看当前记忆
print(memory.load_memory_variables({}))输出:{'history': 'AI: 晴天,25度'}
3.2 ConversationSummaryMemory
ConversationSummaryMemory是LangChain推出的智能压缩对话历史的记忆机制,使用LLM自动生成对话内容的简要摘要,而不是存储原始对话文本。
示例1:如果实例化ConversationSummaryMemory前,没有历史消息,可以使用构造方法实例化
# 1.导入相关包
from langchain_classic.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.创建大模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.定义ConversationSummaryMemory对象
memory = ConversationSummaryMemory(llm=llm)
# 4.存储消息
memory.save_context({"input": "你好"}, {"output": "怎么了"})
memory.save_context({"input": "你是谁"}, {"output": "我是AI助手小智"})
memory.save_context({"input": "初次对话,你能介绍一下你自己吗?"}, {"output": "当然可以了。我是一个无所不能的小智。"})
# 5.读取消息(总结后的)
print(memory.load_memory_variables({}))
示例2:如果实例化ConversationSummaryMemory前,已经有历史消息,可以调用from_messages()实例化
from langchain_classic.memory import ConversationSummaryMemory, ChatMessageHistory
from langchain_openai import ChatOpenAI
# 2.定义ChatMessageHistory对象
llm = ChatOpenAI(model="gpt-4o-mini")
# 3.假设原始消息
history = ChatMessageHistory()
history.add_user_message("你好,你是谁?")
history.add_ai_message("我是AI助手小智")
# 4、创建ConversationSummaryMemory实例
memory = ConversationSummaryMemory.from_messages(
llm = llm,
chat_memory = history,
)
print(memory.load_memory_variables({}))
memory.save_context(inputs = {"human":"我的名字是小明"},outputs = {"AI":{"很高兴认识你"}})
print(memory.load_memory_variables({}))
3.3 ConversationSummaryBufferMemory
ConversationSummaryBufferMemory在保留最近的对话原始记录同时,对较早的对话内容进行摘要。(完整对话记录+摘要记忆)
示例:构造方法实例化
from langchain_classic.memory import ConversationSummaryBufferMemory
llm =ChatOpenAI(model = "gpt-4o-mini")
memory = ConversationSummaryBufferMemory(
llm = llm,
max_token_limit=40, #控制缓冲区大小
return_messages=True
)
# 向memory存储信息
memory.save_context(inputs = {"input":"你好,我的名字叫小明"},outputs = {"output":"很高兴认识你"})
memory.save_context(inputs = {"input":"李白是哪个朝代的"},outputs = {"output":"李白是唐朝的"})
memory.save_context(inputs = {"input":"唐宋八大家有苏轼吗"},outputs = {"output":"有"})
print(memory.load_memory_variables({}))
3.4 ConversationEntityMemory
ConversationEntityMemory是一种基于实体的对话记忆机制,能够识别、存储和利用对话中出现的实体信息(人名、地名、产品)及其属性。
在医疗等高风险领域,必须使用实体记忆确保关键信息被识别。
from langchain_classic.chains.conversation.base import LLMChain
from langchain_classic.memory import ConversationEntityMemory
from langchain_classic.memory.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from langchain_openai import ChatOpenAI
# 初始化大语言模型
llm = ChatOpenAI(
model='gpt-4o-mini',
temperature=0
)
# 使用LangChain为实体记忆设计的预定义模板
prompt = ENTITY_MEMORY_CONVERSATION_TEMPLATE
# 初始化实体记忆
memory = ConversationEntityMemory(llm=llm)
# 提供对话链
chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
#verbose=True, # 设置为True可以看到链的详细推理过程
)
# 进行几轮对话,记忆组件会在后台自动提取和存储实体信息
chain.invoke(input="你好,我叫蜘蛛侠。我的好朋友包括钢铁侠、美国队长和绿巨人。")
chain.invoke(input="我住在纽约。")
chain.invoke(input="我使用的装备是由斯塔克工业提供的。")
# 查询记忆体中存储的实体信息
print("\n当前存储的实体信息:")
print(chain.memory.entity_store.store)
# 基于记忆进行提问
answer = chain.invoke(input="你能告诉我蜘蛛侠住在哪里以及他的好朋友有哪些吗?")
print("\nAI的回答:")
print(answer)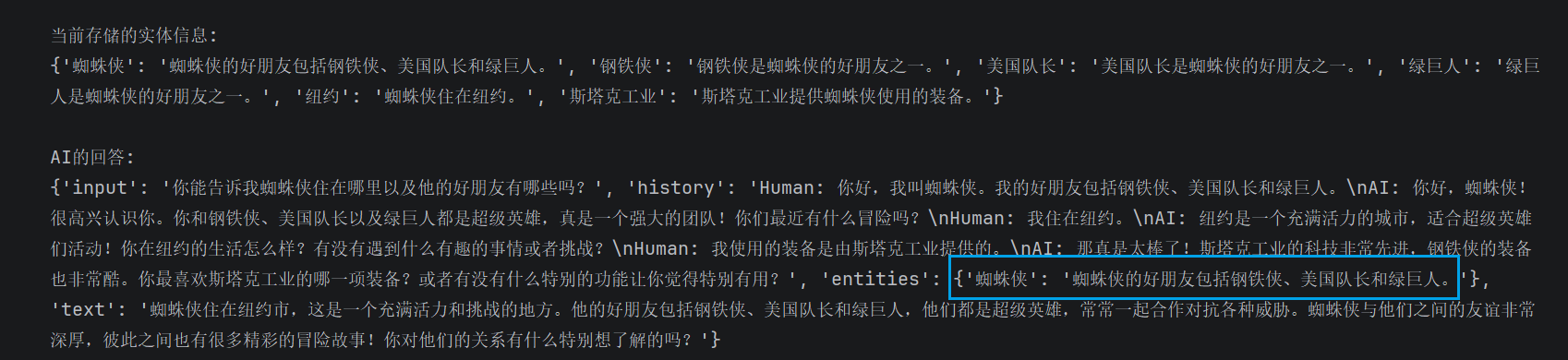
3.5 ConversationKGMemory
ConversationKGMemory是一种基于知识图谱的对话记忆模块,他不但能识别和存储实体,还能捕捉实体之间的复杂关系,形成结构化的知识网络。
#1.导入相关包
from langchain_classic.memory import ConversationKGMemory
from langchain_openai import ChatOpenAI
# 2.定义LLM
llm = ChatOpenAI(
model="gpt-4o-mini",
temperature=0
)
# 3.定义ConversationKGMemory对象
memory = ConversationKGMemory(llm=llm)
# 4.保存会话
memory.save_context(inputs = {"input": "向山姆问好"}, outputs = {"output": "山姆是谁"})
memory.save_context({"input": "山姆是我的朋友"}, {"output": "好的"})
# 5.查询会话
memory.load_memory_variables({"input": "山姆是谁"})输出:{'history': 'On 山姆: 山姆 是 我的朋友.'}
memory.get_knowledge_triplets("她最喜欢的颜色是红色") #将对话内容转化为 (头实体, 关系, 尾实体) 的三元组形式
3.6 VectorStoreRetrieverMemory
VectorStoreRetrieverMemory是基于向量检索的先进记忆机制,将对话历史存储在向量数据库,通过语义相似度检索相关信息,每次调用时查找关联最高的K个文档。
适用于需要长期记忆和语义理解的复杂对话系统。
# 1.导入相关包
from langchain_openai import OpenAIEmbeddings
from langchain_classic.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import FAISS
from langchain_classic.memory import ConversationBufferMemory
# 2.定义ConversationBufferMemory对象
memory = ConversationBufferMemory()
memory.save_context({"input": "我最喜欢的食物是披萨"}, {"output": "很高兴知道"})
memory.save_context({"Human": "我喜欢的运动是跑步"}, {"AI": "好的,我知道了"})
memory.save_context({"Human": "我最喜欢的运动是足球"}, {"AI": "好的,我知道了"})
# 3.定义向量嵌入模型
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002" )
# 4.初始化向量数据库
vectorstore = FAISS.from_texts(memory.buffer.split("\n"), embeddings_model)# 空初始化
# 5.定义检索对象
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
# 6.初始化VectorStoreRetrieverMemory
memory = VectorStoreRetrieverMemory(retriever=retriever)
print(memory.load_memory_variables({"prompt":"我最喜欢的食物是"}))输出:{'history': 'Human: 我最喜欢的食物是披萨'}

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)