AttributeError: module ‘mediapipe‘ has no attribute ‘solutions‘
·
MediaPipe 0.10.0 ~ latest更换API :
MediaPipe 从 0.10.x 版本开始全面重构了 API,彻底废弃了旧版的 solutions 模块(比如 mp.solutions.face_mesh、mp.solutions.pose 等写法),统一使用新的 tasks 模块 + 独立的 vision/text/audio 子模块 替代。
如果与遇到报错:
AttributeError: module ‘mediapipe’ has no attribute ‘solutions’
可以先检查版本:
import mediapipe as mp
print(mp.__version__) #看版本
print(dir(mp)) #看模块
方案1
重新安装低版本
- 卸载
# 强制安装特定版本
pip uninstall mediapipe
# 手动安装冲突依赖
pip uninstall numpy
- 重新强制安装
# 强制安装特定版本
pip install mediapipe==0.9.1 --force-reinstall
# 手动安装冲突依赖
pip install numpy==1.21.6 six==1.16.0
- 检查版本
方案2:
用新的版本
关键变化
- 不再用 solutions:直接删除所有 mp.solutions 相关代码
- 必须下载模型文件:新版需要本地 .task 模型文件(旧版是内置的)
- 初始化方式完全不同:旧版是创建解决方案实例,新版是创建检测器 / 标记器
- 输入输出格式:统一使用 mp.Image 包装图像数据
模型地址
🔥 视觉类(最常用,优先存)
- 人脸关键点 / 人脸网格(FaceLandmarker)
用途:人脸 468 关键点、虹膜、嘴唇、表情
下载:https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task - 手部关键点(HandLandmarker)
用途:单手 / 双手 21 个关节点
下载:https://storage.googleapis.com/mediapipe-models/hand_landmarker/hand_landmarker/float16/1/hand_landmarker.task - 姿态估计(PoseLandmarker)
用途:全身 33 个关键点
下载:https://storage.googleapis.com/mediapipe-models/pose_landmarker/pose_landmarker_lite/float16/1/pose_landmarker_lite.task - 人脸检测(FaceDetector)
用途:只检测人脸框,不关键点
下载:https://storage.googleapis.com/mediapipe-models/face_detector/blaze_face_short_range/float16/1/blaze_face_short_range.tflite - 全身融合(HolisticLandmarker)
用途:人脸 + 手势 + 姿态 一体检测
下载:https://storage.googleapis.com/mediapipe-models/holistic_landmarker/holistic_landmarker/float16/1/holistic_landmarker.task - 人像分割(SelfieSegmentation)
用途:抠图、背景虚化
下载:https://storage.googleapis.com/mediapipe-models/image_segmenter/selfie_multiclass_256x256/float16/1/selfie_multiclass_256x256.task - 手势识别(GestureRecognizer)
用途:识别数字、点赞、OK、拳头等手势
下载:https://storage.googleapis.com/mediapipe-models/gesture_recognizer/gesture_recognizer/float16/1/gesture_recognizer.task
🎯 目标检测 / 常用小模型 - 高效目标检测
下载:https://storage.googleapis.com/mediapipe-models/object_detector/efficientdet_lite0/float16/1/efficientdet_lite0.tflite - 分类模型(ImageClassifier)
下载:https://storage.googleapis.com/mediapipe-models/image_classifier/efficientnet_lite0/float16/1/efficientnet_lite0.tflite
案例
import cv2
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
# 初始化检测器
base_options = python.BaseOptions(model_asset_path='./tasks/hand_landmarker.task')
options = vision.HandLandmarkerOptions(
base_options=base_options,
num_hands=2
)
detector = vision.HandLandmarker.create_from_options(options)
mp_hands = mp.tasks.vision.HandLandmarksConnections #手部关键点连接关系(官方定义好的骨头连线)
mp_drawing = mp.tasks.vision.drawing_utils ## 绘图工具(画关键点、连线)
mp_drawing_styles = mp.tasks.vision.drawing_styles ## 绘图样式(关键点颜色、大小、连线颜色)
MARGIN = 10 # pixels
FONT_SIZE = 1
FONT_THICKNESS = 1
HANDEDNESS_TEXT_COLOR = (88, 205, 54) # vibrant green
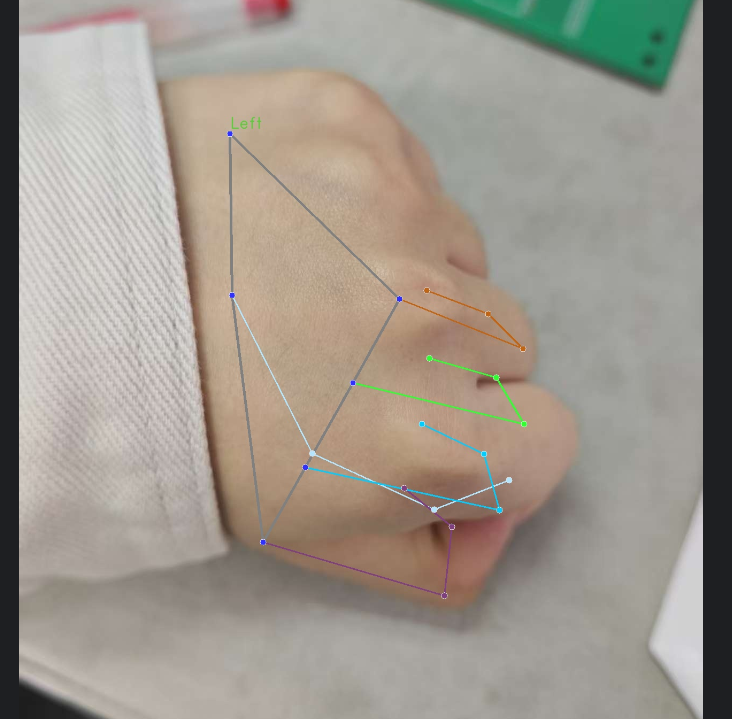
def draw_landmarks_on_image(rgb_image, detection_result):
hand_landmarks_list = detection_result.hand_landmarks # 所有关键点
handedness_list = detection_result.handedness # 左右手判断结果
annotated_image = np.copy(rgb_image) #复制原图
# 循环处理每一只检测到的手
for idx in range(len(hand_landmarks_list)):
# 当前这只手的关键点
hand_landmarks = hand_landmarks_list[idx]
# 当前这只手的左右手信息
handedness = handedness_list[idx]
# Draw the hand landmarks.画出手部关键点 + 连线
mp_drawing.draw_landmarks(
annotated_image, # # 要画在哪个图上
hand_landmarks, # 关键点数据
mp_hands.HAND_CONNECTIONS, # 连线规则(官方定义好的)
mp_drawing_styles.get_default_hand_landmarks_style(), # 关键点样式
mp_drawing_styles.get_default_hand_connections_style()) # 连线样式
# Get the top left corner of the detected hand's bounding box.计算文字位置(左手/右手标签)
height, width, _ = annotated_image.shape # 获取图片宽高
x_coordinates = [landmark.x for landmark in hand_landmarks] # x坐标
y_coordinates = [landmark.y for landmark in hand_landmarks] #y坐标
# 找到手部最左侧、最上方的坐标 → 文字放在这里
text_x = int(min(x_coordinates) * width)
text_y = int(min(y_coordinates) * height) - MARGIN
# Draw handedness (left or right hand) on the image.
cv2.putText(
annotated_image, # 目标图像
f"{handedness[0].category_name}", # 文字:Left 或 Right
(text_x, text_y), # 文字位置
cv2.FONT_HERSHEY_DUPLEX, # 字体
FONT_SIZE, # 大小
HANDEDNESS_TEXT_COLOR, # 颜色
FONT_THICKNESS, # 粗细
cv2.LINE_AA # 抗锯齿
)
return annotated_image
# 处理图像
image = cv2.imread("./imgs/test.jpg")
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
# 检测
detection_result = detector.detect(mp_image)
# 2. 绘制关键点(图)
annotated_img = draw_landmarks_on_image(cv2.cvtColor(image, cv2.COLOR_BGR2RGB), detection_result)
# ======================
# ✅ 新增:保存图片到 imgs 文件夹
# ======================
import os
if not os.path.exists("imgs"):
os.makedirs("imgs")
# 保存(必须转 BGR)
cv2.imwrite("imgs/hand_result.jpg", cv2.cvtColor(annotated_img, cv2.COLOR_RGB2BGR))
print("✅ 结果已保存到:imgs/hand_result.jpg")
# 3. 显示
cv2.imshow("Result", cv2.cvtColor(annotated_img, cv2.COLOR_RGB2BGR))
cv2.waitKey(0)
cv2.destroyAllWindows()

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)