10分钟入门:收藏!Agent记忆系统四层架构详解,小白也能学会大模型进阶
花 10 分钟,搞清楚 Agent 记忆系统的四层架构。
目录
-
- 什么是 Agentic Memory?
-
- 四种记忆类型
- 2.1 上下文记忆(In-context Memory)
- 2.2 外部记忆(External Memory)
- 2.3 情景记忆(Episodic Memory)
- 2.4 语义/参数记忆(Semantic/Parametric Memory)
-
- 记忆如何在 Agent Loop 中流动?
-
- 构建记忆层
- 4.1 MemoryStore 类
- 4.2 EpisodicLogger 类
- 4.3 整合:记忆增强 Agent
-
- 向量数据库
- 5.1 相似性搜索原理
-
- 记忆管理
- 6.1 基于时间的衰减
- 6.2 写入时的重要性打分
- 6.3 定期整合
-
- 总结
想象某天你雇了一个天才员工。第一天她表现惊艳:发现了所有 bug、写了清晰的文档、甚至提出了你没想到的改进。你很满意。
第二天你走过去说:“嘿,还记得昨天我们讨论的那个问题吗?”
她停顿了一下,看着你,微微一笑。
“抱歉……什么问题?”
没有记忆,没有上下文。完全忘了。你在写这段的时候也会和我一样意外。
对LLM来说,这是常态 。 每次新对话都是从零开始。模型不记得你是谁、不记得你们一起做过什么,甚至不记得几分钟前在另一个窗口讨论了什么。
对于简单聊天机器人,这无所谓。但对于 Agent——那种跑任务、做决策、随时间改进的系统——这种失忆是致命的。
真正的智能不只是响应得良好,还关乎记忆、学习,以及在既有基础上进化。记忆把一个无状态系统变成了能真正演进的智能体。
- 什么是 Agentic Memory?
Agentic memory 不是单一组件,它更像一套幕后系统:不同类型的存储、不同检索方式、以及智能管理策略,让 Agent 能真正跨时间携带上下文。
说白了,记忆同时在做三件有区别的事。
连续性(Continuity)关乎身份。Agent 如何知道你是谁、你偏好什么、以及你们已经一起建立了什么。没有它,每次交互都像从零开始。
上下文(Context)关乎当前任务。刚发生了什么、用了什么工具、返回了什么结果、以及下一步需要做什么。它让多步骤工作流不至于崩掉。
学习(Learning)关乎变得更好。理解什么有效、什么无效、慢慢改进决策而不是重复同样的错误。
三者合一,让 Agent 每次交互都更一致、更可靠、甚至更智能一点。
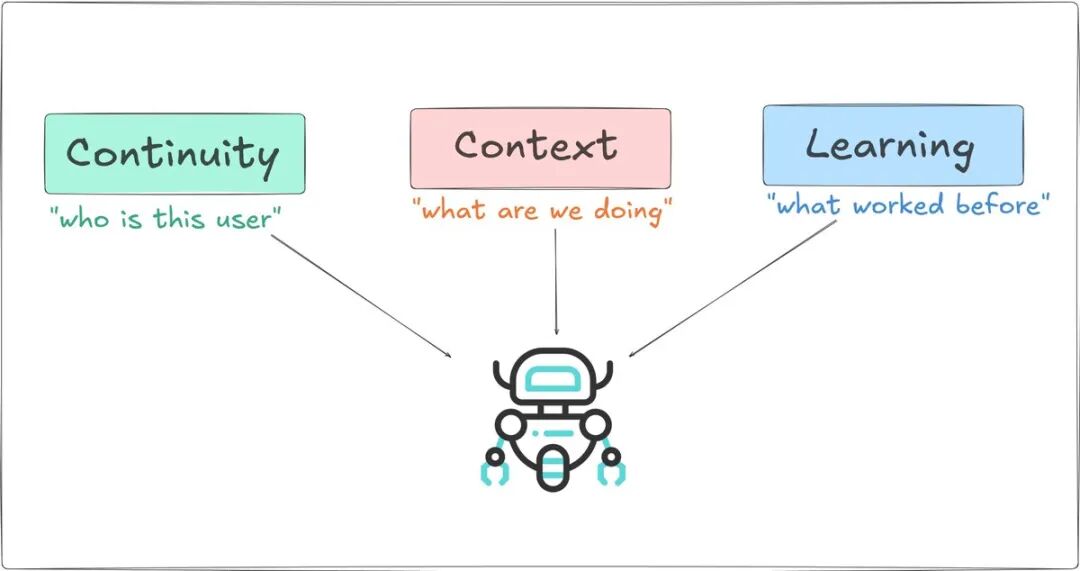
一个设计良好的 Agent 记忆系统同时处理这三件事,每种用不同的存储后端。
- 四种记忆类型
业界已经沉淀出四种有区别的记忆类型。可以把它们理解成大脑的四个区域,每个各司其职。
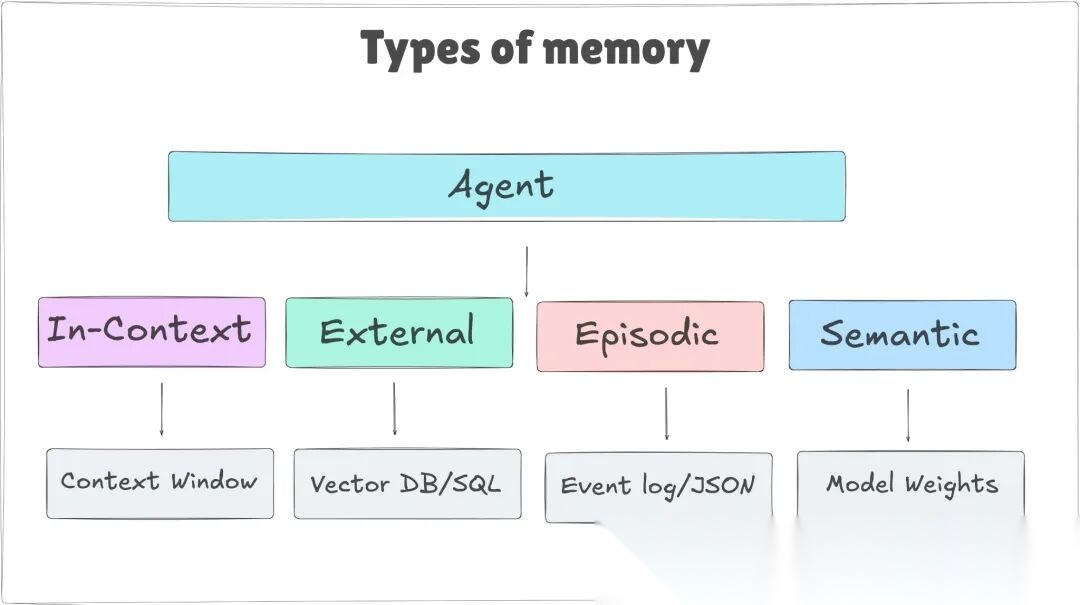
2.1 上下文记忆(In-context Memory)
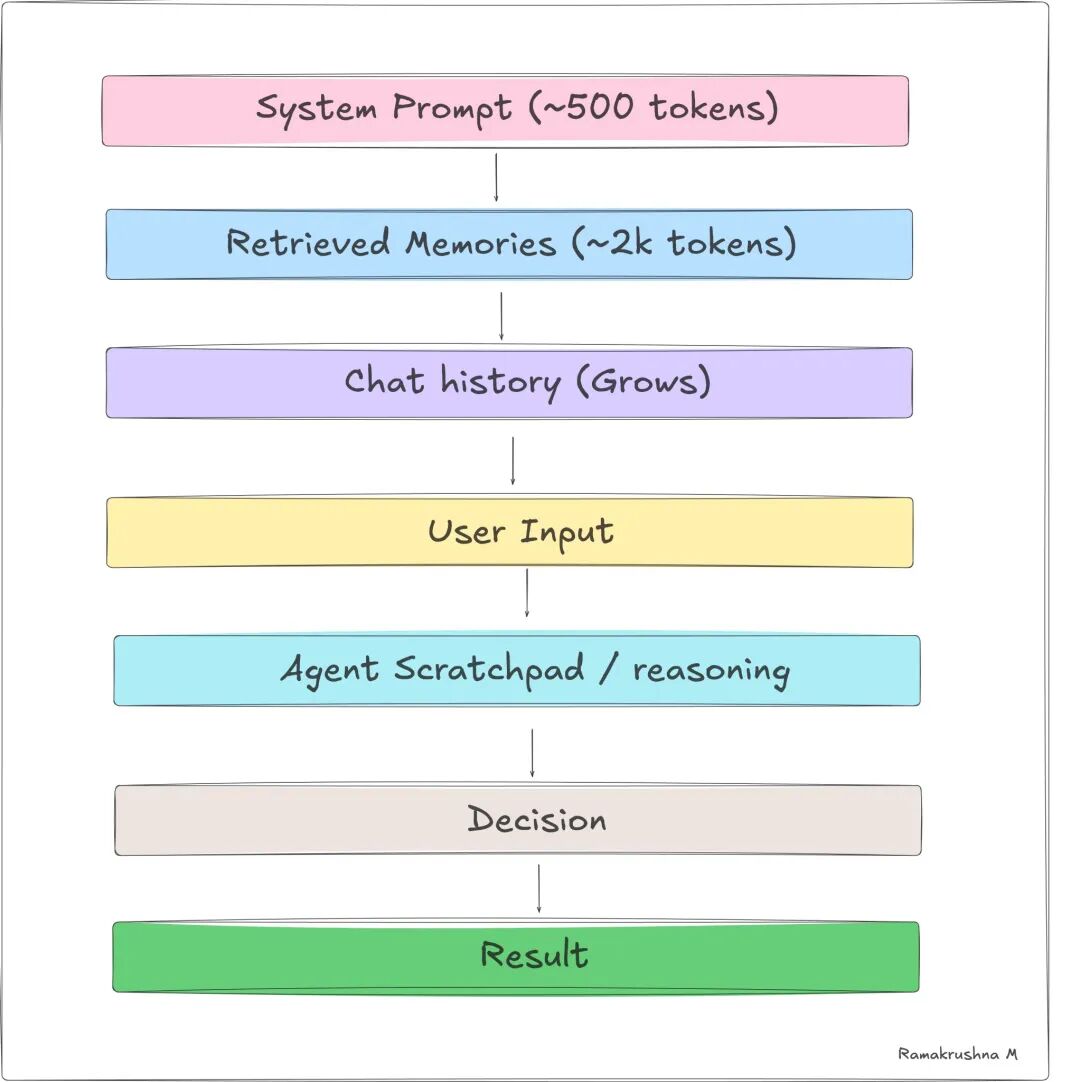
上下文窗口是 Agent 的**工作台。**上面的东西都能即时访问,模型可以在单次前向传播中推理。不需要检索步骤。
但工作台有尺寸限制。每个 token 都要花钱和时间。会话结束时,工作台会被清空。
上下文窗口里有什么?
- System prompt:Agent 人设、规则、能力、当前日期/用户信息
- 对话历史:本次会话的来回交互
- 工具调用结果:Agent 刚调用的工具输出
- 检索到的记忆:从外部存储拉取的片段
- Scratchpad:中间推理(逐步思考输出)
滑动窗口问题
长对话中,历史积累最终会溢出上下文限制。简单截断最旧消息会丢失重要的早期上下文。更好的策略:
- **摘要(Summarization):**定期把旧的对话压缩成简短摘要,用摘要替换
- **选择性保留(Selective retention):**保留包含关键事实、决策或工具结果的对话;丢弃闲聊
- **卸载到外部记忆:**把重要事实提取到向量存储,需要时检索
2.2 外部记忆(External Memory)
外部记忆是任何持久化在模型之外的东西——数据库、向量存储、键值存储、文件。它跨越会话边界存活。如果存储得当,Agent 能记住六个月前的事。
外部存储有两种形式:
**结构化存储(精确查询):**PostgreSQL、Redis、SQLite。按 key、ID 或 SQL 查询。快速、可预测,适合用户画像、偏好和结构化数据。
**向量存储(语义搜索):**Pinecone、Chroma、pgvector。按语义查询,“找与这个概念相似的记忆”。对非结构化笔记和情景回忆至关重要。
检索步骤是瓶颈。 检索不到正确的记忆,Agent 就当那些记忆不存在。记忆架构搞得好不好,80% 看检索设计。
2.3 情景记忆(Episodic Memory)
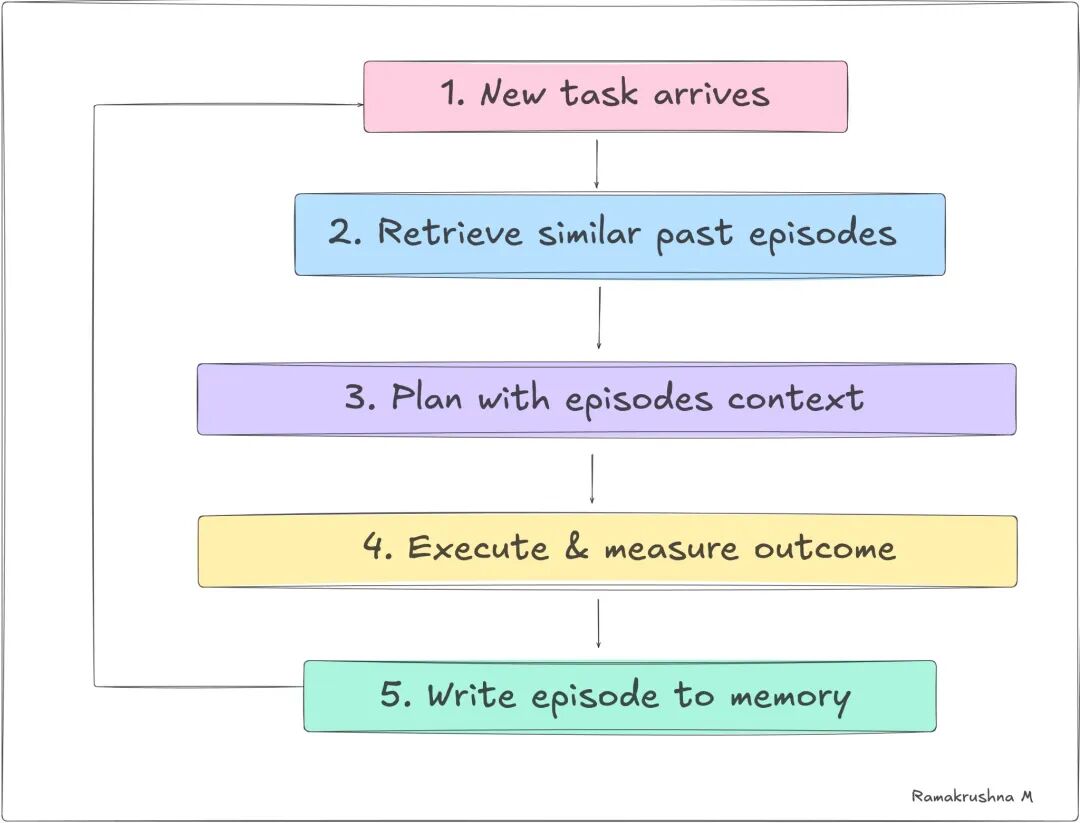
情景记忆是最被低估的类型。外部记忆存储事实,情景记忆存储事件——具体来说是过去行为的结果。
最简单形式是结构化日志:每次 Agent 完成一个任务,它记录发生了什么。随着时间,这个日志成为丰富的自我知识来源,Agent 可以在做决策前查阅。
一个 episode 长这样:
{ "episode_id": "ep_20240315_003", "timestamp": "2024-03-15T14:23:11Z", "task": "Summarize 50-page PDF into 3 bullet points", "approach": "Sequential chunking, 2000 tokens per chunk", "outcome": "success", "duration_ms": 4820, "token_cost": 12400, "quality_score": 0.91, "notes": "Worked well. Hierarchical chunking would be faster.", "embedding": [0.023, -0.441, 0.182, /* ... 1536 dims */]}
新任务进来时,Agent 检索语义最相似的老 episode,用它们来选择策略。说白了,这是从个人历史做 few-shot learning,而不是从手工数据集聚类。
反思循环:
2.4 语义/参数记忆(Semantic/Parametric Memory)
这是模型与生俱来的记忆。所有东西在训练时编码进权重:世界事实、语言模式、推理策略、编码规范、文化知识。
它一直都在。Agent 从不需要检索它。但它有硬限制:
- **训练时冻结:**模型不知道 cutoff 日期之后发生了什么
- **运行时无法更新:**不重训练或微调就无法注入新的永久事实
- **不透明:**无法检查模型到底"知道"什么或不知道什么
- **容易幻觉:**模型用似是而非的错误内容填补空白
对于时间敏感、领域特定或私有的内容,不要依赖参数记忆。用外部检索。参数记忆是你在没有更好来源时的通用世界知识 fallback。
正确的思维模型:参数记忆是 Agent 的通识教育。外部、情景和上下文记忆是 Agent 的在职经验。最好的 Agent 两者结合。

- 记忆如何在 Agent Loop 中流动?
让我们整合起来。以下是 Agent 每次处理请求时发生的事——展示每个记忆系统都在运作。
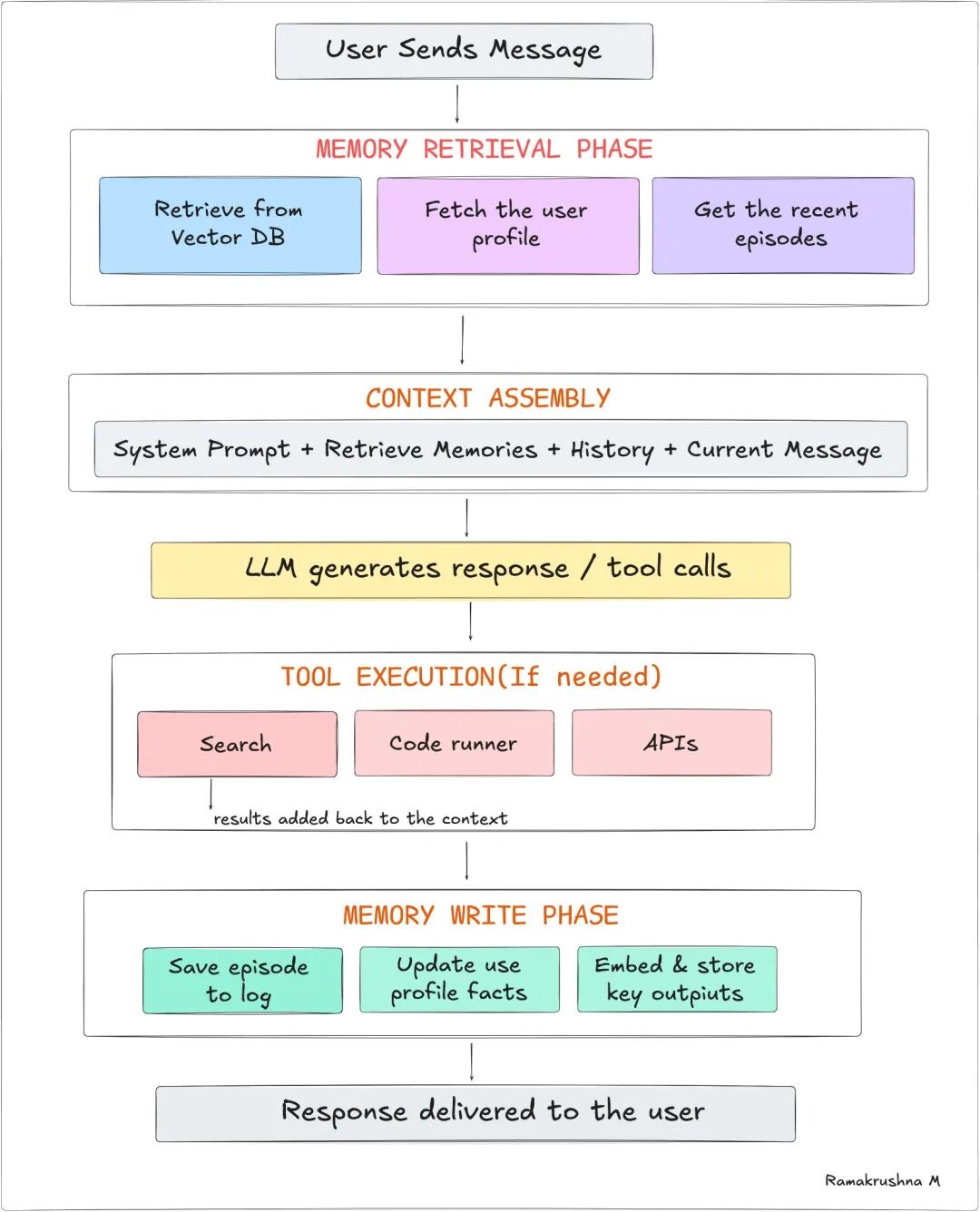
注意记忆操作是包裹 LLM 调用的:先检索、再写入。模型本身无状态,是记忆系统给了无状态的 Agent 有状态的假象。
- 构建记忆层
上代码。用 Python + OpenAI 做嵌入、ChromaDB 做本地向量存储。概念是通用的,换库就行。
pip install chromadb openai anthropic python-dotenv
4.1 MemoryStore 类
这是记忆层的核心:写入(带嵌入)和语义检索。
import chromadbfrom openai import OpenAIfrom datetime import datetimeimport json, uuidclass MemoryStore: """Persistent vector memory for an AI agent.""" def __init__(self, agent_id: str, persist_dir: str = "./memory_db"): self.agent_id = agent_id self.openai = OpenAI() # ChromaDB stores vectors on disk, persists across restarts self.client = chromadb.PersistentClient(path=persist_dir) self.collection = self.client.get_or_create_collection( name=f"agent_{agent_id}_memories", metadata={"hnsw:space": "cosine"} # cosine similarity ) def _embed(self, text: str) -> list[float]: """Convert text to embedding vector using OpenAI.""" response = self.openai.embeddings.create( model="text-embedding-3-small", input=text ) return response.data[0].embedding def remember( self, content: str, memory_type: str = "general", metadata: dict = None ) -> str: """Store a memory. Returns the memory ID.""" memory_id = str(uuid.uuid4()) embedding = self._embed(content) meta = { "type": memory_type, "timestamp": datetime.utcnow().isoformat(), "agent_id": self.agent_id, **(metadata or {}) } self.collection.add( ids=[memory_id], embeddings=[embedding], documents=[content], metadatas=[meta] ) return memory_id def recall( self, query: str, k: int = 5, memory_type: str = None, min_relevance: float = 0.6 ) -> list[dict]: """Retrieve the k most relevant memories for a query.""" query_embedding = self._embed(query) where = {"type": memory_type} if memory_type else None results = self.collection.query( query_embeddings=[query_embedding], n_results=k, where=where, include=["documents", "metadatas", "distances"] ) memories = [] for doc, meta, dist in zip( results["documents"][0], results["metadatas"][0], results["distances"][0] ): relevance = 1 - dist # cosine distance → similarity if relevance >= min_relevance: memories.append({ "content": doc, "metadata": meta, "relevance": round(relevance, 3) }) return sorted(memories, key=lambda x: x["relevance"], reverse=True) def forget(self, memory_id: str): """Delete a specific memory (GDPR compliance, stale data, etc.)""" self.collection.delete(ids=[memory_id])
4.2 EpisodicLogger 类
在 MemoryStore 之上叠加坡情日志层。
from .store import MemoryStorefrom dataclasses import dataclass, asdictfrom typing import Optionalimport time@dataclassclass Episode: task: str approach: str outcome: str # "success" | "partial" | "failure" duration_ms: int token_cost: int quality_score: float # 0.0 – 1.0, set by evaluator or user notes: str = "" error: Optional[str] = Noneclass EpisodicLogger: def __init__(self, memory_store: MemoryStore): self.store = memory_store def log(self, episode: Episode): """Save an episode to memory as a searchable document.""" # Build a rich text representation for semantic search doc = ( f"Task: {episode.task}\n" f"Approach: {episode.approach}\n" f"Outcome: {episode.outcome}\n" f"Notes: {episode.notes}" ) self.store.remember( content=doc, memory_type="episode", metadata={ "outcome": episode.outcome, "quality_score": episode.quality_score, "duration_ms": episode.duration_ms, "token_cost": episode.token_cost, } ) def recall_similar(self, task: str, k: int = 3) -> list[dict]: """Find past episodes similar to the current task.""" return self.store.recall( query=task, k=k, memory_type="episode", min_relevance=0.65 )
4.3 整合:记忆增强 Agent
import anthropicfrom memory.store import MemoryStorefrom memory.episodic import EpisodicLogger, Episodeimport timeclass MemoryAugmentedAgent: def __init__(self, agent_id: str): self.client = anthropic.Anthropic() self.memory = MemoryStore(agent_id) self.episodes = EpisodicLogger(self.memory) def _build_memory_context(self, user_message: str) -> str: """Retrieve relevant memories and format them for injection.""" # Semantic search for related facts memories = self.memory.recall(user_message, k=4) # Similar past task approaches episodes = self.episodes.recall_similar(user_message, k=2) context_parts = [] if memories: context_parts.append("## Relevant memories\n" + "\n".join([ f"- [{m['metadata']['type']}] {m['content']}" f" (relevance: {m['relevance']})" for m in memories ]) ) if episodes: context_parts.append("## Past similar tasks\n" + "\n".join([ f"- {e['content'][:200]}..." for e in episodes ]) ) return "\n\n".join(context_parts) if context_parts else "" def run(self, user_message: str) -> str: start = time.time() # 1. Retrieve relevant memory memory_context = self._build_memory_context(user_message) # 2. Build system prompt with injected memory system = """You are a helpful agent with memory.You have access to relevant context from past interactions.Use this context to give better, more personalized responses.""" if memory_context: system += f"\n\n{memory_context}" # 3. Call the model response = self.client.messages.create( model="claude-opus-4-6", max_tokens=1024, system=system, messages=[{"role": "user", "content": user_message}] ) answer = response.content[0].text duration = int((time.time() - start) * 1000) # 4. Save useful info to memory for next time self.memory.remember( content=f"User asked: {user_message[:200]}", memory_type="interaction" ) # 5. Log the episode self.episodes.log(Episode( task=user_message[:200], approach="single-turn with memory retrieval", outcome="success", duration_ms=duration, token_cost=response.usage.input_tokens + response.usage.output_tokens, quality_score=1.0, # would come from evaluation in prod )) return answer
- 向量数据库
向量检索是正经记忆系统的核心。它不靠精确匹配(不像 SQL),而是在高维空间里找最近邻。这才实现了语义搜索——即便没有共同词汇,也能找到语义相关的记忆。
5.1 相似性搜索原理
每个记忆被转换成向量(用 OpenAI 嵌入模型是 1,536 个浮点数数组)。概念上相似的文本产生相似的向量。查询时,嵌入查询语句,用余弦相似度找最接近的向量。
import numpy as npdef cosine_similarity(a: list, b: list) -> float: """ 1.0 = identical meaning 0.0 = unrelated -1.0 = opposite meaning """ a, b = np.array(a), np.array(b) return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))# Example: these two sentences will have high similarityembedding_a = embed("The user prefers dark mode")embedding_b = embed("They like their interface theme to be dark")score = cosine_similarity(embedding_a, embedding_b)# → ~0.91 (very similar)
本地开发用 ChromaDB。准备部署时,如果已经在用 Postgres,评估 pgvector(零额外基础设施)。需要大规模时用 Pinecone 或 Qdrant。
- 记忆管理
记忆系统光积累不够,还得会忘。一个没有焦点的存储会随时间退化——检索结果越来越嘈杂、延迟上升、相互矛盾的记忆让 Agent 晕头转向。
遗忘策略主要有三种:
6.1 基于时间的衰减
老记忆通常相关性更低。按近因和语义相关性组合给记忆打分。研究中使用的公式:
import mathfrom datetime import datetimedef memory_score( relevance: float, # cosine similarity 0–1 importance: float, # stored at write time 0–1 created_at: datetime, # when memory was formed recency_weight: float = 0.3, decay_factor: float = 0.995) -> float: """ Inspired by the Generative Agents paper (Park et al., 2023). Balances: how relevant, how important, how recent. """ hours_old = (datetime.utcnow() - created_at).total_seconds() / 3600 recency = math.pow(decay_factor, hours_old) return ( relevance * 0.4 + importance * 0.3 + recency * recency_weight )
6.2 写入时的重要性打分
存储记忆时,让模型给自己输出打分。只存储高分的项。这在源头过滤噪音。
import reasync def score_importance(client, content: str) -> float: """Ask the LLM if information is worth saving (0.0 to 1.0).""" prompt = f"""Rate the importance of saving this for future interactions. 0.0 = trivial (greeting) 0.5 = moderately useful 1.0 = critical (preferences, errors, decisions) Information: {content} Reply with ONLY the number.""" try: response = await client.messages.create( model="claude-3-haiku-20240307", max_tokens=10, messages=[{"role": "user", "content": prompt}] ) text = response.content[0].text.strip() match = re.search(r"[-+]?\d*\.\d+|\d+", text) if match: score = float(match.group()) return max(0.0, min(1.0, score)) except Exception: pass return 0.5 # Default fallback
6.3 定期整合
每晚运行任务,把重复或高度相似的记忆合并成单一规范摘要。这类似于人类睡眠巩固记忆的方式。
async def consolidate_memories(store: MemoryStore, similarity_threshold: float = 0.92): """Efficiently merge near-duplicate memories using vector search.""" all_mems = store.collection.get(include=["documents", "embeddings", "ids"]) if not all_mems["ids"]: return visited = set() consolidated_docs = [] for i, (mem_id, doc, emb) in enumerate(zip( all_mems["ids"], all_mems["documents"], all_mems["embeddings"] )): if mem_id in visited: continue results = store.collection.query( query_embeddings=[emb], n_results=10, include=["documents", "distances"] ) group = [doc] visited.add(mem_id) for res_id, res_doc, dist in zip(results["ids"][0], results["documents"][0], results["distances"][0]): sim = 1.0 - dist if res_id != mem_id and res_id not in visited and sim >= similarity_threshold: group.append(res_doc) visited.add(res_id) if len(group) > 1: summary = await summarize_group(group) consolidated_docs.append(summary) else: consolidated_docs.append(doc) store.collection.delete(where={}) for doc in consolidated_docs: await store.remember(doc)
- 总结
没有记忆,Agent 每次交互都从零开始。有了记忆,Agent 才能理解你、适应你、跟你一起进化。
记忆层的设计才是关键:记住什么、遗忘什么、怎么用这些信息——这才是拉开差距的地方。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献81条内容
已为社区贡献81条内容

所有评论(0)