(LangChain)RAG系统链路之数据加载Transformers(二)
1.RAG数据流水线示意图
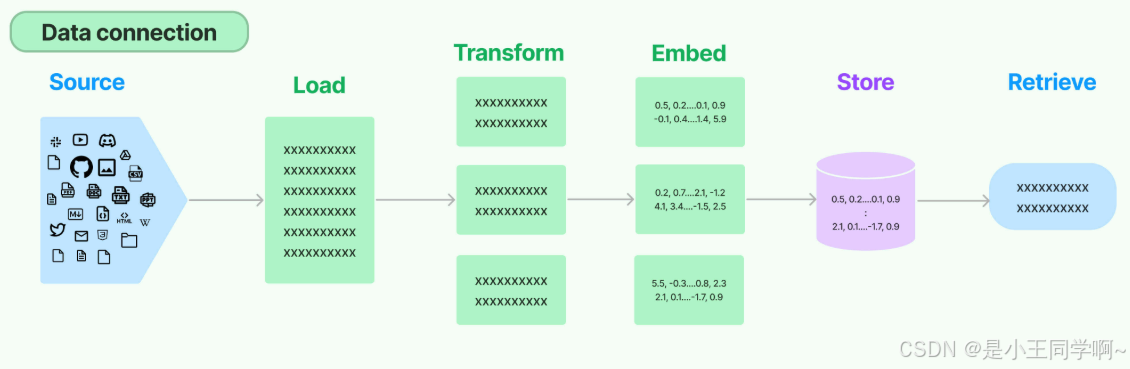
构建RAG系统:涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器
2.为什么要用Transformers
模型输入限制:GPT-4最大上下文32k tokens,Claude 3最高200k
信息密度不均:关键信息可能分布在长文本的不同位置
格式兼容性问题:PDF/HTML/代码等不同格式的结构差异
文档转换器是 LangChain 处理文档流水线的核心组件,负责对原始文档进行结构化和语义化处理,为后续的向量化存储、检索增强生成(RAG)等场景提供标准化输入。
核心任务:文本清洗、分块、元数据增强
关键操作
文本分块:按固定长度或语义分割(防止截断完整句子)
去噪处理:移除特殊字符、乱码、广告内容
元数据注入:添加来源、时间戳等上下文信息
3.文档转换器CharacterTextSplitter
CharacterTextSplitter 字符分割器是 LangChain 中最基础的文本分割器,采用固定长度字符切割策略。
适用于结构规整、格式统一的文本处理场景,强调精确控制块长度.适用于结构清晰的文本(如段落分隔明确的文档)。
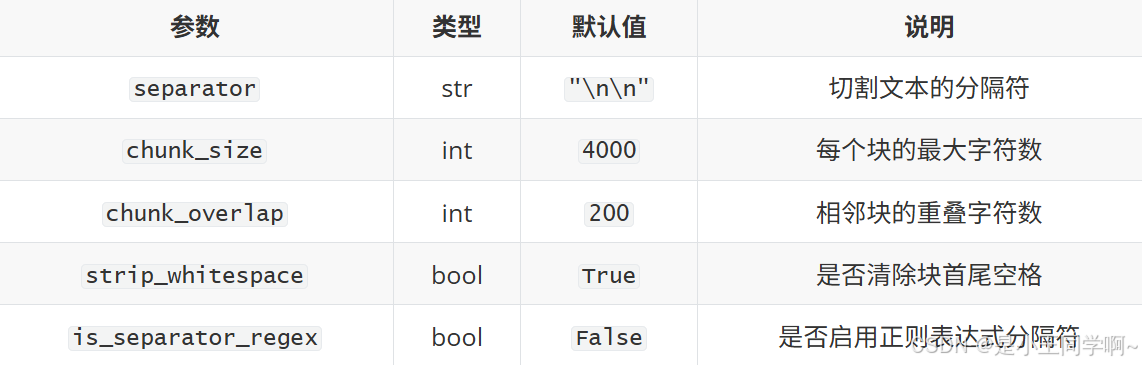
核心参数:
from langchain.text_splitter import CharacterTextSplitter
text = "是一段 需要被分割的 长文本示例....,每个文本块的最大长度(字符数或token数)Document loaders are designed to load document objects. LangChain has hundreds of integrations with various data sources to load data from: Slack, Notion, Google Drive"
splitter = CharacterTextSplitter(separator=" ", chunk_size=50, chunk_overlap=10)
chunks = splitter.split_text(text)
print(len(chunks))
for chunk in chunks:
print(chunk)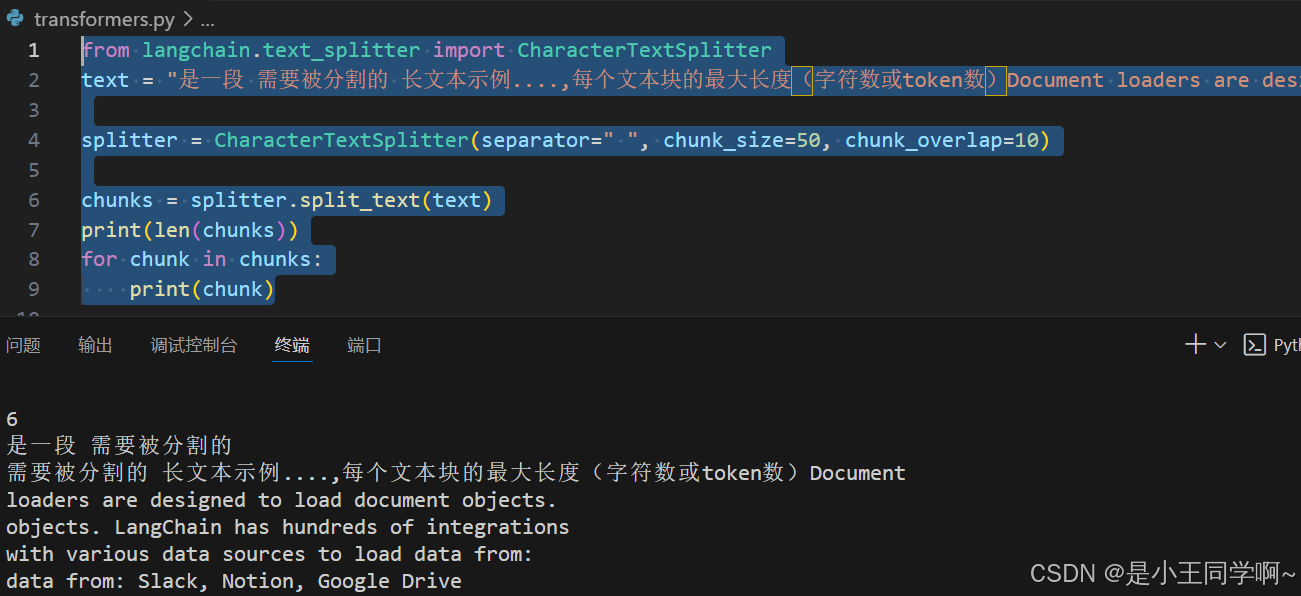
优缺点说明: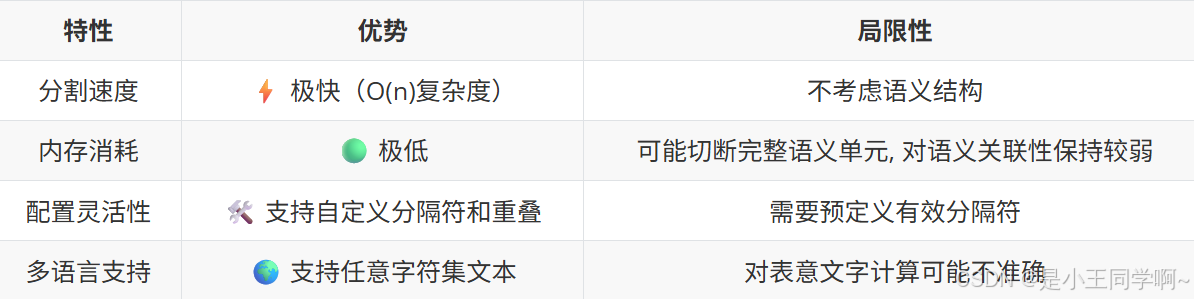
适合场景->
结构化日志处理
代码文件解析
已知明确分隔符的文本(如Markdown)
需要精确控制块大小的场景
4. 递归字符文档转换器TextSplitter(用的比较多)
RecursiveCharacterTextSplitter 递归字符分割器
递归字符分割器采用多级分隔符优先级切割机制,是 LangChain 中使用最广泛的通用分割器。
递归尝试多种分隔符(默认顺序:["\n\n", "\n", " ", ""]),优先按大粒度分割
若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本。
from langchain.text_splitter import RecursiveCharacterTextSplitter
paper_text = """
引言机器学习近年来取得突破性进展...(长文本)若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本
方法我们提出新型网络架构...(技术细节)按优先级(如段落、句子、单词)递归分割文本,优先保留自然边界,如换行符、句号
实验在ImageNet数据集上...处理技术文档时,使用chunk_size=800和chunk_overlap=100,数据表格
"""
splitter = RecursiveCharacterTextSplitter(chunk_size=20, chunk_overlap=4)
paper_chunks = splitter.split_text(paper_text)
print(len(paper_chunks))
for chunk in paper_chunks:
print(chunk)
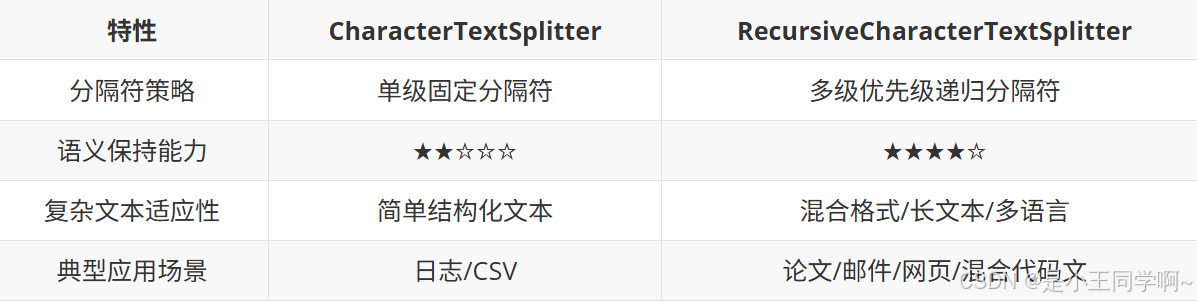
CharacterTextSplitter和RecursiveCharacterTextSplitter对比
RecursiveCharacterTextSplitter适合场景:
学术论文/技术文档解析
多语言混合内容处理
包含嵌套结构的文本(如Markdown)
需要保持段落完整性的问答系统
还有很多Transformers可以参考官网拓展:https://python.langchain.com/docs/how_to/

5.需要关注的核心参数
chunk_size:定义每个文本块的最大长度(根据length_function计算,默认按字符数) 默认值1000 必须为正整数
chunk_overlap:定义相邻块之间的重叠长度 默认20 必须小于chunk_size的50%
常见问题与解决方案
过长导致语义模糊
表现:检索时匹配不精准。
解决:缩小chunk_size,增加chunk_overlap块过短丢失上下文
表现:回答缺乏连贯性。
解决:合并相邻块或使用ParentDocumentRetriever,将细粒度块与父文档关联参数选择原则:
密集文本(如论文):chunk_size较大(如1000),chunk_overlap约15%。
松散文本(如对话记录):chunk_size较小(如200),chunk_overlap约20%。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)