期刊解读:基于TabNet-Stacking的信用违约预测模型研究,《Entropy》
信用风险控制是金融科技的核心命题。本文提出的TabNet-Stacking模型,将改进后的TabNet与Stacking集成学习相结合,在信用违约预测任务上取得了显著优于XGBoost、LightGBM、CatBoost等主流模型的性能。
我方公司专业从事企业建模,期刊论文专利定制服务。具体场景包括:个人信用贷款违约风控模型,企业信用贷款违约风控模型,债券违约预测模型,政府信用评级模型,股票价格预测模型,房价预测模型。
## 该论文由中央财经大学金融学院的王世杰与张学勇合作完成,张学勇为通讯作者,第一作者王世杰同时隶属于河北省农村信用社**,论文于2024年10月发表在MDPI期刊**《Entropy》第26卷第10期。
一、作者信息
|
作者
|
单位
|
备注
|
| — | — | — |
| Shijie Wang
(王世杰)
|
中央财经大学金融学院,北京
|
第一作者
|
| Xueyong Zhang
(张学勇)
|
中央财经大学金融学院,北京
|
通讯作者
|
二、作者所属单位
|
单位名称
|
所在城市
|
备注
|
| — | — | — |
| 中央财经大学金融学院 |
北京
|
第一作者与通讯作者共同所属单位
|
| 河北省农村信用社 |
石家庄
|
第二作者单位(论文中标注为 Rural Credit Cooperative of Hebei, Shijiazhuang 050024, China)
|
|
项目
|
内容
|
| — | — |
| 发布年份 |
2024年
|
| 接收日期 |
2024年10月11日
|
| 发表日期 |
2024年10月13日
|
| 期刊 |
Entropy
|
| 卷/期/文章号 |
Volume 26, Issue 10, Article 861
|
| DOI |
10.3390/e26100861
|
|
项目
|
内容
|
| — | — |
| 期刊名称 |
Entropy
|
| ISSN |
1099-4300
|
| 出版商 |
MDPI (瑞士)
|
| 出版国家 |
瑞士
|
| 开放获取(OA) |
是
|
期刊概述
《Entropy》是由瑞士MDPI出版社出版的国际性学术期刊,被 SCIE(Science Citation Index Expanded) 收录,是Web of Science核心合集中的期刊。目前位于JCR Q2区、中科院3区,2024年影响因子为2.0
引言
随着金融科技的快速发展,传统的基于经验和单一网络的信用违约预测模型已难以满足当下需求。如何高效利用海量数据,准确识别高风险行为,成为金融机构亟需解决的问题。
虽然机器学习模型在信用风险领域已有广泛应用,但单一模型始终存在性能瓶颈。TabNet作为Google在AAAI 2021上发布的专为表格数据设计的深度神经网络,兼顾了树模型的可解释性与深度学习的表征能力,为信用违约预测提供了新的可能性。然而,其在金融领域的应用尚属空白。
本研究首次将TabNet引入信用违约预测,并通过多目标遗传算法优化其特征选择模块、粒子群算法自动调参,最终与Stacking集成学习相结合,构建了TabNet-Stacking信用违约预测模型。
模型核心架构
1. 改进TabNet特征选择模块
TabNet通过顺序注意力机制进行特征选择,但其模块仍有优化空间。本文引入多目标遗传算法对特征选择进行增强:
-
采用二进制编码,1表示特征被选中,0表示未被选中
-
使用轮盘赌选择、单点交叉和基本位变异作为遗传算子
-
通过多种群并行进化,兼顾局部与全局搜索
-
设置迁移算子实现种群间信息交换,避免早熟收敛
这种改进使得特征选择更加精准,能够有效识别对违约预测最有价值的特征。
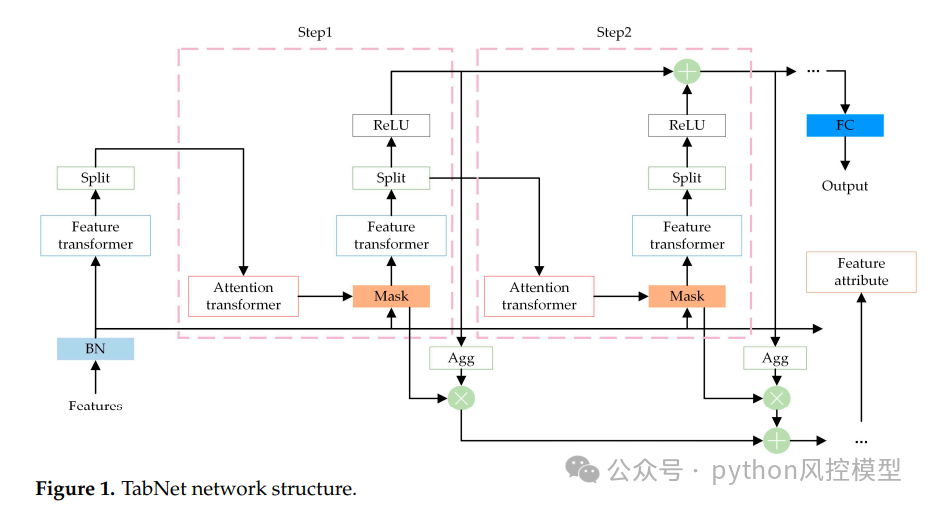
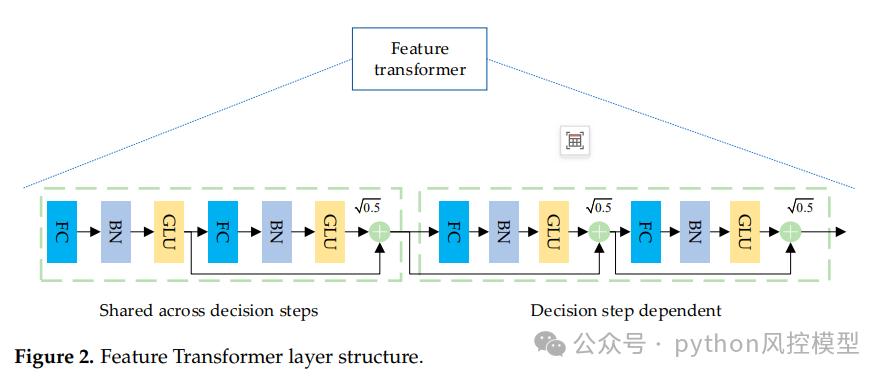
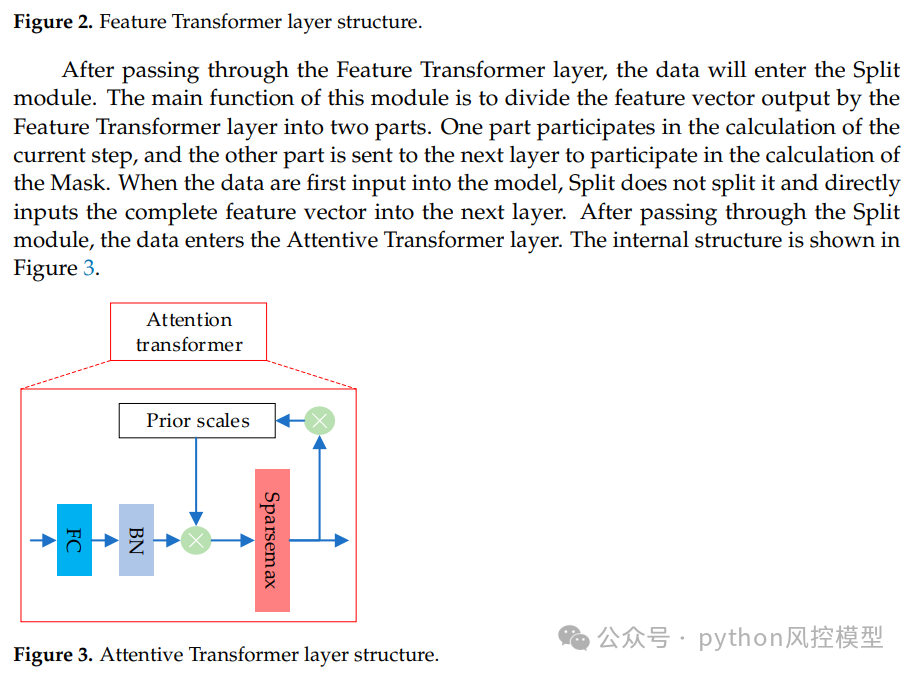
2. 粒子群算法自动调参
TabNet参数复杂、调参困难。本文采用粒子群优化算法实现超参数自动搜索,通过模拟粒子群体在参数空间中的协同搜索,高效找到最优参数组合,提升了模型的适应性和自动化水平。
3. TabNet-Stacking集成框架
模型整体采用双层Stacking集成结构:
-
第一层基学习器:XGBoost、LightGBM、CatBoost、KNN、SVM(五折交叉验证训练)
-
第二层元学习器:XGBoost(从基学习器输出中学习最终预测)
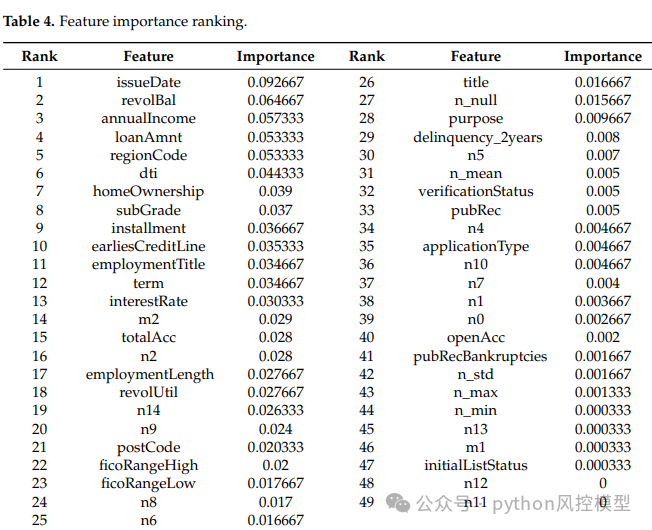
TabNet在此框架中承担特征提取与可解释性的核心角色——通过其Mask矩阵计算各特征在决策中的贡献度,输出特征重要性排序,为后续集成学习提供高质量输入。
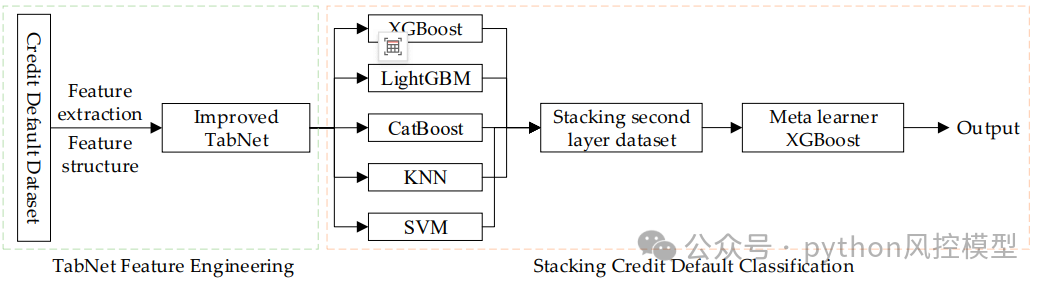
实验设计与结果
数据集
实验采用阿里云天池“贷款违约预测”数据集,共80万条记录,包含47个变量(其中15个为匿名特征),正负样本比例约为1:4,训练集与测试集按4:1划分。
变量名称,描述和数据类型

数值型变量描述性统计表
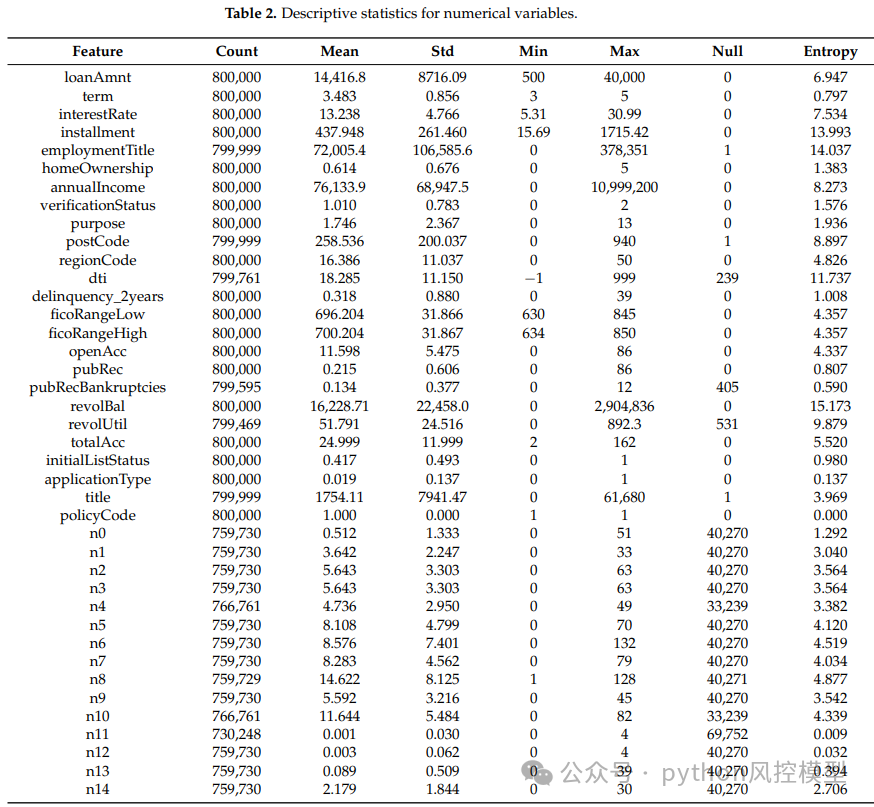
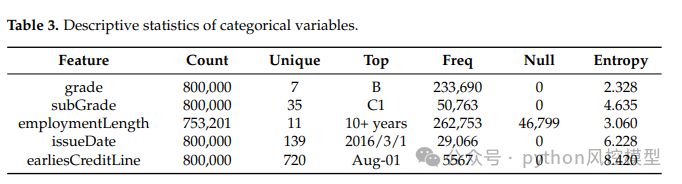
类别变量描述性统计表
变量重要性
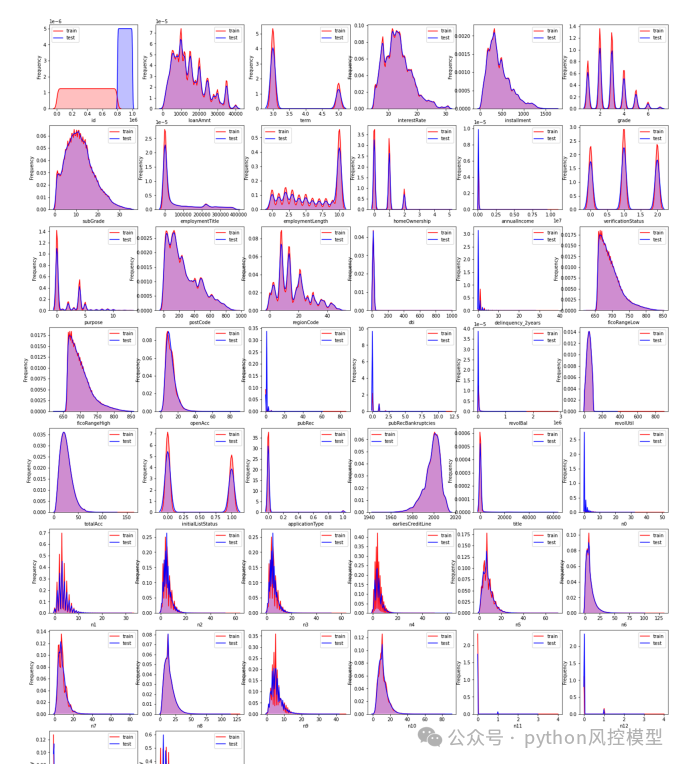
变量分布图
评价指标
采用准确率、精确率、召回率、F1分数、AUC作为评价标准。
多算法比较结果
|
模型
|
Accuracy
|
Precision
|
Recall
|
F1-Score
|
AUC
|
| — | — | — | — | — | — |
|
XGBoost
|
0.920
|
0.505
|
0.691
|
0.583
|
0.816
|
|
LightGBM
|
0.924
|
0.523
|
0.701
|
0.599
|
0.822
|
|
CatBoost
|
0.951
|
0.677
|
0.738
|
0.702
|
0.854
|
|
TabNet
|
0.958
|
0.718
|
0.793
|
0.754
|
0.883
|
| TabNet-Stacking | 0.979 | 0.782 | 0.856 | 0.817 | 0.941 |
结果显示,TabNet-Stacking在所有指标上均显著优于对比模型:
-
准确率提升2.19%~6.41%
-
精确率提升8.91%~54.85%
-
召回率提升7.94%~23.88%
-
F1分数提升8.36%~40.14%
-
AUC提升6.57%~15.32%
尤其值得注意的是,召回率(即违约客户识别率)的提升,对于反欺诈场景具有极高的实际价值。
结论与展望
本文首次在金融学术论文中提出了基于TabNet-Stacking的信用违约预测模型,通过多目标遗传算法优化特征选择、粒子群算法自动调参、Stacking集成学习增强分类性能,在阿里云天池数据集上取得了超越主流模型的综合表现。
该模型可帮助金融机构在贷前更精准地识别高风险借款人,为信贷审批提供科学决策依据。
未来研究方向
-
数据集存在轻微不平衡问题,可进一步优化特征提取方法
-
探索样本外预测,进一步提升预测精度
-
集成网络构建值得更深入研究
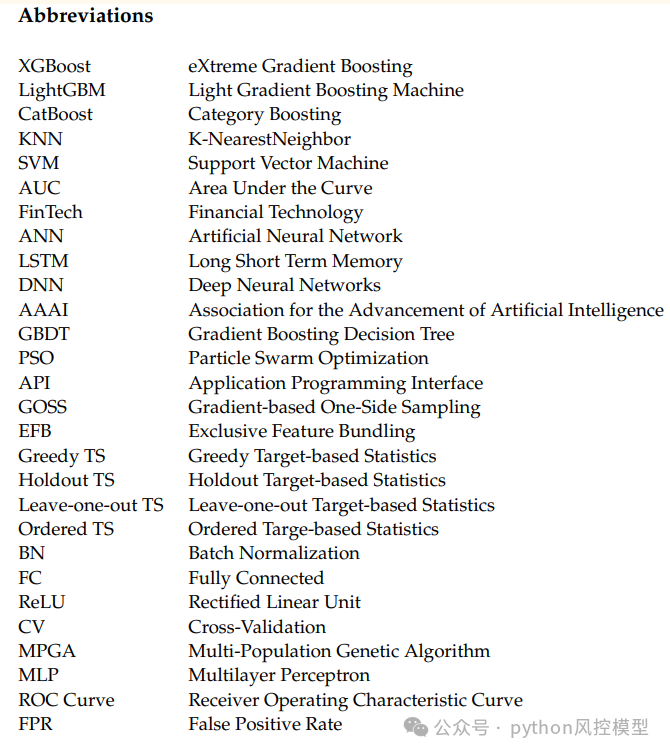
abbreviations
reference


原文来源:期刊解读:基于TabNet-Stacking的信用违约预测模型研究,《Entropy》,附案例和代码。版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)