DC-SAM:基于双一致性的图像与视频上下文分割统一框架
1. 引言
1.1 SAM 的突破与局限
Segment Anything Model(SAM)及其视频版本 SAM2 的问世,标志着交互式图像分割领域的重大突破。凭借超过十亿级别的掩码标注数据训练,SAM 展现了卓越的零样本泛化能力,已被广泛应用于医学影像分析、开放词汇分割、场景理解等下游任务。SAM 的核心架构包含三个关键组件:基于 ViT-H 的图像编码器负责提取高维视觉特征,提示编码器将用户交互(点击、框选、文本)转换为稀疏和密集嵌入,轻量级掩码解码器则融合这些信息生成最终分割结果。这种设计使 SAM 能够在各种场景下实现高质量的交互式分割。
然而,SAM 的核心设计理念是"交互式分割"——用户需要通过点击、框选或文本等方式显式指定分割目标。这一设计在实际应用中暴露出明显的效率瓶颈:当需要在大量图像或连续视频中分割同类目标时,逐帧手动标注的方式既耗时又难以保证时空一致性。更关键的是,SAM 缺乏一种被称为"上下文分割"(In-Context Segmentation)的能力——即仅凭一张参考示例图像及其掩码,自动在新图像中识别并分割出语义相同的目标,这种能力对于批量处理和自动化流程至关重要。
1.2 上下文分割任务定义
上下文分割任务的形式化定义如下:给定一张支持图像(Support Image) I s I_s Is 及其对应的分割掩码 M s M_s Ms,模型需要在查询图像(Query Image) I q I_q Iq 中自动分割出与支持图像中相同语义类别的目标区域。这一任务在少样本学习领域也被称为"单样本分割"(One-shot Segmentation),其核心挑战在于如何从单一示例中提取足够的语义信息,并将其准确迁移到新的视觉场景中。与传统的语义分割不同,上下文分割不依赖预定义的类别标签,而是通过视觉示例来定义分割目标。相关代码在Github开源了。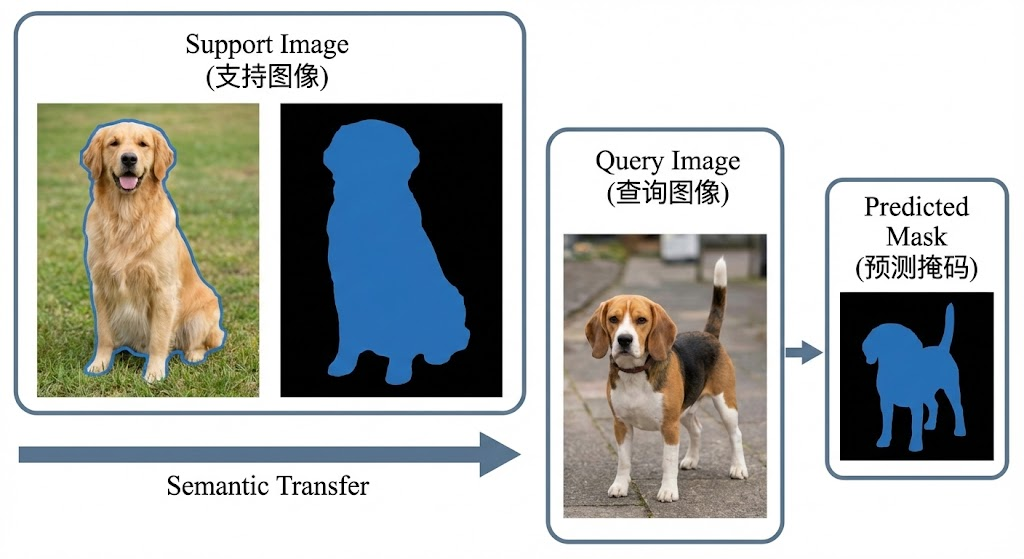
2. DC-SAM 框架总览
2.1 设计理念与命名由来
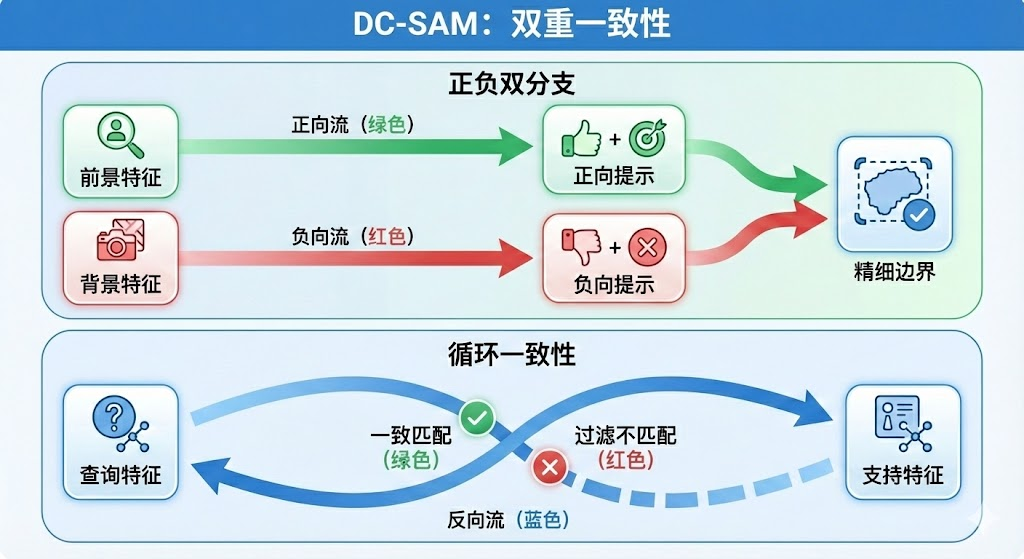
DC-SAM(Dual Consistency SAM)的核心设计理念是:通过提示微调(Prompt Tuning)技术,在不修改 SAM/SAM2 主体参数的前提下,为其注入上下文分割能力。这种设计策略具有重要的实践意义——它保留了 SAM 在海量数据上学习到的强大分割能力,同时通过轻量级的适配模块赋予其新的功能。框架名称中的"双一致性"(Dual Consistency)体现在两个相互协作的层面,共同确保分割结果的准确性和鲁棒性。
第一层一致性是正负双分支一致性:DC-SAM 同时利用前景正样本和背景负样本生成视觉提示,实现精细化的边界控制。正样本提示指导模型关注目标区域,负样本提示则明确告知模型哪些区域应该被排除,两者协同工作能够显著提升边界分割的精度。第二层一致性是循环一致性约束:通过双向匹配验证机制,过滤语义不一致的特征点,抑制错误传播。这种机制确保了特征匹配的可靠性,避免了因纹理相似而产生的错误对应关系。
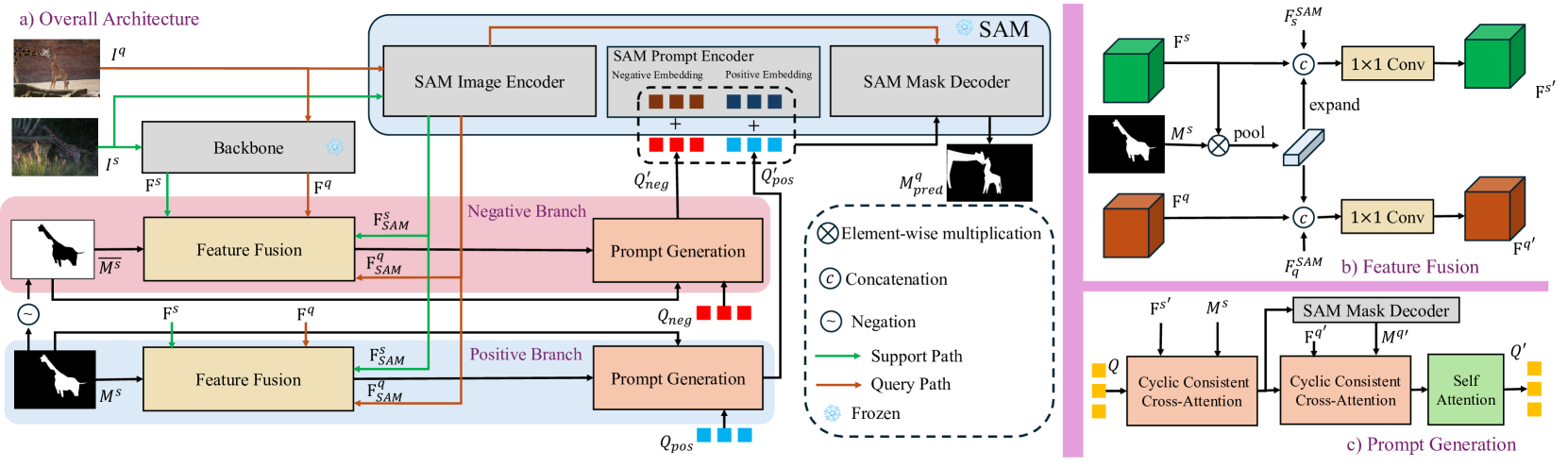
2.2 整体架构
DC-SAM 的整体架构采用两阶段设计,第一阶段基于支持图像生成中间原型,第二阶段利用查询图像的伪掩码进行原型精炼。整个流程可以分解为七个关键步骤,每个步骤都有明确的输入输出和功能定位。这种模块化设计不仅便于理解和调试,也为后续的消融实验提供了清晰的分析框架。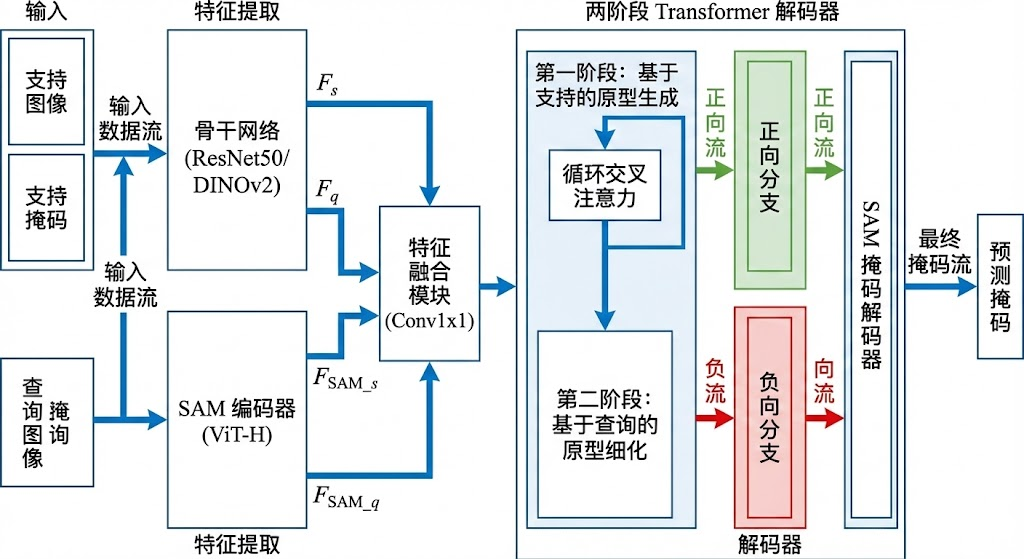
3. 核心技术一:基于 SAM 的多源特征融合
3.1 问题分析:特征空间的语义鸿沟
现有的上下文分割方法(如 VRP-SAM、Matcher)通常仅依赖预训练骨干网络提取特征,这种做法存在一个根本性问题:骨干网络(ResNet、DINOv2)的特征空间与 SAM 内部的特征空间存在显著差异。骨干网络通常在 ImageNet 分类任务上预训练,其特征更侧重于全局语义判别;而 SAM 的编码器在分割任务上训练,其特征更关注局部边界和区域一致性。当使用骨干特征生成的视觉提示输入 SAM 时,这种"语义鸿沟"会导致提示与 SAM 期望的输入分布不匹配,进而影响分割精度。
从代码实现角度来看,DC-SAM 支持多种骨干网络配置,包括 VGG16、ResNet50/101、Swin-B 和 DINOv2-B。每种骨干网络提取的特征维度和语义层次各不相同,但都面临与 SAM 特征空间对齐的挑战。实验表明,单独使用任何一种骨干特征都无法达到最优性能,这验证了特征融合策略的必要性。
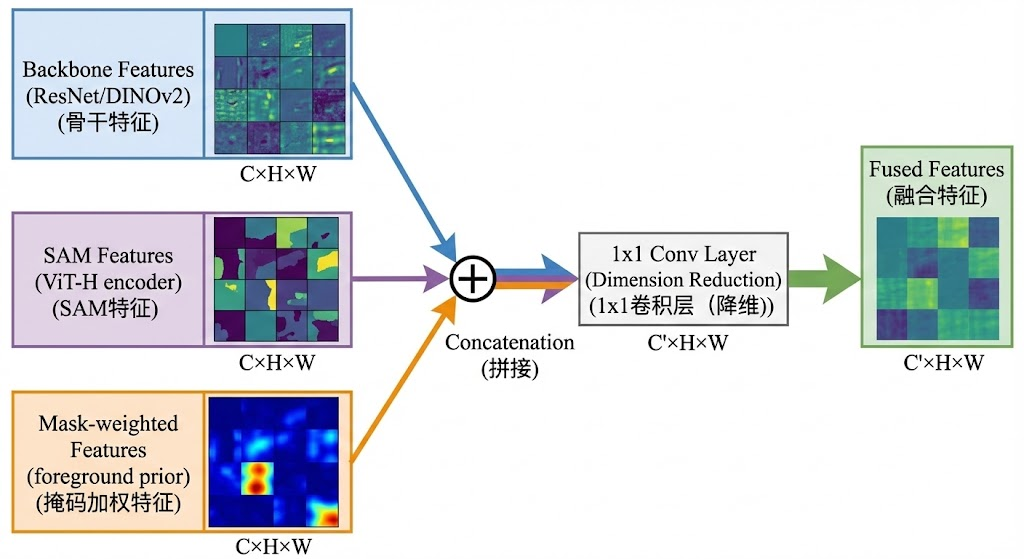
3.2 解决方案:三源特征拼接与融合
DC-SAM 提出了一种多源特征融合策略,同时利用三类互补的特征信息。这种设计的核心思想是:骨干特征提供通用的语义表示,具有良好的类别判别能力;SAM 特征提供与 SAM 解码器对齐的视觉模式,减少特征空间的分布偏移;掩码加权特征显式注入目标类别的先验信息,强化前景区域的特征响应。
# 代码实现:多源特征融合(基于 DC-SAM 源码)
def feature_fusion(self, query_feat, supp_feat, query_sam, support_sam, support_mask):
"""
三源特征融合模块
参数:
query_feat: 查询图像骨干特征 [bs, C, H, W]
supp_feat: 支持图像骨干特征 [bs*nshot, C, H, W]
query_sam: 查询图像 SAM 特征
support_sam: 支持图像 SAM 特征
support_mask: 支持掩码 [bs*nshot, 1, H, W]
"""
# 1. 计算掩码加权的前景特征(二值化处理)
supp_feat_bin = (supp_feat * support_mask).sum(dim=[-2,-1]) / \
(support_mask.sum(dim=[-2,-1]) + 1e-6)
supp_feat_bin = supp_feat_bin.unsqueeze(-1).unsqueeze(-1)
# 2. 支持集三源特征拼接
supp_fused = self.merge_1(torch.cat([
supp_feat, # 原始骨干特征
supp_feat_bin.expand_as(supp_feat), # 前景原型
support_sam, # SAM 编码器特征
support_mask * 10 # 掩码(加权强化)
], dim=1))
# 3. 查询集三源特征拼接
query_fused = self.merge_1(torch.cat([
query_feat, # 原始骨干特征
supp_feat_bin.expand_as(query_feat), # 支持集前景原型
query_sam, # SAM 编码器特征
pseudo_mask * 10 # 伪掩码(加权强化)
], dim=1))
return query_fused, supp_fused
通过 1×1 卷积(self.merge_1)将四类特征融合为统一维度(256 维)的表示,既保留了多源信息的互补性,又确保了与后续 Transformer 模块的兼容性。值得注意的是,掩码信息被乘以系数 10 进行加权,这是为了增强掩码先验在特征融合中的影响力。
3.3 伪掩码生成机制
在处理查询图像时,由于没有真实掩码可用,DC-SAM 采用余弦相似度计算生成伪掩码。这个伪掩码用于指导查询特征的融合过程,使模型能够在没有标注的情况下也能有效地聚焦于潜在的目标区域。
def get_pseudo_mask(self, supp_feat, query_feat, support_mask, nshot):
"""
基于余弦相似度生成伪掩码
"""
bs, ch, h, w = query_feat.shape
# 支持特征与掩码相乘,提取前景原型
supp_fg = supp_feat * support_mask
# 归一化处理
query_norm = F.normalize(query_feat.view(bs, ch, -1), dim=1)
corr_map = torch.zeros(bs, 1, h, w).cuda()
for s_idx in range(nshot):
supp_norm = F.normalize(supp_fg[:, s_idx].view(bs, ch, -1), dim=1)
# 计算余弦相似度
similarity = torch.bmm(supp_norm.permute(0,2,1), query_norm)
# 取最大响应
corr_map += similarity.max(dim=1)[0].view(bs, 1, h, w)
return corr_map / nshot # 多样本平均
4. 核心技术二:循环一致性交叉注意力
4.1 问题分析:语义漂移现象
在基于注意力机制的特征匹配过程中,一个常见问题是"语义漂移"(Semantic Drift):查询图像中的某个像素可能与支持图像中语义不一致的区域产生高相似度响应。例如,当分割"狗"时,查询图像中"猫"的像素可能因毛发纹理相似而错误匹配到支持图像中"狗"的区域。这种错误匹配会导致生成的视觉提示包含噪声信息,进而影响最终分割结果的准确性。传统的交叉注意力机制缺乏验证匹配正确性的能力,容易被表面相似性所误导。
4.2 实现细节:偏置项屏蔽机制
DC-SAM 引入了循环一致性交叉注意力(Cyclic Consistent Cross-Attention)机制来解决语义漂移问题。其核心思想源自一个简单但有效的观察:如果支持图像中的像素 j 与查询 Q 的匹配是正确的,那么从 Q 反向查找时,应该能够回到与 j 语义一致的区域(即属于同一前景/背景类别)。这种双向验证机制能够有效过滤掉那些"单向相似但语义不一致"的错误匹配。
在实际实现中,循环一致性约束通过注意力偏置项(Bias)来实现。这种设计的优雅之处在于:它不需要修改注意力机制的基本结构,只需在计算 Softmax 之前添加一个偏置项即可。当偏置项为负无穷时,对应位置的注意力权重在 Softmax 后趋近于零,从而有效过滤掉语义不一致的特征点。
# 基于 DC-SAM 源码的循环一致性注意力实现
def _scaled_dot_product_attention(q, k, v, mask, attn_mask, dropout_p):
"""
带循环一致性约束的缩放点积注意力
参数:
q: 查询张量 [batch, num_queries, dim]
k: 键张量 [batch, seq_len, dim]
v: 值张量 [batch, seq_len, dim]
mask: 支持掩码 [batch, seq_len] (0=背景, 1=前景)
"""
B, Nt, E = q.shape
q = q / math.sqrt(E)
# 计算注意力分数
attn = torch.bmm(q, k.transpose(-2, -1)) # [B, Nt, seq_len]
# === 循环一致性约束 ===
# Step 1: 对每个支持像素 j,找最相似的查询 i*
argmax_i_star = torch.argmax(attn, dim=1) # [B, seq_len]
# Step 2: 对每个 i*,找最相似的支持像素 j*
argmax_j_star = torch.gather(
torch.argmax(attn, dim=2), # [B, Nt]
dim=1,
index=argmax_i_star
) # [B, seq_len]
# Step 3: 获取 j* 位置的掩码值
ms_j_star = torch.gather(mask, dim=1, index=argmax_j_star)
# Step 4: 创建偏置掩码
bias = torch.where(
mask == ms_j_star, # 语义一致
torch.zeros_like(mask), # 保留 (bias=0)
torch.full_like(mask, float('-inf')) # 屏蔽 (bias=-inf)
)
# 应用偏置并计算注意力权重
attn = attn + bias.unsqueeze(1)
attn = F.softmax(attn, dim=-1)
if dropout_p > 0.0:
attn = F.dropout(attn, p=dropout_p)
output = torch.bmm(attn, v)
return output, attn
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)