富集分析与可视化的方法:GREAT与rGREAT
基因组区域富集注释工具(Genomic Regions Enrichment of Annotations Tool, GREAT)是一个用来进行功能注释和下游分析的工具集,用于分析通过全基因组范围内 DNA 结合事件的局部测量所确定的顺式调控区域的功能意义。与传统的基因富集分析工具如DAVID、enrichr或clusterprofiler不同,GREAT直接分析基因组区域而非基因列表,能够更全面地评估非编码区域的功能意义。
和先前的方法(如DAVID、enrichr等基于基因集列表的方法)相比,GREAT方法考虑了基因组片段,也能够正确纳入远端结合位点,因此在研究基因调控关系等方面效果更好。
一、计算原理(by AI总结)
参考论文:McLean, C., Bristor, D., Hiller, M. et al. GREAT improves functional interpretation of cis-regulatory regions. Nat Biotechnol 28, 495–501 (2010). DOI: 10.1038/nbt.1630
GREAT 的基因组注释原理
GREAT (Genomic Regions Enrichment of Annotations Tool) 的核心创新在于它直接对“基因组区域”(genomic regions) 而非“基因列表”(gene list) 进行功能富集分析。它解决了传统方法在处理远端顺式调控元件(如增强子)时的两大根本性缺陷:信息丢失和假阳性偏差。
其原理可以分解为以下三个关键步骤:
-
定义“调控域”(Regulatory Domain) 而非简单关联:
- 传统的“最近基因法”或“2kb内”方法非常武断,会丢失大量远端调控事件。
- GREAT 提出一个更符合生物学实际的模型:为基因组中的每一个基因定义一个“调控域”。这个域不仅包括启动子区域(默认5kb上游 + 1kb下游),还允许向两侧延伸,直到遇到邻近基因的调控域边界,但最大不超过1Mb(用户可自定义参数)。这模拟了基因可能受到其上下游一定范围内所有调控元件影响的概念。
- 每个输入的基因组区域(例如ChIP-seq峰)会被映射到其覆盖的所有基因的调控域中。这意味着一个区域可以同时关联多个基因。
-
采用“二项检验”(Binomial Test) 作为统计基础:
- 这是GREAT最核心的统计学创新。它不计算有多少“基因”被选中,而是计算有多少“基因组区域”落在了具有特定功能注释的基因的调控域内。
- 具体来说,它首先计算整个基因组中,被特定功能术语(如“细胞骨架”)所覆盖的基因的调控域总长度占全基因组的比例(
p_π)。这个比例就是该功能术语的“先验概率”。 - 然后,它使用二项分布来检验:观察到有
k个输入区域落在这些“功能相关”的调控域内,在总共n个输入区域的情况下,是否显著多于随机期望值(即n * p_π)。 - 关键优势:这种方法天然地校正了“调控域大小偏差”。那些调控域很大的基因(如发育相关基因),其调控域在基因组中占比就大,因此随机情况下也更容易捕获到调控区域。二项检验通过
p_π将这种大小差异纳入考量,从而避免了将这些大基因相关的通用功能错误地判断为显著富集(假阳性)。
-
结合多种本体论并提供双重验证:
- GREAT整合了20种不同的本体论数据库,涵盖基因功能(GO)、表型、疾病、通路、表达谱、转录因子靶点、基因家族等多个维度,提供了丰富的注释资源。
- 它同时运行二项检验(基于区域)和传统的超几何检验(基于基因),并将结果对比展示:
- 仅二项检验显著:可能代表少数几个关键基因吸引了大量调控区域(基因特异性富集)。
- 仅超几何检验显著:很可能是由调控域大小偏差导致的假阳性。
- 两者均显著:这是最可靠的结果,表明该功能不仅在区域层面富集,而且涉及的基因数量也足够多,提供了强有力的支持。
GREAT 与其他工具的不同之处
如下图,是文章中对现有方法(a图)和GREAT方法(b图)的方法总结与对比。GREAT方法使用二项分布进行建模,计算基因组区域的覆盖长度(而传统方法使用超几何分布,计算基因集的交集),因此可以更好的分析调控元件的相互作用。

| 特征 | GREAT | DAVID / clusterProfiler / Enrichr |
|---|---|---|
| 分析对象 | 基因组区域 (Genomic Regions)。输入是一系列坐标区间(BED文件)。 | 基因列表 (Gene List)。输入是一个基因ID列表(如从DEG分析得到)。 |
| 关联方式 | 基于调控域模型(如5+1kb + 最大1Mb扩展)。一个区域可关联多个基因。 | 主要基于距离。通常是取峰附近最近的基因,或限定在TSS ± X kb内的基因。一个区域通常只关联一个或两个最近的基因。 |
| 核心统计模型 | 二项检验 (Binomial Test),以基因组覆盖率为背景。显式地校正了调控域大小带来的偏差。 | 超几何检验 (Hypergeometric Test) 或 Fisher精确检验。以基因总数为背景。无法校正调控域大小偏差,易产生假阳性。 |
| 主要优势 | 1. 充分利用远端调控信息,避免因忽略远端峰而丢失重要功能。 2. 有效控制假阳性,特别是对于调控域大的基因。 3. 分析结果更贴近真实的顺式调控机制。 |
1. 应用范围广,适用于任何能生成基因列表的场景(如RNA-seq, microarray)。 2. 生态成熟,拥有庞大的数据库支持和丰富的可视化功能(尤其是clusterProfiler)。 3. 操作简便,流程标准化。 |
| 主要局限/适用场景 | 专用于顺式调控数据。必须有明确的基因组坐标(如ChIP-seq, ATAC-seq, ChIA-PET等)。不能直接用于分析基因表达水平变化。 | 不适合分析富含远端调控元件的数据。当输入的调控区域大部分位于基因远端时,这些方法会严重低估或完全遗漏其功能。 |
总结来说:
- DAVID、clusterProfiler、Enrichr 是经典的基因列表富集分析工具,它们的输入是“哪些基因发生了变化”,输出是“这些基因参与了什么功能”。它们依赖于“调控=靠近基因”的简化假设。
- GREAT 是专门为顺式调控区域富集分析设计的下一代工具。它的输入是“基因组上哪些区域有功能活性”,输出是“这些活性区域的功能意义是什么”。它通过建立“调控域”模型和使用“二项检验”,打破了“调控=靠近”的限制,能够更准确、更全面地解读远端调控元件的生物学功能,尤其是在研究增强子、超级增强子等长距离调控机制时,GREAT的优势尤为突出。
二、使用方法(网页端接口)
此处需要访问GREAT的官网: http://great.stanford.edu/public/html/
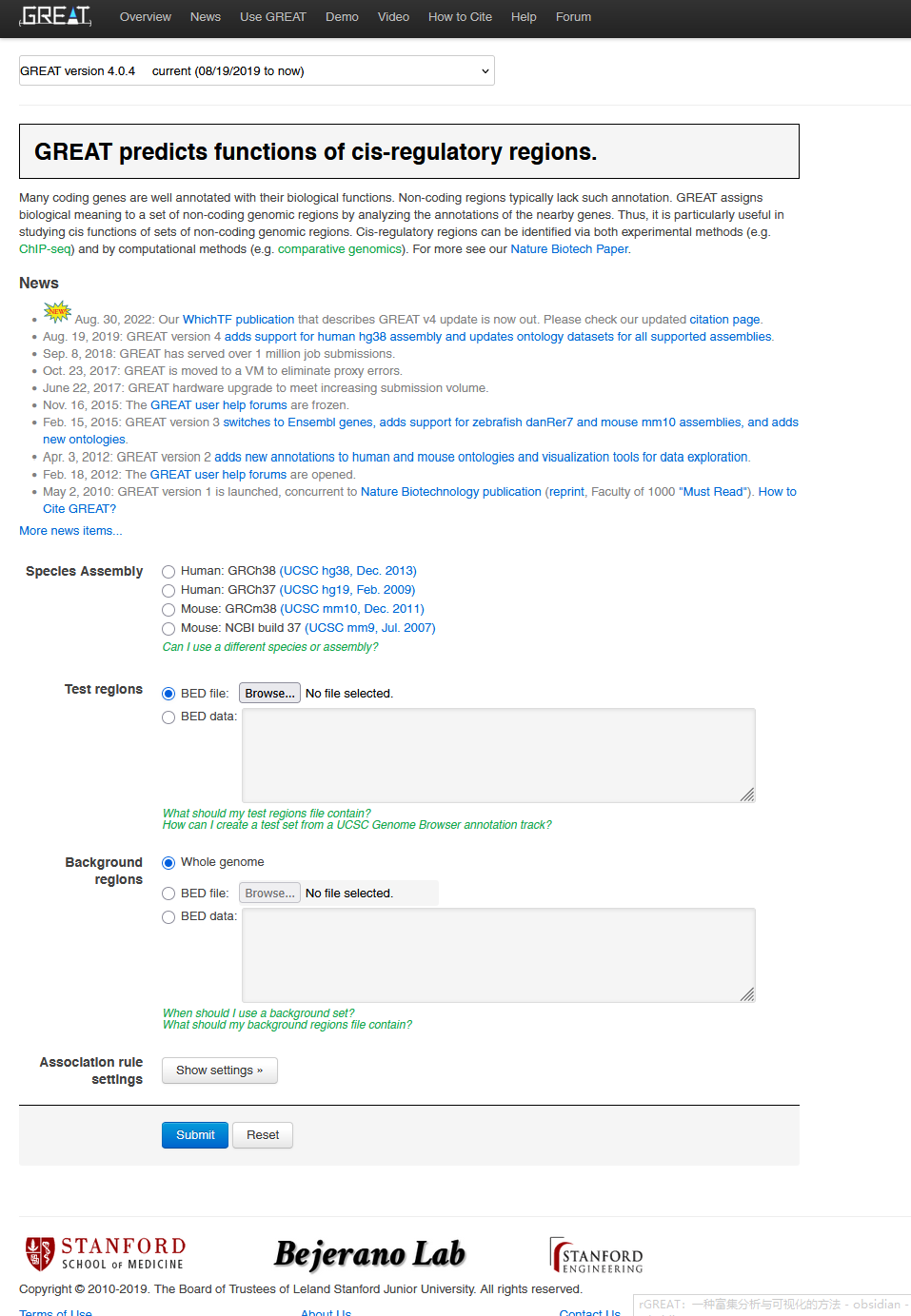
与DAVID等网站的使用方法不同,GREAT在注释时需要准备一个用于检验的bed文件,即test region文件。如有需要,可以再准备第二个背景区域的文件(background region),其必须是test region所包含区域的超集。
关于背景区域文件,官方给出的说明如下图(更多详情见网站)。这个文件是可选的,如果不上传,则在统计检验中会使用全基因组的所有区域作为检验区域。

所谓bed文件,就是以tsv表格形式存储的基因组坐标,其中第一列是染色体编号,第二列是基因组区域的起始位置,第三列是基因组区域的终止位置,从第四列开始用户可以存储一些自定义的信息(例如一些元数据)。下面是一个bed文件的例子:
chrX 55009055 55030977 ALAS2
chr11 57551656 57568284 UBE2L6
chr1 156668763 156677407 NES
chr10 17228241 17237593 VIM
chr10 17214239 17230018 VIM-AS1
chr10 132783179 132786147 NKX6-2
chr2 238238267 238240662 HES6
chr3 185712528 185729787 IGF2BP2-AS1
chr3 185643130 185825042 IGF2BP2
chr6 159969082 160113507 IGF2R
chr16 89171748 89195492 CDH15
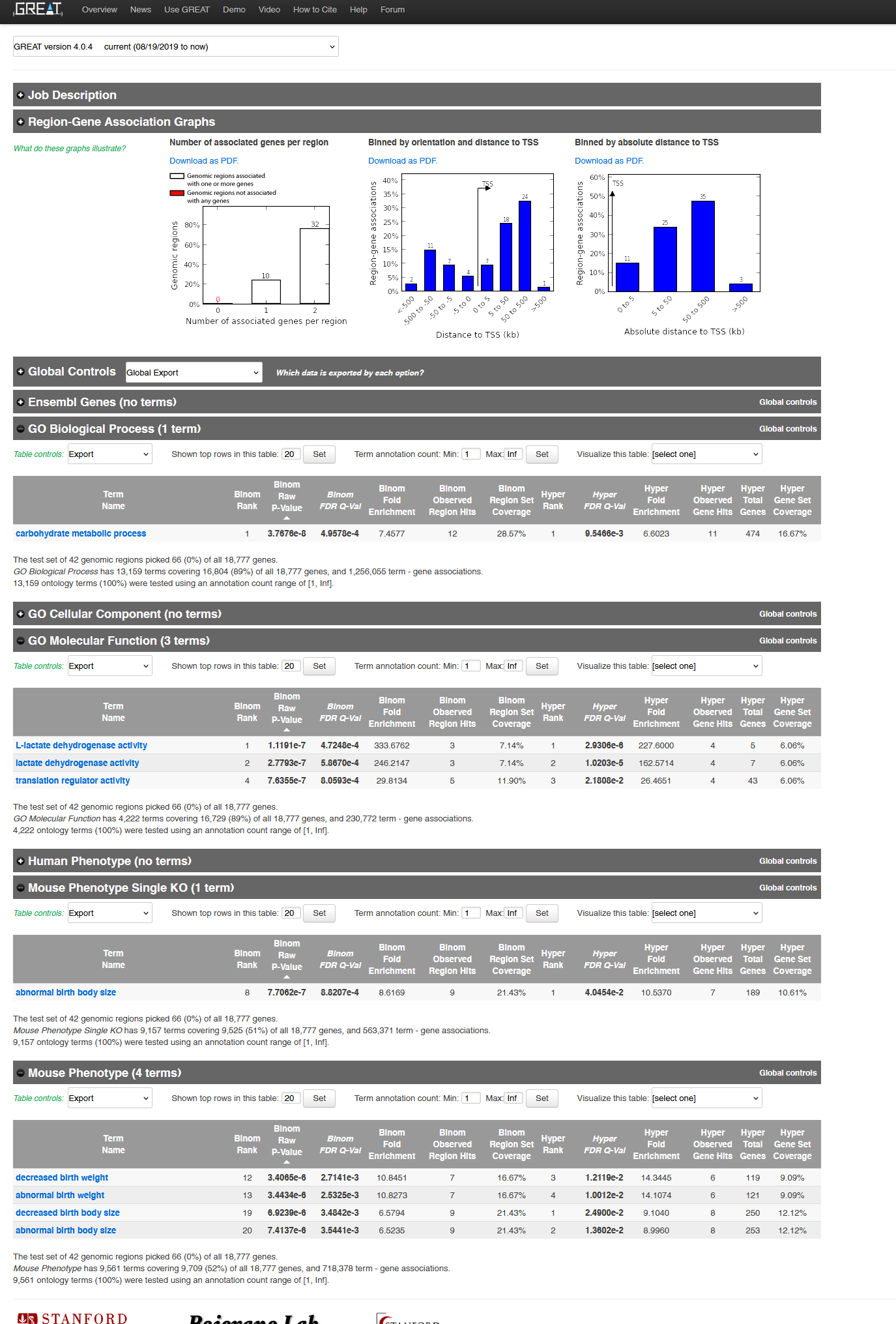
上传bed文件,选择合适的物种参考基因组(例如上面那个bed文件使用的是人类GRCh38的参考基因组坐标),然后点击submit就可以运行了。输出的结果如下所示:
三、附带小工具:一个从gtf文件转bed文件的python代码
这个工具是在组会上听到的,笔者在自己的课题中暂时还没有涉及到需要对基因组调控区和非编码区做功能注释的工作。为了能够检验这个工具的效果,笔者攒了一个小工具,通过给定基因列表和GTF文件,来得到一份bed格式的test region文件( result.bed )。以下是代码:
import pandas as pd
import numpy as np
## GTF文件路径
gtf_file = "F:/Download/GTF/Homo_sapiens.GRCh38.110.gtf.gz" # 此处根据情况,换成具体的文件路径
## 要注释的基因列表
gene_list = ["Alas2","Ube2L6","Nes","Vim","Nkx6-2","Hes6","Igf2","Tubb6","Penk","Eno1","Ldha","Ralgps2","Cdh15"] # 此处根据情况,换成具体的基因列表
df1 = pd.read_csv(gtf_file,comment='#',sep="\t",header=None)
df1_exon = df1[df1[2] == 'gene']
index_arr = np.array(df1_exon[8]).reshape(-1)
def search_and_format(gene_list):
chrom_ = []
start_ = []
final_ = []
genes_ = []
for gene in gene_list:
patten = gene.upper()
print(patten)
for i in range(len(index_arr)):
if(patten in index_arr[i]):
chrom_.append("chr"+str(df1_exon.iloc[i:i+1,0:1].values[0][0]))
start_.append(df1_exon.iloc[i:i+1,3:4].values[0][0])
final_.append(df1_exon.iloc[i:i+1,4:5].values[0][0])
genes_.append(df1_exon.iloc[i:i+1,8:9].values[0][0].split("gene_name")[1].split(";")[0].strip().replace('"',''))
res_df = pd.DataFrame({"#chromesome":chrom_,
"start_pos":start_,
"final_pos":final_,
"gene_name":genes_})
return res_df
if(__name__=="__main__"):
res_df = search_and_format(gene_list)
res_df.to_csv("result.bed",sep="\t",header=False,index=False)
四、关于GREAT算法,一些有用的参考链接
五、rGREAT:适用于R语言的GREAT工具
rGREAT是一个基于GREAT方法的R包,其功能更全面,可以自定义的选项也更多。
前文中,我们介绍了GREAT这个基因组注释工具,以及它的网页版界面的使用方法。在本文的后续部分,我们将更深入的介绍rGREAT——这个工具的R语言版本,并展示一些高级用法。
1. 什么是rGREAT
rGREAT 是一个 R/Bioconductor 包,实现了 GREAT(Genomic Regions Enrichment of Annotations Tool) 算法,用于对基因组区域进行功能富集分析。与传统的基因集富集分析不同,GREAT 直接将基因组区域(如ChIP-seq峰、ATAC-seq开放区域等)与基因功能注释关联起来,从而揭示这些区域可能参与的生物学过程、通路或功能类别。
使用场景:
- ChIP-seq 转录因子结合位点的功能注释
- ATAC-seq 或 DNase-seq 开放染色质区域的功能分析
- 差异甲基化区域的功能富集分析
- 任何基因组区间集的功能解读
2. 安装方法
(一)通过命令行安装rGREAT本体
有三种方法可以安装rGREAT,任选其一即可:
- rGREAT 可通过 Bioconductor 安装(在R-session中运行):
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("rGREAT")
- 也可从 GitHub 安装最新开发版(在R-session中运行):
library(devtools)
install_github("jokergoo/rGREAT")
- 还可以通过conda或者mamba安装(在bash或cmd等终端中运行):
conda install bioconda::bioconductor-rgreat
(二)Trouble-shooting:如果依赖项安装出错,怎么办
有一些附带的包(例如 GO.db )会一并安装。如果在上面的流程中这些依赖项安装出错,可以使用下面的指令在R-session中进行安装:
## 首先切换软件源。
# 官方源和清华源(TUNA)都默认只保留最新版的bioconductor包,
# 只有西湖大学源(westlake)有历史版本的bioconductor包,
# 因此建议先切换到西湖大学软件源
options(BioC_mirror="https://mirrors.westlake.edu.cn/bioconductor")
## 然后下面的指令依次安装
BiocManager::install("GO.db")
BiocManager::install("GenomicFeatures",force = TRUE)
BiocManager::install("TxDb.Hsapiens.UCSC.hg19.knownGene",force = TRUE)
BiocManager::install("TxDb.Hsapiens.UCSC.hg38.knownGene",force = TRUE)
BiocManager::install("org.Hs.eg.db",force = TRUE)
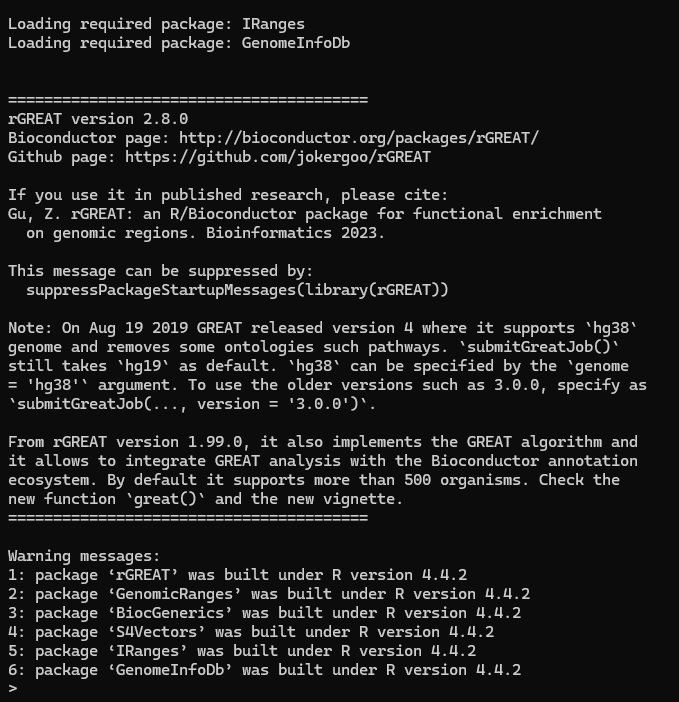
如果能够使用 library(rGREAT) 指令成功加载这个软件包(产生如下图所示的输出),则说明安装成功。
3. rGREAT 的使用方法
主要函数概览:
submitGreatJob():提交在线分析great():执行本地分析getEnrichmentTable():获取富集结果getRegionGeneAssociations():获取区域-基因关联信息plotRegionGeneAssociations():可视化区域与基因的关系shinyReport():启动交互式 Shiny 报告
rGREAT 支持两种分析方式:
(一) 在线分析(Online GREAT Analysis)
将区域提交至 GREAT 官方网站,获取标准化结果。
library(rGREAT)
# 生成随机区域作为示例
set.seed(123)
gr <- randomRegions(nr = 1000, genome = "hg19")
# 提交任务
job <- submitGreatJob(gr)
# 获取富集结果表
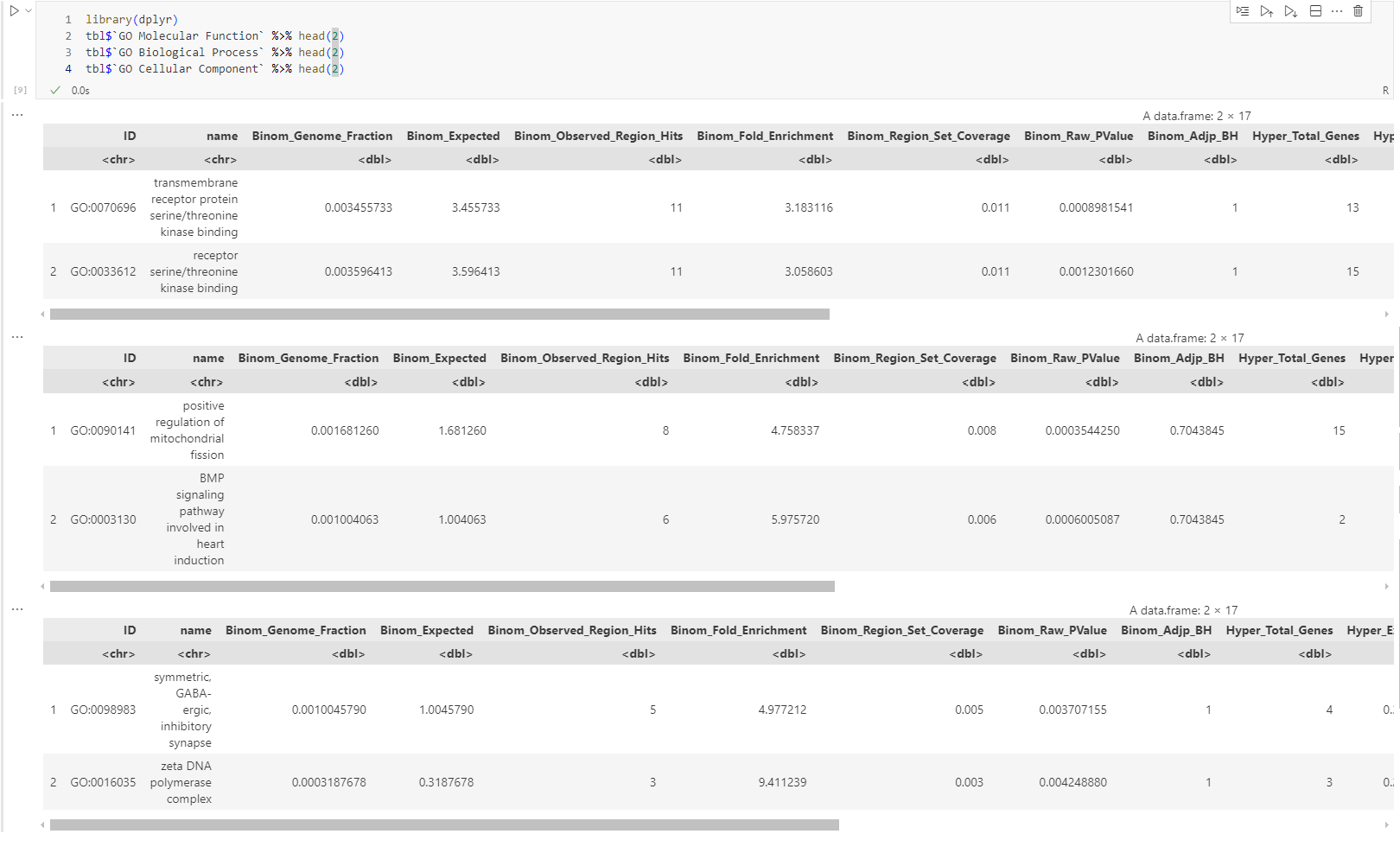
tbl <- getEnrichmentTables(job)
输出:
(二)本地分析(Local GREAT Analysis)
使用内置的 GREAT 算法在本地执行分析,支持自定义基因集和物种。
本地分析的优势:
- 支持600+物种
- 可使用自定义基因集
- 无需网络连接
- 灵活设置背景区域
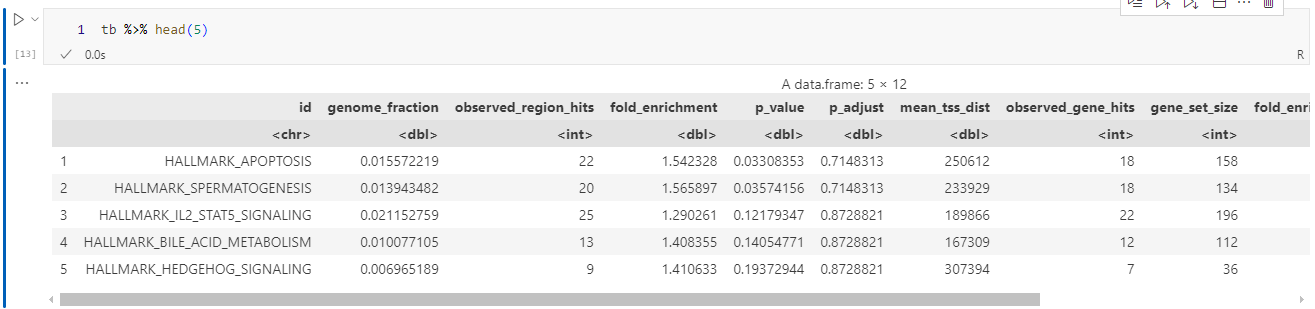
res <- great(gr, "MSigDB:H", "TxDb.Hsapiens.UCSC.hg19.knownGene")
tb <- getEnrichmentTable(res)
输出:
4. 结果解读与可视化
富集结果通常包含以下列:
ID:功能术语ID(如GO:0004984)name:术语名称p_value/p_adjust:原始/校正后的 p 值fold_enrichment:富集倍数region_hits:输入区域中与该术语相关的区域数gene_hits:与该术语相关的基因数
rGREAT 提供多种可视化方法:
- 区域-基因关联图
- 距离TSS的分布图
- 火山图(Volcano plot)
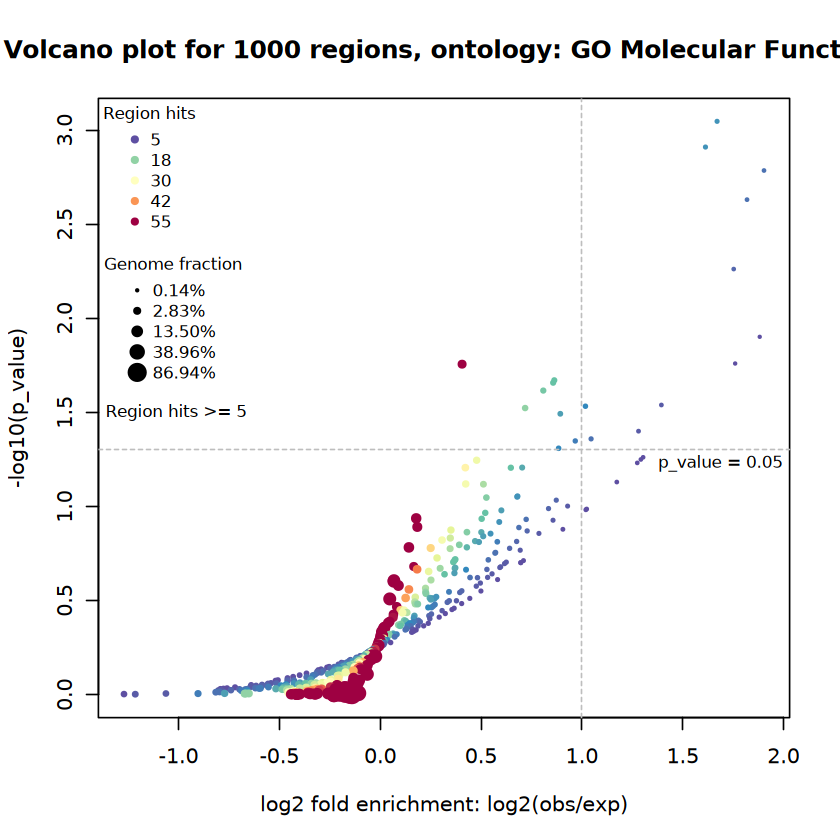
火山图
我们可以对GreatJob或GreatObject对象使用plotVolcano()来绘制火山图,直观地展示富集最显著的条目 。
#library(rGREAT)
# 生成随机区域作为示例
#set.seed(123)
#gr <- randomRegions(nr = 1000, genome = "hg19")
# 提交任务
#job <- submitGreatJob(gr)
plotVolcano(job, ontology = "GO Molecular Function")
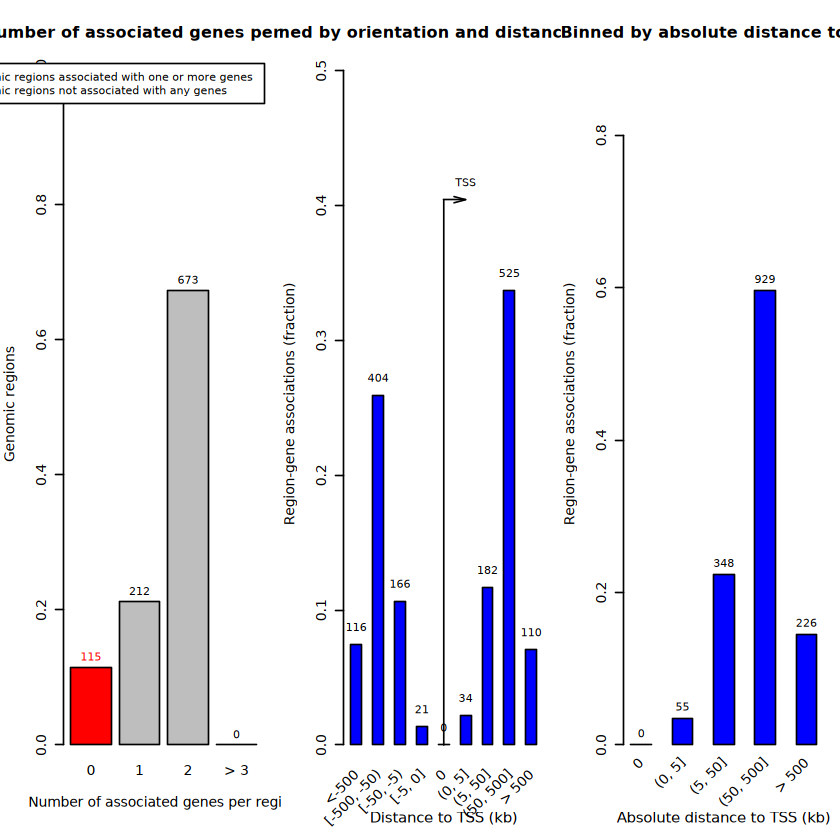
区域-基因关联图 (plotRegionGeneAssociations)
这是GREAT的特色图。它可以展示输入区域与基因TSS的距离分布 ,以及区域与基因的关联情况 。
#library(rGREAT)
# 生成随机区域作为示例
#set.seed(123)
#gr <- randomRegions(nr = 1000, genome = "hg19")
# 提交任务
#job <- submitGreatJob(gr)
plotRegionGeneAssociations(job)
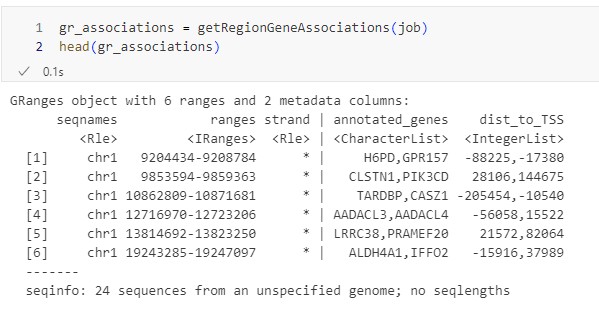
获取关联数据 (getRegionGeneAssociations)
如果我们想获得区域到基因的具体关联信息(例如哪个区域关联到了哪个基因,距离多远),可以使用getRegionGeneAssociations() 。
#library(rGREAT)
# 生成随机区域作为示例
#set.seed(123)
#gr <- randomRegions(nr = 1000, genome = "hg19")
# 提交任务
#job <- submitGreatJob(gr)
gr_associations = getRegionGeneAssociations(job)
head(gr_associations)
交互式shiny文档报告
rGREAT还提供了一个shinyReport()函数,它可以在本地启动一个Shiny应用,让我们以交互方式探索和筛选富集结果 。
#library(rGREAT)
# 生成随机区域作为示例
#set.seed(123)
#gr <- randomRegions(nr = 1000, genome = "hg19")
# 提交任务
#job <- submitGreatJob(gr)
shinyReport(job)
5. 总结与参考文献
rGREAT是一个强大且灵活的R包,它将GREAT算法的分析能力带入了R/Bioconductor生态。无论是想快速调用在线服务,还是需要利用本地模式对非模式生物进行复杂的自定义注释分析,rGREAT都能提供完善的解决方案。
如果读者朋友正在处理基因组区域数据,并希望探索它们的功能意义,rGREAT无疑是一个值得尝试的工具。
以上。
参考文献以及一些有用的链接:
参考:
- Zuguang Gu, et al., rGREAT: an R/Bioconductor package for functional enrichment on genomic regions. Bioinformatics, 2023.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)