强化学习理论6 大语言模型(LLM)的强化学习
大语言模型(LLM)的强化学习
一、核心定义:状态(s)、动作(a)、奖励(R)
对于LLM而言,需要对应RL的三个重要概念:状态(s)、动作(a)、奖励(R)
1. 状态(s):输入的Prompt,比如“写一首关于春天的诗”。
2. 动作(a):输出的Token序列,动作 a 是模型生成的Token序列,比如“春天来了,万物复苏,花开满园。”
3. 奖励(R):衡量动作质量的函数,奖励 R(s,a) 只在序列结束时计算,比如生成完“春天来了,万物复苏,花开满园。”后,才给这个完整的回答打分。
二、优化目标:最大化期望奖励
1. 基本优化目标
目标:最大化生成的句子的期望奖励。
![]()

2. 基于next-token prediction的乘法原理分解
【生成这个句子 a 的可能性】
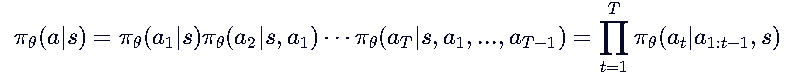
三、状态转移函数:从 st−1 到 stst
1. 状态转移函数的定义
【选下一个词的概率】(0或1)
在已生成的Token序列 (比如“春天来了,万物复苏”)下,生成下一个Token
(比如“花开”)后,新的Token序列
(比如“春天来了,万物复苏,花开”)的概率一定是1或0。
在LLM中,状态转移函数是确定的:
公式:
四、奖励函数的特殊设计:只在序列结束时计算
【当前步骤的奖励】
1. 奖励函数的定义
定义:在LLM中,奖励函数 R(st,at) 通常只在序列结束时计算,
当 t<T 时,生成还未结束,奖励为0。
当 t=T 且 时,生成结束,计算整个序列的奖励 R(s,a1,...,aT)。
公式: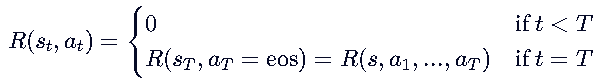 '
'
五、优化目标的重新定义
重新定义:结合状态转移函数,优化目标可以重新定义为:
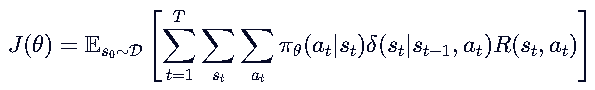
![]() ——【生成这个句子 a 的可能性】
——【生成这个句子 a 的可能性】![]() ——【选下一个词的概率】
——【选下一个词的概率】![]() ——【当前步骤的奖励】
——【当前步骤的奖励】![]() ——【对每个Token求和】
——【对每个Token求和】![]() ——【对所有可能的状态和动作求和】
——【对所有可能的状态和动作求和】
直观含义是:求和所有可能生成的句子的每一个token,每个token的选取概率是【生成这个句子 a 的可能性】*【选下一个词的概率】*【当前步骤的奖励】,因此套三层求和。
六、KL散度约束:防止策略偏离过大
1. KL散度约束的作用
作用:KL散度约束是为了防止策略 πθ 偏离参考策略 πref 过大,从而保证生成的文本不会“跑偏”。
公式:![]()

七、总结:RL for LLM的核心流程
- 输入Prompt:用户输入Prompt s ,作为状态 s0 。
- 生成动作:模型根据策略 πθ(at∣st) ,自回归生成Token序列 a=[a1,a2,...,aT] 。
- 计算奖励:当生成结束( aT=eos )时,计算整个序列的奖励 R(s,a) 。
- 优化目标:最大化期望奖励 J(θ) ,同时通过KL散度约束防止策略偏离过大。
- 更新策略:根据奖励和KL散度,更新策略 πθ ,使其生成更高质量的文本。
我们核心讨论的点就在于如何最大化奖励J(θ)。
GRPO——Clip机制+相对优势
GRPO的核心动机:为什么要“去价值网络”?
前面的TRPO和PPO都是更新双模型的,一个策略模型,一个价值估计模型(隐藏在GAE的优势估计中),每次更新完策略模型后,都需要同步更新价值估计模型。
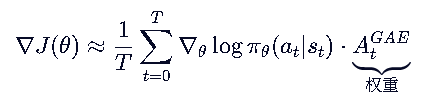

在标准PPO中,计算优势函数 A(s,a) 需要一个价值网络 V(s) 来做基线(Baseline),这带来了两个问题:
- 双倍参数开销:需要同时训练策略网络(Policy)和价值网络(Value),内存和计算成本高。
- 训练不稳定:价值网络拟合不准会直接影响策略更新的方向。
GRPO的解决思路:
既然我们最终的目标是让模型生成“奖励更高”的文本,为什么不直接用同一组输入(Prompt)下,不同输出(Token序列)之间的相对奖励差异来代替复杂的 A(s,a) 计算呢?
这就是GRPO的“Group Relative”思想:在同一组Prompt下,让表现好的Token序列“拉高”表现差的Token序列的梯度,而不是去拟合一个全局的 V(s) 。
直观而言:
GRPO的目标不是让学生“考满分”,而是让学生“比班里平均水平考得好”。
对于每个Token,如果它出现在“高分学生”的序列里,它就会得到正向激励;如果它出现在“低分学生”的序列里,它就会被惩罚。
从PPO到GRPO
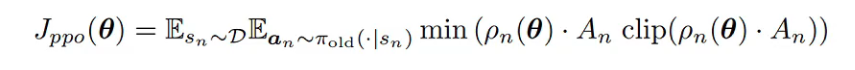
其中:
如果LLM使用PPO训练,就需要持续更新bn这个基线函数,时间空间开销都是两倍,我们考虑用蒙特卡洛采样直接估计A。
GRPO具体过程:【前面提到的RL for LLM核心流程】


轨迹奖励函数 R(s,a) 是固定的,不参与训练更新。
在 LLM 中,生成是自回归的,每个 token 依赖于前面的 token。所以 ρ 需要基于当前 token 的条件概率,而不是整个序列的概率。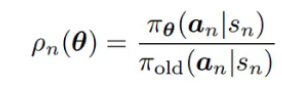 =》
=》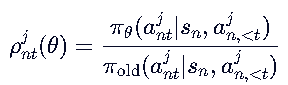

对比前面LLM的优化函数,能发现不少区别,我们解释一下:+KL约束
首先,KL约束之前我们讲PPO就说过了,将其用“CLIP截断+min”解决了。
其次,为什么 GRPO 的优化函数有 1/N 和 1/J ?
因为 GRPO 的优化目标是一个期望(Expectation)的蒙特卡洛估计
1. 1/N:对 Prompt 的期望进行估计
理论上的优化目标:我们希望优化模型在所有可能的 Prompt 上的表现。但我们只能通过蒙特卡洛采样实现,因此用这 N 个 Prompt 的平均值来近似整个期望。
2. 1/J :对回答的期望进行估计
理论上的优化目标:对于每一个 Prompt sn ,我们希望优化模型在所有可能的回答上的表现。用这 J 个回答的平均值来近似这个期望。
至于括号内的不同,则是工程实践上的差异,原本的LLM使用的其实是在追求绝对的“好”,而GRPO是追求相对的“好”,这种指导方向上的差异就决定了二者肯定不一样,LLM的优化函数适合理论推导,他需要遍历所有情况,所有的prompt所有的回答,这是不可能的。而我们用的GRPO采用“CLIP截断+min”内化了KL散度约束,并通过“蒙特卡洛采样”解决了需要遍历所有情况的问题,是工程实践中的标杆!
DAPO
一、DAPO:给“剪贴板”动个手术(不对称剪贴)
1. 它是啥?
DAPO 是对 PPO 里的 Clip 函数 做了微调。
2. 背后的痛点

PPO 原来的 Clip 是对称的(比如 clip(ρ, 0.8, 1.2))。这就像给模型设了个“紧箍咒”:
- 如果模型想变好(优势是正的),它最多只能把概率提高 20%。
- 如果模型想变差(优势是负的),它最多只能把概率降低 20%。
这其实不太公平!我们更希望模型大胆地变好,而不是被限制住。
3. DAPO 怎么改的?
它把 Clip 改成了不对称的:
- 上限放宽一点(比如
1 + 0.28):鼓励模型大胆探索好的动作,让原本很少被选的优质回答能获得更高的概率。 - 下限收紧一点(比如
1 - 0.2):惩罚坏动作要狠一点。
4. 好处
防止模型陷入“熵崩塌”(Entropy Collapse)——也就是防止模型变得越来越死板,只会说那几句最保险的话,不敢创新了。
GSPO
1. 它是啥?
GSPO 是把强化学习的优化粒度从“整句话”细化到了“每一个字(Token)”。
2. 背后的痛点

传统方法(比如 PPO)是“句子级”的:
- 一句话生成完了,得到一个总分。
- 然后用这个总分去更新这句话里每一个字的生成概率。
这很不合理!比如一句话是“今天天气真好,我要去跑步”,如果总分高,难道是因为“跑步”这个词特别好?还是因为“天气”这个词特别好?传统方法把功劳平均分给了所有字,这叫信用分配不均。
3. GSPO 怎么改的?
它做了一件很暴力但有效的事:每个 Token 都算一次奖励和更新。
- 它定义了一个新的概率比
,这个比值是基于整句话的,但被应用到了每一个 Token 上。
- 优化目标
里,那个
就代表它要对这句话里的每一个 Token 都算一遍梯度。
4. 好处
- 训练更快:因为每个 Token 都在参与更新,信息利用率变高了。
- 效果更细:模型能学到具体哪个词用得好,哪个词用得不好,而不是只看整句话的结果。
| 算法 | 核心改动 | 想解决的问题 |
|---|---|---|
| DAPO | Clip 不对称(上松下紧) | 防止模型太保守,鼓励大胆探索好答案 |
| GSPO | 从“句子级”改成“Token 级” | 解决“整句奖励”导致的信用分配不均,训练更精细 |
| 维度 | PPO | GRPO |
|---|---|---|
| 优势函数计算 | ||
| 网络结构 | 双网络(策略网络 + 价值网络) | 单网络(仅策略网络) |
| 计算开销 | 高(需要训练和推理价值网络) | 低(无需价值网络) |
| 适用场景 | 通用强化学习任务 | LLM对齐(RLHF),尤其是资源受限场景 |
| 稳定性 | 依赖价值网络的拟合精度 | 依赖组内采样的多样性,稳定性稍弱但效率更高 |
所有双模型策略网络的运行过程就和GAE的原型Baseline模型一致,交替更新,教学相长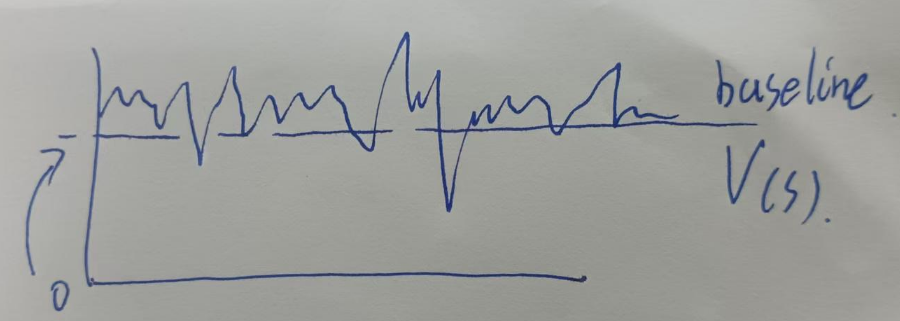
补充证明
从 到
到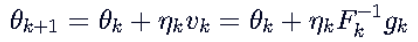







AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)