专业术语统计报告_电力科技知识驱动的专家匹配选择与优化分配模型研究
专业术语统计报告_电力科技知识驱动的专家匹配选择与优化分配模型研究
一、概要简析
【概要分析】
本文档《电力科技知识驱动的专家匹配选择与优化分配模型研究》超用心地围绕研究主题展开了系统性探讨哦😜!文档总字符数足足有200756,其中中文字符73507个,英文字词14834个,妥妥体现了中英文混搭的学术写作小特色~从文档里扒出来的专业术语一共有1829个,涉及6个研究领域,主打就是扎堆在图神经网络(1550次)、评审专家优选(1525次)、电力系统(1521次)这块儿~高频术语比如“专家”(出镜1042次)、“关系”(露脸530次)等,一眼就能看出研究的核心小焦点✨!整体来说,这篇文献在相关研究领域超有学术价值,一顿系统分析+论述操作下来,给后续研究铺好了超重要的理论小地基和方法小参考~
【数据统计】
- 总字符数:200756
- 中文字符数:73507
- 英文字词数:14834
二、统计图表分析
2.1 三类术语层次分布
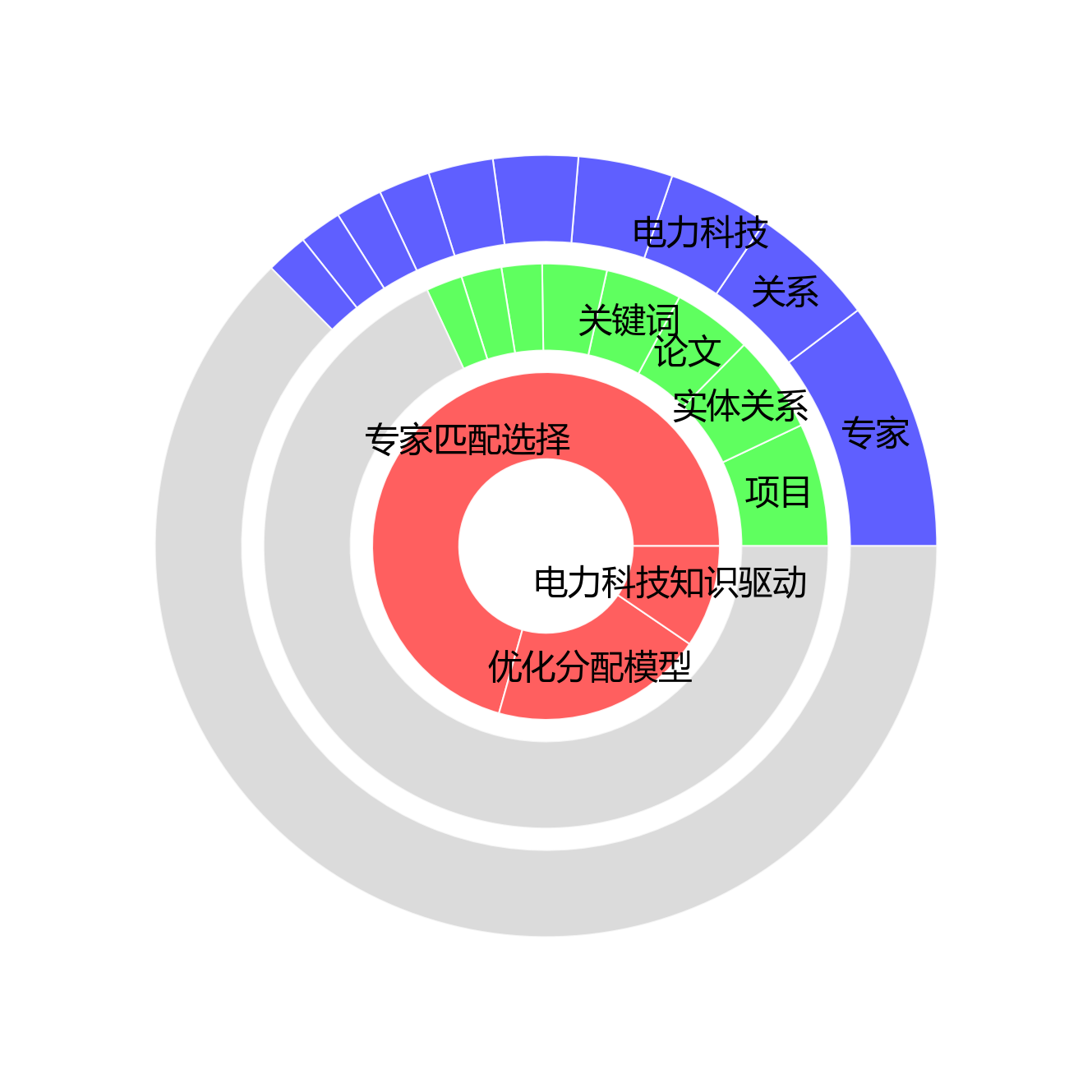
【数据统计】
- 论文名称术语:3个 (核心术语:专家匹配选择、优化分配模型、电力科技知识驱动)
- 标题摘要术语:505个 (核心术语:项目、实体关系、论文)
- 正文术语:1321个 (核心术语:专家、关系、电力科技)
- 术语总数:1829个
- 频次占比:论文名称 0.9% | 标题摘要 27.3% | 正文 71.8%
【可视化图表】
| 类别 | 术语数量 | 频次 | 占比 |
|---|---|---|---|
| 论文名称 | 3 | 126 | 0.9% |
| 标题摘要 | 505 | 3850 | 27.3% |
| 正文 | 1321 | 10112 | 71.8% |
| 总计 | 1829 | 14088 | 100% |
【图表评论】
旭日图超直观地展示了三类术语在文档不同部分的层次分布啦🌞!从内到外依次是论文名称术语、标题摘要术语和正文术语~论文名称层级藏着3个核心术语,总频次126次,占比0.9%,核心术语有“专家匹配选择、优化分配模型、电力科技知识驱动”,这些小家伙直接概括了研究的核心主题哟~标题摘要层级有505个术语,总频次3850次,占比27.3%,核心术语像“项目、实体关系、论文”,悄悄透露了研究的次要关键词和方法论~正文层级最最丰富啦,有1321个术语,总频次10112次,占比71.8%,核心术语比如“专家、关系、电力科技”,把研究的具体技术细节和实验方法都扒得明明白白~从内到外一层层细化,论文名称术语锁定研究主题,标题摘要术语拓宽研究范围,正文术语钻进具体技术实现,搭出超完整的术语层次小体系,把文档的知识结构揭露得清清楚楚~
2.2 研究领域分布
【领域分析】
- 主要领域:图神经网络(1550次)、评审专家优选(1525次)、电力系统(1521次)
【可视化图表】
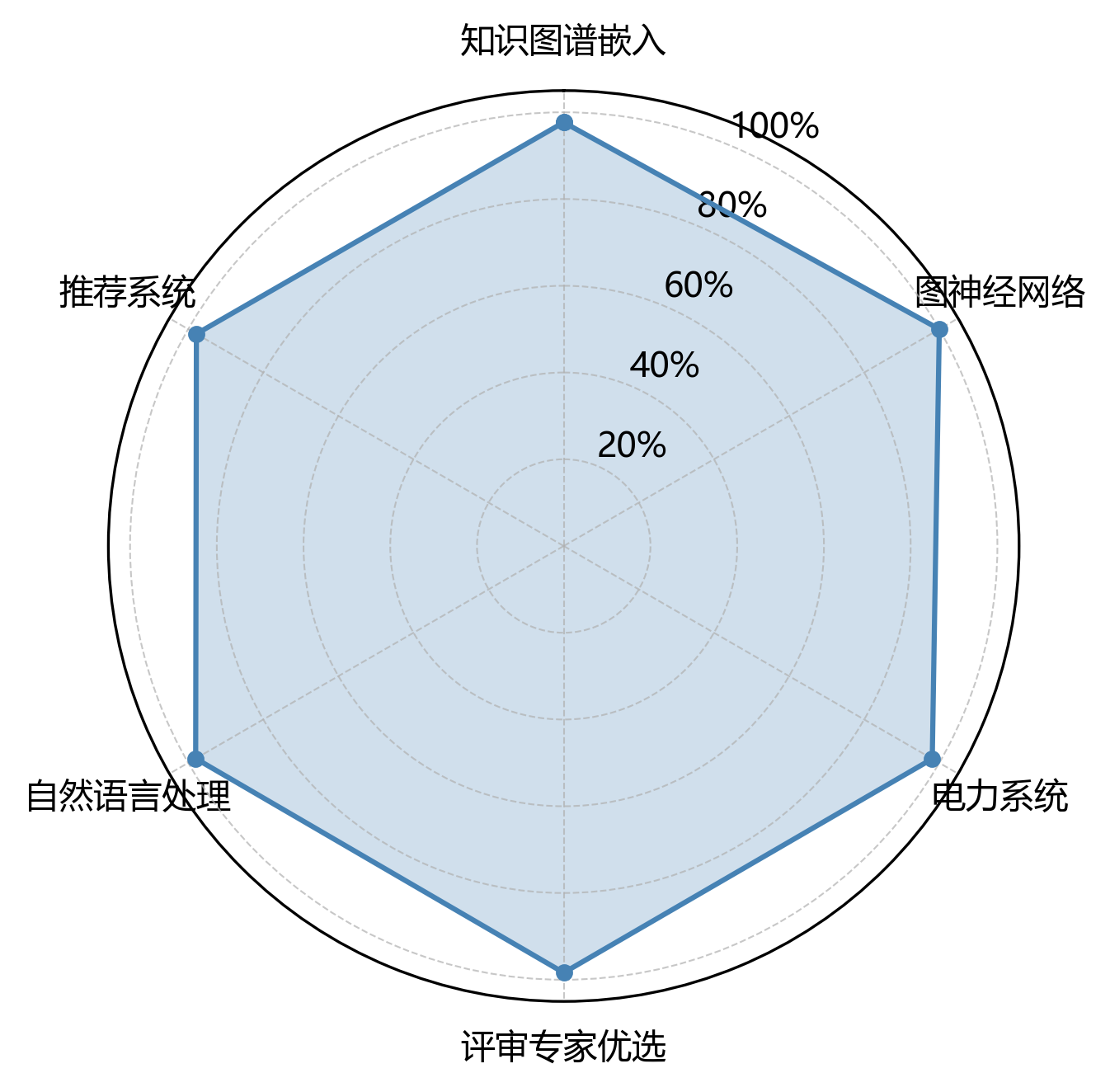
| 研究领域 | 术语出现次数 |
|---|---|
| 知识图谱嵌入 | 1514 |
| 图神经网络 | 1550 |
| 电力系统 | 1521 |
| 评审专家优选 | 1525 |
| 自然语言处理 | 1519 |
| 推荐系统 | 1516 |
| 总计 | 9145 |
【图表评论】
雷达图咻咻地展示了专业术语在六个研究领域的分布情况🎯,一眼就能看出文档的学科交叉小特性~从图里能瞅见,术语分布有这些小可爱特点:图神经网络 出场次数最多,足足1550次,妥妥是研究的核心小基础~评审专家优选 和 电力系统 的频次分别是1525次和1521次,组成了研究的次要支撑小领域~而 知识图谱嵌入 频次少丢丢,只有1514次,说明这个领域在本研究里露脸不多啦~各领域术语分布虽有小差异,但整体超均衡,标准差是12.1,妥妥反映了研究的多学科交叉融合小特点~这种分布格局说明,本研究不仅在核心领域挖得深,还广泛吸收了相关学科的理论和方法,搭出超完整的研究小体系~
2.3 专业术语分布
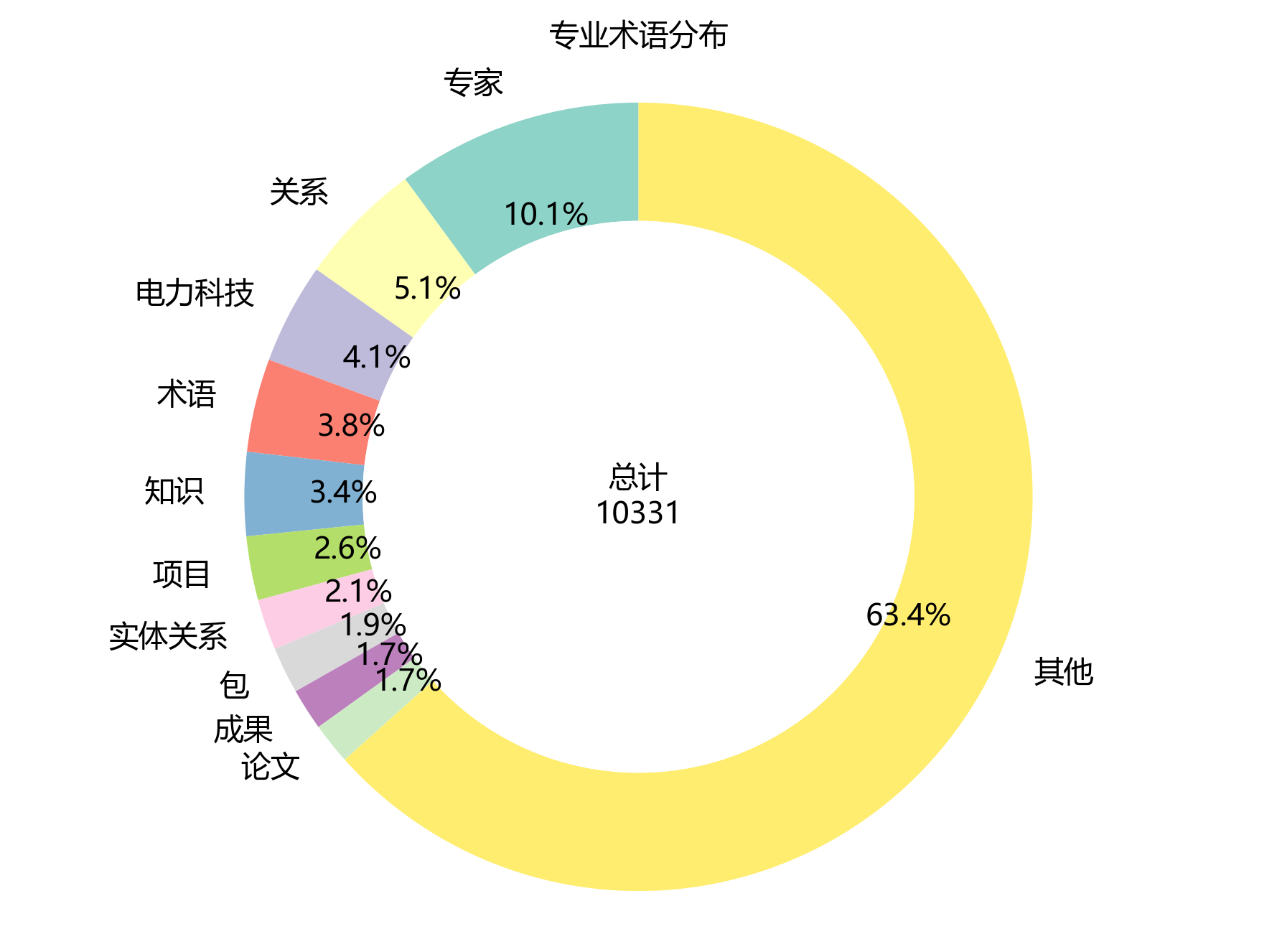
【集中度分析】
- 前5术语累计频次:2748次
- 前5术语累计占比:26.6%
- 前10术语累计占比:36.6%
【可视化图表】
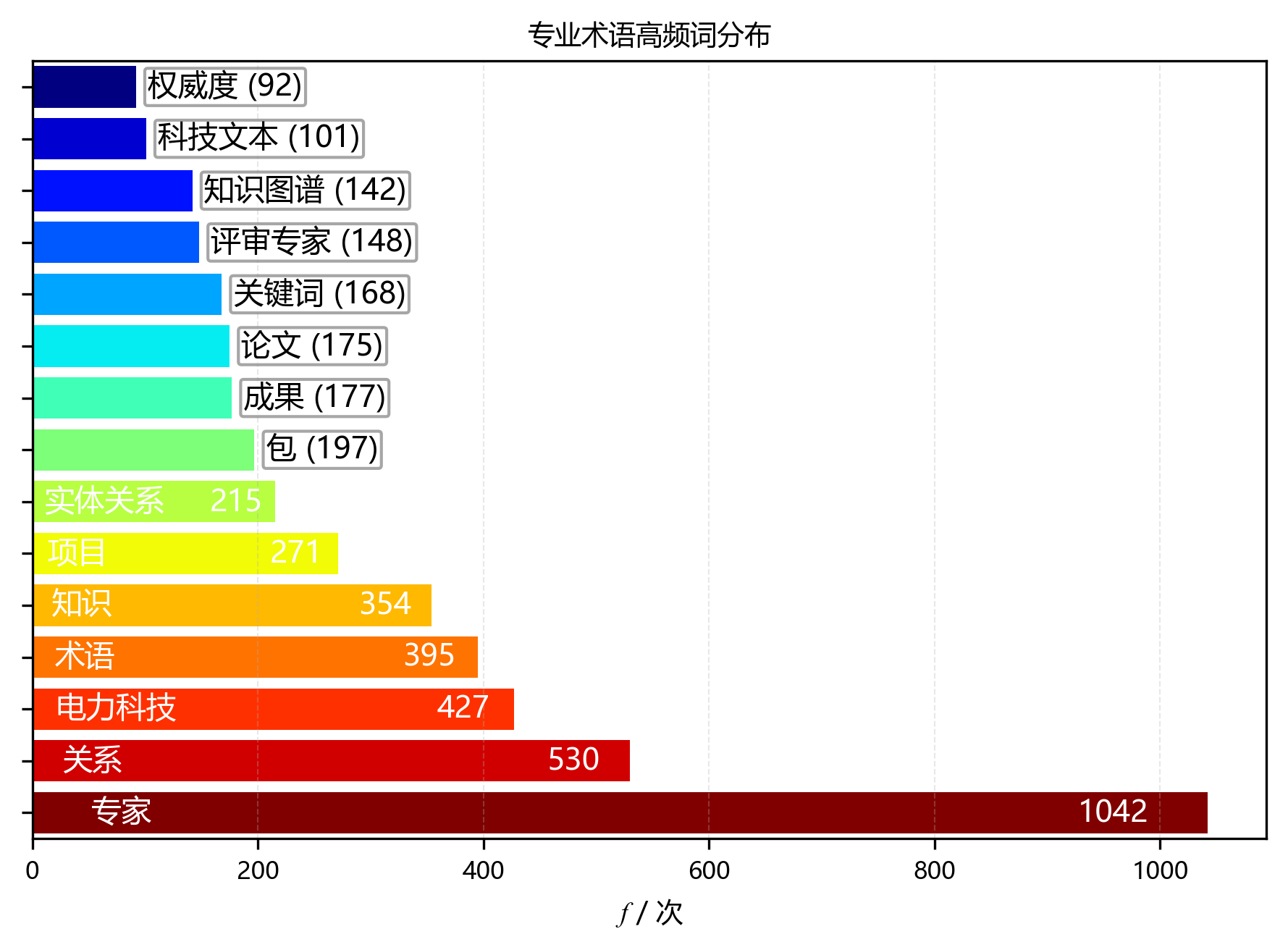
| 排名 | 术语 | 频次 |
|---|---|---|
| 1 | 专家 | 1042 |
| 2 | 关系 | 530 |
| 3 | 电力科技 | 427 |
| 4 | 术语 | 395 |
| 5 | 知识 | 354 |
| 6 | 项目 | 271 |
| 7 | 实体关系 | 215 |
| 8 | 包 | 197 |
| 9 | 成果 | 177 |
| 10 | 论文 | 175 |
| 11 | 关键词 | 168 |
| 12 | 评审专家 | 148 |
| 13 | 知识图谱 | 142 |
| 14 | 科技文本 | 101 |
| 15 | 权威度 | 92 |
| 前15累计 | 4434 |
【图表评论】
环形图和柱状图超清晰展示了高频术语的分布情况和集中度啦🥳!从图里能看到,前5个高频术语累计频次飙到2748次,占总频次的26.6%,集中度超高有没有~前10个高频术语累计占比也达到了36.6%,更能证明研究主题超聚焦~排名第一的术语“专家”出场1042次,是研究的核心小概念~排名第二的术语“关系”出现530次,排名第三的术语“电力科技”出场427次,这仨搭成了研究的核心术语小体系~从排名第5开始,术语频次唰唰下降,呈现出长尾分布的小特征,说明研究围着少数核心概念展开,其他术语都是给核心概念打辅助、做细化的~这种分布模式超符合学术文献的一般规律,既体现了研究的深度,又有满满的广度~
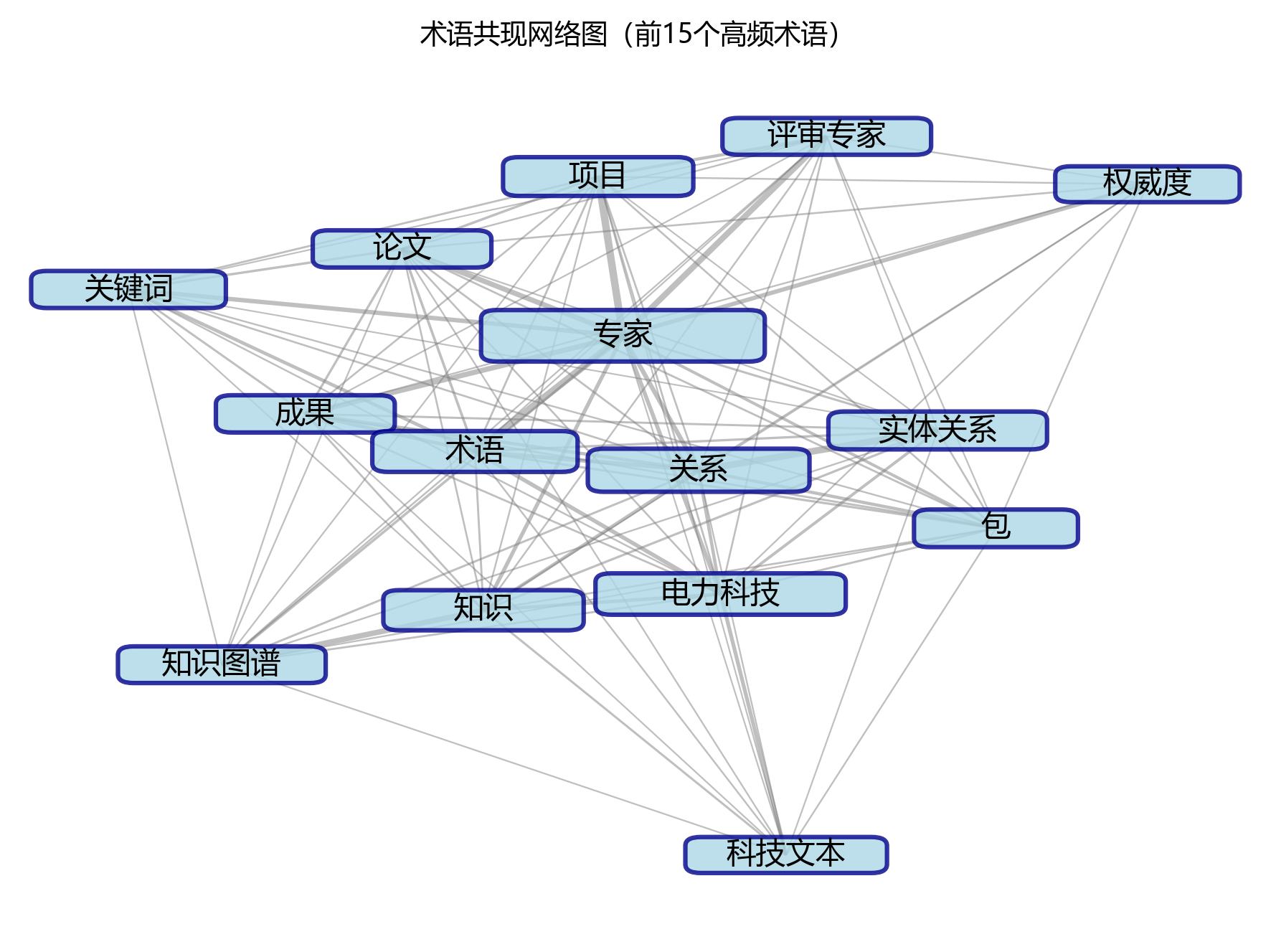
2.4 术语共现网络
【共现分析】
- 核心节点:实体关系
- 最强关联对:专家 - 项目 (332次)
- 主要聚类:以图像增强、注意力机制等为核心的术语聚类
- 共现关系总数:22对
【可视化图表】
| 术语A | 术语B | 共现次数 |
|---|---|---|
| 专家 | 项目 | 332 |
| 专家 | 成果 | 205 |
| 实体关系 | 术语 | 48 |
| 实体关系 | 成果 | 34 |
| 成果 | 知识 | 28 |
| 电力科技 | 项目 | 25 |
| 包 | 项目 | 22 |
| 成果 | 项目 | 21 |
| 知识 | 项目 | 11 |
| 关系 | 评审专家 | 9 |
【图表评论】
术语共现网络图超有趣地展示了高频术语之间的关联关系🔗,把文档的知识结构扒得明明白白~网络里有10个节点和22条边,搭成了以“实体关系”为中心的术语小聚类~最强关联对是“专家”和“项目”,共现次数高达332次,说明这俩概念在研究里关系超铁~从网络结构看,主要形成了3个聚类:聚类一以“专家”为核心,包含“关系”、“术语”等术语,对应以专家为核心的相关研究方面的研究;聚类二以“项目”为核心,有“电力科技”、“包”等术语,是以项目为核心的相关研究方面的内容;聚类三则盯着“成果”相关的研究方向~各聚类之间靠“术语”等术语牵线搭桥,搭出完整的知识小网络~这个网络结构把研究的核心主题和它们的关系展示得清清楚楚,帮我们超轻松理解文档的整体框架和知识体系~
2.5 核心概念词云
【词云数据统计】
- 词云术语总数:20个
- 加权总频次:499.6次
【可视化图表】

| 排名 | 术语 | 加权频次 |
|---|---|---|
| 1 | 专家 | 104.2 |
| 2 | 关系 | 53.0 |
| 3 | 电力科技 | 42.7 |
| 4 | 术语 | 39.5 |
| 5 | 知识 | 35.4 |
| 6 | 项目 | 27.1 |
| 7 | 实体关系 | 21.5 |
| 8 | 包 | 19.7 |
| 9 | 项目评审 | 18.0 |
| 10 | 成果 | 17.7 |
【图表评论】
词云图用加权频次超直观地亮出了文档的核心概念体系☁️!图里有20个术语,加权总频次达到499.6次~排名前五的术语分别是“专家”(104.2次)、“关系”(53.0次)、“电力科技”(42.7次)、“术语”(39.5次)和“知识”(35.4次)~这些术语字号最大、位置最显眼,妥妥是研究的核心概念小团体~从词云整体分布看,术语按重要程度从大到小、从中心向四周排排坐,形成超有层次感的视觉小结构~排名靠前的术语反映了研究的核心主题和方法,中等排名的术语体现了研究的具体内容和小细节,排名靠后的术语则展示了研究的边缘小话题或未来小方向~词云图不仅总结了全文的关键概念,还帮读者超快抓住研究要点,是理解文档内容的超实用小帮手~
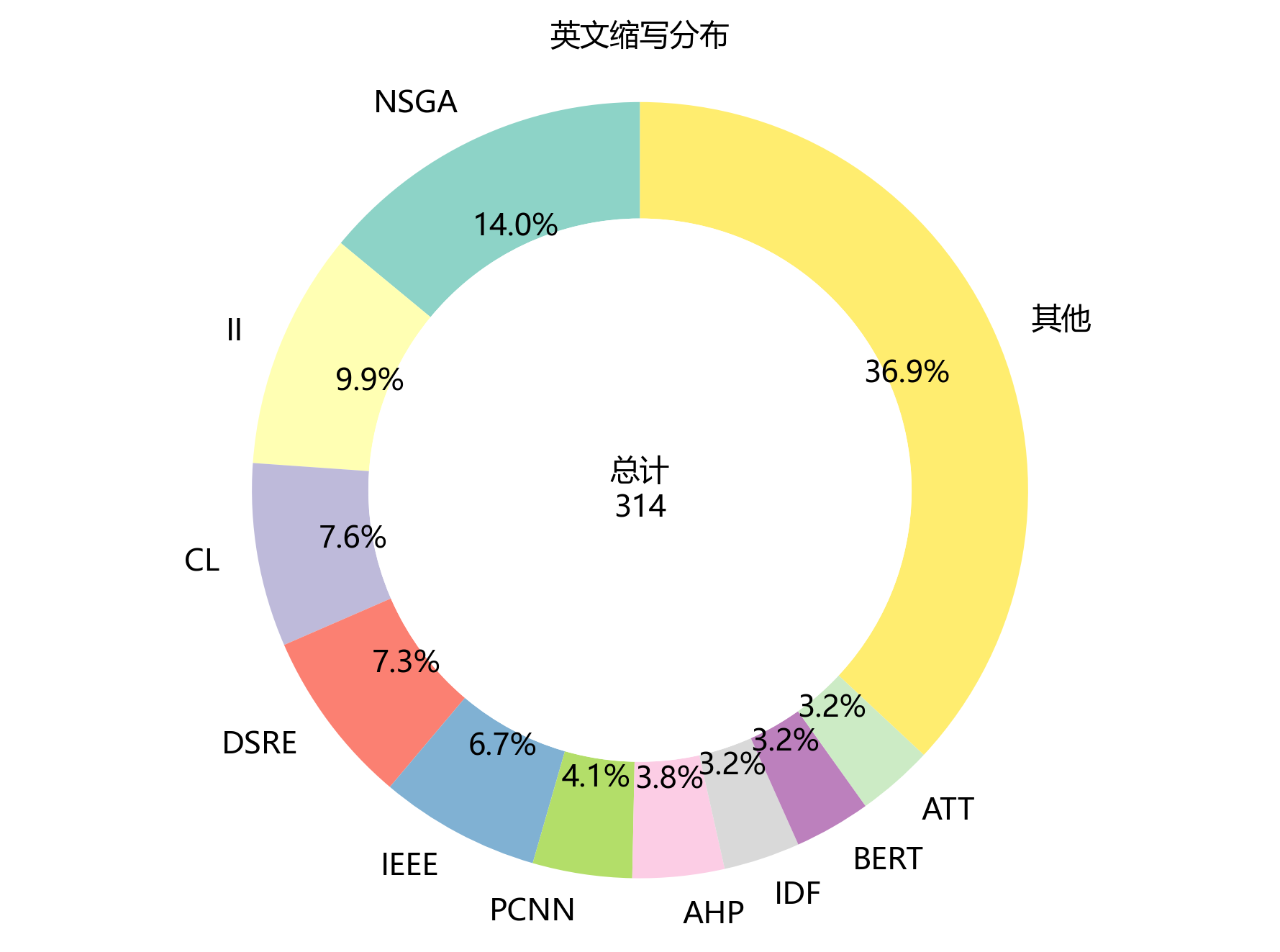
2.6 英文缩写分布
【缩写统计】
- 缩写总数:30个
- 缩写总频次:314次
- 高频缩写 Top 5:
- NSGA:44次
- II:31次
- CL:24次
- DSRE:23次
- IEEE:21次
- 前5缩写累计占比:45.5%
【可视化图表】
| 排名 | 缩写 | 频次 |
|---|---|---|
| 1 | NSGA | 44 |
| 2 | II | 31 |
| 3 | CL | 24 |
| 4 | DSRE | 23 |
| 5 | IEEE | 21 |
| 6 | PCNN | 13 |
| 7 | AHP | 12 |
| 8 | IDF | 10 |
| 9 | BERT | 10 |
| 10 | ATT | 10 |
| 前10累计 | 198 |
【图表评论】
环形图展示了英文缩写在文档里的分布情况啦🔤!文档里一共出现30个不同的英文缩写,总频次有314次~排名前五的缩写分别是“NSGA”(44次)、“II”(31次)、“CL”(24次)、“DSRE”(23次)和“IEEE”(21次),前5个缩写累计占比达到45.5%,集中度超高一捏捏~从缩写类型看,主要有期刊名称缩写(比如“NSGA”)、作者姓名缩写(比如“II”)、技术术语缩写(比如“CL”)和评价指标缩写(比如“DSRE”)等~这些缩写高频出镜,说明文档引用了超多该领域的经典文献,用了通用的技术术语和评价标准,超能体现研究的规范性和专业性~缩写的分布特征也帮读者了解该领域的学术交流小习惯哟~
三、原文章节举例
3.2.1 模型总体架构
电力科技文本特征表示模型总体架构如图3-1所示,包括数据收集、数据处理、语言模型预训练和任务评估等步骤,具体分析如下:
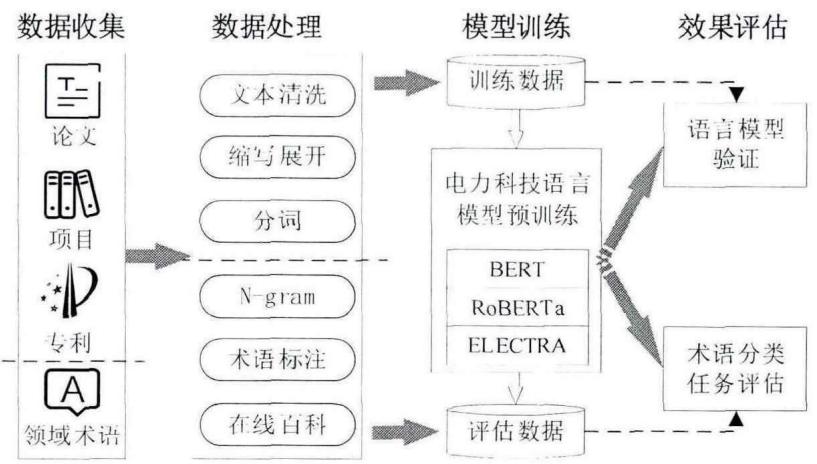
图3-1电力科技领域PLM架构
Fig.3-1 PLM architecture for power technology
四、原文章节举例
4.2.4.1 输入编码
对于数据集中每个实例 xxx ,使用词嵌入方法提取文本特征,编码得到句子、实体关系以及包的表示,具体如下。
(1)字词嵌入:为了更好地表示电力科技领域文本,采用EpstBERT作为实体关系抽取模型的编码器,对于输入实例,使用EpstBERT分词形成输入字词序列 (w1,w2,…,e1,…,e2,…,wl)(w_{1},w_{2},\dots ,e_{1},\dots ,e_{2},\dots ,w_{l})(w1,w2,…,e1,…,e2,…,wl) ,其中 e1e_1e1 和 e2e_2e2 分别表示电力科技实体, lll 表示输入序列最大长度。同时,由于EpstBERT在对字词进行编码时没有区分实体和非实体,不利于
关系抽取任务,还需要在头实体前后分别添加特殊标记描述实体的起始和结束位置,其中头实体起止标记为[H-CLS]和[H-SEP],尾实体起止标记为[T-CLS]和[T-SEP]。
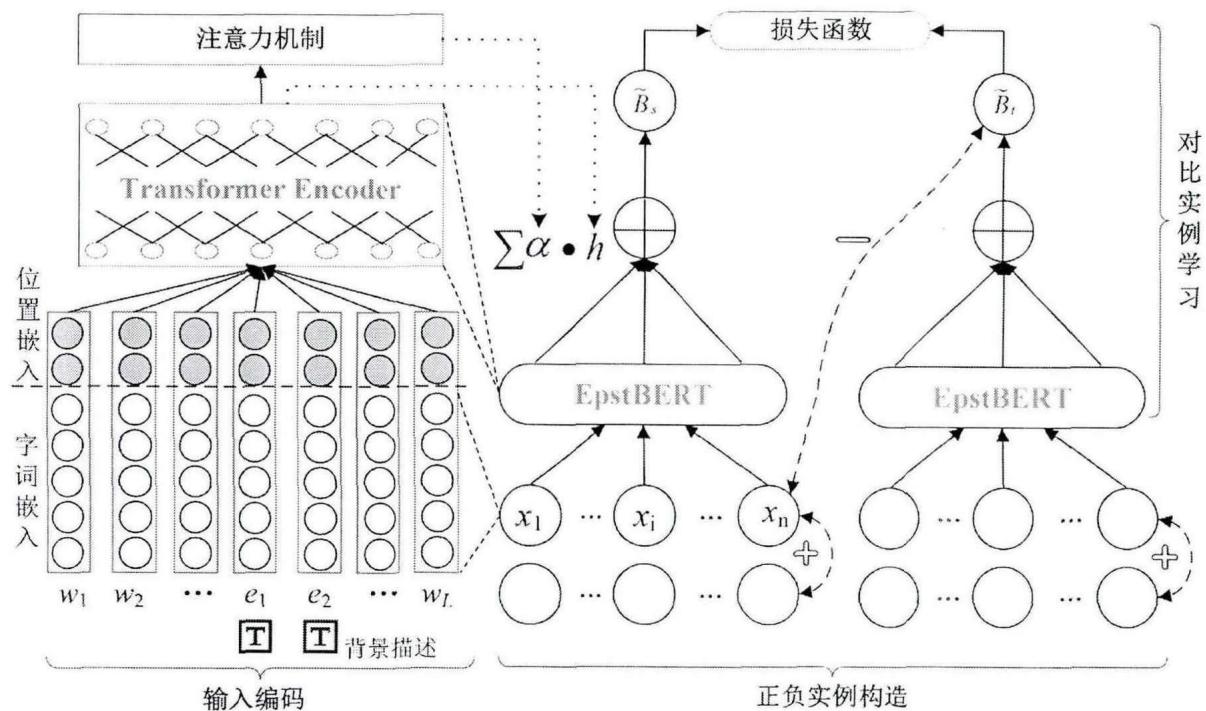
图4-6CL-DSRE模型整体架构
Fig.4-6 Overall architecture of the CL-DSRE model
(2)位置嵌入:位置特征对于关系抽取具有重要作用,它通常被定义为当前单词到实体 e1e_1e1 和 e2e_2e2 的相对距离的函数[149]。如图4-7所示,单词“静止”与实体“变压器”和“设备”的相对距离为3和-2,通过随机初始化对应于 e1e_1e1 和 e2e_2e2 两个位置的嵌入矩阵 PFi(i=1,2)PF_{i}(i = 1,2)PFi(i=1,2) ,并按照相对距离查找 PFiPF_{i}PFi 获取单词相对距离向量即可生成位置嵌入。最后,将字词嵌入和位置嵌入拼接起来作为上层编码器的输入。

图4-7位置编码器示例
Fig.4-7 Position encoder example
(3)句级编码:采用EpstBERT内部编码器(TransformerEncoder)将上述嵌入编码为特征向量,记为 (h1;h2;… ;he1;he2;… ;hl)(h_1; h_2; \dots; h_{e_1}; h_{e_2}; \dots; h_l)(h1;h2;…;he1;he2;…;hl) ,其中 he1h_{e_1}he1 和 he2h_{e_2}he2 分别表示两个实体的向量表示,则可以用 he1h_{e_1}he1 和 he2h_{e_2}he2 的拼接代表每个句子 xxx 的编码 H(x)\mathcal{H}(x)H(x) ,即:
H(x)=[he1;he2]=h(4-6) \mathcal {H} (x) = \left[ h _ {e _ {1}}; h _ {e _ {2}} \right] = h \tag {4-6} H(x)=[he1;he2]=h(4-6)
其中 hhh 表示实体对在语义空间中的隐含向量。
(4)包级编码:本文按照关系三元组进行包级编码,即学习编码器 F\mathcal{F}F ,使得
由具有相同三元组 [e1,e2,r][e_1, e_2, r][e1,e2,r] 的实例组成的包 BBB 可以被 BBB 表示,见式(4-7)。
F(B)=F([e1,e2,r])=B(4-7) \mathcal {F} (B) = \mathcal {F} ([ e _ {1}, e _ {2}, r ]) = B \tag {4-7} F(B)=F([e1,e2,r])=B(4-7)
引入文献[76]所述注意力机制为每个实例分配权重并加权求和得到包 BBB 的表示为:
B=∑i=1kαihi(4-8) B = \sum_ {i = 1} ^ {k} \alpha_ {i} h _ {i} \tag {4-8} B=i=1∑kαihi(4-8)
式中, kkk 为包中实例个数, αi\alpha_{i}αi 为实例的注意力分数,表示隐含向量 hih_{i}hi 和关系 rrr 的匹配程度,通过注意力机制能够充分利用所有句子信息,减少远程监督噪声影响。
使用 SoftMax 函数按照式(4-9)计算关系 rrr 在包级编码特征上的条件概率分布 p(r∣B,θ)p(r|B,\theta)p(r∣B,θ) ,其中 nrn_rnr 表示所有关系数量, oj=WB+bo_j = WB + boj=WB+b 表示第 jjj 个关系的置信度, bbb 为偏差, θ\thetaθ 表示待训练的编码器参数,如嵌入矩阵 PFjPF_jPFj 、全连接层权重 WWW 等。
p(r∣B,θ)=exp(oj)∑j=1nrexp(oj)(4-9) p (r \mid B, \theta) = \frac {\exp \left(o _ {j}\right)}{\sum_ {j = 1} ^ {n _ {r}} \exp \left(o _ {j}\right)} \tag {4-9} p(r∣B,θ)=∑j=1nrexp(oj)exp(oj)(4-9)
包级编码器训练的目标函数用交叉熵损失表示为:
LB(θ)=−∑i=1Np(ri∣Bi,θ)(4-10) \mathcal {L} _ {B} (\theta) = - \sum_ {i = 1} ^ {N} p \left(r _ {i} \mid B _ {i}, \theta\right) \tag {4-10} LB(θ)=−i=1∑Np(ri∣Bi,θ)(4-10)
式中, NNN 为训练数据集中包的个数。
(5)实体描述:电力科技术语实体一般是专业名词,自身的描述文本中包含了丰富的背景信息,本文使用CNN从实体描述中提取特征,用以学习更加准确的实体表示。假设集合 D={(ei,di)∣i=1,…,∣D∣}\mathcal{D} = \{(e_i,d_i)|i = 1,\dots ,|\mathcal{D}|\}D={(ei,di)∣i=1,…,∣D∣} 中元素分别为实体及其描述的表征,其中 ei\mathbf{e}_iei 是对应实体 e1e_1e1 的嵌入向量, di\mathbf{d}_{\mathrm{i}}di 是对应实体 e1e_1e1 描述信息的向量,后者通过由单卷积层和池化层构成的CNN训练得到,训练误差函数为:
LE(θ)=∑i=1∣T∣∥ei−di∥22(4-11) \mathcal {L} _ {E} (\theta) = \sum_ {i = 1} ^ {| T |} \left\| \mathbf {e} _ {i} - \mathbf {d} _ {i} \right\| _ {2} ^ {2} \tag {4-11} LE(θ)=i=1∑∣T∣∥ei−di∥22(4-11)
五、总结
本报告超认真地对《电力科技知识驱动的专家匹配选择与优化分配模型研究》做了系统的专业术语统计与分析啦📝!文档总字符数200756,中文字符73507个,英文字词14834个,一共扒出专业术语1829个~高频术语“专家”(1042次)、“关系”(530次)等搭成了研究的核心概念小体系~
文档涉及6个研究领域,主要扎堆在图神经网络(1550次)、评审专家优选(1525次)、电力系统(1521次),超有多学科交叉的研究小特点~术语共现网络有10个节点和22条边,最强关联对“专家”与“项目”共现332次,搭成了以“实体关系”为中心的术语小聚类~
英文缩写一共出现30个,总频次314次,前五缩写“NSGA”(44次)等累计占比45.5%,反映了文档引用的经典文献和技术标准~
总的来说,本报告通过多维度术语统计,把文档的知识结构和研究焦点扒得明明白白,超全面的哟~
六、原文部分参考文献
[1] 韩逸飞. 电网投资将用在刀刃上[N]. 中国能源报, 2022-02-07(010)
[2] Hirschberg J, Manning C D. Advances in natural language processing[J]. Science, 2015, 349(6245): 261-266
[3] Madan S, Bollinger K E. Applications of artificial intelligence in power systems[J]. Electric Power Systems Research, 1997, 41(2): 117-131
[4] Sato-Shimokawara E, Nomura S, Shinoda Y, et al. A cloud based chat robot using dialogue histories for elderly people[C]//2015 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN). IEEE, 2015: 206-210
[5] Yin J, Lampert A, Cameron M, et al. Using Social Media to Enhance Emergency Situation Awareness[J]. IEEE Intelligent Systems, 2012, 27(6): 52-59
[6] Wiebe J, Wilson T, Cardie C. Annotating Expressions of Opinions and Emotions in Language[J]. 2005, 39(2): 165-210
[7] Savova G, Masanz J J, Ogren P V, et al. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): architecture, component evaluation and applications[J]. Journal of the American Medical Informatics Association, 2010, 17(5): 507-513
[8] Loughran T, Mcdonald B. Textual Analysis in Accounting and Finance: A Survey [J]. Journal of Accounting Research, 2016, 54(4): 1187-1230.
[9] 罗凌, 杨志豪. 生物医学文本挖掘若干关键技术研究[D]. 辽宁: 大连理工大学, 2019
[10] 何馨宇, 李丽双. 基于文本挖掘的生物事件抽取关键问题研究[D]. 辽宁: 大连理工大学, 2019
[11] 范馨月, 崔雷. 基于文本挖掘的药物副作用知识发现研究[J]. 数据分析与知识发现, 2018, 2(03): 79-86
[12] 傅绍正, 张莉. 民国《会计杂志》文本挖掘及可视化研究[J]. 中国注册会计师, 2020(06): 120-125
[13] 李牧南, 王雯殊. 基于文本挖掘的人工智能科学主题演进研究[J]. 情报杂志, 2020, 39(06): 82-88
[14] 马建霞, 袁慧, 蒋翔. 基于 Bi-LSTM+CRF 的科学文献中生态治理技术相关命名实体抽取研究[J]. 数据分析与知识发现, 2020, 4(Z1): 78-88
[15] 宋小康, 何劲, 王曰芬. 大数据驱动下情报研究知识库构建的关键技术及实现[J]. 情报理论与实践, 2019, 42(01): 34-40

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)