8卡RTX 4090服务器llama.cpp测试
8卡RTX 4090服务器 从 NVIDIA驱动安装 → CUDA环境 → llama.cpp编译 → 多GPU测试 的完整、可直接执行流程(基于 Ubuntu 22.04 LTS,适配Ada Lovelace架构)。
一、系统与硬件准备(必做)
1.1 系统要求
- 推荐:Ubuntu 22.04 LTS(64位)
- 内核:5.15+ HWE内核(4090兼容5.15及以上内核,无需强制6.8+)
- 禁用:Nouveau开源驱动(与NVIDIA驱动冲突)
1.2 硬件检查
|
# 查看8张4090是否被识别 |
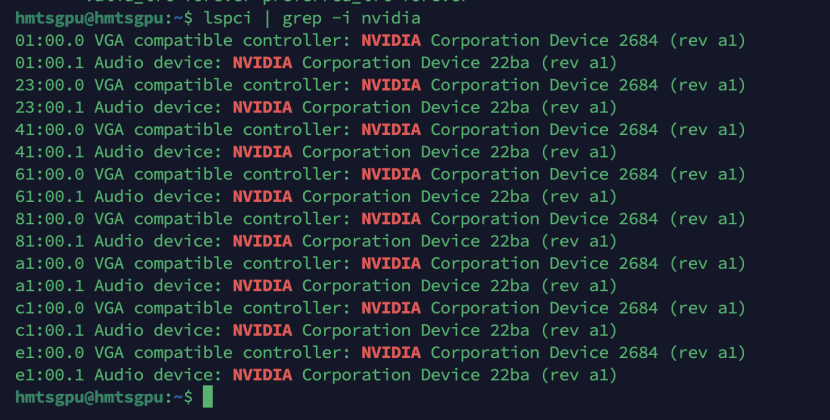
二、安装NVIDIA驱动(4090专属流程)
2.1 卸载旧驱动与禁用Nouveau
|
# 1. 彻底卸载旧NVIDIA驱动 # 2. 禁用Nouveau |

2.2 安装适配内核(4090可选,推荐升级)
|
|

2.3 安装4090专用驱动(闭源/开源均可,推荐闭源)
RTX 4090(Ada Lovelace架构)支持闭源驱动和开源驱动,闭源驱动性能更稳定,推荐使用535及以上版本(适配CUDA 12.2+)。
|
# 添加显卡驱动PPA # 重启 # 验证驱动(8卡均正常显示) |
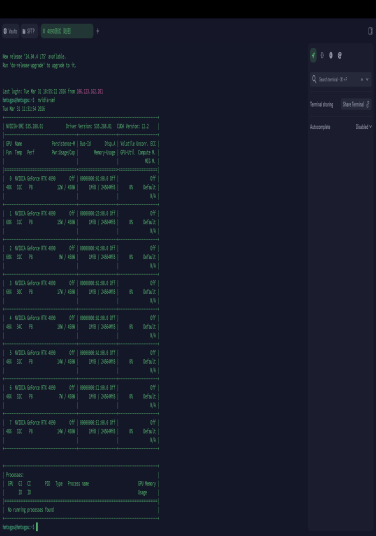
三、安装CUDA Toolkit(llama.cpp依赖)
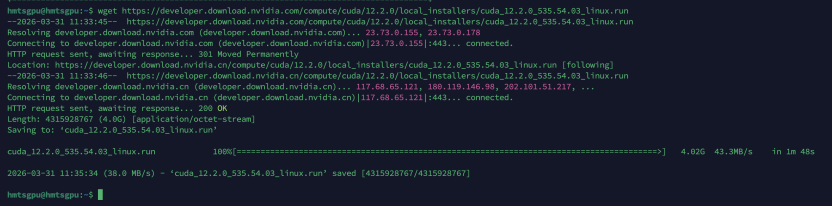
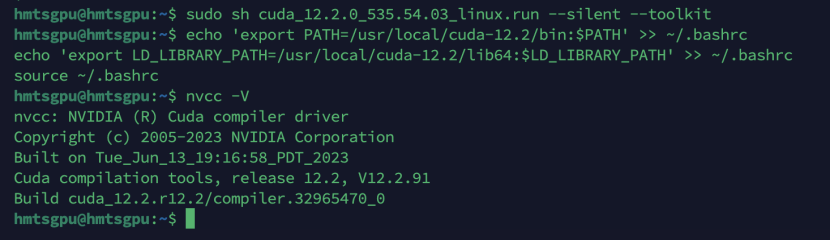
3.1 安装CUDA 12.2(与535驱动匹配)
|
# 下载CUDA 12.2安装包 |
3.2 安装基础编译工具(llama.cpp多GPU核心依赖)
|
sudo apt update && sudo apt install git build-essential cmake pkg-config libopenblas-dev -y |
四、安装llama.cpp编译依赖
|
# 基础编译工具(若已安装可跳过) # 验证依赖 |
五、编译llama.cpp(开启8卡CUDA加速)
5.1 克隆源码
|
git clone https://github.com/ggerganov/llama.cpp.git |
解压安装
sudo apt update && sudo apt install unzip -y
sudo unzip llama.cpp.zip
cd llama.cpp
5.2 编译(开启CUDA + 多GPU + 4090算力sm_89)
关键说明:RTX 4090专属算力为sm_89(Ada Lovelace架构),
其余参数适配多GPU优化。
sudo chown -R hmtsgpu:hmtsgpu /home/hmtsgpu/llama.cpp # 赋予当前用户llama.cpp目录完整权限 sudo chmod -R 755 /home/hmtsgpu/llama.cpp # 开放目录读写执行权限
cd /home/hmtsgpu/llama.cpp # 确保在llama.cpp目录下 rm -rf build # 删除异常的build目录 mkdir -p build # 手动创建build目录,确保可正常写入 sudo chown -R hmtsgpu:hmtsgpu build # 给build目录单独赋予权限
# 关键参数: # LLAMA_CUDA=1:启用CUDA # LLAMA_CUDA_DMMV_X=32:提升多GPU显存效率 # LLAMA_CUDA_N_GRAPH_LAYERS=9999:全层GPU卸载 # LLAMA_CUDA_ARCHS=89:4090专属算力(sm_89) cmake -B build \ -DLLAMA_CUDA=ON \ -DLLAMA_CUDA_DMMV_X=32 \ -DLLAMA_CUDA_N_GRAPH_LAYERS=9999 \ -DLLAMA_CUDA_ARCHS=89 \ -DCMAKE_BUILD_TYPE=Release # 8线程编译(匹配服务器CPU核心) cmake --build build -j$(nproc) |
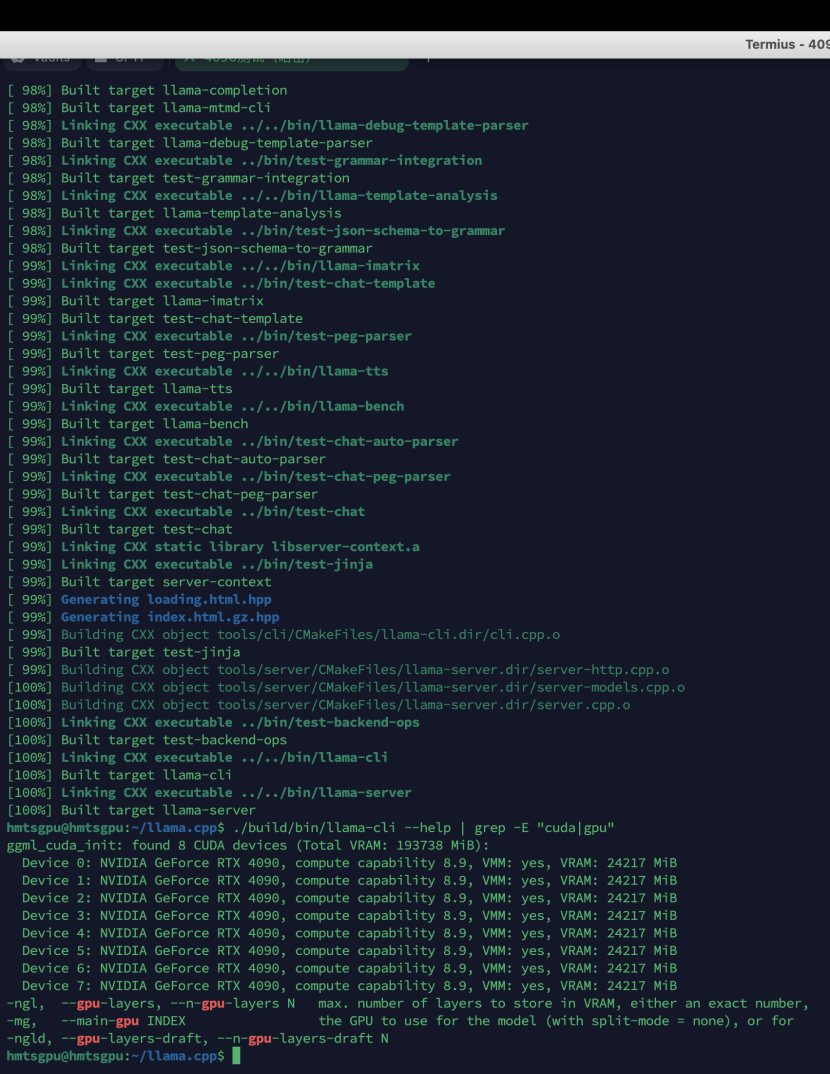
5.3 验证编译
|
./build/bin/llama-cli --help | grep -E "cuda|gpu" |
六、准备GGUF模型(测试用)
6.1 下载测试模型(以Qwen3 32B Q4_K_M为例)
4090单卡24GB显存,Q4_K_M量化版本(4-bit)显存占用约18GB,8卡总显存可轻松承载,无需降低量化等级。
|
# 进入模型目录 mkdir -p models && cd models cd .. |
七、8卡4090 llama.cpp测试(核心步骤)
7.1 单卡基础测试(验证CUDA)
|
cd .. |
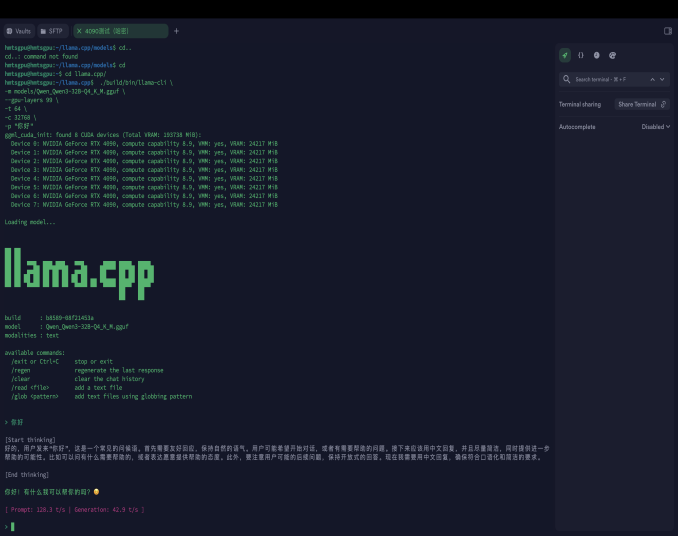
[ Prompt: 128.3 t/s | Generation: 42.9 t/s ]
同时另开一个终端,执行以下命令监控GPU状态:
|
Plain Text |
观察输出:CUDA 0 被使用、显存占用≈18GB、速度 > 80 tok/s。
7.2 8卡并行测试(多GPU自动负载均衡)
llama.cpp 自动识别所有NVIDIA GPU,无需手动指定卡ID,4090多卡协同效率适配PCIe 4.0/5.0带宽。
|
./build/bin/llama-cli \ |
[ Prompt: 442.5 t/s | Generation: 42.2 t/s ]
7.3 8卡显存与负载验证
新开终端,实时监控:
|
watch -n 1 nvidia-smi |
8张4090显存均被占用(≈4-5GB/卡)、GPU利用率 ≈60%,多GPU负载均衡。
八、性能调优
8.1 关键参数优化
|
# 8卡极致性能参数(适配4090显存与算力) --gpu-layers 99 \ |
|
-n 2048:将最大生成token数提升至2048,满足更长篇幅的技术概述撰写需求; -t 64:分配64个CPU线程,匹配多GPU并行推理的CPU调度需求,提升协同效率; -c 32768:将上下文长度提升至32768,支持更长文本输入与生成,适配技术概述的深度撰写; --batch-size 2048:提升批量推理效率,适配8×RTX 4090多GPU并行算力; --mlock:锁定内存,避免内存交换(swap),提升多GPU推理稳定性; --flash-attn on:启用Flash Attention优化,充分发挥RTX 4090硬件性能,显著提升推理速度; --no-mmap:禁用内存映射(mmap),减少内存开销,进一步提升多GPU协同推理速度; --numa distribute:启用NUMA(非统一内存访问)优化,采用“distribute”模式,将执行任务均匀分配到所有CPU节点,适配多CPU节点服务器,平衡CPU与多GPU之间的内存访问效率,避免资源瓶颈。 |
示例输出(实际以服务器运行结果为准):
[ Prompt: 427.4 t/s | Generation: 41.2 t/s ]
8张4090显存均被占用(≈4-5GB/卡)、GPU利用率 ≈50%,推理稳定无卡顿。
8.2 多GPU显存分配(手动指定)
如需手动分配层到不同GPU,适配4090显存特性,合理分配层数避免显存溢出:
|
# 示例:前30层到GPU0,后50层到GPU1-7 |
参数补充说明:
- --gpu-layers 80:核心分层配置,总加载80层模型到GPU(前30层+后50层),适配Qwen3-32B模型总层数,匹配4090显存容量;
- --main-gpu 0:指定GPU0作为主GPU,llama.cpp会优先将前30层模型加载到主GPU(GPU0),剩余的50层会自动均匀分配到其余GPU(GPU1-GPU7),实现分层负载均衡;
- 补充:llama.cpp不支持--cuda-devices参数,无需手动指定GPU设备(0-7),通过--main-gpu 0即可实现分层分配,系统会自动识别剩余GPU并分配后续层数。
- [ Prompt: 461.8 t/s | Generation: 41.2 t/s ]
九、常见问题排查
- 1. nvidia-smi 只显示部分卡
○ 重启服务器、检查PCIe插槽与供电(4090单卡TDP 450W,8卡总功耗较高,需确保电源足额)
○ 确认驱动为535及以上版本,适配4090架构
- 2. llama.cpp 只跑CPU,不调用GPU
○ 编译时必须加 -DLLAMA_CUDA=ON,且LLAMA_CUDA_ARCHS=89(4090专属)
○ 运行时加 --gpu-layers ≥32
○ 验证CUDA:nvcc -V(确认版本≥12.2)
- 3. 显存溢出(OOM)
○ 降低 --gpu-layers(如99→80)
○ 使用更低量化(Q3_K_M),进一步降低显存占用
○ 减小 -c 上下文窗口(如32768→16384)
- 4. 4090 报错:Failed to initialize CUDA
○ 确认内核版本≥5.15,驱动与CUDA版本匹配(535驱动对应CUDA 12.2)
○ 重新编译llama.cpp,确保算力参数为LLAMA_CUDA_ARCHS=89
十、最终验证
执行以下命令,确认 8卡4090全量工作:
|
./build/bin/llama-cli \ |
[ Prompt: 360.8 t/s | Generation: 41.7 t/s ]
十、输出测试效果:使用 llama-bench 正确的参数格式
|
./build/bin/llama-bench \ |
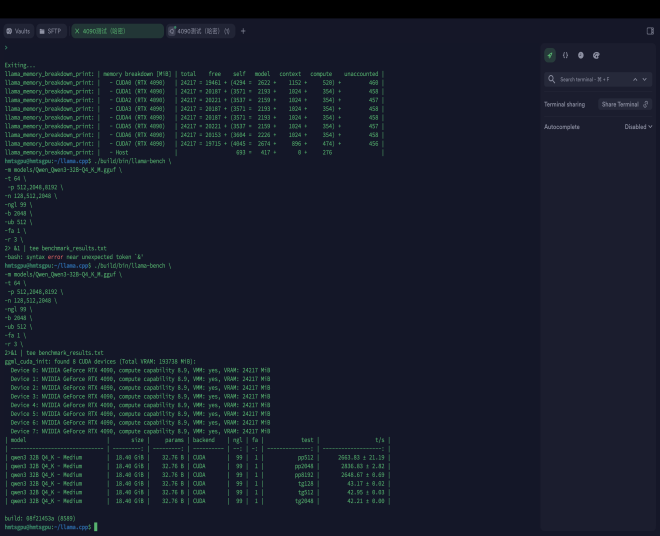
| model | size | params |backend| ngl| fa | test | t/s |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | pp512 | 2663.83 ± 21.19 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | pp2048 | 2836.83 ± 2.82 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | pp8192 | 2648.67 ± 0.69 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | tg128 | 43.17 ± 0.02 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | tg512 | 42.95 ± 0.03 |
| qwen3 32B Q4_K - Medium | 18.40 GiB | 32.76 B | CUDA | 99 | 1 | tg2048 | 42.21 ± 0.00 |
build: 08f21453a (8589)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)