LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels 论文翻译
摘要
联合嵌入预测架构(JEPA)为在紧凑隐空间中学习世界模型提供了极具潜力的框架,但现有方法仍不稳定,需依赖复杂的多损失项、指数移动平均、预训练编码器或辅助监督来避免表征坍缩。本文提出 LeWorldModel(LeWM),首个仅用两项损失即可从原始像素端到端稳定训练的 JEPA:下一时刻嵌入预测损失,以及强制隐嵌入服从高斯分布的正则项。与现有唯一端到端方案相比,可训练损失超参数从 6 个降至 1 个。LeWM 仅 1500 万参数,单 GPU 数小时即可完成训练,规划速度比基于大模型的世界模型快48 倍,且在各类 2D/3D 控制任务上性能相当。除控制任务外,通过物理量探测实验证明,LeWM 的隐空间能编码有意义的物理结构;意外值评估则验证模型可可靠检测物理上不合理的事件。
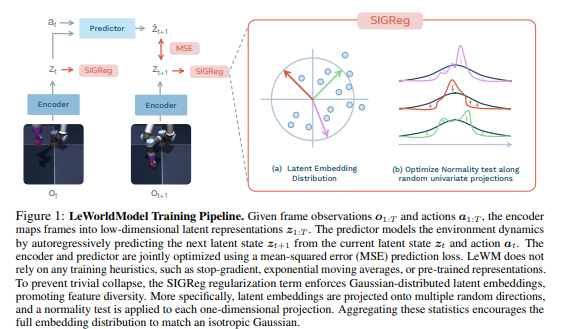
1 引言
人工智能的核心目标之一是让智能体通过单一统一学习范式习得多任务、多环境技能 —— 直接从环境感官输入学习,无需人工设计状态表征或领域特定校准。视觉输入尤为适合:相机成本低、易扩展,从像素学习可实现从原始感官到动作的全端到端训练。
世界模型(World Models, WMs)是一类强大方法,可学习预测动作在环境中的后果。成功的世界模型能让智能体仅在 “想象空间” 中规划与自我提升,这在离线学习场景中尤为重要:智能体无需与环境交互,仅从固定数据集学习,利用模型生成虚拟经验并评估反事实动作序列。
近期流行的世界模型学习方法是联合嵌入预测架构(JEPA)。JEPA 不试图建模环境所有细节,而是聚焦预测未来状态所需的关键特征。具体而言,JEPA 将观测编码为紧凑低维隐空间,并通过预测未来观测的隐表征建模时序动态。
但 JEPA 概念虽简洁,现有方法极易坍缩:模型将所有输入映射为几乎相同的表征,以简单满足时序预测目标,导致表征失效。因此,防止坍缩是 JEPA 训练的核心挑战。诸多工作提出解决方案,但通常依赖启发式正则、多目标损失、外部信息或预训练编码器等架构简化。实际中,这些策略常引入额外不稳定性,或显著提升训练复杂度。
为突破上述局限,本文提出 LeWM:首个无需启发式、原理清晰且简洁,从原始像素端到端稳定学习 JEPA 的方法。LeWM 可在单 GPU 上训练,降低研究门槛。本文在 2D/3D 环境的操作、导航、运动任务上全面评估 LeWM,并通过针对性探测与意外值量化实验,检验其隐空间的直观物理理解能力。
本文核心贡献:
- 提出一种端到端 JEPA 方法,可从原始像素在单 GPU 上学习隐世界模型,依赖简洁稳定的双项目标,在不同架构与超参数下保持鲁棒,支持高效对数时间超参数搜索。
- LeWM 以 1500 万参数的紧凑模型,在各类 2D/3D 控制任务上取得强劲性能,超越现有端到端 JEPA 方法,性能与基于大模型的世界模型相当,成本大幅降低,规划速度最高提升48 倍。
- 通过物理量探测与预期违背测试,评估隐空间的物理理解能力,验证模型可检测非物理轨迹。
2 相关工作
世界模型
世界模型旨在从数据中学习环境动态的预测模型,让智能体在想象中推理未来状态。主流世界模型包含生成式方法:在像素空间显式建模环境动态,基于过去状态与动作生成未来观测,可作为学习型模拟器,已成功用于 Minecraft、CS、Crafter 等游戏环境,提升强化学习策略的样本效率。
但多数生成式世界模型需奖励信号,联合建模动态与价值相关信息。本文聚焦无奖励场景,与 JEPA 系列工作一致:仅从观测数据学习通用、任务无关的世界模型,不依赖奖励监督。
- 传统生成式世界模型(Generative World Models) 通常是面向强化学习(RL)设计的。 它们不只预测“下一帧画面会是什么样”(dynamics),还必须同时预测奖励(reward) 和 结束信号(done)。 为什么?因为它们的最终目标是“训练一个能最大化累计奖励的策略(policy)”。 所以模型的输入是 (当前画面
, 当前动作
),输出是 (下一画面
, 下一奖励
, 是否结束)。 典型例子:DreamerV3、IRIS、DIAMOND 等。它们在训练时会用奖励信号来更新价值函数和策略,所以数据集里必须包含奖励标签。
- LeWorldModel(LeWM)走的完全是另一条路(JEPA 路线): 完全不依赖奖励,只用 (
为什么 LeWM 可以没有奖励?
- 因为它只做下一状态预测(next-embedding prediction):
- 编码器把每一帧画面
。
- 预测器根据
动作
。
- 损失函数只有两项:①预测误差(MSE):||ẑ_{t+1} - z_{t+1}||² ②SIGReg 正则项(让 latent 分布接近高斯,避免 collapse)。
没有奖励,它是怎么“工作”和“得到反馈”的?
- 训练时:完全自监督(self-supervised)。模型自己看数据里的 (
),用“预测得准不准”作为唯一信号来更新参数。SIGReg 再强迫 latent 不能全部坍缩成一个点。
- 使用时(规划/控制): 给模型一个目标画面
(比如你想让机器人把积木推到某个位置),模型把
。 然后在 latent 空间里用 CEM(Cross-Entropy Method)优化动作序列,让预测的最终状态
尽量接近
JEPA
JEPA 在紧凑低维隐空间中预测系统动态演化。自 LeCun 提出后,JEPA 主要沿两条路线发展:
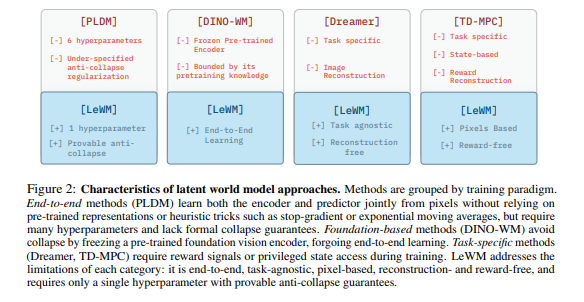
- 自监督表征学习:预测掩码输入块的隐嵌入,如 I-JEPA(图像)、V-JEPA(视频)、Echo-JEPA/Brain-JEPA(医疗数据)。这类方法通常用 ** 目标编码器指数移动平均(EMA)与停止梯度(SG)** 稳定训练、防止坍缩,但 EMA 与 SG 缺乏理论支撑,通常不对应明确定义的目标最小化。
- 基于动作的隐世界建模:部分方法依赖预训练编码器获取表征,虽避免坍缩,但表征表达力受限于预训练编码器。PLDM 则用 VICReg 加额外正则项端到端学习表征,但存在训练不稳定、可扩展性受限问题。
本文提出稳定训练方案:直接从像素端到端训练 JEPA,仅用两项损失—— 未来嵌入预测目标,与强制嵌入服从高斯分布的正则项。
基于隐动态的规划
世界模型开创性地从高维观测的紧凑隐表征直接学习策略。近期工作则在测试时直接在隐空间做规划(MPC),用世界模型在线预测候选动作序列结果并迭代优化,模型保留在控制回路中,支持自适应决策,但计算需求更高。

3 方法:LeWorldModel
本节介绍LeWorldModel(LeWM)。首先描述从离线数据中学习隐式世界模型的简化训练流程,包括数据集、模型架构和训练目标;随后说明如何通过 ** 模型预测控制(MPC)** 在隐空间进行规划,从而利用训练好的模型做决策。
3.1 学习隐式世界模型
离线数据集
本文采用完全离线、无奖励的学习设置。LeWorldModel 仅从未标注的观测与动作轨迹训练,不使用奖励信号或任务指定信息。这一设定与 JEPA 系列工作一致,目标是从观测数据中学习通用、与任务无关的世界模型,而非针对特定任务优化行为。
完全离线(fully offline)的含义:
- 训练阶段完全不和真实环境交互。
- 数据集是事先收集好的固定轨迹(trajectories):只包含 (
),没有奖励,也没有任务标签。
- 训练完以后,模型就固定了(参数不再更新)。
- 后面做规划(planning)或控制时,也不用再去环境里采样新数据,全部在模型的 latent 空间里“想象”完成(imagination / latent planning)。
训练数据由长度为 T 的轨迹构成,包含原始像素观测 o1:T 与对应的动作 a1:T。轨迹从任意行为策略中离线采集,无需满足最优性,只需充分覆盖环境动态即可。
模型架构
LeWM 由两个核心模块构成:编码器(Encoder)与预测器(Predictor)。
- 编码器:将单帧观测 ot 映射为紧凑、低维的隐式表示 zt。
- 预测器:在隐空间建模环境动态,给定当前隐嵌入 zt 与动作 at,预测下一帧观测的嵌入
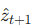 。
。
计算公式:
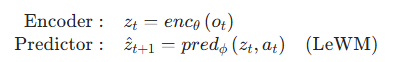
编码器实现为视觉 Transformer(ViT),默认采用 tiny 配置(约 500 万参数),patch 大小 14,12 层、3 个注意力头,隐藏维度 192。观测嵌入 zt 取自最后一层的[CLS] token,再经过单层 MLP + 批归一化做投影。这一步是必要的,因为 ViT 最后一层使用层归一化,会阻碍防坍缩目标的有效优化。
预测器为 6 层 Transformer,16 个注意力头,dropout 率 10%(约 1000 万参数)。动作通过自适应层归一化(AdaLN)融入每一层,AdaLN 参数初始化为 0,以稳定训练并让动作条件逐步影响预测器学习。预测器接收 N 帧历史表示,带时序因果掩码自回归预测下一帧表示。预测器后同样接有与编码器结构一致的投影网络。
世界模型的所有组件联合端到端学习。
训练目标
学习目标是得到对未来预测有用、能建模环境动态的隐式表示。LeWM 的训练损失由两项相加构成:预测损失与正则化损失。
-
预测损失
(教师强制)计算相邻时刻预测嵌入与真实嵌入的均方误差:
![]()
-
预测损失会激励编码器学习对预测器 “可预测” 的表示。但仅用该损失会导致表征坍缩:编码器把所有输入映射成相同常量。
-
SIGReg 防坍缩正则项为避免坍缩、提升嵌入空间的特征多样性,采用SIGReg(Sketched-Isotropic-Gaussian Regularizer),强制隐嵌入服从各向同性高斯分布。
高维空间直接检验正态性很困难,SIGReg 通过将嵌入投影到 M 个随机单位方向![]() ,对每一维投影做单变量Epps–Pulley 正态性检验,再取平均。根据Cramér–Wold 定理,匹配所有一维边缘分布等价于匹配完整联合分布。
,对每一维投影做单变量Epps–Pulley 正态性检验,再取平均。根据Cramér–Wold 定理,匹配所有一维边缘分布等价于匹配完整联合分布。
Z = 一堆隐向量;把它们随机投影到很多个一维直线上(就像从不同角度看);对每个方向检查:是不是像高斯分布(正态分布);把所有方向的结果取平均
总结:强迫模型的输出像正态分布,不要所有输出都变成一样的数。这就是防止坍缩的核心
最终 LeWM 训练目标:
![]()
该方法仅引入两个训练超参数:SIGReg 的随机投影数量 M、正则权重 λ。默认设置 M=1024、λ=0.1。实验表明 M 对下游性能几乎无影响,因此只有 λ 需要调参,可通过二分搜索高效完成(对数复杂度)。
LeWM不使用停止梯度、指数移动平均(EMA)或其他稳定启发式,所有损失全程回传梯度,所有参数联合端到端优化,流程简洁、易实现。
3.2 隐空间规划
推理阶段,在世界模型的隐空间中做轨迹优化。给定初始观测 o1,随机初始化候选动作序列,迭代滚动预测隐状态至规划时域 H。
模型按以下方式预测隐状态转移:![]()
规划目标是最小化终端隐空间与目标的匹配误差:![]() 其中 z^H 是滚动最后一步的预测隐状态,zg 是目标观测 og 的编码。世界模型参数在规划时固定。
其中 z^H 是滚动最后一步的预测隐状态,zg 是目标观测 og 的编码。世界模型参数在规划时固定。
这是一个有限时域最优控制问题:![]()
本文使用 ** 交叉熵法(CEM)** 求解,这是一种采样优化方法,迭代选出最优策略并更新采样分布。
为缓解自回归滚动带来的误差累积,采用 ** 模型预测控制(MPC)** 策略:仅执行前 K 个规划动作,然后根据新观测重新规划
![]()

推理 / 规划阶段(latent planning)(对应 Figure 4):
- 给定当前画面 o₁ 和目标画面 o_g(不需要奖励!)。
- 编码:z₁ = enc(o₁),z_g = enc(o_g)。
- 用 CEM(Cross-Entropy Method)在 latent 空间优化动作序列 a_{1:H},目标是让预测的最终状态尽量接近目标:
- 采用 MPC(Model Predictive Control):只执行前 K 步动作,然后重新从新画面开始规划。
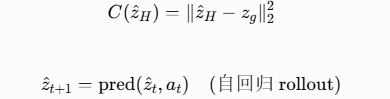
为什么预测损失 + SIGReg 就能逼出物理规律?
想象一下模型在训练时“看到”的数据(以 Push-T 为例):
- 每一条轨迹都是真实物理模拟器生成的:小球推 T 形积木时,积木只会按照真实物理移动(不能穿墙、会旋转、会滑行、有摩擦……)。
- 模型每次都看到 (当前画面 o_t, 动作 a_t, 下一画面 o_{t+1})。
训练过程可以简化成一句话:
“我要把
- 如果 Encoder 把 位置、速度、角度、物体关系 这些真正能决定下一帧的物理量 好好地编进 z 里,Predictor 就很容易预测,损失就小。
- 如果 Encoder 把这些物理量扔掉、或者把所有画面都压成差不多一样的向量(collapse),Predictor 就完全预测不准,损失就会很大。
所以预测损失像一个“物理老师”:它只奖励那些最容易预测未来的表示方式。 而最容易预测未来的表示,恰恰就是低维的物理状态变量(agent 位置、block 位置、block 角度、速度……)。
SIGReg 再加一道保险: 它强迫所有 z 必须铺满一个均匀的高斯球面,不能都挤成一个点。 这样就逼着 Encoder 必须把不同物理状态区分开,不能偷懒。
结果:经过几万条真实物理轨迹的训练,潜空间 z 就自动变成了一个压缩版的物理世界——里面天然包含了位置、速度、碰撞关系等信息。
4 隐式规划性能
4.1 规划评估设置
环境
我们在一系列多样化任务上对 LeWM 进行评估,包括导航、运动规划与操作,覆盖二维与三维环境,所有环境均为连续动作空间。
- Two-Room:简单的 2D 导航任务
- PushT:经典 2D 机器人操作任务
- OGBench-Cube:视觉更丰富的 3D 操作任务
- Reacher:2D 双关节机械臂到达任务
基线方法
我们将 LeWM 与以下基线对比:
- DINO-WM、PLDM:当前最先进的基于 JEPA 的方法
- GCBC:目标条件行为克隆策略
- GCIVL、GCIQL:目标条件离线强化学习算法
其中,PLDM 与本文设置最接近,同样直接从像素观测端到端学习世界模型,但依赖基于 VICReg 的七项训练目标,导致训练不稳定、超参调优复杂。DINO-WM 使用冻结的 DINOv2 作为特征编码器以缓解表征坍缩,但并非端到端学习。为公平对比,实验中 DINO-WM 不使用本体感受信息。
所有方法在所有环境上均使用固定超参数。
4.2 面向高效世界模型规划
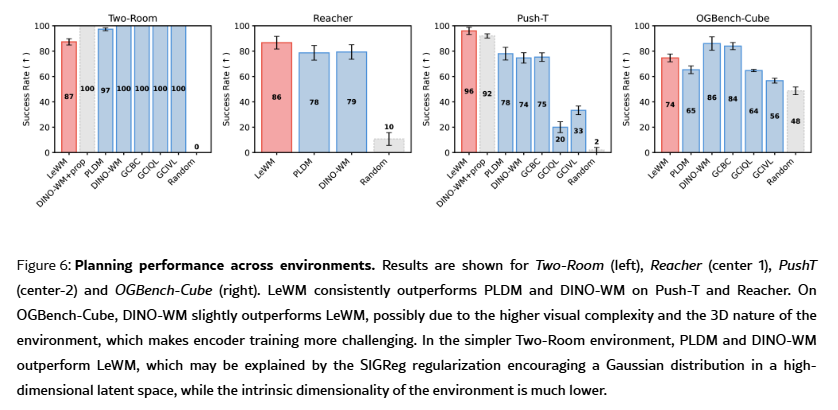
实验结果表明:
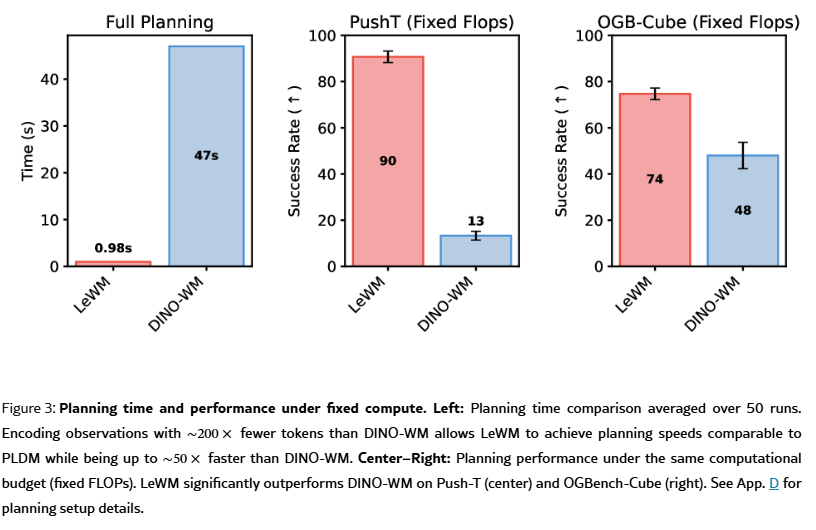
- LeWM 在更具挑战性的规划任务上显著优于 PLDM,在 PushT 任务上成功率高出 18%,并与 DINO-WM 性能相当。
- 值得注意的是,在 PushT 上,仅使用像素的 LeWM 甚至超过了带有额外本体感受信息的 DINO-WM,证明 LeWM 能够有效捕捉任务相关的核心物理量。
- 在最简单的 Two-Room 环境中,LeWM 表现略差,原因是该数据集多样性低、内在维度小,SIGReg 正则在高维隐空间强制高斯分布,可能导致隐表征结构不够理想。
规划速度
LeWM 的规划速度最高提升 48 倍,完整规划可在1 秒内完成,在各环境上表现稳定,大幅接近实时控制的要求。
4.3 面向世界模型的稳定训练
消融实验
我们对 LeWM 的关键设计进行消融分析:
- SIGReg 内部参数随机投影数量 M、积分节点数对性能几乎无影响,说明无需精细调优,λ 是唯一有效超参数。
- 超参搜索效率LeWM 仅需调 1 个超参,可用二分搜索(O (log n))高效完成;PLDM 需调 6 个超参,只能多项式搜索(O (n⁶))。
- 嵌入维度维度需足够大才能保证性能,但超过阈值后快速饱和,说明方法对编码器容量不敏感。
- 编码器架构将默认 ViT 替换为 ResNet-18 仍能达到有竞争力的性能,说明 LeWM 对视觉编码器不敏感。
训练曲线
- LeWM:两项损失目标收敛平滑、单调,预测损失稳步下降,SIGReg 损失在训练初期快速下降后趋于平稳,隐分布快速逼近各向同性高斯。
- PLDM:七项损失目标噪声大、非单调,多个正则项相互竞争,梯度难以平衡。
结果充分体现 LeWM 的核心优势:训练目标极简、过程高度稳定。
5 量化 LeWM 中的物理理解能力
本章将通过从隐表示中提取物理量、测量世界模型对物理变化的检测能力这两种方式,评估 LeWM 隐空间所捕获的动态过程质量。
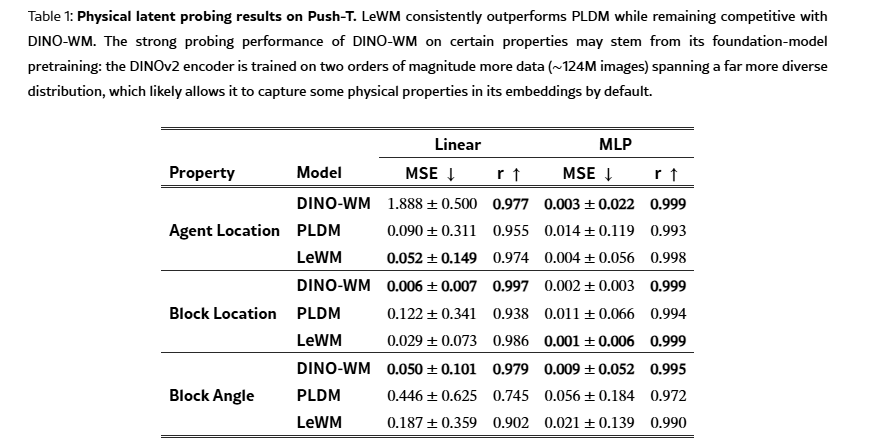
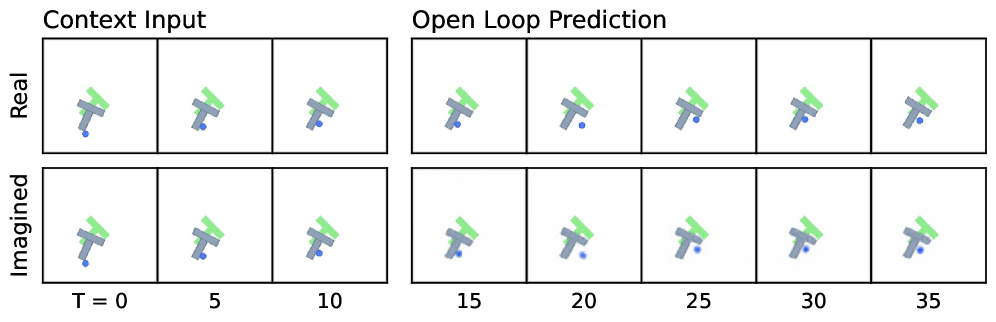
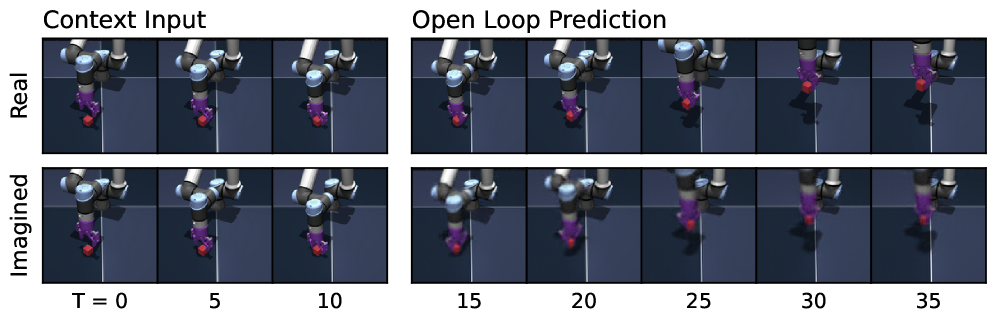
Figure 7:Predictor rollouts on PushT and OGBench-Cube. We visualize decoded latent plans produced by LeWM given a context and an action sequence. Each rollout uses three image observations as context, which are encoded into latent representations. Conditioned on the action sequence, the predictor autoregressively generates future latent states in an open-loop manner. All predicted latents are decoded into images using a decoder that was not used during training. The resulting imagined rollouts closely match the real observations, demonstrating that the latent representation effectively captures the overall scene structure and essential environment dynamics. Some finer details, however, are not fully captured by LeWM; for instance, the angle of the end-effector in OGBench-Cube. Additional rollouts are provided in Fig. 11.

Figure 8:Decoder visualization during training. As training progresses, the latent representation increasingly captures the information required to reconstruct the visual scene, even though no reconstruction loss is used during training. Early in training, the decoded images correspond to slow features, a phenomenon previously reported [49].
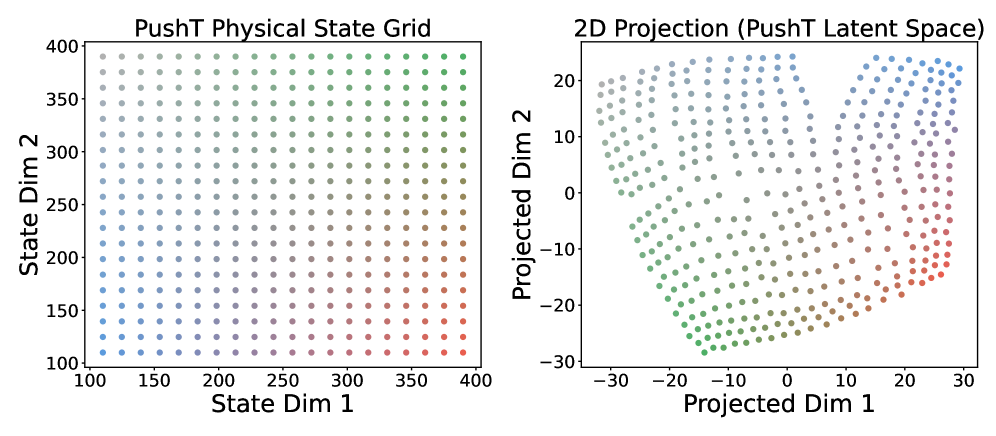
Figure 9:Visualization of the latent space obtained with LeWM for the PushT environment. On the left, the grid of states is obtained by moving the agent and the block in the x-y plane. On the right, the embeddings of these states are visualized using a t-SNE.
5.1 隐空间的物理结构
物理量探测(Probing physical quantities)
作为衡量物理理解的首要指标,我们评估可以从 LeWM 的隐表示中恢复出哪些物理量。我们分别训练线性探针与非线性探针,从给定的隐嵌入中预测目标物理量。
在 Push‑T 环境上的结果(表 1)显示:
- 我们的方法持续优于 PLDM
- 与 DINOv2 这类大规模预训练模型得到的表示相比性能相当
DINO‑WM 在部分物理属性上的强劲表现,可能来自其基座模型的大规模预训练(约 1.24 亿张图像),使其嵌入天然包含部分物理属性。
隐空间解码
为进一步评估隐表示所捕获的信息,我们训练了一个解码器,用于从单个隐嵌入(192 维)重建像素观测。尽管训练过程从未使用重建损失,解码器依然能从学习到的表示中恢复出视觉场景,证明低维紧凑的隐空间保留了足够的底层物理状态信息。
隐空间可视化
我们使用 t‑SNE 对隐空间结构做可视化。结果表明,学习到的表示捕获了环境的空间结构,在隐空间中保留了邻域关系与相对位置。
时序隐路径拉直(Temporal Latent Path Straightening)
受神经科学中的时序拉直假说启发,我们测量训练过程中连续隐速度向量之间的余弦相似度。结果发现:
- LeWM 的隐轨迹在训练中自然变得越来越平直,且没有任何显式正则项鼓励这一行为
- 即使 PLDM 使用了专门的时序平滑正则项,LeWM 依然实现了更高的时序平直度
这一现象是自发涌现的,对下游规划任务有益。
5.2 预期违背(VoE)评估框架
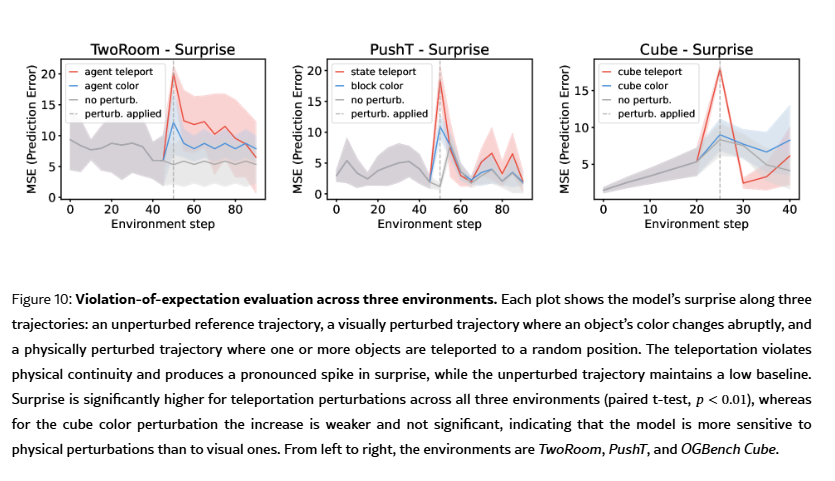
另一种量化物理理解的方式是:检测与所学世界模型相矛盾的事件的能力。本文采用发展心理学中常用的预期违背(VoE)范式,评估模型是否会对违背物理规律的事件赋予更高的意外值(surprise)。
我们用预测值与真实未来观测之间的偏差来量化意外值。实验在三个环境中进行:Two‑Room、PushT、OGBench‑Cube。
对每个环境,我们引入两类扰动:
- 视觉扰动:物体颜色突然改变
- 物理扰动:物体被瞬间传送到随机位置,违背场景的物理连续性
结果(图 10)清晰表明:
- LeWM 对包含物理违背的帧, consistently 赋予显著更高的意外值
- 对未扰动轨迹,意外值保持低基线
- 对颜色这类视觉扰动,意外值上升微弱且不显著
这说明模型对物理扰动远比对视觉扰动更敏感,其隐空间真正学习到了环境的物理规则,而非仅记忆视觉外观
6 结论
本文提出了 LeWorldModel(LeWM),一种用于学习环境隐式世界模型的稳定端到端方法。LeWM 属于联合嵌入预测架构(JEPA),它使用编码器将图像观测映射到隐空间,并通过预测器在嵌入空间中以动作为条件建模时序动态。
在仅使用原始像素输入的多种连续控制环境中,LeWM 在数据效率、规划速度、训练时长与稳定性上均超越了已有方法,同时保持具有竞争力的最终任务性能。训练的稳定性与简洁性,来自于显式地约束隐嵌入服从各向同性高斯分布以避免表征坍缩。
总体而言,LeWM 为现有隐式世界模型方法提供了一种可扩展的替代方案,兼具原理清晰的训练动态,以及可解释、可涌现的表示特性。
局限与未来工作
尽管取得了上述可喜成果,本文仍存在一些局限,也指明了重要的研究方向:
- 长时序规划能力有限当前基于隐式世界模型的规划仍局限于较短的时域。层级世界建模是解决长时序推理与规划的一个很有前景的方向。
- 对数据多样性有依赖本方法仍依赖具有足够交互覆盖度的离线数据集,这类数据的采集成本较高。在极低复杂度、内在维度很小的环境中,SIGReg 正则在高维隐空间中强制匹配高斯先验会变得困难,从而影响效果。在大规模、多样化的自然视频数据集上进行预训练,有望提供更强的表示先验,降低对领域特定数据的依赖。
- 依赖动作标注现有端到端隐式世界模型需要动作标签来预测未来状态,这类标注同样获取成本较高。一个有前景的方向是通过逆动态建模学习未来动作表示,从而减少对显式动作标注的依赖。
一些看完论文之后的小疑问:
这些任务的数据集里有没有前置设置的物理规则?
有,但不是直接写在数据集文件里,而是隐含在“生成数据集的模拟器”里。
所有四个任务的数据集都是完全离线的,里面只有两样东西:
- 原始像素画面序列
- 对应的动作序列
没有任何奖励、任务标签、物理参数、规则描述。
但是,这些数据不是随机生成的,而是在一个固定物理模拟器里用策略(heuristic 或 RL 策略)跑出来的真实轨迹。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)