【Claude基础】08.子代理系统:分身术与并行执行
0. 【Claude基础】全部目录
- 【Claude基础】01.Claude全景图:模型、产品与生态
- 【Claude基础】02.安装与首次交互:5分钟上手Claude Code
- 【Claude基础】03.斜杠命令体系:掌握Claude Code的操作语言
- 【Claude基础】04.Memory与CLAUDE.md:打造你的专属AI助手
- 【Claude基础】05.Skills深度指南:让Claude学会你的工作流
- 【Claude基础】06.Hooks深度指南:事件驱动的自动化管道
- 【Claude基础】07.MCP Servers深度指南:连接万物的协议
- 【Claude基础】08.子代理系统:分身术与并行执行
- 【Claude基础】09.多代理协作:Agent Teams与编排模式
- 【Claude基础】10.插件开发与生产部署:构建可分发的能力包
1. 子代理设计哲学
1.1 单一上下文窗口的局限
Claude Code 的会话运行在一个上下文窗口里。这个窗口有容量上限——即使是最大规格的模型,上下文也就 200K tokens 左右(Opus 4.6 有 1M,但大多数场景用的是 Sonnet)。一个复杂的工程任务,可能需要:
-
读取几十个源码文件做安全审计
-
同时在另一个分支上实现新功能
-
再顺便把 API 文档更新一遍
如果这些事情全塞在一个会话里,问题就来了:
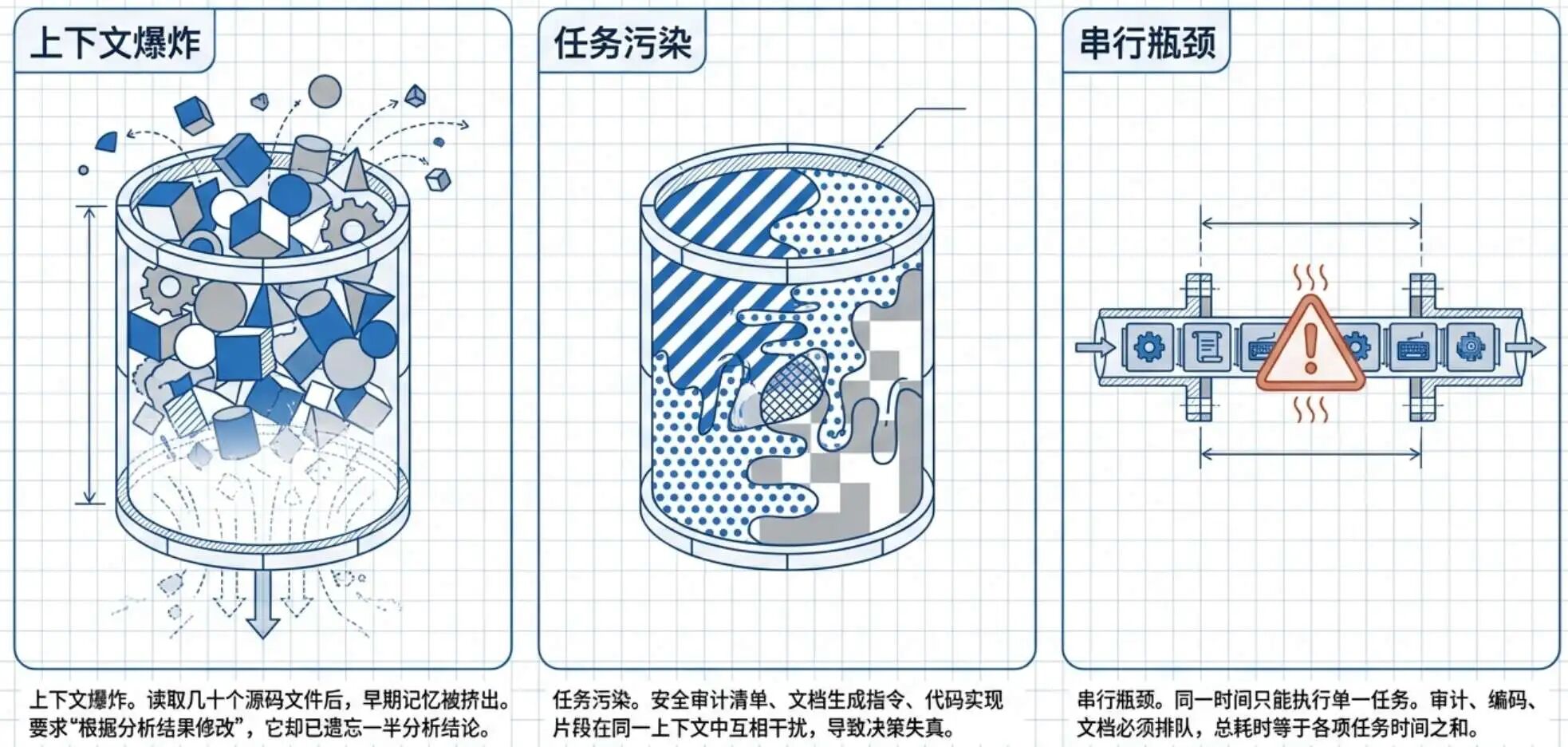
上下文爆炸。读了 30 个文件后,早期读的内容开始被挤出去。你让它"根据刚才的分析结果修改代码",它可能已经忘了分析结果的一半。
任务污染。安全审计的中间思考过程、文档生成的格式化指令、功能实现的代码片段——全部混在同一个上下文里。Claude 在做功能实现的时候,脑子里还飘着安全审计的 OWASP 清单,决策会被干扰。
串行瓶颈。一个会话同一时间只能干一件事。审计完了才能写功能,写完功能才能生成文档。三个任务串行执行,时间直接乘以三。
子代理就是为了解决这些问题而设计的。
1.2 核心价值
子代理提供三个关键能力:
上下文隔离。每个子代理有自己独立的上下文窗口。安全审计代理读了再多文件,也不会挤占功能实现代理的上下文空间。各干各的,互不干扰。
并行执行。多个子代理可以同时运行。你派出三个代理分别做审计、实现、文档,三件事同时进行,总时间取决于最慢的那个,而不是三个的总和。
防止污染。每个子代理有明确的任务边界和工具权限。安全审计代理只能读代码不能改代码,文档代理只能读代码和写 Markdown。权限隔离意味着一个子代理不会意外搞砸另一个子代理的工作。
1.3 子代理 vs 多会话 vs 多实例
这三个概念容易混淆,区别如下:
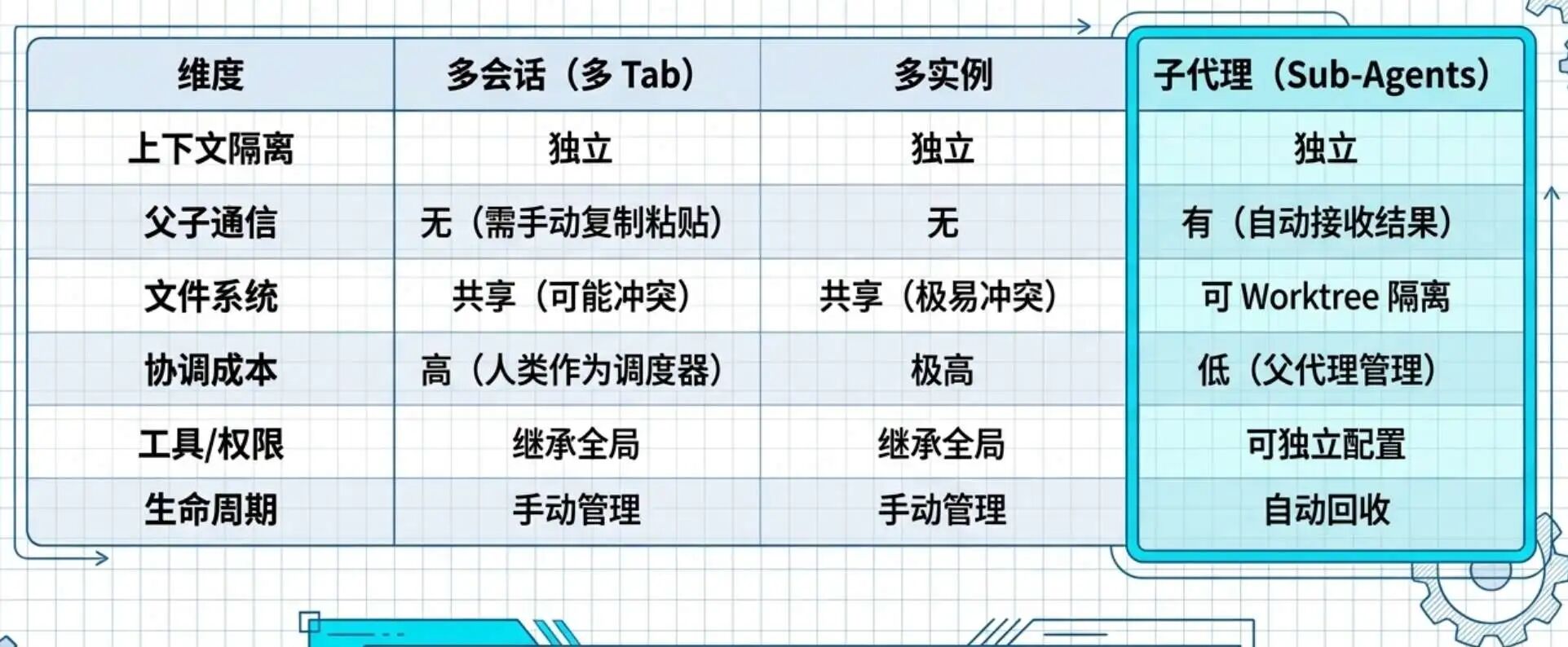
简单说:子代理是"有组织的分身",多会话是"各自为政的克隆人",多实例是"完全独立的平行世界"。
子代理的最大优势在于自动协调——父代理派出子代理,子代理干完活自动把结果交回来,父代理汇总后继续推进。整个过程不需要你手动搬运信息。
2. 内置代理详解
Claude Code 出厂自带四个内置代理,覆盖了最常见的使用场景。
2.1 general-purpose — 通用多步任务
这是最基础的子代理,当 Claude Code 判断需要把一个子任务委派出去时,默认使用的就是它。
特点:
-
继承父代理的模型配置(父代理用 Opus,它也用 Opus)
-
拥有完整的工具集——可以读写文件、执行命令、搜索代码
-
没有特殊的角色设定,就是一个"干活的分身"
典型场景:父代理在做一个复杂重构,发现需要先把某个模块的测试跑通。它会派一个 general-purpose 子代理去"把 tests/unit/auth/ 下的测试全部跑通",自己继续分析其他模块。
2.2 Explore — 快速只读代码库分析
触发方式:描述中包含"探索"、"分析代码库"等意图时自动匹配
特点:
-
使用 Haiku 模型,速度快、成本低
-
工具白名单严格限制为
Read、Grep、Glob——只能看,不能改 -
适合大范围的代码扫描和结构分析
这个代理的设计思路很清晰:代码探索本质上是一个"读多写少"(准确说是"只读")的任务,用高端模型是浪费。Haiku 读文件、搜关键词的能力完全够用,而且速度快很多。
实际用法示例:
"帮我分析一下这个项目的目录结构和主要模块划分"
"找出所有使用了 deprecated API 的文件"
"这个项目的数据库连接是在哪里配置的"
2.3 Plan — 研究型实施规划
触发方式:/plan 命令或描述中包含"制定计划"、"规划方案"等意图
特点:
-
做研究、出方案,但不执行
-
会深入阅读代码、分析依赖关系、评估影响范围
-
输出的是一份结构化的实施计划,交给你或其他代理去执行
这个代理解决的是一个很实际的问题:有时候你只是想知道"如果要做 X,应该怎么做",并不想让 AI 直接动手。比如:
"我想把项目从 REST 迁移到 GraphQL,帮我做个实施计划"
"升级 React 17 到 React 19 需要改哪些东西"
Plan 代理会去读代码、查依赖、分析 breaking changes,最后给你一份步骤清晰的方案。它自己不会去改一行代码。
2.4 claude-code-guide — Claude Code 功能问答
这个代理的作用是回答关于 Claude Code 本身的问题。它内置了 Claude Code 的文档和使用指南。
"claude code 怎么配置 MCP server"
"自定义代理的 YAML 格式是什么"
"/compact 命令有什么参数"
当你不确定某个功能怎么用的时候,问它比翻文档快。
3. 自定义代理创建
内置代理覆盖的是通用场景。真正的威力在于你可以根据自己的需求创建专属代理。
3.1 代理定义文件位置
代理定义文件放在两个地方:
-
.claude/agents/| 项目级 | 跟随项目走,可以提交到 Git,团队共享 -
~/.claude/agents/| 个人级 | 所有项目都可用,个人偏好
文件名就是代理名。比如 .claude/agents/security-reviewer.md 定义了一个名叫 security-reviewer 的代理。
3.2 代理定义文件结构
一个代理定义文件由两部分组成:
-
YAML frontmatter——结构化配置(工具、模型、隔离模式等)
-
Markdown 正文——代理的系统提示词(角色定义、行为指令)
基本骨架长这样:
---
description: "一句话描述这个代理做什么(用于自动匹配)"
tools:
- Read
- Grep
- Glob
model: sonnet
maxTurns: 15
---
# 你是一个 [角色]
你的职责是 [做什么]。
## 工作流程
1. 先做什么
2. 再做什么
3. 最后做什么
## 输出格式
按照以下格式输出结果:
...
YAML frontmatter 定义代理的"能力边界",Markdown 正文定义代理的"行为模式"。两者配合,一个专业的子代理就诞生了。
3.3 配置选项完全参考
下面逐一讲解每个配置项。
tools — 工具白名单/黑名单
控制代理能使用哪些工具。
# 白名单模式——只能使用列出的工具
tools:
- Read
- Grep
- Glob
# 黑名单模式——禁用特定工具(其他都能用)
tools:
- "!Bash"
- "!Write"
白名单适合需要严格限制的场景(比如只读审计),黑名单适合"大部分工具都要用,只是禁掉几个危险的"场景。
常用工具名:Read、Write、Edit、Bash、Grep、Glob、WebSearch、WebFetch。
model — 指定模型
# 指定具体模型
model: haiku # 速度优先,成本低
model: sonnet # 平衡之选
model: opus # 质量优先,成本高
# 不指定——继承父代理的模型
选择策略很简单:
-
纯搜索/扫描任务 → haiku
-
常规编码/分析任务 → sonnet
-
需要深度推理的复杂任务 → opus
effort — 推理深度控制
effort: low # 快速粗略,适合简单任务
effort: medium # 默认级别
effort: high # 深度思考,适合复杂推理
这个参数影响的是模型在每一步的"思考深度"。设为 low 时模型会快速给出答案,设为 high 时模型会花更多时间做推理。配合 model 一起用效果最好——比如 model: opus + effort: high 是最大火力输出。
maxTurns — 最大执行轮数
maxTurns: 10 # 最多执行 10 轮工具调用
这是一个安全阀。防止代理陷入死循环或者做了太多不必要的操作。对于有明确边界的任务(比如审计一个目录),设一个合理的上限能避免不必要的 token 消耗。
isolation: worktree — Git Worktree 隔离
isolation: worktree
这个配置值得单独拿出来说(后面第 5 节详细展开)。简单讲:开启 worktree 隔离后,代理会在一个独立的 Git worktree 中工作,有自己的分支和工作目录。它做的所有文件修改都不会影响你当前的主分支。
适用场景:大规模重构、实验性功能、任何你不确定代理做的修改是否靠谱的情况。
memory — 持久存储
memory: true
开启后,代理可以在 MEMORY.md 中存储和读取持久化信息。这在需要跨会话保持状态的场景下很有用——比如一个代理专门负责某个模块的维护,它可以把上次发现的问题、修改历史等信息存下来,下次启动时自动加载。
background: true — 后台非阻塞执行
background: true
这个配置让代理在后台运行,不阻塞父代理的主流程。父代理派出后台代理后,可以继续做其他事情,后台代理完成后会通知父代理。
典型场景:
父代理:正在做功能实现
├── 派出后台代理 A:跑测试
├── 派出后台代理 B:更新文档
└── 继续写代码...
[后台代理 A 完成] → 测试全通过
[后台代理 B 完成] → 文档已更新
permissionMode — 代理级权限覆盖
permissionMode: auto # 自动批准所有操作
permissionMode: default # 继承父代理的权限设置
对于你完全信任的代理(比如只读审计代理),可以设为 auto 让它自动执行不用每次确认。对于会修改文件的代理,建议保持 default 或更严格的权限。
skills — 预加载技能
skills:
- commit
- review-pr
代理启动时自动加载指定的技能(Skills)。技能是预定义的指令集,类似于给代理预装"知识模块"。
mcpServers — 代理专属 MCP
mcpServers:
- name: my-database
url: "http://localhost:3001"
- name: jira
url: "http://localhost:3002"
为代理配置专属的 MCP(Model Context Protocol)服务器。比如一个数据库管理代理可以连接数据库 MCP,一个项目管理代理可以连接 Jira MCP。不同代理连不同的外部服务,职责清晰。
3.4 优先级链
当多个来源的代理定义冲突时,优先级从高到低:
Policy(组织策略) > CLI 定义 > 项目级 > 用户级 > 插件 > 内置
比如项目级 .claude/agents/ 里有一个 reviewer.md,个人级 ~/.claude/agents/ 里也有一个同名文件。项目级的会覆盖个人级的。再往上,如果组织策略里定义了同名代理,策略的优先级最高。
这个优先级链的设计逻辑是:越具体、越受控的来源优先级越高。
4. 代理调用方式
定义好的代理有多种调用方式。
4.1 自动匹配
Claude Code 会根据你的任务描述自动匹配合适的代理。匹配依据是代理定义中的 description 字段。
# .claude/agents/security-reviewer.md
---
description: "安全审计,检查代码中的安全漏洞和风险"
---
当你说"帮我检查这个项目有没有安全漏洞"时,Claude Code 看到关键词"安全"、“漏洞”,会自动匹配到这个代理并调用它。
自动匹配是最"无感"的调用方式,但也最不可控。如果你有多个描述相近的代理,自动匹配可能选错。
4.2 显式调用
用 @ 语法直接指定代理:
@security-reviewer 检查 src/auth/ 目录的代码安全性
这种方式最明确——就是要用这个代理,没有歧义。
4.3 自然语言调用
在对话中明确提到代理名称:
"使用 security-reviewer 代理审查 src/api/ 下所有的接口"
"让 implementation-agent 在独立分支上实现用户注册功能"
"用文档代理更新一下 API 参考文档"
Claude Code 能从自然语言中识别出你想调用的代理。
4.4 CLI 启动
直接用命令行参数启动一个代理作为整个会话的主角色:
claude --agent security-reviewer
这种方式下,整个会话都由指定代理控制。适合单一用途的场景——比如你就想做一次安全审计,从头到尾都用安全审计代理。
4.5 列出所有可用代理
claude agents
这个命令会列出所有可用的代理(内置 + 项目级 + 个人级),包括名称和描述。当你忘了某个代理叫什么名字时,这个命令能救急。
5. Git Worktree 隔离
5.1 工作原理
Git worktree 是 Git 的原生功能——允许在同一个仓库下创建多个工作目录,每个目录关联一个不同的分支。Claude Code 的 worktree 隔离就是利用了这个机制。
当一个配置了 isolation: worktree 的代理启动时:
-
Claude Code 调用
git worktree add在临时目录下创建一个新的工作树 -
自动创建一个新分支(通常命名为
agent/<agent-name>/<timestamp>之类的格式) -
代理在这个独立的工作目录中执行所有操作
-
代理完成后,结果留在那个分支上,主分支完全不受影响
整个过程对你来说是透明的——你不需要手动管理 worktree,代理启动时自动创建,完成后你决定怎么处理。
5.2 优势
主分支安全。代理做的所有修改——不管是写得好的代码还是写崩了的代码——都在独立分支上。你的 main 分支纹丝不动。
可安全实验。你可以让代理尝试一些激进的重构方案。方案好就合并,不好就直接丢掉分支,零成本。
并行不冲突。多个 worktree 隔离的代理可以同时工作,各自在自己的分支上改文件,不会出现文件冲突。
5.3 完成后处理
代理完成后,你有三种选择:
审查并合并:
# 查看代理做了什么
git diff main..agent/implementation/20260502
# 满意的话合并
git merge agent/implementation/20260502
Cherry-pick 部分提交:
# 只要其中几个提交
git cherry-pick abc123 def456
丢弃:
# 不满意,直接删掉
git worktree remove /path/to/worktree
git branch -D agent/implementation/20260502
5.4 实际场景
大规模重构:让代理在独立分支上把整个项目从 CommonJS 迁移到 ESM。迁移完了你审查一下,没问题就合并,有问题就丢掉让它重来。
实验性功能:让代理在独立分支上实现一个新的认证方案。你可以同时让另一个代理实现另一种方案,最后比较两个分支的代码,选更好的那个。
破坏性操作:比如"删掉所有 deprecated 的 API 端点并更新调用方"。这种操作影响面大,在 worktree 里做比在主分支上做安全得多。
6. 实战:创建 2 个自定义代理
下面给出三个完整的代理定义文件,涵盖了不同的使用模式。
6.1 Security Reviewer — 安全审计专家
文件位置:.claude/agents/security-reviewer.md
---
description: "代码安全审计,检查安全漏洞、敏感信息泄露、注入风险等"
tools:
- Read
- Grep
- Glob
model: sonnet
effort: high
maxTurns: 30
---
# 安全审计代理
你是一个专注于代码安全审计的专家代理。你的任务是对指定的代码范围进行全面的安全检查。
## 审计清单(基于 OWASP Top 10 2021)
### A01: 访问控制失效
- 检查 API 端点是否有适当的权限校验
- 寻找 IDOR(不安全的直接对象引用)漏洞
- 检查是否存在路径穿越风险
- 验证角色/权限检查是否在每个需要的地方都存在
### A02: 加密失败
- 检查敏感数据(密码、token、密钥)是否明文存储
- 查找硬编码的密钥、API key、密码
- 验证密码是否使用了安全的哈希算法(bcrypt/scrypt/argon2)
- 检查 HTTPS/TLS 配置
### A03: 注入
- SQL 注入:查找字符串拼接 SQL 的代码
- XSS:检查用户输入是否未经转义直接输出到 HTML
- 命令注入:查找 shell 命令拼接
- LDAP/XML/NoSQL 注入风险
### A04: 不安全的设计
- 检查业务逻辑中的竞态条件
- 验证重要操作是否有速率限制
- 检查是否缺少 CSRF 防护
### A05: 安全配置错误
- 查找 DEBUG 模式在生产环境中开启的风险
- 检查默认凭据
- 验证 CORS 配置是否过于宽松
- 检查错误处理是否泄露敏感信息(堆栈跟踪、数据库信息)
### A06-A10: 其他风险
- 过时的依赖组件(检查 package.json/requirements.txt)
- 认证和会话管理缺陷
- 数据完整性校验
- 日志和监控不足
- SSRF(服务端请求伪造)
## 工作流程
1. 先用 Glob 获取目标范围内的文件列表
2. 用 Grep 快速扫描常见的安全模式(如 `eval(`、`exec(`、`password`、`secret`、`api_key`)
3. 用 Read 逐个检查可疑文件的完整上下文
4. 按严重程度分类输出结果
## 输出格式
按以下格式输出审计报告:
### 🔴 严重(Critical)
[需要立即修复的漏洞]
### 🟠 高危(High)
[应尽快修复的风险]
### 🟡 中危(Medium)
[建议修复的问题]
### 🔵 低危(Low)
[最佳实践建议]
每个发现包含:
- **文件**:具体文件路径和行号
- **问题**:一句话描述
- **风险**:可能导致什么后果
- **修复建议**:具体的修复方案
这个代理的关键设计决策:
-
工具只给了 Read/Grep/Glob——审计代理不应该有修改代码的权限。它的职责是发现问题,不是修复问题。
-
model: sonnet + effort: high——安全审计需要一定的推理能力(理解业务逻辑才能发现逻辑漏洞),但不需要 Opus 级别的成本。Sonnet 配合高推理深度是性价比最优解。
-
maxTurns: 30——安全审计需要读很多文件,30 轮工具调用给了足够的空间。
6.2 Documentation Agent — 文档生成代理
文件位置:.claude/agents/doc-generator.md
---
description: "分析代码结构并生成或更新 API 文档、模块文档"
tools:
- Read
- Grep
- Glob
- Write
- Edit
model: sonnet
effort: medium
maxTurns: 40
---
# 文档生成代理
你是一个技术文档生成代理,负责分析代码并生成准确、实用的技术文档。
## 核心原则
1. **准确性第一**。文档必须与代码实际行为一致。不确定的地方宁可标注"待确认"也不要瞎编。
2. **示例驱动**。每个 API、函数、类都应该有使用示例。没有示例的文档是半成品。
3. **面向使用者**。文档的读者是要使用这些 API 的开发者,不是写这些 API 的人。关注"怎么用"而不是"怎么实现的"。
## 文档类型
### API 参考文档
对于每个公开的 API 端点/函数/类,记录:
- 功能描述(一句话)
- 参数列表(名称、类型、是否必须、默认值、说明)
- 返回值(类型、结构、可能的值)
- 错误情况(什么条件下会抛出什么错误)
- 使用示例(至少一个基本用法 + 一个高级用法)
### 模块概览文档
对于每个主要模块/包,记录:
- 模块职责(这个模块干什么的)
- 对外暴露的接口
- 与其他模块的依赖关系
- 核心概念和术语解释
## 工作流程
1. 用 Glob 扫描目标范围内的所有源码文件
2. 用 Grep 查找公开接口(export、public、装饰器等)
3. 用 Read 阅读每个接口的完整实现
4. 生成文档内容
5. 如果已有文档文件,用 Edit 更新;如果没有,用 Write 创建
## 输出格式
使用 Markdown 格式,结构如下:
# 模块名
> 一句话描述
## 安装/引入
## 快速开始
## API 参考
### function_name(param1, param2)
描述...
**参数:**
| 名称 | 类型 | 必须 | 默认值 | 说明 |
|------|------|------|--------|------|
**返回值:**
**示例:**
## 常见问题
这个代理比安全审计代理多了 Write 和 Edit 工具——因为它需要生成文档文件。但注意它没有 Bash,不能执行任意命令。这是一个合理的权限边界:文档代理只需要读代码、写 Markdown。
7. 代理间通信与协调
当你使用多个子代理时,它们之间的通信和协调是一个关键话题。
7.1 父子代理的信息传递
父代理和子代理之间的通信遵循一个简单的模式:
下行(父 → 子):父代理在创建子代理时传递任务描述。这个描述是子代理的全部输入——它不能访问父代理的上下文历史,只能看到父代理明确传给它的信息。
父代理心里想的:
"用户要我做一个完整的代码审查。我先让安全审计代理去查安全问题。"
父代理传给子代理的:
"对 src/api/ 目录下所有文件进行安全审计,重点关注认证和授权相关的代码。
项目使用 Express.js + TypeScript,认证方案是 JWT。"
这意味着父代理在派发任务时,需要把必要的上下文信息提炼出来一并传递。子代理不会"自动继承"父代理读过的文件内容。
上行(子 → 父):子代理完成任务后,把结果返回给父代理。返回的内容就是子代理的最终输出文本。父代理拿到后,可以继续基于这个结果做下一步决策。
子代理返回:
"审计完成。发现 3 个高危问题:
1. src/api/users.ts:45 — SQL 注入风险
2. src/api/auth.ts:78 — JWT 密钥硬编码
3. src/api/upload.ts:23 — 文件上传没有类型校验"
父代理收到后:
"好的,有 3 个高危问题。我现在让 implementation-agent 去修复这些问题。"
7.2 后台代理的结果回收
后台代理(background: true)的结果回收是异步的。
时间线:
t0: 父代理派出后台代理 A(跑测试)
t1: 父代理派出后台代理 B(更新文档)
t2: 父代理自己继续写代码
t3: 后台代理 B 完成 → 结果进入待处理队列
t4: 后台代理 A 完成 → 结果进入待处理队列
t5: 父代理在合适的时机处理队列中的结果
父代理不会被后台代理阻塞。它可以在任何时候检查后台代理的状态:
-
代理还在跑 → 继续干自己的事
-
代理已完成 → 读取结果并处理
-
代理出错 → 获取错误信息并决定是否重试
这种异步模式特别适合"派出去做耗时任务,自己不用干等着"的场景。
7.3 多代理输出的合并策略
当多个代理并行完成后,父代理需要合并它们的输出。这里没有自动的合并机制——合并逻辑完全由父代理(或者你)来决定。
补充型合并:多个代理分别负责不同的方面,结果直接拼起来。比如安全审计报告 + 性能分析报告 + 代码质量报告,三份报告合在一起就是完整的代码审查结果。
冲突型合并:多个代理对同一段代码做了不同的修改。这种情况下需要人工介入判断,或者让父代理基于所有修改做一个综合决策。
如果用了 worktree 隔离,冲突型合并就变成了 Git 分支合并问题——用标准的 git merge 或 git rebase 流程处理。
筛选型合并:多个代理做同一个任务(比如让两个代理分别实现同一个功能),选结果更好的那个。这种模式成本高但质量也高,适合关键功能的开发。
实际工作流示例
把上面的知识串起来,看一个完整的工作流。
假设你要给一个 Express.js 项目添加"用户注册"功能:
你:"添加用户注册功能,要包含邮箱验证"
Claude Code(父代理):
1. 先派出 Explore 代理 → 快速扫描项目结构,了解现有的认证模块、数据库模型、路由组织方式
2. 基于探索结果,派出 Plan 代理 → 制定实施方案(需要改哪些文件、添加哪些端点、邮件服务怎么集成)
3. 把方案展示给你确认
4. 你确认后,派出 implementation-agent(worktree 隔离)→ 在独立分支上实现功能
5. 同时派出 security-reviewer(后台)→ 对新写的代码做安全审计
6. implementation-agent 完成 → 父代理报告分支名和改动摘要
7. security-reviewer 完成 → 父代理报告安全审计结果
8. 如果有安全问题,让 implementation-agent 修复
9. 最后派出 doc-generator → 更新 API 文档
10. 所有子代理完成,父代理给你一个完整的总结
整个过程中,你只说了一句话。Claude Code 自动拆分任务、调度子代理、汇总结果。这就是子代理系统的核心价值——让 AI 自己管理 AI。
小结
子代理系统的本质是任务分解 + 并行执行 + 结果汇总。通过给每个子任务分配独立的上下文、独立的工具权限、甚至独立的 Git 分支,把一个复杂的大任务拆成多个简单的小任务并行处理。
几个实操建议:
-
从内置代理开始。Explore 和 Plan 已经覆盖了大部分场景,先用熟了再考虑自定义。
-
权限最小化。给代理的工具权限尽量少——不需要写文件的代理就不给 Write,不需要执行命令的就不给 Bash。
-
worktree 隔离用在"不确定"的场景。任何你觉得代理可能改出问题的任务,都用 worktree 隔离。成本几乎为零,但能避免很多麻烦。
-
maxTurns 要设合理。太小了代理干不完活,太大了浪费 token。根据任务复杂度调整——简单搜索 10 轮够了,功能实现可能需要 40-50 轮。
-
description 写准确。自动匹配的准确率完全取决于 description 写得好不好。用具体的关键词,不要写空泛的描述。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 46
46 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)