当知识有了‘关系网‘:LightRAG如何让大模型‘秒懂‘你的文档?
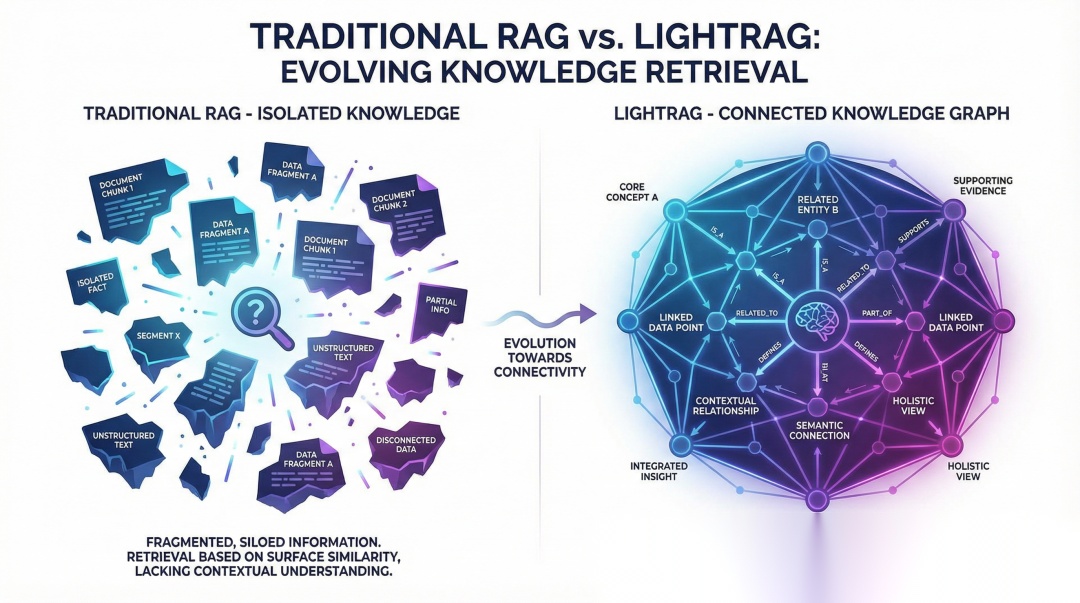
想象一下,你有一座藏书万卷的图书馆,但你找书的方式只有一种——记住每本书某个页面的关键词,然后靠"猜"来定位。
这,就是传统RAG系统的尴尬处境。
今天要介绍的这个开源项目LightRAG,被顶会EMNLP 2025接收。它用一种"给知识画关系图"的思路,彻底改变了检索增强生成的玩法。
一、从"关键词搜索"到"关系图谱":一次认知升级
传统RAG的"碎片化"困境
我们先来做个思想实验。
假设你的知识库里有一篇文章讲的是"林黛玉、薛宝钗、贾宝玉三人的关系如何影响了大观园的命运"。现在用户问:
“《红楼梦》中,林黛玉和薛宝钗的关系是如何影响林黛玉最终命运的?”
传统RAG会怎么回答?它可能会分别找到这几个碎片:
- “林黛玉性格敏感多疑”
- “薛宝钗出身名门、性格稳重”
- “林黛玉最终病逝于潇湘馆”
然后把这些碎片一股脑丢给大模型,让它自己"拼"出答案。
问题来了:大模型根本不知道这三者之间有什么关联,它只能靠"感觉"来拼凑。就像给你一堆拼图碎片,却没有原图参考——你可能拼出正确图案,也可能拼出一团乱麻。
LightRAG的解决思路:给知识画张"关系网"
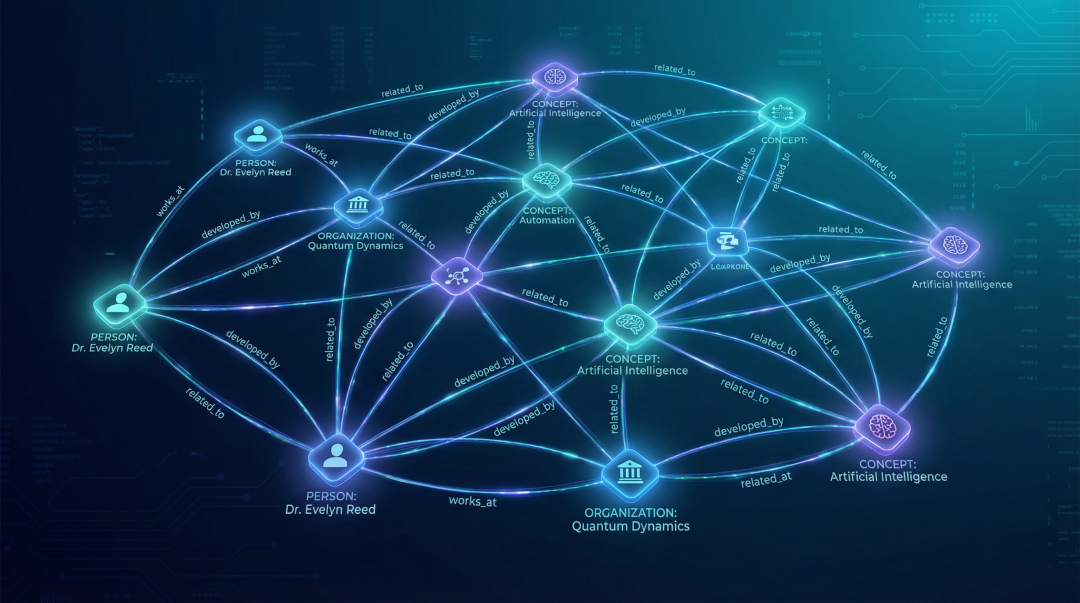
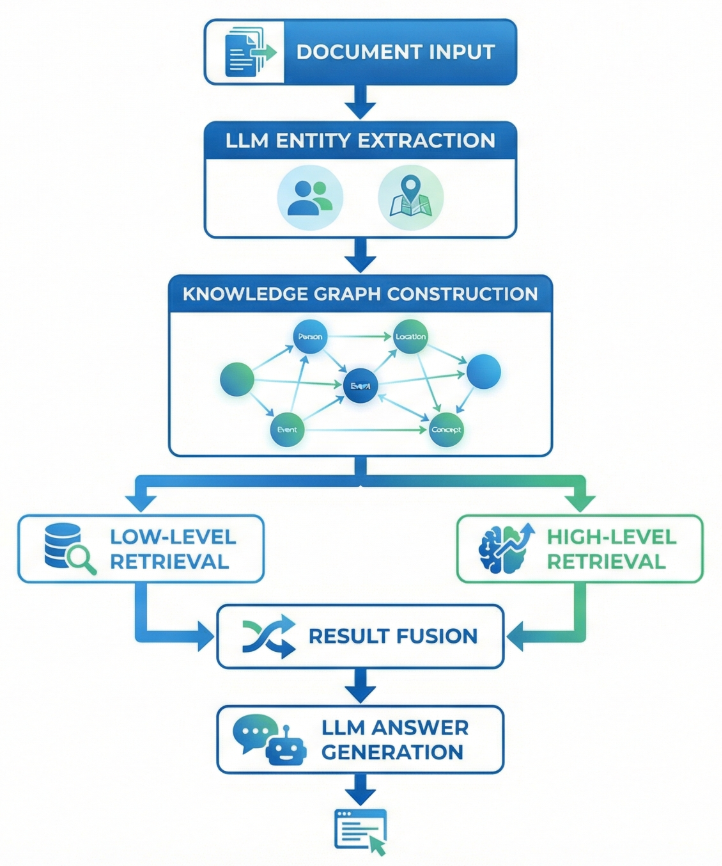
LightRAG的核心创新,就是先用大模型从文档中抽取出"实体"和"关系",然后构建一张知识图谱。
还是刚才那个例子。LightRAG会提取出:
实体节点:
- 林黛玉
- 薛宝钗
- 贾宝玉
- 潇湘馆
关系边:
- 林黛玉 ←姐妹关系→ 薛宝钗
- 林黛玉 ←相爱→ 贾宝玉
- 薛宝钗 ←寄居→ 贾府
- 林黛玉 ←结局→ 病逝潇湘馆
这下,当用户提问时,系统就能"顺着关系网"找到答案的完整路径:姐妹关系紧张 → 与宝玉的爱情受阻 → 身心俱疲 → 悲剧结局。
这就是LightRAG所谓的Graph-Enhanced(图增强)——让知识不再是孤立的碎片,而是一张有结构、有脉络的关系网。
二、LightRAG的两大核心"黑科技"
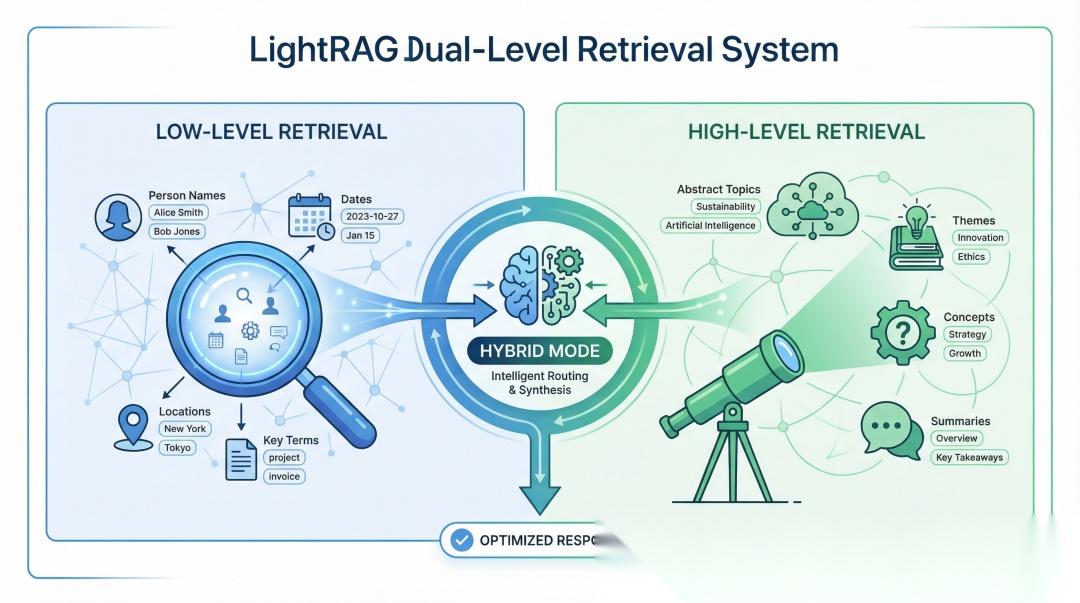
黑科技1:双层级检索——既见树木,又见森林
如果只是建了知识图谱,LightRAG还不算特别出彩。它的另一个杀手锏是双层级检索机制。
什么意思呢?这里有个精妙的类比:
低层级检索像是"查户口",专门找某个具体的人/事/物;高层级检索像是"做调研",了解某个主题的全貌和趋势。
举个例子:
| 问题类型 | 低层级检索 | 高层级检索 |
|---|---|---|
| “谁是《傲慢与偏见》的作者?” | ✅ 精准定位到"简·奥斯汀"这个实体 | ❌ 太笼统 |
| “AI如何改变现代教育?” | ❌ 找不到单一答案 | ✅ 综合多个AI+教育相关实体和关系 |
| “特斯拉被马斯克收购后,股价怎么变的?” | ✅ 找到特斯拉、马斯克、股价等实体 | ✅ 还需要理解"收购→股价变化"这条关系链 |
LightRAG的聪明之处在于:它能自动判断问题属于哪种类型,然后智能切换或组合两种检索模式。
论文中的消融实验也证明了这一点:
- 只用低层级检索:复杂问题回答不全面,过于关注细节
- 只用高层级检索:广度够了,但深度不足
- 两者结合:全面性和准确性达到最优平衡
黑科技2:增量更新——知识库的"热插拔"
用过传统RAG系统的朋友可能有过这种体验:知识库要更新几条内容?好,等我重新索引一下…两三个小时后见。
这对于需要频繁更新内容的场景(比如新闻资讯、实时财报、产品文档)是致命的。
LightRAG的第三个核心设计就是增量更新算法——新增内容只需要"挂载"到已有的知识图谱上,不需要重建整个索引。
打个比方:传统方案像是给一本书加章节,需要重印整本书;LightRAG则像是用活页夹,加几页纸就够了。

三、实测效果:LightRAG到底强在哪?
研究团队在多个数据集上进行了对比实验,包括农业、法律、计算机科学等领域。
评估维度
大语言模型会从三个维度打分:
- 全面性(Comprehensiveness):答案是否覆盖了问题的各个方面?
- 多样性(Diversity):答案内容是否丰富、视角是否多元?
- 赋能性(Empowerment):答案是否有助于用户深入理解问题?
实验结果一览
以法律数据集为例:
| 指标 | LightRAG | GraphRAG | HyDE | NaiveRAG |
|---|---|---|---|---|
| 全面性 | 83.6% | 76.4% | 70.0% | 62.4% |
| 多样性 | 86.4% | 79.2% | 73.2% | 65.2% |
| 赋能性 | 83.6% | 76.4% | 70.0% | 62.4% |
LightRAG在所有维度上都显著领先。尤其在多样性方面,提升幅度高达32%。
成本对比:省的不只是钱
除了效果提升,LightRAG在Token消耗和API调用次数上也大幅优化:
- 索引阶段Token开销:显著低于GraphRAG
- API调用次数:Cextract指标大幅降低
对于需要处理海量文档的企业来说,这省下的可是真金白银。
四、15分钟上手
说了这么多技术原理,你可能想知道:这玩意儿用起来复杂吗?
答案:超级简单。
安装
pip install lightrag-hku
基础使用
import asyncio
from lightrag import LightRAG, QueryParam
from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed
# 初始化
rag=LightRAG(
working_dir="./rag_storage",
embedding_func=openai_embed,
llm_model_func=gpt_4o_mini_complete,
)
# 初始化存储
await rag.initialize_storages()
# 插入文档
await rag.ainsert("""
LightRAG是香港大学开发的新一代检索增强生成系统。
它通过图结构索引和双层级检索,
显著提升了RAG的上下文感知能力。
""")
# 查询
result=await rag.aquery(
"LightRAG的核心创新是什么?",
param=QueryParam(mode="hybrid")
)
print(result)
查询模式选择指南
LightRAG 支持6种查询模式,适用于不同的业务场景:
| 模式 | 检索方式 | 适用场景 | 示例问题 |
|---|---|---|---|
hybrid |
局部 + 全局混合检索 | 复杂综合问题 | “分析特斯拉收购推特后对新能源汽车行业的影响” |
local |
低层级检索,关注具体实体 | 细节导向问题,关联上下文信息 | “谁写了《傲慢与偏见》?他/她还有什么代表作?” |
global |
高层级检索,遍历知识图谱 | 需要全局视野的综述类问题 | “AI技术如何改变现代教育体系?” |
mix |
知识图谱 + 向量双重检索 | 深度推理任务,整合双重优势 | “马斯克收购推特事件与特斯拉股价变化有何关联?” |
naive |
基础向量相似度检索 | 简单的事实问答,快速响应 | “今天北京的天气怎么样?” |
bypass |
直接 LLM 生成,无检索 | 测试/调试/完全信任 LLM 能力 | “用你自己的知识回答…” |
总结:
- 不确定用什么?复杂综合问题 选
hybrid——它会自动平衡局部细节和全局视野 - 问具体事实?细节追问 选
local——精准定位实体和关系 - 问趋势综述?需要全局视野 选
global——遍历整个知识图谱找答案 - 需要深度推理?选
mix——图谱和向量双重保险

五、适合哪些场景?
LightRAG特别适合以下场景:
| 应用领域 | 具体场景 |
|---|---|
| 企业知识库 | 内部Wiki检索、员工手册问答 |
| 法律文书 | 法条解读、案例匹配 |
| 医疗文献 | 病历分析、药物相互作用 |
| 金融报告 | 财报问答、市场分析 |
| 客服系统 | 多轮对话、复杂咨询 |
简单来说,只要你的业务涉及大量文档的智能问答,LightRAG都值得一试。
六、模块化存储:想用什么数据库都行
LightRAG采用了非常灵活的四层存储架构:
- KV存储:支持SQLite、PostgreSQL、Redis、MongoDB、OpenSearch
- 向量存储:支持Chroma、Milvus、Faiss、Qdrant、PGVector
- 图存储:支持NetworkX、Neo4j、PostgreSQL图扩展
- 文档状态:跟踪文档索引状态
这意味着:
- 快速原型:用内置的SQLite和NetworkX,几分钟就能跑起来
- 生产部署:换成Neo4j + Milvus,企业级稳定性

七、总结
LightRAG通过三个核心创新,解决了传统RAG的三大痛点:
🕸️ 图结构索引 → 解决"知识孤岛"问题
🔄 双层级检索 → 兼顾"细节"与"全局"
⚡ 增量更新 → 告别"重建索引"的噩梦
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)