Gated DeltaNet 线性注意力:揭秘大模型算力魔咒的破局之道!
文章深入探讨了线性注意力机制在大模型中的重要性,特别是Gated DeltaNet如何通过改变运算顺序,将Transformer的注意力计算复杂度从平方级降低到线性级,从而打破算力瓶颈。文中对比了阿里Qwen、Kimi Linear等模型的线性架构应用,以及MiniMax的转向,并详细解析了从Softmax Attention的局限到Gated DeltaNet的演进过程,揭示了其在保持高性能的同时降低计算需求的潜力。
芳树无人花自落,春山一路鸟空啼。小伙伴们好,我是"小窗幽记机器学习"的小编卖铁观音的小男孩。纵观近期爆发的开源大模型潮,一条隐秘的底层暗线已然浮出水面:以 Gated DeltaNet 为代表的线性注意力(Linear Attention),正在迅速“夺权”。
阿里系率先扛旗。从去年的 Qwen-next 到不久前发布的 Qwen 3.5,彻底告别纯全局注意力,杀入 3:1 混合架构(3 层 Gated DeltaNet + 1 层标准 Attention)。凭借近乎线性的复杂度,Qwen 硬生生把超长上下文塞进了消费级显卡的极限。
月之暗面紧随其后。去年底重磅发布的 Kimi Linear,同样以 Gated DeltaNet 为底座,甚至将其魔改到了极度精细的“特征通道级遗忘(Channel-wise KDA)”。他们向世人宣告:要支撑百万级 Token,线性模型也能拥有媲美 Full Attention 的变态级检索精度。
然而,就在阿里与Kimi高歌猛进之时,却有人突然紧急“跳车”。
曾经的“线性急先锋” MiniMax,曾激进地用 7:1 的闪电注意力(Lightning Attention)死磕百万 Token;却在最新的 M2 与 M2.5 版本中上演了极致的改旗易帜——出人意料地彻底抛弃线性架构,全面退回传统的纯 Softmax 多头注意力。为此,官方还专门写了一篇博客进行说明,感兴趣的小伙伴可以前往围观。
巨头们的激进与反水,将一个巨大的悬念直接拍在桌面上:线性注意力,究竟是打破 算力魔咒的终极解药,还是极度难以调教的“炼金术”?
接下来,本文将带你从 Softmax 的历史死局出发,一路推演到 RNN 架构,最终揭开当下最硬核的终极形态——Gated DeltaNet。
全局符号约定
为了推导清晰,我们先统一以下符号:
- :序列长度(Sequence Length)。
- :隐藏层特征维度(Hidden Dimension)。
- :注意力机制中的 Query, Key, Value 矩阵。
- :代表第 个 Token 对应的查询、键、值列向量。
- :代表第 步的输出列向量。
第一步:Softmax Attention 的“死局”
在深入枯燥的数学推导前,我们需要建立一个直观的“上帝视角”:Transformer 为什么会慢?
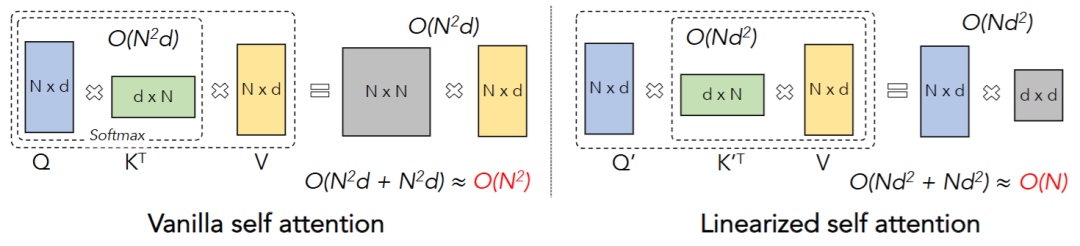
本质上,是因为标准注意力计算过程选择了 的运算顺序。由于 先计算出了一个 的 Attention Map,这正是导致显存与计算量随序列长度 二次方()增长的元凶。尽管像 FlashAttention 这样的工程优化显著降低了显存读写压力,但并没有改变其平方级的计算复杂度底色。
线性注意力的核心直觉,就是利用矩阵乘法的结合律“偷天换日”,将运算顺序强行调整为 :
- 计算顺序变更:不再计算完整的 矩阵,而是先计算 (直接得到一个极小的 状态矩阵),再让 Query 与这个状态相乘。
- 复杂度剧变:由于特征维度 通常远小于序列长度 (例如 而 ),计算量瞬间从与 相关降为与 线性相关,从而彻底打破了 的魔咒。
那么,这种“改变乘法顺序”的操作,在数学公式上到底该如何严谨地实现呢?我们从标准的因果注意力公式切入。
标准的因果注意力(Causal Attention)计算第 个 token 的输出 ,公式是计算 与历史所有 的内积,经过 Softmax 得到权重,再对 加权求和:
瓶颈在哪里? 为了算出全局的输出 ,模型在底层必须执行 矩阵乘法,计算出一个 的庞大 Attention Map 矩阵,再对其做指数运算 。空间和时间复杂度死死卡在 。当 极长时,显存直接撑爆。
第二步:破局——去掉 Softmax,化身线性 RNN
为了打破 的魔咒,最早的 Linear Attention 提出了最暴力的解法:直接干掉公式里的 函数和归一化分母(或者用其他线性函数替代)。
去掉 后,第 步的输出公式简化为:
在数学中,标量与向量相乘满足交换律。
- 的结果是一个标量(比如数值 )。
- 是一个向量(比如维度为 的列向量)。
所以:
因此,调整一下顺序:
注意,因为向量内积满足交换律,即 ,我们将其改写为:
核心魔法开始:标量与矩阵的结合律变换
在上述公式中, 是 的行向量, 是 的列向量,两者的乘积 是一个标量(一个具体的数字)。 把一个数字乘在向量 上,相当于对 进行了缩放。根据线性代数结合律,我们可以改变括号的位置:
这里的性质发生了奇妙的变化: 是 的列向量, 是 的行向量。两者相乘 变成了一个 的矩阵!
把这个变换代回求和公式,并且由于对 求和的过程中, 是不随 变化的常数向量,我们可以把 整体提取到求和符号的外面:
现在,我们令括号里的这堆东西为状态矩阵 :
我们惊喜地发现,这个 居然可以通过加上当前步的 递归得来!于是我们得到了最基础的线性 RNN 形式:
为什么说复杂度变成了线性?在推理(生成)时,我们不需要像传统 Transformer 那样保存所有过去的 和 (即大家所熟悉的 KV Cache),我们只需要维护一个固定大小的 矩阵 。每输入一个新的 token,只做一次外积 并加到 上即可,每步计算量是 ,处理 个 token 的总复杂度变成了 ,成功实现了与 的线性关系!
第三步:引入遗忘机制(RetNet 的雏形)
基础版本 有一个致命缺陷:随着序列越来越长, 是无数个 的等权重无脑累加。旧的信息和新的信息混杂在一起,导致模型产生“记忆模糊”。
为了符合语言模型“就近原则”(最近的词通常对当前预测更重要),学者们给隐状态的更新加上了一个遗忘因子(衰减因子) ,其中 。 公式进化为:
这样一来,经过多步迭代,早期的记忆会被 不断衰减,模型就能保持对近期上下文的高分辨率。
第四步:从“测试时训练 (TTT)”视角推导 DeltaNet
学术界并不满足于人工硬凑出一个衰减因子。近年来的 Test-Time Training (TTT) 理论提出了一种降维打击般的理解思路: RNN 的本质,其实就是一个把历史序列 压缩成模型权重 的在线学习(Online Learning)过程!
我们把 想象成一个小小的线性回归模型的“参数矩阵”,输入是 ,我们希望模型能精准预测出对应的 。即:
预测值
既然是预测,就该有损失函数。最经典的回归损失就是均方误差(MSE):
接下来,我们就像训练神经网络一样,用梯度下降(SGD) 来更新参数 。 对上述损失函数 求关于参数 的梯度:
(注:这里应用了矩阵求导法则,标量对矩阵的导数。直观理解:误差 输入的转置。至于详细的推导见文章尾部的补充)
根据梯度下降法则,用旧参数减去梯度更新新参数(假设学习率 ):
把括号展开:
提取公因式 ,我们就得到了著名的 DeltaNet 更新法则:
公式解读:什么是 Delta Rule (除旧迎新)?
- 除旧: 的作用是把 中关于当前特征 的旧认知“擦除”掉。
- 迎新: 则是强行把新的特征映射关系写进状态矩阵里。 这种基于梯度的更新法则,比简单的相加()具备了更精准、更有目的性的“状态追踪”能力。
补遗与启发:Mamba 的高光与遗憾
在学术界推演 Delta Rule 的同时,另一条基于状态空间模型(SSM)的路线诞生了耀眼的明星——Mamba。 Mamba 向世界证明了一件事:RetNet 那种固定的常数衰减率 是不够的,真正强大的是与输入数据相关的动态遗忘门(Data-dependent Decay, )——遇到没用的废话就疯狂遗忘,遇到关键信息就牢牢记住。 但 Mamba 也有其局限性,其初代非外积的形式难以把 GPU 的矩阵乘法算力榨干(直至 Mamba2 才向线性 Attention 的外积形式妥协),且它依旧没有解决“精准状态追踪”的问题。 这引发了学者们的终极思考:如果我们把 Mamba 引以为傲的“动态门控()”,与 DeltaNet 极其科学的“除旧迎新(Delta Rule)”结合起来,再加上 GPU 高效的外积并行形式,会发生什么?
于是,大一统——Gated DeltaNet 诞生了!
第五步:大一统——Gated DeltaNet 的诞生
既然遗忘门(衰减因子 )对语言模型有效,而 Delta Rule 对状态更新更加科学,那能不能把它们两者结合起来? 答案是肯定的,这就是最终的 Gated DeltaNet。
我们在 DeltaNet 的梯度下降更新公式中,引入两个动态标量门控:
- 数据依赖的衰减因子 :用来控制对全局过去状态 的保留程度(相当于带权重的记忆衰减)。
- 动态学习率 :用来控制当前步“除旧迎新”特征的更新力度。
将其代入我们第四步推导的梯度下降法:
为了符号好看,我们将减号吃进括号里换位:
至此,我们就成功推演出了 Gated DeltaNet 的终极 RNN 更新形式。
(补充说明:在某些论文中,你可能会看到它的形式写成 。别慌,如果你把这个式子展开,并令 以及 ,再将 进行简单的系数缩放替代,就会发现它在数学本质上跟我们推导出来的公式是完全等价的,只是套了一层不同的马甲而已。)
总结归纳
- 起点:为了消灭 复杂度,去掉了 Softmax 非线性枷锁。
- 第一形态 (Linear RNN) :通过提取公因式,实现了 ,。
- 第二形态 (RetNet) :为了防止记忆混浊,加上了常数衰减率 。
- 第三形态 (DeltaNet) :从在线学习视角出发,使用 MSE 损失求导,推导出了“除旧迎新”的 Delta Rule。
- 终极形态 (Gated DeltaNet) :融合了动态衰减与 Delta Rule,成为了当下线性 Transformer 领域的性能霸主。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献150条内容
已为社区贡献150条内容

所有评论(0)