人机交互——C++
引言:
C++一门重要的语言。
C++ 是一种静态类型的、编译式的、通用的、大小写敏感的、不规则的编程语言,支持过程化编程、面向对象编程和泛型编程。
C++ 被认为是一种中级语言,它综合了高级语言和低级语言的特点。

第一阶段:C++基础入门
第一章:数据类型、运算符与表达式
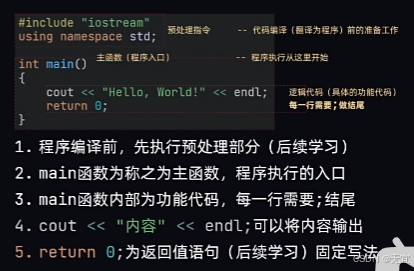
1、C++基本结构
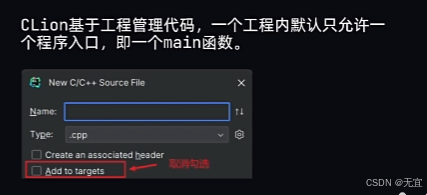
2、单工程多main函数
3、手动编译C++代码
利用MinGW-w64软件;

4、cout打印输出
cout <<...<<...<<...<<endl(换行)
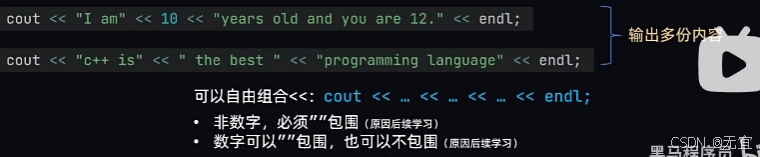
在 cout 语句中,字符串需要用双引号括起来;字符用单引号括起来;其他数据类型(如整数、浮点数等)可以直接使用,不需要加引号。

5、字面常量

6、标识符与关键词
变量的命名即标识符,不能作为标识符的即关键词;

7、符号常量

8、变量的基础使用


9、变量的特征

10、变量的快速定义

11、标识符的限制规则:

12、数据类型(整型)

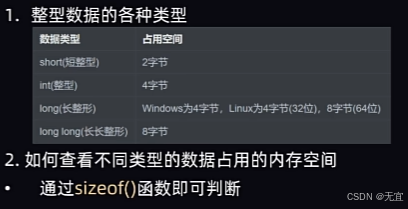
13、有符号和无符号的数字
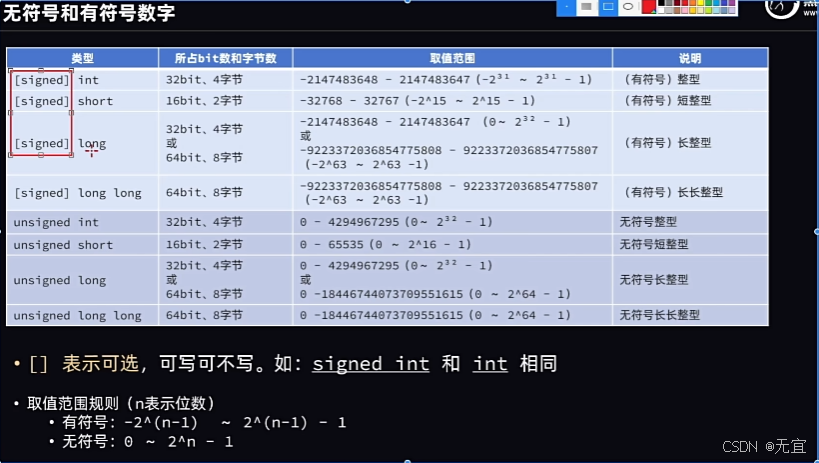
其中unsigned必须写,并且代表无符号,只有正的;signed可写可不写,有符号,有正有负;
同时可简写,即unsigned int可简写为u_int;
14、数据类型(实型)

浮点数:小数
 即整数位、小数点、小数位;
即整数位、小数点、小数位;
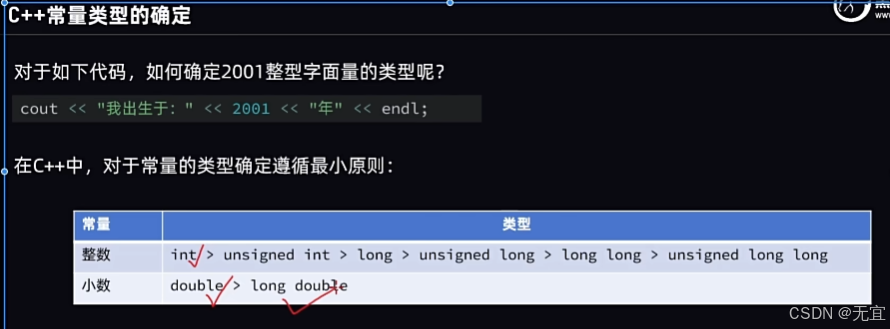
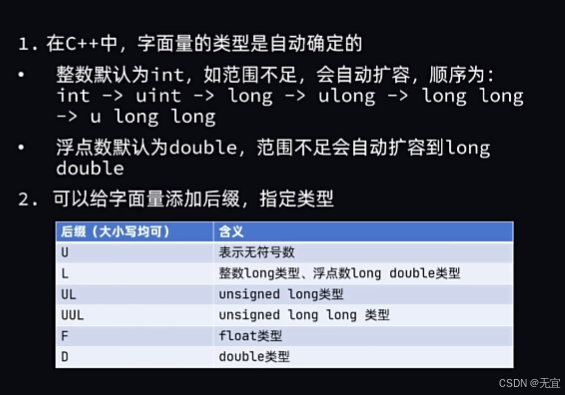
15、C++常量类型的确定
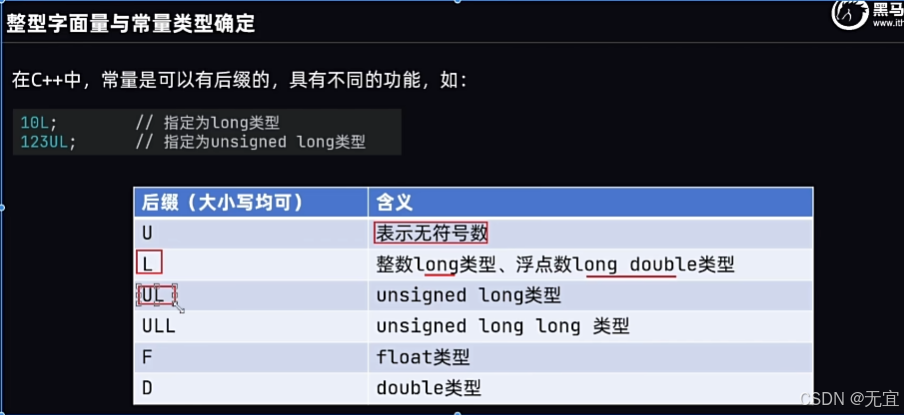
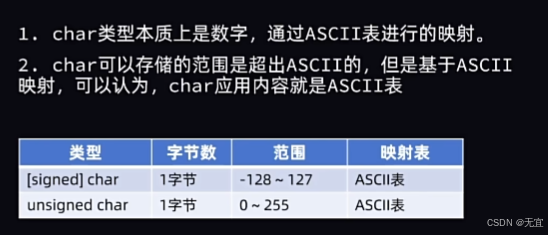
16、数据类型-char类型
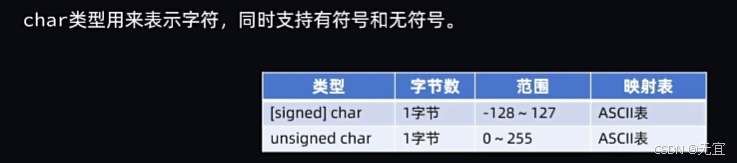
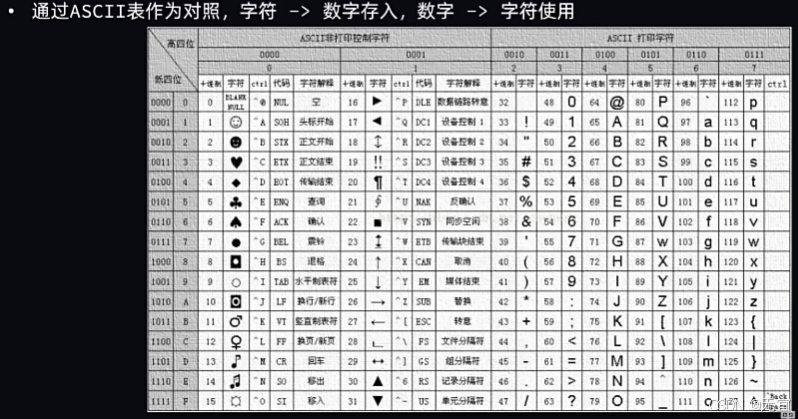
char类型可存储内容:ASCII表;
17、转义字符
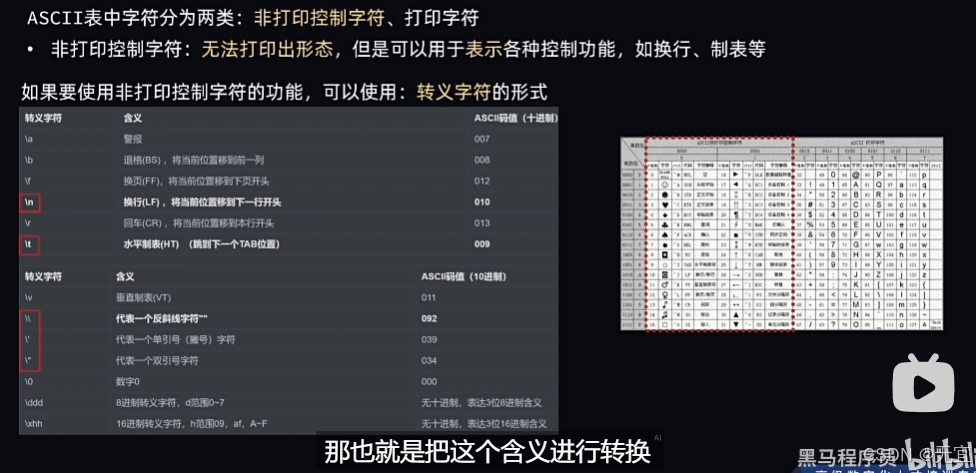

单独打印“与‘,需要\消除其字符意义,\“与\‘才能打印出来“与‘。

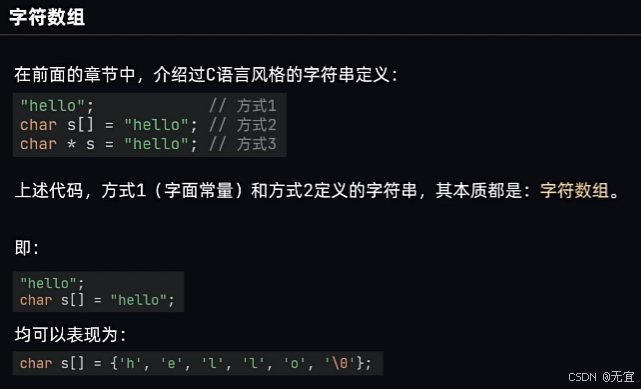
18、数据类型-字符串

字符数组在赋值语句下不能进行赋值;
19、字符串的拼接

其中利用to_string()函数将非字符串转换为字符串之后,可用+号进行拼接。
20、数据类型-布尔型

21、cin数据输入

22、cin中文乱码

23、算术运算符
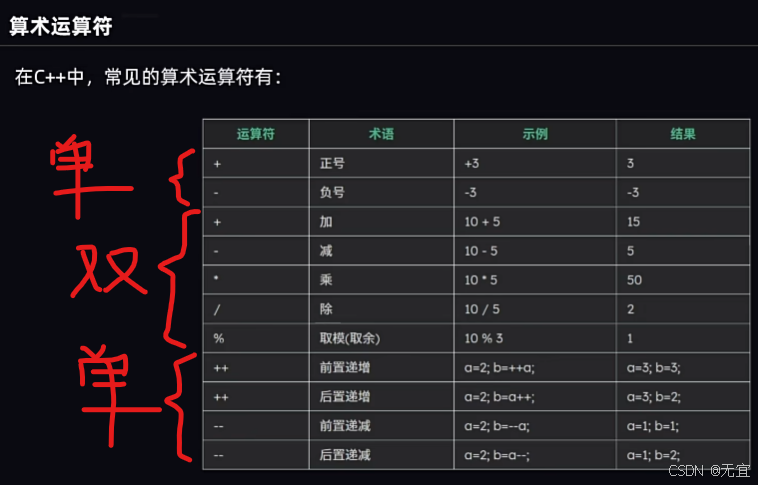

 即整除结果(10/3=3);
即整除结果(10/3=3);
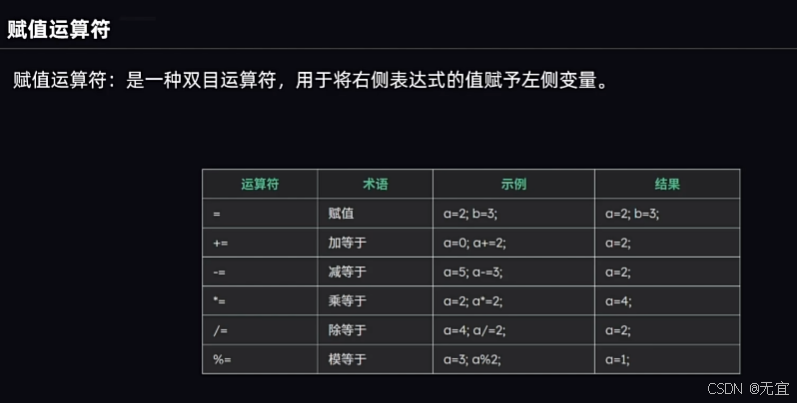
24、赋值运算符


25、比较运算符
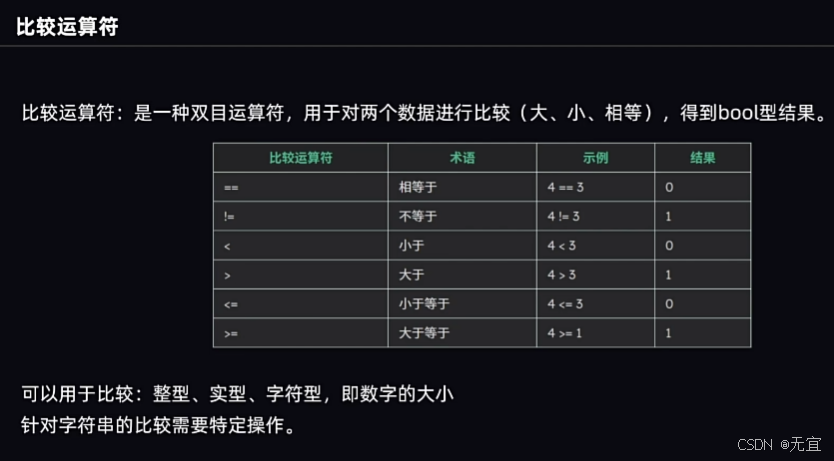

- C语言风格:
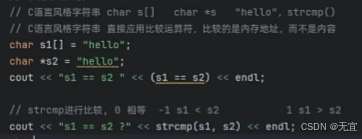
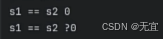 第一个0是false不相等,第二个0是相等。
第一个0是false不相等,第二个0是相等。
- C++风格:
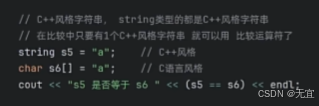
 记得s5==s6要加小括号();
记得s5==s6要加小括号();
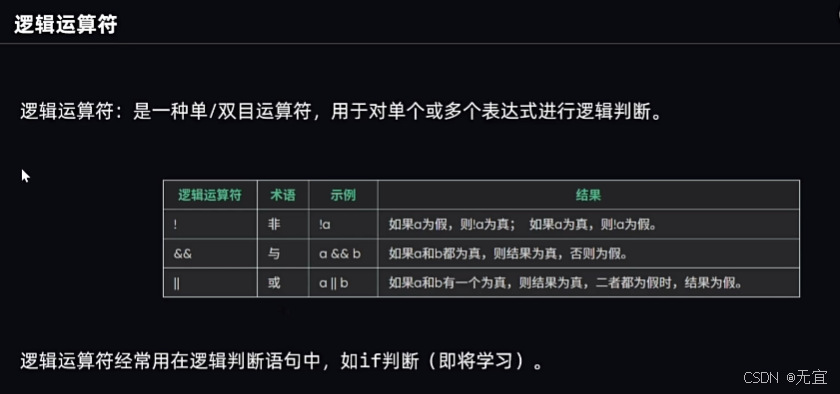
26、逻辑运算符
27、三元运算符


第二章:控制结构
28、if与if else与else if逻辑判断语句



else if语句里面的几个条件互斥,只能成立一个。

29、逻辑判断语句的嵌套
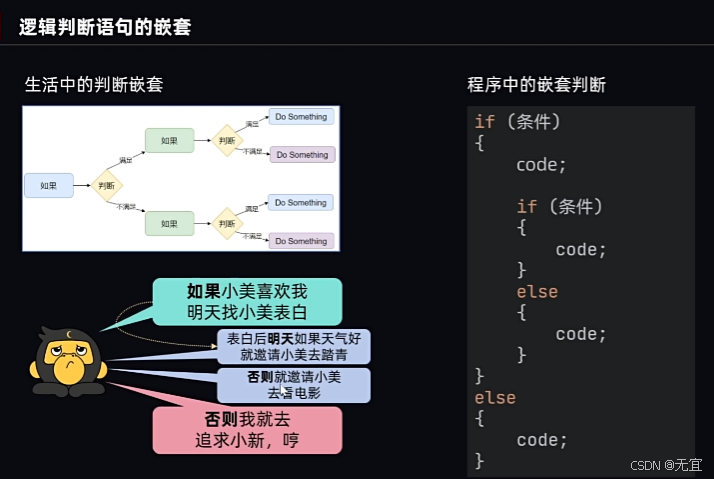
30、Switch控制语句


31、枚举类型
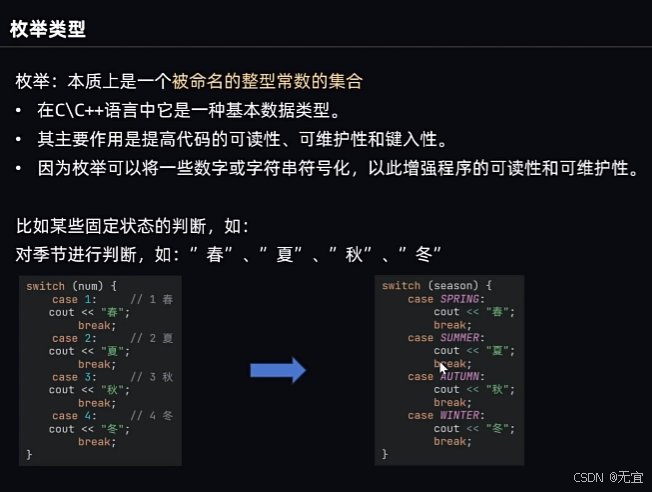

例子: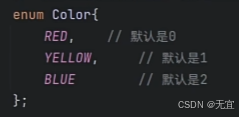

32、while循环语句
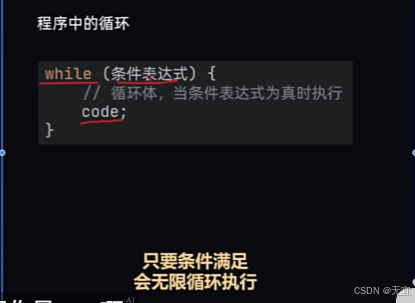
即条件表达式为true(1)的时候,执行code,然后再返回来看条件表达式,还是1就继续执行code......

33、do while循环语句


34、while循环嵌套

35、for循环语句

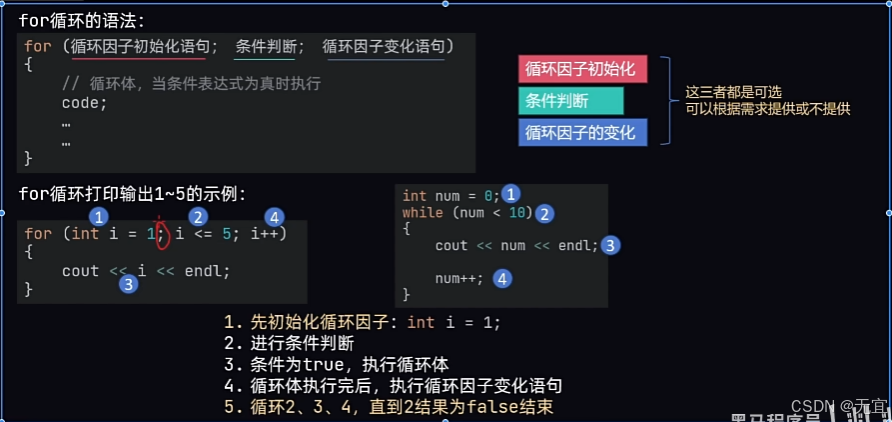
两者执行步骤均从1到4;

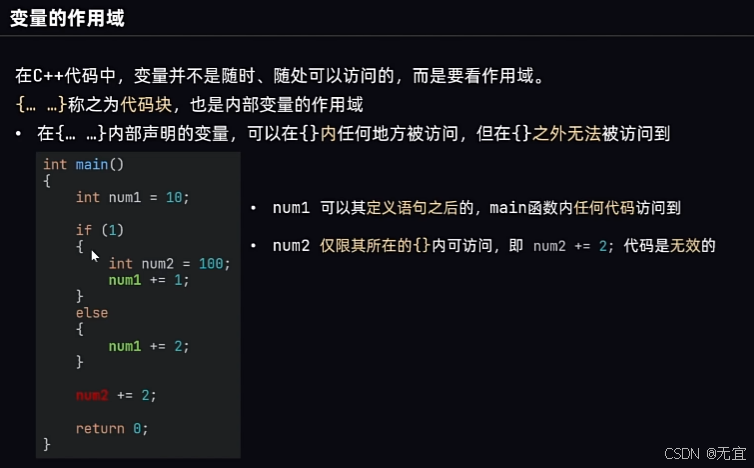
36、变量的作用域
37、循环中断语句(continue与break)

例子程序:
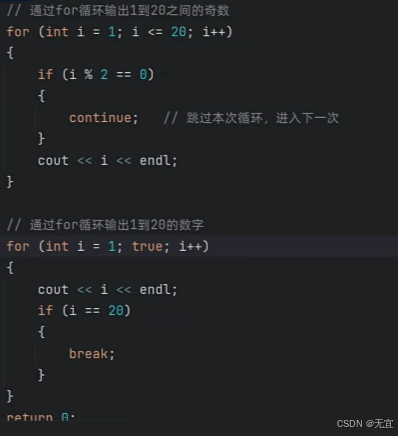 其中两个都是对所在for循环起作用;
其中两个都是对所在for循环起作用;
输出结果分别是:1-20的奇数,1-20数字(到20终止);

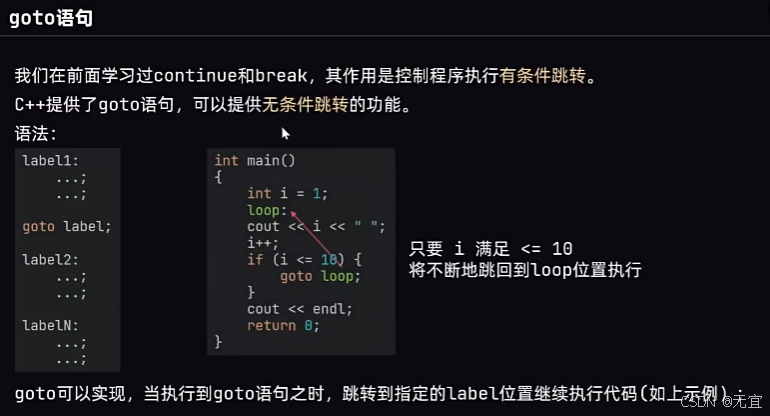
38、goto语句

第三章:数组、指针、引用与结构体
39、数组的定义
大盒子装进同类型小物品;
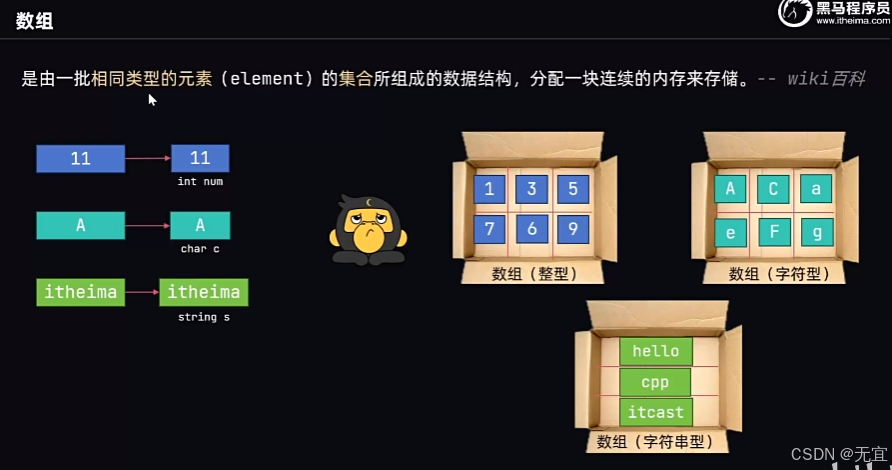

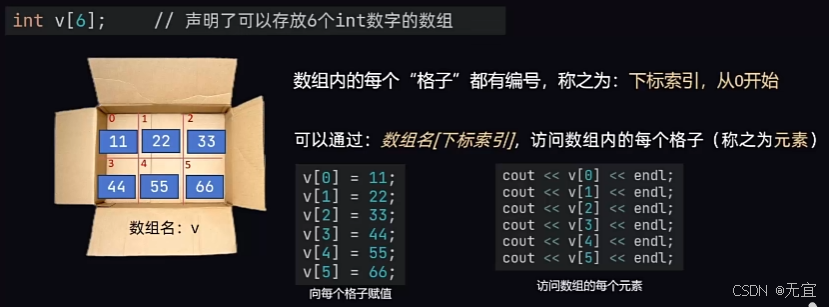
v[6]表明数组内可存放6个元素,分别是v[0]到v[5];而不是到v[6];
注:
- 数组声明+赋值快捷写法

- cout输出的时候,数组不加引号,数组的输出不加引号是因为数组本身并不是一个字符串,而是一个由多个元素组成的集合,你需要处理每个元素进行输出。引号“the six”只是为了用于表示字符串字面量,而数组本身是一个数据结构,不是字符串。

40、数组的特点
特点1:
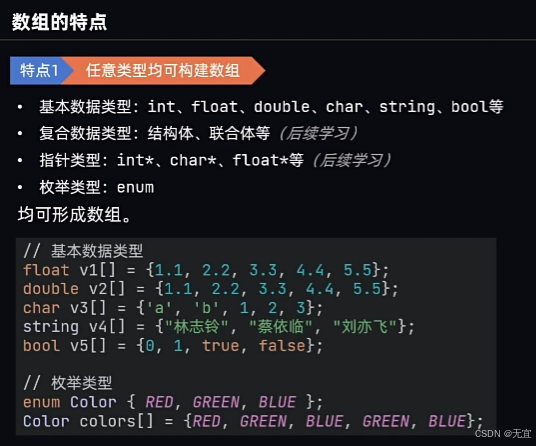
特点2:

两种类型都代表数组v大小固定为5;
特点3:

其中sizeof函数可以计算变量的空间占用大小;
特点4:
 1改为11,;2改为22;
1改为11,;2改为22;
特点5:

v本身不存数据,通过记录的内存地址去访问0号元素,再加(int)4个字节,访问1号元素等等;

 直接输出的v9代表的是一个内存地址,即0号元素(v[0]);
直接输出的v9代表的是一个内存地址,即0号元素(v[0]);
41、数组的遍历

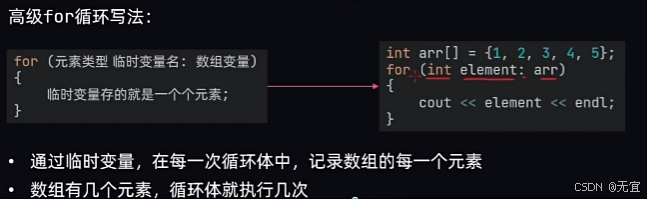
42、字符数组
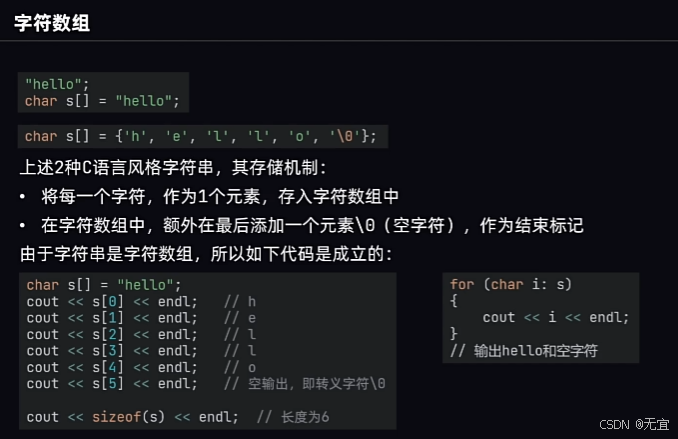
hello用sizeof函数的出来是6个元素;(多了一个/0)
上述代码输出为h,e,l,l,o,/0;

采用string类型:string 类型用于表示和操作文本数据,是编程中非常常用的一种数据类型。
43、多维数组

二维数组:

上下两种表达,要不先声明,一个一个赋值;要不直接声明+赋值。
三维数组:

上下两种表达,要不先声明,一个一个赋值;要不直接声明+赋值。
44、多维数组的遍历
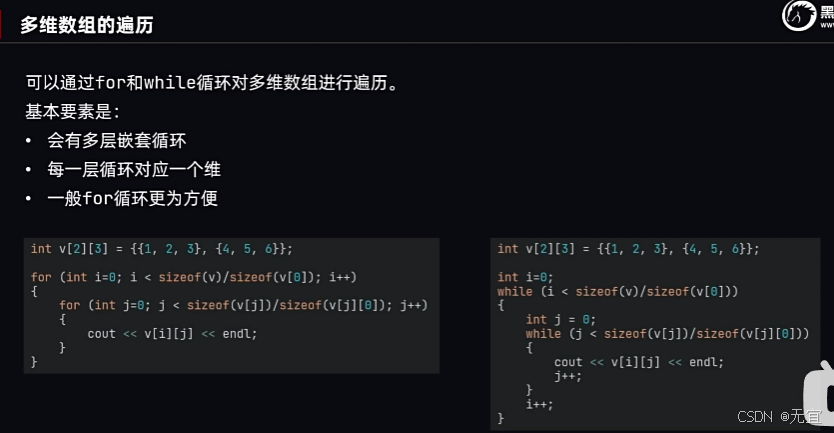
45、指针基础
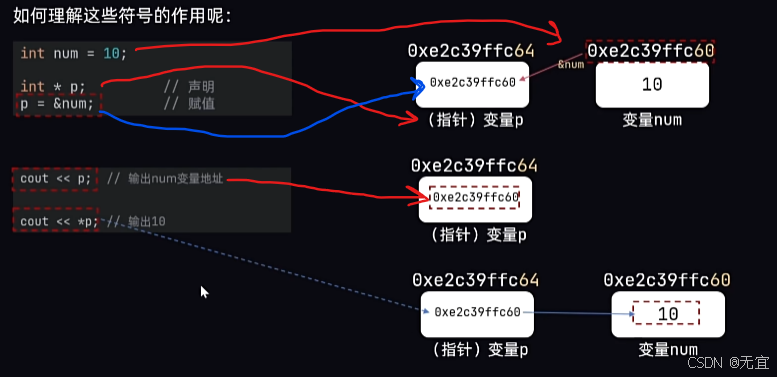
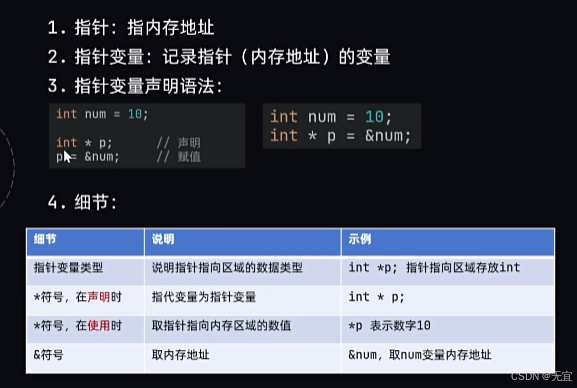
指针是一个变量,其值是另一个变量的地址。通过指针,可以间接访问和操作存储在该地址上的数据。

定义变量的时候加一个*,那么后面的变量存的就是一个内存地址,而不是数字等;通过&来取得某个变量的地址,并存放到p中;
若是取数组arr[ ]的地址,不用加该符号&,因为数组本身记录的就是地址,并且指向的是数组中的0号[0]元素地址;如下图:

易错分辨:
int a = 10;
int* ptr (int *ptr)= &a; // ptr 是一个指向 a 的指针;*的位置不会影响语义。
int value = *ptr = a; // 解引用 ptr,获取 ptr 指向的地址的值,即 a 的值,赋值给 value
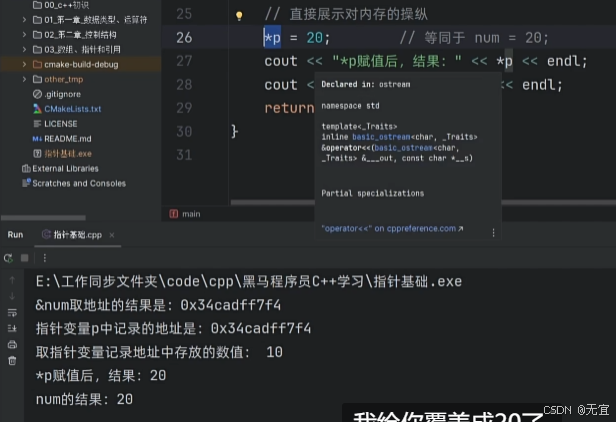
如上图所示,直接对指针变量进行了赋值,可以直接修改内存;
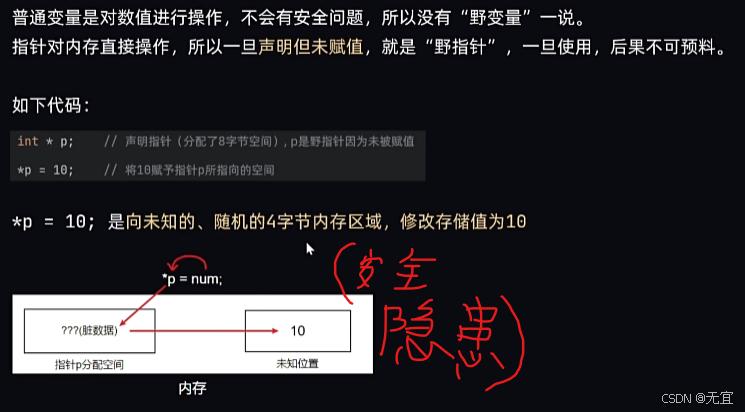
46、野指针和空指针
 下一个人不吃上一个的残羹剩饭;
下一个人不吃上一个的残羹剩饭;

指针变量本身所占字节数:
64位系统:8字节;32位系统:4字节
对野指针直接进行赋值,所赋的值可能会存储在一个未知的区域,造成安全隐患,如下所示:
为避免上述问题,引入空指针的定义:


总结:

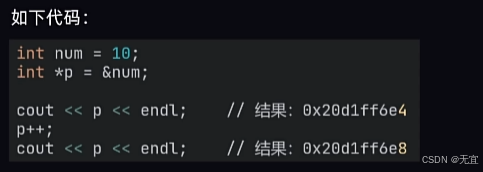
47、指针运算

例如:int类型4个字节,所以加一个int的地址即4个字节;


48、动态内存分配

例如
如下伪代码:
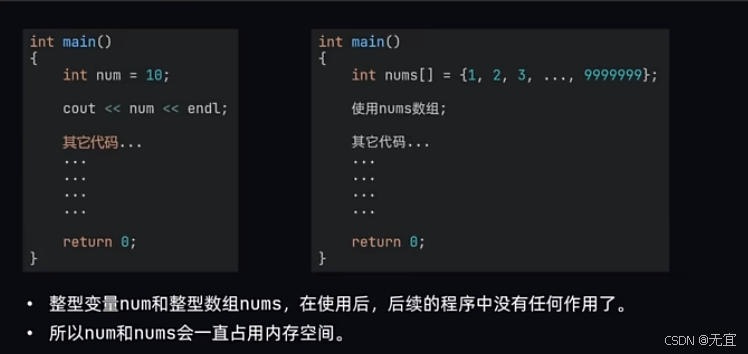
上述伪代码称为:(自动)静态内存分配

对此,采用的方法为:
 其中delete不能删除C++的静态内存;
其中delete不能删除C++的静态内存;

49、数组元素的移除


50、数组元素的插入

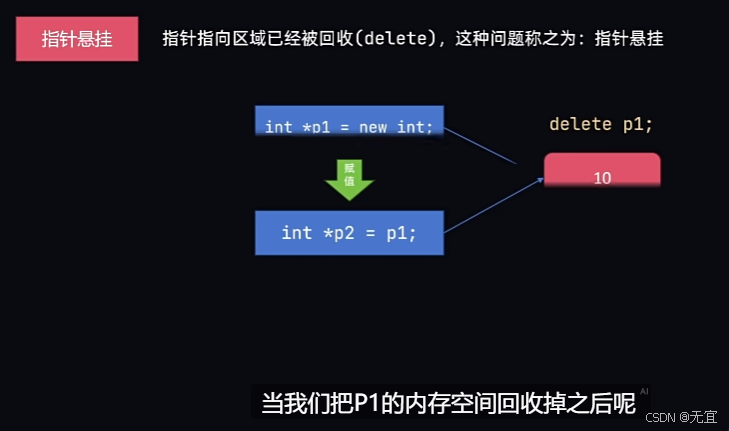
51、指针悬挂
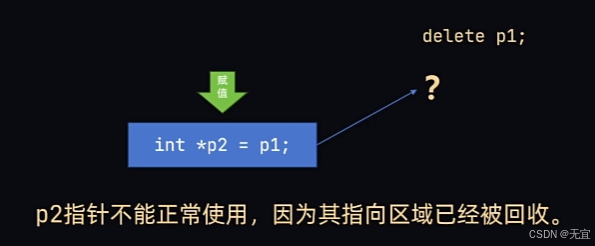

52、常量指针(const)
常量指针(const pointer)是一种特殊类型的指针,用于确保指针所指向的值不能被修改。
分为三类例如:
第一种:
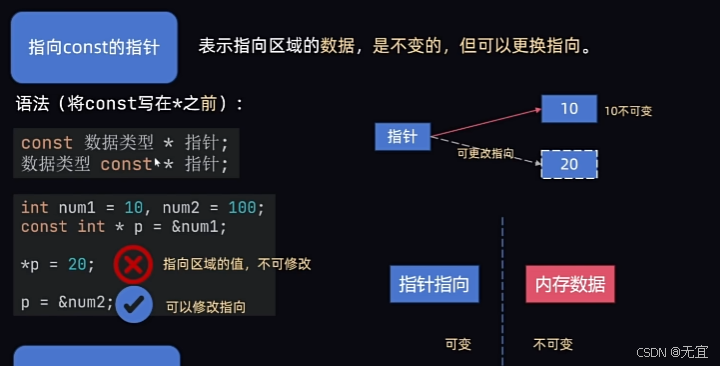
第二种:

第三种:

第四章:函数
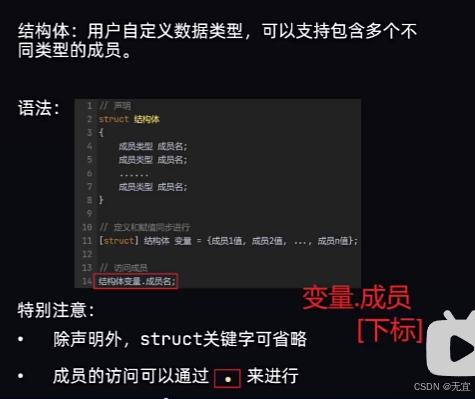
51、结构体基本应用
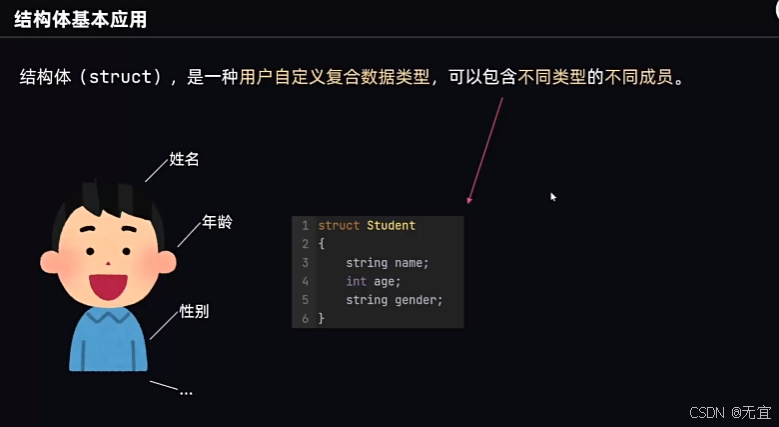
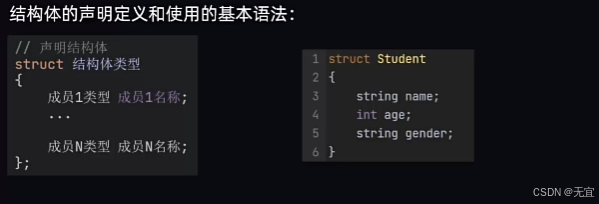
struct 是结构体(structure)的缩写。它是一种用户定义的数据类型,用于将不同类型的数据组合在一起。结构体允许你创建一个包含多个数据字段的复合数据类型,常用于组织和管理数据。
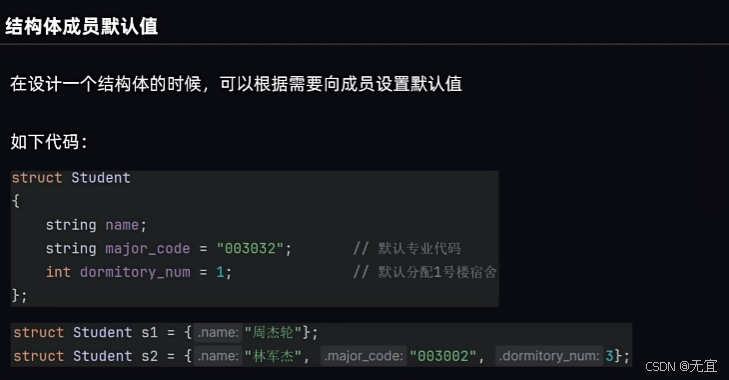
52、结构体成员默认值
53、结构体数组
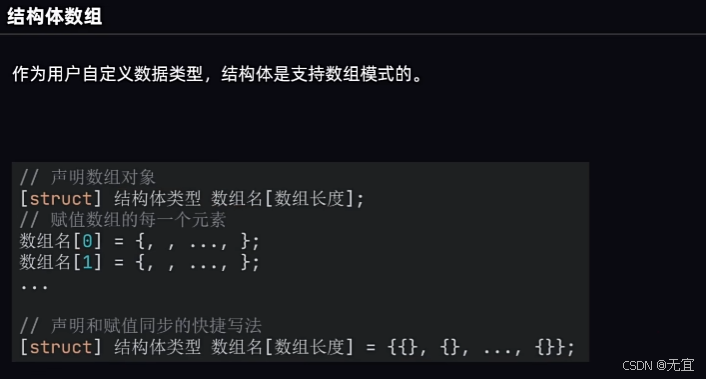
结构体数组例如:

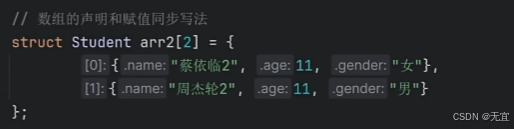
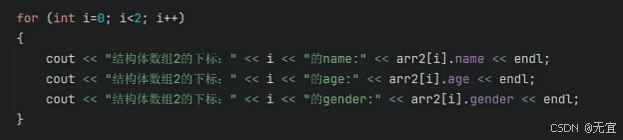
54、结构体指针
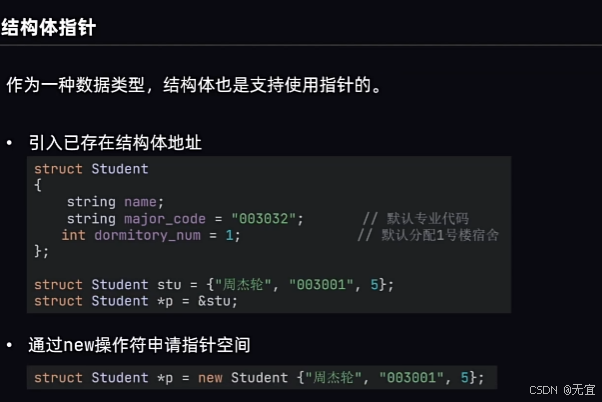
指针访问结构体内成员的时候采用-<;

55、结构体指针数组
结构体指针数组是指一个数组,其中的每个元素都是指向结构体的指针。
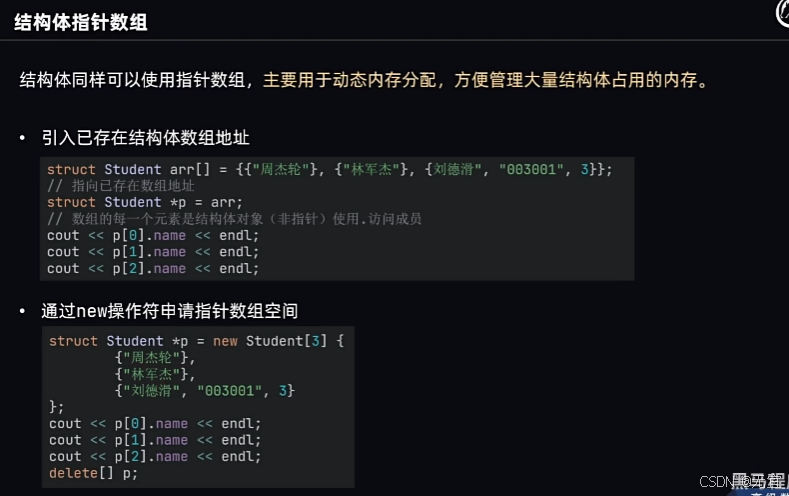

上图中用的是.来访问内容,因为p1是指针,但是p1中的[0]号元素是结构体,所以用.;
56、函数的概念
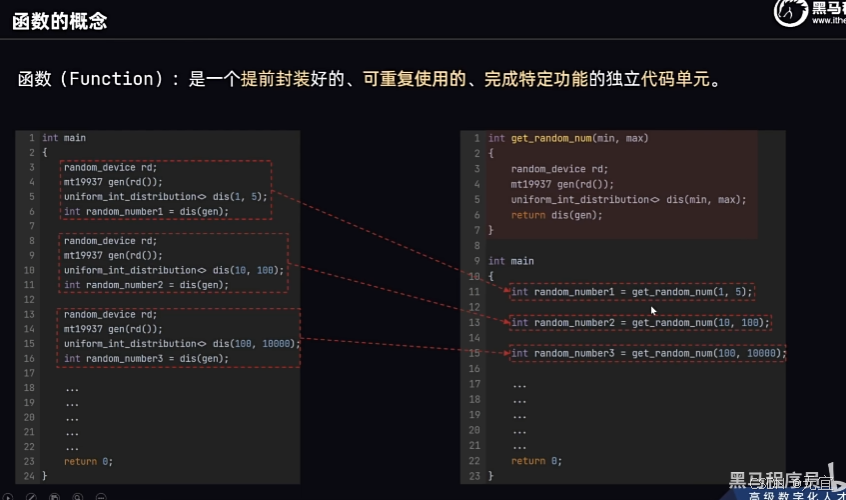

57、函数的基础语法
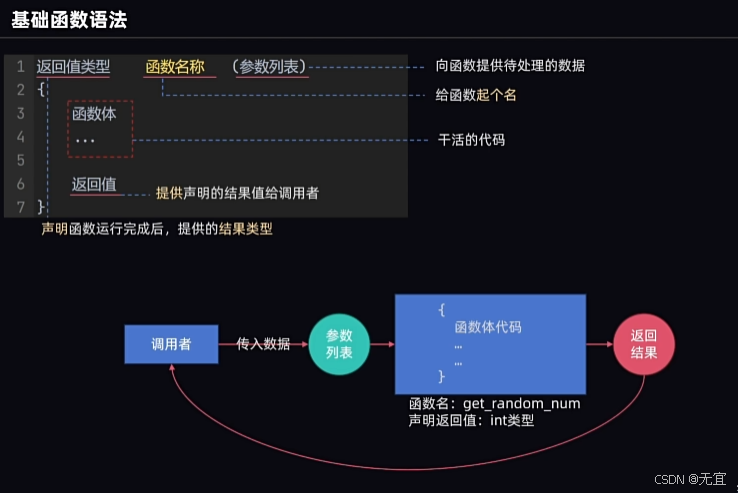
在main前编写函数,然后在main内使用;
返回值类型有整型int、浮点型double、字符型char、string等;

- 函数与int main(){}同级,所以函数不可定义在main内部。
- 其中a,b形式参数(形参);3,5实际参数(实参);
58、无返回值函数和void类型
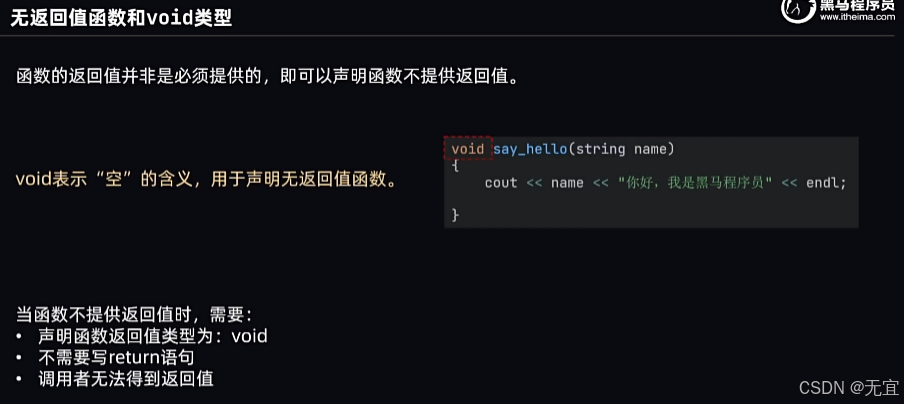
void:空
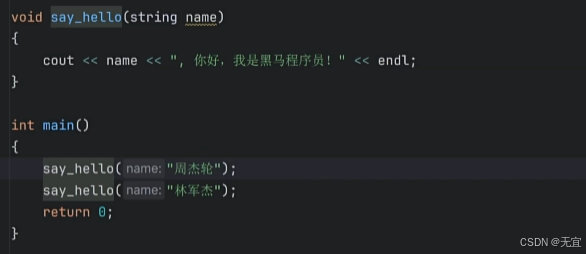
没return返回值,所以不用(=)接收它的结果;
“即不需要你的结果,直接去干”;
59、空参函数

60、函数的嵌套调用

61、参数的值传递与地址传递

其中把x,y的值给了a,b;所以函数里的交换和x,y本身无关;
故上图是单纯的值传递;
下图换个写法,是地址传递,x,y的值完成了互换;
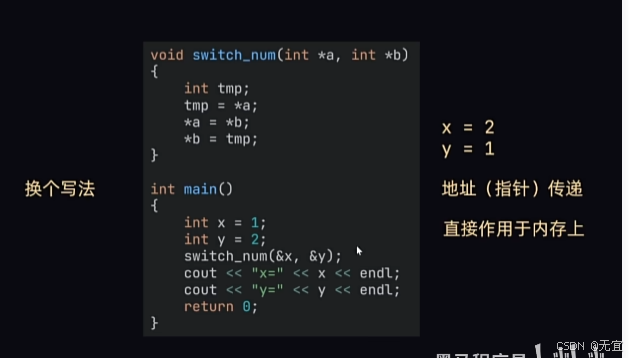
总结:

62、函数传入数组

63、引用的基本概念

、
三个特点:
类似: 引用为空,会报错;
引用为空,会报错;
 必须一开始就初始化,引用了谁(b引用了a);
必须一开始就初始化,引用了谁(b引用了a);
引用的代码实现:

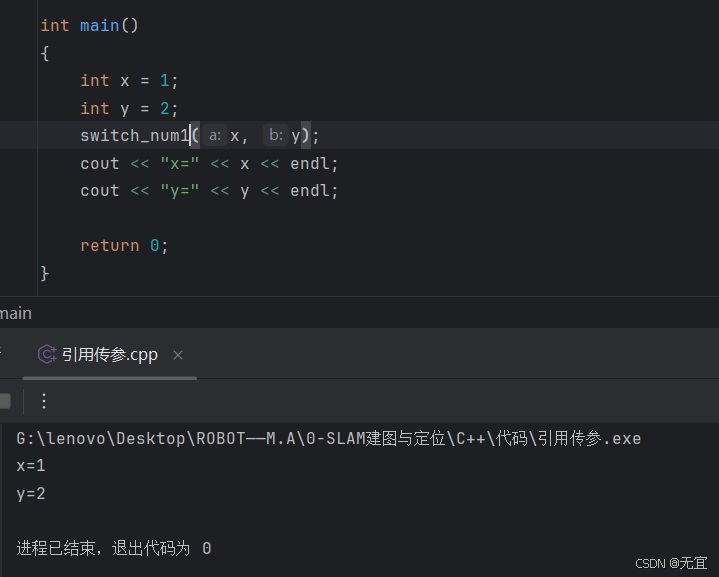
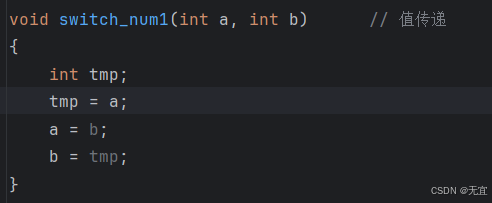
64、引用传参

- 单单x,y值传递是无法对主函数main中的x,y进行改变(无法改变实参),如下图:
- 引用传递会直接改变main中的值(会改变实参),如下图:

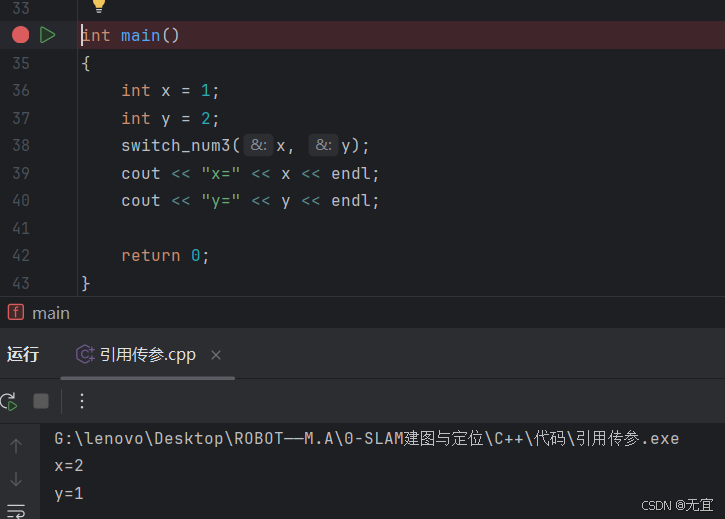
- 指针地址传参,可根据地址改变实参
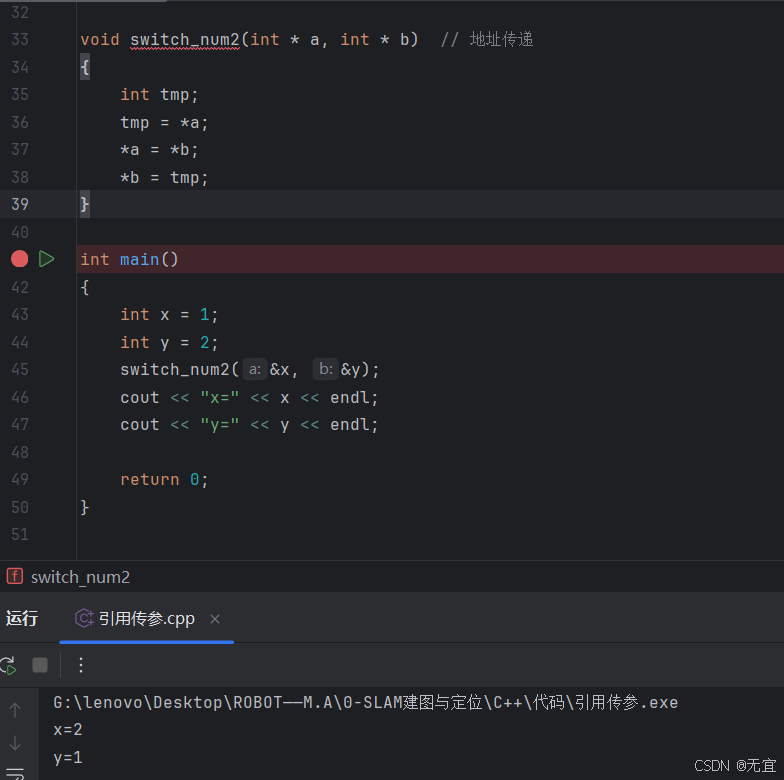
以上三种的区别与联系:
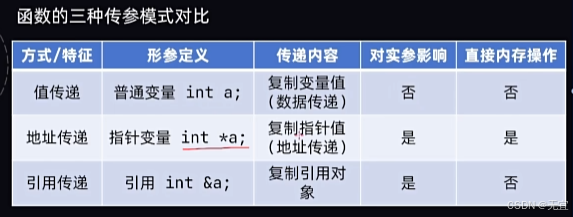
常量引用:在函数形参列表中,可以加const修饰形参,防止形参改变实参;
65、函数返回指针及局部变量的生命周期


即在子函数内部创建的变量无法作为函数的返回值,因为会在子函数执行之后原地销毁;
应当如下编写代码:
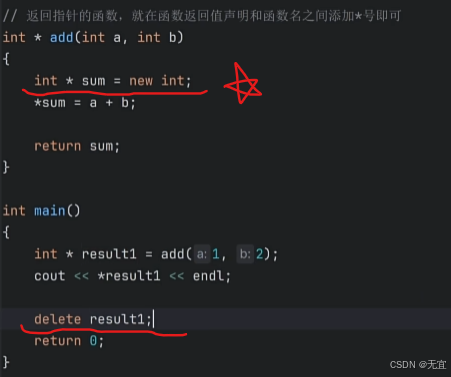
关于 return sum 中不加 * 的原因:
在 return sum; 这行代码中,我们返回的是指针 sum,而不是指针指向的值。
-
sum是一个指针,它保存的是动态分配内存的地址。如果在return sum;中加上*,即return *sum;,那么你将返回指针sum所指向的值(在本例中是a + b的和)。但函数声明中要求返回一个int*类型(即指针),所以我们不需要加*,因为我们要返回的是sum指向的内存地址,而不是内存中的值。
简而言之,sum 本身就是一个指针,*sum 是解引用操作,表示返回指针指向的内容。return sum; 返回的是指针,而不是它指向的值。
总结:
-
sum是指针,*sum是指针指向的值。 -
函数
add的返回值类型是int*,所以直接返回sum,而不需要加*。

66、static关键字


当变量所占的空间较小的时候可以使用例如int就4个字节;但是要是有很多个元素的数组,会占用大量空间,此时应当直接使用new和delete进行动态手动管理内存如上点65;
67、函数返回数组


![]()
例如点61和点64。
第二阶段:C++核心编程(剩余部分在文件核心编程中)
第一章:程序的内存模型
1、内存四区
C++程序在执行时,将内存大方向划分为4个区域
- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程
(1)程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放 CPU 执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此.
全局区还包含了常量区, 字符串常量和其他常量也存放在此.
该区域的数据在程序结束后由操作系统释放
总结:
- C++中在程序运行前分为全局区和代码区
- 代码区特点是共享和只读
- 全局区中存放全局变量、静态变量、常量
- 常量区中存放 const修饰的全局常量 和 字符串常量
(2)程序运行后
栈区:
由编译器自动分配释放, 存放函数的参数值,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放
堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
总结:
堆区数据由程序员管理开辟和释放
堆区数据利用new关键字进行开辟内存
第二章:函数高级
1、函数的默认参数
在C++中,函数的形参列表中的形参是可以有默认值的。
语法: 返回值类型 函数名 (参数= 默认值){}
例如:
int func(int a, int b = 10, int c = 10) {
return a + b + c;
}
//1. 如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
//int func2(int a = 10, int b){ //错误代码
//}
//2. 如果函数声明有默认值,函数实现的时候就不能有默认值;声明和实现只能有一个有默认值;
int func2(int a = 10, int b = 10); //加分号即函数的声明
int func2(int a, int b) { //即函数实现
return a + b;
}
int main(){
cout << func(10) <<endl; //3. 指仅传入a的值即可,因为b,c在子函数中已经设置为默认参数了,不过如果这个地方传入了b,c的值,程序输出则优先用已传入的值,而不是子函数中的默认值;
system("pause");
return 0;
} 2、函数的占位参数
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置。
语法: 返回值类型 函数名 (数据类型){}
(1)
//函数占位参数int
void func(int a, int) {
cout << "this is func" << endl;
}
int main() {
func(10,10); //占位参数必须填补,必须补个10来代表后面的占位参数int
system("pause");
return 0;
}
(2)
//占位参数也可以有默认参数,那此时后面的main函数调用的时候直接func();即可,不用填补了;
void func(int 10) {
cout << "this is func" << endl;
}
3、函数重载
作用:函数名可以相同,提高复用性;
(1)函数重载满足条件:
- 同一个作用域下
- 函数名称相同
- 函数参数类型不同 或者 个数不同 或者 顺序不同
注意: 函数的返回值不可以作为函数重载的条件
例如如下代码:
(1)
//函数重载需要函数都在同一个作用域下(目前的是全局作用域)
void func()
{
cout << "func 的调用!" << endl;//个数不同,一个func是0,一个func (int a)是1
}
void func(int a)
{
cout << "func (int a) 的调用!" << endl;//类型不同
}
void func(double a)
{
cout << "func (double a)的调用!" << endl;
}
void func(int a ,double b)
{
cout << "func (int a ,double b) 的调用!" << endl;//顺序不同
}
void func(double a ,int b)
{
cout << "func (double a ,int b)的调用!" << endl;
}
int main() {
func();
func(10);
func(3.14);
func(10,3.14);
func(3.14 , 10);
system("pause");
return 0;
}
(2)
//函数返回值(int与void的区分)不可以作为函数重载的条件(因为编译器不能按照返回值来区分函数)
//int func(double a, int b)
//{
// cout << "func (double a ,int b)的调用!" << endl;
//}
(2)函数重载注意事项
- 引用作为重载条件
- 函数重载碰到函数默认参数
//函数重载注意事项
(1)
//1、引用作为重载条件
void func(int &a) //int &a=10不合法,10在常量区;
{
cout << "func (int &a) 调用 " << endl;
}
void func(const int &a)// const int &a=10合法
{
cout << "func (const int &a) 调用 " << endl;
}
(2)
//2、函数重载碰到函数默认参数
void func2(int a, int b = 10)//默认参数10
{
cout << "func2(int a, int b = 10) 调用" << endl;
}
void func2(int a)
{
cout << "func2(int a) 调用" << endl;
}
int main() {
int a = 10;
func(a); //调用无const
func(10);//调用有const
//func2(10); //碰到默认参数产生歧义,出现二义性,需要避免,因为此时两个都可调用
system("pause");
return 0;
}第三章:类和对象
类的组成部分:
1、成员变量(属性): 类内部可以定义多个成员变量,这些变量表示该类对象的状态或特征。成员变量可以是任何数据类型,可以在类内部直接声明和使用。
2、成员函数(方法): 成员函数定义了对象的行为。类的成员函数可以操作类的成员变量,或者提供对外的功能接口。
3、访问控制符:
-
public:公开的,任何地方都可以访问这些成员。
-
private:私有的,只有该类的成员函数可以访问,外部无法直接访问。
-
protected:受保护的,只有该类和其派生类(子类)能够访问。
4、构造函数: 构造函数是一个特殊的成员函数,在创建对象时自动调用,用于初始化对象的成员变量。构造函数的名称与类名相同,没有返回类型。
5、析构函数: 析构函数是另一个特殊的成员函数,当对象销毁时自动调用,用于释放资源。
C++面向对象的三大特性为:=封装、继承、多态=
C++认为=万事万物都皆为对象=,对象上有其属性和行为
例如:
人可以作为对象,属性有姓名、年龄、身高、体重...,行为有走、跑、跳、吃饭、唱歌...
车也可以作为对象,属性有轮胎、方向盘、车灯...,行为有载人、放音乐、放空调...
具有相同性质的=对象=,我们可以抽象称为=类=,人属于人类,车属于车类
1、封装
(1)封装的意义
封装是C++面向对象三大特性之一
封装的意义:
- 将属性和行为作为一个整体,表现生活中的事物
- 将属性和行为加以权限控制
封装意义一:
在设计类的时候,属性和行为写在一起,表现事物
语法: class 类名{ 访问权限: 属性 / 行为 };
//圆周率
const double PI = 3.14;
//将属性和行为作为一个整体,用来表现生活中的事物
//类中的属性和行为 统称为 成员
//属性 == 成员属性/成员变量
//行为 == 成员函数/成员方法
//封装一个圆类,求圆的周长
//class代表设计一个类,后面跟着的是类名
class Circle//类名
{
public: //访问权限 公共权限
//属性
int m_r;//半径
//行为
//获取到圆的周长
double calculateZC()
{
return 2 * PI * m_r;
}
};
int main() {
//通过圆类,创建圆的对象
Circle c1;//(实例化)通过一个类Circle,创建一个对象c1的过程
c1.m_r = 10; //给圆对象的半径 进行赋值操作
cout << "圆的周长为: " << c1.calculateZC() << endl;
system("pause");
return 0;
}封装意义二
类在设计时,可以把属性和行为放在不同的权限下,加以控制
访问权限有三种:
- public 公共权限
- protected 保护权限
- private 私有权限
//三种权限(成员函数、成员变量都有权限,都有属性)
//公共权限 public 成员 类内可以访问 类外可以访问
//保护权限 protected 类内可以访问 类外不可以访问 儿子可访问父亲的保护权限(汽车等)
//私有权限 private 类内可以访问 类外不可以访问 儿子不可访问父亲的私有权限(银行卡密码等)
class Person
{
//姓名 公共权限
public:
string m_Name;
//汽车 保护权限
protected:
string m_Car;
//银行卡密码 私有权限
private:
int m_Password;
public:
void func()
{
m_Name = "张三";
m_Car = "拖拉机";
m_Password = 123456;
}
}; //类内
int main() { //;类外
//实例化具体对象
Person p;
p.m_Name = "李四";
//p.m_Car = "奔驰"; //保护权限类外访问不到
//p.m_Password = 123; //私有权限类外访问不到
//p.func();//public可访问
system("pause");
return 0;
}(2)struct和class区别
struct 是用于定义一个结构体(structure)的关键字。结构体是一个用户自定义的数据类型,它允许将不同类型的数据组合在一起,形成一个复合数据类型。结构体通常用于表示具有不同属性的实体。
在 C++ 中,class 是用于定义对象类型的关键字。通过类可以封装数据和功能,使得代码更加模块化和可重用。
在C++中 struct和class唯一的区别就在于 默认的访问权限不同
区别:
- struct 默认权限为公共
- class 默认权限为私有
class C1
{
int m_A; //默认是私有权限
};
struct C2
{
int m_A; //默认是公共权限
};
int main() {
C1 c1;
c1.m_A = 10; //错误,访问权限是私有
C2 c2;
c2.m_A = 10; //正确,访问权限是公共
system("pause");//
return 0;
}(3)成员属性设置为私有
优点1:将所有成员属性设置为私有,可以自己控制读写权限
优点2:对于写权限,我们可以检测数据的有效性
(读:别人可读,可看见;写:该变量可以被修改)
读权限(Read):
-
含义:具有读权限的变量或数据可以被外部查看、读取。也就是说,其他代码可以访问这个变量的值,但不能直接修改它。
-
示例:在 C++ 或 Java 中,
public修饰的变量通常具有读权限。任何地方都可以读取这个变量的值。
写权限(Write):
-
含义:具有写权限的变量或数据可以被外部修改。也就是说,其他代码可以改变该变量的值。
-
示例:如果类的成员变量被定义为
public,那么它也可以被外部代码修改,拥有写权限。如果成员变量是private,那么只有该类的成员函数可以修改它,外部不能直接修改。
class Person {
public:
//姓名设置可读可写
void setName(string name) {
m_Name = name;
}
//获取姓名
string getName()
{
return m_Name;
}
//获取年龄 只读状态
int getAge() {
return m_Age;
}
//设置年龄,为了验证数据有效性,设置为可写状态
void setAge(int age) {
if (age < 0 || age > 150) {
cout << "年龄输入有误" << endl;
return;
}
m_Age = age;
}
//情人设置为只写
void setLover(string lover) {
m_Lover = lover;
}
private:
string m_Name; //可读可写 姓名
int m_Age; //只读 年龄
string m_Lover; //只写 情人
};
int main() {
Person p;
//姓名设置
p.setName("张三");
cout << "姓名: " << p.getName() << endl;
//年龄设置
p.setAge(50);
cout << "年龄: " << p.getAge() << endl;
//情人设置
p.setLover("苍井");
//cout << "情人: " << p.m_Lover << endl; //只写属性,不可以读取
system("pause");
return 0;
}2、对象的初始化和清理
- 生活中我们买的电子产品都基本会有出厂设置,在某一天我们不用时候也会删除一些自己信息数据保证安全
- C++中的面向对象来源于生活,每个对象也都会有初始设置以及对象销毁前的清理数据的设置。
(1)构造函数和析构函数
- 对象的初始化和清理也是两个非常重要的安全问题
一个对象或者变量没有初始状态,对其使用后果是未知;
同样的使用完一个对象或变量,没有及时清理,也会造成一定的安全问题;
- c++利用了构造函数和析构函数解决上述问题,这两个函数将会被编译器自动调用,完成对象初始化和清理工作。
- 对象的初始化和清理工作是编译器强制要我们做的事情,因此如果我们不提供构造和析构,编译器会提供
- 编译器提供的构造函数和析构函数是空实现(无内容:表示这些函数没有执行任何操作)。
构造函数:主要作用在于创建对象时为对象的成员属性赋值,构造函数由编译器自动调用,无须手动调用。
构造函数语法:类名( ){ }
- 构造函数,没有返回值也不写void
- 函数名称与类名相同
- 构造函数可以有参数,因此可以发生重载
- 程序在调用对象时候会自动调用构造,无须手动调用,而且只会调用一次
析构函数:主要作用在于对象销毁前系统自动调用,执行一些清理工作。
析构函数语法: ~类名(){ }
- 析构函数,没有返回值也不写void
- 函数名称与类名相同,在名称前加上符号 ~
- 析构函数不可以有参数,因此不可以发生重载
- 程序在对象销毁前会自动调用析构,无须手动调用,而且只会调用一次
class Person
{
public:
//1、构造函数
Person()
{
cout << "Person的构造函数调用" << endl;//你写什么就调用什么,没写的话系统自动sc
}
//2、析构函数
~Person()
{
cout << "Person的析构函数调用" << endl;
}
};
void test01()
{
Person p;//未调用构造函数
}
int main() {
test01();
system("pause");
return 0;
}
//结果会自动调用构造函数,当程序结束前才调用析构函数;
(2)构造函数的分类及调用
两种分类方式:
- 按参数分为: 有参构造和无参构造
- 按类型分为: 普通构造和拷贝构造
三种调用方式:
- 括号法
- 显示法
- 隐式转换法
//1、构造函数分类
// 按照参数分类分为 有参和无参构造 无参又称为默认构造函数
// 按照类型分类分为 普通构造和拷贝构造
class Person {
public:
//无参(默认)构造函数
Person() {
cout << "无参构造函数!" << endl;
}
//有参构造函数
Person(int a) {
age = a;
cout << "有参构造函数!" << endl;
}
//拷贝构造函数
Person(const Person& p) {
age = p.age;
cout << "拷贝构造函数!" << endl;
}
//析构函数
~Person() {
cout << "析构函数!" << endl;
}
public:
int age;
};
//2、构造函数的调用
//调用无参构造函数
void test01() {
Person p; //调用无参构造函数
}
//调用有参的构造函数
void test02() {
//2.1 括号法,常用
Person p1(10);
//注意1:调用无参构造函数不能加括号;如果加了,编译器认为这是一个函数声明
//Person p2(); //类似于void func()函数声明
Person p3(p1);//拷贝构造函数
//2.2 显式法
Person p2 = Person(10); //有参构造
Person p3 = Person(p2); //拷贝构造
//Person(10)单独写就是匿名对象 当前行结束之后,马上析构(系统会回收掉匿名函数)
//2.3 隐式转换法
Person p4 = 10; // 无参构造,等价于Person p4 = Person(10);
Person p5 = p4; // 拷贝构造,等价于Person p5 = Person(p4);
//注意2:不能利用 拷贝构造函数 初始化匿名对象 编译器认为是对象声明
//Person p5(p4);
}
int main() {
test01();
//test02();
system("pause");
return 0;
}(2)拷贝构造函数调用时机
C++中拷贝构造函数调用时机通常有三种情况
- 使用一个已经创建完毕的对象来初始化一个新对象
- 值传递的方式给函数参数传值
- 以值方式返回局部对象
(3)构造函数调用规则
默认情况下,c++编译器至少给一个类添加3个函数
1.默认构造函数(无参,函数体为空)
2.默认析构函数(无参,函数体为空)
3.默认拷贝构造函数,对属性进行值拷贝
构造函数调用规则如下:
- 如果用户定义有参构造函数,c++不在提供默认无参构造,但是会提供默认拷贝构造
- 如果用户定义拷贝构造函数,c++不会再提供其他构造函数
(4)深拷贝与浅拷贝
深浅拷贝是面试经典问题,也是常见的一个坑
浅拷贝:简单的赋值拷贝操作
深拷贝:在堆区重新申请空间,进行拷贝操作
总结:如果属性有在堆区开辟的,一定要自己提供拷贝构造函数,防止浅拷贝带来的问题
第三阶段:C++提高编程(剩余部分在文件提高编程中)
第一章 模板
第二章 STL初识
第三章 STL- 常用容器
注:素材来源于黑马程序员C++第二章-23_变量的作用域_哔哩哔哩_bilibili;16 类和对象-封装-属性和行为作为整体_哔哩哔哩_bilibili;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)