基于Agent-SDK的Claude 记忆插件来了:上下文不再丢,Agent 开始“记住你是谁”
关注 霍格沃兹测试学院公众号,回复「资料」, 领取人工智能测试开发技术合集
导读
你有没有遇到过这种情况:
-
写到一半,模型“忘了”你刚刚的设计约束
-
多轮对话后,代码风格开始漂移
-
上下文越长,token 越贵,但效果反而变差
问题不在模型能力,而在记忆机制。
最近一个项目开始把这件事工程化解决:claude-mem —— 给 Claude Code 加一层“长期记忆系统”。 https://github.com/thedotmack/claude-mem
目录
-
为什么“记忆”是当前 Agent 的最大短板
-
claude-mem 在做什么(不是简单存日志)
-
核心架构:压缩、抽取、注入
-
和 OpenClaw / Claude Code 的定位差异
-
能落地的工程场景(不是概念)
-
这类方案的边界与风险
一、为什么记忆是当前 Agent 的最大短板
现在大多数 AI 编程工具,本质还是:
-
Prompt + 临时上下文
-
Session 内有效,Session 外失忆
这会导致三个工程级问题:
1)上下文“越用越脏”
长对话会引入:
-
冗余指令
-
过期决策
-
错误假设残留
最终结果:模型越来越不稳定
2)经验无法复用
你每次都在:
-
重复解释项目结构
-
重复定义编码规范
-
重复纠正模型行为
这本质是没有长期记忆层
3)成本指数上升
上下文越长:
-
token 成本 ↑
-
推理延迟 ↑
-
质量反而 ↓
所以:
现在的 Agent,更像“短期记忆+强推理”,而不是“持续学习系统”
二、claude-mem 在做什么(关键不是“存”,而是“压缩”)
这个项目核心做了三件事:
1)全量记录
-
捕获 Claude 在 coding session 中的行为
-
包括:对话、修改、决策路径
这一步很多工具都能做(日志系统)
2)AI 压缩(关键)
不是简单存文本,而是:
-
抽取关键决策
-
去掉冗余上下文
-
生成“高密度记忆片段”
类似于:
原始上下文:5000 tokens
压缩后记忆:200 tokens(但保留核心信息)
3)精准注入
在未来交互中:
-
根据当前任务
-
自动检索相关记忆
-
注入 prompt
本质是一个轻量版 RAG + Memory Layer
三、核心架构拆解(工程视角)
可以把它理解成三层结构:
[Session行为流]
↓
[Memory Engine]
- 抽取
- 压缩
- 存储
↓
[Context Injection]
- 检索
- 重组
- 注入Prompt
关键技术点
1)记忆抽取策略
不是所有信息都要记:
-
设计决策(要)
-
bug 修复经验(要)
-
临时调试输出(不要)
这是“信号 vs 噪音”的问题
2)压缩模型质量
压缩如果做不好:
-
会丢关键上下文
-
或引入错误总结
直接影响后续推理准确性
3)注入时机
不是每次都注入:
-
过多 → 干扰推理
-
过少 → 没价值
需要动态策略
四、和 OpenClaw / Claude Code 的区别
很多人会混淆这几类系统,其实是不同层:
|
组件 |
解决问题 |
核心能力 |
|---|---|---|
|
Claude Code |
写代码 |
Agent执行 |
|
OpenClaw |
多工具编排 |
Agent平台 |
|
claude-mem |
记忆能力 |
长期上下文 |
可以这样理解:
Claude Code = 手
OpenClaw = 身体
claude-mem = 大脑记忆
五、能真正落地的场景
这类系统不是“看起来很强”,而是确实有几个高价值场景:
1)大型代码库协作
问题:
-
每次都要解释架构
解决:
-
自动记住:
-
模块边界
-
命名规范
-
依赖关系
-
2)测试开发(重点)
你会明显受益:
-
记住测试策略
-
复用历史用例设计逻辑
-
自动延续断言风格
本质是“测试经验被模型继承”
3)长期项目迭代
例如:
-
SaaS系统
-
中后台平台
-
AI工具链
模型可以逐渐:
-
理解业务语义
-
记住设计权衡
-
避免重复错误
4)个人开发助手
你会得到一个效果:
一个越来越像“你”的 AI
六、这类方案的边界(必须看)
1)记忆污染问题
错误信息一旦写入:
-
会被持续引用
-
甚至被强化
2)上下文偏置
过度依赖历史:
-
会限制模型探索新解法
-
导致“路径依赖”
3)安全问题
如果接入企业代码:
-
记忆层 = 数据资产
-
需要权限隔离与审计
4)成本问题
虽然压缩降低 token:
但新增:
-
存储成本
-
检索成本
-
计算成本
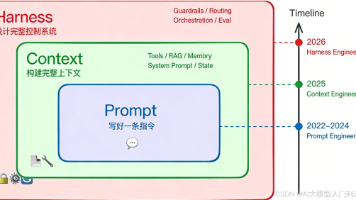
七、一个更重要的趋势
这件事背后其实是一个更大的变化:
Agent 正在从“对话系统”,变成“持续学习系统”
未来的系统结构,大概率是:
LLM(推理)
+ Memory(记忆)
+ Tools(执行)
+ Workflow(编排)
结尾
如果说过去的 AI 是:
-
聪明,但不记事
那么现在开始:
-
不仅会做事
-
还会记住你做过什么
这一步,决定了 Agent 能不能真正进入工程体系。
留个问题(评论区见)
你现在用 AI 写代码时:
-
最大的问题是“不会写”
-
还是“写完就忘”
或者说:
你更需要一个更强的模型,还是一个“不会忘的模型”?
关于我们
霍格沃兹测试开发学社,隶属于 测吧(北京)科技有限公司,是一个面向软件测试爱好者的技术交流社区。
学社围绕现代软件测试工程体系展开,内容涵盖软件测试入门、自动化测试、性能测试、接口测试、测试开发、全栈测试,以及人工智能测试与 AI 在测试工程中的应用实践。
我们关注测试工程能力的系统化建设,包括 Python 自动化测试、Java 自动化测试、Web 与 App 自动化、持续集成与质量体系建设,同时探索 AI 驱动的测试设计、用例生成、自动化执行与质量分析方法,沉淀可复用、可落地的测试开发工程经验。
在技术社区与工程实践之外,学社还参与测试工程人才培养体系建设,面向高校提供测试实训平台与实践支持,组织开展 “火焰杯” 软件测试相关技术赛事,并探索以能力为导向的人才培养模式,包括高校学员先学习、就业后付款的实践路径。
同时,学社结合真实行业需求,为在职测试工程师与高潜学员提供名企大厂 1v1 私教服务,用于个性化能力提升与工程实践指导。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)