毕业设计:python基于AI实现智能旅游推荐系统(源码)
目录
一、项目背景
随着国民生活水平的不断提高,旅游业已成为推动经济发展的重要引擎。然而,在旅游消费升级的大背景下,传统的旅游服务模式正面临着前所未有的挑战。一方面,互联网上的旅游信息呈现出“爆炸式”增长,游客在面对海量的景点攻略、酒店评价和交通路线时,往往陷入“信息过载”的困境,难以在有限的时间内筛选出真正符合个人偏好的行程;另一方面,传统旅游平台普遍采用“热门推荐”或“大众评分”的单一维度推送模式,忽视了用户之间的个性化差异,导致推荐结果千篇一律,难以满足现代游客对深度化、定制化旅行体验的需求。
这种供需之间的矛盾,催生了旅游行业向智能化、个性化转型的迫切需求。近年来,随着人工智能技术的飞速发展,特别是机器学习、自然语言处理以及深度学习在推荐系统领域的成熟应用,为解决上述痛点提供了全新的技术路径。相较于传统的协同过滤算法,基于AI的智能系统能够更精准地捕捉用户的显性行为(如搜索、收藏)与隐性偏好(如浏览时长、社交足迹),从而构建出动态的用户画像,实现从“人找信息”到“信息找人”的服务模式革新。
在此背景下,本课题设计并实现一个基于Python的智能旅游推荐系统。Python语言凭借其丰富的数据处理库(如Pandas、NumPy)和强大的机器学习框架(如Scikit-learn、TensorFlow),为系统的快速开发与算法验证提供了坚实的支撑。该系统旨在通过整合多源异构的旅游数据,利用AI算法挖掘用户的潜在需求,为用户提供包含景点、路线、住宿在内的个性化智能决策方案。本项目的开展,不仅是对现有旅游服务平台功能的有效补充,更是对人工智能技术在垂直领域应用的一次有益探索,具有重要的理论意义与广阔的应用前景。
二、技术介绍
基于你提供的技术栈(Django、MySQL、HTML、CSS、JS),以下是对项目技术背景与选型理由的扩写,约300字,侧重于技术实现的可行性与优势:
技术背景与选型
在明确了基于AI实现个性化推荐的核心需求后,本系统在技术架构上采用了经典的Web开发全栈模式,以确保系统的稳定性、可扩展性与交互性。
后端方面,系统选用 Django 作为核心开发框架。Django 是 Python 生态下最成熟的高层级 Web 框架,遵循“开箱即用”的设计哲学。它不仅内置了强大的 ORM(对象关系映射)组件,能够通过简单的 Python 代码无缝操作 MySQL 数据库,高效管理用户信息、景点数据及交互日志;还提供了完善的用户认证、Admin 后台管理以及安全性防护机制,能够显著提升开发效率,让开发者得以将更多精力聚焦于 AI 推荐算法的核心逻辑实现。
数据存储方面,选择 MySQL 作为关系型数据库。MySQL 具有体积小、速度快、开源免费且支持高并发访问等优点,能够稳定存储系统的结构化数据,并保证数据的一致性与完整性,完美适配中小型毕业设计项目的规模。
前端展示方面,采用 HTML、CSS、JavaScript 的传统组合。通过 HTML 构建清晰的页面结构,CSS 实现响应式布局与美观的视觉风格,确保在不同设备上的浏览体验;原生 JavaScript 则用于实现异步数据交互(如通过 Ajax 请求推荐结果)以及页面动态效果的渲染,无需引入繁杂的第三方框架即可实现流畅的用户交互。
综上所述,该技术栈兼具开发高效性与运行稳定性,能够完整覆盖从数据采集、智能推荐到前端交互的整个闭环,为智能旅游推荐系统的落地提供了坚实的技术保障。
三、功能介绍
本系统是一个基于Python和Django框架开发的国内旅游景点分析与AI旅游路线推荐平台。
角色:用户、管理员
主要功能:
1.用户注册/登录及个人信息管理
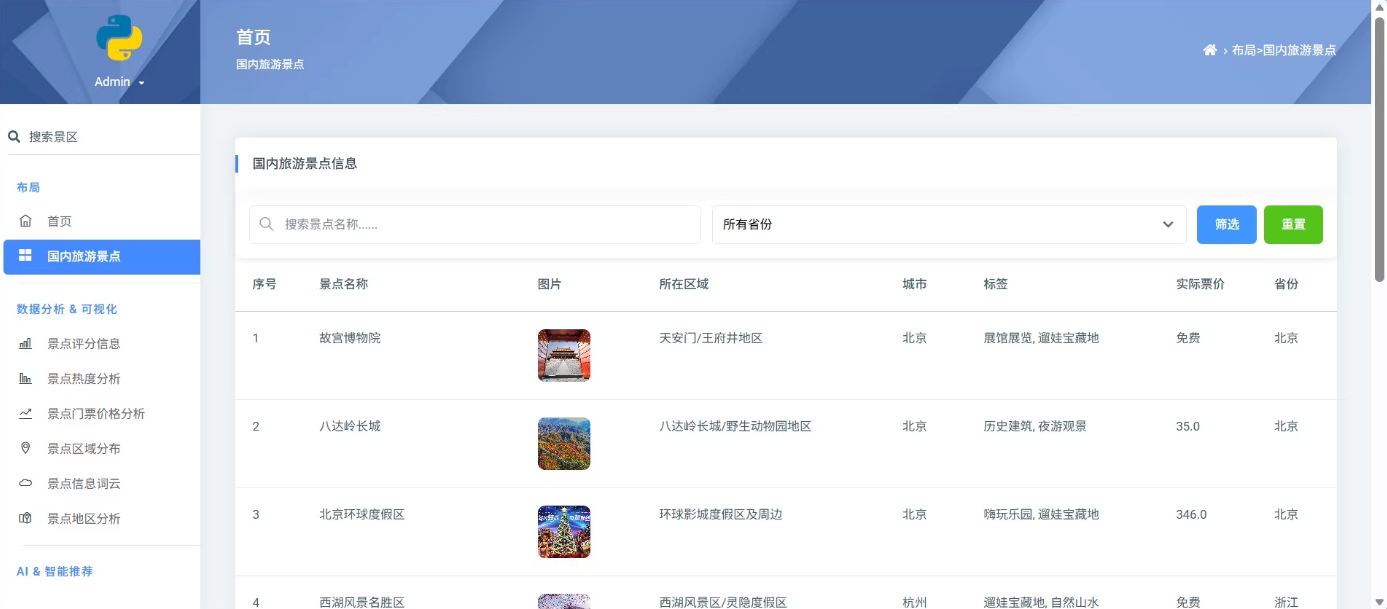
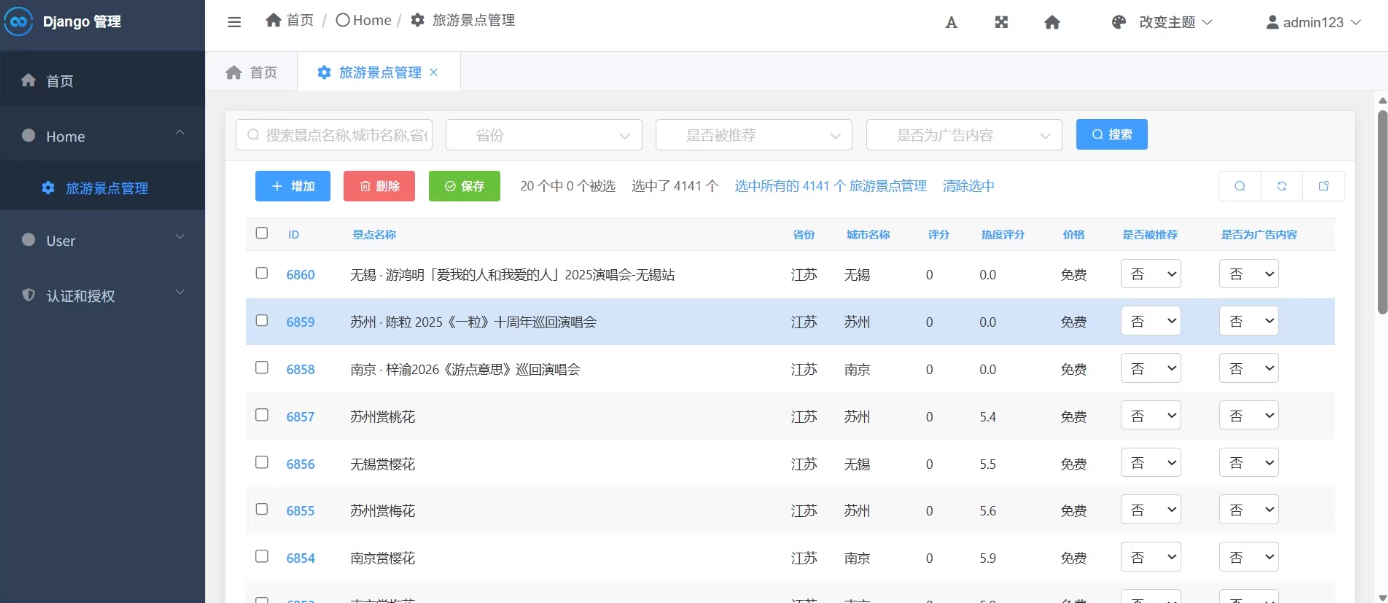
2.旅游景点信息的爬取、清洗与存储
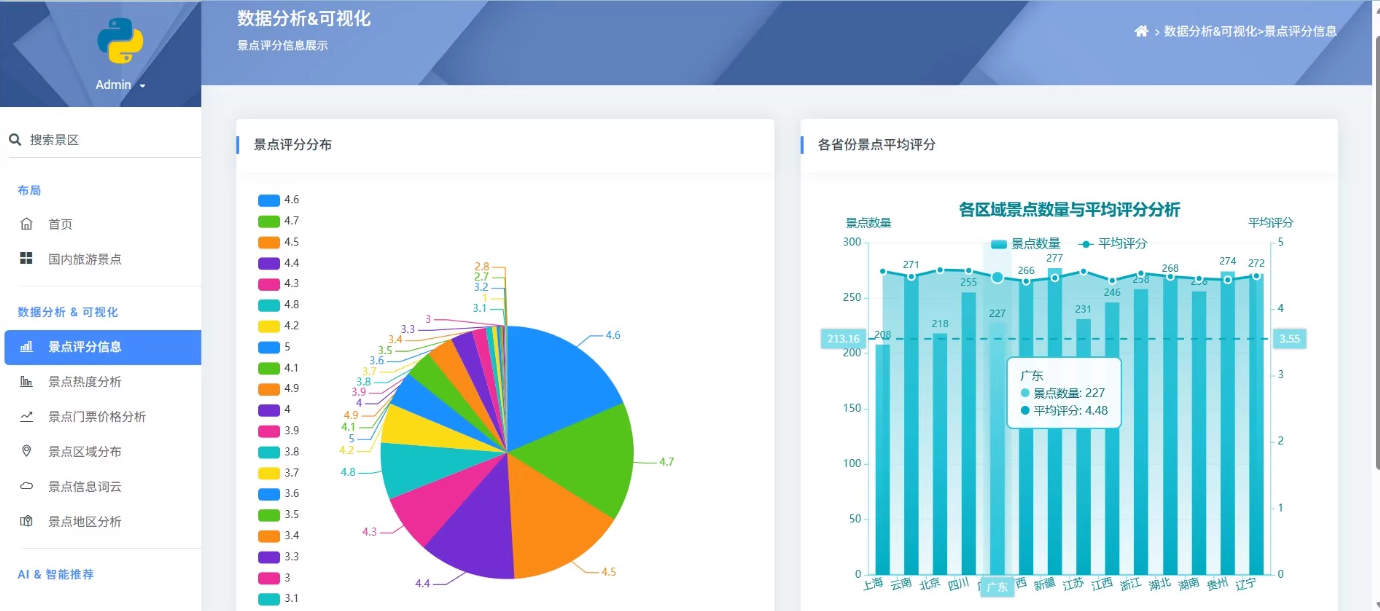
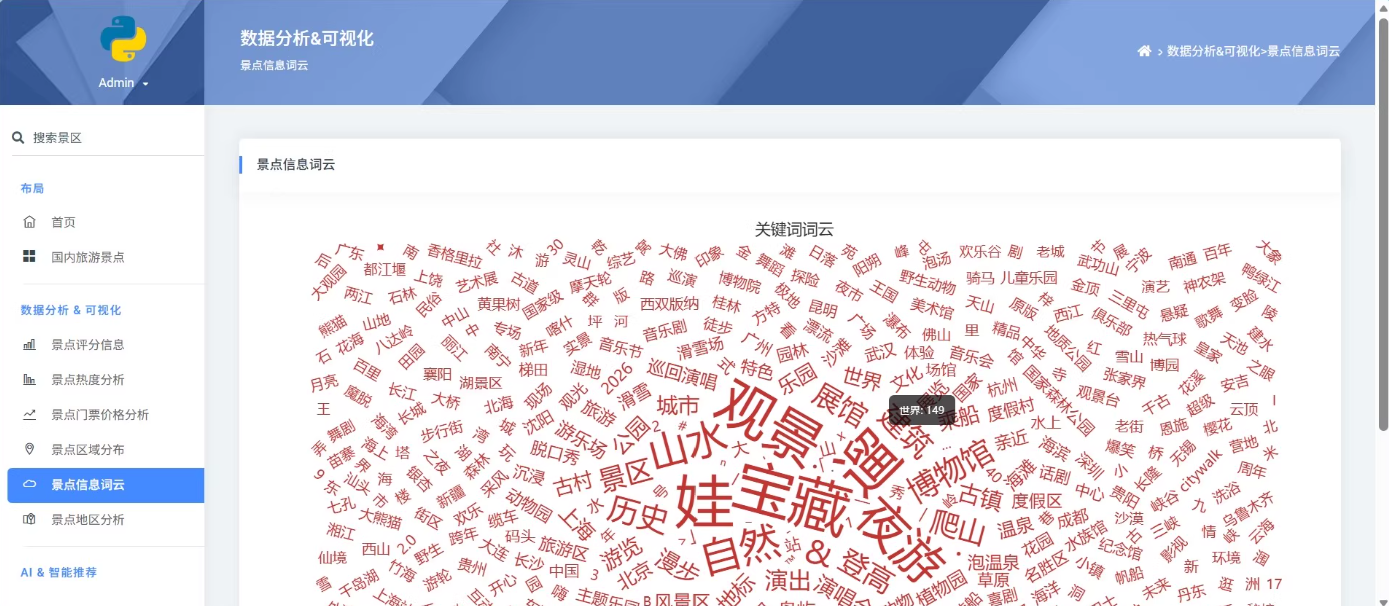
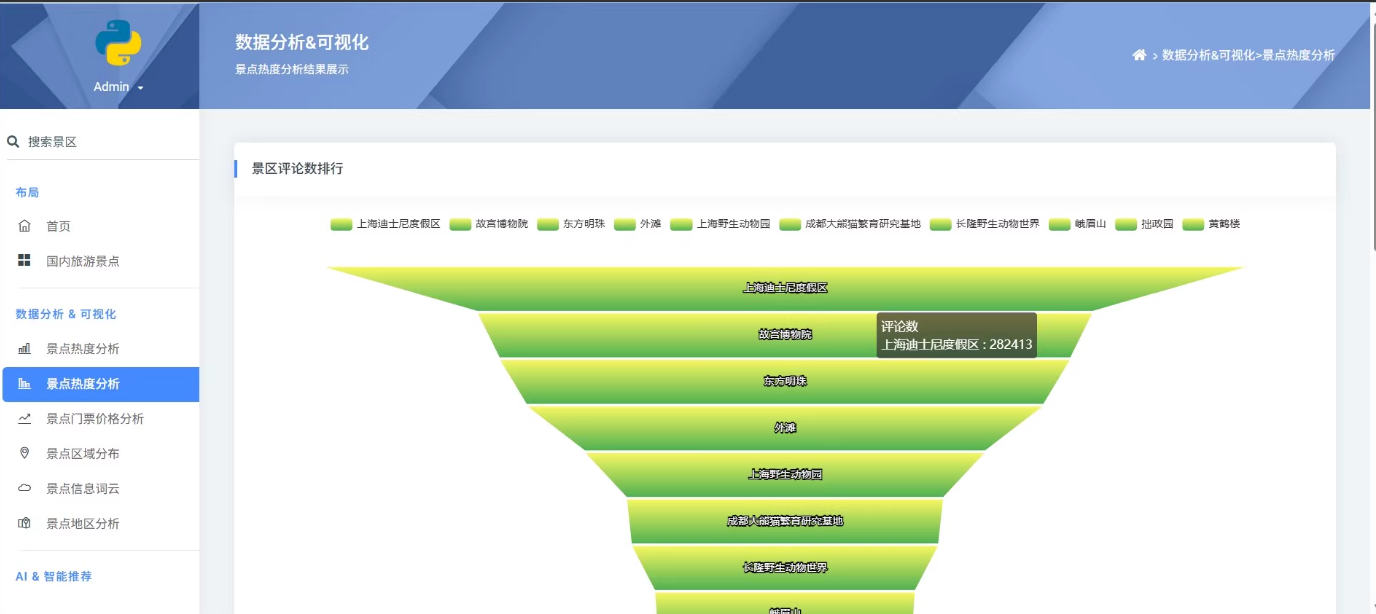
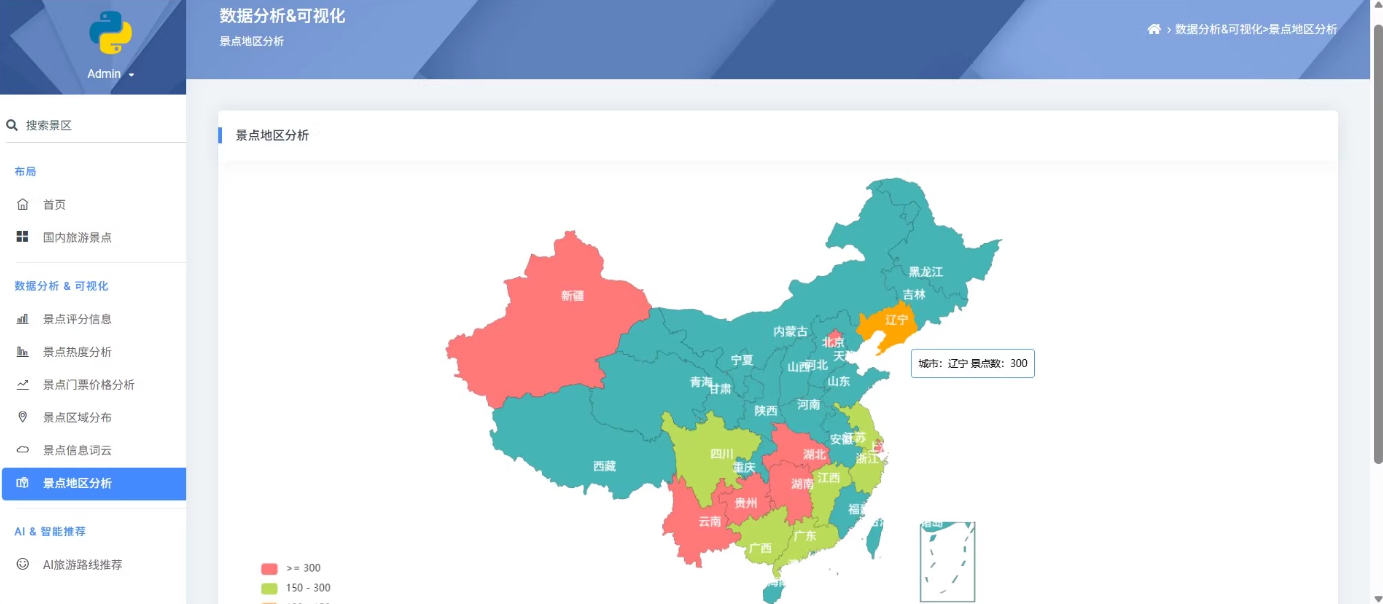
3.景点数据分析与可视化展示
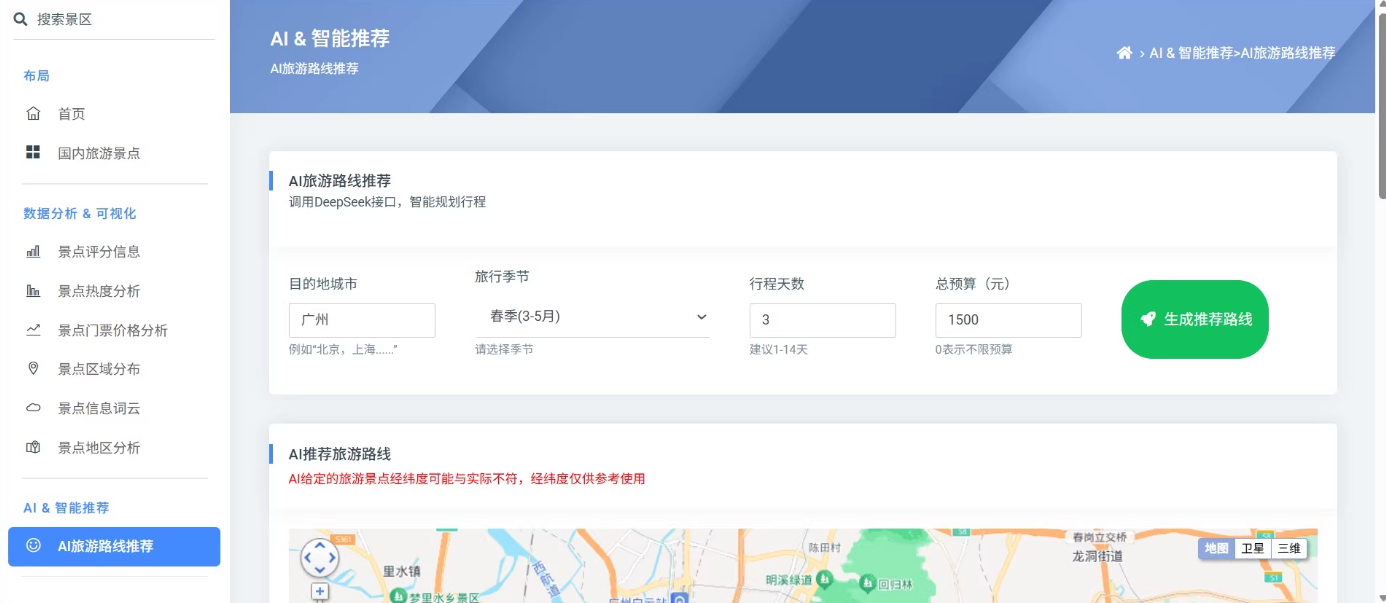
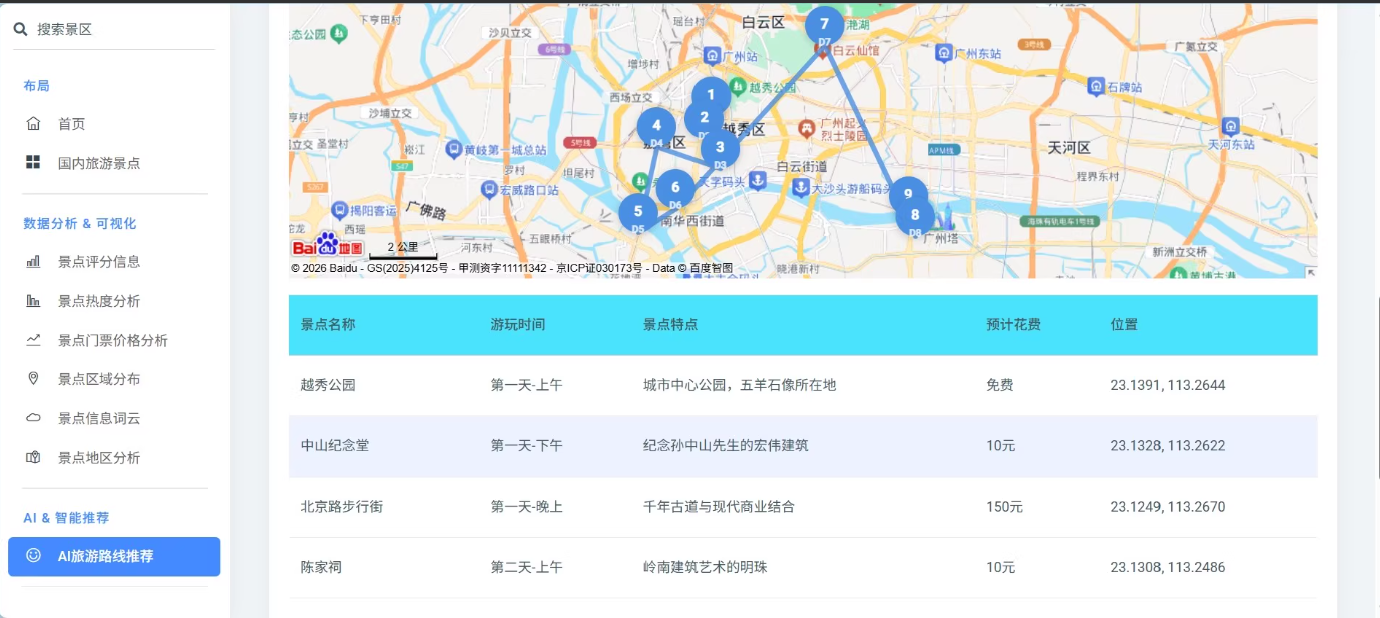
4.基于AI的个性化旅游路线推荐
系统通过爬虫技术从携程等旅游平台获取景点数据,经过数据清洗和分析后存储到MySQL数据库中。前端采用Bootstrap框架实现响应式设计,后端使用Django框架处理业务逻辑。
系统还集成了百度地图API和ECharts图表库,提供数据可视化功能。AI推荐模块通过调用DeepSeek大模型API,根据用户输入的城市、季节、预算和天数等信息,生成个性化的旅游路线推荐。
四、代码实现
from django.db import models
from django.contrib.auth.models import Userclass Scenery(models.Model):
"""景点模型"""
name = models.CharField(max_length=100, verbose_name='景点名称')
city = models.CharField(max_length=50, verbose_name='所在城市')
category = models.CharField(max_length=50, verbose_name='类别', blank=True) # 自然/人文/游乐场等
rating = models.FloatField(default=0, verbose_name='综合评分')
price = models.DecimalField(max_digits=8, decimal_places=2, default=0, verbose_name='门票价格')
image_url = models.URLField(blank=True, verbose_name='图片链接')
description = models.TextField(blank=True, verbose_name='景点描述')
def __str__(self):
return self.name
class Meta:
db_table = 'scenery'
class UserAction(models.Model):
"""用户行为记录(用于推荐算法)"""
ACTION_TYPES = (
('view', '浏览'),
('collect', '收藏'),
('like', '点赞'),
('rate', '评分'),
)
user = models.ForeignKey(User, on_delete=models.CASCADE, verbose_name='用户')
scenery = models.ForeignKey(Scenery, on_delete=models.CASCADE, verbose_name='景点')
action_type = models.CharField(max_length=20, choices=ACTION_TYPES, verbose_name='行为类型')
score = models.IntegerField(default=0, verbose_name='评分(1-5)') # 仅rate时使用
created_at = models.DateTimeField(auto_now_add=True)
class Meta:
db_table = 'user_action'
unique_together = ('user', 'scenery', 'action_type')import numpy as np
from collections import defaultdict
from django.db.models import Q
from django.contrib.auth.models import User
from .models import Scenery, UserAction
class CollaborativeFilteringRecommender:
"""基于用户的协同过滤推荐算法"""
def __init__(self):
self.user_similarity = {} # 存储用户相似度矩阵
self.user_ratings = {} # 存储用户-景点评分矩阵
def build_user_item_matrix(self):
"""
构建用户-景点评分矩阵
返回: user_ratings = {user_id: {scenery_id: score}}
"""
user_ratings = defaultdict(dict)
# 获取所有有效的评分行为(评分或点赞,点赞视为5分)
actions = UserAction.objects.filter(
Q(action_type='rate') | Q(action_type='like')
).select_related('user', 'scenery')
for action in actions:
user_id = action.user.id
scenery_id = action.scenery.id
# 评分:1-5分;点赞:默认5分
if action.action_type == 'rate':
score = action.score
else: # like
score = 5
user_ratings[user_id][scenery_id] = score
return user_ratings
def calculate_similarity(self, user1_ratings, user2_ratings):
"""
计算两个用户之间的余弦相似度
"""
# 找到两个用户共同评分的景点
common_items = set(user1_ratings.keys()) & set(user2_ratings.keys())
if len(common_items) == 0:
return 0
# 提取评分向量
vec1 = [user1_ratings[item] for item in common_items]
vec2 = [user2_ratings[item] for item in common_items]
# 计算余弦相似度
dot_product = sum(v1 * v2 for v1, v2 in zip(vec1, vec2))
norm1 = np.sqrt(sum(v ** 2 for v in vec1))
norm2 = np.sqrt(sum(v ** 2 for v in vec2))
if norm1 == 0 or norm2 == 0:
return 0
return dot_product / (norm1 * norm2)
def get_user_similarities(self, target_user_id):
"""
获取目标用户与其他所有用户的相似度
"""
if not self.user_ratings:
self.user_ratings = self.build_user_item_matrix()
if target_user_id not in self.user_ratings:
return {} # 新用户,无历史数据
target_ratings = self.user_ratings[target_user_id]
similarities = {}
for user_id, user_ratings in self.user_ratings.items():
if user_id == target_user_id:
continue
sim = self.calculate_similarity(target_ratings, user_ratings)
if sim > 0:
similarities[user_id] = sim
# 按相似度降序排序
return dict(sorted(similarities.items(), key=lambda x: x[1], reverse=True))
def recommend(self, user_id, top_n=10):
"""
为目标用户推荐景点
:param user_id: 目标用户ID
:param top_n: 推荐数量
:return: 推荐的景点列表
"""
# 获取相似用户
similarities = self.get_user_similarities(user_id)
if not similarities:
# 冷启动:返回热门景点
return self.get_hot_sceneries(top_n)
# 获取目标用户已交互过的景点
interacted = set()
actions = UserAction.objects.filter(user_id=user_id).values_list('scenery_id', flat=True)
interacted.update(actions)
# 加权计算候选景点的推荐分数
candidate_scores = defaultdict(float)
for similar_user_id, sim_score in list(similarities.items())[:20]: # 取前20个相似用户
# 获取相似用户的评分记录
user_ratings = self.user_ratings.get(similar_user_id, {})
for scenery_id, score in user_ratings.items():
if scenery_id not in interacted: # 排除已交互过的
candidate_scores[scenery_id] += sim_score * score
# 按推荐分数排序
sorted_candidates = sorted(candidate_scores.items(), key=lambda x: x[1], reverse=True)
recommended_ids = [scenery_id for scenery_id, _ in sorted_candidates[:top_n]]
# 如果推荐数量不足,补充热门景点
if len(recommended_ids) < top_n:
hot_ids = self.get_hot_sceneries(top_n - len(recommended_ids), exclude_ids=recommended_ids)
recommended_ids.extend(hot_ids)
# 返回景点对象
sceneries = Scenery.objects.filter(id__in=recommended_ids)
# 保持推荐顺序
order = {id: idx for idx, id in enumerate(recommended_ids)}
return sorted(sceneries, key=lambda x: order.get(x.id, 999))
def get_hot_sceneries(self, limit=10, exclude_ids=None):
"""获取热门景点(基于用户行为数量)"""
from django.db.models import Count
queryset = Scenery.objects.annotate(
action_count=Count('useraction')
).order_by('-action_count', '-rating')
if exclude_ids:
queryset = queryset.exclude(id__in=exclude_ids)
return list(queryset[:limit])
五、系统实现
六、源码 获取
大家点赞、收藏、关注、评论啦 、👇🏻获取联系方式在文章末尾👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)