06 从 MLP 到 LeNet:为什么线性模型不够用?
第6讲 为什么线性模型不够用?
线性模型几乎是很多机器学习入门内容的起点。它形式简单、训练高效、解释性也比较强,因此在很多基础任务中都非常常见。也正因为如此,一个很自然的疑问就会出现:
既然线性模型已经能够根据数据学习参数,为什么在一些问题上还是学不好?
这个问题并不只是“效果差”那么简单。很多时候,模型训练是正常进行的,参数也在更新,但结果始终达不到预期。遇到这种情况,问题不一定出在训练过程本身,也可能出在模型的表达能力上。
线性模型真正的局限,不在于它简单,而在于它只能表示线性关系。一旦数据中的规律超出了“直线”或“平面”所能表达的范围,线性模型就会遇到非常明确的边界。
1. 线性模型到底在做什么?
先从最基础的形式看,线性模型通常可以写成:
[
z = w_1 x_1 + w_2 x_2 + \cdots + w_n x_n + b
]
这里:
- (x_1, x_2, \dots, x_n) 是输入特征
- (w_1, w_2, \dots, w_n) 是对应的权重
- (b) 是偏置
- (z) 是模型输出的结果
如果这是一个分类问题,模型通常会根据这个结果来做判断,例如:
- (z > 0),判成一类
- (z < 0),判成另一类
从几何角度看,这相当于在特征空间里画出一个分界面:
- 在二维空间中,是一条直线
- 在三维空间中,是一个平面
- 在更高维空间中,是一个超平面
因此,线性模型最本质的能力其实可以概括成一句话:
用线性边界去分开不同类别。
这也是它名字里“线性”二字真正重要的地方。
2. 为什么线性模型在很多场景下都很好用?
线性模型之所以常常被作为起点,不只是因为它简单,更因为它在很多场景里确实有效。
2.1 结构清楚
每个参数都比较容易理解,模型形式也很直白。
2.2 计算高效
训练和推理都相对轻量,尤其适合快速建立一个基础模型。
2.3 可解释性强
如果某个特征对应的权重大,往往可以直接理解为这个特征对结果更重要。
对于那些类别边界比较规则、规律相对简单的问题,线性模型通常就已经足够好用了。
但问题在于:
并不是所有数据的规律都能用一条直线概括。
3. 线性模型的核心限制是什么?
线性模型最核心的限制在于,它只能表示线性关系。
这句话听起来有点抽象,但从分类角度看,可以把它理解成:
- 如果两类样本能被一条直线分开,线性模型就有机会学好
- 如果两类样本本身不是线性可分的,线性模型就会遇到根本性的困难
这里的关键不在于参数多少,也不在于训练时间长短,而在于模型能表达的边界形状是有限的。
无论参数怎么变,它最终能学出来的,本质上都还是线性的分界面。
所以有些问题的难点,并不是“还没训练好”,而是:
当前模型根本不具备表达正确规律的能力。
4. XOR 为什么会成为线性模型的经典反例?
最经典的例子就是 XOR(异或)问题。
先看下面这组数据:
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
它的规律很简单:
- 两个输入相同,输出 0
- 两个输入不同,输出 1
从逻辑上看,这个规则非常清楚。
但一旦把它画到平面上,就会发现问题出现了:正类和负类是交叉分布的(这世界上的事情,坏就坏在我中有你,你中有我)。
这意味着,不存在一条直线,能够把它们完全分开。
这就是 XOR 为什么重要。
它不是一个“难题”,而是一个非常典型、非常纯粹的反例,用来说明:
有些规律虽然非常清晰,但它们并不在线性模型能表达的范围内。
5. 先看二维图:为什么一条直线分不开 XOR?
先把 XOR 画到二维平面上,直观观察一下它的分布。
import matplotlib.pyplot as plt
import numpy as np
# XOR 数据
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 1, 1, 0])
plt.figure(figsize=(6, 6))
for i in range(len(X)):
if y[i] == 0:
plt.scatter(X[i, 0], X[i, 1], color='tomato', s=120, label='Class 0' if i == 0 else "")
else:
plt.scatter(X[i, 0], X[i, 1], color='royalblue', s=120, label='Class 1' if i == 1 else "")
plt.xlim(-0.2, 1.2)
plt.ylim(-0.2, 1.2)
plt.xticks([0, 1])
plt.yticks([0, 1])
plt.xlabel("x1")
plt.ylabel("x2")
plt.title("二维空间中的 XOR 分布")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
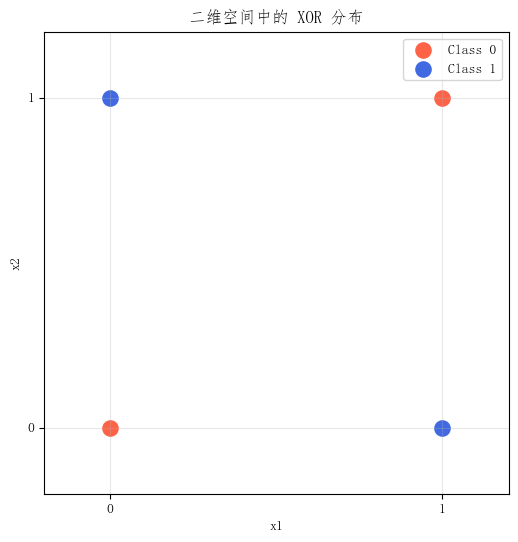
图 1: 二维空间中的 XOR 分布。正类和负类交叉分布,无法用一条直线完全分开。
这张图的价值非常直接。只要看一眼,就能明白问题出在哪里:
- 左下角和右上角是一类
- 左上角和右下角是另一类
这是一种交叉结构。
而一条直线只能把平面切成两半,却无法处理这种交叉关系。
所以这里的核心结论非常明确:
在原始二维空间里,XOR 本身就不是线性可分的。
6. 用线性模型实际试一下,会发生什么?
从图上已经能看出问题,但如果再用一个线性模型实际跑一下,结论会更有说服力。
import numpy as np
from sklearn.linear_model import LogisticRegression
# XOR 数据
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 1, 1, 0])
model = LogisticRegression()
model.fit(X, y)
pred = model.predict(X)
print("真实标签:", y)
print("预测结果:", pred)
print("准确率:", np.mean(pred == y))
输出:
真实标签: [0 1 1 0]
预测结果: [0 0 0 0]
准确率: 0.5
这段代码的重点不在于具体准确率是多少,而在于说明一个事实:
即使模型正常训练,面对 XOR 这种非线性可分的问题,它依然学不出真正正确的边界。
这里的问题不是逻辑回归失灵了,而是逻辑回归本质上仍然是线性模型。
它能做的,依然只是寻找一个线性分界面。
如果正确答案不在线性模型能表示的函数空间里,那么再怎么调参数,也很难得到真正理想的结果。
7. 这不是训练问题,而是表达问题
这是理解线性模型局限时最容易被误解的地方。
当模型效果不好时,最常见的第一反应往往是:
- 数据不够多
- 训练不够久
- 学习率没调好
- 参数还没找到合适值
这些因素当然都可能影响结果。
但对于 XOR 这类问题,更关键的矛盾并不在训练细节,而在模型能力边界。
可以这样理解:
- 训练是在已有模型空间里找更好的参数
- 但如果正确答案本身就不在这个空间里
- 那参数再怎么优化,也找不到真正合适的解
所以这类问题不是“还没训好”,而是:
模型本身就不具备表达这类规律的能力。
这也是为什么“线性模型不够用”是一个结构性问题,而不是一个简单的调参问题。
8. 把 XOR 映射到三维空间之后,会发生什么?
二维图已经说明了 XOR 在原始空间里为什么不可分。
但这个问题还有一个更有启发性的观察角度:
原始二维空间里线性不可分,不代表换一种表示之后仍然不可分。
对于 XOR,一个很经典的做法是加入一个新特征:
[
z = x_1 \cdot x_2
]
这样,原来的二维点:
[
(x_1, x_2)
]
就被映射成了三维点:
[
(x_1, x_2, x_1x_2)
]
这个变化的意义很大。因为它说明,问题不一定出在数据没有规律,也可能出在当前表示方式不够好。
9. 看看三维图:数据表示改变之后,结构会发生什么变化?
下面把 XOR 映射到三维空间中看看。
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
# XOR 数据
X = np.array([
[0, 0],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 1, 1, 0])
# 新特征 z = x1 * x2
Z = X[:, 0] * X[:, 1]
fig = plt.figure(figsize=(7, 6))
ax = fig.add_subplot(111, projection='3d')
for i in range(len(X)):
if y[i] == 0:
ax.scatter(X[i, 0], X[i, 1], Z[i], color='tomato', s=120, label='Class 0' if i == 0 else "")
else:
ax.scatter(X[i, 0], X[i, 1], Z[i], color='royalblue', s=120, label='Class 1' if i == 1 else "")
ax.set_xlabel("x1")
ax.set_ylabel("x2")
ax.set_zlabel("x1 * x2")
ax.set_title("三维空间中的 XOR 映射")
ax.legend()
plt.show()
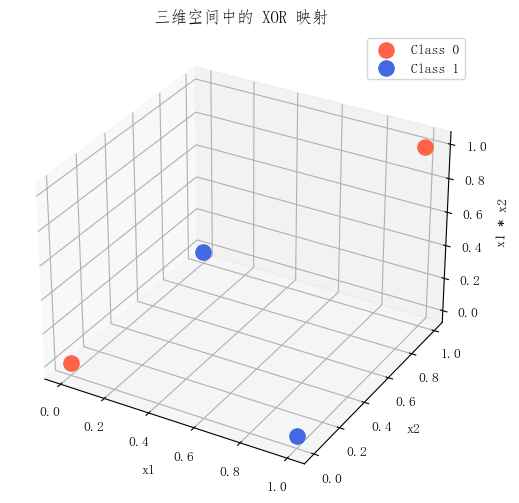
图 2: XOR 映射到三维空间后的分布。引入新特征 (x_1x_2) 后,原始二维空间中的交叉结构发生了变化。
这张图真正想说明的不是“升维一定能解决问题”,而是:
- 原始表示方式会影响数据的可分性
- 同样一组数据,在不同表示空间里结构可能完全不同
- 更强的模型,本质上往往是在学习更适合任务的表示方式
从这个角度看,XOR 的意义就不仅仅是“证明线性模型不行”,而是进一步说明:
模型表达能力的提升,往往来自更灵活的特征表示。
10. 线性模型不够用,真正推动了什么?
线性模型的局限并不只是一个失败案例,它实际上推动了后续很多更强模型的发展。
问题的关键不是“线性模型为什么不好”,而是:
如果一条直线不够,模型还能不能学出更复杂的边界?
这也是后面一整类模型出现的根本原因:
- 感知机
- 多层感知机
- 非线性激活函数
- 更深的神经网络
这些方法的共同目标,并不是单纯“让模型变大”,而是让模型具备表示非线性关系的能力。
因此,线性模型不够用这件事,本质上不是一个结论,而是一个起点。
11. 最容易混淆的几个点
11.1 线性模型效果不好,一定是训练没做好
不一定。
有些问题不是训练不够,而是模型本身没有足够的表达能力。
11.2 线性模型不能处理复杂问题,所以没有价值
不是。
线性模型在很多简单任务中依然有效,而且是理解更复杂模型的重要起点。
11.3 只要增加参数,线性模型就会变强
不一定。
即使参数变多,只要模型本质上仍然是线性的,它的表达能力边界仍然存在。
11.4 XOR 只是一个小例子,没有现实意义
不是。
XOR 的价值就在于它把“线性模型无法表示非线性关系”这件事暴露得非常清楚。
12. 总结
线性模型的问题,不在于它简单,而在于它只能表示线性关系。
当数据中的规律能够被一条直线或一个平面分开时,它会非常有效;但当类别边界变得更复杂时,线性模型的表达能力就会遇到非常明确的上限。
XOR 是一个最经典的例子。二维图说明了它为什么在线性空间里不可分,三维图则进一步说明:问题有时并不只是“模型没学会”,而是“当前表示方式不够”。
如果把全文压缩成一句话,可以概括为:
线性模型不够用,不是因为它不会训练,而是因为它只能画直线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)