建堆方法及其效率讲解
1. 建堆方法
1.1 向上调整算法建堆
时间复杂度为O(N*logN)
这个方法更容易让学者理解,当我们在一个数组上建堆时(默认建小堆),每一个数据进来,就向上调整一次.实现代码如下:
void SWap(HPDataType* x, HPDataType* y)
{
assert(x && y);
HPDataType temp = 0;
temp = *x;
*x = *y;
*y = temp;
}
//向上调整算法
void AdjustUp(HPDataType* a, int child)
{
//调成小堆
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
//交换
SWap(&a[child],&a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//
//完成建堆
int main()
{
int i = 0;
int a[] = { 4,2,8,1,5,6,9,7 };
for(i = 1;i < n;i++)
{
AdjustUp(a,i);
}
return 0;
代码解释:我们是在数组上建堆,所以向上调整算法的第一个参数,是我们数组的地址,而第二个参数就是每次要插入数据的下标. i从一开始,表明我们假设第一个数据为堆
实际我们在建堆其实不会使用这种方法 ,因为效率没有向下调整法建堆好。
下面推导向上调整算法建堆的时间复杂度。
1.11. 向上调整算法建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的 就是近似值,多几个结点不影响最终结果):
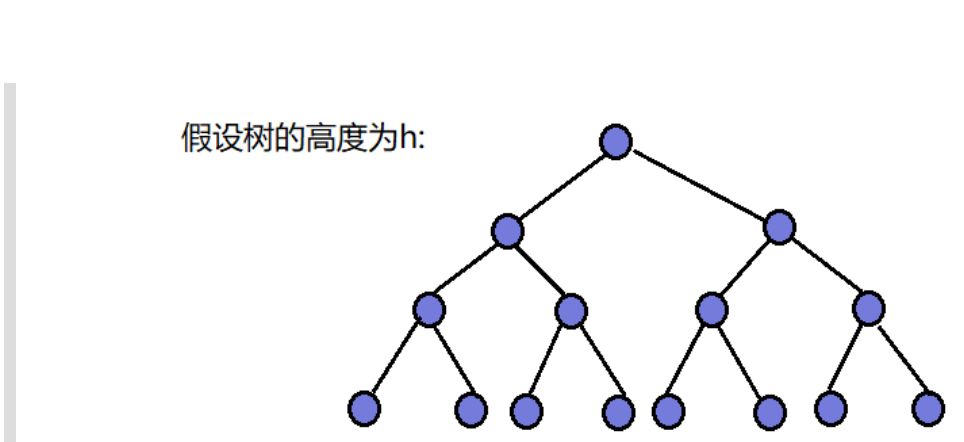
我们假设树的高度为h,因为向上调整算法是从最后一层开始调整,即第h层开始调整
故第h层:有2^(h-1)个结点,每个结点需要调整次数为(h-1)次。
第h-1层:有2^(h-2)个结点,每个结点需要调整次数为(h-2)次。
……
第2层:有2^1个结点,每个结点需要调整次数为 1 次。
第1层:有2^0个结点,每个结点需要调整次数为 0 次。
故我们可以列出方程:
使用向上调整算法建堆,总共需要调整 T(h)次
T(h) = 2^0* 0 + 2^1* 1 + ...... + 2^(h-2)* (h-2) + 2^(h-1)*(h-1);
由数学知识可知,该式子由等比乘以等差数列构成,故使用错位相减法
解得 : T(h) = 2^h *(h -2) -1;
我们已知结点个数N和高度h的关系:
N = 2^0 + 2^1 + 2^2 + ...... + 2^(h-1) = 2^h -1;
联立两式得调用次数和结点个数的关系
T(N) = (N+1)*log_2 (N+1) -2N -1;
故时间复杂度为 O(N * logN)。
1.2 向下调整法建堆
时间复杂度为O(N);
(假设建小堆)首先我们知道向下调整法建堆的前提是: 左子树和右子树都为小堆。
那如果我们二叉树从上往下开始调整是完不成的,因为不能满足调整的前提,那我们考虑倒着来调整,从下往上调整,那么每次调整的前提就都能满足了。
且最后一层的结点是不需要调整的,因为最后一层的结点没有子树。
所以我们应该从倒数第一个非叶子结点开始调整
下面给出,向下调整法建堆的代码:
void SWap(HPDataType* x, HPDataType* y)
{
assert(x && y);
HPDataType temp = 0;
temp = *x;
*x = *y;
*y = temp;
}
//调小堆
void AdjustDown(HPDataType* a, int n, int parent)
{
//找孩子中更小的那个与父亲交换
//假设法//假设是左孩子
int child = (parent * 2) + 1;
while (child < n)//循环结束条件,是parent没有孩子就结束
{
//可能只有左孩子没有右孩子,这时后就越界访问了
if (child + 1 < n && a[child + 1] < a[child])///注意!!!
{
//右孩子更小
child = child + 1;
}//不管情况怎么样,child一定指向更小的孩子
if (a[parent] > a[child])
{
//交换
SWap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//测试向下调整算法建堆
int main()
{
for (int i = (n - 1 - 1) / 2; i >= 0;i--)
{
AdjustDown(a, n ,i);
}
return 0;
}注意,这里的n是有效数据个数,所以 n-1为 最后一个数据,(n -1 -1)/2表示倒数第一个非子叶,所以表明我们从倒数第一个非子叶开始向下调整。这样就可以完成建堆
下面讲解这种算法建堆的原理和时间复杂度的推导
1.21. 向下调整算法建堆的时间复杂度
同样使用满二叉树来讲解
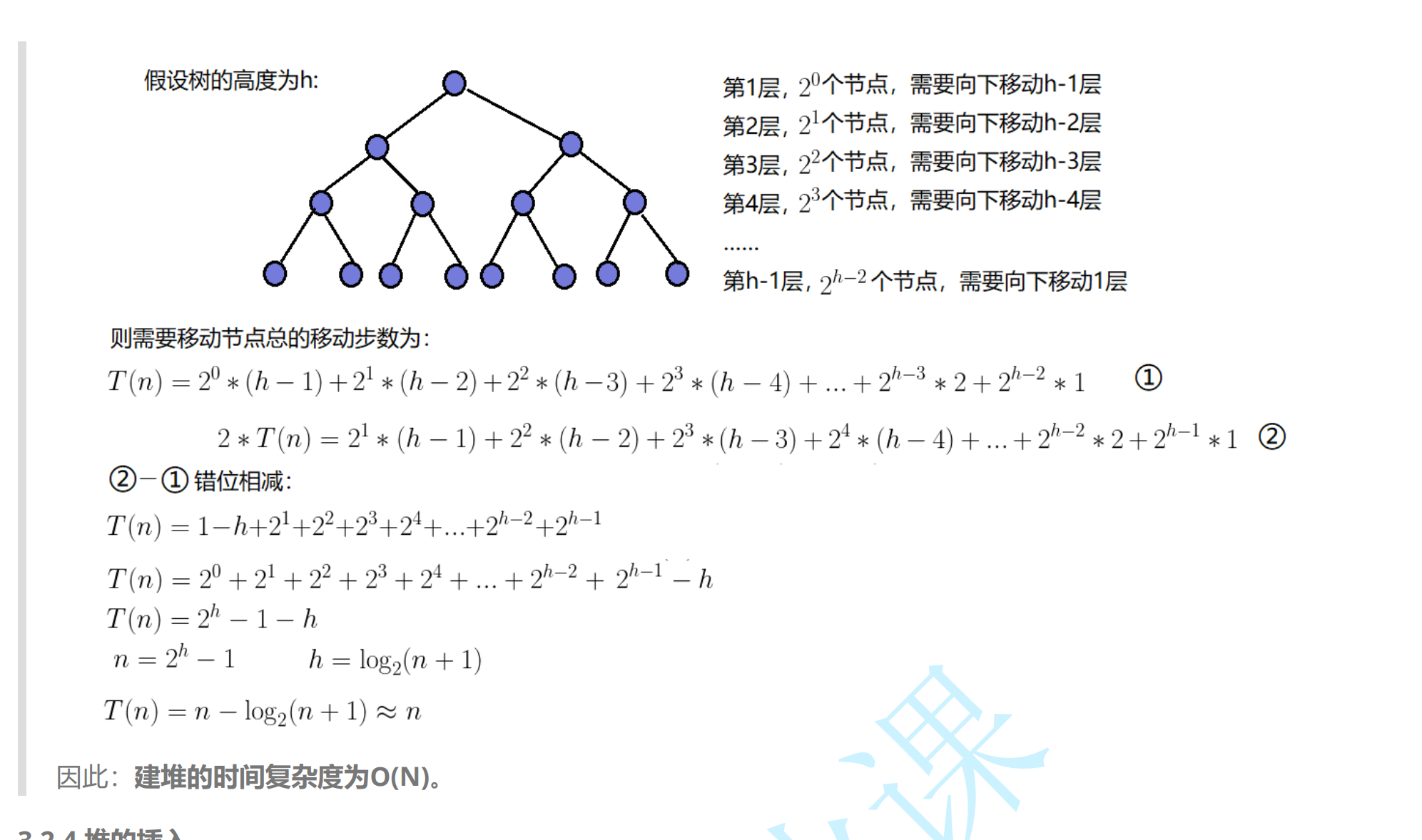
也是与向上调整算法建堆方法的推导逻辑相同。
1.3 两种方法的比较
通过上述的计算,我们得知了向下调整算法建堆的时间复杂度更优。
下面简单阐述为什么。
首先我们知道向上调整算法建堆要从最后一层开始调整,并且最后一层的结点数为 2^(h-1) ,占总结点数的一半还要多一点,那么其效率肯定是没有后者好的,归纳为 多节点 * 多调用次数
而向下调整算法建堆,最后一层结点是不用向下调整的,且 因为每一层是向下调整,而结点越多的层向下调整的次数也越小,比如说第一层,虽然说要向下调整h-1次,但是第一层只有一个结点。所以归纳为 少结点 *少调用次数。
总的来说,向下调整算法建堆是更好的,且我们在实际中也基本上只会使用它。
那么建完堆我们就可以进一步实现堆排序了;

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)