通过未充分利用的输出特征增强人群分析中的检测(CVPR2023)
摘要
基于检测的方法由于在密集人群中表现不佳,在人群分析中被认为是不利的。然而,我们认为这些方法的潜力被低估了,因为它们为人群分析提供了经常被忽视的关键信息。具体来说,输出提案和边界框的面积大小和置信度得分提供了对人群规模和密度的洞察。为了利用这些未被充分利用的功能,我们提出出了CrowdHat,这是一个即插即用的模块,可以很容易地与现有的检测模型:集成。该模块使用混合2D-1D压缩技术来细化输出特征,并获得特定人群信息的空间和数值分布。基于这些特征,我们进一步提出了区域自适应NMS阈值和解耦-然后对齐范式,以解决基于检测的方法的主要局限性。我们对各种人群分析任务(包括人群计数、定位和检测)进行了广泛的评估,证明了利用输出特征的有效性以及基于检测的方法在人群分析中的潜力。
1、代码和数据集
1.1 文章代码链接:https://github.com/wskingdom/Crowd-Hat
1.2 数据集:JHU-Crowd++ [22]、UCF-QNRF[6]和NWPU-Crowd[28]
2、存在的问题
基于检测的方法由于在密集人群中表现不佳,在人群分析中被认为是不利的。然而,我们认为这些方法的潜力被低估了,因为它们为人群分析提供了经常被忽视的关键信息。具体来说,输出提案和边界框的面积大小和置信度得分提供了对人群规模和密度的洞察。
检测方法仅限于使用由点标签生成的伪边界框进行训练。然而,这些伪边界盒的低 劣质量使得神经网络难以获得有效的监督。
不同图像之间的人群密度差异很大,从0到数万不等,并且在同一图像的不同区域之间可能存在差异,这给非最大抑制(NMS)中选择允许的重叠区域带来了重大挑战。
当前的检测方法采用检测计数范式进行人群计数,其中通过从检测输出中获得的边界框来计 数人的数量。然而,如果没有边界框标签进行训练,人 群检测任务极具挑战性,导致人群中出现大量的误标记和无法识别的盒子。这种不准确的检测结果使得 检测计数范式表现不佳,与基于密度的方法相比,产生的计数结果较差。
虽然最先进的人群计数方法是基于密度的,但它们往往忽略了空间信息,导致个体精确定位和人群头部的边界框提供性能不佳。
虽然这些方法在定位方面 优于基于密度的方法,但其计数性能普遍较差,在满足人群检测需求方面仍有不足。
检测的基本能力通常需要大量的边界框标签进 行训练,而这些标签在许多人群数据集中通常是不可用 的[5,6,38]。只有少数方法,如[16,20,30],尝试用由点 注释生成的伪盒标签来训练检测网络。然而,由于固定 的NMS过程,这些方法存在不准确的边界框,从而导 致太多的误报。因此,基于检测的方法通常在计数和定 位任务中表现较差。
基于检测的人群计数方法存在使用检测计数范式的 缺点[16,20,30],其中通过计算输出边界框的数量来预 测人群计数。这种范式导致计数性能与检测和定位结果 之间的纠缠,考虑到数据集通常只提供点注释,这尤其 成问题操作,导致对训练检测管道的监督有限。
3、 文章创新点
我们首先引入混合2D-1D压缩,以细化检测管道输出特征的空间和数值分布。我们进一步提出了一种NMS解码器,从这些特征中学习区域自适应NMS阈值,有效 地减少了低密度区域下的误报和高密度区域下的误报。 此外,我们使用解耦-然后对齐范式,通过从输出特征中回归人群计数并使用该预测计数来指导边界框选择, 从而提高计数性能。我们的人群帽模块可以集成到各种单阶段和两阶段的目标检测方法中,为人群分析任务带 来显著的性能提升。
3.1 初步
我们论文中的所有方法都只使用点注释进行训练, 以确保公平的比较[6,28,38]。因此,我们按照惯例[16,20, 30],从点注释中生成伪边界框标签,用于训练所有检测方法。
3.2 方法:人群论
我们将检测输出定义为来自检测管道的预测边界框和建议。,我们采用了两个输出特征,即来自检测输出的 “面积大小”和“置信度得分”。与从卷积层中提取的 特征图(CNN特征)相比,输出特征主要关注人类,即图 像的前景,并且被认为是相对“纯粹”的特征,用于人 群分析任务。因此,我们提出了人群帽模块来挖掘和利 用这些输出特征,如图2所示。在本节中,我们使用两 阶段检测方法PSDNN[16]作为检测管道,其他一阶段检 测方法[20,30]可以很容易地适应。
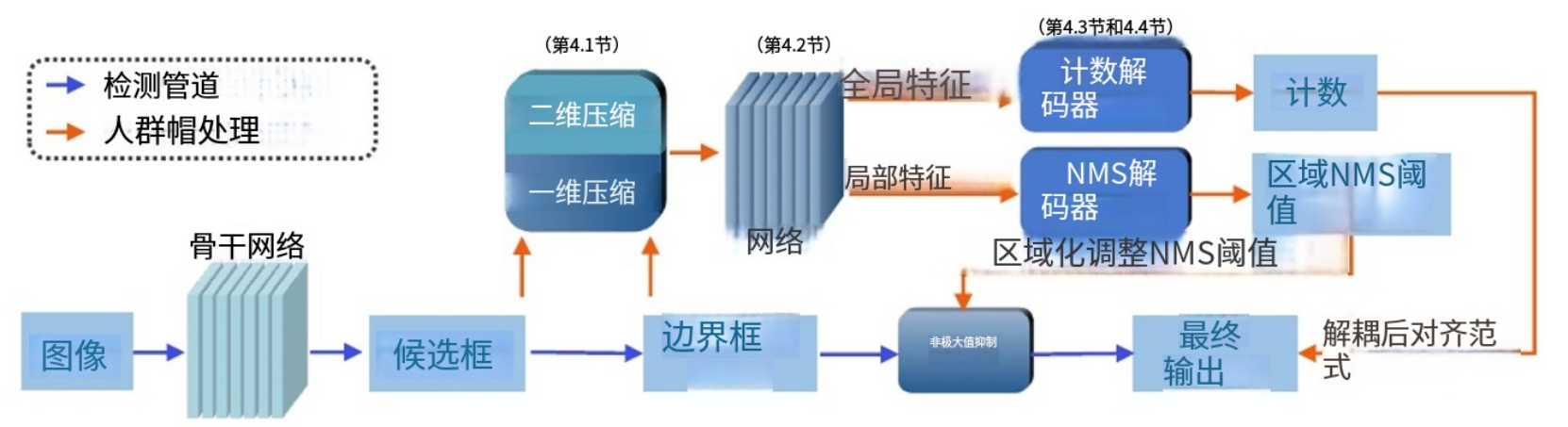
3.2.1 输出特征压缩
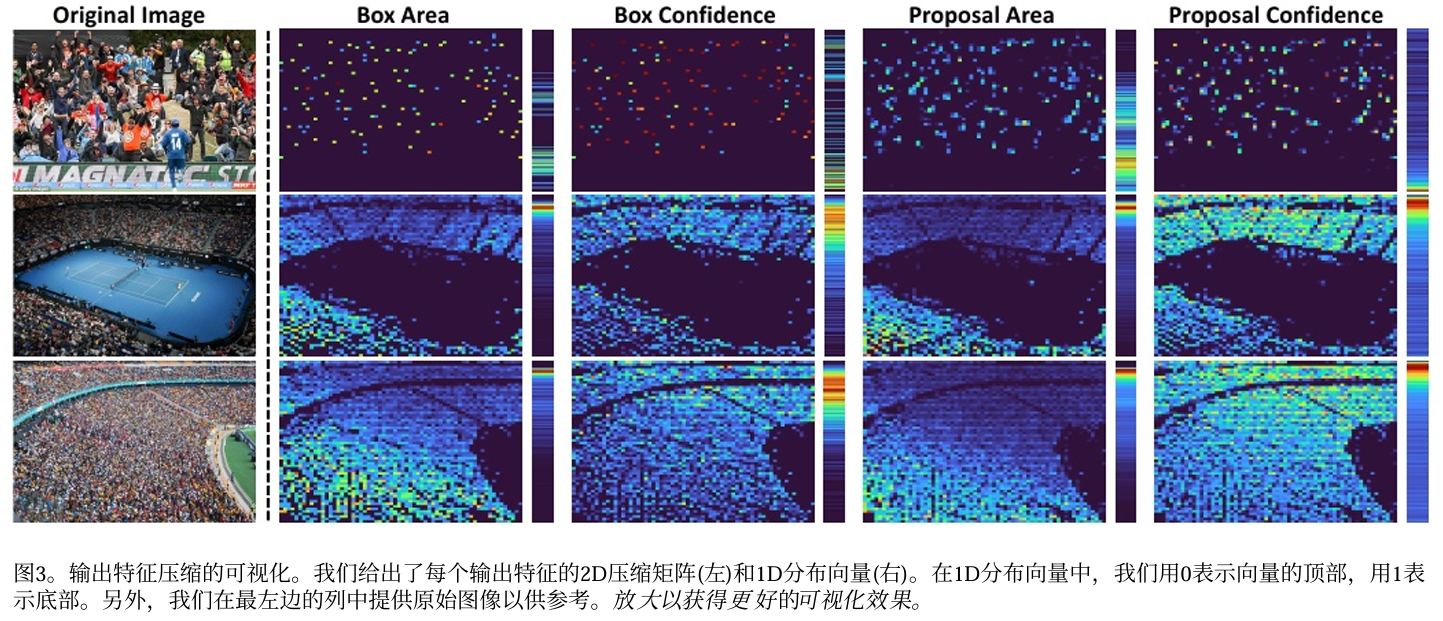
由于预测的提案或边界框的数量远远小于每张图像的 像素数量,因此生成的特征映射将过于稀疏而无法传达 代表性信息。为了解决这一问题,我们提出了一种混合2D-1D压缩方法,进一步细化 输出特征,获得这些人群特定信息的空间和数值分布。 我们在图3中展示了2D-1D压缩方法的不同特征的可视化结果。
3.2.1.1 2D压缩
为了确定图像中人群密度的空间分布,我们提出了使用 矩阵M∈RS×S将每个输出特征压缩成patch的2D压缩。 我们根据提议或边界框的中心坐标将其映射到输入图像 上,将图像划分为S个等高和等宽的×S patch,并将位 于每个patch内的每个输出feature求和,得到压缩矩阵M 中对应的元素。
考虑使用压缩矩阵来压缩边界框面积。为了计算第 k个边界框的归一化面积,我们将其宽度乘以图像高度, 并将结果除以图像宽度和高度的乘积。这个归一化步骤 消除了不同图像分辨率的影响。
我们使用表示法MB C来表示包围盒置信度分数的压 缩矩阵,分别使用MP A和MP C来表示提案面积大小和置 信度分数的压缩矩阵。如果一阶段检测方法没有生成提 案,我们只使用MB A和MB C作为压缩矩阵。这些矩阵的 正式定义如下:
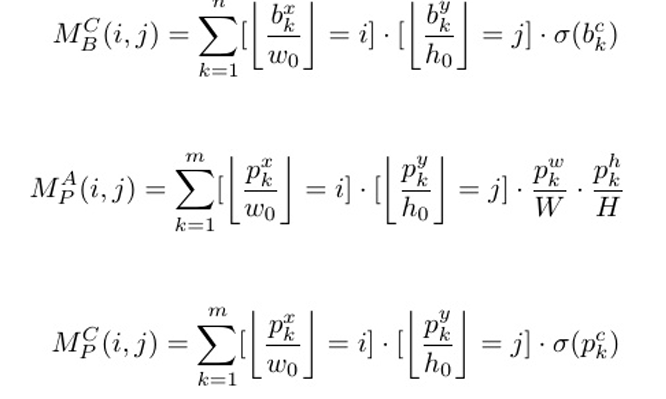
3.2.1.2 1D压缩
图像内部和图像之间的人群密度差异很大,有些图像的 密度从0到数万不等。为了确定图像的整 体人群密度,我们提出了一种1D压缩方法,该方法可以找到图像内输出特征的数值分布。
我们提出的1D压缩方法的工作原理如下:首先,我们将置信度得分和面积大小值归一化到0到1的范围内。接下来,我们将这个范围划分为L个离散区间,其中第i个 区间为[Li, i+1L)。然后,我们计算落在每个区间内的值的数量,形成直方图,并获得数值分布,直方图的第i个值 表示落在区间[Li, i+1L)内的值的数量。
为了将输出特征归一化为0到1的区间,我们使用两步过程。首先,我们将输出特征乘以一个尺度系数α≥1,这是一个超参数。这一步是 必要的,以确保非线性映射后输出特征的分布是可区分 的。面积大小和置信度评分的原始值可能在数值上拥挤, 导致它们在非线性映射后落入相同的区间或附近的区间。 其次,我们对输出特征应用非线性映射函数,将其范围 限制为[0,1]。注意,面积大小总是大于零,而置信度可以是正的也可以是负的,因此我们使用sigmoid函数σ(x) 作为置信度评分,使用双曲正切函数tanh(x)作为面积大 小。
3.3 Crowd Hat网络
为了聚合来自上述不同输出特征的信息,我们将 2D压缩矩阵堆叠成一个张量t2d∈RC×S×S,将1D压 缩的分布向量堆叠成一个张量t1d ∈RC× L。这里,C是使 用的输出特征的数量,对于两阶段方法,C = 4,对于 单阶段方法,C = 2。然后将这些张量传递到我们的 Crowd Hat网络中以获得全局和局部特征,如下所述。 详细结构如图4所示。
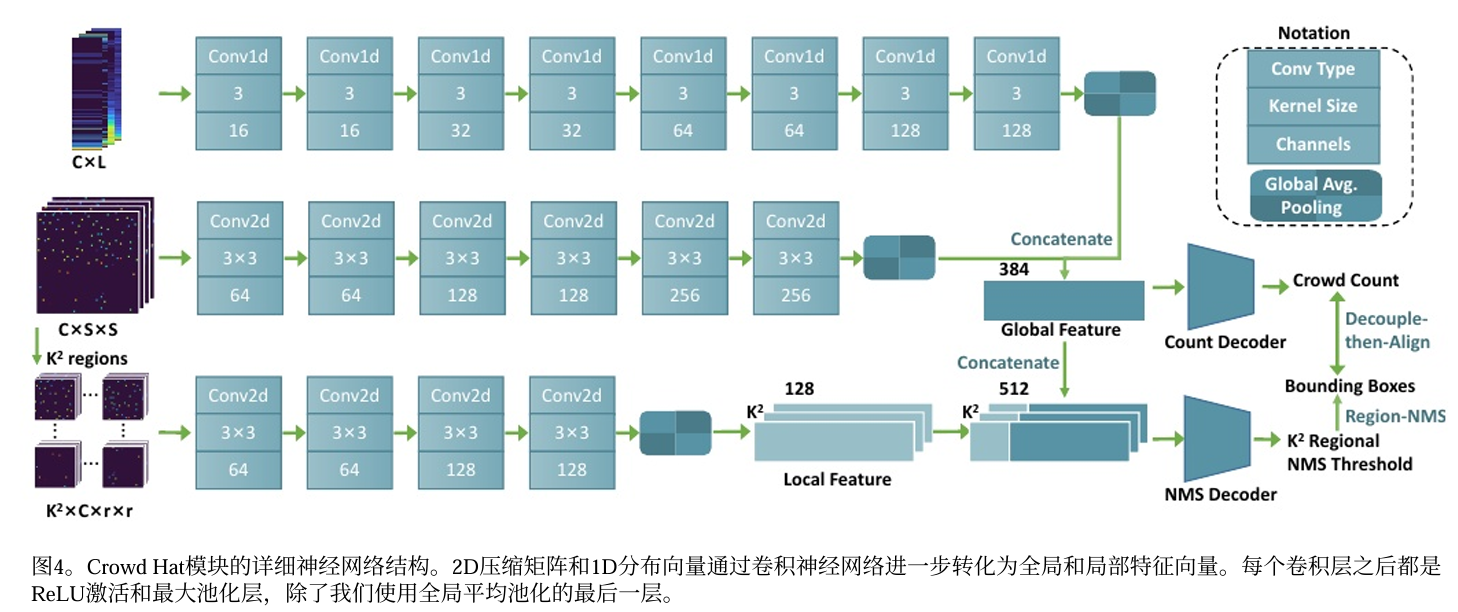
全局特征为了结合t2d 的空间信息和t1d 的数值分布信息, 我们使用2D卷积对t1d 进一步编码t2d 和1D卷积,如图4所 示。在全局平均池化之后,我们将两者连接起来,形成 全局特征向量Fg。
为了捕获图像中人群密度的高变化并支持我们的区域自 适应NMS,我们通过将t2d 划分为固定大小的补丁并使 用神经网络对其进行编码来引入局部特征。我们将t2d 分 割成K个×K小块,然后通过具有全局平均池化的2D卷 积神经网络传递它们,生成局部特征向量[Fl1,Fl2,... FlK2]。
3.4 区域自适应NMS解码器
我们提出了一个NMS解码器来解决不同地区人群 密度的挑战。区域自适应NMS方法学习每个区域的最优NMS阈值,使用当前的伪边界框标签最大化F1分数。确定每个区域的伪NMS阈值标签[T1 ,T2 ,…] [TK2 ],我们使用线性搜索算法,以固定步长s衡量不同 NMS阈值(从0到1)下的模型性能,并选择每个区域F1得 分最高的NMS阈值。
为了训练我们的NMS解码器,我们将局部和全局 特征连接起来,并通过MLPPN 传递它们,以生成区域 自适应的NMS阈值。我们直接回归伪NMS阈值标签进 行训练。区域NMS损失定义如下:
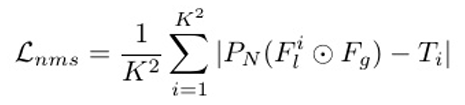
其中⊙表示串联。
在推理过程中,我们使用从NMS解码器中学习到 的伪NMS阈值标签进行区域自适应NMS。对于每个区 域,我们使用相应的伪NMS阈值标签作为NMS阈值, 过滤掉冗余的边界框。由于不同的区域可能有不同的人 群密度,区域自适应NMS可以在人群密度高的区域过 滤掉更多冗余的边界框,在人群密度低的区域保留更多 的边界框,从而获得更好的性能。
3.5 解耦-然后对齐范式(decoupling -then- align)
为了解决这个问题,我们建议通过使用全局特征Fg 直接回归人群计数来解耦检测和计数过程。 与一些早期 使用CNN特征进行计数回归的方法不同,我们使用的 输出特征提供了有价值的特定于人群的信息,使其更适 合于直接计数回归。我们使用一个单独的MLP,称为 计数解码器PC ,来预测人群计数n =PC (Fg ),该计数由从 点注释获得的地面真实人群计数来监督。损失函数的表 述如下:
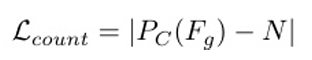
然而,由于回归和检测过程之间的结果不一致,使 用单独的计数回归可能会造成混淆。网管过滤nc 后生成 的边界框个数可能与计数解码器n´的计数输出不一致, 导致不确定引用哪个数字。为了解决这个问题,我们优 先考虑计数解码器的准确性和可靠性,并选择具有最高 置信度的最小(-n,nc ))边界框作为最终结果。
4、 结论与不足
在本文中,我们提出了一个人群帽模块,以利用检 测管道中未充分利用的边界盒和提案的输出特征来进行 人群分析任务。我们在三种不同的人群分析任务下进行 了广泛的评估,证明了我们方法的有效性,并强调了在 人群分析中使用输出特征作为有价值资产的潜力。
局限性和未来的工作。我们表明,面积大小和置信度得 分与人群分布有很强的对应关系,但可能存在潜在的更 好的特征更有效。此外,由于1D压缩不可微,我们的模 型不能以端到端方式进行训练。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)