注意力残差:Kimi如何用“选择性记忆”做到将计算效率提升1.25倍,训练效率提升25%,而推理延迟的增加低于2%?
论文标题:Technical report of Attention Residuals
(注意力残差技术报告)
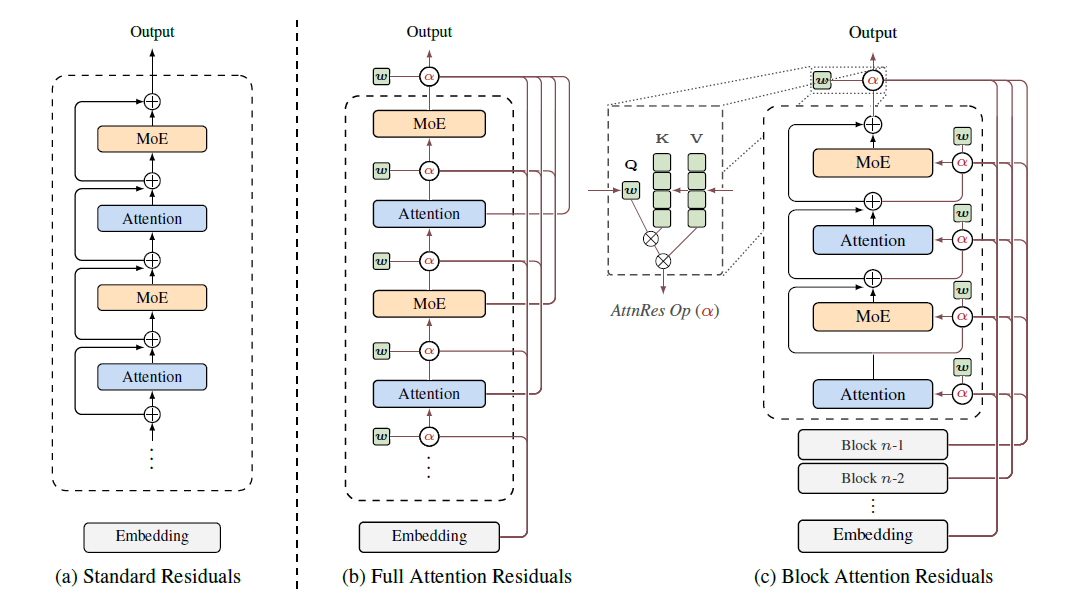
论文主题:用“注意力残差”(AttnRes)替代传统的“残差连接”(Residual Connections),让模型在深度堆叠时能更智能地选择和利用信息。
论文链接↓↓↓
https://arxiv.org/pdf/2603.15031
《注意力残差 (Attention Residuals)》论文解读
1. 一句话总结
Kimi 团队提出了一种名为“注意力残差 (Attention Residuals,简称AttnRes)”的新型网络连接范式,利用“时间与深度的对偶性”,将 Transformer 中的注意力机制从“序列维度”迁移到“深度维度”,用可学习的 Softmax 权重替代传统的固定残差累加,解决了深层网络中的信息稀释 (Dilution) 问题,在几乎不增加推理成本的情况下显著提升了模型性能。

2. 背景与问题:标准残差的“阿喀琉斯之踵”
现代大模型(LLM)普遍采用 PreNorm + 残差连接 (Residual Connection) 的结构。虽然残差连接解决了梯度消失问题,但随着模型层数 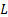 的增加,它暴露出了严重的局限性:
的增加,它暴露出了严重的局限性:
- 信息稀释 (Dilution): 标准残差公式为
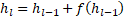 。展开后,第
。展开后,第 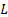 层的输入实际上是所有前面层输出的等权重累加。随着深度增加,隐藏状态的幅度
层的输入实际上是所有前面层输出的等权重累加。随着深度增加,隐藏状态的幅度 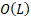 线性增长,导致每一层的相对贡献被无限稀释(就像一滴墨水滴入不断变大的湖泊中)。
线性增长,导致每一层的相对贡献被无限稀释(就像一滴墨水滴入不断变大的湖泊中)。 - 缺乏选择性: 传统残差像一个“无脑搬运工”,不管前面层的信息是否有用,都一股脑加进来。它无法像注意力机制那样,根据内容选择关注哪些 Token。
- PreNorm 的副作用: 为了稳定训练,PreNorm 强制隐藏状态归一化,这导致深层网络必须输出巨大的梯度才能对抗归一化,造成训练动态极不均衡(深层梯度大,浅层梯度小)。
3. 核心方法:从 RNN 到 Transformer 的深度复刻
“将注意力旋转 90°”——论文作者之一 Yulun Du
论文的核心洞察是:“序列维度 (Time) 的 RNN 到 Transformer 的演进,应该在深度维度 (Depth) 上复刻一遍。”
- 直觉类比:
- 序列维度: RNN 通过隐藏状态传递信息(容易遗忘长距离信息)
Transformer 通过 Self-Attention 全局关注所有 Token。 - 深度维度: 残差连接通过累加传递信息(容易稀释长距离层信息)
Attention Residuals 注意力残差全局关注所有前层的输出。
- 序列维度: RNN 通过隐藏状态传递信息(容易遗忘长距离信息)
关键公式与架构对比
|
特性 |
标准残差 (Standard Residual) |
全注意力残差 (Full AttnRes) |
|
公式 |
|
|
|
权重 |
固定权重 1 |
Softmax 权重 |
|
计算逻辑 |
简单求和 |
|
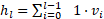
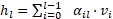
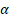
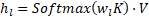
- V (Value): 前面每一层的实际输出
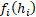 。
。 - K (Key): 前面每一层的输出表示(通常经过 RMSNorm)。
- Q (Query) w_l: 这是核心创新点。 每一层
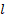 拥有一个与输入无关的可学习参数向量
拥有一个与输入无关的可学习参数向量 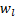 。它不依赖于当前的 Token,而是代表了“这一层”的偏好,询问:“我应该从历史层中提取什么信息?”
。它不依赖于当前的 Token,而是代表了“这一层”的偏好,询问:“我应该从历史层中提取什么信息?”
工程化方案:分块注意力残差 (Block AttnRes)
为了防止 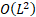 的计算爆炸,论文提出了 Block AttnRes:
的计算爆炸,论文提出了 Block AttnRes:
- 将
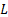 层网络分成
层网络分成 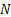 个块(例如
个块(例如 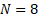 )。
)。 - 块内使用标准残差累加。
- 块间使用注意力机制。即每一层关注的是前面所有“块”的摘要表示。
- 复杂度优化: 从
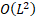 降至
降至 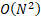 ,且
,且 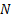 通常很小,计算成本几乎可以忽略。
通常很小,计算成本几乎可以忽略。
区别:
-
Full AttnRes(全注意力残差)
每一层都能通过注意力机制,动态地、有选择地回顾并聚合之前所有层的输出。就像一个“全知型记忆系统”,可以随时调取任意早期信息。 -
Block AttnRes(块注意力残差)
为了降低计算开销,将网络的多层划分为若干“块”(block),块内使用传统残差连接,而块之间才使用注意力机制进行信息聚合。相当于“摘要式记忆”,只记住每个块的“重点”,跨块时再做选择性回顾。
| 维度 | Full AttnRes | Block AttnRes |
|---|---|---|
| 信息聚合范围 | 每层可访问所有前序层的输出 | 仅聚合各“块”的摘要信息 |
| 内存与通信开销 | 高,复杂度为 O(Ld)(L为层数) | 低,复杂度降至 O(Nd)(N为块数) |
| 适用场景 | 理想理论设计,适合小规模验证 | 大规模模型训练的实用方案 |
| 性能表现 | 理论最优,信息利用最充分 | 接近 Full AttnRes,实测损耗更低(如1.692 vs 1.714) |
| 工程可行性 | 显存和通信压力大,难落地 | 可作为“即插即用”模块,额外开销不足4% |
- Full AttnRes 像一个过目不忘的学者,每读一页书都完整存档,随时翻阅任意章节。但书越多,记忆负担越重。
- Block AttnRes 像一个聪明的学生,每读完一章写个摘要,后续只根据摘要决定是否回看,既省力又高效。
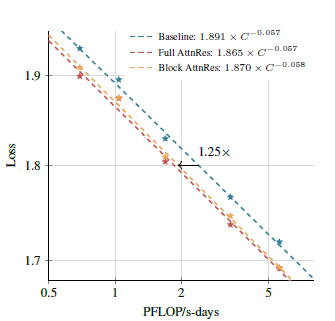
如图,该图为核心结论图。证明 AttnRes(Full 和 Block)(全量注意力残差与块注意力残差)在整个计算预算范围内一致优于 Baseline,且 Block AttnRes 的性能非常接近 Full 版本。
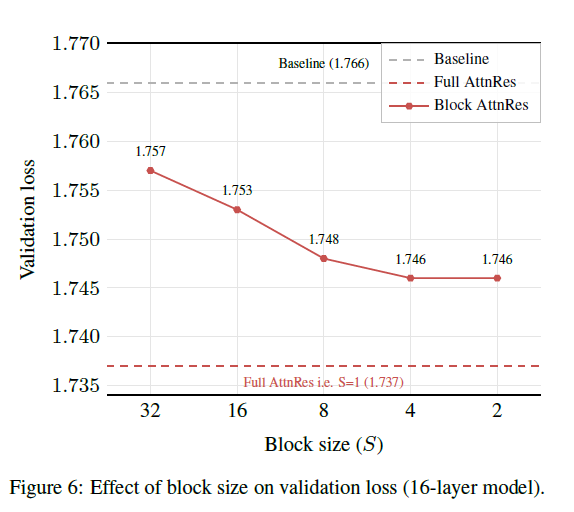
- 核心结论:损失随 S 增大缓慢退化,S=2/4/8 时损失均接近 1.746(远优于 Baseline 的 1.766),而 S=1 时等价于 Full AttnRes(损失最低 1.737);
- 工程指导:实际训练中固定块数 N≈8即可恢复 Full AttnRes 的绝大部分收益,兼顾性能与基础设施效率。
4. 工程优化:如何实现“零成本”落地?
为了让 Block AttnRes 在数千亿参数的大模型上训练,团队设计了精妙的系统级优化:
- 两阶段计算策略 (Two-phase Computation):
- Phase 1 (并行): 计算所有块之间的注意力。因为 Query
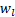 是与输入无关的参数,这一阶段可以批量计算,极大减少了内存读写。
是与输入无关的参数,这一阶段可以批量计算,极大减少了内存读写。 - Phase 2 (串行): 计算块内的残差连接,并通过 Online-Softmax 将块内信息与块间注意力结果合并。
- 效果: 推理延迟增加 < 2%。
- Phase 1 (并行): 计算所有块之间的注意力。因为 Query
- 跨阶段缓存 (Cross-stage Caching):
- 在流水线并行 (Pipeline Parallelism) 训练中,通常需要在不同 GPU 阶段传输激活值。
- AttnRes 利用缓存机制,只传输增量的块摘要,而不是每一层的输出,消除了冗余通信。
- 效果: 训练开销增加 < 4%。
5. 实验结果:数据不会说谎
论文在 Kimi Linear 架构(48B 总参数 / 3B 激活参数)上进行了 1.4T token 的预训练验证:
- 缩放定律 (Scaling Laws): Block AttnRes 的效果等同于标准残差模型使用 1.25 倍计算量训练出来的效果。这意味着它直接帮你节省了 20% 的训练成本。
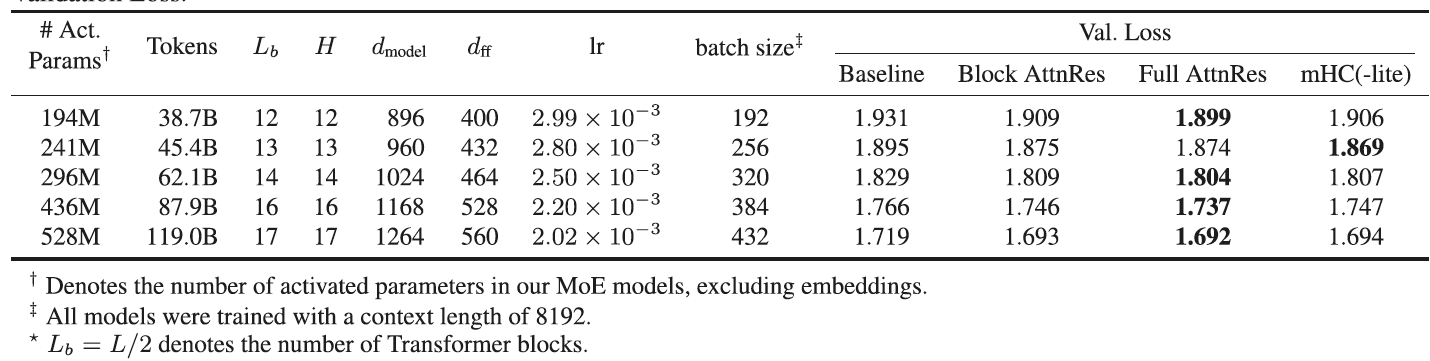
在所有 5 个不同规模的模型上,Block AttnRes 和 Full AttnRes 的验证损失(Val. Loss)都低于基线(Baseline)。这再次证实了方法的鲁棒性。
- 训练稳定性:
- 隐藏状态幅度: 标准残差随深度线性爆炸,而 AttnRes 保持稳定。
- 梯度分布: 标准残差的梯度集中在深层,而 AttnRes 的梯度在整个网络深度上分布均匀,证明了信息流动更通畅。
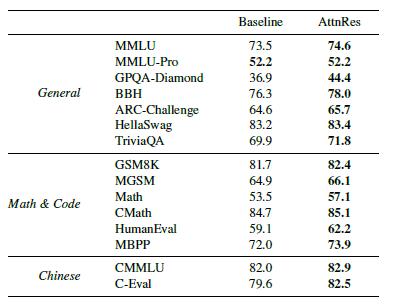
- 下游任务提升 (48B 模型):
- 数学与推理: GSM8K (+4.3), Math (+3.6)。这是最大的收益来源,因为注意力机制能更好地捕捉深层的逻辑链条。
- 代码生成: HumanEval (+3.1)。
- 知识理解: MMLU (+1.1)。
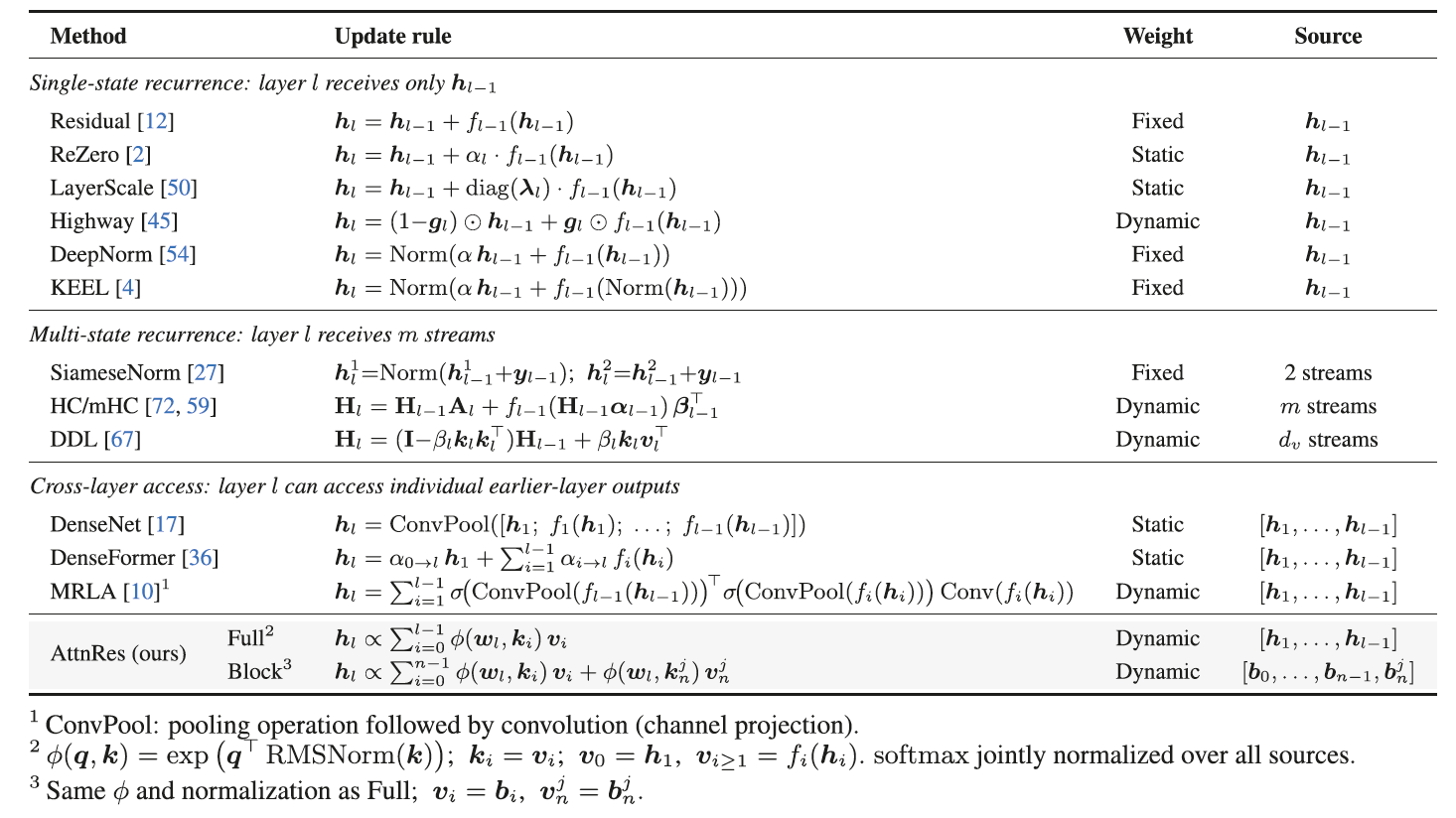
这是一张残差连接方法的“全家福”。
- 总结了从传统的标准残差连接到 mHC 再到 AttnRes 的数学公式。
- 分类: 将它们分为“单状态递归”(如标准残差)、“多状态递归”(如 mHC)和“跨层连接”(如 AttnRes),确立了 AttnRes 在理论谱系中的位置。AttnRes (ours) 也被归入了跨层连接这一类。
6. 个人思考:亮点与局限
- 最大亮点:架构的“优雅”与“必然”
- 这项工作最大的价值在于它揭示了“序列-深度对偶性”。它证明了 Transformer 成功的核心——Softmax 注意力,不仅在序列上有效,在网络深度上同样有效。这不仅仅是修修补补,而是对神经网络信息聚合方式的根本性修正。
- 潜在局限:
- 从结构化矩阵的角度看,标准残差和 AttnRes 都可以看作是特殊的线性注意力。AttnRes 的核心优势在于引入了 Softmax 的非线性竞争机制,但这是否是唯一的解法仍有待观察。
- 虽然通信优化做得很好,但在极深网络(>1000层)且不使用分块策略时,显存占用依然较高。
提出的问题
1. 宏观洞察与类比理解
- 序列-深度对偶性: 想象一下,RNN 就像一个人在读一本书,读完一页就把内容总结成一句话记在便签上,然后翻页。读到第 100 页时,他只记得第 99 页的便签,完全忘了第 1 页的内容(长期依赖丢失)。Transformer 解决了这个问题,它把所有页的内容都摊开在桌上,随时可以看任何一页(Self-Attention)。“序列-深度对偶性” 指出,传统的残差连接在“层与层之间”的传递,其实和 RNN 的“页与页之间”传递是一模一样的问题。因此,我们也要把“便签纸”换成“摊开的桌面”,这就是在深度维度上应用注意力机制。
- 信息稀释: 就像一个微信群里,每个人都按同样的音量说话。如果群里只有 3 个人,你能听清。如果群里有 1000 个人同时说话(深度增加),每个人为了让你听到,都得扯着嗓子喊(输出幅度
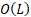 增长),结果就是一片嘈杂,谁也听不清谁(信息稀释)。
增长),结果就是一片嘈杂,谁也听不清谁(信息稀释)。 - AttnRes 的解决之道: AttnRes 就像给群聊加了一个“静音”和“提神”的功能。每一层都可以选择性地把想听的那几层声音放大,把无关的噪音关掉,这样即使群里人再多,也能清晰地听到重点。
2. 核心算法与数学拆解
- 标准残差缺陷: 展开公式
-
缺陷在于权重恒为 1。这导致模型无法区分哪些层的特征重要,且随着 L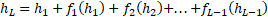
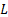 增加,求和项爆炸。
增加,求和项爆炸。 - Full AttnRes 公式推导:
-
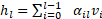
- 其中权重
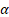 由 Softmax 计算:
由 Softmax 计算: -
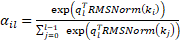
- Query (q_l): 第
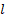 层的可学习偏好向量(Pseudo-query)。它代表了“第
层的可学习偏好向量(Pseudo-query)。它代表了“第 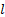 层想要什么”。
层想要什么”。 - Key (k_i) / Value (v_i): 第
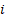 层的实际输出。Key 用于计算匹配度,Value 用于加权求和。
层的实际输出。Key 用于计算匹配度,Value 用于加权求和。
- Query (q_l): 第
- 为何 Query 与输入无关? 如果 Query 依赖于当前输入 Token(Input-dependent),那么在计算时必须等待当前层的输入计算完毕,这会破坏模型的并行计算能力,导致训练速度变慢。Kimi 团队发现,使用与输入无关的参数化 Query(每层一个向量),既能通过 Softmax 实现层间的“竞争选择”机制,又能保持极高的计算并行效率。
3. 工程优化与系统设计
- 引入 Block 的原因: 在千亿参数大模型训练中,显存和通信是瓶颈。Full AttnRes 需要保存每一层的中间状态(KV Cache),显存开销是 OLd
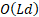 。如果模型有 100 层,显存占用就是 100 份;如果分成了 8 个 Block,显存占用就只有 8 份,极大地降低了门槛。
。如果模型有 100 层,显存占用就是 100 份;如果分成了 8 个 Block,显存占用就只有 8 份,极大地降低了门槛。 - 两阶段计算策略:
- Phase 1 (并行): 利用 Query 是参数的特性,一次性计算当前块对所有历史块摘要的注意力权重。这一步是“粗筛选”。
- Phase 2 (串行): 在块内部,像传统残差一样累加,但最后会将 Phase 1 的结果与块内累加结果通过 Online Softmax 合并。这一步是“精加工”。
- 跨阶段缓存: 在流水线并行中,GPU 之间需要传输数据。如果没有缓存,每次传输都要把所有历史块的摘要传一遍。有了跨阶段缓存,GPU 会记住之前收到的块摘要,每次只传输“新产生的块摘要”。这就像同步文件夹,只传增量,不传全量,极大降低了通信量。
4. 批判性对比与评估
- 对比分析:
- Highway Networks: 使用 Sigmoid 门控,权重是输入依赖的,但本质上还是线性组合,没有 Softmax 的竞争机制。
- DenseNet: 直接拼接所有层,参数量爆炸,无法扩展到大模型。
- DeepSeek 的 MHC: 使用多流和约束矩阵,虽然也解决了部分信息流问题,但引入了复杂的矩阵运算和额外的流管理。AttnRes 仅引入了一个 Softmax 归一化的权重矩阵,形式上更接近 Transformer 的原始美学。
- N=8 的甜点效应: 消融实验表明,当分块数 N
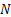 增加到 8 以上时,性能提升几乎停滞。 N=8
增加到 8 以上时,性能提升几乎停滞。 N=8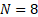 既能保留大部分历史信息的细粒度,又能将显存和通信开销压到最低。
既能保留大部分历史信息的细粒度,又能将显存和通信开销压到最低。 - 下游收益: 在 GSM8K(数学推理)上提升显著。这证明了 AttnRes 帮助模型建立了一条从浅层(提取数字)到深层(进行逻辑推导)的“信息高速公路”,让模型在做复杂数学题时,不会忘了题目里最初的数字。
一句话总结数学原理:该论文核心数学原理是基于 “时间与深度的对偶性”,将注意力机制从序列维度拓展至深度维度:通过每层独立的可学习查询向量 wl,对前层输出 vi 做 RMSNorm 归一化后计算相似度,经 softmax 得到动态注意力权重 αi→l,再通过
实现层间信息的选择性聚合,替代标准残差
的固定累加;同时为降低 O (L²d) 的复杂度,提出分块策略将层划分为 N 个块,通过块内累加、块间注意力将复杂度降至 O (N²d),配合跨阶段缓存与两阶段计算优化,在几乎不增加开销的前提下,解决了 PreNorm 稀释效应、梯度分布不均等问题,实现 1.25 倍计算效率提升与下游任务全面优化,为大模型残差连接提供了兼具理论与工程价值的升级方案。
工程实践:在工程实践与系统设计中,核心优化逻辑在于通过分治策略(Block Partitioning)将原本随深度二次增长的计算复杂度O(L^2) 降为可控的常数级开销,同时利用跨阶段缓存(Cross-stage Caching)与两阶段计算流水线消除分布式训练中的通信瓶颈,最终在几乎不增加显存与推理成本的前提下,实现了深度维度上的全局信息交互。
参考链接:
注意力残差论文原文https://arxiv.org/pdf/2603.15031
【闪客】深入解读 Kimi 爆火论文,马斯克都转了!到底什么是注意力残差?白话解读哟_哔哩哔哩_bilibili
Kimi Team 最新论文《Attention Residuals》残差连接 | 动画讲解_哔哩哔哩_bilibili
260322 直播回放-Attention Residuals_哔哩哔哩_bilibili
【注意力残差】10分钟看懂 马斯克盛赞的Kimi最新技术_哔哩哔哩_bilibili
一起读论文01:注意力残差 | Attention Residuals | Kimi最新技术_哔哩哔哩_bilibili

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)