我们如何构建一个成本感知型 AI 平台来控制失控的 LLM 费用
一、未追踪人工智能成本的隐患
未追踪的人工智能成本带来的挑战是多方面的,即使是最警惕的团队也可能措手不及。
- 意外账单:想象一下,月底收到一张天文数字般的 AI 使用账单,不禁让人疑惑:“这到底是怎么回事?”。虽然 OpenAI 会在你达到预设限额的 80% 时发出警报,但这并不能提供任何透明度。你不知道账单何时产生的,为什么会产生费用,也不知道是哪个功能或哪个组织造成的。
- 动态且不透明的定价:LLM 提供商经常更新其模型和定价。模型行为或每个代币成本的细微变化都可能对您的账单产生重大影响。
- 配置混乱:看似微小的更改,例如更新模型版本、调整提示或修改模型配置(例如,将温度从 0.5 改为 0),都可能在幕后造成严重的成本影响。例如,旨在提高准确性的更具体的提示可能会无意中增加输入标记的数量,从而增加成本。
- 谁该负责?:当成本飙升时,很难准确指出是哪个团队开发了导致成本增加的功能。我们无法轻易将成本与特定的业务部门联系起来,也无法识别需要关注的“浪费资源”的功能。
- 模型选择缺乏标准化:目前没有标准化的方法来比较不同模型的性价比。如何判断一款功能更多但价格更高的模型是否比一款速度更快、价格更低的模型更好呢?
- 优化无盲点:如何在不降低人工智能响应质量的前提下优化成本?实施优化后,如何准确衡量其对成本和质量的实际影响?
- 从被动应对到主动出击:我们经常发现自己处于危机管理模式,在看到高额账单后组织“节约日”。与可以通过公式预测成本的传统系统不同,人工智能的使用具有高度不可预测性。我们需要超越被动应对每月账单的模式。
二、构建成本感知平台
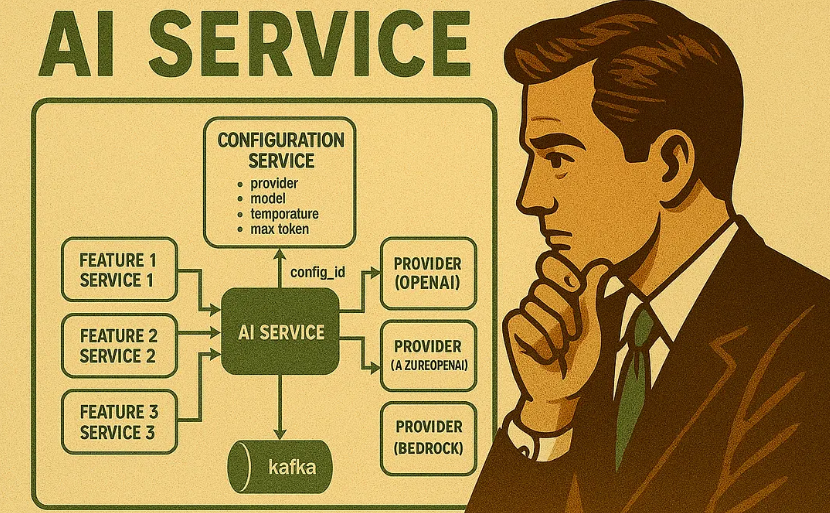
为了应对这些挑战,我们实施了一套强大的AI成本跟踪系统。我们的核心原则是记录与AI服务的每一次交互,并将其整合到我们现有的数据平台中。
以下是我们搭建它的方法:
- 中央AI服务:来自各个功能(我们的服务)的所有AI请求都通过中央服务进行路由AI Service。该服务不仅转发请求,而且非常智能。它会根据config_ID每个客户和功能独有的配置信息(例如首选提供商、模型、温度、最大令牌数或候选数)来检索特定配置。
- 全面数据采集:程序AI Service与 AI 提供商(OpenAI、Bedrock、Azure OpenAI 等)通信并收到响应后,会记录每个请求的详细事件。该事件包含关键指标,随后会将数据流传输到我们的消息层Kafka。
- 关键指标追踪:我们记录Time请求类型(有助于识别概念验证或营销活动)、发起人Organization和Feature责任方(用于成本归因)、使用的令牌、令牌类型Provider和Model令牌Model Version数量,以及至关重要的Input Tokens发送令牌和Output Tokens接收令牌。这一点至关重要,因为LLM(生命周期管理)会对输入令牌和输出令牌收费,而且通常收费标准不同。
三、数据管道详解:
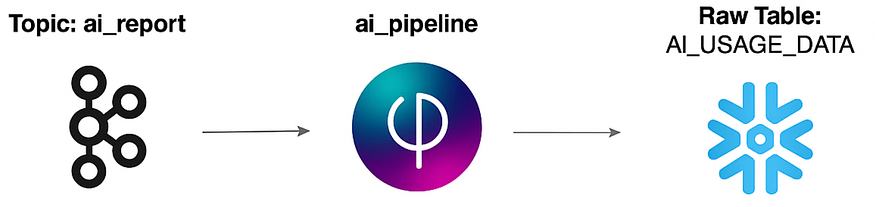
Kafka:作为中央枢纽,所有 AI 请求事件都在这里传输。
Upsolver:这款实时工具持续从 Kafka(以及 S3 等其他数据源)摄取事件,并将其作为原始数据加载到Snowflake中。Upsolver 现已被 Qlik 收购,并提供 SQLake 版本,以实现更直观的数据处理。
Snowflake:我们的数据仓库。它存储原始成本数据AI_USAGE_DATA以及转换和计算后的成本数据。
四、基于DBT的动态模型定价管理
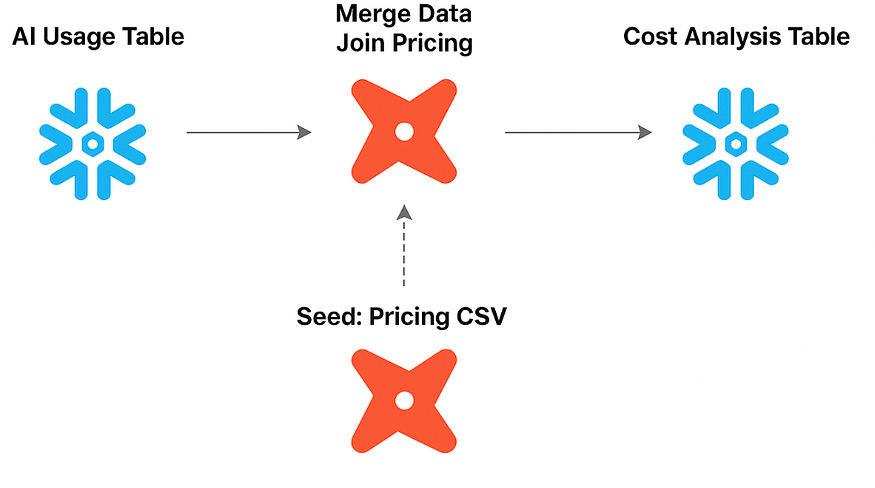
DBT(数据构建工具):这是我们的转换引擎。DBT 会定期运行(每隔几分钟或几小时),处理 Snowflake 中的原始数据。它执行计算、聚合和连接操作,将原始事件转换为有意义的成本指标。
我们使用版本控制系统(Git)维护一个关键的CSV 文件,其中包含我们所有的模型定价信息。该表包含Model名称(使用正则表达式以提高灵活性)、Type(输入/输出)、Price(每百万代币价格)Provider、以及Publish_Date(用于跟踪价格随时间变化的指标)。DBT的seed命令会将此 CSV 文件加载到 Snowflake 的静态表中。
在转换阶段,DBT 将原始使用数据与此定价表连接起来。然后,它将数据in_tokens乘以input价格,再out_tokens乘以output价格,将它们相加,并汇总每个组织、每个功能和每天的成本。这便得出我们的结果Cost Analysis Table。
五、实际影响:我们获得了什么
构建这个平台不仅仅是为了解决问题,更是为了转变我们采用人工智能和成本管理的方式。
- 早期问题检测与应对:我们的系统近乎实时,能够及早发现异常使用模式,通常当天即可发现。任何显著的成本激增都会通过 Slack 或电子邮件向我们发出警报。这意味着我们可以立即采取行动,例如回滚导致流量激增的变更,甚至暂时禁用特定高流量客户的某项功能。这标志着我们从被动的危机管理转向了主动预防。
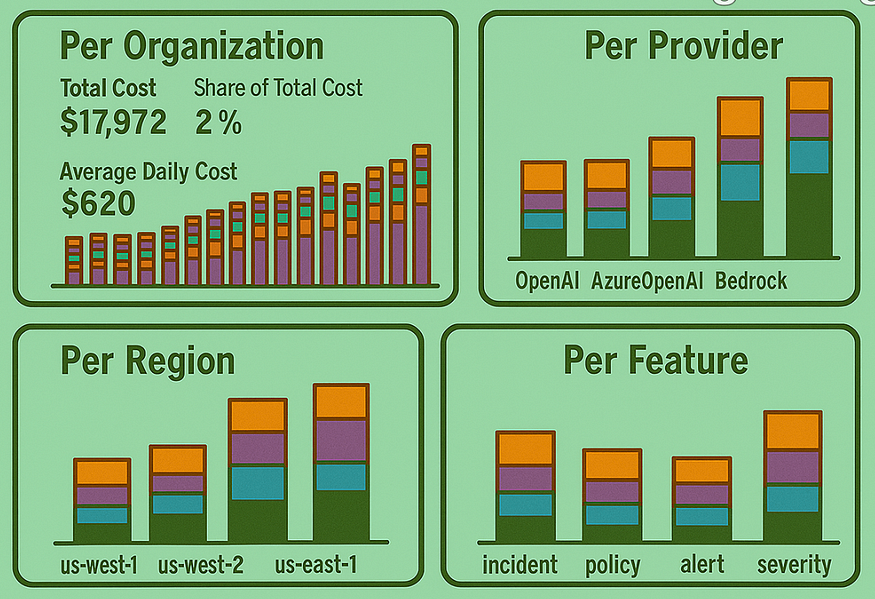
- 前所未有的成本可视性和控制:我们现在可以通过清晰的仪表盘深入了解各项成本。例如:
-按组织:我们可以查看哪些客户或部门产生了哪些成本。
-按功能:这对开发团队至关重要,使他们能够跟踪其功能的具体成本并确定需要改进的领域。-
按提供商:我们可以查看我们在不同人工智能提供商处的支出情况。 - 数据驱动决策:现在,关于模型选择、工程优化或配置变更的每一个决策都以数据为依据。我们不再需要猜测,而是可以根据数据做出明智的选择,找到性价比最高的车型。
- 精准的预算与定价:我们可以为新功能和概念验证提供更准确的成本估算。这将直接影响我们如何为客户提供服务定价,确保我们充分考虑他们实际的AI使用情况。
- 赋能团队,培养责任感:我们的仪表盘赋能业务部门和开发团队,让他们不仅负责缺陷,更能掌控成本。他们可以尝试各种变更,并立即查看成本影响。我们甚至可以在全面推广之前,先在测试团队中测试特定的配置变更。
- 持续优化:我们可以持续分析令牌使用情况,并衡量优化措施的影响。如果及时更改或调整配置能够在不牺牲质量的前提下降低成本,我们可以用数据验证这一点。
六、展望未来:迈向更智能的人工智能成本管理之路
虽然我们已经取得了显著进展,但我们的征程尚未结束。仍然存在一些悬而未决的问题和需要改进的领域。
我们的目标是实现一种文化转变,让成本意识从一开始就融入到开发流程中。在选择模型或设计提示时,开发人员应该在考虑性能和质量的同时,也务必考虑成本影响。
未来可能的发展方向包括:
- 自动模型选择:超越手动配置更改,根据实时成本、性能和质量指标自动选择模型。
- 追踪更多指标:纳入响应时间(延迟)和响应长度等数据,可以更深入地了解模型性能与成本之间的关系。这有助于识别哪些情况下,速度稍慢但价格更低的模型完全可以满足需求。
- 改进我们的 AI 服务:我们正在考虑将我们自主开发的 AI 服务从 LangChain 迁移到 LiteLLM,因为它提供了许多我们自己开发的功能,而且都是免费的。
我们最初因人工智能成本追踪不力而遭受的惨痛教训促使我们构建了一个强大且主动的平台。该系统赋予我们无与伦比的可见性和控制力,使我们能够做出更明智、数据驱动的决策,持续优化,并赋能我们的团队构建兼顾成本的人工智能解决方案。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)