WorkBuddy 进阶 | 日常工作 & 业余创作 “虾“都懂
WorkBuddy 进阶 | 日常工作 & 业余创作 "虾"都懂
概述:最近也是参加了一场腾讯云举办的龙虾线下活动,作为 WorkBuddy 实操导师的身份。在活动过程中,有关注到非技术人员关于 WorkBuddy 的疑问,这里也做一个简单的答疑。
龙虾答疑
最近也是参加了一场腾讯云举办的龙虾线下活动,作为 WorkBuddy 实操导师的身份。在活动过程中,有关注到非技术人员关于 WorkBuddy 的疑问,这里也做一个简单的答疑。
WorkBuddy 可以干什么
正如 WorkBuddy 官网所言,WorkBuddy 是腾讯推出的全场景职场 AI 智能体桌面工作台,适配全职场角色使用,是具备自主执行能力、可协同完成办公任务的 AI 办公工具。通过内置模型、主流 MCP Server 适配、Skills 技能包扩展、高危指令拦截等高阶功能,以协同协作模式辅助用户完成工作、交付合规成果,提升职场办公效率。
WorkBuddy 可以做的事很多,一句话概括就是只有你想不到,没有它做不到。简单来说就是:WorkBuddy 是一个强大的 AI 编程与工作助手,可以帮你完成几乎所有"坐在电脑前能做的事":写代码、调试 Bug、构建网站和应用、分析数据并生成可视化报告、读写本地文件、搜索互联网获取实时信息、生成 PPT/Word/Excel/PDF 等各类文档、自动化定时任务(比如每天早上生成报告)、操作浏览器完成网页交互,还能通过专家中心接入 100+ 领域专家……它不仅仅是你的私人 AI 全能助理,而是一个既懂技术又懂业务,帮你把想法变成现实的 Buddy。
WorkBuddy 烧 Token 吗
WorkBuddy 目前采用的是个人体验版(消耗积分方式)、个人专业版(按月/年计费方式),大家可以不用太担心 Token 的问题了。
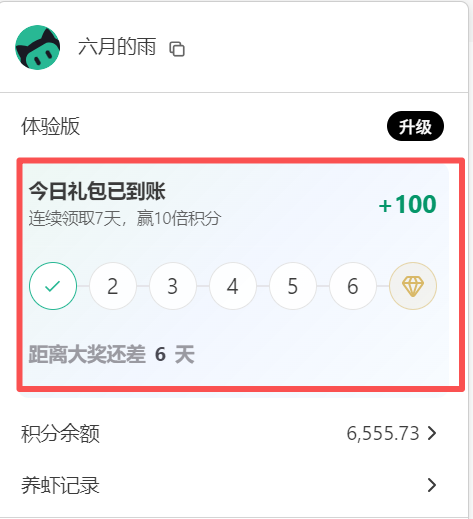
另外积分目前是每天签到领取的方式,具体的签到位置在 WorkBuddy 客户端左下角登录用户名处,2026.03.31 号之前登录账号免费领取 5000 积分,后续每天签到领取 100 积分,(连续签到 7 天有大积分哦)
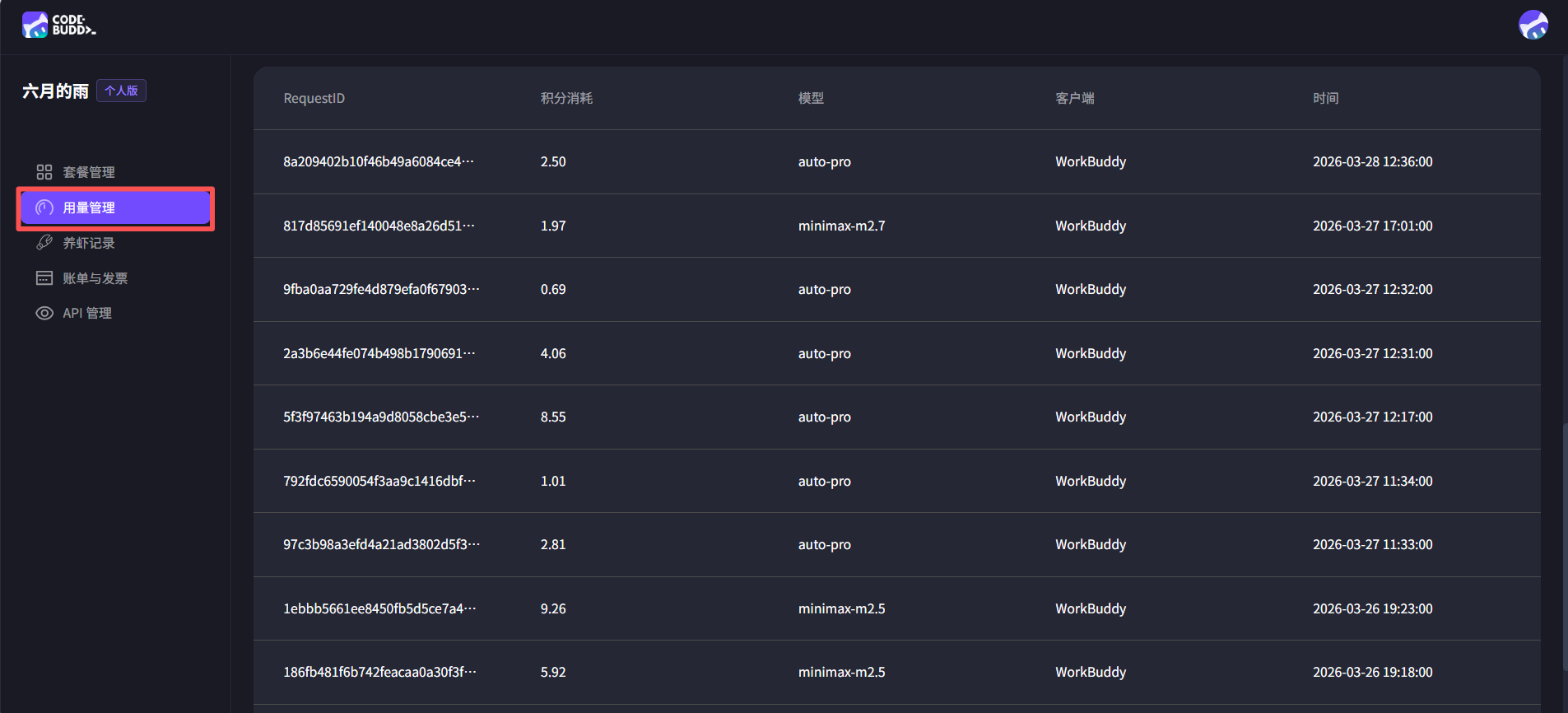
关于积分的消耗,大家也不用担心,很省的,每天敞开了用,大概 500 积分足够用了,具体的积分消耗也可以通过 WorkBuddy 左下角【用户名】-【积分余额】-【用量管理】看到
关于 WorkBuddy 其他相关问题,会在下面的正文中涉及,请关注哦。
日常工作
作为开发者,最近在处理业务系统中查询慢的一些 sql,那么想要获取一手 sql 语句及参数来排查 sql 慢查询的情况,日志文件必不可少。这个时候你可能会说,直接在生产环境服务器 tail -f 打开日志文件,页面点击,抓取 sql 就可以了。但是你可能会忽略一个小问题,那就是生产日志的刷新比眼睛快,很难准确抓取你想要的 sql 查询以及对应的 sql 参数。这个时候,你就可以下载日志文件,然后慢慢搜索慢慢找了…
但是,有了 WorkBuddy 就不一样了,日志分析功能咱们多少得用点吧。那么下面教程来了。
日志分析&sql 优化
获取请求地址
分析日志第一步,我们需要让生产服务器产生我们请求页面的访问日志,那么这时我们就可以在页面进行查询来抓取请求地址,我们可以用谷歌浏览器,用【F12】打开浏览器控制台,选择【Network】这时,我们可以看到页面查询的具体请求地址
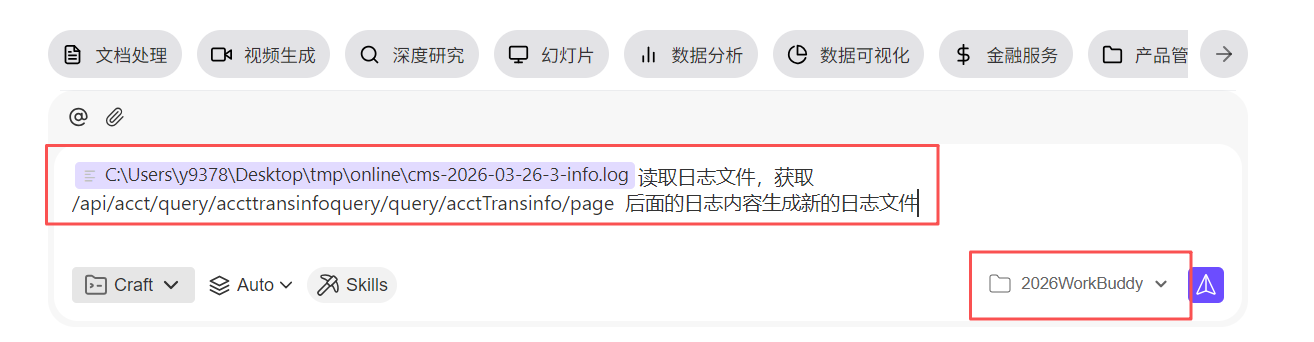
复制请求地址备用,
/api/acct/query/accttransinfoquery/query/acctTransinfo/page
下一步,我们就可以去生产服务器下载日志了。
分析日志文件
在生产服务器找到具体的日志文件,利用 xftp 工具或者 sz 命令下载日志文件,这里日志文件可以下载在任何文件夹都可以。下载完成后,打开 WorkBuddy,【新建任务】,这里我选择我创建好的 WorkBuddy 文件夹,附件选中下载的日志文件,输入
读取日志文件,获取 /api/acct/query/accttransinfoquery/query/acctTransinfo/page 后面的日志内容生成新的日志文件
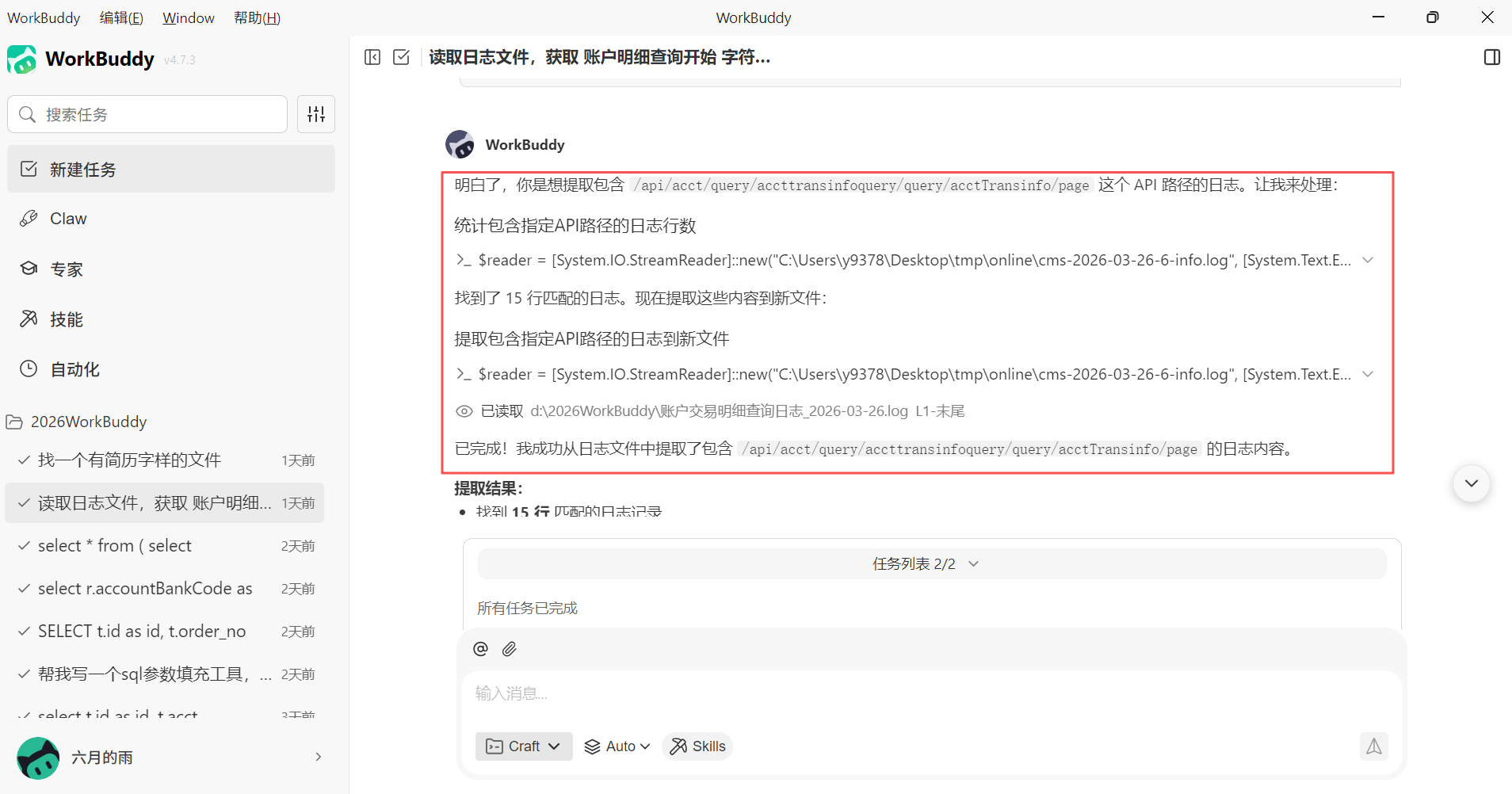
在接收到我们的需求后,WorkBuddy 会自动对日志文件进行解析,读取日志文件内容,并获取我们提供的请求地址相关日志,最终生成新的日志文件
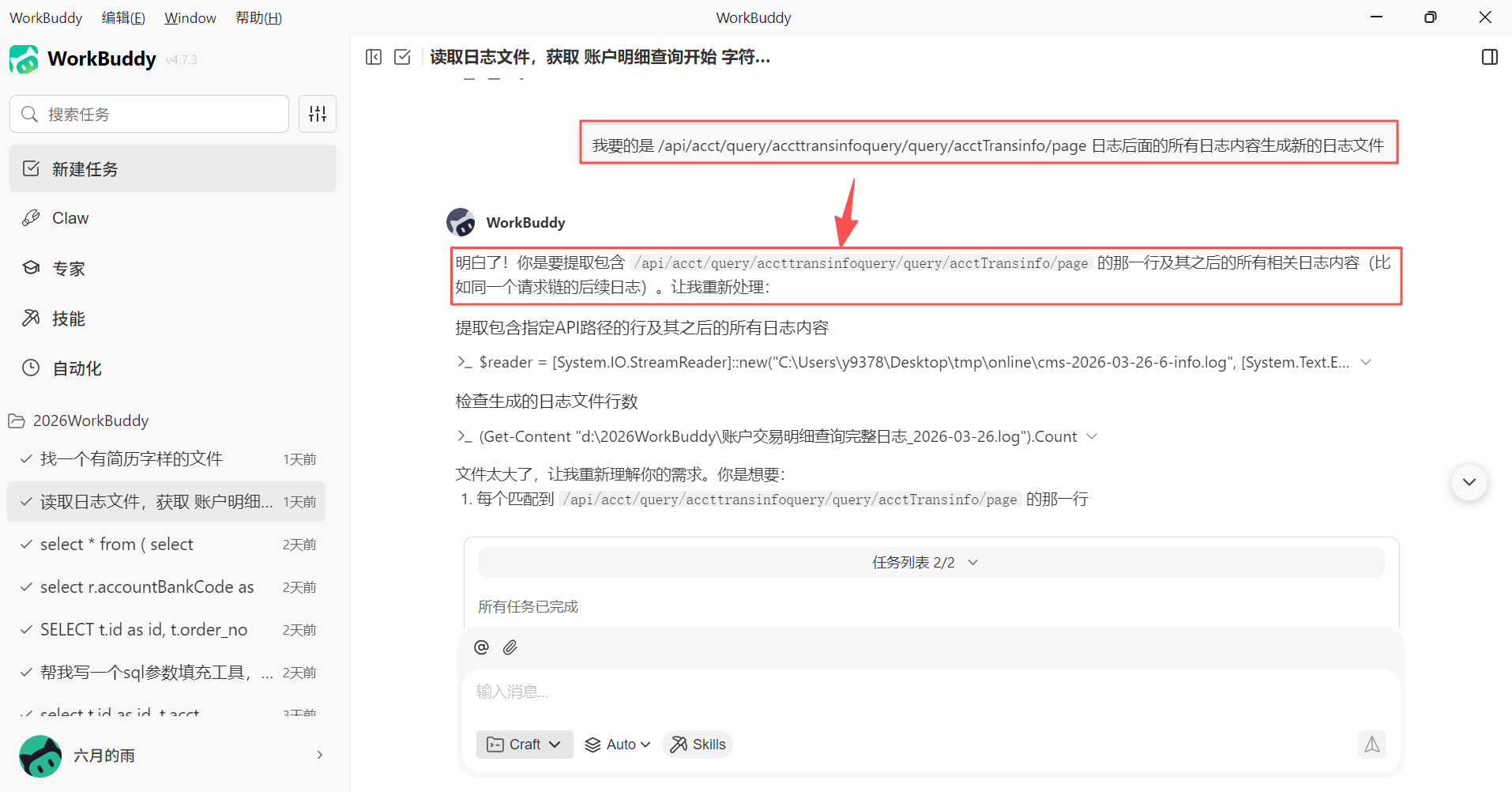
当然了,第一次往往不会那么顺利的,当日志文件我们关注的请求地址日志内容比较多的时候,可能给我们生成的新的日志文件并不能满足我们的想法,这个时候我们就可以继续提出我们的需求,WorkBuddy 也很容易 get 需求
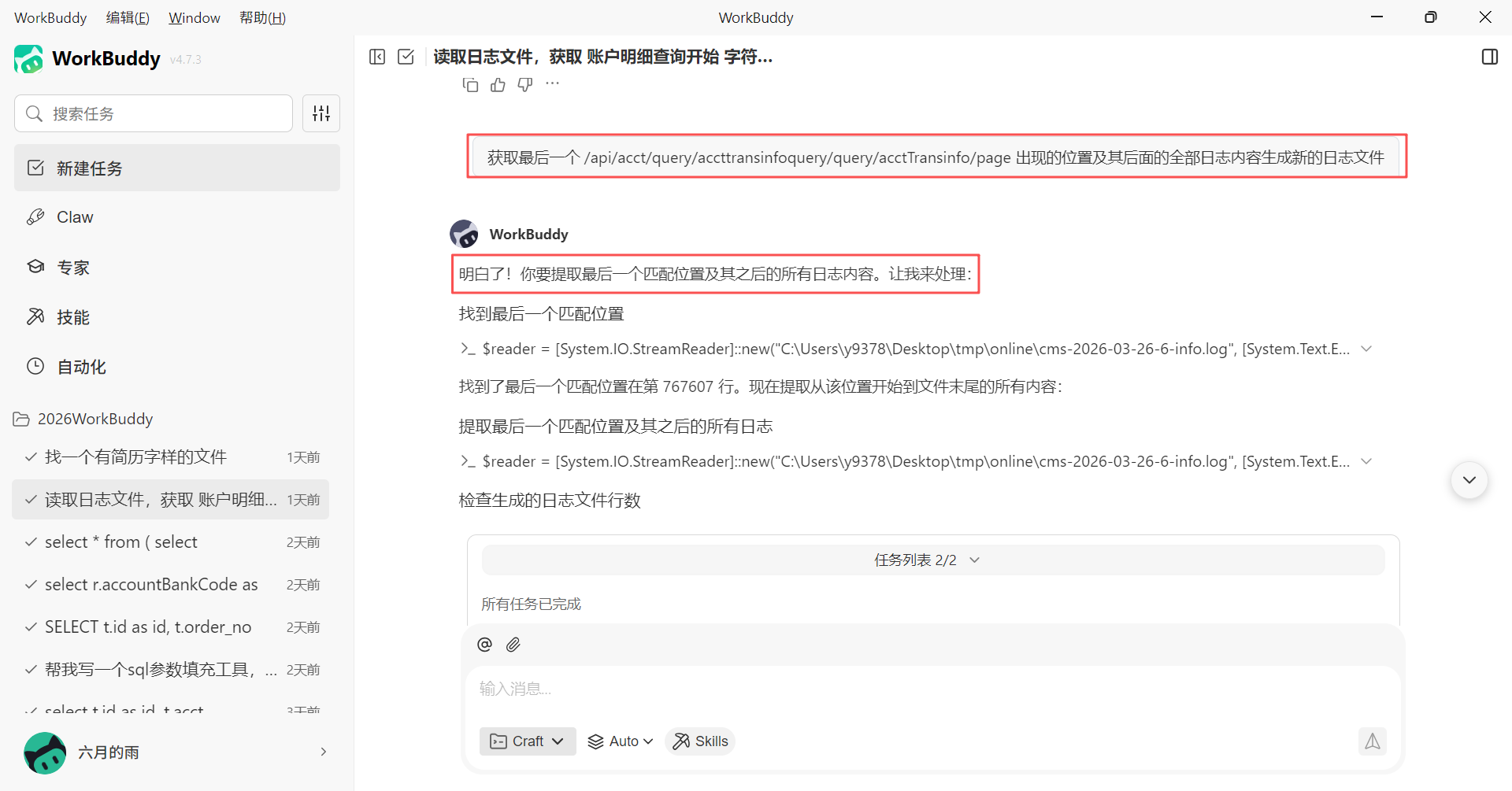
遇到当前请求地址相关的日志文件很大的情况,比如这里我们想要获取的请求地址后面的新的日志文件有 90M,那么 WorkBuddy 就会询问我们需要多少行日志,这里我们也可以再次给出我们的新需求
这样的话,WorkBuddy 为我们生成的新的日志文件就不会太大了,打开新生成的日志文件,就可以很快找到我们需要的 sql 了,大大提高了日志的排查效率。到这里,暂停一下 sql 优化,因为我们还需要一个好用的工具。
做个 sql 参数填充工具
排查过日志文件中 sql 查询语句的都知道,sql 查询语句打印的往往是 sql 语句和 sql 参数是分开的,就像下面这样。sql 参数少的时候,我们可以手动填充参数,

但是如果 sql 参数很多呢,就像下面这样,你还要手动填充 sql 参数吗?手动填充 sql 参数,参数多的时候,除了会增大出错的机会,还无情的增加了开发人员的耗时,延误了真正应该关注的 sql 优化本身的工作
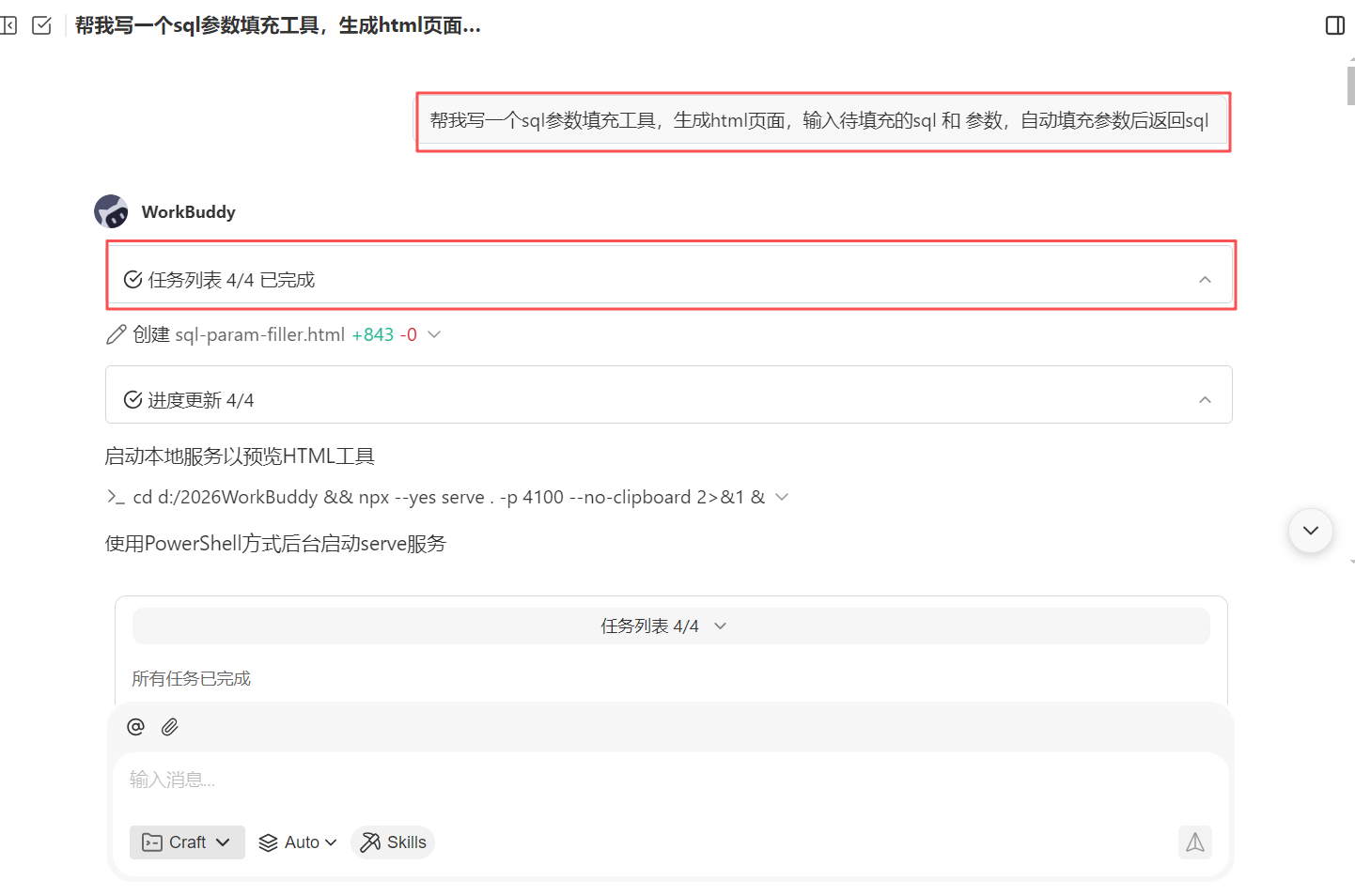
这时候,我们就可以自己用 WorkBuddy 来做个 sql 填充工具了。
同样的,在 WorkBuddy 工作页面,选择我自己指定的 WorkBuddy 工作文件夹,输入我们的想法
帮我写一个 sql 参数填充工具,生成 html 页面,输入待填充的 sql 和 参数,自动填充参数后返回 sql

WorkBuddy 会自动根据我们的描述开始来创建任务列表,帮助我们生成我们想要的 sql 参数填充工具
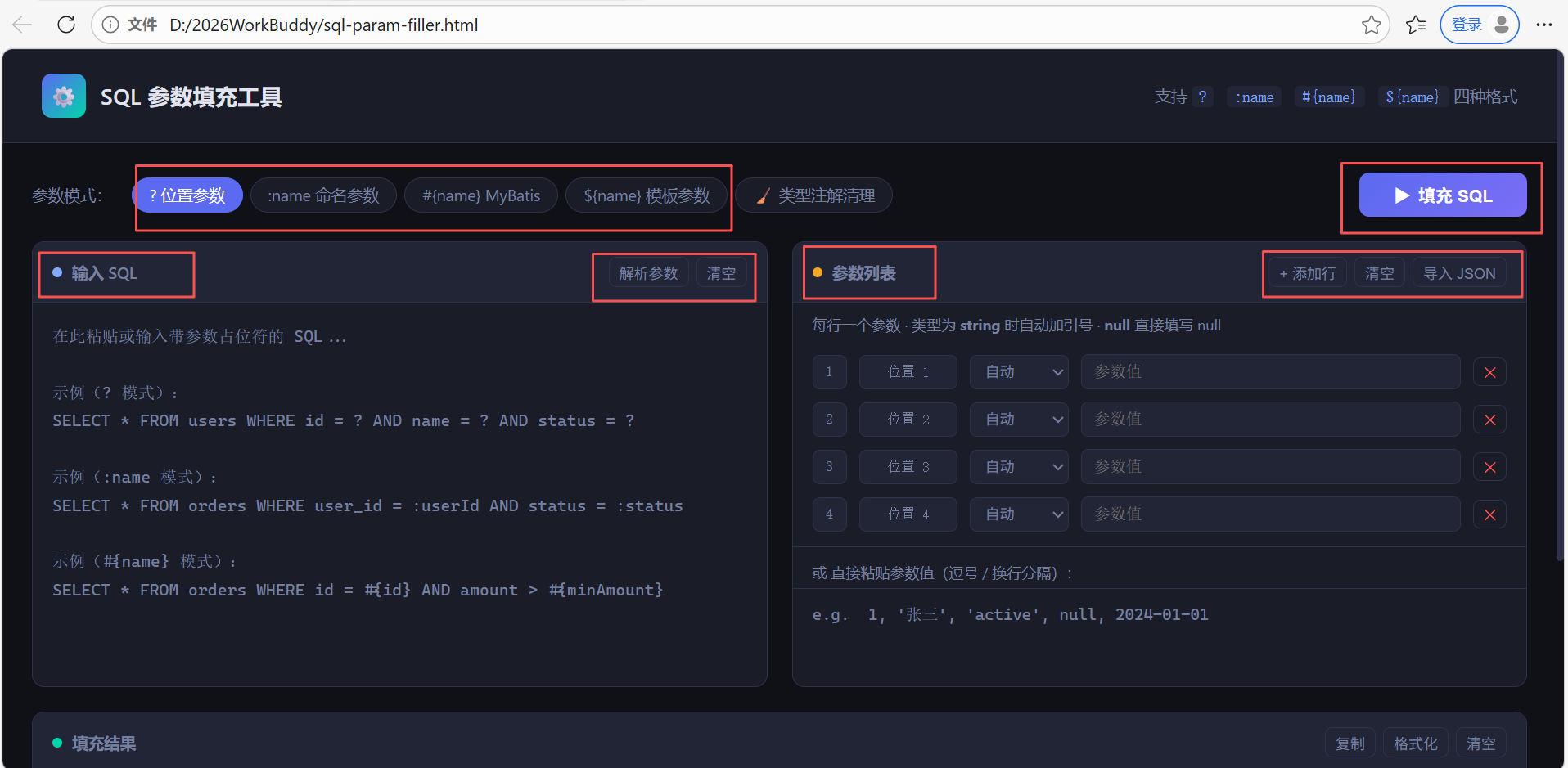
同时给出为我们生成的 sql 参数填充工具支持的当下比较主流的 4 种参数格式及示例,方便我们快速匹配生成的这个工具是不是真的能匹配我们抓取到的 sql 语句和 sql 参数
我们找到生成的 sql 填充工具,右键通过浏览器打开这个本地文件,我们可以看到我们的 sql 参数填充工具页面
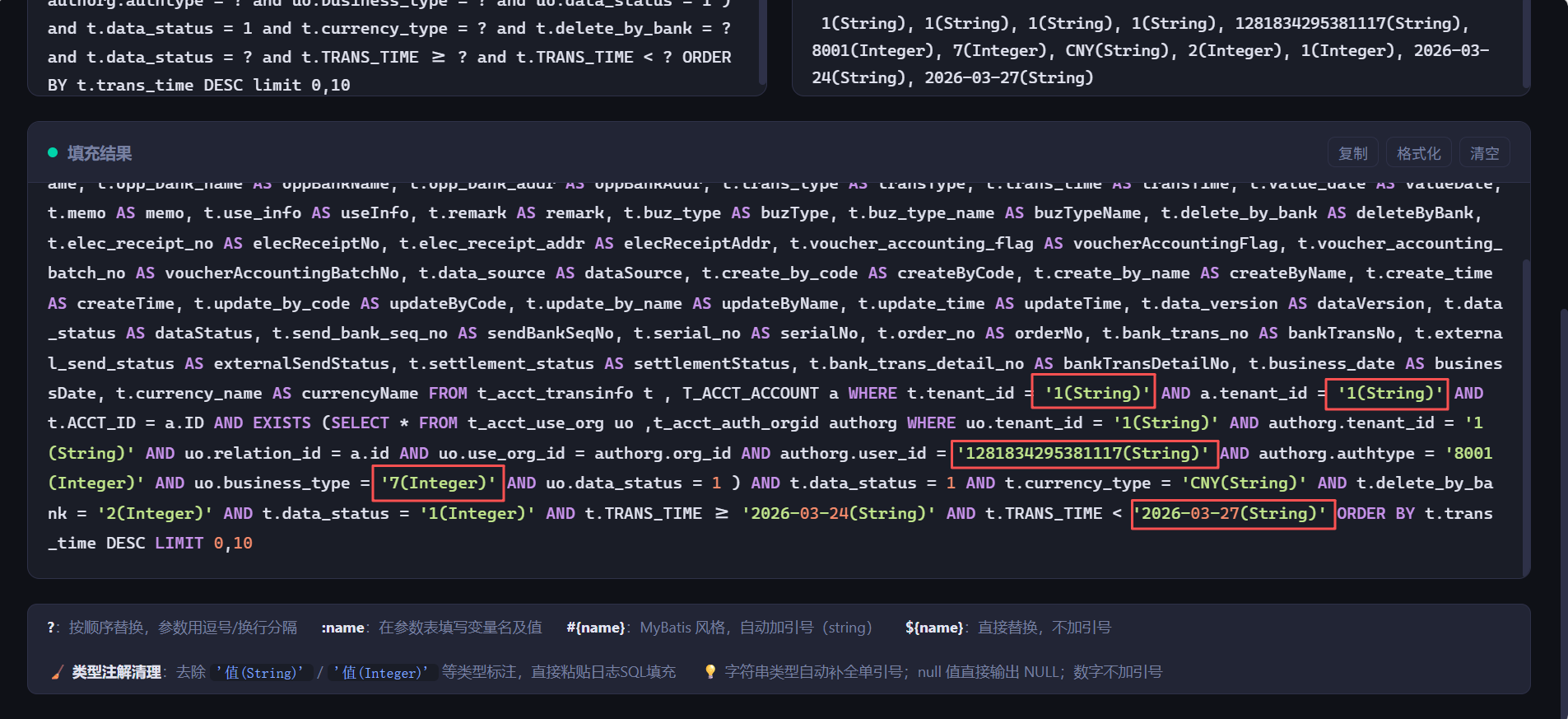
功能栏以及操作按钮一看就很符合我们的需求,下面我们将日志文件中的 sql 语句和 sql 参数复制出来,放在对应的位置,上面切换为【?位置参数】,点击【填充 SQL】我们可以得到我们填充 sql 参数后的 sql 语句
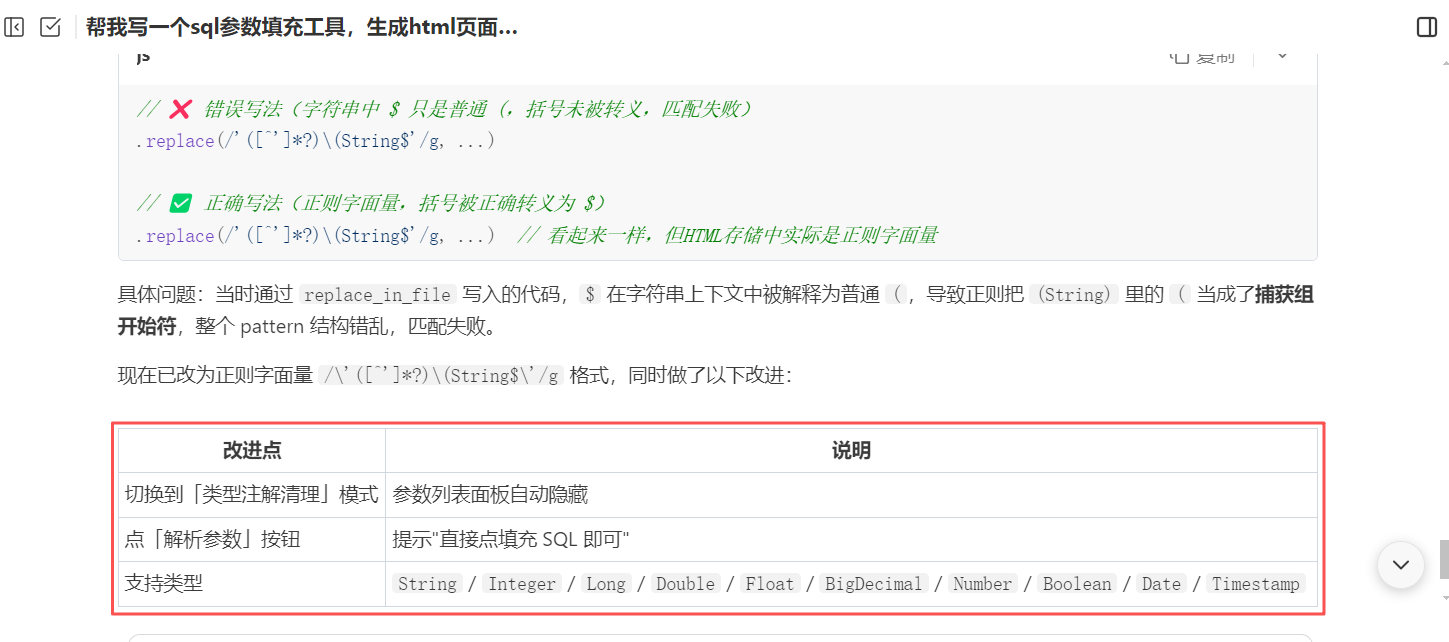
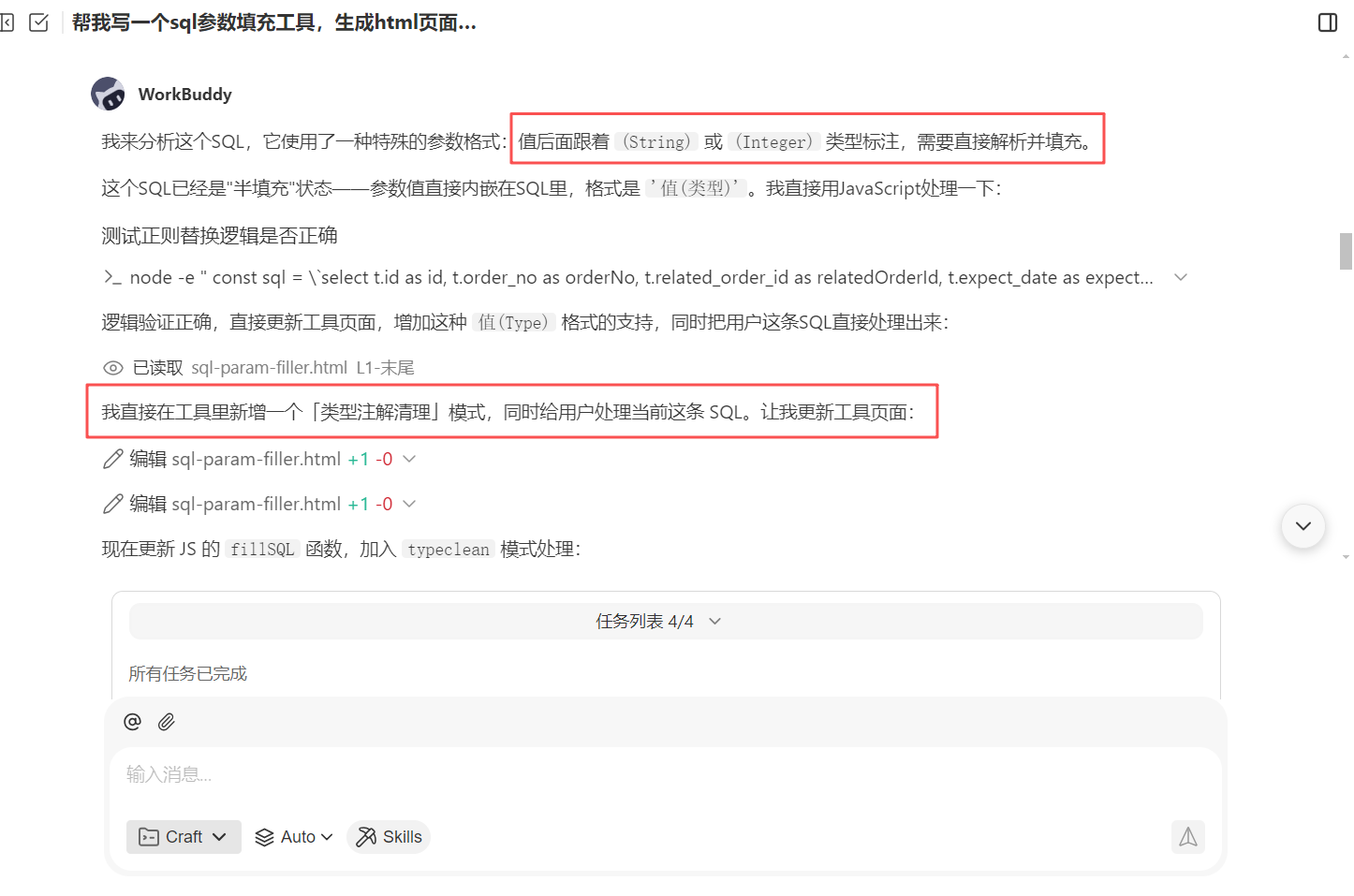
这里我们可以看到参数填充的似乎有点问题,默认把参数类型也给填充进去参数了,这样的 sql 肯定是不对的。这个时候我们就可以继续回到我们的 WorkBuddy 来优化我们这个 sql 参数填充工具,直接将我们填充参数后的 sql 给 WorkBuddy 让他分析
分析完成后,WorkBuddy 会自动丰富我们的 sql 参数填充页面,增加关于参数后面参数类型的替换内容
此时我们就可以按照操作说明,复制有参数类型的 sql 切换到【类型注解清理】模式,输入 sql 语句后,点击【填充 SQL】按钮可以看到我们得到了我们想要的效果,清理类型注解后的 sql 可以直接在 mysql 工具执行了
好了,拿到了我们的 sql 语句,下一步就可以来优化我们的 sql 语句提高查询效率了。
优化 sql
在拿到了填充完 sql 参数的 sql 查询语句之后,我们就可以来优化我们的 sql 语句了。直接复制 sql 语句,同时输入我们的需求
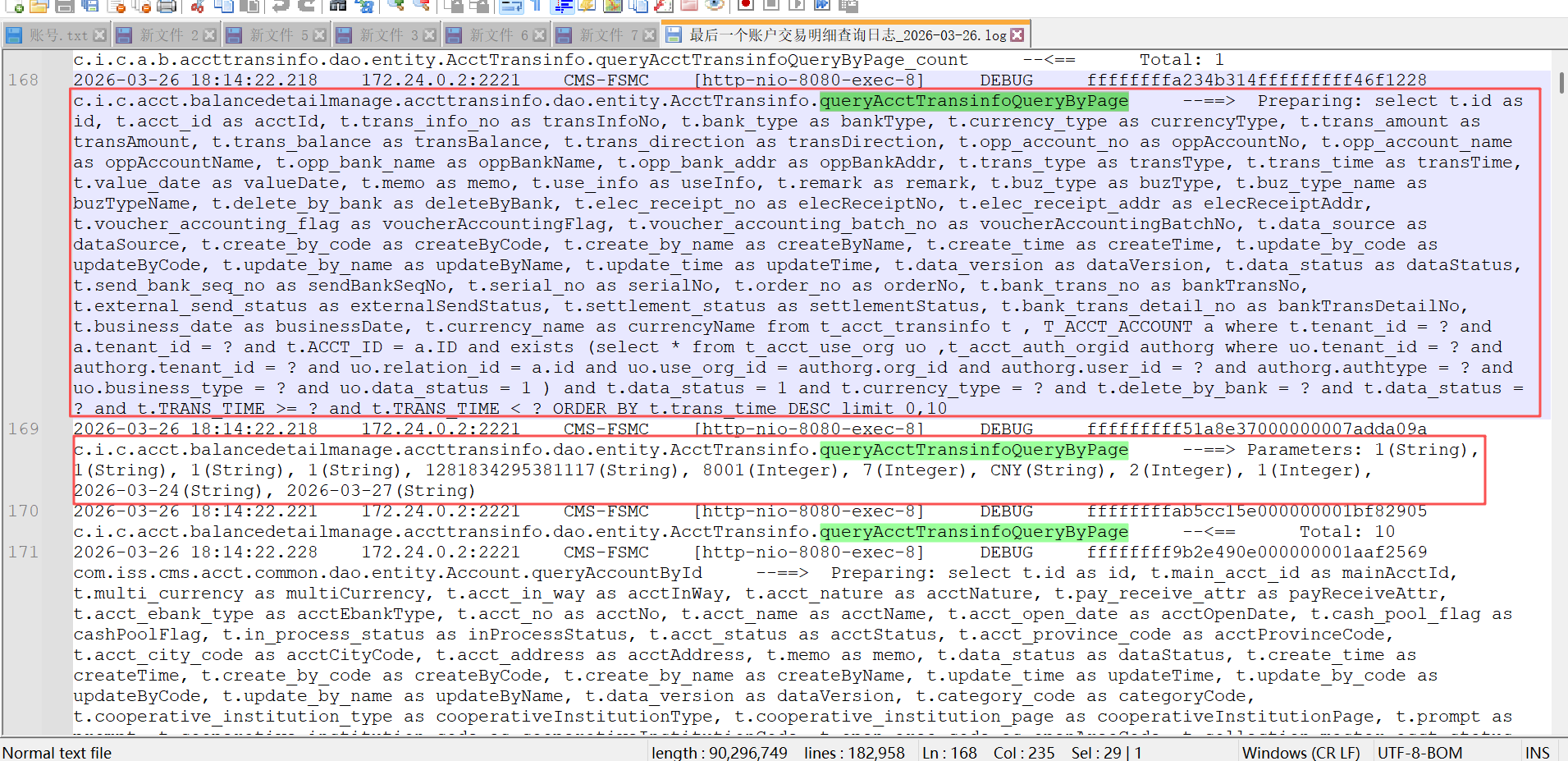
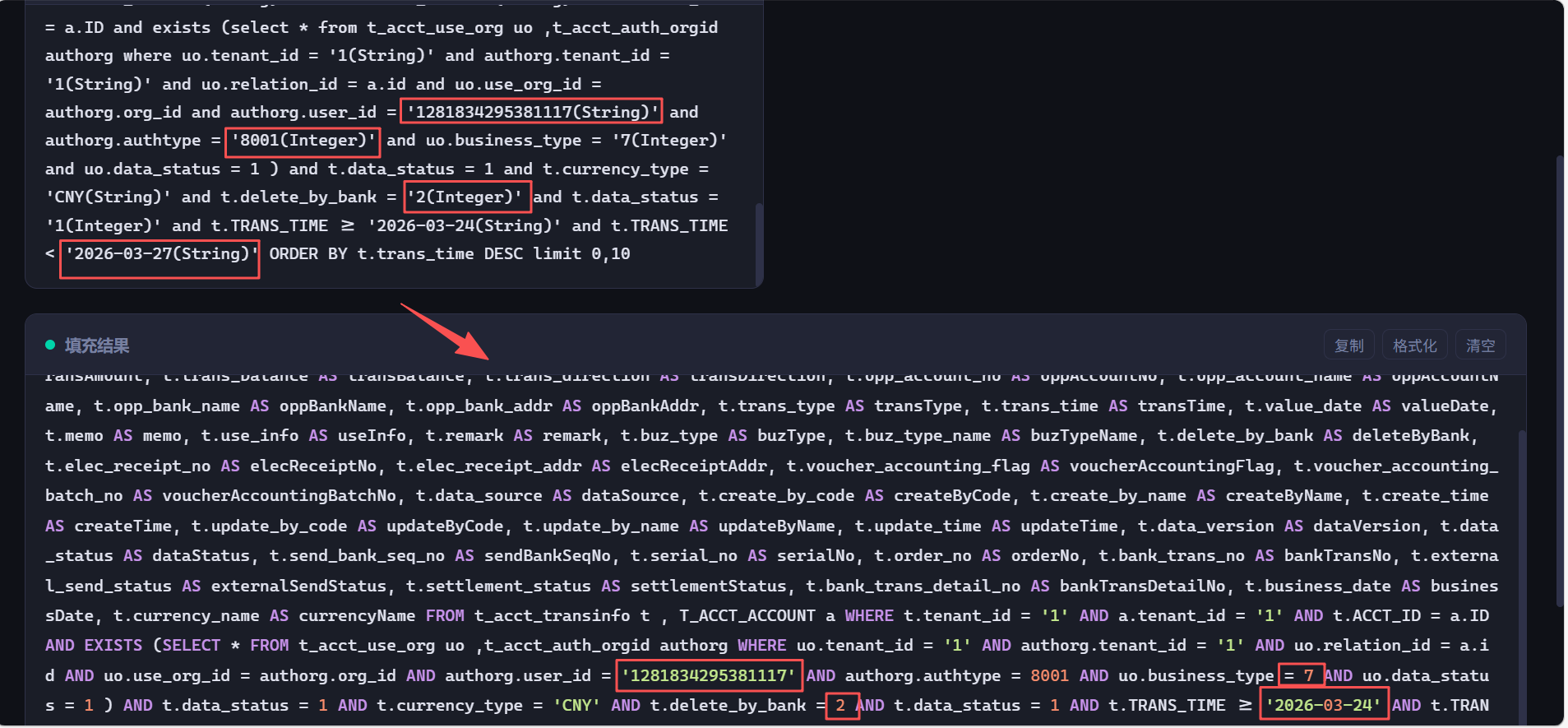
select t.id as id, t.acct_id as acctId, t.trans_info_no as transInfoNo, t.bank_type as bankType, t.currency_type as currencyType, t.trans_amount as transAmount, t.trans_balance as transBalance, t.trans_direction as transDirection, t.opp_account_no as oppAccountNo, t.opp_account_name as oppAccountName, t.opp_bank_name as oppBankName, t.opp_bank_addr as oppBankAddr, t.trans_type as transType, t.trans_time as transTime, t.value_date as valueDate, t.memo as memo, t.use_info as useInfo, t.remark as remark, t.buz_type as buzType, t.buz_type_name as buzTypeName, t.delete_by_bank as deleteByBank, t.elec_receipt_no as elecReceiptNo, t.elec_receipt_addr as elecReceiptAddr, t.voucher_accounting_flag as voucherAccountingFlag, t.voucher_accounting_batch_no as voucherAccountingBatchNo, t.data_source as dataSource, t.create_by_code as createByCode, t.create_by_name as createByName, t.create_time as createTime, t.update_by_code as updateByCode, t.update_by_name as updateByName, t.update_time as updateTime, t.data_version as dataVersion, t.data_status as dataStatus, t.send_bank_seq_no as sendBankSeqNo, t.serial_no as serialNo, t.order_no as orderNo, t.bank_trans_no as bankTransNo, t.external_send_status as externalSendStatus, t.settlement_status as settlementStatus, t.bank_trans_detail_no as bankTransDetailNo, t.business_date as businessDate, t.currency_name as currencyName from t_acct_transinfo t , T_ACCT_ACCOUNT a where t.tenant_id = '1' and a.tenant_id = '1' and t.ACCT_ID = a.ID and exists (select * from t_acct_use_org uo ,t_acct_auth_orgid authorg where uo.tenant_id = '1' and authorg.tenant_id = '1' and uo.relation_id = a.id and uo.use_org_id = authorg.org_id and authorg.user_id = '1281834295381117' and authorg.authtype = 8001 and uo.business_type = 7 and uo.data_status = 1 ) and t.data_status = 1 and t.currency_type = 'CNY' and t.delete_by_bank = 2 and t.data_status = 1 and t.TRANS_TIME >= '2026-03-24' and t.TRANS_TIME < '2026-03-27' ORDER BY t.trans_time DESC limit 0,10 优化这个 sql,提高查询效率,给出优化原因
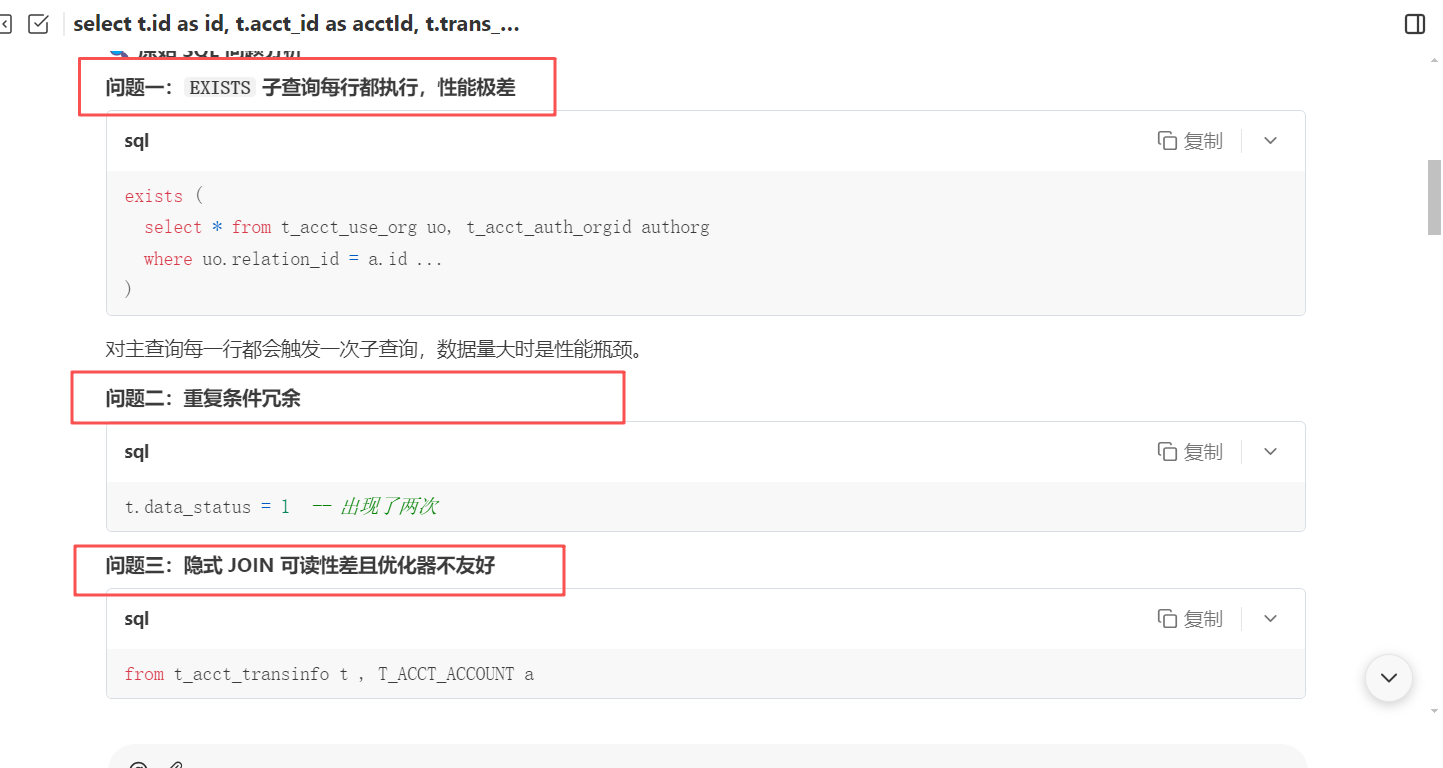
在接收到我们的需求之后,WorkBuddy 会对我们给出的 sql 语句进行分析并指出现在 sql 语句存在的问题
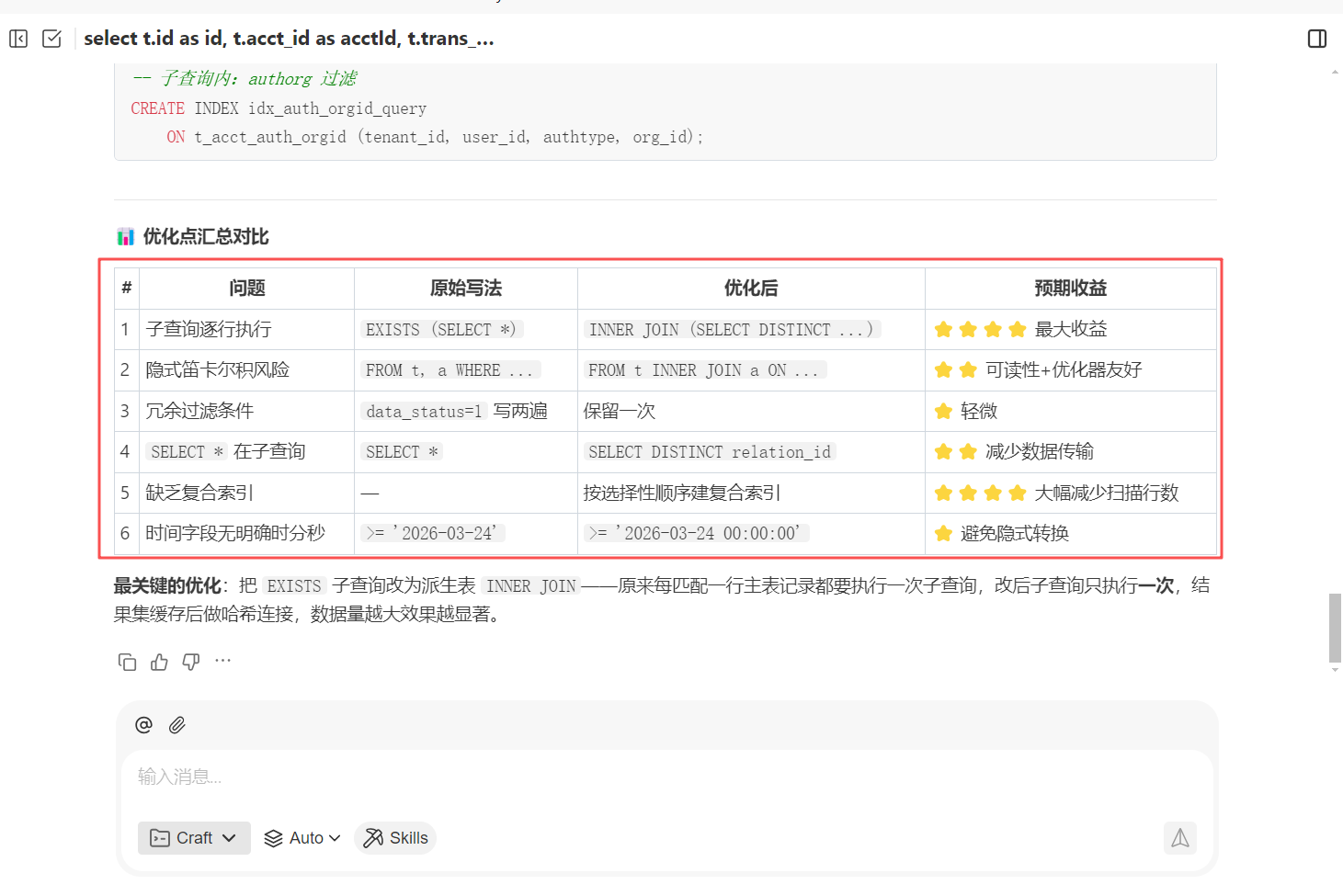
同时会给出优化后的 sql 以及适配当前 sql 的推荐索引创建语句
-- 核心:t_acct_transinfo 覆盖主过滤条件
-- 把等值过滤放前面,范围过滤放最后,ORDER BY 字段紧跟范围字段
CREATE INDEX idx_transinfo_query ON t_acct_transinfo (tenant_id, data_status, currency_type, delete_by_bank, trans_time DESC);
-- acct_id 用于 JOIN
CREATE INDEX idx_transinfo_acct ON t_acct_transinfo (acct_id);
-- T_ACCT_ACCOUNT 关联
CREATE INDEX idx_account_tid ON T_ACCT_ACCOUNT (tenant_id, id);
-- 子查询内:uo 过滤
CREATE INDEX idx_use_org_query ON t_acct_use_org (tenant_id, business_type, data_status, use_org_id, relation_id);
-- 子查询内:authorg 过滤
CREATE INDEX idx_auth_orgid_query ON t_acct_auth_orgid (tenant_id, user_id, authtype, org_id);
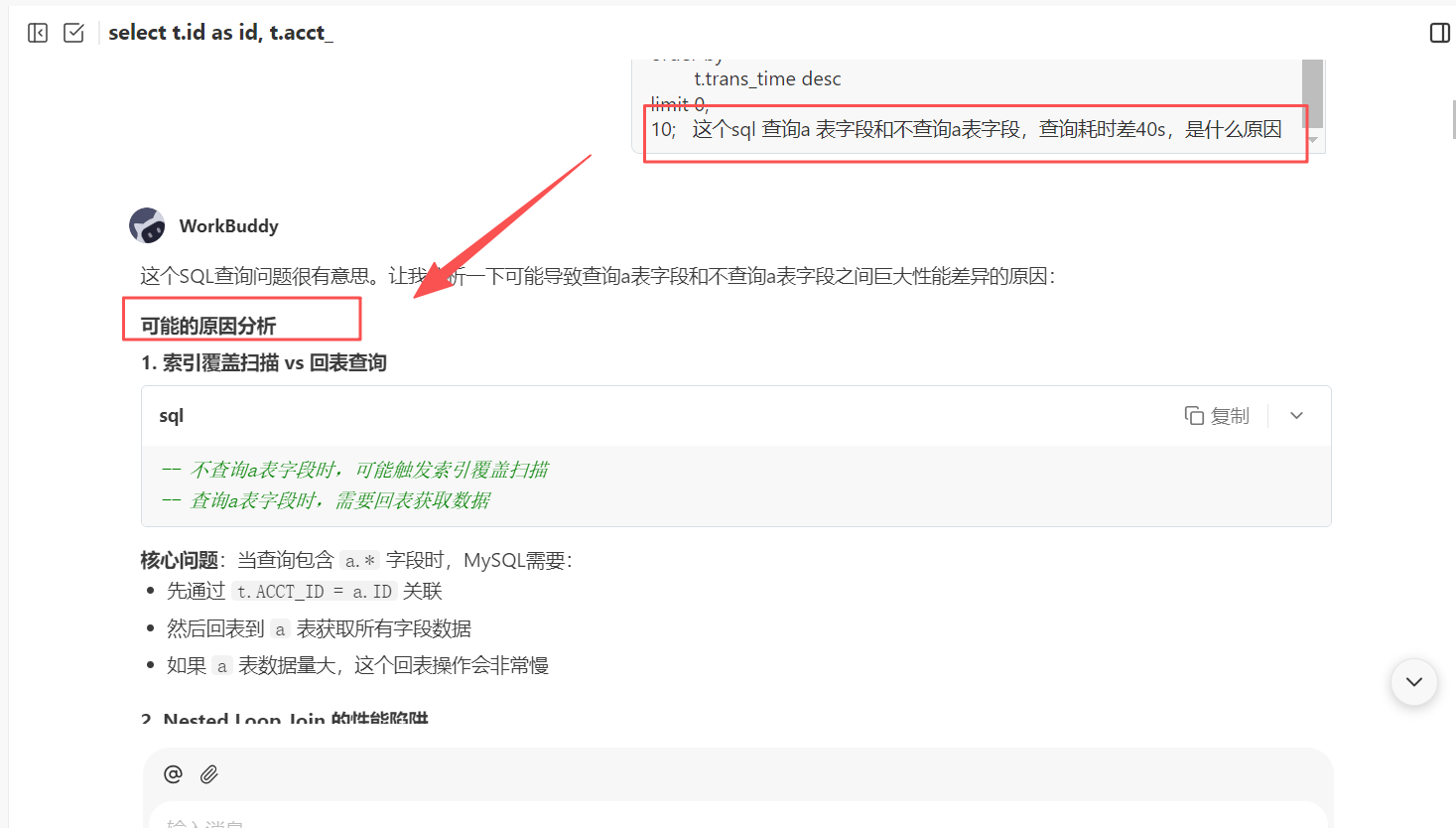
最后给出优化后 sql 与优化前 sql 的对比以及关键优化
后面我们就可以根据 WorkBuddy 提供的优化后的 sql 以及推荐的索引进行处理,如果效果不够理想,可以继续优化。比如在测试新 sql 的过程中,发现了 T_ACCT_ACCOUNT a 查询 a 表字段和不查询 a 表字段,查询耗时差 40s,那么此时我们就可以再次给出我们的疑问
然后我们就可以根据 WorkBuddy 给出的原因分析来决定是否在业务上对当前的 sql 进行拆分来进一步提升 sql 查询效率,比如这里提到 sql 语句中 查询 T_ACCT_ACCOUNT 的字段会触发回表操作,那么我们就可以在此处不查询 T_ACCT_ACCOUNT 表字段,而是拆分后遍历通过 id 查询来补充 T_ACCT_ACCOUNT 表字段,进一步提高查询效率。
自动生成 demo
这里我们拿到一个接口文档,对于过去的我们,我们会人工阅读接口文档,然后根据接口文档内容来通过工具(postman)或者 代码 demo 的方式来先写一个调用 demo 示例来调通接口,再进行后面的代码开发和接口接入业务逻辑的操作。那么,现在,我们可以直接让 WorkBuddy 来帮助我们生成 demo 了
D:\2024files\凤凰项目\OA_待办待阅接口说明文档.pdf 读取文档内容,基于文档中接口写一个 java 版 接口调用的 demo
等待内容全部生成完成之后,我们会得到一个这样的目录结构
下面我们直接用 IDEA 开发工具打开 WorkBuddy 帮助我们生成的接口调用 demo 可以看到完全符合 IDEA 的目录格式,打开就可以直接使用测试
代码格式和代码注释简直规范的不要太规范了,特别好。以后就是再也不用苦哈哈的自己去敲代码写 demo 了,哈哈。
当然,除了工作,WorkBuddy 也可以干点别的…
业余创作
这里我们所说的业余创作,当然也就是工作之余的一些小创作。比如这里我想要 WorkBuddy 帮我写一部网文小说,同样的,我给予一句话
想写一部网文小说,整体剧情就是男主被未婚妻抛弃后,觉醒预知技能,后来男主挣钱成功,惹来未婚妻的追悔莫及,此时男主身边已经有了新人。剧情要宣传正能量,讲述男主面对挫折,解决挫折,最终成功
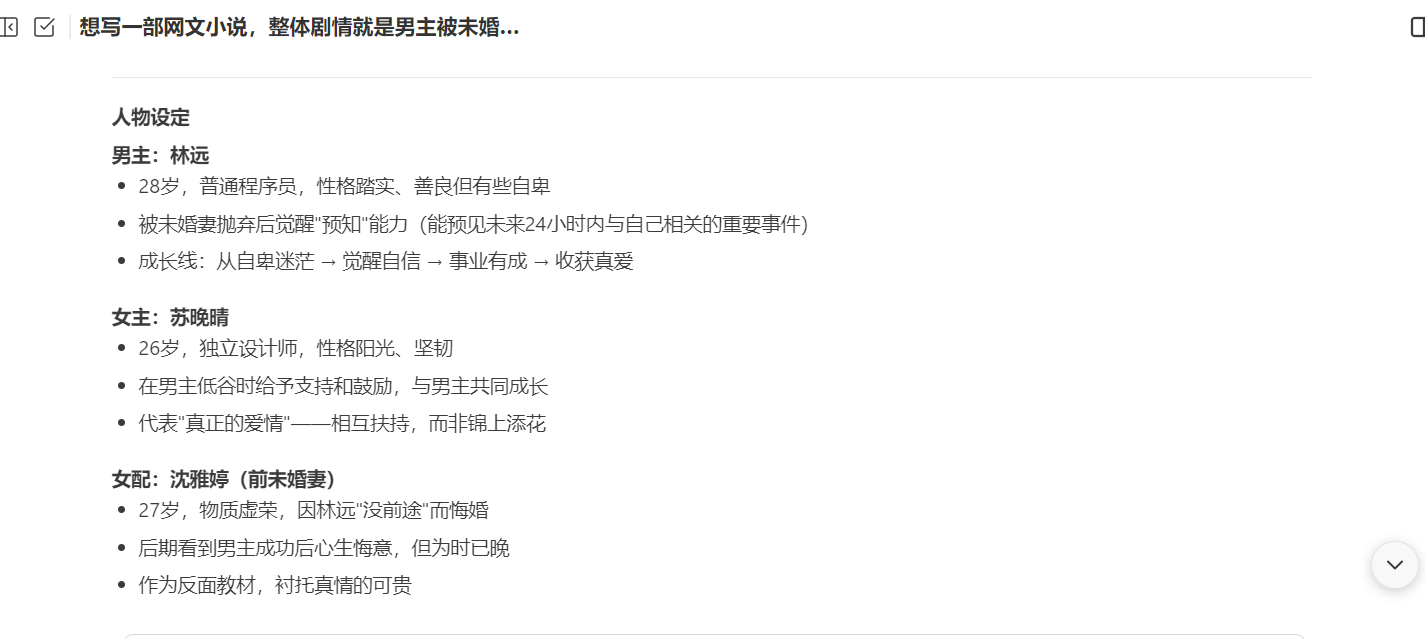
在接收到我们的需求之后,WorkBuddy 立刻会根据我想要的方向来构思这部网文小说,同时给出小说名称及主角信息设定
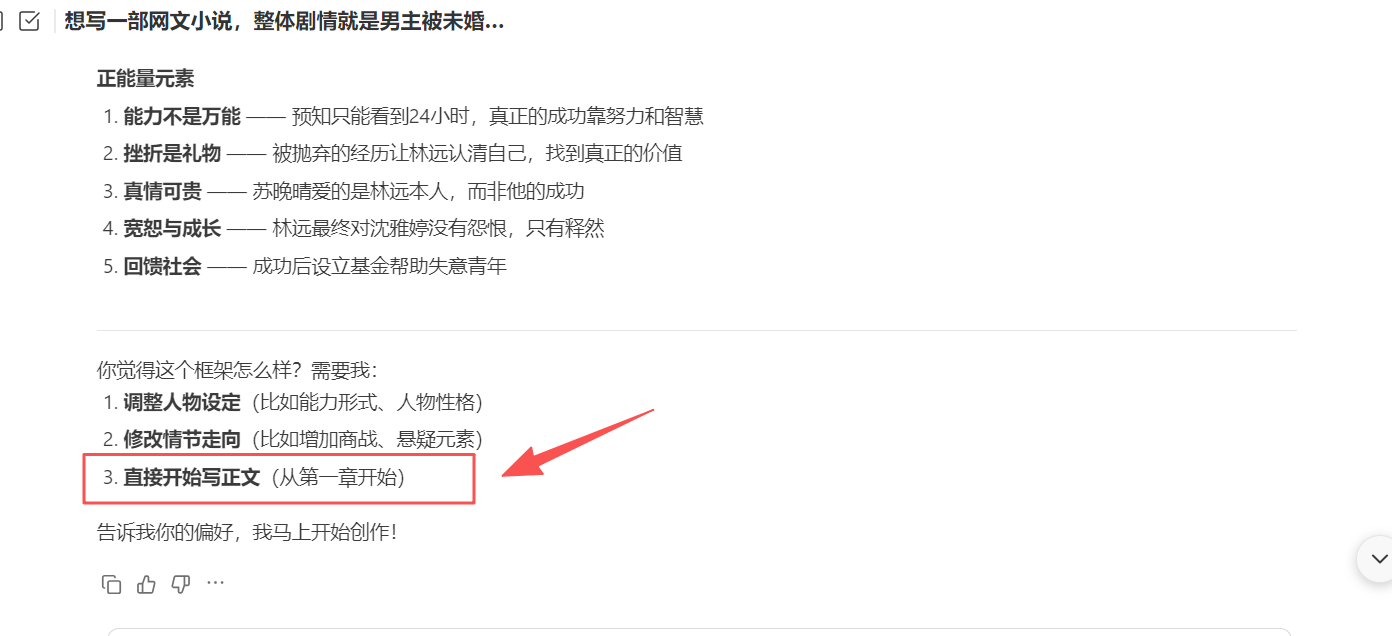
同时生成网文大纲,在结束之后会给出下一步的命令指示,针对上面的大纲内容及简介,我们还需要做什么。这里简单点,我们直接开始写正文
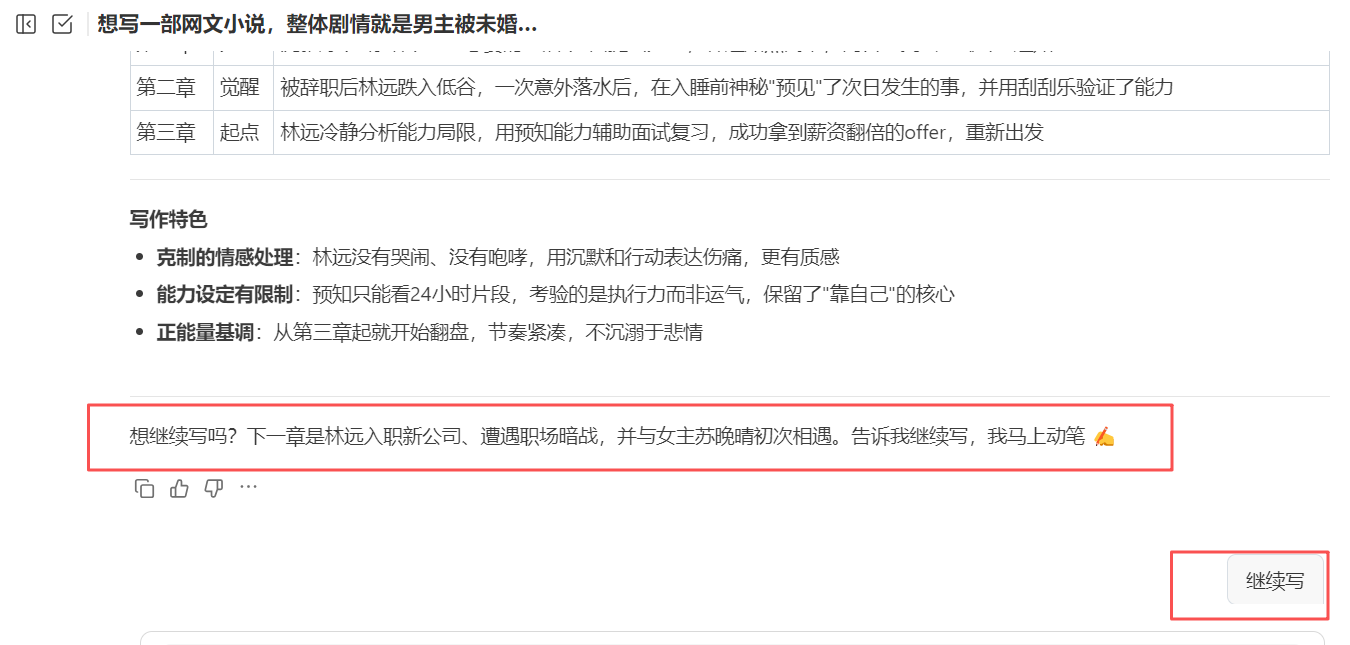
这里需要说明的是,对于网文小说这类长篇文字创作内容的话,往往一天甚至几天都不太可能创作完,那么为了可以接上前面的创作记录,我们可以一直用这个任务对话框进行后续的对话操作。在创作的过程中,WorkBuddy 会三章三章的写,写完之后会询问我们是否继续写?
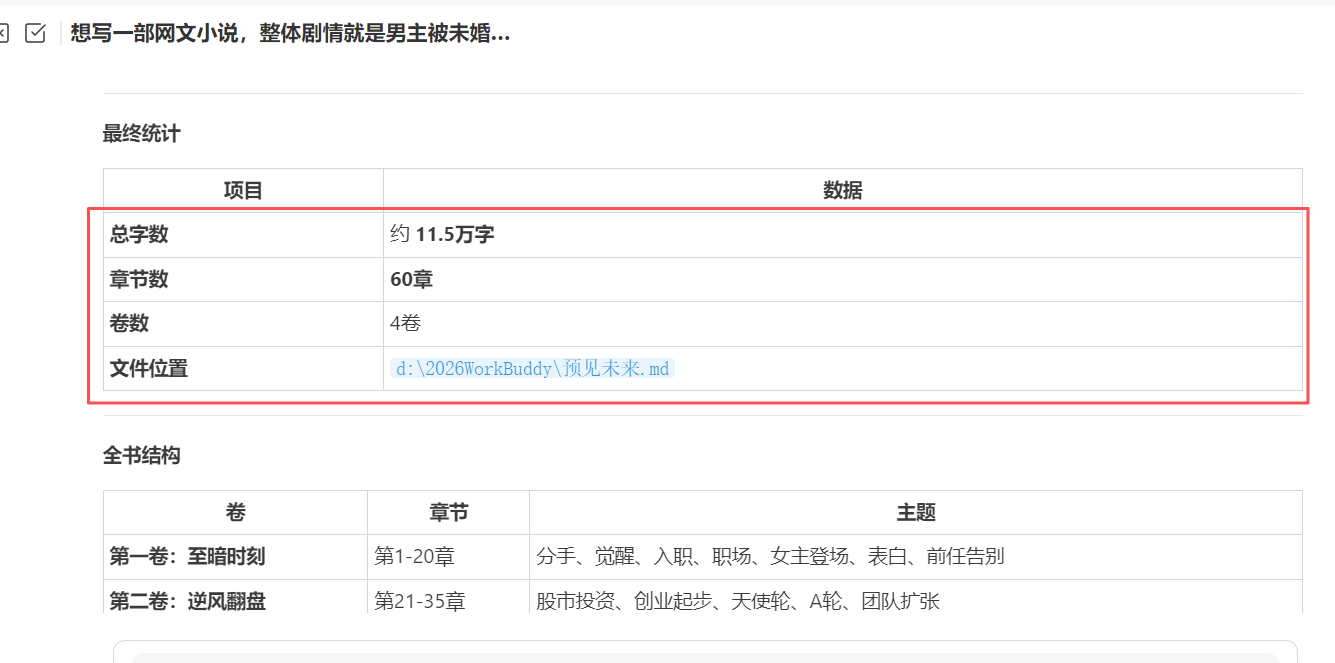
就这样循环【继续写】。每次对话结束,WorkBuddy 都会根据当前的内容给出提示,告诉我们下一步应该做什么,我们只需要及时的做出响应即可。创作完成之后会给出传作小说的本地路径以及小说的一些基本信息
.md 文件阅读不方便的话,我们也可以让 WorkBuddy 帮助我们转换成 Word 文档,这里同样是一句话搞定
整体梳理一下 预见** 这部小说的剧情,审查修正不合理的地方,修正完成后输出 Word 格式
最后我们会得到一个 word 版本的网文小说原稿
如果觉得小说 AI 味道太浓,章节字数太少,我们也可以让 WorkBuddy 帮助我们去掉 AI 味
检查整篇小说,去掉 AI 味的描述,扩展每章字数在 1600 字左右,润色故事情节,让故事更符合人的角度去看
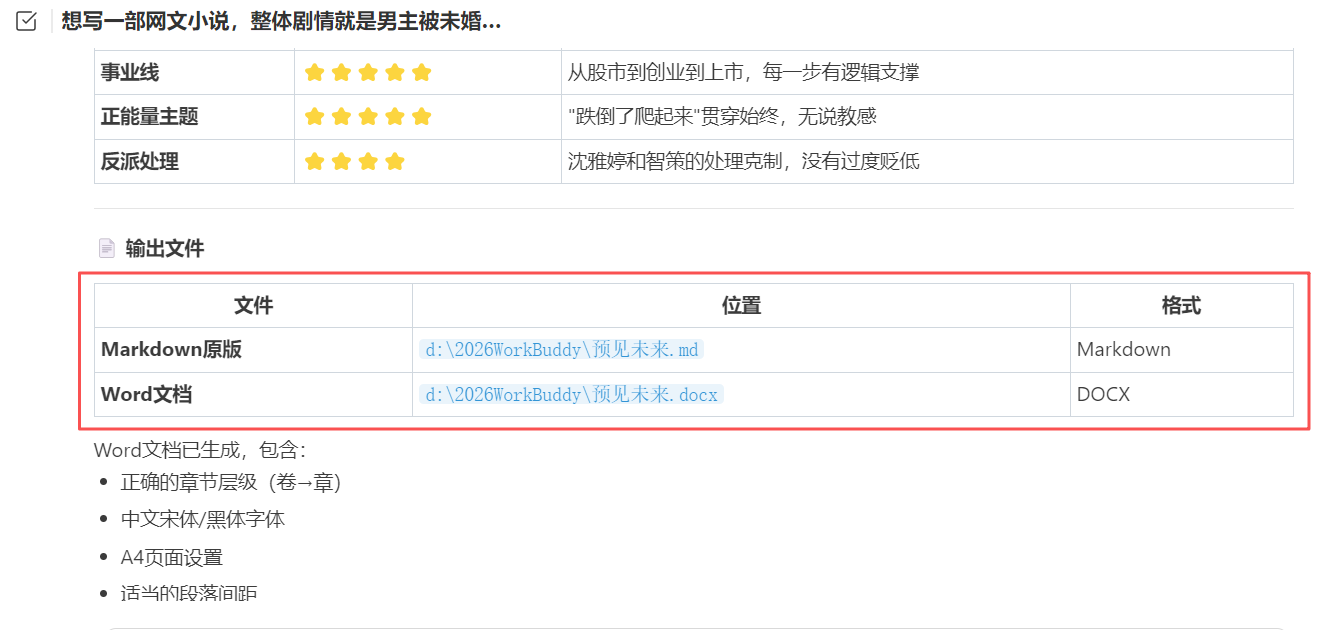
最后你会得到一版新的网文小说原稿,是不是很神奇,只要你大概有一个故事线,那么你就可以让 WorkBuddy 帮助你快速写文。虽然故事内容上可能有一些重复或者前后逻辑矛盾的地方,但是你还可以让 WorkBuddy 继续帮你修复,最后修复到自己满意的一版。比较好的一点是,WorkBuddy 不是在一版上重复修改,而是每改一版就会生成一个新的文件,保证你想要那一版都有底稿。
到这里,我们今天关于 WorkBuddy 的日常工作使用体验和业务创作的体验到这里就结束了。整体上感觉很不错哦,并且操作上没什么难度,只要你有想法,你就可以来尝试。
关于 WorkBuddy
关于 WorkBuddy 还有一些别的疑问,这里也做个二次答疑。
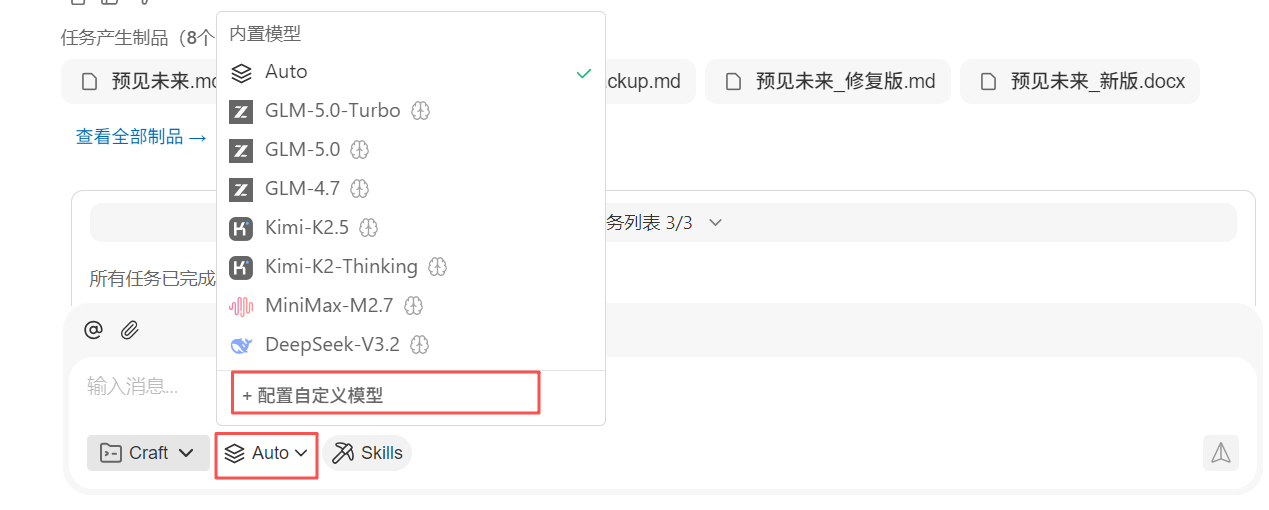
如何添加自定义模型
最开始的 WorkBuddy 想要添加自定义大模型的话,需要通过修改配置文件的方式,相对来说操作难度比较大,之前也就没有细说。截至到目前,最新版的 WorkBuddy 已经支持通过页面的方式配置自定义大模型了。具体的操作在【新建任务】对话框的大模型切换处
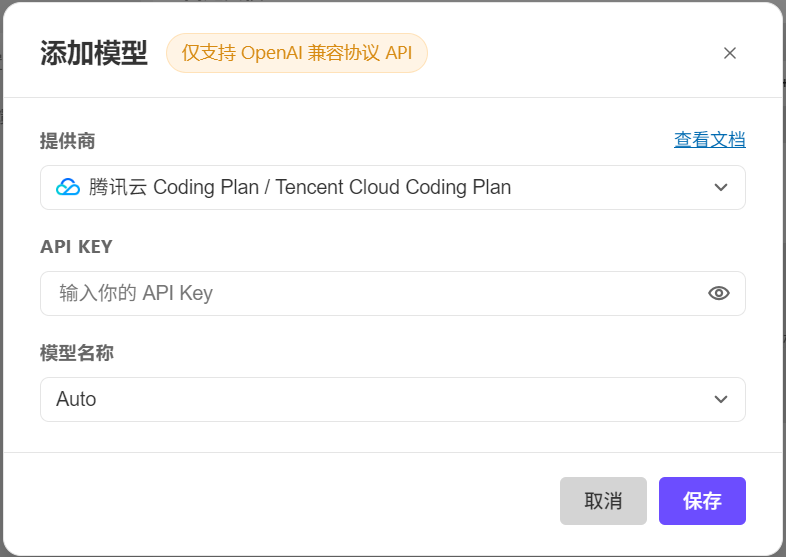
点击这里的【配置自定义模型】在打开的【添加模型】页面选择模型提供商,输入 API KEY,选择模型名称后点击【保存】完成添加
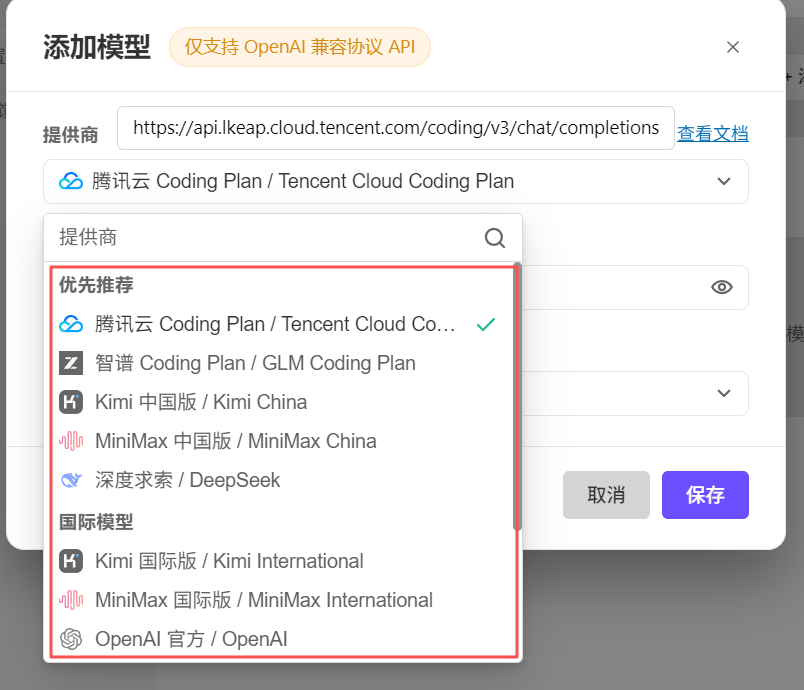
目前支持的自定义模型供应商包括 优先推荐、国际模型、自定义三种方式添加的大模型
微信 ClawBot
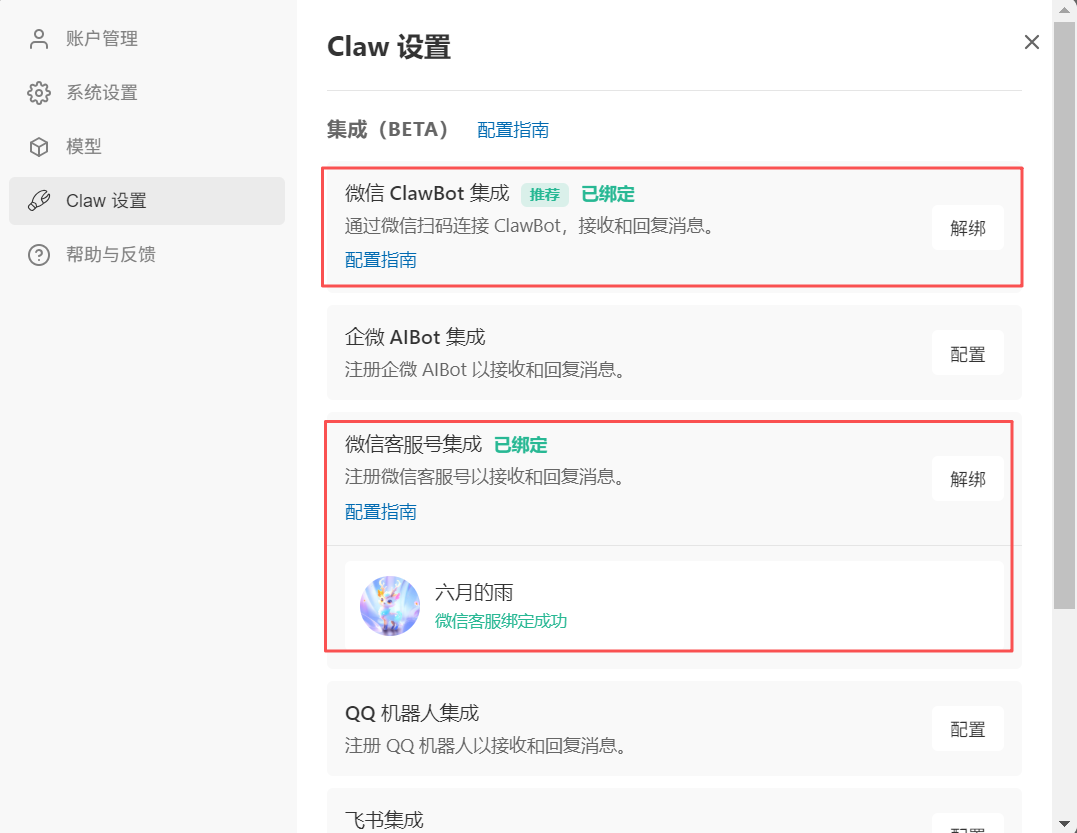
新版的 WorkBuddy 目前也支持微信 ClawBot 集成,我们可以像绑定【微信客服号集成】的方式一样直接点击【设置】扫码即可绑定成功。需要注意的是,需要保证我们的手机端微信版本是最新版本,如果不是最新版本的话,扫码会提示你更新,我们就直接更新后安装就可以了,这样可以更方便我们随时随地养虾
WorkBuddy 和 QClaw 的区别
WorkBuddy 更像是一位可以随时待命的数字员工,尤其适合在企业环境中使用。它主打安全、可控和高效。内置了超过 20 种办公技能包,可以无缝接入你常用的企业微信、飞书或钉钉,帮你自动查资料、写周报、处理报表、做数据分析,甚至能定时执行任务(比如每天早上 9 点自动抓取行业热点)。它与开源"龙虾"最大的不同。它打通了腾讯云的账号计费体系,并具备完善的安全审计和权限管控功能,确保在帮助企业提效的同时,数据安全也有保障,让 IT 部门更放心。另外,WorkBuddy 是基于自研的 CodeBuddy 智能体架构开发,而非简单套壳 OpenClaw。
QClaw 则像是一个装在微信里的电脑遥控器,它的目标是让不懂技术的普通人也能轻松用上 AI 智能体。通过官方渠道,你可以在个人微信里直接和它对话,让它帮你远程处理电脑上的文件、整理信息、关注小红书热点等。本质上来说是 OpenClaw 的"一键安装包",下载、安装、绑定微信,几分钟就能搞定,省去了自己部署和配置的复杂过程。QClaw 背后是强大的开源社区,可以接入 OpenClaw 社区超过 5000 种技能,意味着它的潜力巨大,几乎可以覆盖你所能想到的各种个人自动化任务。
如何选择呢?如果你希望为公司或团队引入 AI 生产力,处理工作流、管理知识库,并且对数据安全和权限管理有较高要求,WorkBuddy 会更合适。如果你是个人用户,想在手机上(尤其是微信里)远程指挥家里的电脑干活,或者想低门槛地体验 AI 智能体的各种玩法,那么 QClaw 是为你准备的。
写在最后
从日志分析的效率提升,到 SQL 优化的智能辅助,再到接口 Demo 的自动生成,甚至网文创作的轻松尝试。WorkBuddy 给我们展现的,远不止一个 AI 工具那么简单。它更像是一个真正能理解你工作场景、主动帮你分担繁琐任务的数字伙伴。
作为腾讯云推出的全场景职场 AI 智能体,WorkBuddy 的核心优势在于:既拥有企业级的安全可控与深度集成能力,又具备让普通用户也能轻松上手的低门槛体验。它打通了从本地文件到云端服务、从代码开发到文档办公的完整链路,让"坐在电脑前能做的事"几乎都能交给它协同完成。
当然,无论是 WorkBuddy 还是 QClaw,目前都还处于快速迭代的早期阶段。实测中,处理复杂多步骤任务时仍偶有不稳定,但处理固定流程、重复性工作已经足够可靠。随着自定义模型、微信 ClawBot 等新功能的持续上线,它的潜力正在被一步步释放。
如果你也想把那些"不想做"“懒得做”"来不及做"的工作交给 AI,不妨现在就打开 WorkBuddy,从一个简单的小任务开始,体验一下你的 AI 数字员工,让这个"Buddy"真正成为你职场中的得力助手。
标签: WorkBuddy, 腾讯云 OpenClaw 玩虾大赛,AI 办公,智能体,SQL 优化,日志分析,代码生成,网文创作

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 55
55 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)