深入研究RAG: Embedding(向量化)
前言
大家好,这里是程序员阿亮,今天继续讲解RAG的流程之一:Embedding
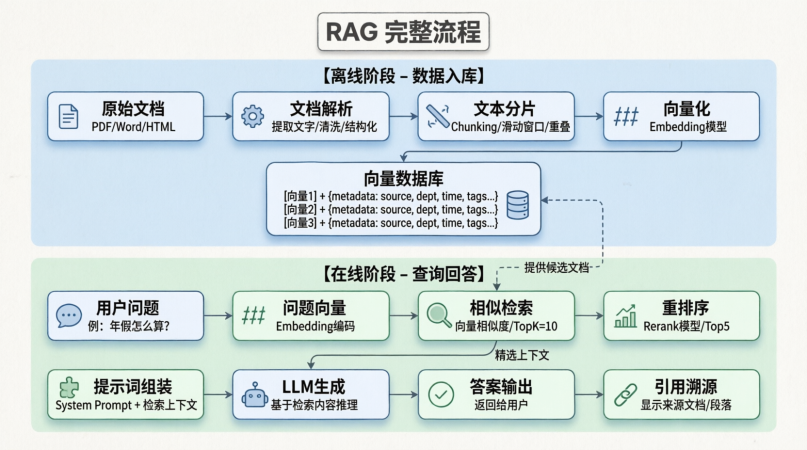
为了防止大家忘记前面的流程,我继续给大家放图:
前面的俩篇文章我们已经讲解了文档解析、文本分片,接下来就该讲解一波向量化了
一、什么是向量化(Embedding)?
计算机是个纯粹的理科生,它只认识数字 0 和 1,根本不理解什么是“猫”、什么是“冰箱”。我们要怎么让计算机知道:“猫”和“小狗”是近亲,而“猫”和“冰箱”八竿子打不着?
答案就是 Embedding(嵌入)。
通俗来说,Embedding 就是把人类的文字翻译成一串数字(也就是向量),让语义相似的文字,在数字世界里也长得相似。
想象一下这样的映射关系:
-
当你输入 "猫" 时,模型输出 [0.82, -0.15, 0.43...]
-
当你输入 "小狗" 时,模型输出 [0.80, -0.13, 0.45...](数字极其接近)
-
当你输入 "冰箱" 时,模型输出 [0.12, 0.67, -0.89...](数字天差地别)
在这个过程中,这串数字被称为向量 (Vector),这串数字的长度(比如包含 768 个浮点数)被称为维度 (Dimension)。
其实线代有更严谨得多的建议,但是我还是想用比较通俗的语言表达,实际上我们只要理解所谓向量就是多维的一组数字就好了。
二、语义的几何解释
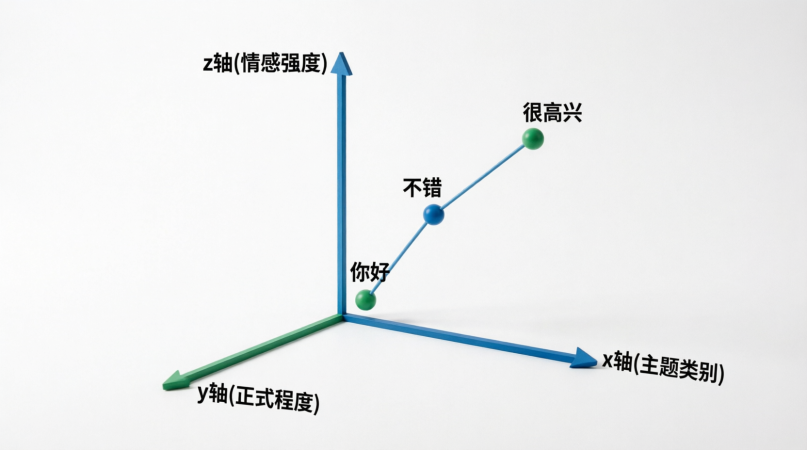
仅仅看一串数字是不直观的,我们不妨在脑海中构建一个几何空间。
假设我们有一个三维坐标系:X 轴代表“主题类别”,Y 轴代表“正式程度”,Z 轴代表“情感强度”。
当我们将词语放进这个空间时,奇妙的事情发生了:“很高兴”和“不错”这两个词在这个三维空间里的物理距离会非常近,而它们离“你好”就会有一段距离。
在向量空间里,物理距离越近,代表语义越相似;距离越远,代表语义越不相关甚至相反。
那么,计算机如何衡量这种“距离”呢?最常用的武器是余弦相似度 (Cosine Similarity):它计算的是两个向量在空间中夹角的余弦值。
-
夹角 0 度 ➔ 相似度 1.0 ➔ 意思完全相同
-
夹角 90 度 ➔ 相似度 0.0 ➔ 毫无关系
-
夹角 180 度 ➔ 相似度 -1.0 ➔ 意思完全相反
三、为什么是浮点数?
很多初学者会问:为什么不用简单的整数来表示?比如 1 代表猫,2 代表狗。
因为人类的语言语义是连续的,而不是离散的。
如果用整数,从“猫”到“狗”之间没有任何过渡。但如果使用浮点数,模型就能表达出极为细腻的灰度语义。比如,模型可以生成一个介于“猫”和“狗”之间的向量,用来完美表示“狐狸”这种既有点像猫又有点像狗的生物。
浮点数向量赋予了模型强大的“泛化能力”。即使模型从来没见过“猫咪”这个词,它也能通过计算,将其精准定位在“猫”的旁边。
四、 剥开黑盒:Embedding 模型内部架构揭秘
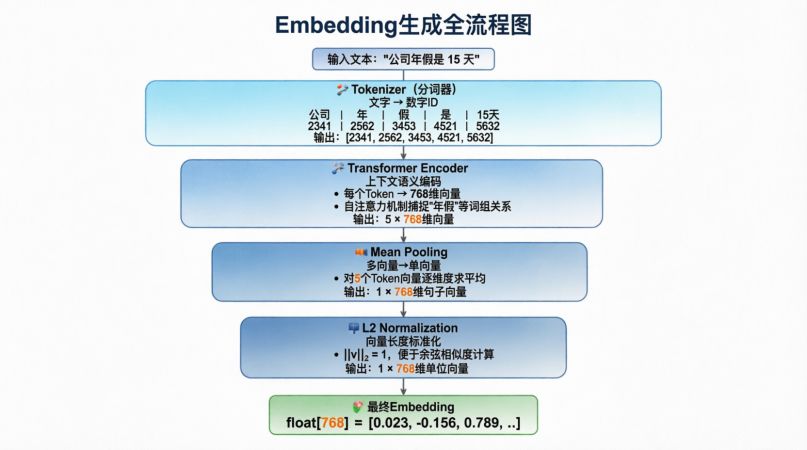
当你调用 API 把一句话丢给模型,然后拿到一串浮点数时,这中间到底发生了什么?让我们走进这台“语义制造机”的流水线,一步步看清它的四大核心组件。
第一步:Tokenizer (分词器) —— 现实文字到数字 ID 的签证官
模型是不认识汉字或英文字母的,第一步必须将文本打碎,映射成词汇表中的数字 ID。
英文通常按空格和词根分,而中文的分词则是一门玄学(按字分还是按词分?)。
你需要格外注意的是:不同模型的分词器是完全不通用的!
同一句“Spring AI 很好用”:
-
OpenAI 的分词器可能会切成 ["Spring", " AI", " 很", "好", "用"],对应 ID [1234, 5678, ...]
-
国内的 BGE 模型可能会切成 ["Spring", "AI", "很", "好", "用"],对应 ID [2345, 6789, ...]
如果分词器选错或混用,出来的向量就是一团乱码。
第二步:Transformer Encoder (编码器) —— 洞察上下文的智者
拿到数字 ID 后,真正的 AI 计算开始了。Transformer 编码器的核心超能力是“双向注意力机制”,这意味着它在看一个词时,会同时兼顾它左边和右边的词。
举个经典例子:
-
“我在银行存钱”
-
“我在河边银行(bank有河岸之意)散步”
Transformer 能敏锐地察觉到上下文的不同,为第一句的“银行”生成偏向金融语义的向量,为第二句生成偏向地理环境的向量。经过这一步,输入的每个 Token(词元)都会变成一个独立的 768 维向量。
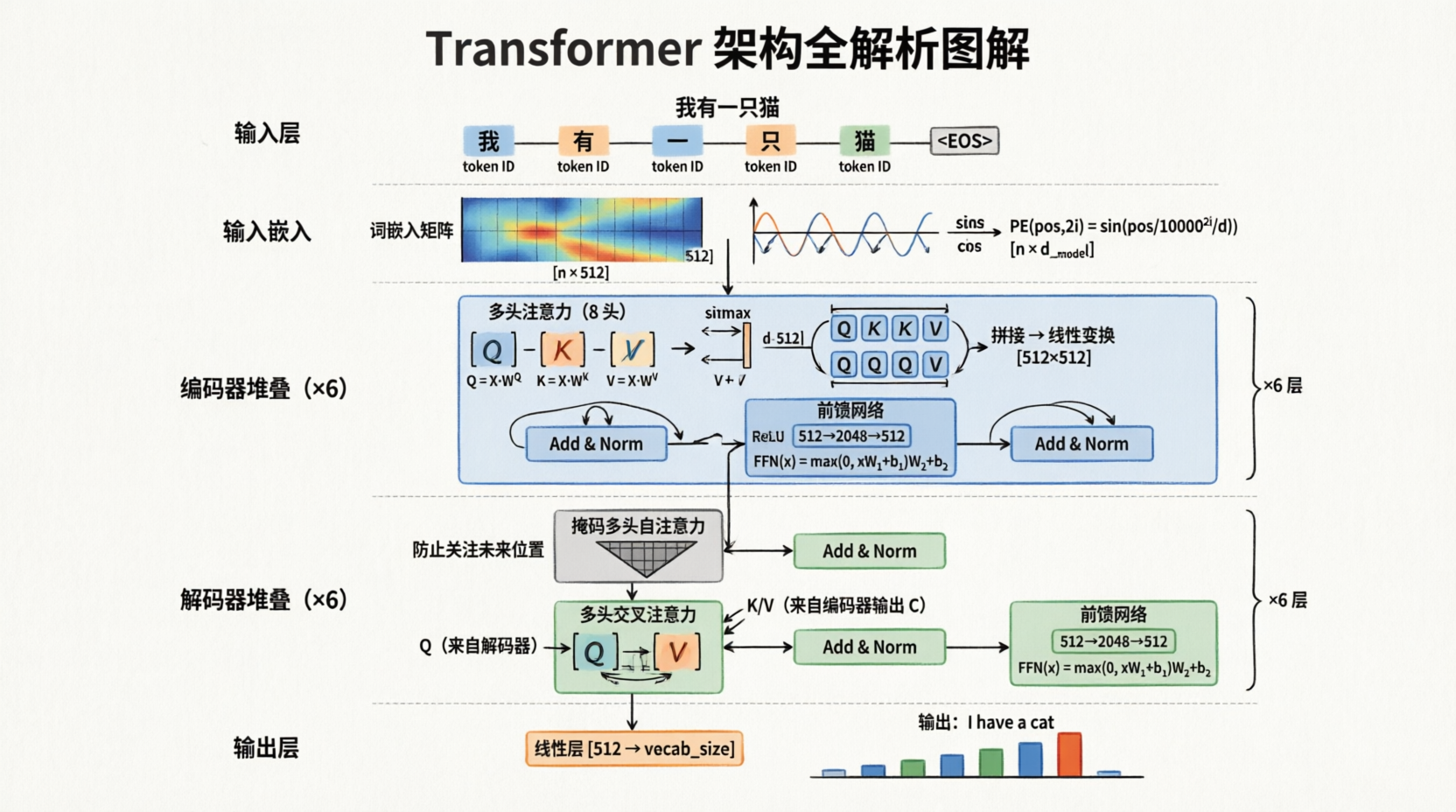
这里面实际上只用了Transformer的Encoder
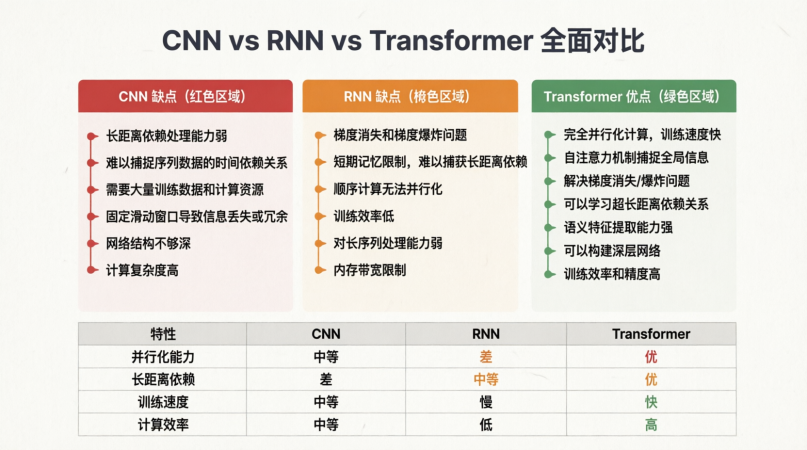
所谓Transformer实际上并不是什么复杂的架构,它的用通俗的含义来讲就是:
为了解决CNN全文依赖的 不足,以及RNN必须依靠上一个字的上下文去生成下一个字的线性生成的速度有限性、上文丢失问题
那么我们Transformer就表示,我直接把上下文都算到每个字里面,就好了!
这就是Transformer的核心:Attention机制
第三步:Pooling (池化) —— 万法归一的提炼术
经过上一步,一句话如果有 5 个词,就会产生 5 个向量。但存入数据库时,我们需要用一个向量来代表整句话。怎么办?这就是池化层的工作。
业界主要有三种做法:
-
CLS Pooling:直接拿这句话第一个特殊占位符(CLS)的向量代表全文。这种方法简单粗暴,相当于只看文章标题。
-
Max Pooling:取所有词在每一个维度上的最大值。它能凸显句子中最关键的特征,但会丢失一些细节。
-
Mean Pooling (平均池化):将所有词的向量相加求平均。这是目前业界最受推崇的方法。 它就像是开一场民主会议,综合了句子中每一个词的“意见”,得出的向量能最完整地代表整句话的全局语义。
第四步:Normalization (归一化) —— 绝对公平的度量衡
最后一步至关重要,却常被忽视:将生成的向量长度统一缩放为 1(即转换为单位向量)。
为什么要这么做?如果不归一化,有的向量长,有的向量短。在计算相似度时,你需要同时考虑方向和长度,这会让计算极其复杂且缓慢。
一旦所有向量的长度都变成了 1,我们要比较两个向量的相似度,就不需要算复杂的余弦角度了,直接将两个向量做简单的“点积(Dot Product)”即可。 这在处理千万级规模的数据检索时,能节省极其恐怖的算力和时间。
五、 实战抉择:Embedding 模型选型与避坑
在真实工程中,选模型就像选伴侣,没有绝对的最好,只有最合适。模型选型主要考量四个维度:向量维度(精度与存储的博弈)、最大上下文(决定切片大小)、语言支持(中文是否友好)、部署方式(云端还是本地)。
5.1 云端 API 模型:省心省力的土豪首选
如果你追求免运维、按需付费,并且数据可以出域(不存在涉密问题),云厂商的 API 是最优解。
-
text-embedding-3-small (OpenAI):当前通用场景的性价比之王。维度 1536,支持 8191 tokens 输入,价格低至 $0.02 / 100 万 Tokens(相当于处理 1000 篇千字长文只需一两毛钱人民币)。
-
text-embedding-3-large (OpenAI):预算充足且对精度有极高要求的场景,维度高达 3072。
5.2 开源本地模型:数据安全的终极防线
如果你的项目涉密,或者想彻底摆脱云厂商的长期账单,本地部署是必经之路。
-
bge-large-zh-v1.5 (智源):中文 RAG 绝对的首选。 1024 维,虽然最大支持长度只有 512 tokens,但其对中文语义的捕捉能力极其强悍,需要 8GB 左右的显存。
-
m3e-base:贫民窟福音。768 维,在纯 CPU 环境下也能跑得飞起,适合资源极度受限的场景。
-
nomic-embed-text:长文本克星。支持高达 8192 tokens,适合不愿把文档切得太碎的开发者。
5.3 血泪教训:选型必读的三大警告
警告 1:中文场景下,警惕纯英文模型!
千万别用早期的 ada-002 甚至一些缺乏中文训练的开源模型去处理纯中文文档。测试发现,这些模型遇到英文文档能给出 0.85 的相似度,遇到语义完全相同的中文文档,相似度却跌到了 0.65。做中文 RAG,务必选择带有 zh 后缀或在 MTEB 中文榜单上名列前茅的模型。
警告 2:维度一旦确定,就是数据库的“钢筋混凝土”。
如果模型输出 1024 维,而你的 PostgreSQL (pgvector) 或 Milvus 表结构建成了 1536 维,写入时会直接报 dimension mismatch 的致命错误。建表前,请反复确认模型文档。
警告 3:更换模型 = 推倒重来。
不同模型的向量空间是不兼容的! A 模型生成的 [0.1, 0.2...] 和 B 模型生成的 [0.5, 0.6...] 虽然代表同一个词,但在数学上它们存在于两个平行的宇宙。如果你在项目迭代中更换了 Embedding 模型,你必须清空向量数据库,用新模型把所有历史文档重新向量化一遍。
六、高阶 Embedding 与检索技术
当你的 RAG 系统跑通后,如果想让检索准确率从 70% 飙升到 95%,你需要祭出以下高级武器。
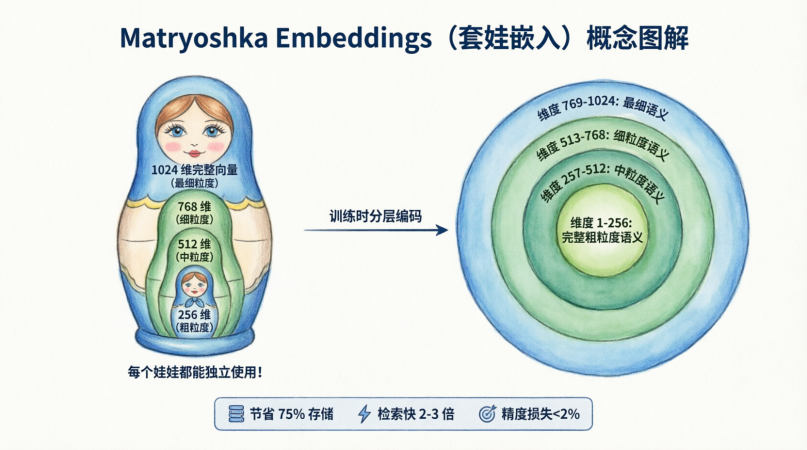
4.1 套娃嵌入 (Matryoshka Embeddings):弹性存储的艺术
想象一个俄罗斯套娃,大娃娃里面装着小娃娃。套娃嵌入技术让模型生成的一个长向量(如 1024 维)包含了从小到大的多层语义。
它的杀手锏在于:你可以直接截断向量。 比如为了省钱,你只取前 256 维存入数据库。传统模型这么干,语义会彻底丢失;但套娃模型(如 text-embedding-3 或 bge-m3)截断后,效果几乎不打折扣!
在工程上,你可以用 256 维进行粗排(提速 4 倍),再用完整的 1024 维进行精排,实现速度与精度的完美平衡。
4.2 ColBERT (多向量检索):不放过任何蛛丝马迹
传统的做法是一句话生成一个向量,这不可避免地会丢失词级别的细节。
ColBERT 颠覆了这一点:它为一句话中的每一个词都保留一个独立的向量。 当用户搜索“年假几天”时,系统会拿“年”、“假”、“几”、“天”四个词的向量,分别去全库扫描最匹配的词向量然后求和。
优点:对专有名词、特定业务术语的匹配极其精准。
代价:存储量暴增 5-10 倍,检索速度下降,属于“土豪专属”的高精度方案。
4.3 混合检索 (Hybrid Search):双剑合璧
纯向量检索有一个致命弱点:不擅长精确匹配。
当用户搜索报错代码 "ERR_503" 时,向量模型可能会去寻找“系统故障”、“错误说明”等语义相近的内容,反而把包含 "ERR_503" 关键字的精准文档排在后面。
解决方案就是混合检索:向量检索(捕捉语义) + 关键词检索(BM25,捕捉精确字符)。
最后通过倒数排序融合(RRF)算法,把两份结果按权重结合。这已经是当下企业级 RAG 系统的标配。
4.4 查询扩展 (Query Expansion):比用户更懂用户
用户经常很懒,只搜两个字:“年假”。光靠这两个字去向量库里大海捞针,极易命中“年度总结”等不相关的废话。
此时,我们可以让 LLM 做中间人。在去向量库检索前,先让 LLM 把问题扩充:“请问公司的年假政策是多少天?年假的申请流程和计算规则是什么?”
拿扩充后、语义饱满的句子去生成 Embedding 并检索,召回率(Recall@10)通常能飙升 15% 以上。
七、SpringAI中是如何配合Embedding的?
理论说罢,如何在 Java 生态中优雅地落地?借助 Spring AI,我们可以极大简化开发流程。但真正的资深工程师,会把精力放在省钱和提速上。
7.1 基础配置 (以对接 OpenAI 体系为例)
Spring AI 将底层的复杂性做了极好的封装。你只需要在 application.yml 中配置:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
embedding:
options:
model: text-embedding-3-small # 明确指定模型
dimensions: 1536 # 明确维度,防止数据库对不上在代码中,直接注入 EmbeddingModel 即可自动完成转换并存入向量库:
@Service
public class DocumentService {
private final VectorStore vectorStore;
// Spring AI 自动配置好了 EmbeddingModel,内置于 VectorStore 的执行逻辑中
public void addDocument(String text) {
Document doc = new Document(text);
vectorStore.add(List.of(doc)); // 内部自动调用 Embedding API 并入库
}
}5.2 本地化大杀器:Ollama 无缝集成
如果你选择了前面的 bge-large 本地模型,配合 Ollama 简直是绝杀。
安装好 Ollama 并拉取模型(ollama pull bge-large)后,仅需改动配置文件:
spring:
ai:
ollama:
base-url: http://localhost:11434
embedding:
model: bge-large你的代码一行都不需要改,底层的 Embedding 引擎已经丝滑切换到了本地。
5.3 进阶优化 1:实现 Embedding 缓存(为老板省钱的核心秘籍)
在实际业务中,相同的文档、相同的用户高频查询会被反复计算。调用 Embedding API 虽然便宜,但也架不住高并发的积少成多,而且网络开销极大。
不要裸奔调用 API,务必在前面挡一层缓存!
@Service
public class CachingEmbeddingModel implements EmbeddingModel {
private final EmbeddingModel delegate; // 实际调用的模型
private final CacheManager cacheManager; // Spring Cache
// 省略构造函数...
@Override
public EmbeddingResponse embed(EmbeddingRequest request) {
String text = request.getInstructions();
// 用文本的 MD5 作为缓存 Key
String cacheKey = DigestUtils.md5Hex(text);
Cache cache = cacheManager.getCache("embeddings");
float[] cachedVector = cache.get(cacheKey, float[].class);
// 缓存命中,直接返回,一分钱不花,0 延迟
if (cachedVector != null) {
return new EmbeddingResponse(new Embedding(cachedVector, null));
}
// 未命中,走网络请求
EmbeddingResponse response = delegate.embed(request);
// 将结果塞入缓存
cache.put(cacheKey, response.getResult().getOutput());
return response;
}
}经过测试,对于结构化较强的内部知识库,这个简单的拦截器能节省 90% 的 API 成本和 88% 的处理时间。
5.4 进阶优化 2:批量处理 (Batching) 与防爆雷
向量化历史文档时,如果你用 for 循环一条一条发请求,不仅慢到怀疑人生,还容易触发并发限制。
必须将文本打包成 List 批量发送。但这里隐藏着一个深坑:Token 超限。
以 OpenAI 为例,一次请求的总 Tokens 数通常不能超过 8191。如果你盲目地把 100 篇长文档放在一个批次里,必然会收到 400 Bad Request: maximum context length exceeded。
工程实践最佳方案: 在发送前,粗略估算字符串长度(比如中文 1000 字符 ≈ 600 Tokens),动态控制每批次的 List 大小,确保总量安全。
八、Embedding 评估与可视化调试
如何向老板证明你选的模型、做的优化是有价值的?不能靠“我感觉挺准的”,你需要数据和可视化。
6.1 查阅权威榜单与本地验证
对于通用能力,直接查看 HuggingFace 的 MTEB 排行榜。如果你做的是 RAG 系统,不要看总分,死盯 Retrieval (检索) 这一列的得分。
在本地,你可以写一个简单的测试类,计算“正样本”(应该相似的句子)和“负样本”(毫无关联的句子)的余弦相似度差值。
健康的标准是:正样本的相似度(如 0.85)应该比负样本(如 0.20)高出至少 0.3 以上。如果发现两者都在 0.7 左右,说明这个模型对你的业务数据毫无区分度,赶紧换模型。

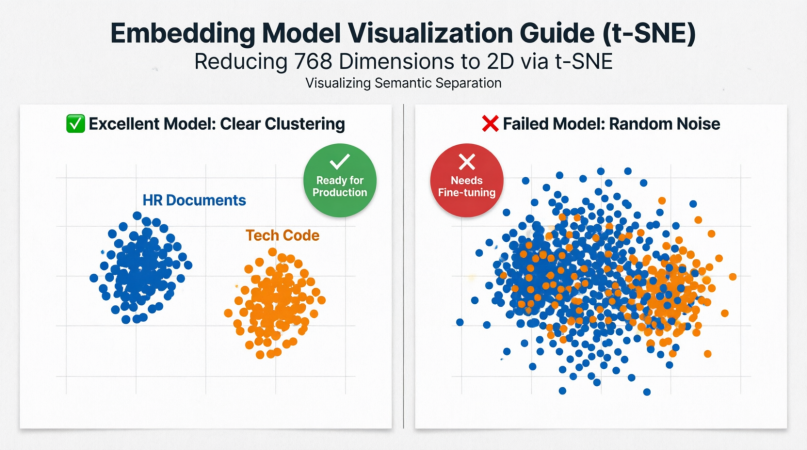
6.2 开启天眼:t-SNE 降维可视化
人类看不懂 768 维的空间,但我们可以用 Python 脚本结合 t-SNE 算法,把高维向量“拍扁”到二维平面上画成散点图。
如果你看到:HR 制度文档聚成一团,技术代码规范聚成另一团,且两团界限分明——恭喜你,你的 Embedding 模型极其优秀。
如果你看到:各种类别的文档像满天星一样毫无规律地混杂在一起——别犹豫,这模型在你的垂直领域失效了,需要重新微调(Fine-tuning)或更换。
总结
好,那么本文的Embeddin之旅就到此结束,接下来,下一篇就开始讲解查询部分的检索增强了!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)