大模型RAG嵌入向量数据库实战
向量数据库概念介绍
RAG的入库流程,也称为索引构建或数据摄取(Ingestion),这个流程的核心目标是:将非结构化的文本数据,转化为结构化的、富含语义信息的“知识碎片”,并建立高效的索引,转化为大型语言模型(LLM)可以检索和利用的结构化知识库的过程。入库的质量直接决定了RAG系统检索的上限,一个高质量、易于检索的知识库,直接决定了您的大模型在回答特定领域问题时的准确性和可靠性。
- 做什么: 将所有文本块的向量,连同它们对应的原始文本内容,一起存储到专门的数据库(向量数据库)中,并建立高效的索引。
- 为什么: 当用户提问时,系统需要快速地从数百万个向量中找到最相关的几个。索引就像图书馆的检索系统,能实现海量数据下的毫秒级查询。
- 关键点:
-
- 数据库选择: 常用的向量数据库有Chroma, Pinecone, Weaviate, Milvus, Faiss等。
- 存储内容: 数据库中存两样东西:向量(用于快速搜索)和 元数据(如来源文件名、页码、创建时间等,用于后期筛选和溯源)。
Embedding模型介绍
在检索增强生成(Retrieval-Augmented Generation, RAG)系统中,嵌入(Embedding)模型承担着将文本转换为向量表示的核心职责,直接决定检索质量的上限与整体系统的可扩展性。本节课围绕LlamaIndex框架,系统梳理与评估主流Embedding模型的集成路径、性能特征与成本结构,面向企业级落地给出可操作的选型策略与实施路线。
- Embedding 模型是一位博学的“索引员”。他阅读每一个文本块,然后根据其深层语义(而非表面关键词)为每个块生成一个独一无二的、浓缩了其含义的“身份ID”(即向量)。语义相近的段落,其“身份ID”在空间中也彼此接近。
- 向量数据库是“索引卡系统/GPS”,它不存储书籍原文,而是存储所有文本块的“身份ID”(向量)以及指向原文的链接。当你提出问题时,它能在毫秒级内找到与问题“身份ID”最相近的那些文本块的位置。
- 核心思想:入库的目标是构建能让 LLM 快速、精准找到相关知识的“语义地图”。
- 提示:后续章节将从模型选型、成本与评估、到向量库与组件协同逐步展开,并给出可运行的示例。
主流Embedding模型对比(云 API vs 本地开源)
|
集成类型 |
典型依赖 |
配置要点 |
优势 |
注意事项 |
|
云端API(OpenAI、Cohere) |
对应Python客户端、API密钥 |
通过LlamaIndex的Embedding类配置模型ID与参数;可设置base_url兼容自建兼容层 |
快速上线、免运维、弹性扩容 |
成本随调用量线性增长;需关注速率限制与数据出境合规 |
|
本地开源(HuggingFace/SentenceTransformers、BGE) |
sentence-transformers或特定模型库;可选ONNX/Optimum |
通过HuggingFaceEmbedding等类加载;可配置最大序列长度、维度与指令模板;可导出ONNX加速 |
数据可控、长期TCO友好、可离线使用 |
初期工程投入较高;需自建服务与监控;硬件与吞吐需评估 |
- 云端 API:免运维、弹性扩容,多语言强;需关注成本、速率限制与数据合规。
- 本地开源:数据可控、长期 TCO 友好;需工程投入与运维能力。
- 选型决策:
-
- 合规/数据边界严格 → 本地开源(
BGE/M3E)。 - 多语种与全球化 → 云 API(OpenAI/Cohere)。
- 成本敏感/入门 →
text-embedding-3-small或jina-embeddings-v2。 - 性能精排 → 组合
Embedding + Reranker(OpenAI/BGE Reranker)。
- 合规/数据边界严格 → 本地开源(
主流Embedding模型特性对比与中文推荐
|
模型系列 |
代表模型 |
维度 |
最大序列长度 (Tokens) |
核心优势 |
主要适用场景 |
|
OpenAI |
text-embedding-3-large |
3072 / 1536 / 512 |
8192 |
顶级通用语义理解、多语言能力强 |
高质量检索、复杂和多语言业务 |
|
OpenAI |
text-embedding-3-small |
1536 / 512 |
8192 |
极高性价比、性能均衡 |
大规模索引、成本敏感型应用 |
|
Cohere |
embed-multilingual-v3.0 |
1024 |
512 |
强大的多语言能力,与Rerank模型生态协同好 |
全球化业务、需要高质量精排的场景 |
|
BGE (BAAI) |
BGE-M3 |
1024 |
8192 |
多功能(稠密、稀疏、多向量)、长文本、中英文强 |
混合检索、长文档问答、中英混合场景 |
|
M3E(Moka AI) |
m3e-base / m3e-large |
768 |
8192 |
多语混合(中英优),长文本支持、检索表现强 |
企业多语种检索、中文主导场景、长文档问答 |
|
Jina AI |
jina-embeddings-v2-base-en |
768 |
8192 |
性价比高,长文本支持好 |
预算有限但需要处理长文本的场景 |
|
智谱AI |
Embedding-3 |
256 / 512 / 1024 / 2048 |
8K |
维度上进行多种选择 |
支持中文/英文混合、大段文本、甚至跨模态的语义检索 |
- 中文入门:
BAAI/bge-small-zh或moka-ai/m3e-base。 - 进阶:
BGE-M3(支持稠密/稀疏/多向量、长文本检索)。 - 生产:参考 MTEB 榜单,结合业务场景做 A/B 测试。
-
- MTEB榜单(Massive Text Embedding Benchmark (大规模文本嵌入基准) ),这是一个用于评估和比较文本嵌入模型性能的权威基准测试。
- 链接:https://huggingface.co/spaces/mteb/leaderboard
- A/B测试就是将一个“新版本”(B)的大模型应用与当前“线上运行版本”(A)进行对比实验,在真实用户中评估哪个版本的综合表现更好。
- 提示:维度越高通常检索效果更稳,但存储与计算成本更高;最大序列长度影响切分与上下文覆盖。
from llama_index.core.settings import Settings
import os
from llama_index.embeddings.openai import OpenAIEmbedding
from dotenv import load_dotenv
# 加载环境变量
load_dotenv()
# 设置为全局默认Embedding模型
Settings.embed_model = OpenAIEmbedding(
model="text-embedding-3-small", # 模型的维度是1536
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL", "https://api.openai.com/v1"),
dimensions=1536, # 可控制返回向量的维度
embed_batch_size=100, # 控制批量处理文本时每个批次包含的文本数量,提高吞吐量,减少API的调用量
timeout=60, # 配合batch size设置合理超时
max_retries=3 # 批量失败时的重试机制
)
# 将文本进行向量化
embeddings = Settings.embed_model.get_query_embedding("hello world")
print(len(embeddings))价格对比与预算估算(每1m tokens)
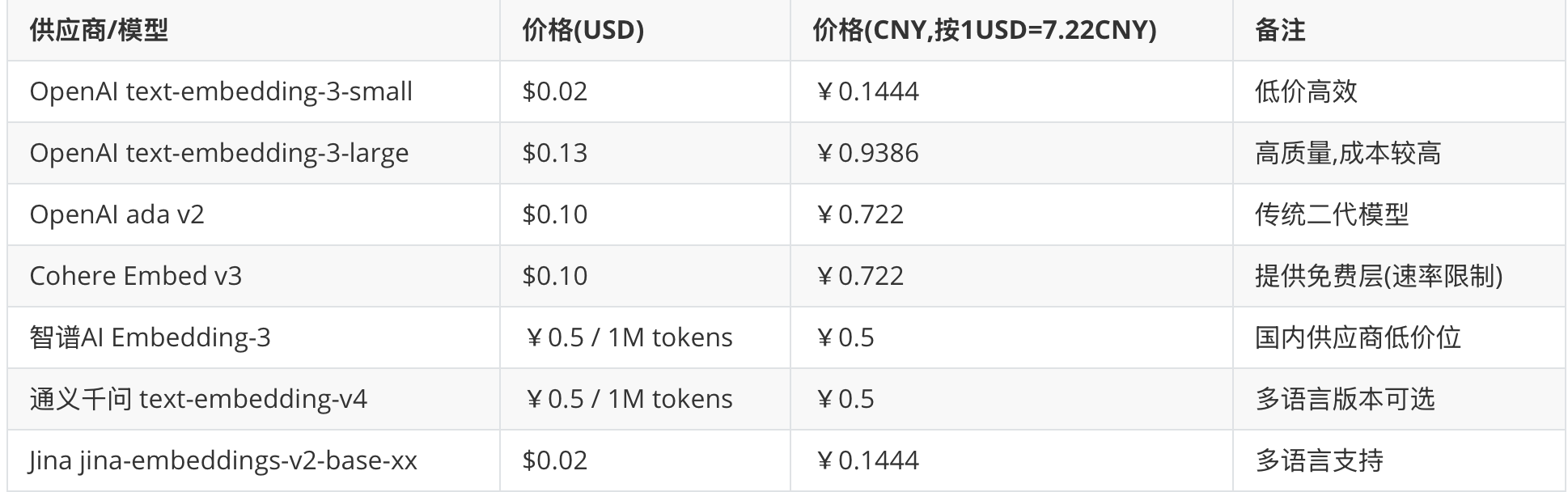
- 入库成本 ≈ 文档总
tokens× 单位价;查询成本 ≈ 每次查询tokens× 单位价 × 查询频次。 - 建议:先做样本测试评估,再估算全量入库预算,合理设定
top_k与缓存策略。
本地部署实践(HuggingFaceEmbedding)
|
集成类 |
依赖 |
关键特性 |
适用场景 |
|
HuggingFaceEmbedding |
sentence-transformers |
通用包装,易用;可选BGE、Instructor、E5等模型 |
快速试用与通用本地检索 |
|
InstructorEmbedding |
Instructor + SentenceTransformers |
指令模板区分query与passage;增强语义区分 |
检索粒度要求高、指令可控场景 |
|
OptimumEmbedding |
transformers + Optimum[exporters] |
ONNX导出与加速;跨平台兼容 |
吞吐优化、CPU/边缘部署 |
- 步骤:安装
HuggingFaceEmbedding→ 选模型 → 本地加载与缓存 → 可选Optimum/ONNX加速。 - 常见问题:CUDA 不匹配、网络下载失败(代理)、内存不足(调小
batch_size)。
from llama_index.core.settings import Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# 设置为全局默认Embedding模型
Settings.embed_model = HuggingFaceEmbedding(
model_name='BAAI/bge-large-zh-v1.5', # 模型名称,可以在魔搭社区或者huggingface上查询
device="cpu", # 有显卡的使用cuda:0
embed_batch_size=64, # 控制批量处理文本时每个批次包含的文本数量,提高吞吐量,减少API的调用量
)
# 将文本进行向量化
embeddings = Settings.embed_model.get_query_embedding("hello world")
print(len(embeddings))评估指标定义与计算逻辑
|
指标 |
定义 |
计算逻辑 |
解释与适用场景 |
|
Hit Rate@k |
前k条检索结果包含正确答案的是否命中 |
Hit Rate = 命中查询数 / 总查询数 |
衡量“能否找到”,适合召回充分性的对比 |
|
MRR@k |
正确答案的首次出现位置的倒数,在前k条内的平均值 |
MRR = (1/rank_i)之和 / 总查询数,其中rank_i为第i个查询的正确答案首次排名 |
强调“找得准”,适合首条答案质量敏感的业务 |
HitRate @k:前 k 条检索结果包含正确答案的查询是否命中,它只关心“有”或“没有”,不关心排名位置,是否存在至少一个相关(即能用来正确回答问题)的文档
-
- 存在则得分为1;否则为0。
- K值的选择:
-
-
- Hit Rate @ 1:非常严格,要求最相关的文档必须排在第一位。这衡量了系统的“精准度”。
- Hit Rate @ 5/10:更宽松,更侧重于衡量“召回率”。只要正确答案出现在前5或前10,就算成功。这在实践中更常用,因为后续的LLM可以从多个片段中综合信息。
-
-
- 特点:简单、快速,能宏观反映检索的可靠性。
MRR @k:正确答案首次出现位置的倒数,在前 k 条内的平均值,即平均倒数排名。它不仅关心是否检索到了相关文档,还关心相关文档的排名位置。排名越靠前,得分越高。
-
- 它比Hit Rate更精细,能反映出排序模型的质量。
- 对于单个问题,找出排名最高的相关文档所在的位置(排名)。例如,第一个相关文档排在第2位,则其排名为2。
- 计算这个排名的倒数。在上例中,倒数就是 1/2 = 0.5。如果没有任何相关文档,则倒数为0。
- 对所有问题的倒数得分取平均值。
# RetrieverEvaluator
from llama_index.core.evaluation import RetrieverEvaluator,generate_question_context_pairs
from llama_index.core.schema import TextNode
# 自定义测试数据
nodes = [
TextNode(text="""在检索增强生成(RAG)系统中,文档切分与 Node 转换作为连接原始数据与语言模型的关键预处理环节,直接决定了系统的检索精度、生成质量及整体性能。行业实践数据表明,90% 的 RAG 效果问题源于元数据与分块策略不当,而通过优化分块策略可使检索准确率提升 30 - 50%,语义分块较固定分块的准确率优势可达 27%。这一技术环节的重要性体现在:分块过大易引入冗余噪音,增加语言模型理解负担;分块过小或切分不当则可能破坏语义连贯性,导致完整知识点被拆分;未能适配文档结构的机械分块方式还会忽视标题、列表等结构化信息,影响信息提取完整性。"""),
TextNode(text="""LlamaIndex 作为连接自定义数据与大语言模型(LLMs)的核心框架,通过将文档(如 PDF、文本文件)分解为包含文本内容、向量嵌入和元数据的 Node 组件,构建了结构化文档管理的技术范式。其核心抽象在于将原始文档转换为语义连贯的 Node 集合,向量存储仅保留 Node 内容的嵌入向量与文本信息,这一机制简化了索引构建流程并提升了检索相关性。文档切分与 Node 转换的质量不仅影响向量检索的效率,更决定了上下文增强(Context Augmentation)这一 RAG 核心能力的实现效果。"""),
TextNode(text="""本文聚焦文档切分与 Node 转换的技术实践,结合 LlamaIndex 框架的实现机制,系统调研分块策略设计、元数据管理及 Node 组件化等关键技术点。通过分析行业最佳实践与典型案例,旨在为 RAG 系统开发者提供可落地的优化方案,解决分块噪音、语义断裂、结构信息丢失等核心痛点,为构建高性能检索增强生成应用奠定技术基础。"""),
]
def load_corpus_and_queries():
# 示例:从文件加载语料与查询(实际实现需按企业数据格式适配)
index = VectorStoreIndex(nodes,embed_model=Settings.embed_model)
# 模拟用户提出的问题
queries = ["在RAG系统中,文档切分与节点转换不当可能导致哪些具体问题?",
"在LlamaIndex框架中,一个Node组件通常包含哪些核心元素?",
"通过研究文档切分与Node转换,帮助RAG系统开发者解决哪些核心痛点?"]
# 模拟正确答案的node_id
qrels = ['7c4ee258-36fa-4907-afe3-a7e3e894562a',
'67b2fe9b-1a76-4ab2-9fb9-6b6581b1d440',
'26fff0e9-2ecf-40ad-af7c-779e43c75762']
return index, queries,qrels
index,queries,qrels = load_corpus_and_queries()在实际RAG评估中的应用建议
- 结合使用:这两个指标是互补的,而不是互斥的。一个优秀的RAG检索系统应该同时拥有高Hit Rate和高MRR。
-
- 高Hit Rate + 低MRR:系统能找到答案,但经常把它们藏在后面。你需要优化排序模型/重排器。
- 低Hit Rate + 高MRR(较少见):系统排在前面的东西质量很高,但经常完全漏掉正确答案。你需要优化召回,比如调整分块策略或使用更强大的嵌入模型。
- 与生成指标结合:Hit Rate和MRR是检索器指标。要全面评估RAG,还需要将它们与生成器指标结合,例如:
-
- Faithfulness:答案是否基于检索到的上下文,没有胡编乱造?
- Answer Relevance:答案是否直接回答了问题?
- Context Relevance:检索到的上下文是否精炼且相关?
模型使用思考
- 延迟敏感:客服 FAQ/短问短答 → 轻量模型与低
top_k。 - 长文档问答:注意切分策略与最大长度;推荐
BGE-M3、较大维度模型。 - 跨语种:选择多语言模型或分语种路由;可引入翻译与多向量策略。
- 迭代路线:纯向量检索 → 加入 Reranker → 引入 Hybrid Search混合检索。
向量数据库多维度对比
存储能力矩阵与选择要点
|
向量存储 |
存储文本 |
元数据过滤 |
混合检索 |
删除/更新 |
持久化形态 |
部署复杂度 |
典型场景 |
|
SimpleVectorStore |
是(默认内存,可持久化) |
支持(框架层过滤) |
依赖后端能力 |
支持删除与持久化 |
本地文件 |
低 |
快速实验、本地小规模 |
|
Chroma |
支持(集合中管理文本与元数据) |
支持 |
部分能力(依实现与查询) |
支持 add/update/upsert/delete |
本地/持久化/容器 |
中 |
开发者友好、本地到中小规模 |
|
Pinecone |
否(侧重向量;文档内容依赖外部存储) |
支持 |
支持(稠密/稀疏/混合) |
支持删除与命名空间清理 |
云托管(Serverless) |
低-中 |
云端高并发、低延迟 |
|
Weaviate |
支持(集合中管理对象与文本) |
支持 |
支持(与 BM25 等稀疏结合) |
支持(动态批处理) |
自托管/云 |
中 |
现有集群集成、混合检索 |
|
Qdrant |
支持(集合中管理 payloads) |
支持 |
支持(稠密+BM25) |
支持(集合级操作) |
自托管/云 |
中 |
混合检索、性能取向 |
|
Milvus |
依集成与模式(向量为主) |
支持(字段过滤) |
依索引与实现 |
支持(集合/分区级) |
自托管/云 |
中-高 |
亿级向量、毫秒级检索 |
|
Faiss |
否(仅存储向量) |
否 |
否 |
删除未实现 |
本地文件 |
低 |
本地高效相似度搜索 |
- 能力关注:持久化与一致性、元数据过滤、混合检索支持、删除/更新能力、部署复杂度与成本。
- 元数据设计建议:
source/section/page/lang/department/updated_at等,便于过滤与路由。 - 入库执行时机:离线全量与增量更新。
-
- 离线构建:上线前对已有知识库全量入库。
- 增量更新:新文档加入时触发针对新内容的入库流程,索引支持增量更新。
工作原理与索引类型
- 基本原理:向量数据库通过近似最近邻(ANN)算法在高维空间中检索“最相似”的向量,以平衡精准度与性能。
- 常见索引类型与特点:
-
- HNSW:基于分层小世界图,查询延迟低、召回好;适合在线检索与混合过滤。
- IVF(倒排文件):先聚类再在簇内检索,适合大规模数据;参数可控,吞吐高。
- PQ/OPQ(乘积量化):对向量压缩以节省存储与加速检索,存在精度损失;适合成本敏感场景。
- DiskANN/ScaNN:针对超大规模与磁盘优先场景优化,在云/大数据场景表现突出。
- 选择建议:
-
- 小规模与低延迟优先:HNSW。
- 亿级向量与高吞吐:IVF + PQ/OPQ。
- 云端与海量数据:DiskANN/ScaNN 或云托管(Pinecone/Weaviate)。
元数据建模与过滤
- 目的:让检索不仅“找得近”,还“找得对”。通过元数据过滤限定业务域、部门、时间段、语种等。
- 建模示例:
-
{"source": "policy.pdf", "section": "leave", "page": 12, "lang": "zh", "department": "HR", "updated_at": "2024-08-01"}
- 统一元数据键名与取值范围;时间使用 ISO 格式;必要时建立“路由层”先根据元数据选择库或命名空间。
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
from llama_index.core import VectorStoreIndex
# 建立测试集数据
nodes = [
TextNode(
text=(
"HR年假政策:员工入职未满一年按入职月数按比例计算年假。"
),
metadata={
"department": "HR",
"lang": "zh",
"source": "policy_hr_2024.md",
"section": "leave_policy",
"page": 1,
"updated_at": "2024-08-01",
},
),
TextNode(
text=(
"年假计算口径:以自然年为周期,离职结算时按实际在岗月份折算。"
),
metadata={
"department": "HR",
"lang": "zh",
"source": "policy_hr_2024.md",
"section": "leave_policy",
"page": 2,
"updated_at": "2024-08-01",
},
),
TextNode(
text=(
"请假流程:OA 系统提交→直属主管审批→HR 备案。"
),
metadata={
"department": "HR",
"lang": "zh",
"source": "process_hr_oa.md",
"section": "leave_process",
"page": 1,
"updated_at": "2024-07-15",
},
),
TextNode(
text=(
"IT 资产借用流程:工单申请→IT 审批→资产出库。"
),
metadata={
"department": "IT",
"lang": "zh",
"source": "process_it_asset.md",
"section": "asset_borrow",
"page": 1,
"updated_at": "2024-06-10",
},
),
]
# 构建索引
index = VectorStoreIndex(nodes)
# 定义过滤器
filters = MetadataFilters(filters=[
ExactMatchFilter(key="department", value="HR"),
ExactMatchFilter(key="lang", value="zh"),
])
# 应用过滤器
qe = index.as_query_engine(similarity_top_k=3, filters=filters)
print(qe.query("年假政策的计算口径?"))LlamaIndex向量数据库核心组件
核心组件StorageContext存储
核心作用:统一管理向量索引涉及的多种存储组件(向量、文档、索引元数据、图结构)。
from llama_index.core import StorageContext
# 创建StorageContext的典型方式
storage_context = StorageContext.from_defaults(
vector_store=vector_store, # 向量存储
docstore=docstore, # 文档存储
index_store=index_store, # 索引元数据存储
graph_store=graph_store # 图结构存储(用于知识图谱)
)主要功能:多存储组件协调
# 管理四种核心存储类型
storage_context = StorageContext.from_defaults(
vector_store=ChromaVectorStore(chroma_collection), # 向量嵌入存储
docstore=SimpleDocumentStore(), # 原始文档内容存储
index_store=SimpleIndexStore(), # 索引元数据存储
graph_store=SimpleGraphStore() # 节点关系存储
)数据持久化与恢复
if os.path.exists("./storage"):
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
else:
# 重新构建索引
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)VectorStoreIndex(向量存储索引)
核心作用:基于向量相似性搜索的索引实现,服务语义搜索与相似度查询。
from llama_index.core import VectorStoreIndex
# 创建向量索引
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=embed_model,
show_progress=True
)文档分割与节点创建
# 自动处理文档分割和节点创建
index = VectorStoreIndex.from_documents(
documents,
chunk_size=512, # 文本分块大小
chunk_overlap=50, # 块之间重叠
embed_model=embed_model # 嵌入模型
)相似性搜索接口
# 自动处理文档分割和节点创建
index = VectorStoreIndex.from_documents(
documents,
chunk_size=512, # 文本分块大小
chunk_overlap=50, # 块之间重叠
embed_model=embed_model # 嵌入模型
)内部工作机制(示意)
# VectorStoreIndex的核心处理流程
class VectorStoreIndex:
def from_documents(self, documents):
# 1. 文档分割成节点
nodes = self._split_documents(documents)
# 2. 为节点生成嵌入向量
embeddings = self._generate_embeddings(nodes)
# 3. 存储到向量数据库
self._store_embeddings(nodes, embeddings)
# 4. 构建索引结构
self._build_index_structure()
return self适用场景
# 文档问答系统
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("人工智能的发展历史?")大规模文档检索
# 处理大量文档
index = VectorStoreIndex.from_documents(
large_document_collection,
storage_context=storage_context, # 使用外部向量数据库
show_progress=True
)基于内容的推荐
retriever = index.as_retriever(similarity_top_k=10)
similar_items = retriever.retrieve("用户偏好内容")两者协同工作关系
|
组件 |
职责 |
数据流向 |
|
StorageContext |
存储管理、持久化、多存储协调 |
向下管理具体存储后端 |
|
VectorStoreIndex |
索引构建、查询处理、相似性计算 |
向上提供查询接口 |
# 1. 初始化存储组件
vector_store = ChromaVectorStore(chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 2. 创建向量索引(自动使用storage_context)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=OpenAIEmbedding()
)
# 3. 查询时自动利用存储上下文
query_engine = index.as_query_engine()
response = query_engine.query("查询问题")数据入库实现方式
- LlamaIndex 内置 + 内存向量(快速 PoC):实现最简单,适合验证。不可持久化、不易扩展到大数据量。
- 本地向量库(FAISS/Chroma/Milvus):低延迟、可离线、成本可控;FAISS 单机扩展有限,Milvus 需运维。
- 云向量服务(Pinecone/Weaviate/Qdrant/Milvus Cloud):高可用与扩展性强;成本与隐私需评估。
- 混合检索(倒排 + 向量):关键词初筛 + 向量精排,兼顾精准命中与语义召回。
from llama_index.readers.file.unstructured import UnstructuredReader
from unstructured.partition.auto import partition
from llama_index.core import Document
from pathlib import Path
def smart_load(file_path):
"""
智能文档加载器:根据文件类型选择最佳解析策略
Args:
file_path: 文件路径
Returns:
解析后的Document对象列表
"""
file_path = Path(file_path)
file_ext = file_path.suffix.lower()
# 定义复杂文件类型(需要高精度解析)
complex_types = {
'.pdf', # PDF文档(可能包含表格、图像、复杂布局)
'.png', '.jpg', '.jpeg', '.gif', '.bmp', '.tiff', # 图片文件(需要OCR)
'.docx', '.doc', # Word文档(可能包含复杂格式)
'.pptx', '.ppt', # PowerPoint(复杂布局)
'.xlsx', '.xls' # Excel(表格结构)
}
# 简单文件类型(可以用Reader直接处理)
simple_types = {
'.txt', '.md', '.csv', '.html', '.xml', '.json'
}
if file_ext in complex_types:
# 复杂文件使用底层解析,获得更好的结构识别
print(f"检测到复杂文件类型 {file_ext},使用partition高精度解析")
try:
elements = partition(
filename=str(file_path),
# 使用hi_res模式进行高精度解析
strategy="hi_res",
# 支持中文、英文
languages=["eng", "chi_sim"],
# 推断表格结构
infer_table_structure=True
)
# 将解析元素转换为Document对象
return [Document(text=e.text, metadata={
"source": str(file_path),
"element_type": type(e).__name__,
"file_type": file_ext
}) for e in elements if e.text.strip()] # 过滤空文本
except Exception as e:
print(f"高精度解析失败,回退到Reader: {e}")
# 回退到Reader
reader = UnstructuredReader()
return reader.load_data(file=file_path)
else:
# 简单文件或未知类型优先使用Reader
print(f"检测到简单文件类型 {file_ext},使用Reader解析")
try:
# 直接使用Reader进行简单解析
reader = UnstructuredReader()
# 加载解析后的文档,返回 Document 对象列表
docs = reader.load_data(file=file_path)
return docs
except Exception as e:
print(f"Reader解析失败,回退到partition: {e}")
# 回退到底层解析
elements = partition(filename=str(file_path), strategy="auto")
return [Document(text=e.text, metadata={"source": str(file_path)}) for e in elements]基于内存的向量数据库实现
from llama_index.core import VectorStoreIndex,StorageContext
# 1. 构建 VectorStoreIndex(内存)基于documents
index = VectorStoreIndex.from_documents(documents, text_splitter=splitter)
# 直接基于nodes构建索引
# index = VectorStoreIndex(nodes)
# 2. 索引持久化
index.storage_context.vector_store.persist("vector_store.json")
# 3. 加载缓存过的向量索引
# ctx = StorageContext.from_defaults(persist_dir="vector_store.json")
# index = VectorStoreIndex.from_documents(documents, storage_context=ctx)
# 4. 查询(QueryEngine 由 index.build_query_engine() 提供)
query_engine = index.as_query_engine()
resp = query_engine.query("请用中文总结这些文档的主要内容")
print(resp)LlamaIndex + Chroma(持久化、可扩展)
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
import os
# 1. 创建数据库目录并初始化Chroma客户端
db_path = "./chroma_db" # 指定数据库路径
os.makedirs(db_path, exist_ok=True) # 确保目录存在
try:
# 数据库层级持久化,构建索引后 - 数据会自动持久化
chroma_client = chromadb.PersistentClient(path=db_path) # 指定路径的持久化客户端
print(f"ChromaDB客户端初始化成功,数据库路径: {db_path}")
except Exception as e:
print(f"ChromaDB客户端初始化失败: {e}")
# 如果持久化客户端失败,尝试使用内存客户端
print("尝试使用内存客户端...")
chroma_client = chromadb.Client()
# 2. 创建或获取集合(处理集合已存在的情况)
collection_name = "my_collection"
try:
chroma_collection = chroma_client.get_or_create_collection(collection_name)
print(f"成功创建或获取到集合: {collection_name}")
except Exception as e:
print(f"获取集合失败: {e}")
# 尝试删除并重新创建
try:
chroma_client.delete_collection(collection_name)
chroma_collection = chroma_client.create_collection(collection_name)
print(f"删除旧集合并重新创建: {collection_name}")
except Exception as e2:
print(f"重新创建集合失败: {e2}")
raise e2
# 3. 创建ChromaVectorStore实例
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 4. 配置存储上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)
print("ChromaDB向量存储配置完成!")
# 5. 构建索引并查询,基于向量相似度进行召回
# index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 6. 持久化(Chroma 会在内部 persist)需要手动调用persist来保存数据
vector_store.persist(persist_path=db_path)
# 保存 index metadata(可选)
# index.storage_context.persist(persist_dir="./index_storage")
query_engine = index.as_query_engine()
response = query_engine.query("请用中文总结这些文档的主要内容")
print(f"模型回答:{response}")
Pinecone 云服务数据库
Pinecone Serverless 非常适合流量波动大的应用场景,例如:
- 初创公司和快速迭代的产品:在初期,你无需为不确定的流量进行大量基础设施投资。
- 开发与测试环境:在这些环境不需要持续高负载运行时,Serverless 模式可以节省大量成本。
- 具有明显波峰波谷的业务:比如电商促销、内容平台特定事件等,Serverless 能自动应对流量高峰。
- pinecone官网:https://www.pinecone.io/
import os
from dotenv import load_dotenv
from pinecone import Pinecone
# 加载环境变量.env文件中的配置
load_dotenv()
# 1) 初始化 Pinecone,需要申请官网的PINECONE_API_KEY
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
print("Pinecone 初始化成功!")
import time
# 设置索引名称和向量维度
index_name = "my-first-index"
# 维度必须与你后续使用的嵌入向量模型匹配
dimension = 1536
# 1. 创建索引
# 检查索引是否已存在,不存在则创建
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension, # 维度必须与你后续使用的嵌入向量模型匹配
metric="cosine", # 相似度计算方式,常用cosine, euclidean, dotproduct
spec={ # 选择免费套餐适用的serverless规格
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
}
)
print(f"索引 '{index_name}' 创建成功!")
# 等待索引准备就绪
time.sleep(10)
else:
# 如果索引已存在,先删除它
pc.delete_index(index_name)
# 然后创建新索引
pc.create_index(
name=index_name,
dimension=dimension, # 维度必须与你后续使用的嵌入向量模型匹配
metric="cosine", # 相似度计算方式,常用cosine, euclidean, dotproduct
spec={ # 选择免费套餐适用的serverless规格
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
}
)
print(f"索引 '{index_name}' 创建成功!")
# 等待索引准备就绪
time.sleep(10)
# 2. 连接到索引
index = pc.Index(index_name)
# 3. 准备并插入数据(向量)
# 这里插入3个简单的示例向量,每个向量是1536维
sample_vectors = [
("vec1", Settings.embed_model.get_query_embedding(documents[0].text), {"category": "Title", "text": documents[0].text}),
("vec2", Settings.embed_model.get_query_embedding(documents[1].text), {"category": "Text", "text": documents[1].text}),
("vec3", Settings.embed_model.get_query_embedding(documents[2].text), {"category": "Text", "text": documents[2].text})
]
# 4. 使用upsert方法插入数据
index.upsert(vectors=sample_vectors, namespace="example-namespace")
print("示例数据插入成功!")
# 短暂等待数据被处理
time.sleep(5)Pinecone的 upsert 操作是"insert or update"的组合:
- Insert : 如果向量ID不存在,则插入新向量
- Update : 如果向量ID已存在,则覆盖原有向量
多租户隔离
import os
from pinecone import Pinecone, ServerlessSpec
from llama_index.vector_stores.pinecone import PineconeVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
# 1) 初始化 Pinecone
pc = Pinecone(api_key=os.environ["PINECONE_API_KEY"])
# 2) 创建索引
index_name = "my-first-index"
pinecone_index = pc.Index(index_name)
# 3) 向量存储与索引
vector_store = PineconeVectorStore(
pinecone_index=pinecone_index,
namespace="default", # 多租户隔离
batch_size=100, # 批量 upsert
add_sparse_vector=False,
)
# 4) 加载存储上下文
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 5) 构建索引
# index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 6) 查询
query_engine = index.as_query_engine()
response = query_engine.query("请用中文总结这些文档的主要内容")
print(f"模型回答:{response}")Milvus 数据库本地部署存储
下载安装milvus的docker-compose文件
- curl -L -o docker-compose.yml https://github.com/milvus-io/milvus/releases/download/v2.3.21/milvus-standalone-docker-compose.yml
- 默认情况下,MilvusVectorStore 会在 Milvus 集合中同时保存节点的文本 (text)、嵌入向量和元数据 。这样,在检索时可以直接返回节点内容,并通过 LlamaIndex 提供的元数据过滤器对结果进行筛选。例如,在上述索引建立后,可定义如下过滤器来仅检索“year > 2000”的节点:
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
# 1. 加载文档并构建索引
vector_store = MilvusVectorStore(
dim=1536,
collection_name="milvus_collection",
uri="http://localhost:19530",
overwrite=True
)
# 2. 从向量数据库构建索引
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 3. 构建索引
# index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
index = VectorStoreIndex(nodes, storage_context=storage_context)
# 4. 查询
milvus_response = index.as_query_engine().query("请用中文总结这些文档的主要内容")
milvus_response.response使用MetadataFilter进行过滤查询
from llama_index.core.vector_stores import MetadataFilter, MetadataFilters, FilterOperator
# 定义 MetadataFilter 进行过滤查询
filters = MetadataFilters(filters=[
MetadataFilter(key="element_type", value="Text", operator=FilterOperator.EQ)
])
# 执行过滤查询
retriever = index.as_retriever(filters=filters, similarity_top_k=5)
# 输入检索文本
results = retriever.retrieve("龙头公司中报业绩")
# 打印查询结果
for node in results:
print(node.metadata)
print(node.text)
print("=" * 60)Faiss 本地高效检索,不存储文本
import faiss
from llama_index.vector_stores.faiss import FaissVectorStore
from llama_index.core import VectorStoreIndex, StorageContext
# 1) 创建 Faiss 索引(此处为 L2 距离的 Flat Index)
d = 1536
faiss_index = faiss.IndexFlatL2(d)
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 2) 构建索引(注意:Faiss 不存储文本,文本需由 Docstore 管理)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
# 3) 持久化向量索引到本地文件
vector_store.persist("./faiss_index.bin")
# 4) 查询
query_engine = index.as_query_engine()
response = query_engine.query("请用中文总结这些文档的主要内容")
print(response)MongoDB Docstore + IndexStore(多索引共享节点)
- MongoDocumentStore:把文档/节点(node text、metadata)存到 MongoDB;文档仓库(docstore)。
- MongoIndexStore:索引结构/索引元数据(index_struct、index metadata)存到 MongoDB。
- Chroma(本地 PersistentClient)作为 vector_store:实际向量(embeddings)与向量索引/检索由 Chroma 存储并负责。
- StorageContext.from_defaults(docstore=..., index_store=..., vector_store=...):把三者组合在一起,多个索引(SummaryIndex/VectorStoreIndex/TreeIndex)共享相同 storage_context。
结论:你已把文档/索引元数据放在 Mongo,本地 Chroma 负责向量。这是一种常见组合(Mongo 负责结构化数据 & metadata,专用向量 DB 负责 ANN 检索)。
import os
from llama_index.core import StorageContext, SummaryIndex, VectorStoreIndex,TreeIndex
from llama_index.storage.docstore.mongodb import MongoDocumentStore
from llama_index.storage.index_store.mongodb import MongoIndexStore
# 1) 连接 MongoDB(通过 MONGO_URI)
# MONGO_URI = os.environ.get("MONGO_URI", "mongodb://localhost:27017")
# 设置MongoDB连接参数
MONGO_HOST = os.environ.get("MONGO_HOST", "localhost")
MONGO_PORT = os.environ.get("MONGO_PORT", "27017")
MONGO_USERNAME = os.environ.get("MONGO_USERNAME", "root")
MONGO_PASSWORD = os.environ.get("MONGO_PASSWORD", "example123")
MONGO_DATABASE = os.environ.get("MONGO_DATABASE", "my_database")
# 构建带认证的连接字符串
MONGO_URI = f"mongodb://{MONGO_USERNAME}:{MONGO_PASSWORD}@{MONGO_HOST}:{MONGO_PORT}/{MONGO_DATABASE}?authSource=admin"
# 连接 MongoDB
docstore = MongoDocumentStore.from_uri(uri=MONGO_URI)
index_store = MongoIndexStore.from_uri(uri=MONGO_URI)
# 向量存储使用Chroma
chroma_client = chromadb.PersistentClient(path="./chroma_db")
vector_store = ChromaVectorStore(chroma_collection=chroma_client.get_or_create_collection("docs"))
storage_context = StorageContext.from_defaults(
docstore=docstore, # 文档存储
index_store=index_store, # 索引元数据存储
vector_store=vector_store # 向量存储
)
# 2) 构建多索引(共享同一组节点)
# summary_index = SummaryIndex(nodes, storage_context=storage_context)
# vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
# 摘要索引
summary_index = SummaryIndex.from_documents(documents, storage_context=storage_context)
# 向量索引
vector_index = VectorStoreIndex.from_documents(documents, storage_context=storage_context)
# 树索引
tree_index = TreeIndex.from_documents(documents, storage_context=storage_context)
# 3) 查询
summary_engine = summary_index.as_query_engine()
vector_engine = vector_index.as_query_engine()
tree_engine = tree_index.as_query_engine()
s = summary_engine.query("请用中文总结这些文档的主要内容")
v = vector_engine.query("请用中文总结这些文档的主要内容")
t = tree_engine.query("请用中文总结这些文档的主要内容")
print(s.response)
print("=" * 60)
print(v.response)
print("=" * 60)
print(t.response)两种持久化方法对比
chromadb.PersistentClient(path=...)(数据库层级持久化)
import chromadb
# 数据库层级的持久化
chroma_client = chromadb.PersistentClient(path="./chroma_db")vector_store.persist(persist_path=...)(框架层级持久化)
from llama_index.vector_stores.chroma import ChromaVectorStore
# 框架层级的持久化
chroma_client = chromadb.PersistentClient(path="./chroma_db")
vector_store = ChromaVectorStore(chroma_collection=chroma_client.get_or_create_collection("docs"))
# 或者显式调用
vector_store.persist(persist_path="./chroma_db")- 特点:手动批量持久化,I/O 次数可控;开发调试更灵活,程序异常退出可能丢数据。
- 建议:生产优先使用原生持久化;开发调试可用框架持久化并做好异常保护与备份。
向量检索工具封装
VectorDB 是 LlamaIndex 提供的一个 向量数据库工具封装类,它继承自 BaseToolSpec。
- 作用:将已构建的
VectorStoreIndex封装为可被智能体(Agent)调用的工具,支持多源知识库与路由检索。 - 对比:
VectorDB(面向 Agent,底层VectorStoreIndex)、QueryEngineTool(封装 QueryEngine)、ToolSpec(基础类)、RetrieverQueryEngine(执行检索)。 - 支持后端:Milvus、MongoDB Atlas Vector、Pinecone、Weaviate、Qdrant、FAISS、Chroma。
- 推荐搭配:
RetrieverQueryEngine+MetadataFilters+ Agent,按用户角色/部门/语种做路由与权限控制。
它不是直接用来检索的,而是把一个“向量检索能力”包装成一个可调用工具(ToolSpec);之后,你可以在 Agent、QueryEngineTool、或者多工具组合系统(Multi-Tool Agent)中直接使用; 它能让大语言模型通过自然语言调用底层向量检索逻辑(例如 Milvus、Pinecone、FAISS 等);同时保留了 LlamaIndex 原有的过滤、权重和组合能力。
|
使用场景 |
说明 |
|
Agent 工具集成 |
让一个 LLM(如 GPT)能通过自然语言调用“知识库检索”功能。 |
|
多模态或多知识源融合 |
当系统有多个 VectorIndex(例如“报告知识库”“产品知识库”),可以给每个建一个 VectorDB,并交给 Agent 动态选择调用。 |
|
自定义 Query Engine 集成 |
将 VectorDB 与 RetrieverQueryEngine 或 RouterQueryEngine 组合,实现多源路由检索。 |
|
企业内部知识问答系统 |
通常配合 Milvus / Pinecone / MongoDB Vector Store 使用,将不同业务库做成不同 Tool。 |
from llama_index.core import VectorStoreIndex
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import QueryEngineTool
from llama_index.core.workflow import Context
from llama_index.vector_stores.milvus import MilvusVectorStore
# 1. 加载已有 Milvus / Mongo 向量数据库
milvus_vector_store = MilvusVectorStore(
dim=1536,
collection_name="milvus_collection",
uri="http://localhost:19530",
overwrite=True
)
# 2. 从向量数据库构建索引
storage_context = StorageContext.from_defaults(vector_store=milvus_vector_store)
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
# 3. 构建查询引擎
query_engine = vector_index.as_query_engine(similarity_top_k=4)
# 4. 封装为向量数据库检索tool工具
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine, # 简化示例:将其封装为查询引擎工具
name="vector_auto_retrieve",
description="对向量数据库进行自动检索并应用元数据过滤"
)
# 5. 创建 Agent(ReActAgent 演示),异步执行,可以使用asyncio.run()来执行
agent = ReActAgent(tools=[vector_tool],llm=Settings.llm)
ctx = Context(agent)
# 6. 调用示例
handler = agent.run("请检索向量数据库中关于海外AI龙头企业有哪几家?", ctx=ctx)可自定义向量元数据
from llama_index.core import VectorStoreIndex
from llama_index.core.agent import ReActAgent
from llama_index.core.tools import QueryEngineTool
from llama_index.core.workflow import Context
from llama_index.vector_stores.milvus import MilvusVectorStore
# 1. 加载已有 Milvus / Mongo 向量数据库
milvus_vector_store = MilvusVectorStore(
dim=1536,
collection_name="milvus_collection",
uri="http://localhost:19530",
overwrite=True
)
# 2. 从向量数据库构建索引
storage_context = StorageContext.from_defaults(vector_store=milvus_vector_store)
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
# 3. 构建查询引擎
query_engine = vector_index.as_query_engine(similarity_top_k=4)
# 4. 封装为向量数据库检索tool工具
vector_tool = QueryEngineTool.from_defaults(
query_engine=query_engine, # 简化示例:将其封装为查询引擎工具
name="vector_auto_retrieve",
description="对向量数据库进行自动检索并应用元数据过滤"
)
# 5. 创建 Agent(ReActAgent 演示),异步执行,可以使用asyncio.run()来执行
agent = ReActAgent(tools=[vector_tool],llm=Settings.llm)
ctx = Context(agent)
# 6. 调用示例
handler = agent.run("请检索向量数据库中关于海外AI龙头企业有哪几家?", ctx=ctx)RetrieverTool检索器工具
from llama_index.core.tools import RetrieverTool
from llama_index.core.agent import ReActAgent
from llama_index.llms.openai import OpenAI
# 1. 构建检索器
retriever = vector_index.as_retriever(similarity_top_k=5)
# 2. 封装为检索工具
retr_tool = RetrieverTool.from_defaults(
retriever=retriever,
name="文档片段检索",
description="直接检索相关文档片段"
)
# 3. 创建 Agent
agent = ReActAgent(tools=[retr_tool], llm=Settings.llm, verbose=True)
# 4. 异步运行(ReActAgent 的 run 为 async)
response = agent.run("筛选包含 Title 的片段并返回内容")与其他工具类对比
|
工具类 |
作用 |
是否面向 Agent |
使用底层 |
|
VectorDB |
封装向量检索能力为工具 |
是 |
VectorStoreIndex |
|
QueryEngineTool |
封装 QueryEngine,为多源检索设计 |
是 |
QueryEngine |
|
ToolSpec |
所有工具的基础类 |
是 |
任意能力(可自定义) |
|
RetrieverQueryEngine |
执行检索查询 |
否 |
Retriever |
- 需要 Agent 得到原始片段供后续逻辑决策或把检索结果交给外部系统做加工:用 VectorDBToolSpec / VectorDB 工具(低层检索工具)。
- 希望 Agent 直接拿到用户提问的答案(检索 + LLM 汇总):用 QueryEngineTool。
- 你要实现自定义动作(调用外部 API、写 DB、触发任务):实现为 FunctionTool / 自定义 ToolSpec。
- 做评估、调参或想拿到 raw_scores / ids:直接用 RetrieverQueryEngine 或 index.as_retriever(...),不走 Agent 层。
向量数据库进阶思考
安全与多租户
在构建基于RAG(检索增强生成)等AI应用时,向量数据库的安全性与多租户能力是确保系统稳定、可靠、合规的基石。多租户架构的核心目标是让多个租户(可以是不同部门、不同业务线或不同客户)共享同一套系统,但保证每个租户的数据、配置和性能表现是相互隔离的。
- 命名空间/集合隔离:按业务域、环境(dev/prod)、租户维度划分;避免数据交叉与权限泄漏。
- 访问控制:云向量服务配置 API Key 与 RBAC;自托管结合网关与反向代理控制访问。
- 合规与加密:敏感数据尽量本地化;磁盘与传输加密;日志脱敏;审计与可追溯。
性能与成本优化
向量数据库的优化是一个系统工程,贯穿了从数据准备、入库到查询的全链路。核心思路在于:“前置减轻负担,中间加速处理,后续精准打击”。 前置:通过合适的模型和量化技术,从源头减少数据体积。 中间:利用批处理和缓存,提升系统整体的吞吐量和响应速度。 后续:在检索时,通过 top_k 与 Reranker 的配合,以最小成本获取最佳答案。
- 降维与模型选择:向量维度越高存储与计算越贵;在可接受精度下选中小模型(如 bge-small-zh 512)。
- 批量与缓存:批量嵌入、批量写入;热点问题与结果缓存;减少重复计算与 I/O。
top_k与重排:召回top_k不宜过大;结合Reranker提升前几条质量而不显著增加成本。- 删除与更新策略:不支持删除(如纯 Faiss)时采用“软删除 + 重建”或旁路过滤;增量更新做好去重与版本标记。
部署与运维
- 形态:单机(Chroma/Faiss)→ 自托管集群(Qdrant/Milvus/Weaviate)→ 云托管(Pinecone/Weaviate Cloud)。
-
- 选择自托管集群意味着你对数据和架构有完全的控制力,但需要面对显著的运维挑战。例如,Milvus在设计上就依赖Kubernetes以实现企业级扩展,这意味着你需要具备相应的k8s运维能力。
- 选择云托管服务则是一种“省心”的方案,供应商会负责所有底层基础设施、软件升级和可用性保障,让你可以专注于业务逻辑开发。
- 持久化与备份:原生持久化优先;定期快照与异地备份;版本化索引目录。
- 监控指标:写入/查询 QPS、p95/p99 延迟、召回质量变化、存储占用、压缩比、失败率;定期索引重建与数据压实(compaction)。
常见问题
- Embedding 维度变更的影响与迁移:存储大小、索引重建、模型切换的兼容性。
- 中文/英文混合场景:语种路由与多语言模型选择;切分策略是否保留中英文标点。
- Chroma collection 命名与目录组织:按业务域/部门/环境(dev/prod)分命名空间。
- Faiss 不支持删除的处理:重建索引或标记失效并旁路过滤。
- Milvus 索引参数选择(IVF/HNSW/DiskANN):结合数据量、延迟与召回需求评估。
- 云 API 速率限制:退避重试与并发控制;网络抖动等问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)