分层潜动作模型
26年3月来自韩国延世大学和NYU的论文“Hierarchical Latent Action Model”。
潜动作模型(LAM)能够从无动作数据中学习,其应用范围涵盖机器人控制到交互式世界模型。然而,现有的LAM通常侧重于短时程的帧转换,捕捉低级运动,而忽略长期的时间结构。相比之下,无动作视频往往包含时间跨度较长的高级技能。本文提出HiLAM,一种分层潜动作模型,它通过建模长期时间信息来发现潜技能。为了捕捉这些跨越长时程的依赖关系,用预训练的LAM作为底层提取器。该架构将包含视频底层动态模式的潜动作序列聚合为高级潜技能。实验表明,HiLAM优于基线模型,并展现出稳健的动态技能发现能力。
近年来,机器人学习的进展越来越依赖于大规模数据的训练。然而,获取标注动作的数据成本极其高昂,且难以保证数据集的多样性。为了解决这个问题,潜动作模型(LAM)(Schmidt & Jiang, 2024; Bruce et al., 2024; Ye et al., 2025; Kim et al., 2025)应运而生,成为一种重要的研究方法,它能够直接从观测数据中提取潜动作。通常,LAM利用逆动力学模型和正向动力学模型来推断两帧之间的潜动作。这些潜动作随后被用于使用无动作数据预训练视觉-语言-动作模型(VLA)(Ye et al., 2025; Bu et al., 2025),在不同具身模型间迁移动作(Kim et al., 2025),或在世界模型中实现交互(Bruce et al., 2024; Gao et al., 2025)。
潜动作学习
潜动作学习是一种从仅观测数据中推断动作的常用方法。潜动作模型(LAM)通过分析帧转换,利用逆动力学模型(IDM)提取帧间潜动作。LAPO(Schmidt & Jiang,2024)专注于从游戏环境中推断离散潜动作,而Genie(Bruce et al.,2024)则通过离散潜动作空间提出一种用于游戏的交互式世界模型。由于以往的研究大多局限于模拟环境,LAPA(Ye et al.,2025)将潜动作学习引入机器人领域,利用各种无动作数据,并将潜动作作为伪标签来训练虚拟潜动作(VLA)。
标准的LAM通常使用正向动力学模型(FDM)来预测未来图像,其中重建目标将动态信息编码到潜动作中。然而,这个过程可能会意外地将与任务无关的信息纳入潜表示中。为了解决这个问题,UniVLA(Bu,2025)提出了一种以任务为中心的学习方法,而UniSkill(Kim,2025)采用一种图像编辑流程,LAOM(Nikulin,2025)则利用监督学习来减少此类依赖性。此外,为了表示更多样化的动作空间,UniSkill(Kim,2025)和CLAM(Liang,2025)采用连续的潜动作而非离散的潜动作。潜动作还可以替代世界模型中的显式动作标签,这对于交互至关重要。最近的一些工作,例如AdaWorld(Gao,2025)和潜动作世界模型(Garrido,2026),专门利用潜动作学习进行世界模型训练。
HiLAM
潜动作为利用来自不同视频源的动态信息提供一种很有前景的方法。尽管现有的潜动作模型具有灵活性,但它们大多局限于短期运动。因此,它们可以从仅包含观察数据中捕捉低级动态,但往往会忽略更高层次的结构,例如时间上延伸的技能。这暴露出一个关键的差距:无动作视频不仅包含原始运动,还包含尚未充分利用的高级技能。
这就引出了一个自然的问题:如何从未标注的视频中提取这些技能?以往的研究通常要么假设技能向量是固定的(Zhu et al., 2022; Liang et al., 2024),要么将固定长度的底层动作序列编码成技能表征(Pertsch et al., 2021a)。然而,现实世界中的技能持续时间各不相同,大规模数据也引入了日益多样化的行为模式。即使是同一任务,演示的执行速度也可能存在显著差异,进而导致技能持续时间的差异。当技能被强制限制在一个固定长度的窗口内时,表达相同底层行为的两条轨迹可能会被映射到截然不同的技能表征。另一种研究方法利用语言来定义技能(Shi et al., 2025)。然而,这种方法通常是将行为从任务描述中分割出来,例如将指令拆分成子指令,而不是从运动线索中分割出来。因此,语言是技能发现的补充信号,而不是动态建模的替代品。
为此,提出HiLAM,一种分层潜动作模型,它能够从潜动作序列中编码潜技能,而无需考虑动作序列的长度或是否需要预定义的技能集。如图展示HiLAM的整体架构。为了实现动态分层设计,采用H-Net(Hwang,2025)架构,该架构引入一种动态分块机制,可以自动分割边界。遵循H-Net框架,在预训练期间使用下一个token预测方法来构建HiLAM,并利用从逆动力学模型(IDM)中提取的潜动作。此外,与先前的工作(Ye,2025;Kim,2025)一致,预测的潜动作用于重建未来的帧,以保持其动态运动特性。由于H-Net的动态分块机制,潜动作自然地被分组为长度不同的相似表示,而无需动作标签。这些表征随后通过编码器进行处理,作为潜技能。获得这些技能后,训练一个技能策略,根据当前观测结果预测潜技能。同时,训练一个技能条件策略,根据观测结果和预测的潜技能预测底层动作。
HiLAM 是一种分层潜动作模型。该框架包含两个阶段。
在第一阶段,HiLAM 利用动态分块机制进行训练,以预测下一个潜动作。由于其架构特性,HiLAM 能够自动检测未经裁剪的输入潜动作序列中的技能边界。
在第二阶段,利用这些潜动作和编码后的潜技能来训练高层策略和低层策略。
由于每个潜技能在分块片段内都包含共享信息,因此高层策略用于预测潜技能,而低层策略用于预测潜动作。最后,用真实动作对低层策略进行微调,从而将潜动作空间映射到真实动作空间。
该方法将长时域轨迹分解为一系列潜表征,并将视觉观测映射到可执行动作。借鉴先前的工作(Ye et al., 2025; Kim et al., 2025),用逆动力学模型来推断由固定时间间隔 k 分隔的两帧 I_t 和 I_t+k 之间的运动。为了捕捉时间抽象,将这一系列低级潜动作进一步压缩为一系列高级潜技能。
对于下游控制,采用一种分层策略框架。在每个决策步骤中,高级策略观察当前状态和任务指令来预测目标潜技能。随后,基于该高级技能和当前观测值,低级策略生成机器人执行所需的基本动作。
为了将长序列的潜动作抽象为时间上延伸的技能,HiLAM 采用H-Net(Hwang,2025)架构,该架构通过动态分块学习输入的数据驱动分割。根据边界模式,通过仅选择边界特征来执行分块(下采样)。
用分层序列模型从仅包含观察数据的视频中学习潜技能表示的层次结构。在序列建模中,输入通常包含语言token、DNA 基或动作轨迹。然而,由于仅包含观察数据中没有真实动作,用预训练的逆动力学模型(IDM)(Ye,2025;Kim,2025)来提取潜动作。然后,应用动态分块机制(Hwang,2025)将潜动作序列分割成有意义的时间块,并将每个时间块编码为一个潜技能。
最后,经过编码器-主-解码器堆栈的分层处理后,HiLAM 在最底层预测下一个潜动作。
训练中优化以下三者的加权组合:(i) 下一个潜动作预测,(ii) 一个可以以不同方式实例化的视觉监督项,以及 (iii) H-Net 分块正则化项:
L = L_latent + λ_rec L_rec + λ_ratio L_ratio.
在此公式中,L_latent 是预测潜动作与目标潜动作之间的逐元 l1 损失(Bardes,2024;Assran,2025),用于建模下一个token的预测任务。项 L_rec 提供额外的监督,以确保预测的潜动作保持其动作属性。
训练 HiLAM 后,提取阶段性潜技能,并将其与原始视频长度 T 对齐,以便进行下游分层策略学习。如图所示,所得序列作为每个时间步的潜技能序列,用于下游策略学习。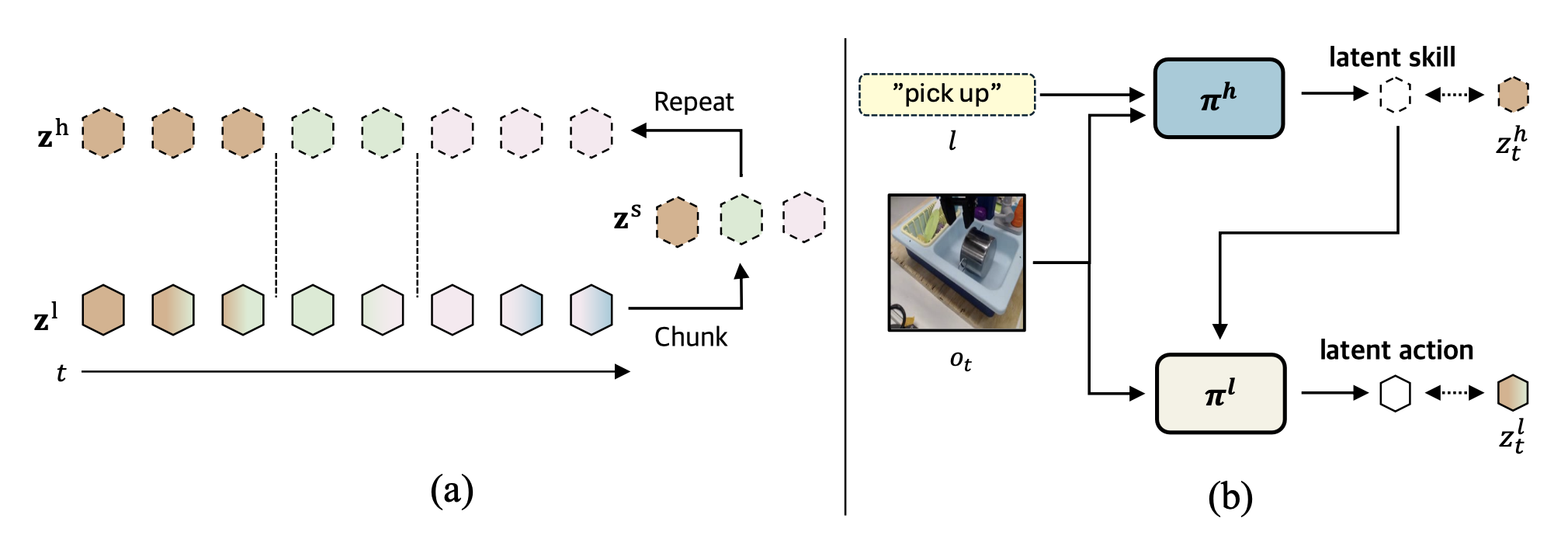
为了利用学习的潜技能进行控制,训练一个分层策略,该策略由高层策略和低层策略组成(图b所示)。考虑两个训练阶段:在大规模无动作视频上进行预训练,以及在带有动作标签的目标域上进行微调。在预训练阶段,用 HiLAM 提取的潜技能/动作序列来监督两种策略。预训练结束后,冻结高层策略,并使用目标域数据和真实动作对底层策略进行微调。
数据集:用仅包含观测数据的视频数据集训练 HiLAM,这些数据集涵盖人类和机器人的行为。对于人类视频,用 Something-Something V2 (Goyal et al., 2017),其中包含人类执行各种以物体为中心的动作的短片。对于真实世界的机器人视频,用 Droid (Khazatsky et al., 2024) 和 BridgeV2 (Ebert et al., 2022),它们分别是使用 Franka 和 WidowX-250 机械臂收集的大规模数据集。
实现细节:HiLAM 遵循 H-Net (Hwang et al., 2025) 的思路,使用两阶段 H-Net。为了从无动作视频中提取潜动作,用 UniSkill (Kim et al., 2025) 的逆动力学模型 (IDM) 作为潜动作token化器,并使用其正向动力学模型 (FDM) 基于预测的潜动作进行帧预测。对于高级潜技能,用 stage-s = 2 表示。对于分层策略学习,高层策略和低层策略均基于 BAKU 架构(Haldar,2024),并使用 T5 编码器(Raffel,2020)作为语言编码器。预训练时,用人类视频(Something-Something V2)或机器人视频(BridgeV2)。在这两种情况下,都将数据视为仅包含观察值:丢弃所有可用的动作标注,仅从每个视频中提取潜动作/技能,并将其用作伪标签来训练高层策略和低层策略。微调时,冻结高层策略,仅使用专家演示训练低层策略。除非另有说明,预训练和微调均运行 10 万个梯度步。
基准测试:用 LIBERO 基准测试集(Liu,2023)评估下游控制策略。报告四个测试套件的结果:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long。LIBERO-Spatial 侧重于空间推理,而 LIBERO-Object 通过改变操作对象来测试泛化能力。LIBERO-Goal 使用一致的对象和背景,要求策略必须遵循语言指令才能成功。LIBERO-Long 是最具挑战性的测试套件,包含多个子目标的长时域任务。每个套件包含 10 个任务,每个任务提供 50 条演示轨迹。基于提供的专家演示进行微调,并使用官方评估版本报告成功率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)