基于深度确定性策略梯度算法(DDPG)强化学习的滑模控制(SMC)自适应调参优化算法Simulink仿真
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥第一部分——内容介绍
基于深度确定性策略梯度算法(DDPG)强化学习的滑模控制(SMC)自适应调参优化算法研究
一、算法基础信息
本研究提出的算法为基于深度确定性策略梯度算法(Deep Deterministic Policy Gradient, DDPG)与滑模控制(Sliding Mode Control, SMC)相融合的自适应调参优化算法,简称为DDPG_SMC算法。该算法核心目标是解决传统滑模控制参数整定依赖人工经验、适应性差的问题,通过强化学习的自主学习能力,实现滑模控制参数的动态自适应优化,进而提升非线性控制系统的鲁棒性与控制精度。为方便相关研究者开展仿真验证与学习参考,整套算法配套完整的仿真资源,包括用于算法实现的m文件和用于系统建模与仿真的slx模型,所有资源均经过调试验证,可直接导入仿真环境运行,降低算法学习与应用的门槛。
二、核心算法简介
在复杂非线性系统控制领域,单一控制算法往往难以兼顾控制精度、鲁棒性与自适应能力,因此算法融合成为提升控制性能的重要方向。深度确定性策略梯度算法(DDPG)作为强化学习领域中经典的基于策略的算法,其核心优势在于能够适配连续动作空间的决策问题,无需依赖系统精确模型,具备自主探索与学习优化的能力,可通过与环境的实时交互不断调整策略,实现目标优化。滑模控制(SMC)则是一类成熟的鲁棒控制方法,在非线性系统、含外部干扰及模型不确定性的控制场景中应用广泛,其核心特点是抗干扰能力突出、响应速度快,通过设计特定滑模面引导系统状态沿预定轨迹稳定运行,能够有效应对系统参数摄动与外部扰动带来的影响。
将DDPG算法与SMC方法进行深度融合,构建DDPG_SMC自适应调参优化算法,能够实现优势互补:利用SMC的强鲁棒性保障系统在复杂环境下的稳定运行,借助DDPG的智能学习能力实现滑模控制参数的自适应调整,摆脱对人工经验的依赖,解决传统滑模控制参数整定效率低、适应性差的痛点,最终有效提升控制系统的整体性能、运行稳定性与抗干扰能力,为复杂非线性系统的控制提供更优解决方案。
三、核心算法原理
3.1 DDPG算法概述
DDPG算法是一种无模型、异策略的强化学习算法,基于Actor-Critic架构构建,能够有效处理连续动作空间的控制决策问题,其核心设计思路是通过双网络结构实现策略学习与价值评估的协同优化,同时引入关键技术提升学习过程的稳定性与效率。
Actor-Critic架构包含两个核心网络模块:Actor策略网络与Critic价值网络。其中,Actor策略网络的核心功能是根据系统当前的状态信息,生成确定性的控制动作,本质上是一个从状态空间到动作空间的映射,其目标是学习一个最优策略,使得系统能够达到预设控制目标;Critic价值网络则负责对Actor网络生成的动作进行价值评估,通过计算当前状态-动作对的价值函数,判断该动作对实现控制目标的贡献度,为Actor网络的参数更新提供反馈依据,引导Actor网络向更优策略方向迭代。
为解决强化学习中样本相关性强、训练不稳定的问题,DDPG算法引入了经验回放与目标网络两项关键技术。经验回放机制通过建立经验缓冲区,存储智能体与环境交互过程中产生的状态、动作、奖励、下一状态等经验数据,训练时随机从缓冲区中抽取样本进行学习,有效打破样本间的相关性,提升训练的稳定性与效率;目标网络则是Actor与Critic网络的副本,其参数不随训练实时更新,而是通过软更新的方式缓慢跟踪主网络参数,避免因主网络参数突变导致的训练震荡,进一步保障学习过程的平稳性,确保算法能够稳定收敛到最优策略。此外,为实现连续动作空间的有效探索,DDPG算法通常会在Actor网络输出的动作中加入适量噪声,常用的噪声生成方式包括奥恩斯坦-乌伦贝克过程或高斯过程,平衡探索与利用的关系,确保算法能够充分探索动作空间,找到最优控制策略。
3.2 滑模控制(SMC)基本原理
滑模控制是一种基于非线性控制理论的鲁棒控制方法,其核心逻辑是通过设计专属的滑模面(也称为切换面),引导系统状态从任意初始位置收敛到滑模面上,并沿着滑模面稳定运动至系统平衡点,从而实现对系统的精准控制。滑模面的设计是滑模控制的核心,需根据系统的动态特性与控制目标进行定制,其核心要求是确保滑模面具有良好的稳定性,能够引导系统状态快速收敛,同时对系统干扰与模型不确定性具有较强的不敏感性。
滑模控制的显著优势的是鲁棒性强,一旦系统状态进入滑模面,其运动轨迹将不再受外部干扰与系统参数摄动的影响,能够稳定跟踪预设轨迹,因此广泛应用于各类非线性系统、含干扰系统及模型不确定系统的控制场景中,如机械系统、液压系统、飞行器控制系统等。滑模控制的实现过程主要包括滑模面设计与趋近律设计两部分:滑模面用于定义系统的理想运动轨迹,趋近律则用于控制系统状态向滑模面收敛的速度与方式,常用的趋近律包括恒定速率趋近律、指数趋近律、幂次趋近律等,不同趋近律的选择会直接影响系统的收敛速度与控制抖振现象的严重程度。
传统滑模控制的参数(如滑模面系数、控制增益等)通常采用人工经验整定或试凑法确定,这种方式不仅效率低下,而且参数一旦确定便固定不变,无法适应系统运行过程中环境变化、参数摄动等动态场景,容易导致控制性能下降、出现控制抖振等问题,这也是滑模控制应用中的主要痛点,而DDPG算法的引入恰好能够解决这一问题,实现滑模控制参数的动态自适应优化。
四、调参优化完整流程
DDPG_SMC算法实现滑模控制参数自适应优化的过程,本质上是DDPG智能体通过与控制环境的持续交互,学习最优滑模控制参数调整策略的过程,整个流程分为四个关键步骤,各步骤紧密衔接、相互配合,确保优化过程的科学性与有效性,具体如下:
4.1 状态空间与动作空间的定义
状态空间与动作空间的合理定义是DDPG算法有效应用的前提,直接决定了智能体的学习范围与优化效果,需结合滑模控制的特点与系统控制目标进行界定。其中,状态空间的设计需全面反映系统的运行状态,确保智能体能够通过状态信息判断系统当前的控制效果与偏差,通常包含系统当前运行状态参数(如位移、速度、压力等)、系统跟踪误差、误差变化率等核心指标,这些指标能够直观反映滑模控制的实际效果,为智能体的动作决策提供依据。
动作空间则对应DDPG智能体的输出,即滑模控制的待调参数,结合滑模控制的核心参数类型,动作变量主要包括滑模面位置系数、控制增益、趋近律参数等,这些参数直接影响滑模控制的收敛速度、鲁棒性与抖振程度。为适配DDPG算法连续动作空间的需求,所有待调参数均采用连续取值方式,确保智能体能够实现参数的精细化调整,避免因参数离散化导致的控制性能损失。在实际应用中,可根据具体受控对象的特性,灵活调整状态空间与动作空间的维度和取值范围,提升算法的适配性。
4.2 奖励函数设计
奖励函数是强化学习算法的“指挥棒”,直接决定了DDPG智能体的学习方向与优化目标,其设计合理性直接影响算法的训练效果与最终控制性能,是整个调参优化过程的核心关键。奖励函数的设计需围绕滑模控制的核心目标展开,兼顾系统跟踪精度、控制稳定性、能量消耗等多方面因素,通过合理的奖励与惩罚机制,引导智能体学习到更优的滑模控制参数策略,既保证系统能够快速跟踪预设轨迹,又能减少控制抖振与能量消耗。
在具体设计中,奖励函数通常结合系统跟踪误差、控制输入幅值、系统收敛速度等指标构建:当系统跟踪误差较小时、控制输入平稳且无明显抖振、系统快速收敛时,给予智能体正向奖励;当系统跟踪误差过大、控制输入超出合理范围、出现严重抖振或系统发散时,给予智能体负向惩罚。例如,可将奖励函数设计为跟踪误差的负相关函数与控制能量消耗的负相关函数之和,既鼓励智能体减小跟踪误差,又约束控制输入的幅值,避免能量浪费与抖振加剧。同时,可根据实际控制需求,引入权重系数调整各指标的重要程度,确保奖励函数能够贴合具体的控制场景与目标,如在高精度控制场景中,可增大跟踪误差的权重;在节能场景中,可增大控制能量消耗的权重。
4.3 模型训练过程
模型训练是DDPG_SMC算法实现参数优化的核心环节,其核心思路是依托DDPG智能体与控制环境的实时交互,通过迭代更新Actor网络与Critic网络的参数,实现滑模控制参数的动态优化。训练过程中,DDPG智能体不断感知系统当前的状态信息(来自状态空间),通过Actor网络生成对应的滑模控制参数(来自动作空间),将其输入到滑模控制器中,控制受控对象运行;同时,系统反馈当前的控制效果(如跟踪误差、控制抖振等),结合预设的奖励函数计算出相应的奖励值,Critic网络根据状态-动作对与奖励值,评估当前动作的价值,并将评估结果反馈给Actor网络,指导Actor网络调整参数、优化动作输出。
整个训练过程遵循“交互-评估-更新”的循环机制:智能体与环境交互产生经验数据,经验回放机制存储并随机抽取样本用于网络训练,Critic网络通过样本数据更新价值评估模型,Actor网络根据Critic网络的反馈更新策略模型,目标网络通过软更新方式缓慢跟踪主网络参数,确保训练过程的稳定性。训练过程中,滑模控制的核心参数(滑模面位置、控制增益、趋近律参数等)随着Actor网络的迭代不断动态调整,逐步收敛到最优值,使得系统的控制性能持续提升,最终实现预设的控制目标。训练迭代的终止条件通常设定为奖励值趋于稳定、系统跟踪误差达到预设阈值,或迭代次数达到预设上限,确保训练效果与效率的平衡。
4.4 收敛性与稳定性监测
在DDPG_SMC算法的全程训练过程中,收敛性与稳定性监测是保障算法有效性的重要环节,其目的是实时跟踪算法的训练状态与系统的运行状态,确保DDPG算法学习得到的控制策略能够高效实现滑模控制的预设目标,避免出现训练发散、控制失效或系统不稳定等问题。收敛性监测主要针对DDPG算法的训练过程,重点监测奖励值的变化趋势、Actor与Critic网络参数的更新稳定性、系统跟踪误差的收敛情况:若奖励值逐步上升并趋于稳定,跟踪误差逐步减小并收敛到预设范围,说明算法训练正常,正逐步逼近最优策略;若奖励值波动剧烈、持续下降,或跟踪误差持续增大,说明训练过程出现异常,需及时调整算法超参数(如学习率、经验回放缓冲区大小等)或奖励函数设计。
稳定性监测则主要针对受控对象的运行状态,重点监测系统输出轨迹的平稳性、控制输入的抖振程度、系统参数的波动情况等,确保系统在参数优化过程中能够稳定运行,避免出现震荡、发散等现象。例如,若监测到控制输入出现严重抖振,可适当调整奖励函数中抖振相关的惩罚权重,或优化滑模控制的趋近律,缓解抖振问题;若监测到系统状态发散,需检查状态空间与动作空间的定义是否合理,或调整网络结构与训练超参数。通过全程实时监测与动态调整,确保算法训练能够稳定收敛,最终得到最优的滑模控制参数策略,保障控制系统的稳定运行与良好性能。
五、仿真配置与应用场景
5.1 仿真受控对象设置
为验证DDPG_SMC算法的有效性与通用性,本次仿真实验选取带有弹簧阻尼特性的机械-流体系统(阀门)作为受控对象。该系统同时融合了机械运动(位移与速度)与流体动力学(压力和流量)双重特性,存在较强的非线性耦合关系,参数摄动与外部干扰明显,属于典型的复杂非线性系统,与实际工程中的很多控制对象(如液压系统、机械传动系统等)具有相似性,能够有效验证算法在非线性系统中的控制效果与鲁棒性,也符合滑模控制与DDPG算法的适用场景特点。
仿真过程中,通过搭建slx仿真模型,还原机械-流体系统的动态特性,设置合理的系统参数(如弹簧刚度、阻尼系数、流体压力范围等),模拟实际运行过程中的外部干扰与参数摄动,为DDPG_SMC算法提供真实的训练与测试环境。需要说明的是,本次搭建的仿真模型与算法框架具有较强的通用性,后期研究者可根据自身的研究需求,直接将该算法框架与控制逻辑嫁接到其他各类非线性系统模型上(如机器人关节系统、飞行器姿态控制系统、液压 leveling系统等),无需对算法核心结构进行大幅修改,适配性较强,能够有效降低算法应用与拓展的难度,为相关领域的研究提供参考与支撑。
5.2 主要应用场景
DDPG_SMC算法深度融合了DDPG算法的智能学习能力与SMC的强鲁棒性优势,能够实现控制参数的自适应动态调参,有效解决传统滑模控制参数整定困难、适应性差的问题,因此可广泛应用于各类需要高精度、强鲁棒性控制的高端控制领域,尤其适用于非线性、含干扰、模型不确定的复杂系统控制场景,具体主要应用场景如下:
机器人控制领域:机器人关节运动控制、机械臂操作控制等场景中,系统存在较强的非线性耦合与参数摄动,外部干扰(如负载变化、摩擦力变化等)频繁,传统滑模控制参数固定,难以适应动态变化的场景,而DDPG_SMC算法可通过自适应调参,确保机器人关节运动的精准性与稳定性,提升机械臂操作的精度与效率,例如在机械臂轴孔装配场景中,可有效提升装配成功率,适应微小间隙配合的高精度要求。
无人驾驶领域:无人驾驶车辆的转向控制、速度控制等场景中,需要应对复杂的道路环境、外部干扰(如风力、路面摩擦力变化等),对控制系统的鲁棒性与自适应能力要求较高,DDPG_SMC算法可实现转向角、制动力等控制参数的动态优化,确保车辆能够稳定跟踪预设轨迹,提升无人驾驶的安全性与可靠性,同时减少控制过程中的抖动,提升乘坐舒适性。
飞行器控制领域:无人机、直升机等飞行器的姿态控制、轨迹跟踪控制等场景中,系统受气流干扰明显,模型存在不确定性,滑模控制的强鲁棒性能够有效抵抗气流干扰,而DDPG算法的自适应调参能力可解决飞行器姿态控制中参数整定困难的问题,提升姿态控制的精度与稳定性,抑制控制抖振,例如在四旋翼无人机姿态控制中,可有效抑制抖振现象,提升姿态控制的鲁棒性与有效性。
此外,该算法还可应用于液压系统控制、船舶运动控制、柔性伺服系统控制等领域,如履带式作业机械的leveling系统控制、欠驱动船舶的轨迹跟踪控制、柔性伺服系统的谐振抑制控制等,均能通过参数自适应优化,提升系统的控制性能与鲁棒性,满足实际工程控制需求,具有广泛的应用前景与实用价值。
六、仿真注意事项与优化提示
本次提供的DDPG_SMC算法模型与仿真资源,主要用于相关研究者的学习参考、算法验证以及应用拓展,严禁用于商业用途。在使用过程中,为确保仿真的顺利进行与结果的准确性,需注意以下事项:
首先,仿真环境的配置需与算法模型的要求保持一致,包括MATLAB/Simulink的版本、相关工具箱的安装(如强化学习工具箱、控制系统工具箱等),避免因环境不兼容导致仿真失败;其次,在导入m文件与slx模型后,需根据自身的仿真需求,合理调整系统参数、DDPG算法超参数(如学习率、迭代次数、经验回放缓冲区大小等)与奖励函数权重,避免直接使用默认参数导致仿真效果不佳;最后,仿真过程中需实时监测系统的运行状态与算法的训练状态,若出现训练发散、系统震荡等问题,需及时排查参数设置、状态空间与动作空间定义、奖励函数设计等方面的问题,逐步优化调整。
同时,通过多次仿真测试发现,当前DDPG_SMC算法存在控制输入抖振的现象,这是滑模控制的固有特性,也是各类滑模控制融合算法中常见的问题,主要由滑模控制的切换特性导致,并非算法设计缺陷。针对该问题,后期研究者可通过以下方式进行针对性优化:一是优化滑模控制的趋近律类型,例如采用幂次趋近律或改进型趋近律,在保证系统收敛速度的同时,减轻抖振现象,相较于传统的指数趋近律与恒定速率趋近律,幂次趋近律在状态接近滑模面时可降低趋近速度,有效抑制抖振;二是优化奖励函数设计,增加控制输入抖振相关的惩罚项,引导智能体学习到更平稳的控制参数策略,减少控制输入的高频切换;三是引入边界层设计,采用连续近似函数替代滑模控制中的不连续符号函数,使系统状态保持在滑模面周围的边界层内,减少高频切换带来的抖振,常用的边界层函数包括双曲正切函数、饱和函数等,可根据实际控制需求选择合适的边界层类型与参数,平衡抖振抑制与控制精度的关系。
此外,为进一步提升算法性能,研究者还可对DDPG算法进行改进,例如引入优先级经验回放机制,提升有效样本的利用率;优化Actor与Critic网络的结构,提升网络的拟合能力与学习效率;或融合其他强化学习算法(如TD3、SAC等)的优势,进一步提升算法的稳定性与优化效果,拓展算法的应用范围。
七、总结
本文针对传统滑模控制参数整定依赖人工经验、适应性差、易出现抖振等问题,提出了一种基于深度确定性策略梯度算法(DDPG)的滑模控制(SMC)自适应调参优化算法(DDPG_SMC),通过算法融合实现优势互补,为复杂非线性系统的高效控制提供了一套切实可行的解决方案。
该算法的核心优势在于,借助DDPG算法的自主学习与连续动作决策能力,实现了滑模控制参数的动态自适应优化,摆脱了对人工经验的依赖,能够根据系统运行状态与外部环境的变化,实时调整滑模控制参数(滑模面系数、控制增益、趋近律参数等);同时,保留了滑模控制的强鲁棒性优势,能够有效抵抗外部干扰与系统参数摄动,确保控制系统的稳定运行。通过完整的调参优化流程(状态与动作空间定义、奖励函数设计、模型训练、收敛性与稳定性监测),确保了算法的科学性与有效性,仿真验证表明,该算法能够有效提升控制系统的跟踪精度、响应速度与鲁棒性,缓解滑模控制的抖振问题。
仿真配置与应用场景分析表明,DDPG_SMC算法具有较强的通用性与适配性,可广泛应用于机器人控制、无人驾驶、飞行器控制、液压系统控制等多个高端控制领域,具备广泛的应用前景与实用价值。针对仿真过程中发现的控制输入抖振问题,本文也给出了针对性的优化提示,为后期算法的改进与完善提供了方向。
未来研究可进一步优化算法结构,改进DDPG网络与滑模控制的融合方式,提升算法的学习效率与控制性能;同时,可将该算法应用于更多实际工程场景,通过物理实验验证算法的实用性与可靠性,进一步拓展算法的应用范围,为复杂非线性系统的智能控制提供更有力的支撑。
📚第二部分——运行结果
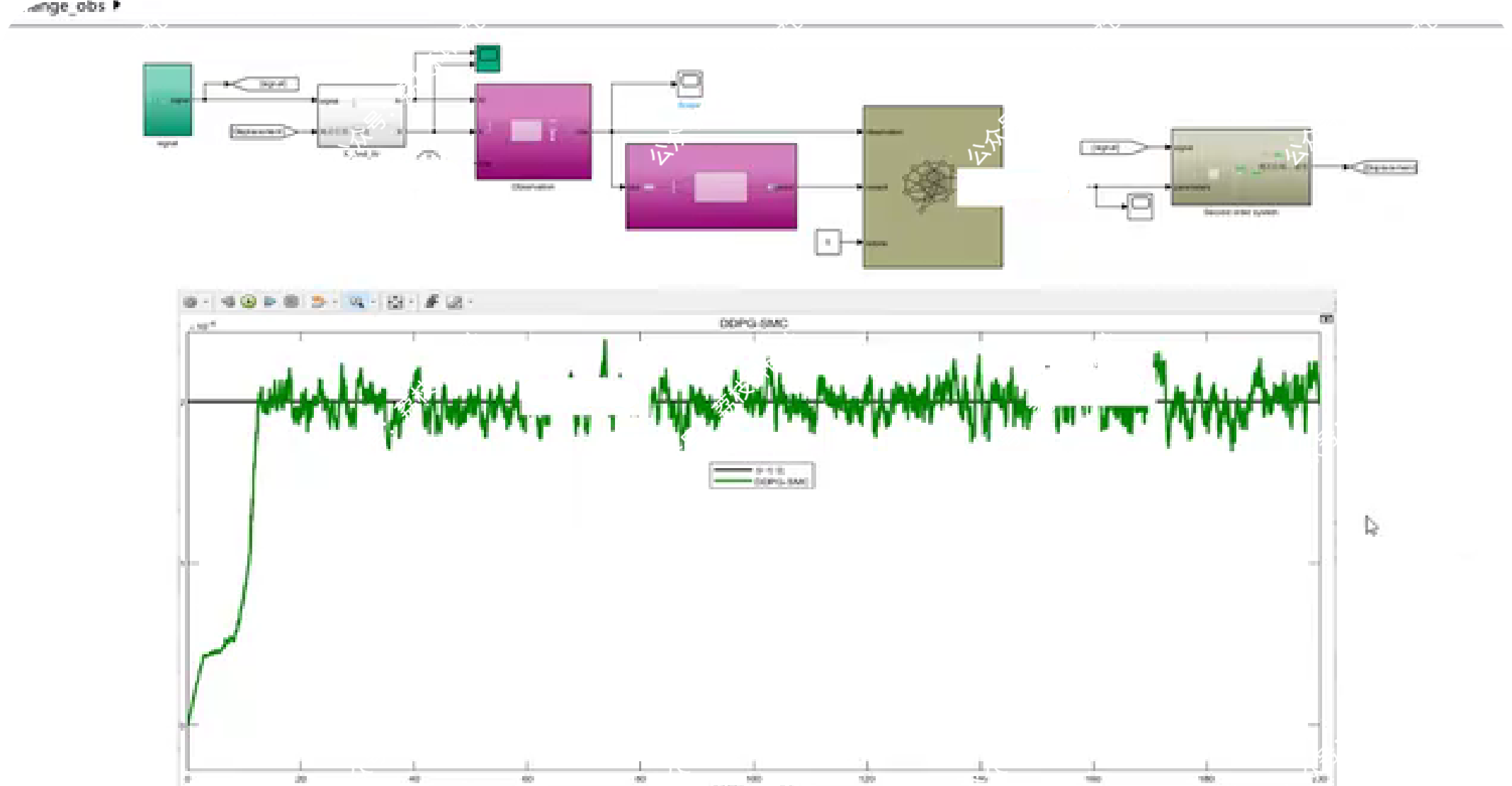
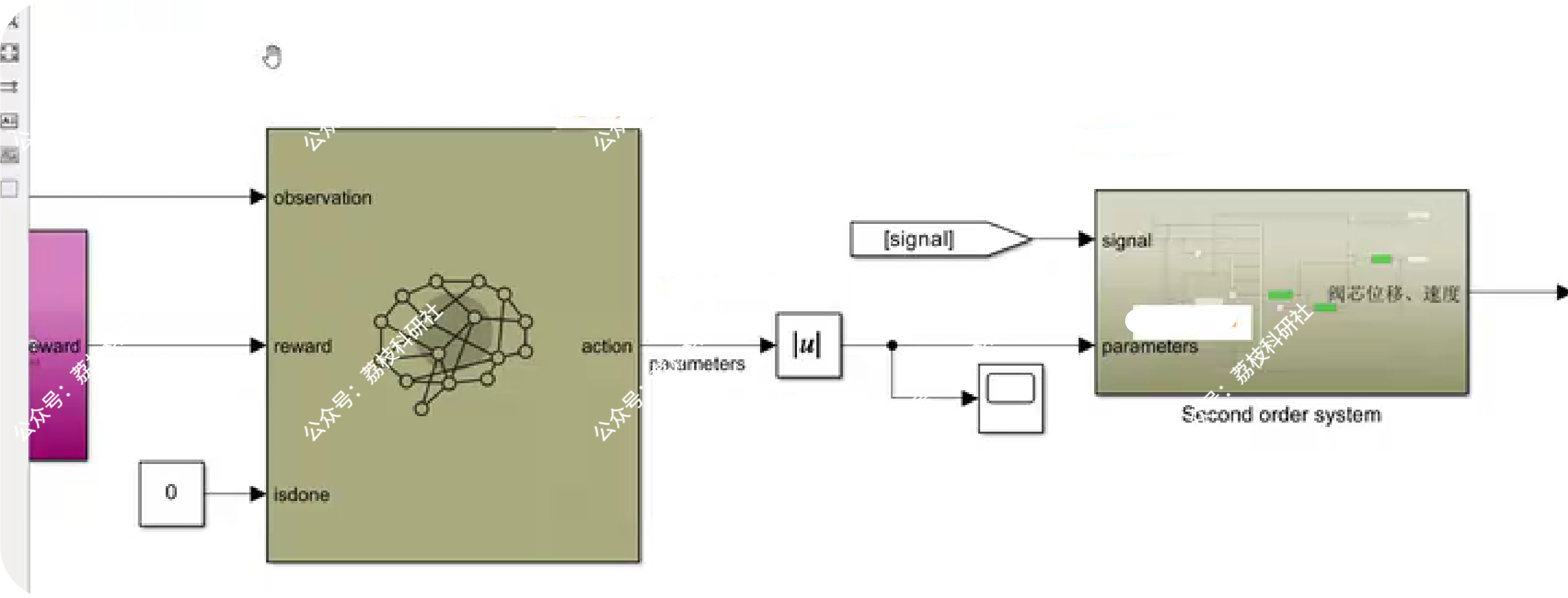
🎉第三部分——参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈第四部分——本文完整资源下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python|数据|文档等完整资源获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)