【OpenClaw】云服务器端 openclaw 集成本地 Windows端 ollama 模型
【OpenClaw】云服务器端 openclaw 集成本地 Windows端 ollama 模型
一、本地 ollama 配置
首先配置两个环境变量, 打开 powershell ,执行以下指令:
# 设置监听所有 IP
[Environment]::SetEnvironmentVariable("OLLAMA_HOST", "0.0.0.0:11434", "User")
# 允许跨域
[Environment]::SetEnvironmentVariable("OLLAMA_ORIGINS", "*", "User")
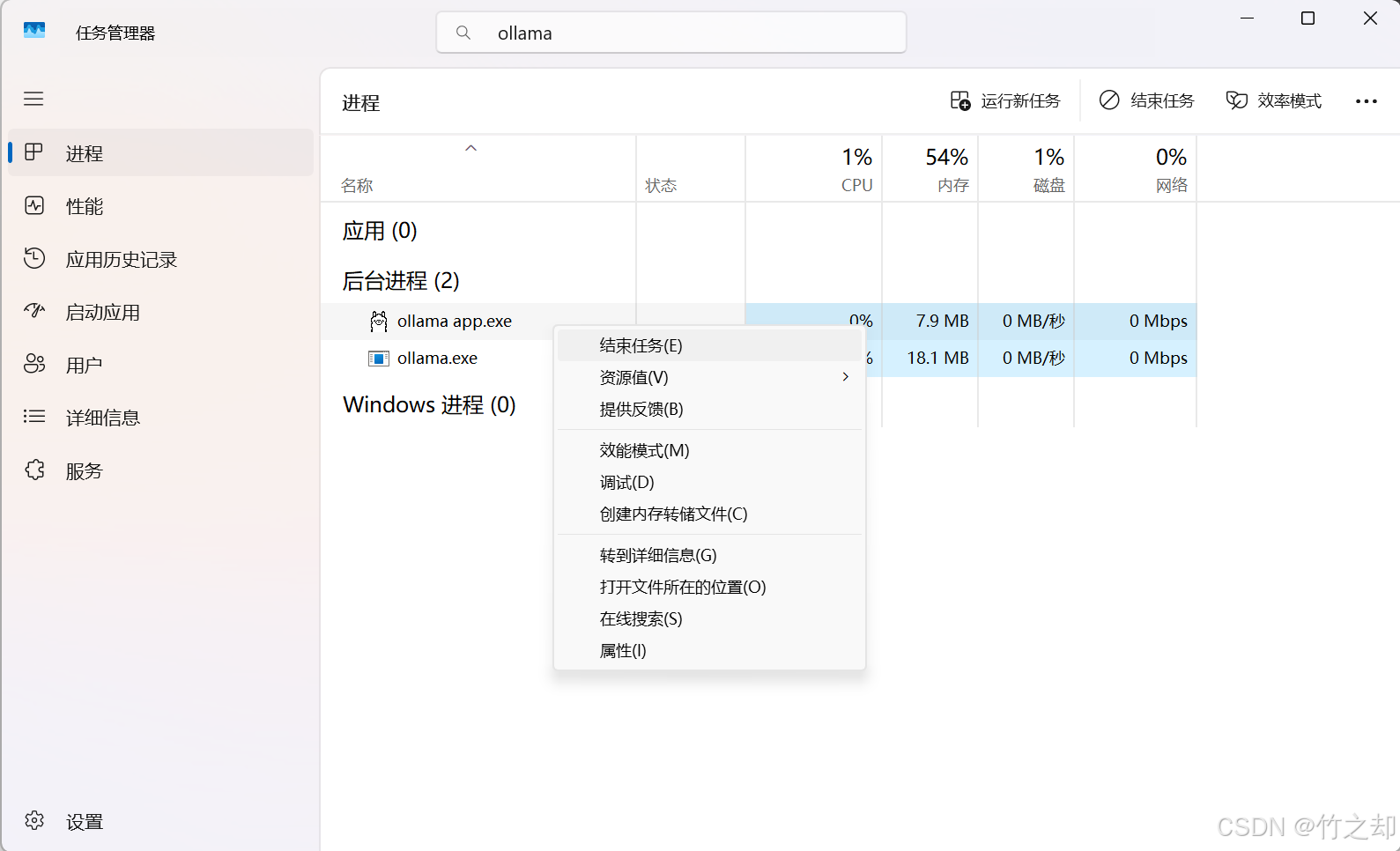
接下来,打开任务管理器( ctrl + shift + ESC ),搜索 ollama ,在后台进程中,右键,选择 结束任务 。关闭所有 ollama 相关的进程。然后 重新启动 ollama , 让 ollama 检测到环境变量。
二、内网穿透
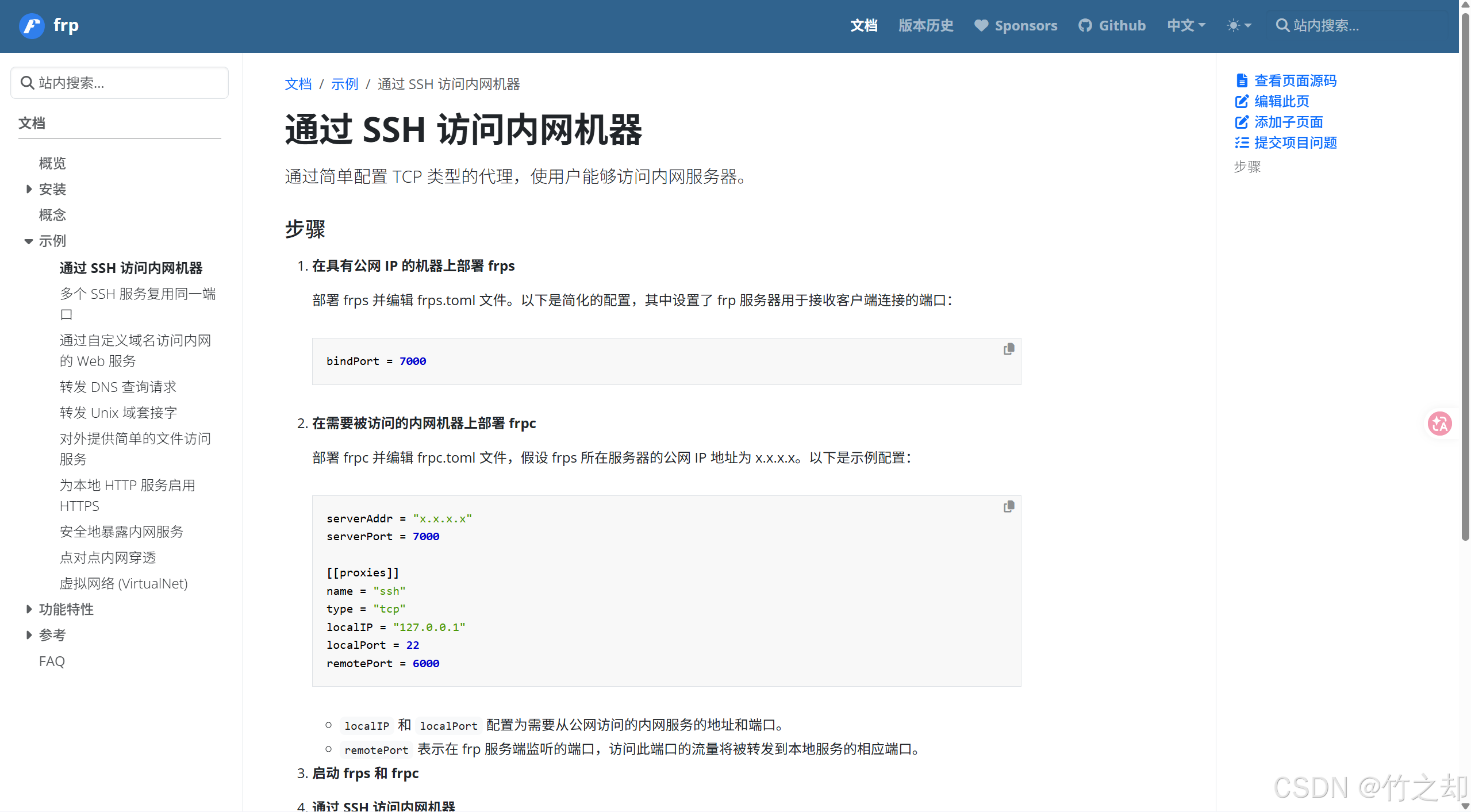
你的 ollama 服务跑在自己的 Windows 电脑上(内网),opencalw 跑在远程云服务器上面(外网)。内网设备可以访问外网设备,但是外网无法直接访问内网设备,所以要做 内网穿透 。 你可以使用 github 上开源项目 frp 自己搭建内网穿透服务,也可以使用现成的工具做内网穿透(比如:SakuraFrp,Ngrok,zerotier,tailscale等)。文章以 frp 做演示。
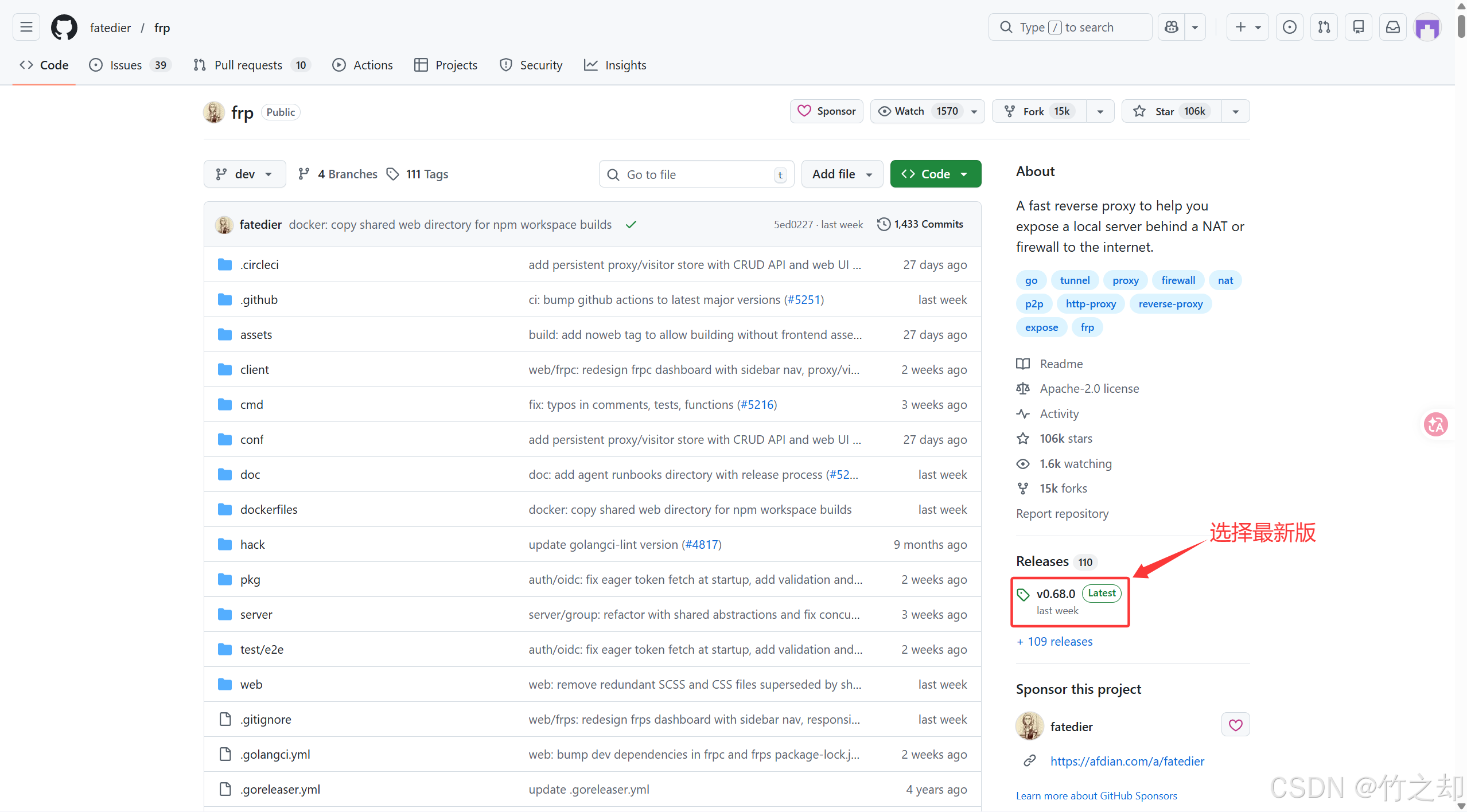
2.1 frp 工具下载
选择最新版下载。 github FRP 官方地址
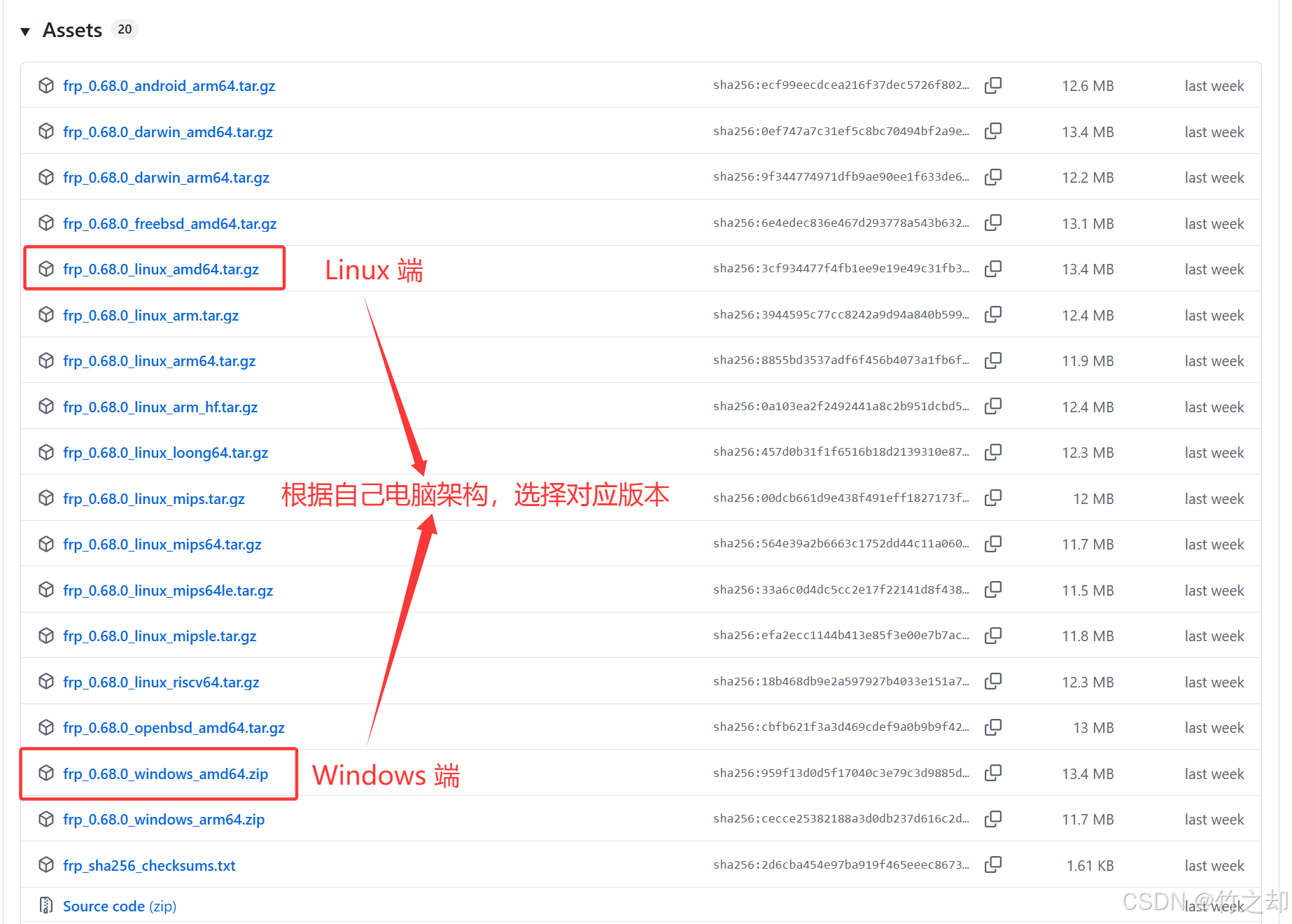
根据自己电脑架构,选择对应版本:
2.2 服务端配置
服务端配置,一般是带有 公网IP 的设备,即云服务器。更多文件配置,请参考官方文档。 frp 官方文档
将下载的 linux 版本的压缩包上传至服务器,解压后进入文件夹。
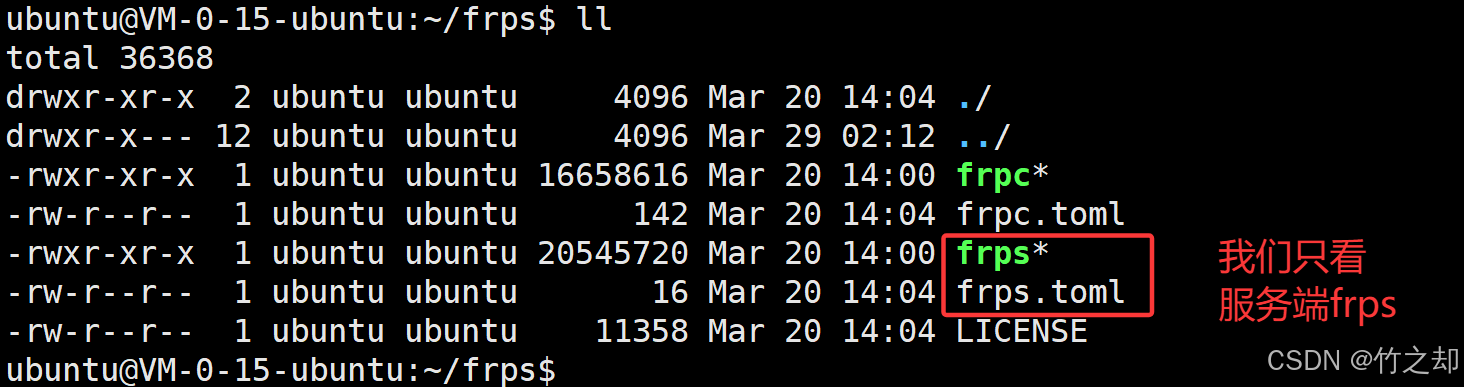
文件介绍:
解压后里面由5个文件,frpc 和 frpc.toml 为客户端可执行文件和客户端配置文件,frps 和 frps.toml 为服务端可执行文件和服务端配置文件,LICENSE 是许可证信息。服务端配置,我们只看 frps和frps.toml 。
编辑 frps.toml 文件,粘贴以下内容:
# frp 服务端监听端口(frpc 连接用)
bindPort = 7000
# 连接密码,必须和客户端一致
auth.token = "my_password"
# ======= Web 管理面板(可选,主要用于查看连接信息) ========
# 默认为 127.0.0.1,如果需要公网访问,需要修改为 0.0.0.0。
webServer.addr = "0.0.0.0"
webServer.port = 7500
# dashboard 用户名密码,可选,默认为空
webServer.user = "admin"
webServer.password = "admin"
# ====================================================
开启防火墙/放行安全组:
# 7000 frp 通信端口
ufw allow 7000/tcp
# 11434 ollama 穿透端口
ufw allow 11434/tcp
# 服务端 web 面板端口(非必须)
ufw allow 7500/tcp
服务端启动指令:
./frps -c frps.toml

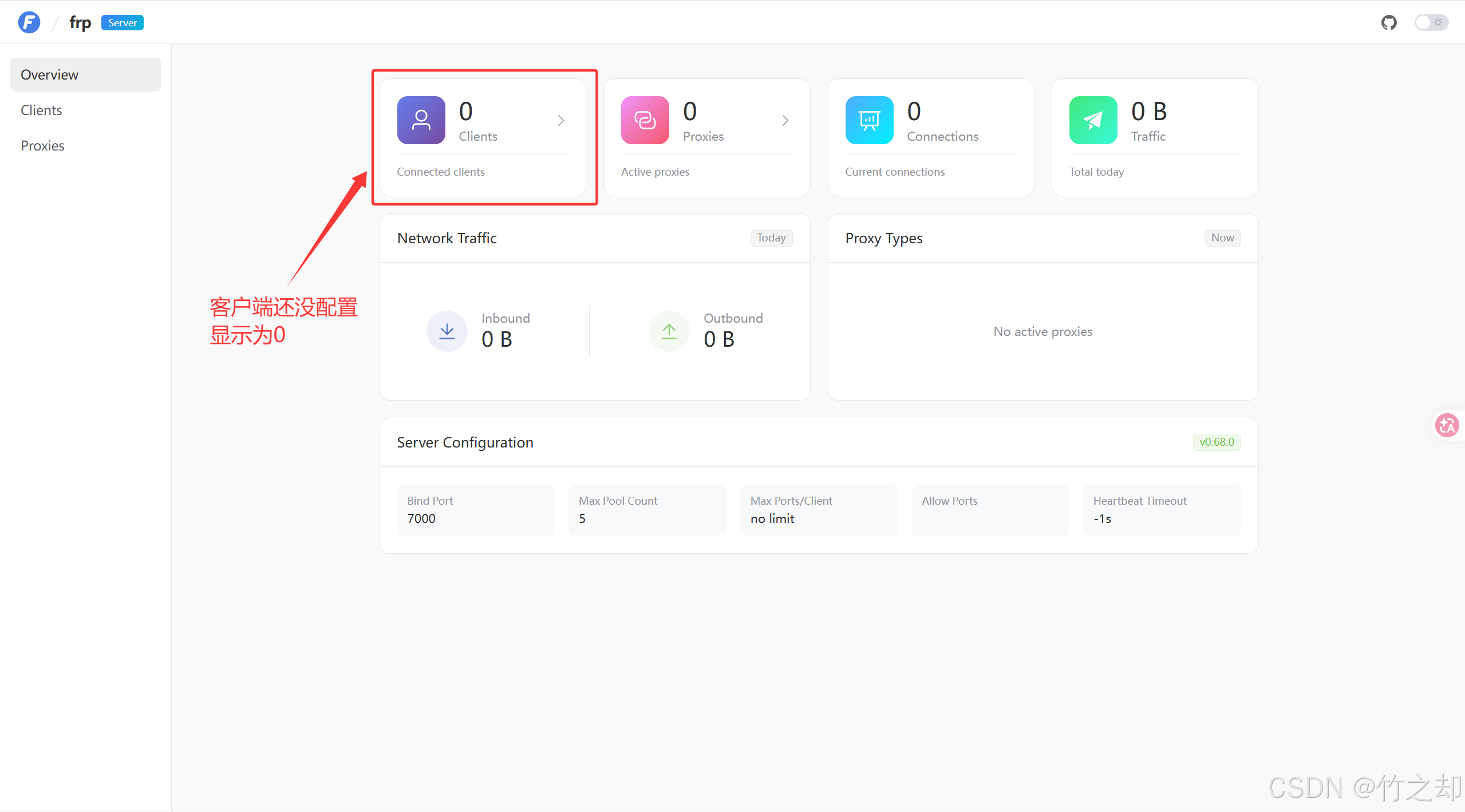
面板访问地址(可选,主要用于查看连接信息),访问后输入上面配置文件中的账号和密码(admin, admin)。
<你的云服务器IP>:7500
能看到这个界面就说明服务端部署成功。
2.3 客户端配置
客户端配置,一般是希望被访问的内网设备,即本地 Windows 电脑。
将下载的 Windows 端的压缩包放在一个没有中文路径的文件夹下,解压后进入文件夹。
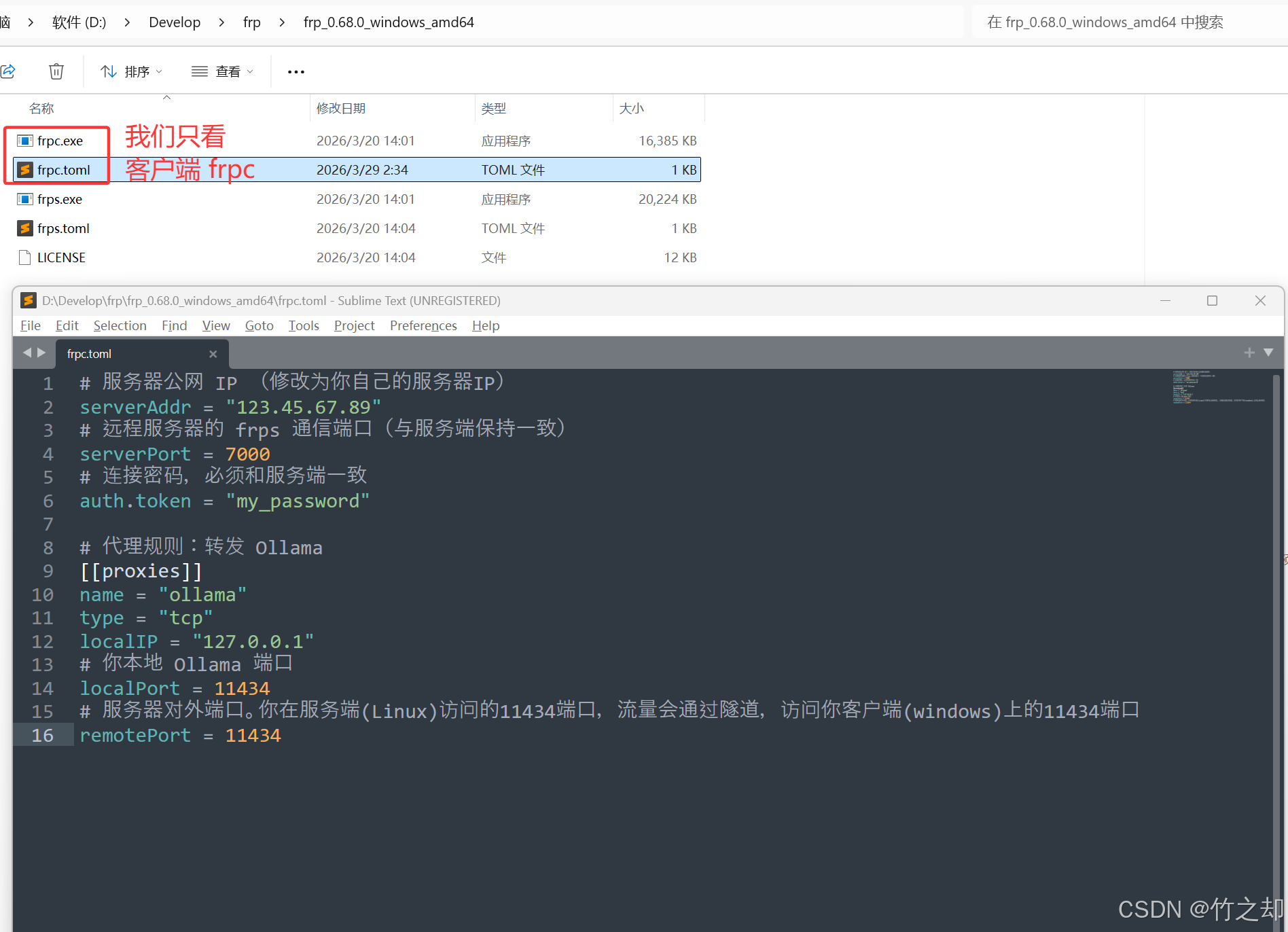
编辑 frpc.toml 文件,修改为你自己的服务器IP:
# 服务器公网 IP (修改为你自己的服务器IP)
serverAddr = "123.45.67.89"
# 远程服务器的 frps 通信端口(与服务端保持一致)
serverPort = 7000
# 连接密码,必须和服务端一致
auth.token = "my_password"
# 代理规则:转发 Ollama
[[proxies]]
name = "ollama"
type = "tcp"
localIP = "127.0.0.1"
# 你本地 Ollama 端口
localPort = 11434
# 服务器对外端口。你在服务端(Linux)访问的11434端口,流量会通过隧道,访问你客户端(windows)上的11434端口
remotePort = 11434
localIP和localPort配置为需要从公网访问的内网服务的地址和端口。remotePort表示在 frp 服务端监听的端口,访问此端口的流量将被转发到本地服务的相应端口。- 第一个
localPort=11434表示的是你windows内网的11434端口,第二个remotePort = 11434表示你远程云服务器的 11434 端口。 - 访问:云服务器
123.45.67.89:11434等价于访问内网设备的:127.0.0.1:11434。
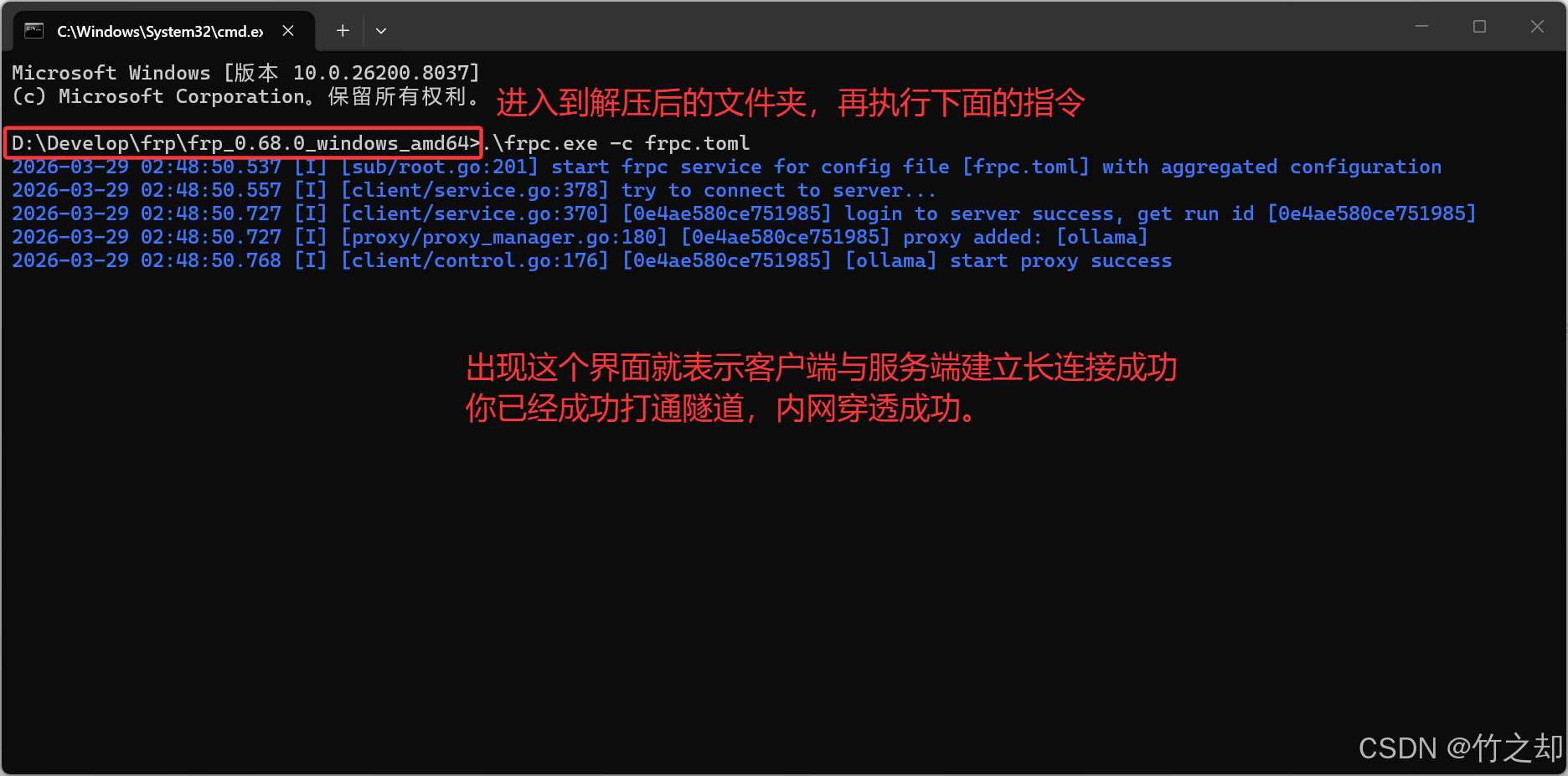
客户端启动指令:
.\frpc.exe -c frpc.toml
2.4 连接验证
访问这个地址,验证是否连接成功。如果无法访问,请先查看你本地的 ollama 是否正在运行?先让本地 ollama 服务跑起来,再进行内网穿透。
<你的云服务器IP>:11434
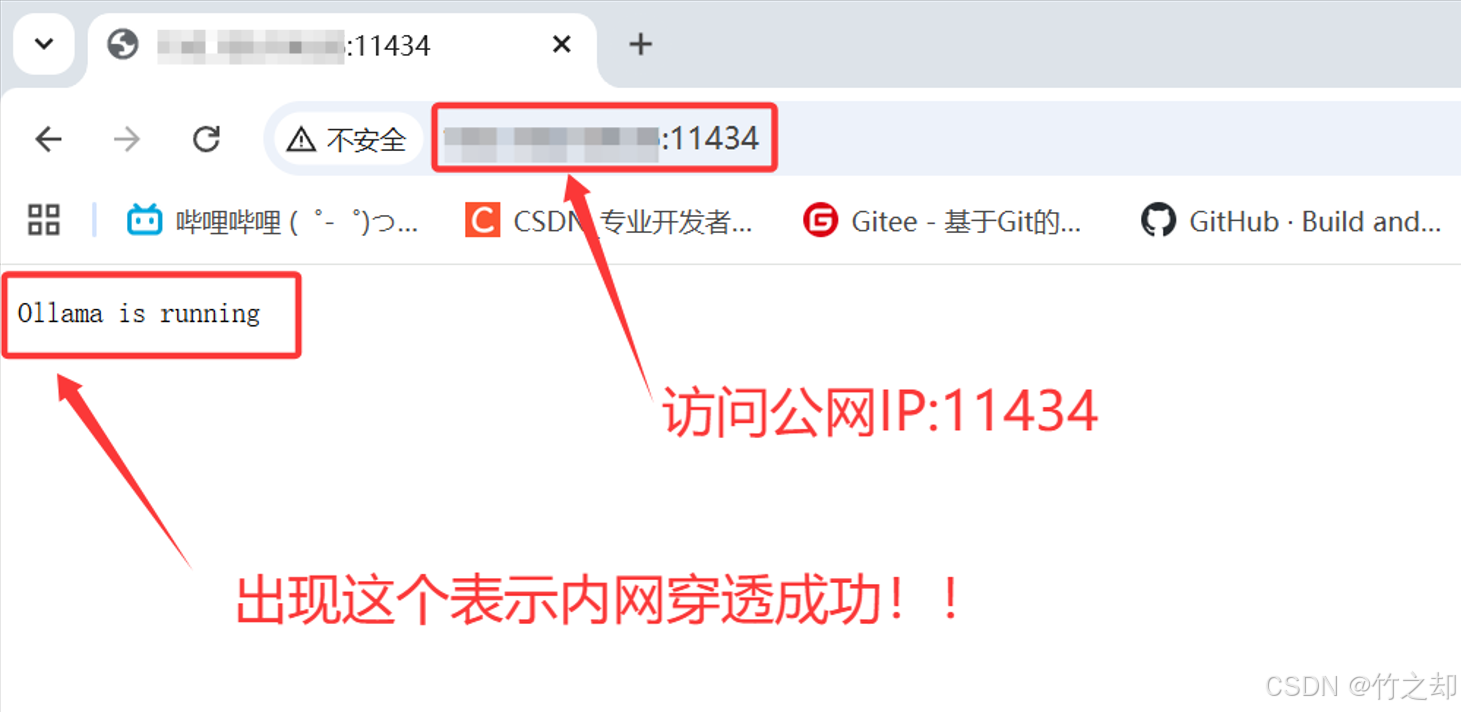
访问这个地址,查看你本地已经下载的大模型。
<你的云服务器IP>:11434/api/tags
2.5 原理简述
原理简述: 由内网设备(客户端frpc)主动向外网设备(服务端frps)发起请求连接,被服务端接收后建立一条 长连接通路,这个长连接的通路就是我们所说的隧道。内网穿透就是要搭建这条长连接的隧道,使得外网可以访问你内网的设备。
流量走向: 访问<云服务器IP>:端口号,被服务端frps 监听到,由服务端frps通过隧道将流量转发给客户端frpc,客户端frpc接收到请求后,会根据代理转发规则,将流量转发给本地电脑对应的服务,服务响应数据,然后回复原路返回。
【公网用户】
↓ 访问 云IP:11434
【frps】
↓ 11434被frps监听,frps将流量送入【隧道】
【隧道:frpc ↔ frps:7000】
↓
【本地frpc】
↓ 转发到 127.0.0.1:11434
【Ollama】
↓ 处理完返回
【原路全部返回】
连接建立成功后,你就可以通过外网IP 间接访问(需要服务器中转流量) 你的内网设备的服务。比如:你在windows电脑的本地部署了一个网站(访问地址:localhost:8089),你想让远在外地的朋友访问,很显然,你的朋友无法访问,当你做了内网穿透,你的朋友就可以在远程访问你的电脑的网站。再比如:你在自己电脑上玩我的世界,你想和你的朋友一起联机,很简单,做个内网穿透就行了。
如果你想做到低延迟,两台内网设备 直接访问 ,那么你就做 P2P 点对点连接 的内网穿透。P2P 隧道打通后无需服务器做流量转发,两台设备直接进行通信,延迟最低,网速最快。但受路由器,校园网,NAT等你可能打洞不成功。
三、openclaw 连接 ollama
3.1 配置 openclaw
执行以下指令配置 openclaw :
openclaw config
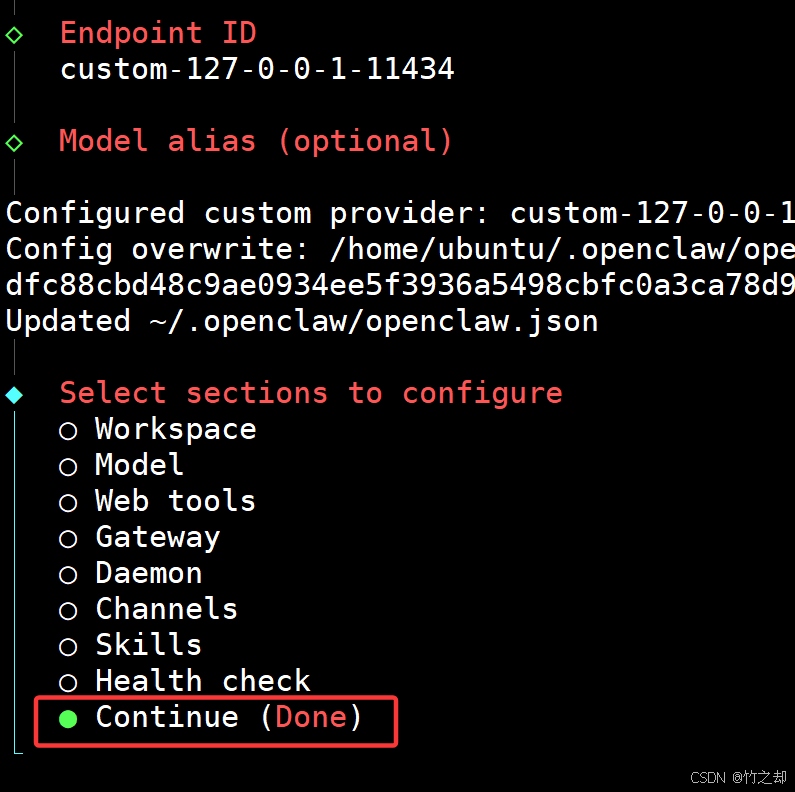
这里给出总览配置,和两个需要注意的点,具体的详细配置与你第一次安装 openclaw 时的选择是一样的,选择与OpenAI 兼容的接口。

选择 Contune(Done) ,配置完成。
API Base URL: 这个地址链接是固定的:
http://127.0.0.1:11434/v1
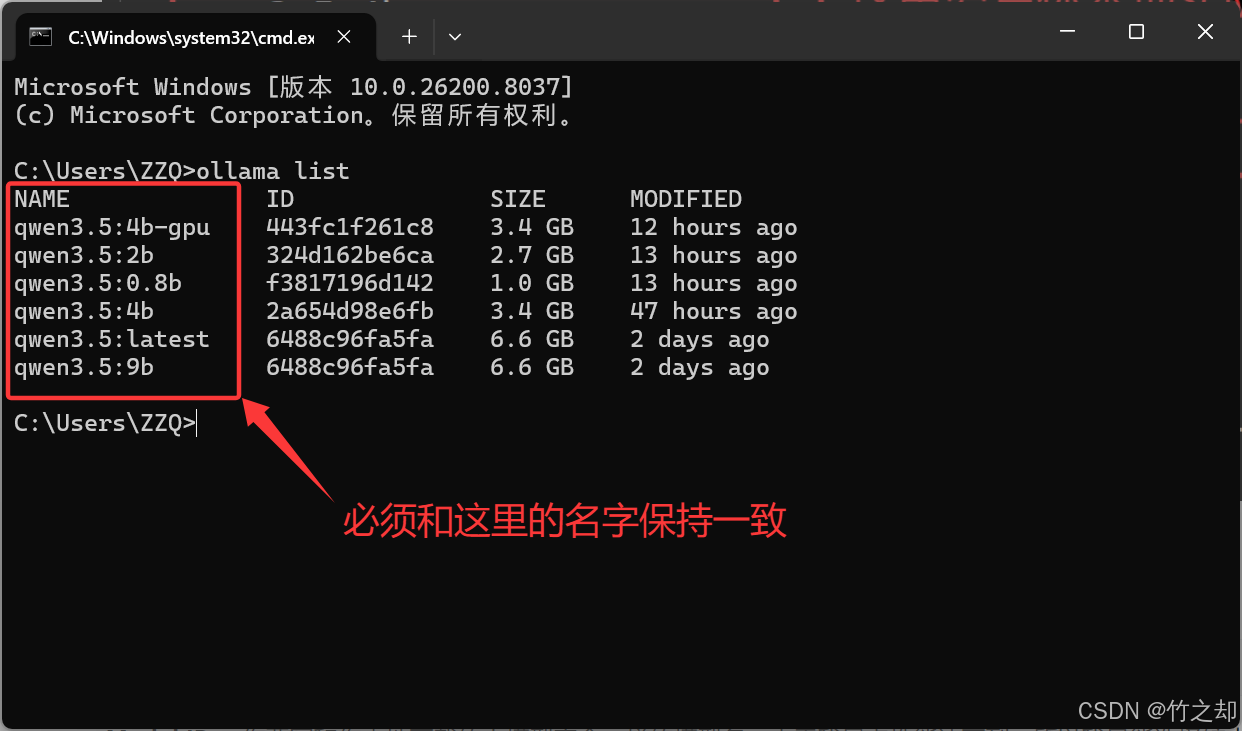
Model ID: 你要写和你本地下载的大模型完全一样的模型名。由于我显卡性能达不到, qwen3.5:4b 参数的模型,无法完全放入 GPU 进行计算,所以我更换了较小参数的模型,我更换了: qwen3.5:2b 模型。 注意:deepseek-r1:1.5b 模型不可以接入openclaw, 其他参数没试。qwen3.5系列的模型都可以接入。
qwen3.5:2b
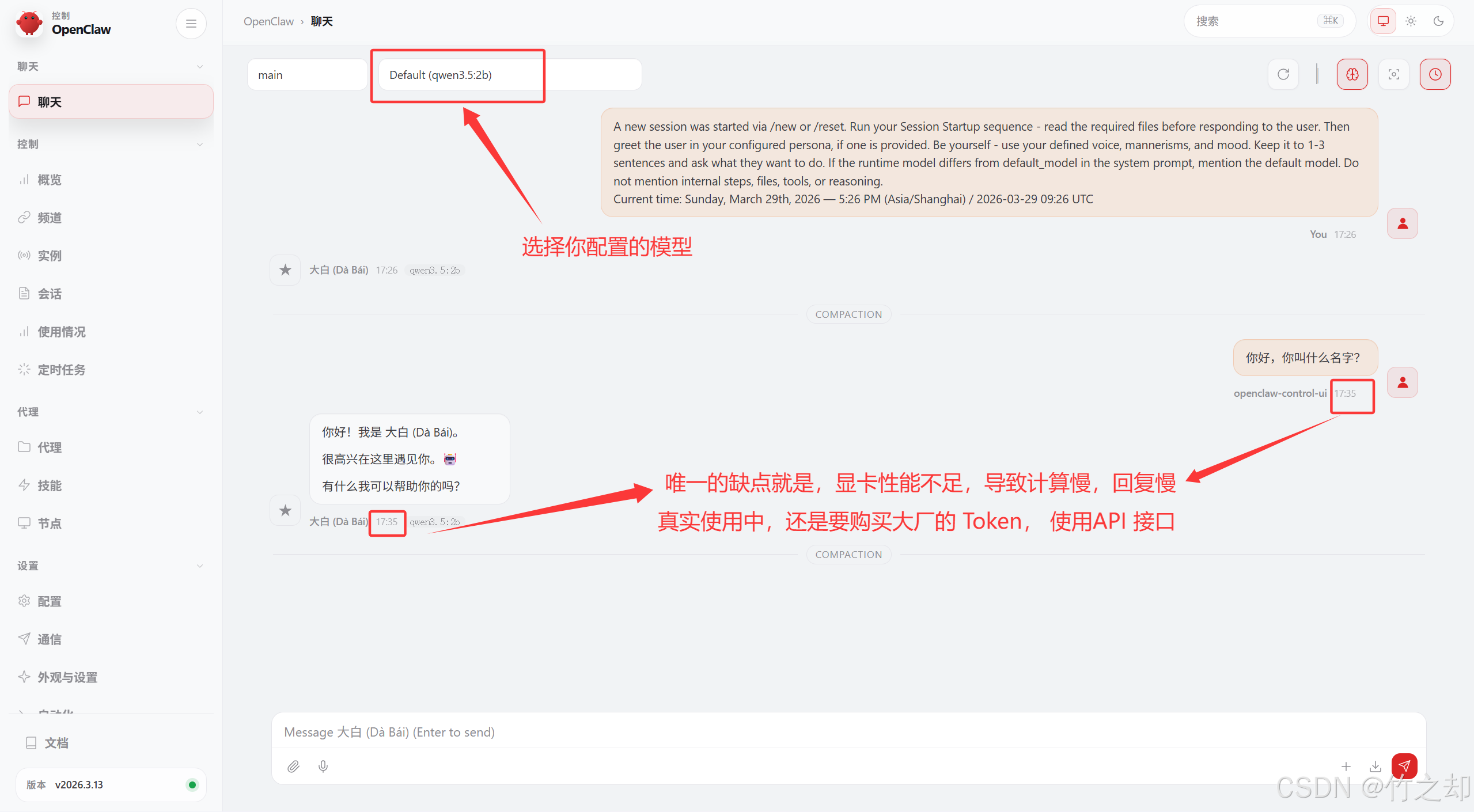
3.2 测试连接
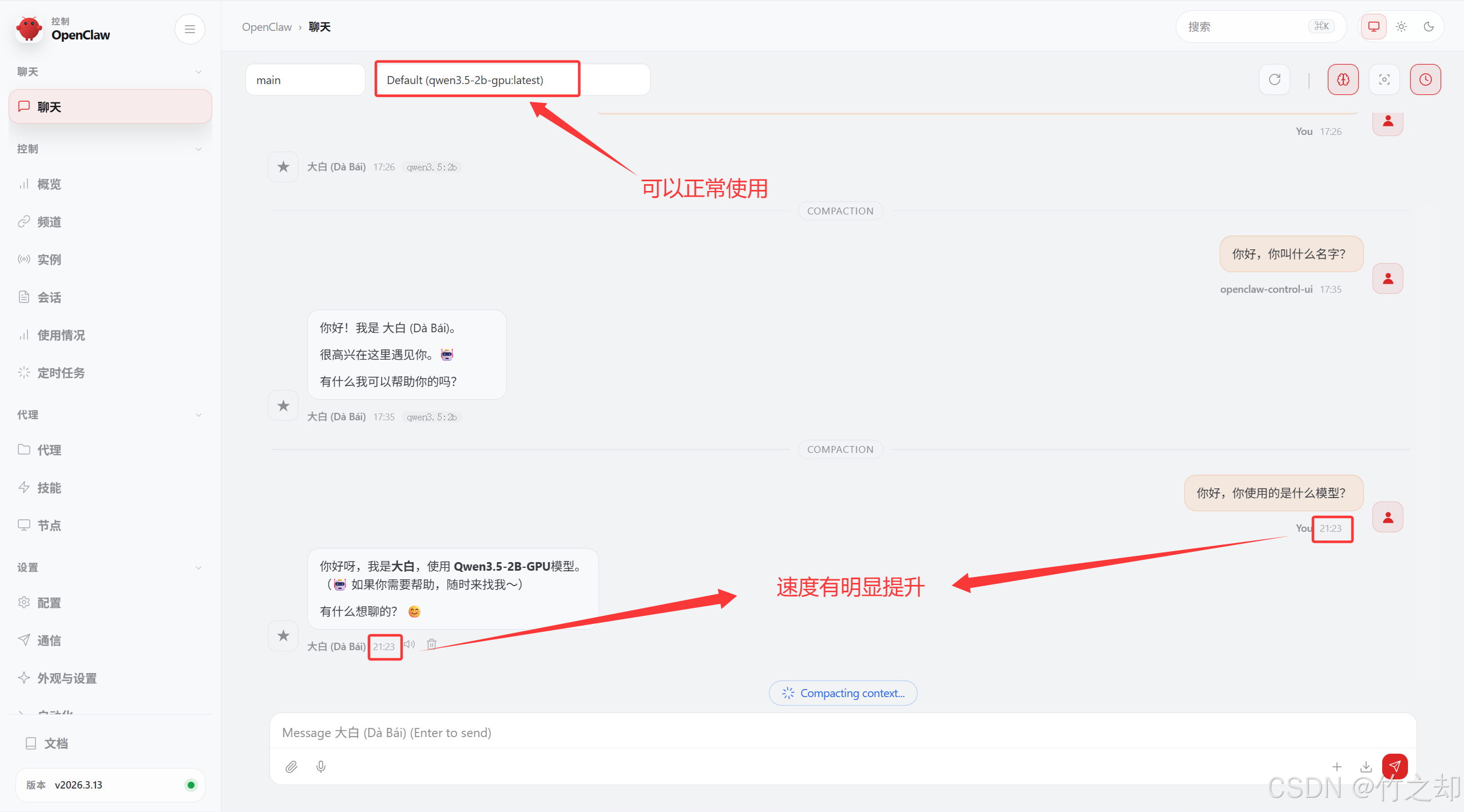
连接成功,可以正常使用。模型计算速度受限于你本地GPU性能,和模型参数。GPU性能越好,显存越大计算月快,回复越快。模型参数越大,回复越准确。
四、使用GPU加速模型的训练
4.1 查看模型进程
ollama 官方参考文档【Modelfile Reference】
你在跑本地模型时,回复总是很慢,你不妨查看你的模型是在你的显卡GPU上面跑,还是在你的CPU上面跑。对于大模型的计算,真正起作用是你的显卡GPU( 独显 ),而不是你的 核显 / CPU 。
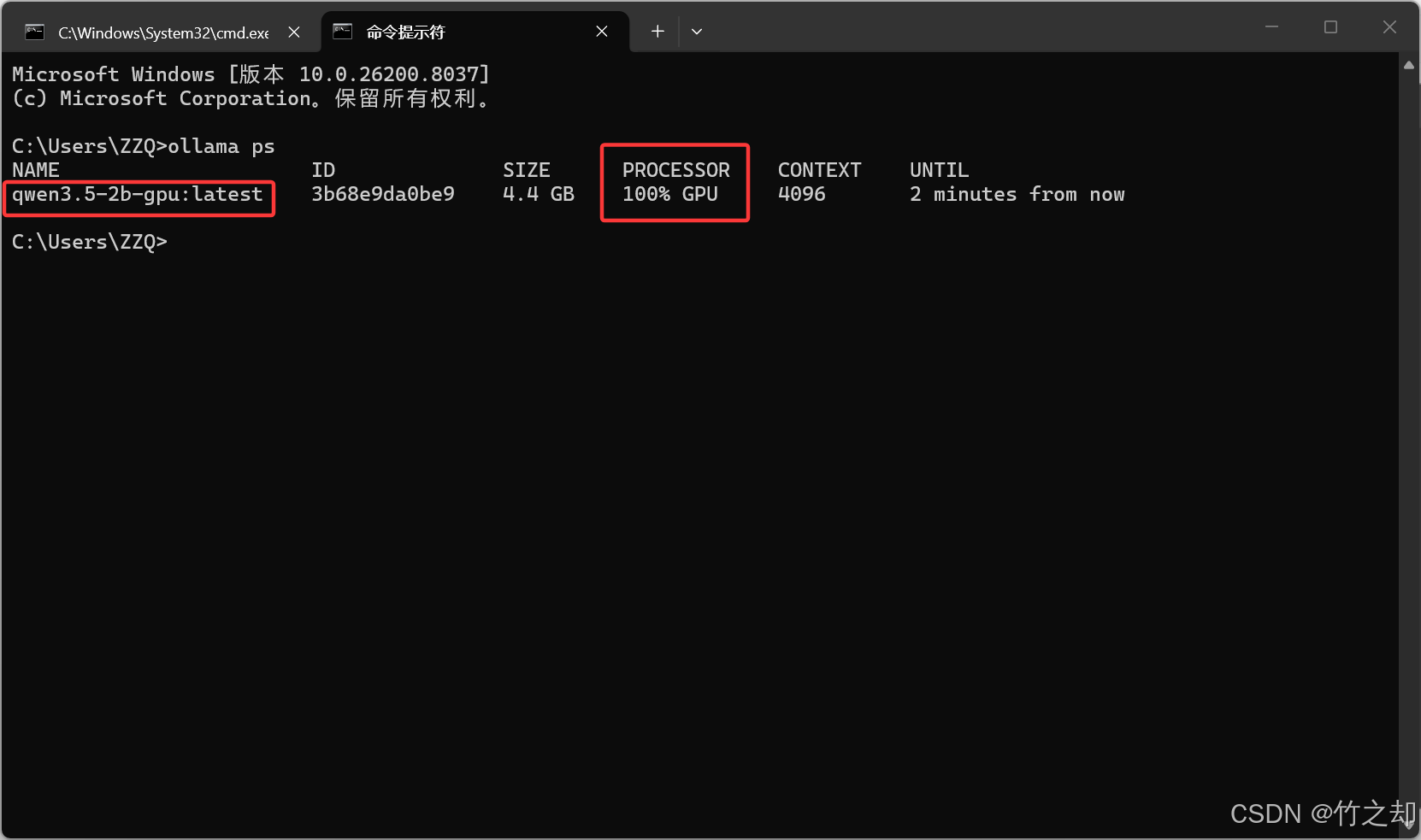
执行以下指令查看你本地的模型是在什么设备上跑:
ollama ps
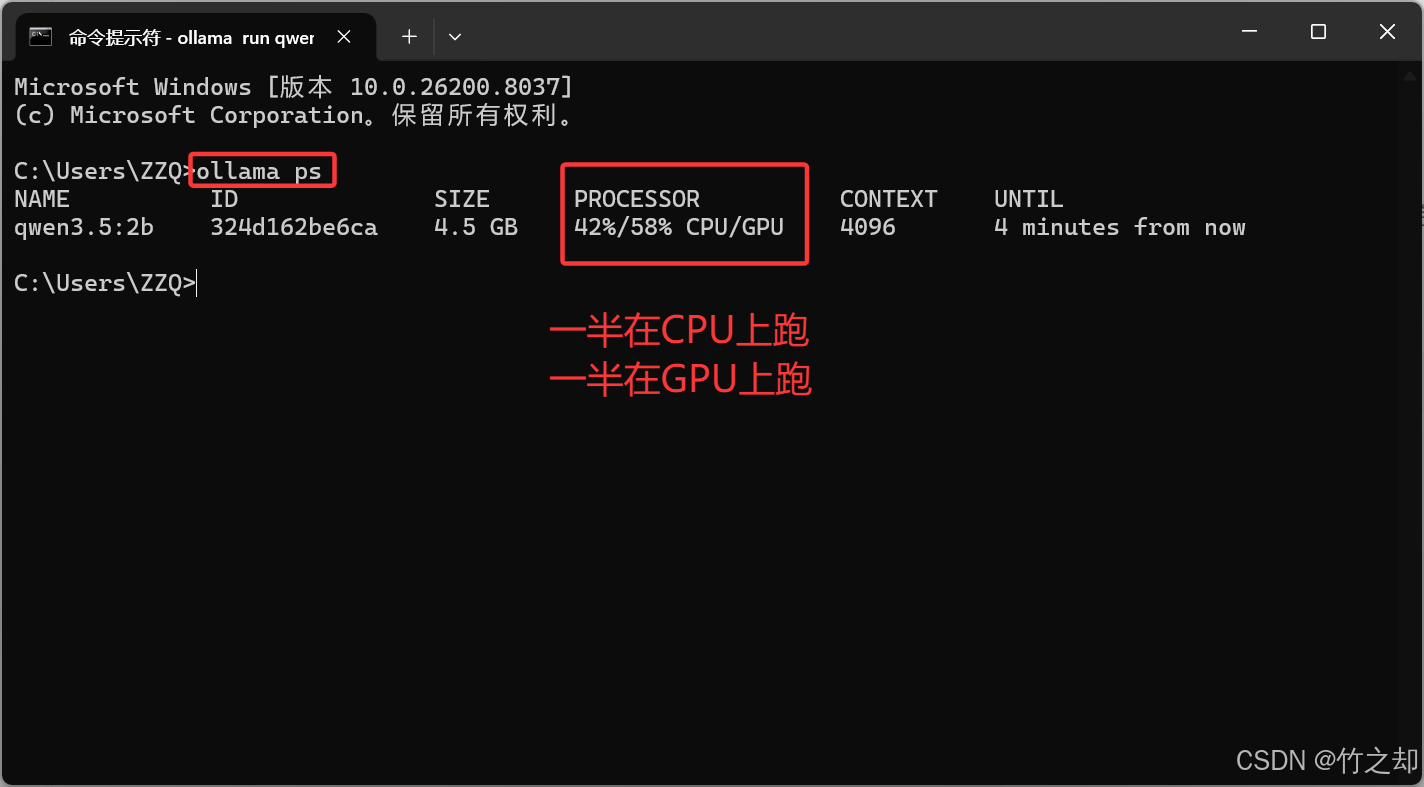
如果显示空白,请先让模型跑起来再查看:
ollama run qwen3.5:2b
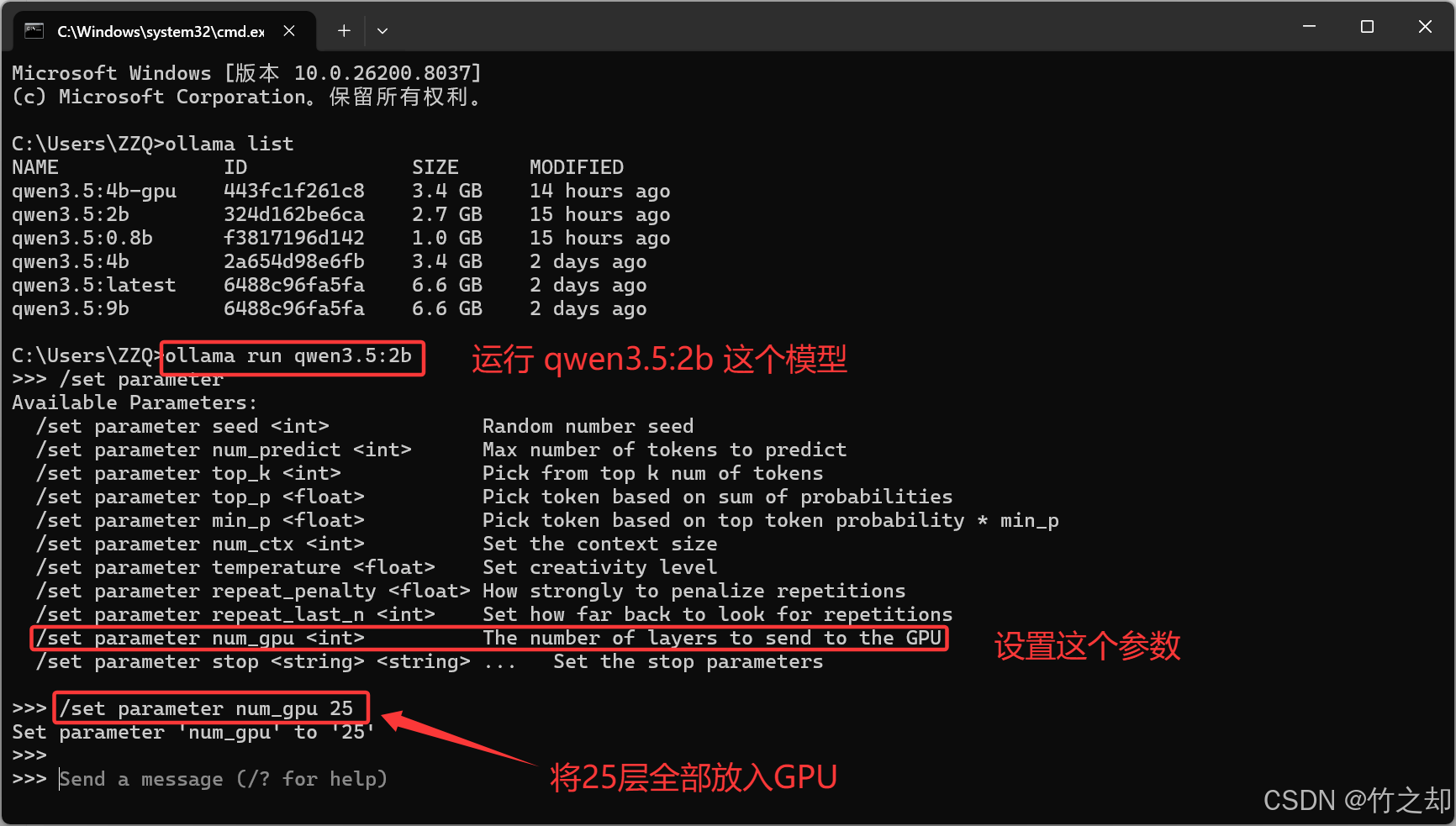
4.2 模型调参(num_gpu)
num_gpu: 用于指定加载多少层模型到 gpu 。加载到GPU的模型层数越多,计算的越快,我们要尽可能多的将模型放入GPU计算。
如何查看这个模型一共有多少层?
查看 ollama 日志文件,右键 ollama 的托盘图标,点击 View logs 查看日志。默认路径在: C:\Users\<你的用户名>\AppData\Local\Ollama ,打开 server.log 日志文件。Ctrl +F 搜索 offloaded ,可以看到目前使用的 qwen3.5:2b 这个模型,一共有 25层 ,已经将24层放在GPU,但是输出层在CPU上计算,所以回复会很慢。
# 日志文件:server.log
time=2026-03-29T18:12:38.363+08:00 level=INFO source=ggml.go:482 msg="offloading 24 repeating layers to GPU"
time=2026-03-29T18:12:38.363+08:00 level=INFO source=ggml.go:486 msg="offloading output layer to CPU"
time=2026-03-29T18:12:38.363+08:00 level=INFO source=ggml.go:494 msg="offloaded 24/25 layers to GPU"
方法一:交互模式指定
方法二:放在 4.3 讲解
将模型跑起来,然后设置这个参数:
/set parameter num_gpu 25
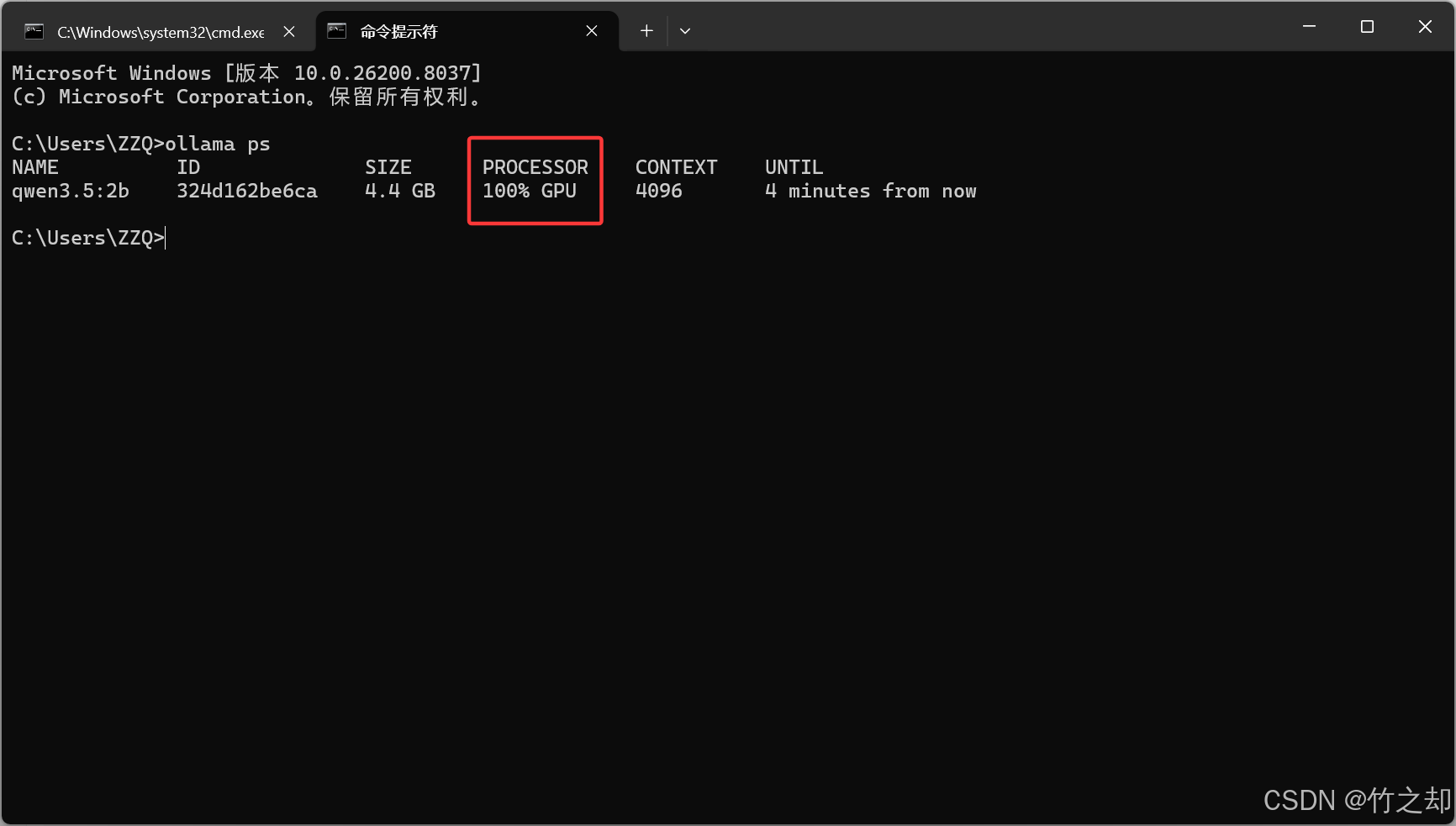
询问它一个问题,然后查看日志。可以看到25层模型全部放入GPU计算:
# 日志文件:server.log
time=2026-03-29T19:02:59.446+08:00 level=INFO source=ggml.go:482 msg="offloading 24 repeating layers to GPU"
time=2026-03-29T19:02:59.446+08:00 level=INFO source=ggml.go:489 msg="offloading output layer to GPU"
time=2026-03-29T19:02:59.446+08:00 level=INFO source=ggml.go:494 msg="offloaded 25/25 layers to GPU"
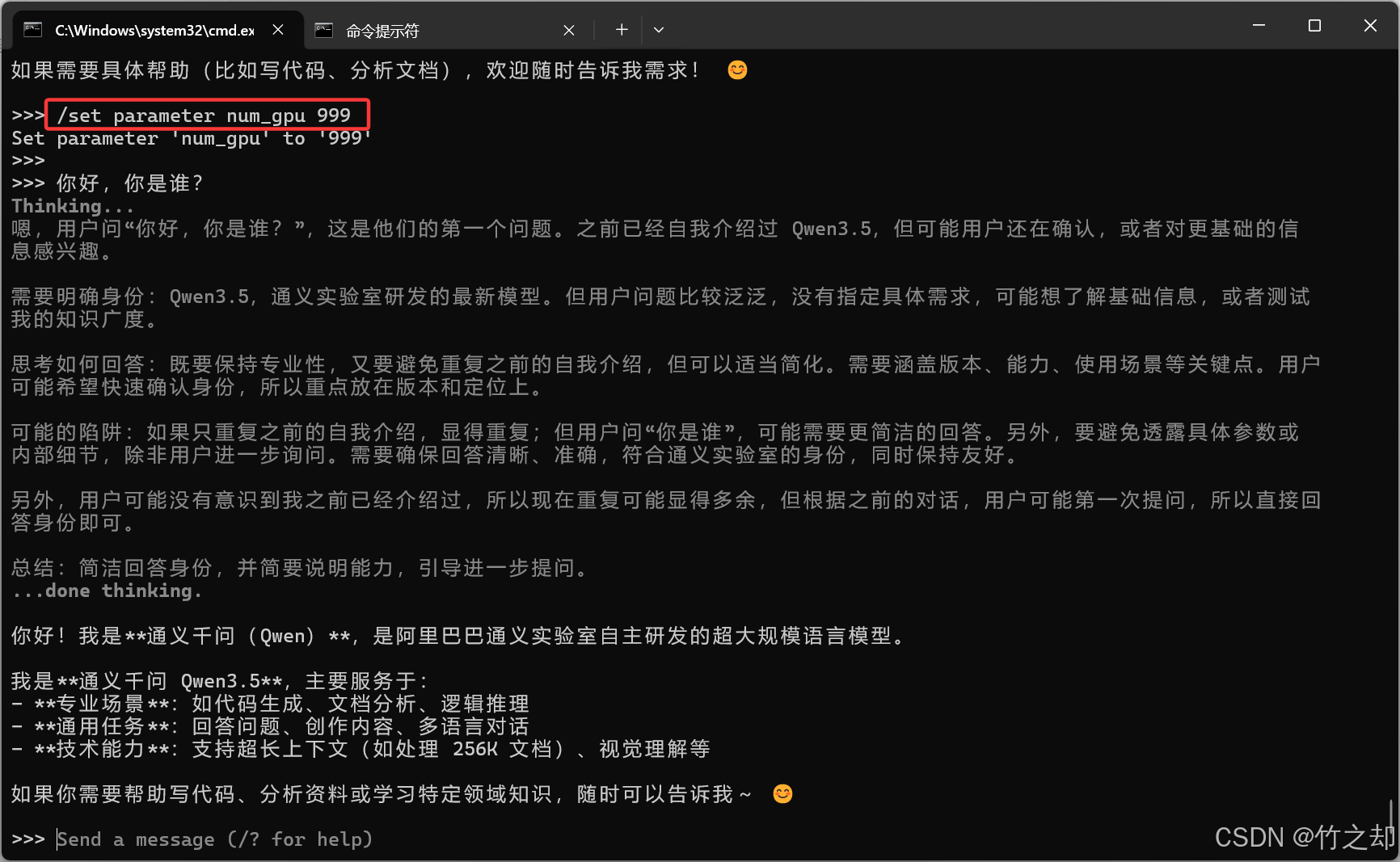
如果你不想查看这个模型有多少层,你可以直接将 num_gpu 设置一个很大的数字(比如: 999 ),如果模型层数小于999层,他会将模型的所有层全部加载到GPU计算。
# 日志文件:server.log
time=2026-03-29T19:24:11.573+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=25 requested=999
... ...
time=2026-03-29T19:24:12.916+08:00 level=INFO source=ggml.go:482 msg="offloading 24 repeating layers to GPU"
time=2026-03-29T19:24:12.916+08:00 level=INFO source=ggml.go:489 msg="offloading output layer to GPU"
time=2026-03-29T19:24:12.916+08:00 level=INFO source=ggml.go:494 msg="offloaded 25/25 layers to GPU"
如果你设置的 num_gpu 的层数超过显存的最大容量,那么就会报错,无法启动大模型。比如:我的电脑4G显存,无法完全放下 qwen3.5:4b 参数的模型。
# 日志文件:server.log
time=2026-03-29T19:37:42.882+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=33 requested=999
... ...
time=2026-03-29T19:37:44.104+08:00 level=INFO source=sched.go:511 msg="Load failed" model=D:\Develop\Ollama\models\blobs\sha256-81fb60c7daa80fc1123380b98970b320ae233409f0f71a72ed7b9b0d62f40490 error="memory layout cannot be allocated with num_gpu = 999"
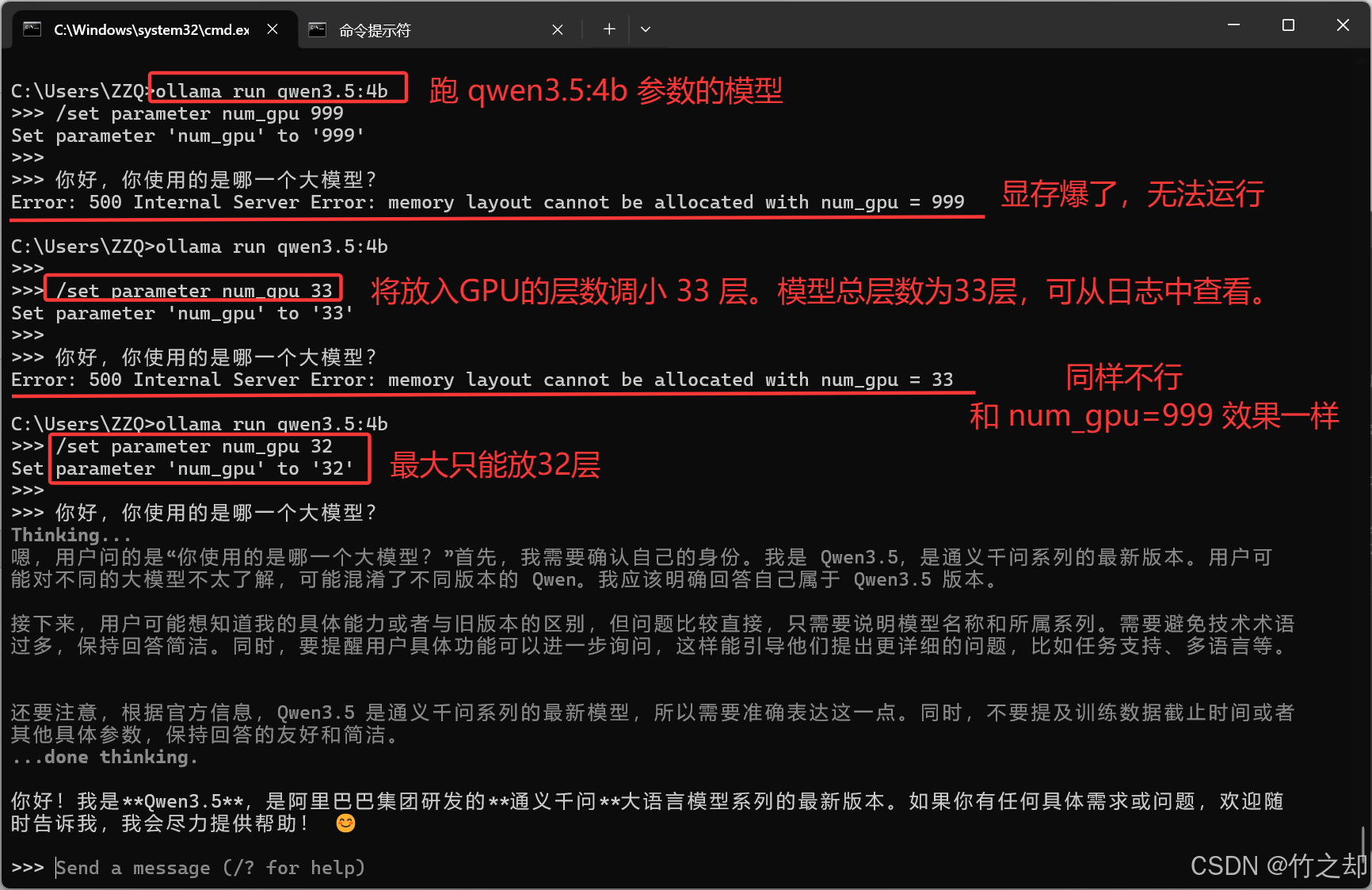
# 日志文件:server.log
# 设置 32 层可以正常跑,有一层输出层由CPU计算
time=2026-03-29T19:41:56.548+08:00 level=INFO source=server.go:757 msg="loading model" "model layers"=33 requested=32
... ...
time=2026-03-29T19:41:58.200+08:00 level=INFO source=ggml.go:482 msg="offloading 32 repeating layers to GPU"
time=2026-03-29T19:41:58.201+08:00 level=INFO source=ggml.go:486 msg="offloading output layer to CPU"
time=2026-03-29T19:41:58.201+08:00 level=INFO source=ggml.go:494 msg="offloaded 32/33 layers to GPU"
方法二:修改模型配置文件
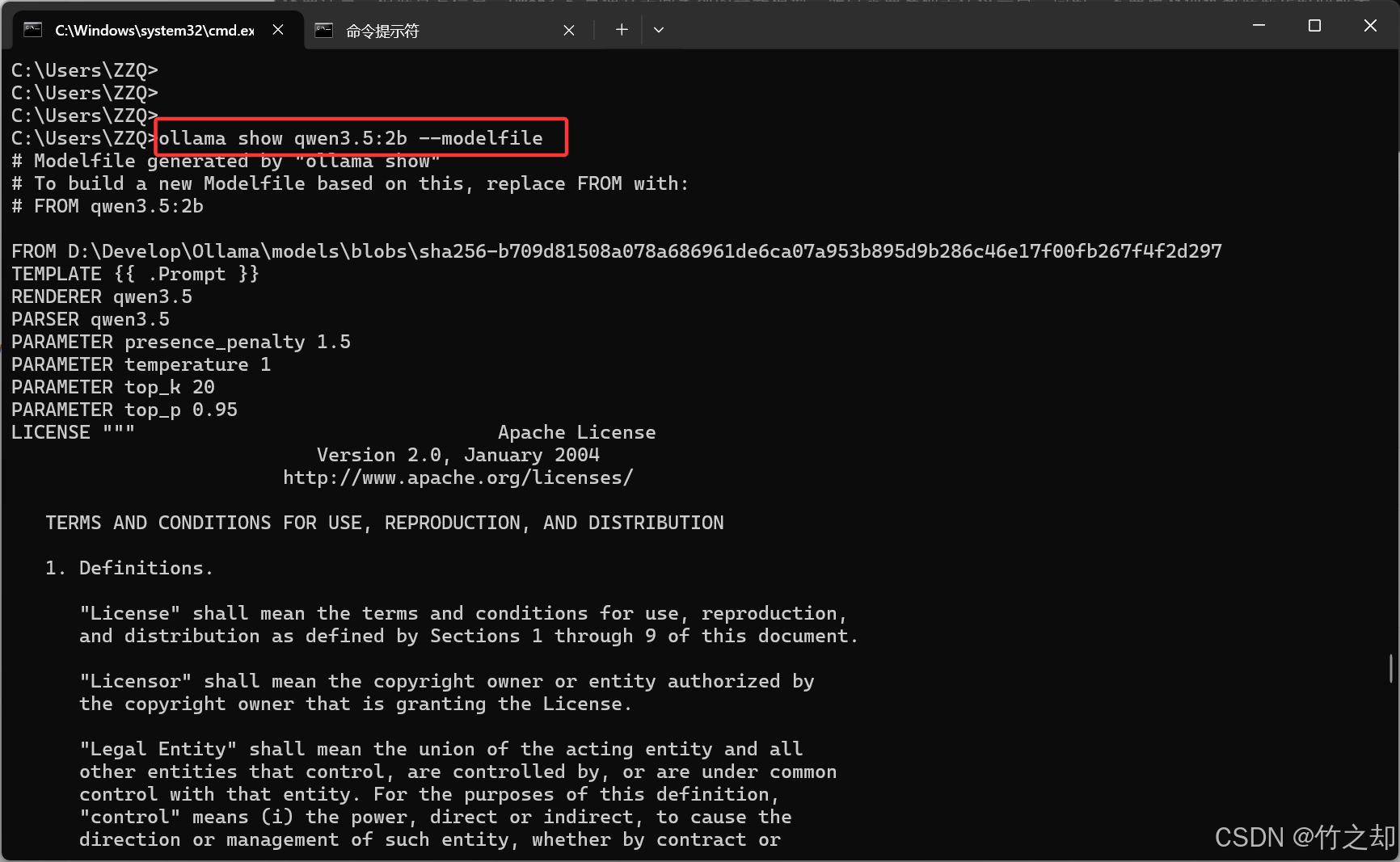
执行以下指令查看 qwen3.5:2b 模型的配置文件:
ollama show qwen3.5:2b --modelfile
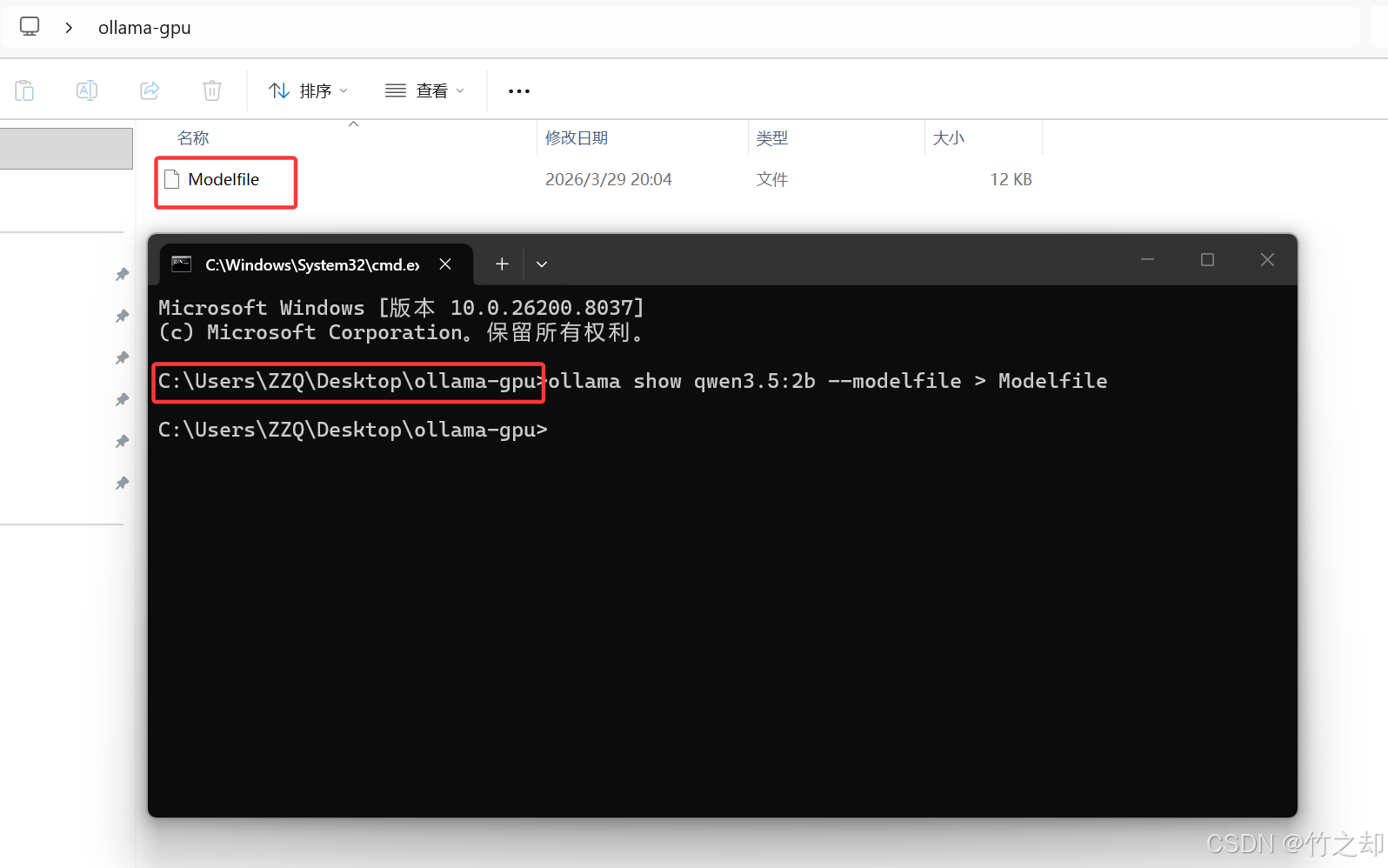
在桌面上新建一个文件夹,名字随意不要带中文,打开 cmd,进入到该文件夹。执行以下指令导出模型配置文件:
ollama show qwen3.5:2b --modelfile > Modelfile
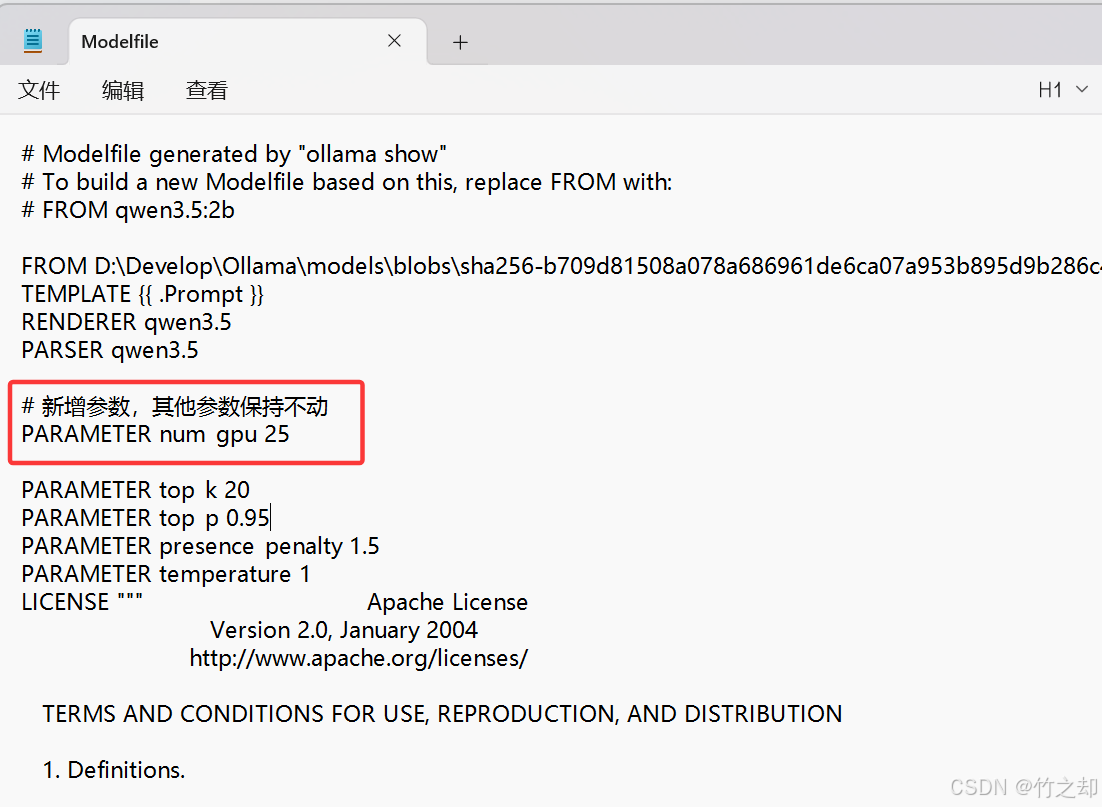
使用记事本打开 Modelfile 模型文件,新增以下参数,其他参数保持不变。
PARAMETER num_gpu 25
执行以下指令,使用模型文件创建新的模型。
ollama create qwen3.5-2b-gpu -f Modelfile
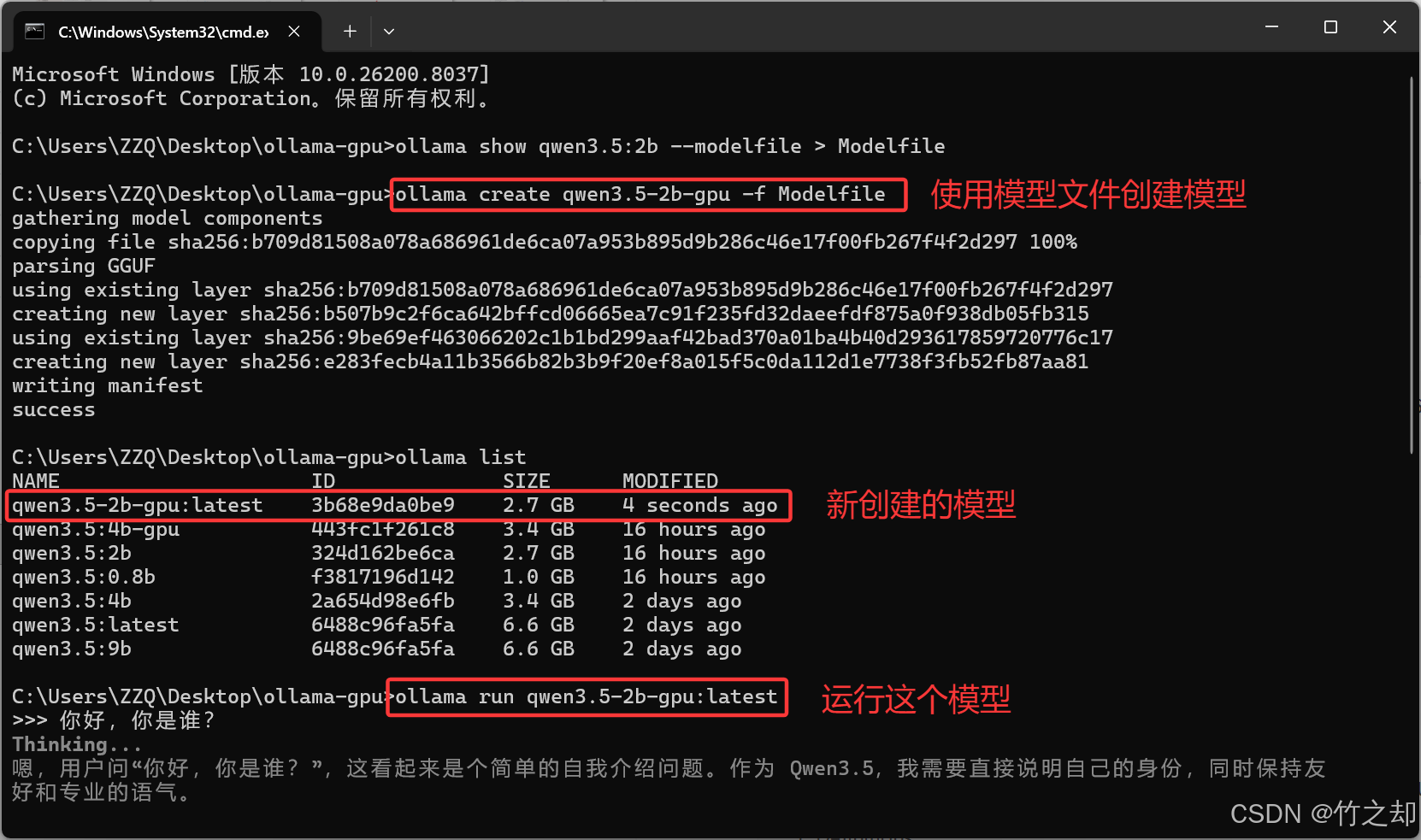
可以看到全部层使用GPU运算。
4.3 调参后的模型接入 openclaw
和 3.1 的配置一样,执行以下指令:
openclaw config
将模型名字修改为你新创建的模型名字,其他设置保持不变:
qwen3.5-2b-gpu:latest
End
你好,少年,未来可期~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)