Google的Deepseek时刻:TurboQuant压缩算法是在革谁的命?
2026年3月24日,Google Research 发表一篇论文《TurboQuant: Redefining AI efficiency with extreme compression》(中文译:《TurboQuant:以极端压缩重新定义 AI 效率》)。此文已出,AI界和财经界都极为震惊!——存储芯片先跌为敬,AI界更是有人提出,这是谷歌的Deepseek时刻!
为什么大家都极为震惊?原因很简单,请听我慢慢道来。
如需查阅论文原文,请于后台界面回复 TurboQuant,或者:https://arxiv.org/pdf/2504.19874
背景
如果您对下面的背景介绍月度还比较吃力,请详细阅读“模型的运行原理”章节,这一章主要介绍LLM是如何运行的!
随着大语言模型(LLM)广泛应用,LLM的KV缓存****(Key-Value Cache)成为主要的内存瓶颈。每产生一个新Token,都会将其对应的高维向量存入KV缓存,以加速后续的注意力计算;但随着上下文(Context)长度增长,这些缓存规模飙升,导致显存压力和推理延迟激增。而传统的模型量化方法主要集中在参数权重上,无法减少推理时不断增长的KV缓存大小。
现有的向量量化技术(如产品量化PQ)可以对检索任务的向量进行压缩,但通常需要额外存储高精度常数(如码本),引入了新的“元数据开销”。
TurboQuant应运而生,它关注KV缓存本身的压缩问题,从信息论角度寻找最优方案,以支持更长上下文和更高效的向量检索任务。
模型的运行原理
专有名词介绍
LLM:大语言模型(我们熟知的:豆包、deepseek、chatgpt、千问等通常是他们各自的底层模型衍生出来的给普通大众使用的产品)
Token:词元(即LLM可以理解被拆分的最小语义单元)
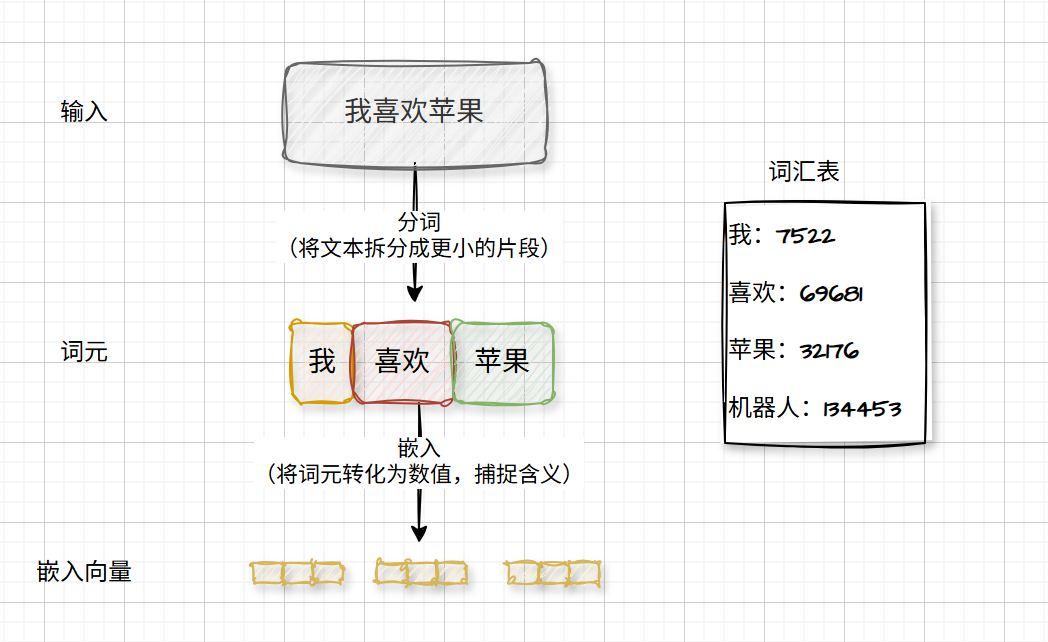
分词:将一段文字拆分成词元(比如:我喜欢苹果 --> 我 喜欢 苹果)
向量:有大小和方向,以二维坐标系为例,从原点(0,0)指向终点(比如 (0,2))的箭头
嵌入:把词元转成高维向量的过程。注意LLM根据大小支持的维度也不同,有的几千维有的上万维
Context:上下文(多轮对话里的“记忆”,如果没有它,那大模型会失忆,它只能回答你当前的问题)
显存:可以理解成显卡内存(上下文存储的物理单元)
Q、K、V:每个词元都自带这三要素(query、key、value),分别表示:q:我在找什么?k:我是谁?v:我的真实内容是什么?
KV Cahce:把之前所有词(包括历史轮次)的 K 和 V 缓存下来,避免重复计算。
自注意力机制:让模型在理解一个词元时,自动“关注”句子中其他词的相关程度,从而捕捉上下文关系
比特:bit(位),计算机能够识别的最小单位,电信号(通:1 断:0)
字节:8bits = 1Byte(英文(ASCII)字符占1字节,中文字符(根据编码不同)一般占2~4字节)
千字节:KB = 1024 Bytes
兆字节:MB = 1024 KB
吉字节:GB = 1024 MB
太字节:TB = 1024 TB
线性代数:介绍TurboQuant算法的时候会涉及到矩阵相关知识点,最好有一些线性代数基础
LLM已经融入了我们的日常,我们之前习惯的搜索引擎现在几乎已经被LLM取代。它们是如何理解我们人类的文字的?搜索引擎和LLM****最大的区别在于,前者纯粹是将问题分词,而后者分词后将词元信息嵌入,然后 LLM 根据训练好的模型理解语义、推理生成答案返回给用户。
原理剖析
首先,我们要认清一个实时:电脑或者大模型是不懂人类的语言的!
开始吧,我们跟LLM进行了这样一轮对话:
人:你觉得华为手机怎么样?
ai:华为手机挺好的…
人:我喜欢苹果
ai:…
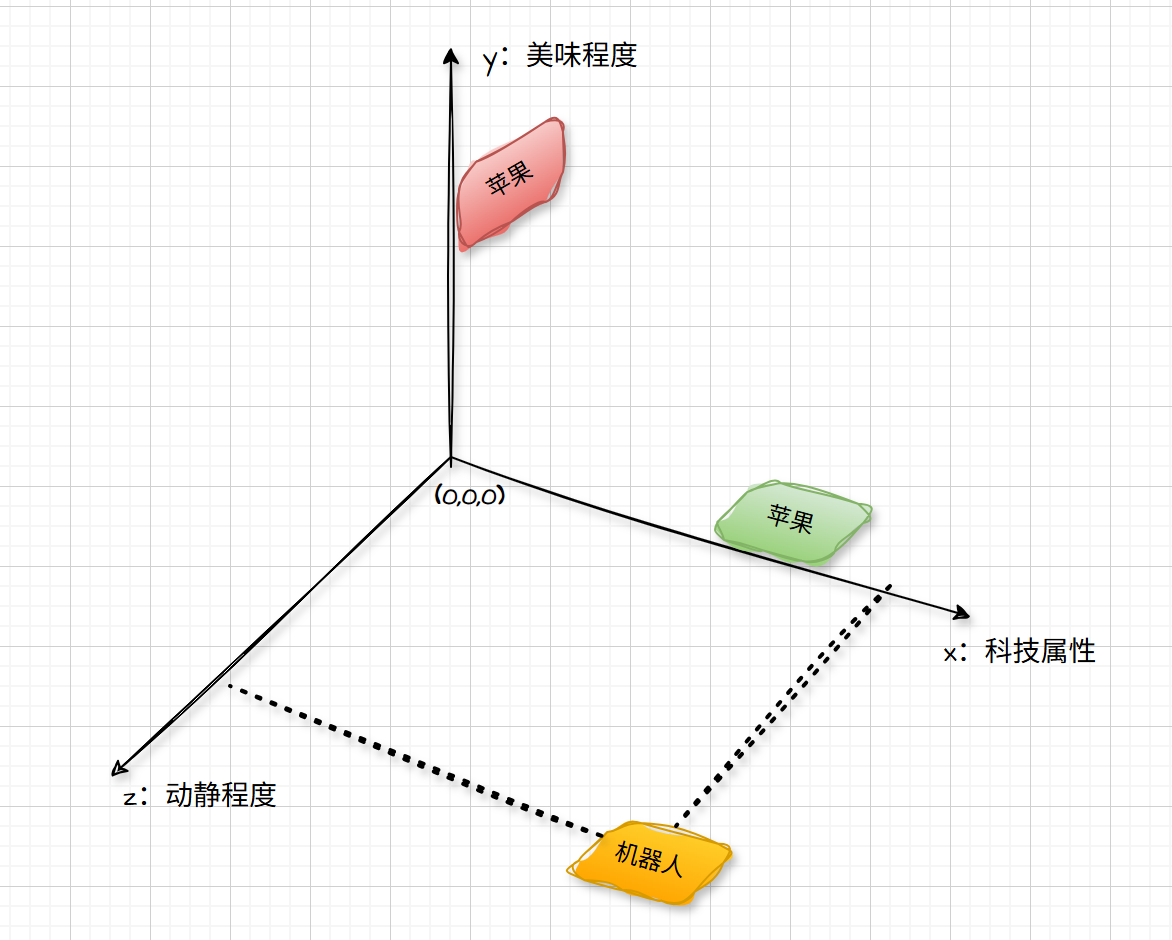
我们主要从我喜欢苹果这段对话说起。首先,我们知道,苹果在人类的语言中代表多个含义(吃的苹果、苹果手机等等)。假设我们现在讨论的这个大模型只有二维(X轴:科技属性,Y轴:美味程度),可以得到这样的坐标系:
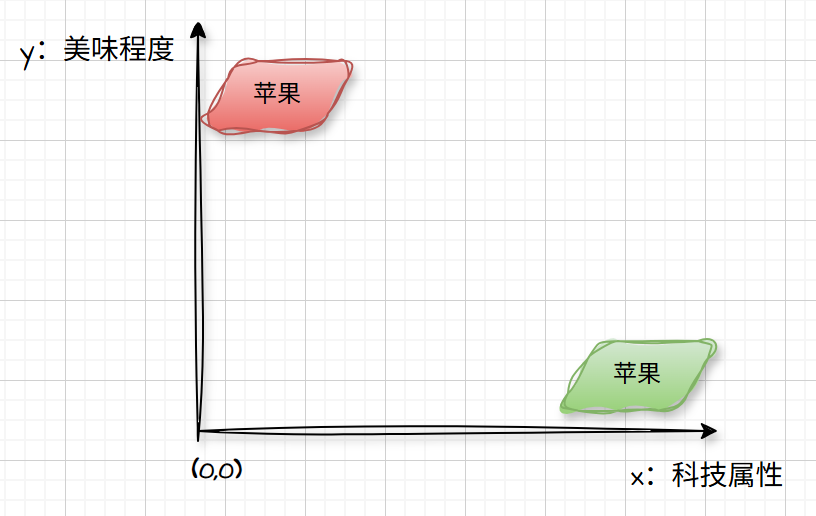
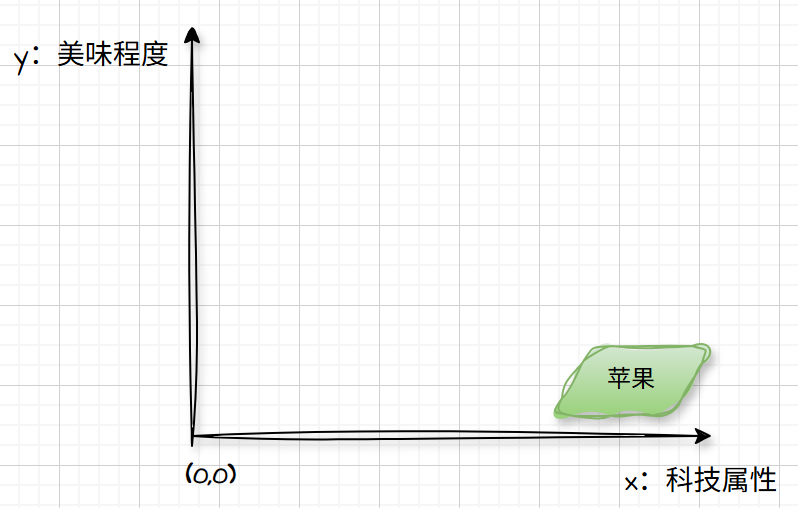
“绿苹果”坐标:(1000,0.1)
“红苹果”坐标:(0.1,1000)
虽然都是“苹果”,但是表达的语义却千差万别。但是在我们刚才的语义中,这个苹果是吃的还是手机,我们现在还不得而知。为了不偏袒谁,此时的坐标是这样的:
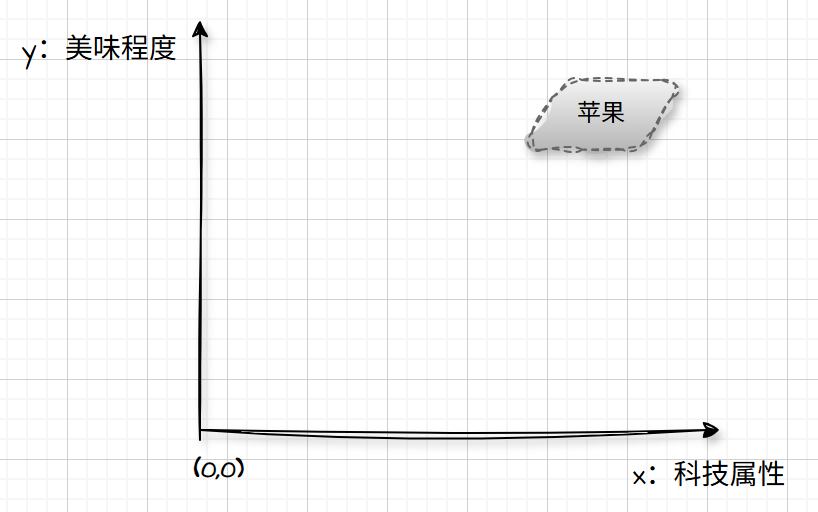
重点来了,根据上下文的理解,它知道我们在谈论手机,所以这里的苹果指的是苹果手机!(注:如果我们该轮对话中体现了苹果手机(我喜欢苹果手机),那么LLM会依据自注意力机制识别出苹果就是指苹果手机的苹果)
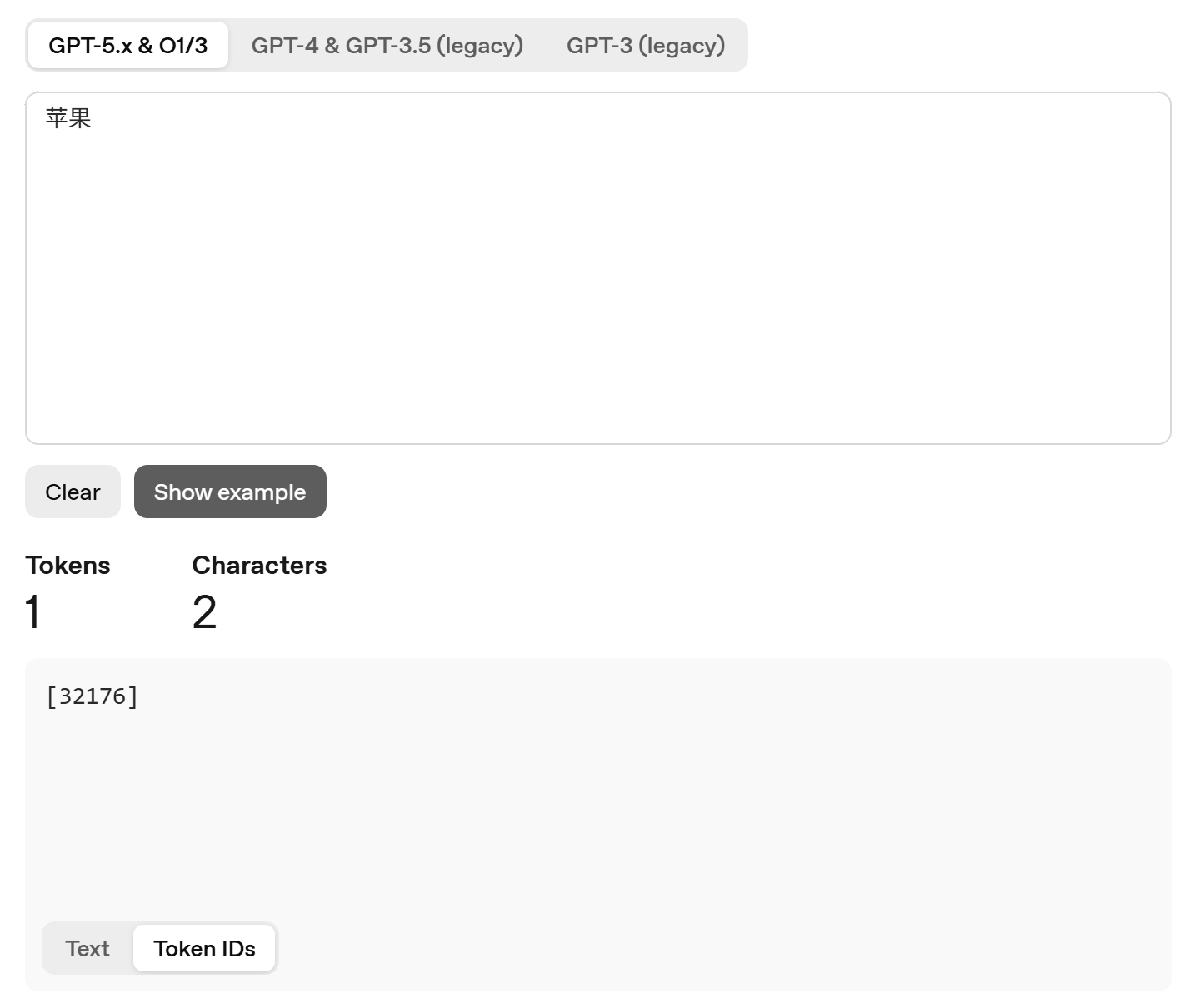
另外,大模型的设计者为了让它们能读懂人类,给他们设计了一套词(元)典:每个词元都可以在字典中找到对应的位置,如下图GPT5.X中苹果的ID为32176,LLM拿到这个ID回去过五关斩六将(经过几十层Transformer处理),将该词元得到最终的向量坐标(1000,0.1)。
注:这里用到了自注意力机制,每一层Transformer层都在努力将词元真实表达的意思表现出来,最终定位到几千维的坐标系中
为了完美的表达人类的语言或者感知力,每一个维度的精度用16bits表示(FP16:16位浮点)。有人说:为什么不能用更低的位数来表示呢?只因人类的感知是复杂的,我们的情绪从来不是非黑即白,尝试一下,如果我们的情绪用红绿灯来表示,会是怎样?不是痛苦,就是快乐——哦还有黄灯的抑郁——这是不足以表达人类情感的!
扩展到三维
我们在之前的X轴、Y轴的基础上再添加一个Z轴(动静程度),因为机器人的科技属性和动作都比较高,故机器人的向量表示大概是这样的。
所以当一个LLM它的向量维度是4096维的时候,一个词元所占的内存空间大概是:
4096 维度 × 2 字节(16bits) = 8192 字节 = 8 KB (你可以这样理解,但是不对!)
实际的存储空间大概是这样的 2B * 128维 * 2(k、v) * 32 = 16KB(因为k 和 v 分别占8kb)
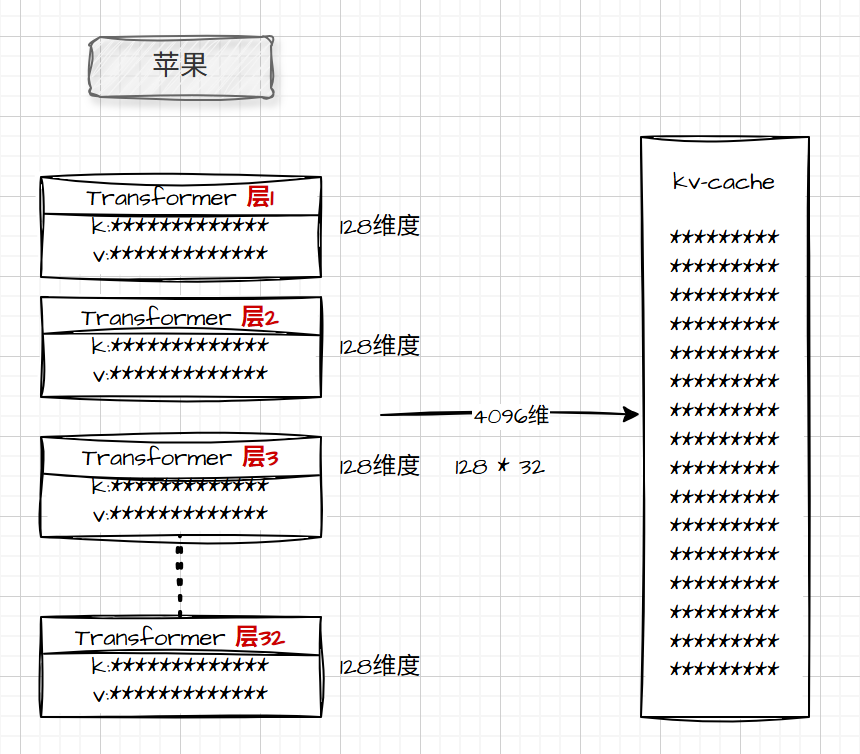
一个词元就是**16KB**,那么一句话是多少?大模型回复你的信息依然要进行分词及向量存储(即,不单单你问的要存储,大模型回答的依然要存储)!所以你也许知道这段还见存储芯片为什么涨价了吧?
尤其近几个月“小龙虾”盛行,更加消耗了算力的极限,很多公司都在限流、甚至停止使用。
TurboQuant原理剖析
- 极坐标粗压(PolarQunat): 用 $ r $(16位)保整体能量,用 4095 个 $ \theta $(比如 2位或3位)保大致方向。
- 残差精修(QJL): 额外为每个维度分配 1位(符号位),用于记录高斯投影后的误差方向,通过统计学在解压时完美找回丢失的精度。
注:粗压分极限压缩(2位)和标准压缩(3位),前者TQ总位数为3位,后者为4位(包含QJL1位误差位)。
背景
现在我们知道,LLM将大量的KV信息存储在显存中,占用了大量的空间,导致存储成了目前算力的瓶颈。现在考虑的是如何将其压缩(而不丢失精度),我先告诉你答案,Google的研发团队将存储向量每一维的**16位信息压缩到3位****!**而且不需要预训练,而且精度不丢失!(从16位到3位精度如何做到不丢失的?)

PolarQuant
PolarQuant 先做随机旋转,让坐标服从更易量化的集中分布。所以,提供了一个旋转矩阵$ Q $(**假设**矩阵如下,我们以四维的向量作为演示):
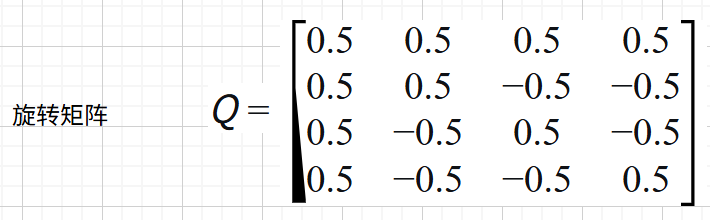
假设我们有一个原始的列向量,这个向量就是苹果(手机)所在的坐标点位(我们已经将其简化,实际几千维甚至几万维,对应的点位信息更加苛刻)。
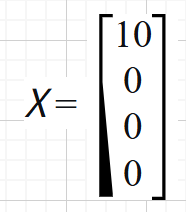
旋转矩阵的主要作用就是将突兀的点位变得更平滑,我们将$ Q $和 $ X $相乘,得到的结果将是:
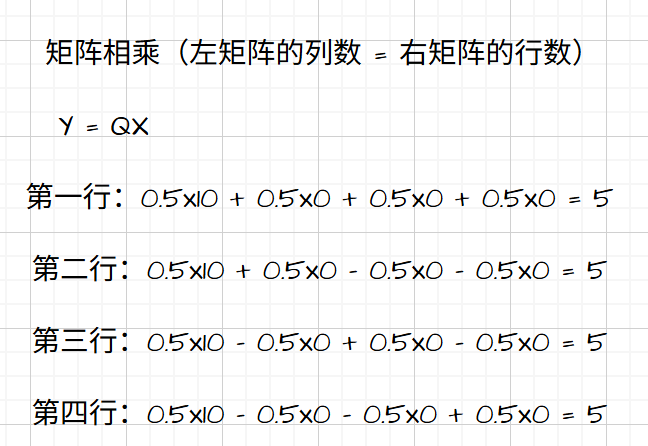
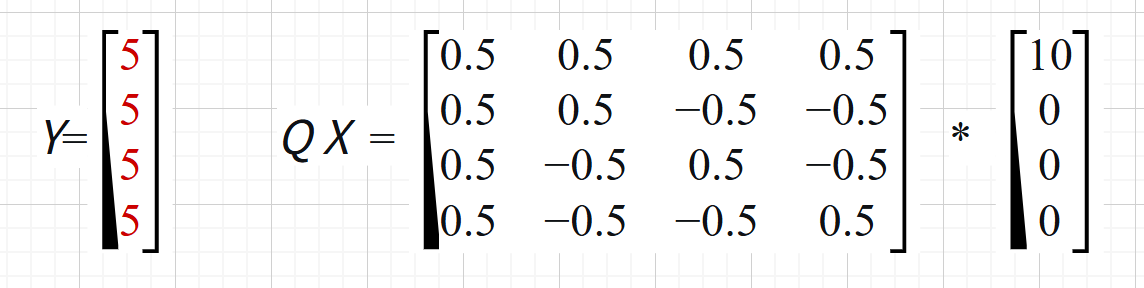
得到$ [5,5,5,5]T ∗ ∗ 列矩阵 ∗ ∗ ,将原本突兀的 **列矩阵**,将原本突兀的 ∗∗列矩阵∗∗,将原本突兀的 X $轴平均到了其他坐标轴上——我认为可以理解,我们看它的视角变了,这也是压缩前最关键的一步!——可以想象一个三维坐标系中的三角形如果侧着对着我们,他就是一条线!从错误的视角越压缩越失真。
将笛卡尔积坐标转为极坐标
对一个4096维的向量 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">x = (x₁, x₂, ..., x₄₀₉₆)</font>,其变换过程如下:
- 第一维(长度
**<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">r</font>**):用欧几里得公式计算出的模长(Norm)。
$ r = \sqrt{x_1^2 + x_2^2 + \dots + x_{4096}^2} $
- **<font style="color:rgb(15, 17, 21);">作用</font>**<font style="color:rgb(15, 17, 21);">:这个标量</font><font style="color:rgb(15, 17, 21);"> </font>`<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">r</font>`<font style="color:rgb(15, 17, 21);"> </font><font style="color:rgb(15, 17, 21);">代表了向量的“能量”或“尺度”,在压缩时通常需要更高精度保留(例如存储为 FP16)。</font>
- 其余维度(角度****
**<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">θ₁, θ₂, ..., θ₄₀₉₅</font>**):代表向量在单位超球面上的方向。- 这些角度值的分布在高维空间中非常集中,因此非常适合用低比特 进行量化压缩。
我们再以二维坐标点打比方,**θ **就是转换后的苹果与原点位的夹角。
有了r和θ我就已经将原始的4096维向量(记住这里所有维度都是16位)和新的4096维(这里只有第一位是16位,其余维度都是2位或3位)建立了映射关系!论文中表示,以前笛卡尔积的垂直走线(走折线:向东走 3 个街区,向北 4 个街区),转变为走直线(共走 5 个街区,呈 37 度角)

QJL
PolarQuant 为了节省内存,不会存储精确的、全精度的角度值(比如 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">35.724...°</font>),而是会用一个低精度的近似值来代替它(比如,把它近似到最近的、允许的离散值,如 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">36°</font>)。这个“近似”过程就是量化,而 QJL 的目标就是尽可能低代价地修正这个近似带来的误差。
如果仅仅是让每个维度用 1 位信息(0 或 1)去记录“自己偏大还是偏小”,是无法精确还原误差的,因为这种做法丢失了误差的“大小”信息。为了解决这个问题,QJL 引入了极其巧妙的统计学机制:
1. 提取残差与“高斯投影”打散
首先,系统会将原始高精度向量与 PolarQuant 粗略量化后的向量相减,得到一个包含 4096 个维度误差的残差向量(Residual Vector)。 接着,QJL 让这个残差向量穿过一个“JL 随机投影矩阵”(类似于一个数学搅拌机)。这一步的目的是将某些维度上极其突出的“大误差”,均匀地打散并分摊到所有的 4096 个维度中,使其变成一串整体均匀的“白噪声”。
2. 极致的 1-bit 符号量化
当误差被彻底打散均匀后,QJL 开始执行最极限的压缩:它彻底抛弃了具体的数值,只保留这 4096 个新维度的正负号!
- 只要数值大于 0,就分配 1-bit 记录为
<font style="color:rgb(15, 17, 21);">1</font>(表示正向)。 - 只要数值小于 0,就分配 1-bit 记录为
<font style="color:rgb(15, 17, 21);">0</font>(表示反向)。 至此,原本庞大的误差数据,被极其严苛地压缩成了 4096 个简单的二元符号。
3. “群智涌现”的最终修正
只存正负号,凭什么能还原精确的误差?这依赖于高维空间的大数定律。 当大模型在进行注意力计算时,它会拿着当前的查询向量(Query),去和这 4096 个 <font style="color:rgb(15, 17, 21);">0</font> 和 <font style="color:rgb(15, 17, 21);">1</font> 的符号位进行大规模的碰撞。因为维度高达 4095 维,这 4095 次简单的“正负号”相乘,会在统计学上发生极其精准的相互抵消与纠偏。
最终,这 4096 个 1-bit 的微小碎片共同协作,能够输出一个无限逼近真实误差的修正分数(无偏估计)。将其与 PolarQuant 的粗略结果相加,我们就用极其低廉的代价(每维度额外 1-bit),换回了模型 100% 的推理精度。
市面上压缩算法对比
| 方法 | 应用范围 | 是否需训练 | 存储开销 | 精度损失 | 备注 |
|---|---|---|---|---|---|
| TurboQuant | KV缓存/向量检索 | 无 | 0(无归一化常数) | 0% | 在线算法,接近信息论极限 |
| 传统PQ | 向量检索 | 需 | 高(存储码本和常数) | 显著 | 经典产品量化,需要离线训练 |
| AWQ (4-bit) | 模型权重量化 | 无 | 中(每块4-bit表示) | ~1–2% | 自适应分块量化,保留性能优于GPTQ |
| GPTQ (4-bit) | 模型权重量化 | 无 | 中(特定算法位宽) | ~5–10% | 无需额外训练(后训练量化) |
谷歌计划于4月的国际学习表征会议(ICLR 2026)上展示TurboQuant技术。敬请期待!
参考文章及工具
https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
https://platform.openai.com/tokenizer




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)