面向对象第一单元回顾
面向对象第一单元回顾
截至此时,我完成了面向对象课程的第一次迭代任务。在该单元作业项目中,我逐步实现了一个支持复杂嵌套、自定义函数调用以及求导运算的数学表达式解析与化简系统,并在此过程中逐步理解需求解耦和将研究的问题抽象封装为对象的设计思想。
架构设计综述
我将处理流程大致划分为解析——计算两级,从前端到后端,构建了输入处理、词法分析、语法解析器、表达式语法树、基本多项式模型五层架构体系。
在设计过程中,我理解并落实了解耦的工程价值,依赖一个扎实坚固的架构,我的代码能够较从容地应对文法规则的不断扩展,高效地发挥其功能,而较少地出现预料之外的问题。
程序结构度量分析
1. 类级别的规模与复杂度分析
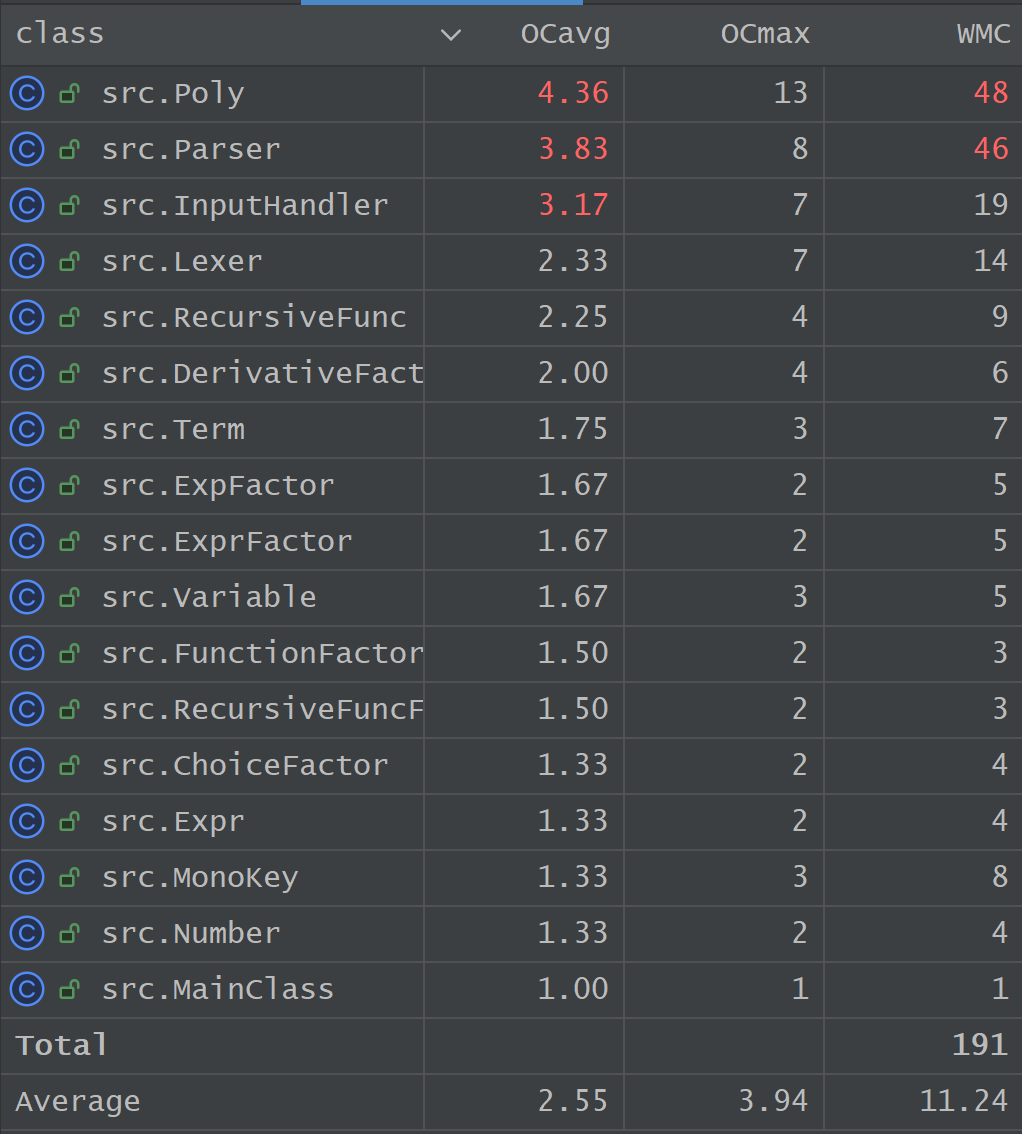
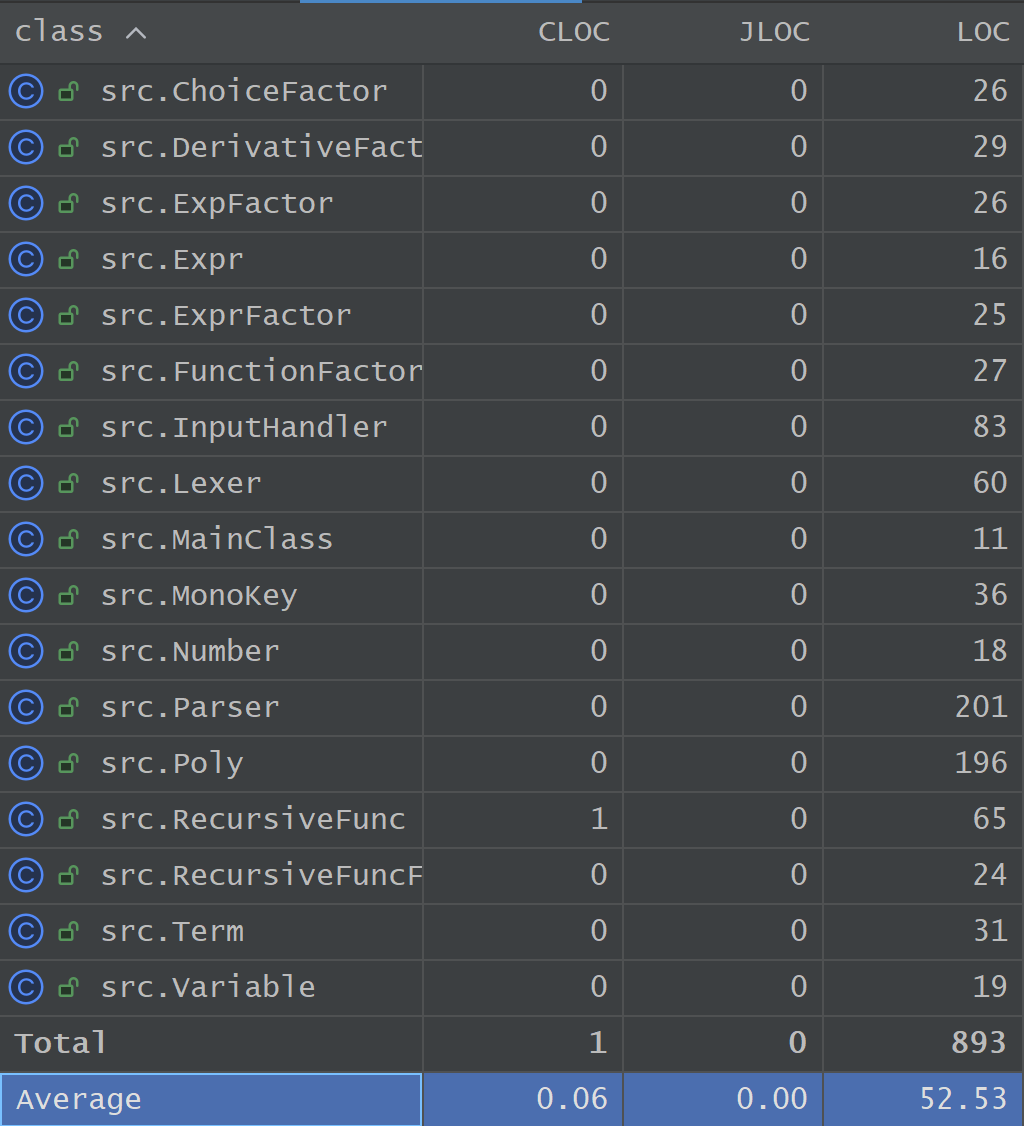
类规模与类复杂度排行
数据观察:
结合代码行数(LOC)与总圈复杂度(/WMC)两份报表,项目代码呈现出了明显的“两极分化”态势。Parser(201行,WMC=46)与 Poly(196行,WMC=48)包揽了规模与复杂度的前两名。而其余的 AST 节点类(如 Variable, ExpFactor, Term 等)的行数均在 20-30 行左右,WMC 极低(平均 < 5)。
反思评估:
Parser类和Poly类分别承担着语法解析和底层化简计算的核心职能,呈现出功能臃肿的倾向。考察Poly类,它不仅要负责底层多项式模型的加法、乘法与偏导计算,还要负责处理最终极其复杂的字符串拼接,这种功能杂糅让其耦合度高出合理水平。- 所有实现
Factor接口的底层节点类的数据表现优秀(OCavg 接近 1.5)。这有力地证明了面向对象中“多态”设计的成功。各种不同因子的计算逻辑被完美下放到了各自的toPoly()方法中,节点之间实现了彻底的解耦。
2. 方法级别的规模与分支分析
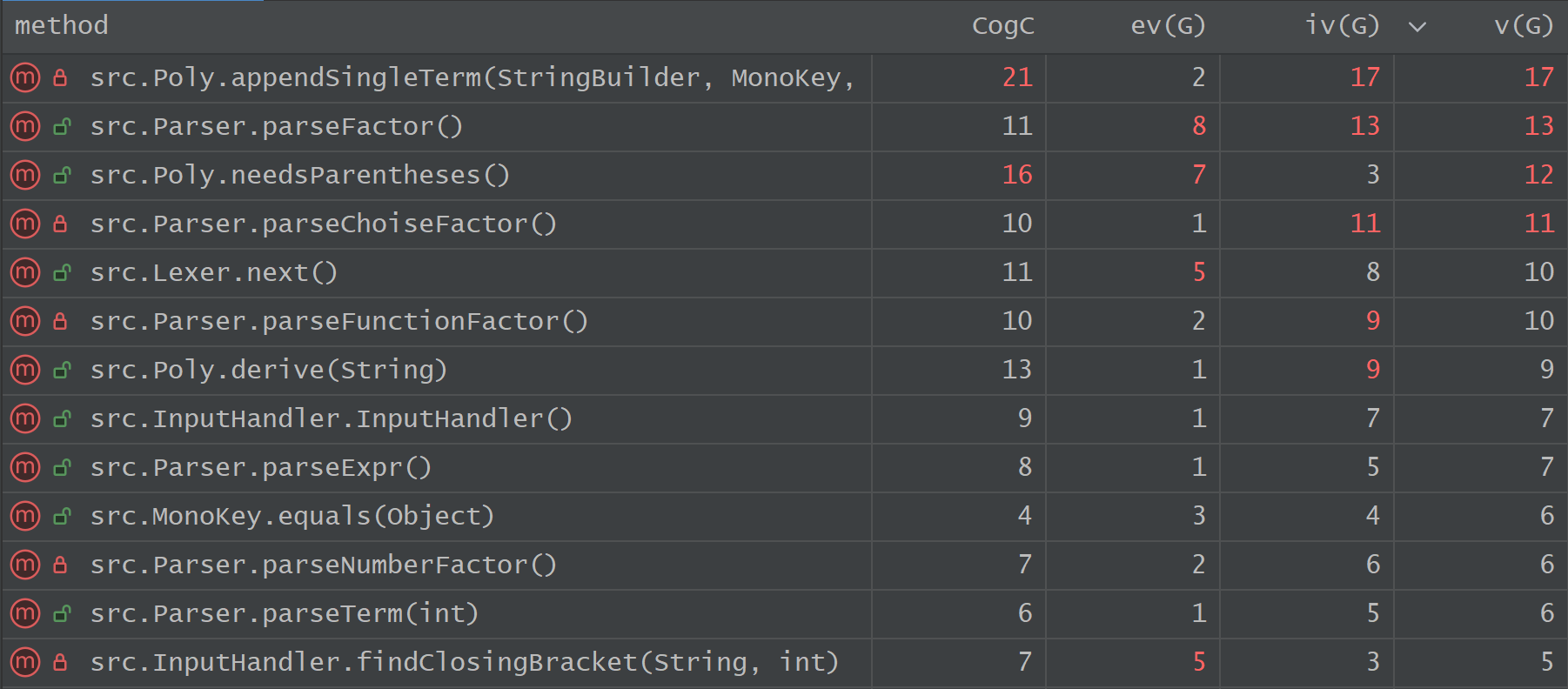
方法复杂度排行
数据观察:
从方法度量统计中可以看出,整个工程中圈复杂度(v(G))与认知复杂度(CogC)最高的三个方法分别是 Poly.appendSingleTerm (v(G)=17)、Parser.parseFactor (v(G)=13) 以及 Poly.needsParentheses (v(G)=12)。
反思评估:
Poly.appendSingleTerm方法实现的是在最后的字符串拼接过程中“接入下一项”的功能,它充斥了极多琐碎且互斥的控制分支:需要判断是否为首项以决定正号的省略、判断系数是否为 111 或 −1-1−1、判断指数是否为 000 或 111 等。这些特判逻辑相互交织,导致该方法的分支数目骤增。
private void appendSingleTerm(/*略*/) {
//前略
if (expX.equals(BigInteger.ZERO) && expY.equals(BigInteger.ZERO) && !hasExp) {
sb.append(coe);
return;
}
if (coe.equals(BigInteger.ONE.negate())) {
sb.append("-");
} else if (!coe.equals(BigInteger.ONE)) {
sb.append(coe).append("*");
}
//后略
}
Parser.parseFactor承担递归下降解析器中解析“因子”的职能,其内部使用了冗长的if-else if链条来分流到不同因子的解析方法。
public Factor parseFactor() {
String token = lexer.peek();
if (token.equals("(")) {
return parseExprFactor();
}
else if (token.matches("\\d+") ||
token.equals("+") || token.equals("-")) {
return parseNumberFactor();
}
else //后略
}
重构思考:
针对上述高复杂度方法,未来的优化方向在于多态分发与职责抽离。例如,可以为 Parser 引入工厂模式(Factory Pattern),将各类因子的解析逻辑注册进 Map 中,用查表法替代 if-else 链;对于多项式的输出,可以单独抽离出一个 PolyPrinter 打印控制类,将冗长的拼接方法拆分为 appendCoefficient 和 appendExponent 等高内聚的私有小方法。
3. 类图分析
设计考虑
1. 预处理与解析流设计
InputHandler:设计该类的初衷是为了将“规则定义(函数与递推式)”与“表达式语法解析”剥离。考虑到第三次作业中递推函数严谨的模板约束,我没有让 Parser 去构建臃肿的语法树,而是让该类直接承担函数计算规则模板提取,生成RecursiveFunc计算引擎。这极大降低了后续解析的复杂度。Lexer与Parser:将词法切分与语法解析解耦。Lexer剪切并返回最小完整字块,去除空白符;Parser则在接收后基于递归下降算法构建 AST。二者分离使得文法扩展变得极为平滑,只需在 Parser 的parseFactor中新增一个分支即可。
2. AST 节点与多态设计
- 接口
Factor:这是整个 AST 树上叶子节点的核心接口,强制所有实现类必须提供toPoly()方法。这意味着从顶层来看,不管树的叶子节点是简单的Number还是复杂的DerivativeFactor,都可以被同等对待,完美符合面向对象的开闭原则 和依赖倒置原则。 Expr与Term:采用经典的组合模式(Composite Pattern)。Expr是由Term构成的列表,Term是由Factor构成的列表。它们本身也实现了向Poly转换的逻辑(内部循环调用子节点的toPoly()并执行加法/乘法),从而实现了表达式层层递进的延迟求值。
3. 底层数学建模与缓存计算
Poly与MonoKey:将“三个指数”(x、y的指数及e的表达式指数)相同的项视作最小单项式。MonoKey作为 HashMap 的键,封装了同类项的判定逻辑(基于“三个指数”的equals和hashCode重写)。Poly类则将所有的多项式加减乘除转化为底层的 HashMap 遍历,使同类项合并在 O(1)O(1)O(1) 时间内天然完成。RecursiveFunc:专门为递推函数设计的计算引擎。核心设计是在输入处理时将函数定义特征储存并构建计算模板,同时引入了双层HashMap缓存已计算的结果,避免重复递归计算。
三次迭代设计体验
HW1 :基础表达式解析与多项式建模
递归下降解析(Lexer + Parser)
学习“训练”“实验”中的基础设计,本阶段确立了经典的前端解析双层架构:
- Lexer(词法分析器):负责将输入的原始字符串切割为独立的 Token 流(如数字、变量、符号),屏蔽了空白字符等干扰因素。
- Parser(语法分析器):采用递归下降算法,严格按照表达式文法构建了
Expr(表达式)、Term(项)、Factor(因子)的语法树层级关系。
public class Lexer {
private String input;
private int pos = 0;
public String peek() { /* 查看当前 Token */ }
public void next() { /* 过滤空白,步进切下Token */ }
}
public class Parser {
private Lexer lexer;
public Expr parseExpr() { /* 解析多个 Term 的加减 */ }
public Term parseTerm() { /* 解析多个 Factor 的乘除 */ }
public Factor parseFactor() { /* 解析单个 Factor */ }
}
基于哈希表的一致化计算(Poly)
在后端计算层面,放弃了直接对 AST 节点进行字符串操作,而是建立了一套纯数学的底层模型:
- 底层采用
HashMap<Integer, BigInteger>的数据结构。以指数特征作为键(Key),以系数作为值(Value)。这使得多项式的加法和乘法运算转化为了高效的哈希表遍历与整数运算。 - 所有的表达式最终都被转化为
Poly对象计算。
HW2 :哈希重写,多态发挥作用
- 指数函数的引入,使得原本的
HashMap失去其最小单项式的作用,我考虑需要将基本单位设计为同时满足 xxx 的指数与 expexpexp 的指数表达式完全一致的单项式。于是我抽取出了独立的MonoKey自定义类作为HashMap的新键。通过在MonoKey内部维护 xxx 的指数(及后续 yyy 的指数)以及 expexpexp 内部表达式的Poly,并重写equals()和hashCode()方法。这样,我从根本的层面解决了多维度变量组合时的同类项判定问题。
public class MonoKey {
private final int expX;
private final int expY;
private final Poly expInner;
@Override
public boolean equals(Object obj) { }
@Override
public int hashCode() { }
}
- 在这一阶段,我还设立了统一的
Factor接口,让Variable、ExpFactor等全部实现该接口的toPoly()方法。Parser 只需要无脑将解析到的因子塞进Term的列表中,彻底屏蔽了底层的差异。这使得我的解析引擎在面对新物种时,具备了极其平滑的扩展性。
HW3 :递推函数独立计算引擎
- 如前文所说,我引入的针对递推函数计算的独立类
RecursiveFunc,实现定义——解析——计算的三层解耦。 - 对于求导计算的处理则简单得多:引入和其他因子类似的
DerivativeFactor类,在Poly中设置求导计算方法,在计算化简时对原函数对应的多项式调用该方法即可。这同样体现了一个“面向对象”式的架构的优越性。
可能的迭代场景与可扩展性分析
可以设想在未来需要引定积分算子int(Expr, dx, lower, upper)。
我们要做的必要修改如下:
- 前端扩展:
在Parser的parseFactor()方法中,识别特征 Token ,并新增一个分支parseIntegralFactor()。它按顺序提取表达式、积分变量、下限和上限,然后将它们打包放入一个全新的节点中,不破坏原有解析逻辑。 - 新增 AST 节点:
新建一个IntegralFactor类并实现Factor接口,内部存储定积分相应节点的必要属性,实现toPoly方法,对被积函数及其他相关属性调用Poly中的展开方法。 - 后端引擎扩展:
新建积分计算方法,对基础多项式按照数学规则遍历计算即可。
结论:在当前架构下,对于常规的数学计算表达式,都只需要进行增量开发,而不用大量修改原有代码结构,这体现了代码结构的可靠性。
程序 Bug 分析与应对策略
选择式因子的短路求值
除第三次作业互测外,我遇到的系统性 Bug 主要就是,我没有注意选择式和函数交互时的短路求值问题。
在第二次作业中测阶段,我的代码怠慢了函数式的处理,我没有设置单独的因子节点,而是在解析阶段直接对其进行参数替换并展开为表达式因子存入 AST 中。在互测时我遇到了在选择式的假分支设置多层复杂嵌套函数的样例,如果不先对其进行选择处理而直接展开的话,必然会导致 TLE 错误。
于是我只能老老实实地设置独立节点 FunctionFactor ,实现 Factor 接口。在定义阶段提取函数的计算规则,解析阶段分离函数的实参,并保存为相应节点,接入语法树中。在最终的统一计算阶段完成参数替换与计算化简。
反思:这个 Bug 的产生,本质上就是我在没有贯彻设计上的“多态”与“解耦”原则,在功能的实现内部做了多余的处理。其原本是很容易避免的。
测试策略
主要通过借助大模型构造边界数据和高复杂度数据来测试。测试有效性比较一般(一共hack到两人)
优化
实际上几乎没做优化(除了避免首位负数外)
了解到应该尝试提取长系数等优化方法,但综合考虑时间精力和风险性,没有应用到自己的代码上。
(不过HW3强测里也并没有体现令人难以接受的性能分)
大模型相关使用
- 生成代码使用率:不知道如何确定,总的来说较高。包括为我提供思路提示、代码补全等。
- 其他使用:辅助学习语法和基本思想方法,检查代码基本问题,构造测试样例,分析测试结果排查bug
- 该文章开头部分(度量分析)让大模型提供了写作提示,但我自己也做了大量文字修改,后半段纯手工。
- 完成效果:
- 生成代码正确率很高;
- 虽然难以直接读代码找全bug,但是可以通过{测试、向大模型反馈错误情况、大模型提供进一步排查方案、再测试再反馈、给出bug所在}的方式完善代码
心得体会
要说体会也就是这个互测,如果让我真的通过看同学的代码找出来问题,再给针对性的测试,感觉自己很难做得到,而且精力也不允许(一个房六份码)。暂时没想明白怎么查别人代码。就该作业来说我三次互测比较划水。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)