CLIP学习详解
目录
1. CLIP 的损失函数为什么采用对称交叉熵(Symmetric Cross Entropy)?
2. CLIP 为什么需要极大 Batch Size(32768)?算力不足如何优化?
一、对比学习(Contrastive Learning)
对比学习是自监督学习领域的核心范式之一,其核心逻辑是:无需人工标注标签,通过自动构建样本间的相似与对立关系,让模型学习到具有判别性的通用特征表示。相较于传统监督学习对大规模标注数据的强依赖,对比学习仅利用无标签数据即可构造自监督信号,大幅降低了数据标注成本,是当前视觉、文本、多模态领域特征预训练的主流方法。
1.1 对比学习的核心工作原理
对比学习的完整流程围绕 “构造对比关系、学习特征区分度” 展开,包含四大关键步骤,环环相扣构成自监督训练闭环:
1. 多视角样本增强
对原始无标签样本施加多样化但不改变语义本质的数据增强,生成同一样本的多个不同视角(Views),这是构造正样本对的基础:
- 图像领域:随机裁剪、随机水平翻转、颜色抖动、高斯模糊、灰度化等;
- 文本领域:同义词替换、随机掩码、句子重排、回译等;
- 核心约束:增强后的样本需保留原始样本的核心语义,如猫的图片增强后仍为猫,不可改变样本的本质类别属性。
2. 统一编码器特征提取
采用共享参数的神经网络编码器(如 ResNet、ViT、Transformer 等),对所有增强后的样本进行特征编码,将高维原始数据映射为低维紧致的特征向量,该编码器是对比学习最终要优化的核心模型。
3. 正负样本对构建
基于样本来源自动划分对比关系,是自监督信号的核心来源:
- 正样本对:源自同一原始样本的不同增强视角,语义完全一致,是模型需要 “拉近” 的样本对;
- 负样本对:源自不同原始样本的任意视角,语义互斥,是模型需要 “推开” 的样本对。
4. 对比损失优化目标
通过对比损失函数约束特征空间分布,实现 “同类相聚、异类相离” 的优化目标:
- 最小化正样本对在特征空间中的距离,让同源样本特征高度对齐;
- 最大化负样本对在特征空间中的距离,让异源样本特征显著区分。
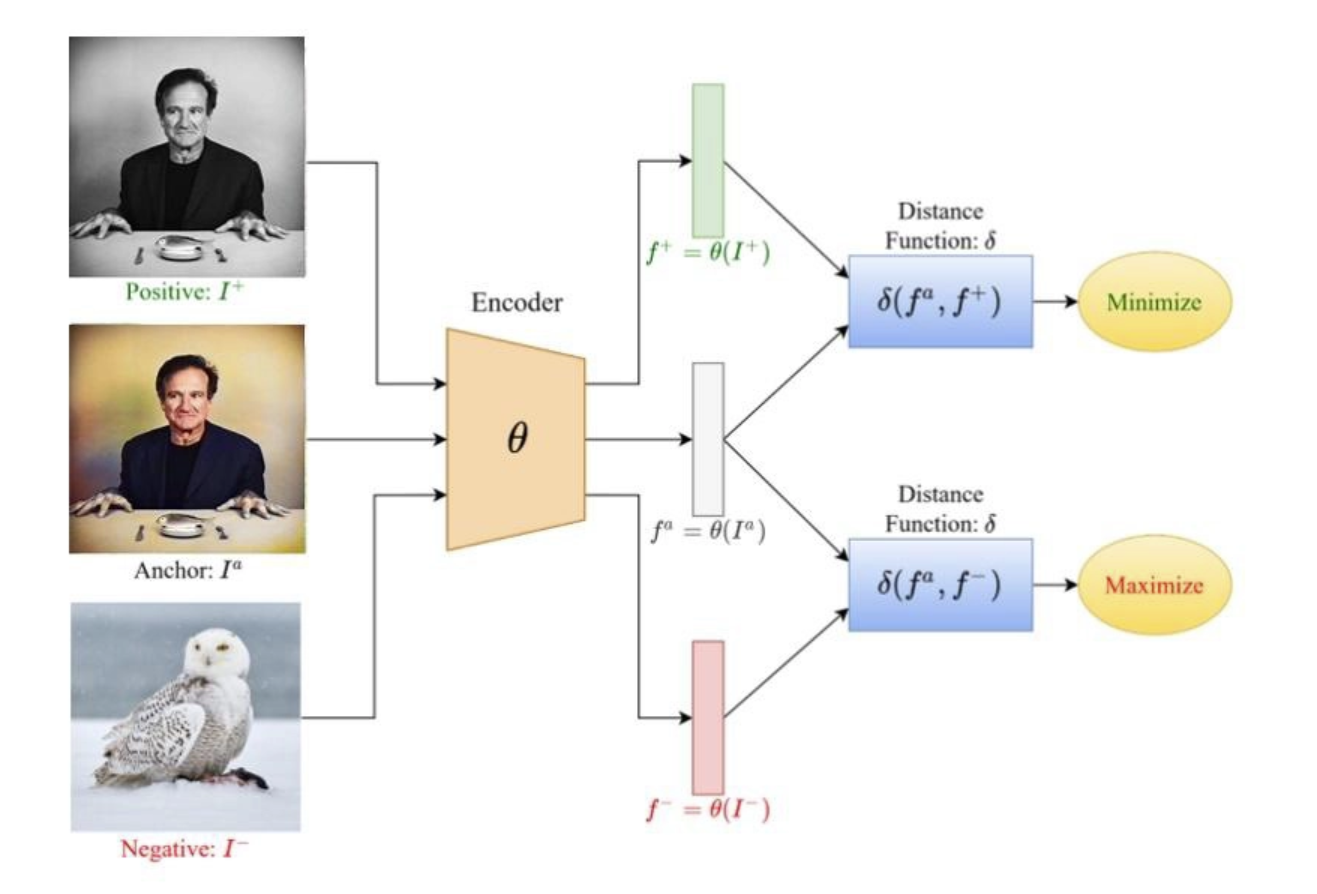
以经典样本示例直观理解:
- Anchor(锚点):基准样本(如彩色人像图),作为对比的核心参照;
- Positive(正样本):同一样本的增强版(如同一人的黑白人像图),与锚点语义同源;
- Negative(负样本):不同语义样本(如猫头鹰图),与锚点语义无关。
三者输入同一编码器后得到特征向量,通过欧氏距离、余弦相似度等距离函数度量特征差异,最终目标是让编码器学会提取可区分不同语义、对齐相同语义的优质特征。
1.2 对比学习核心损失函数:InfoNCE
InfoNCE(Information Noise Contrastive Estimation,信息噪声对比估计)是对比学习中应用最广泛的损失函数,SimCLR、MoCo 等经典算法均基于此优化,其数学定义与直观逻辑如下:
数学表达式
公式符号精准释义
:锚点样本的特征向量;
:锚点zi对应的正样本特征向量(同一样本的另一增强视角);
:当前训练批次内的所有样本特征(包含 1 个正样本 + 其余负样本);
:指示函数,仅当
时取值为 1,排除样本自身对比的无效情况;
:特征相似度度量函数,余弦相似度为工业界与学界标配选择;
:温度系数,用于缩放相似度分布,τ越小,模型对正样本的聚焦程度越高,区分度越强;
:训练批次大小,
为总样本数(因每个原始样本生成 2 个增强视角)。
直观理解
- 分子:锚点与正样本的缩放后相似度指数值,代表模型对 “正确匹配” 的置信度,优化目标为最大化该值;
- 分母:锚点与批次内所有其他样本的缩放后相似度指数和,代表所有候选匹配的总置信度;
- 整体含义:分数部分等价于模型从所有候选样本中精准识别正样本的概率,对其取负对数后,最小化 InfoNCE 损失等价于最大化该识别概率,最终实现特征空间的高效聚类与区分。
二、CLIP模型
2.1 CLIP核心原理
CLIP的英文全称是Contrastive Language-Image Pre-training,中文译为“基于对比学习的语言-图像预训练”,其本质是一种基于对比学习的多模态预训练模型,核心突破在于将对比学习从单模态(如计算机视觉领域的MoCo、SimCLR)拓展到文本-图像双模态,通过对齐文本与图像的语义特征,实现跨模态的特征学习与匹配。
与传统单模态对比学习不同,CLIP的训练数据并非无标签样本,而是大规模的文本-图像对齐样本——即一张图像与其对应的自然语言描述(如“一只奔跑的金毛犬”与对应的金毛犬图片)。其核心目标是通过对比学习,让模型学会捕捉文本与图像之间的语义关联,实现“看到图像能匹配对应文本,看到文本能联想对应图像”。
CLIP的模型结构简洁且对称,主要由两个核心编码器组成(结合图示理解):
-
文本编码器(Text Encoder):负责提取文本描述的特征表示,一般采用NLP成熟的Text Transformer架构,能够将文本序列映射为固定维度的高维特征向量;
-
图像编码器(Image Encoder):负责提取图像的特征表示,支持两种主流架构——传统卷积神经网络(CNN)中的ResNet系列,以及基于Transformer的视觉模型(ViT),可根据需求选择不同规模的模型。
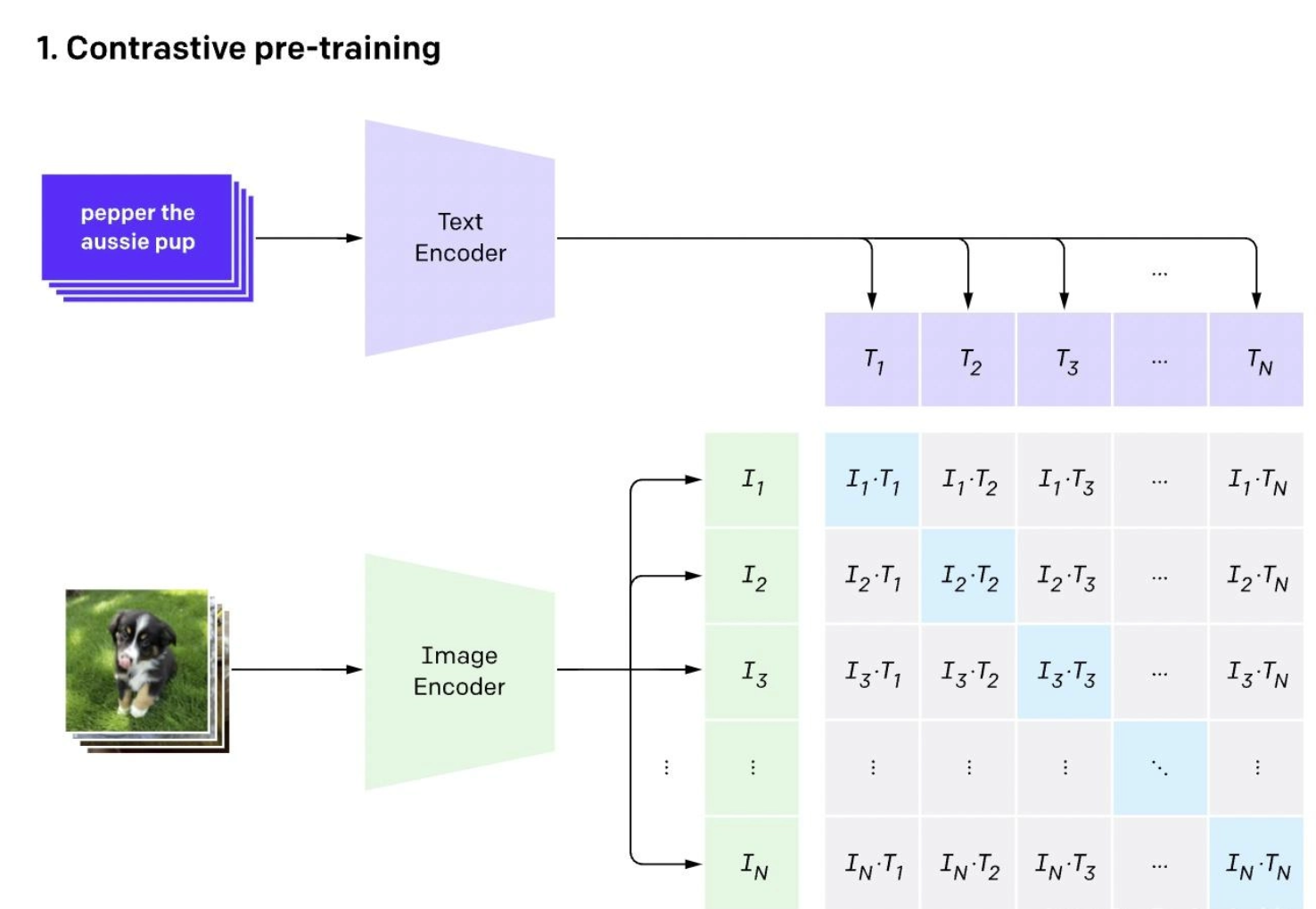
CLIP的对比学习训练逻辑的具体流程如下:
-
选取包含N个文本-图像对齐样本的训练批次,将N个图像输入图像编码器,得到N个图像特征向量;将N个对应文本输入文本编码器,得到N个文本特征向量;
-
将所有图像特征与文本特征进行两两组合,构建N×N的相似度矩阵,矩阵中每个元素代表某一个图像特征与某一个文本特征的余弦相似度(余弦相似度是CLIP默认的相似度度量方式);
-
定义正负样本对:矩阵对角线元素对应“原始对齐的文本-图像对”,共N个,视为正样本对(语义完全匹配);矩阵中其余N²−N个元素对应“非对齐的文本-图像对”,视为负样本对(语义不匹配);
-
训练目标:最大化所有正样本对的相似度,同时最小化所有负样本对的相似度,通过对称对比损失函数约束模型,实现文本与图像特征的跨模态对齐。
以下是CLIP训练过程的核心伪代码:
# 模型与输入定义
# image_encoder - 可选ResNet或Vision Transformer(视觉编码器)
# text_encoder - 可选CBOW或Text Transformer(文本编码器)
# I[n, h, w, c] - 批量对齐的图像数据(n为批次大小,h/w/c为图像高/宽/通道数)
# T[n, l] - 批量对齐的文本数据(n为批次大小,l为文本序列长度)
# W_i[d_i, d_e] - 图像特征到嵌入空间的可学习投射矩阵(d_i为图像特征维度,d_e为统一嵌入维度)
# W_t[d_t, d_e] - 文本特征到嵌入空间的可学习投射矩阵(d_t为文本特征维度,d_e为统一嵌入维度)
# t - 可学习温度系数(控制相似度分布锐度)
# 1. 提取图像与文本原始特征
I_f = image_encoder(I) # 输出形状:[n, d_i],n个图像的原始特征
T_f = text_encoder(T) # 输出形状:[n, d_t],n个文本的原始特征
# 2. 特征投射与归一化(确保图像与文本特征维度一致,便于计算相似度)
I_e = l2_normalize(np.dot(I_f, W_i), axis=1) # 图像特征投射到统一嵌入空间并L2归一化
T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 文本特征投射到统一嵌入空间并L2归一化
# 3. 计算缩放后的余弦相似度矩阵(形状:[n, n])
logits = np.dot(I_e, T_e.T) * np.exp(t) # 温度系数缩放,增强区分度
# 4. 计算对称对比损失(等价于多分类交叉熵损失)
labels = np.arange(n) # 标签为对角线索引,对应正样本对
loss_i = cross_entropy_loss(logits, labels, axis=0) # 以图像为锚点的损失
loss_t = cross_entropy_loss(logits, labels, axis=1) # 以文本为锚点的损失
loss = (loss_i + loss_t) / 2 # 对称损失取平均,平衡图像与文本学习CLIP的性能优势源于其大规模的训练数据与合理的模型设计,具体训练细节如下:
-
训练数据集:OpenAI从互联网收集了4亿个文本-图像对齐样本,命名为WebImageText,规模远超谷歌JFT-300M数据集(多1亿样本),与GPT-2的训练数据集WebText单词量相当,为跨模态特征学习提供了充足的数据支撑;
-
模型架构选择:文本编码器固定采用63M参数的Text Transformer;图像编码器提供两类架构、8种不同规模的模型——ResNet系列(ResNet50、ResNet101、RN50x4、RN50x16、RN50x64,后三者为ResNet按EfficientNet缩放规则放大得到)、ViT系列(ViT-B/32、ViT-B/16、ViT-L/14);
-
训练配置:所有模型统一训练32个epochs,采用AdamW优化器,使用32768的大批次大小(保证负样本多样性);由于数据量与模型规模庞大,训练成本极高——最大ResNet模型RN50x64需在592张V100显卡上训练18天,最大ViT模型ViT-L/14需在256张V100显卡上训练12天;
-
性能优化:ViT-L/14模型额外在336×336分辨率下微调1个epoch,性能最优,记为ViT-L/14@336,论文中所有对比实验均采用该模型。
需要注意的是,尽管CLIP是双模态模型,但其核心目标是训练可迁移的视觉模型,文本编码器主要用于构建对比监督信号,最终的视觉特征可迁移到各类计算机视觉下游任务中。
2.2 CLIP的核心应用:Zero-Shot分类
CLIP最具亮点、最强大的特性的是:无需对预训练模型进行任何微调,即可直接实现Zero-Shot(零样本)图像分类——即不使用任何下游任务的训练数据,就能完成该任务的图像分类,彻底打破了传统视觉模型“预训练→微调”的固定流程,极大降低了模型迁移的成本。
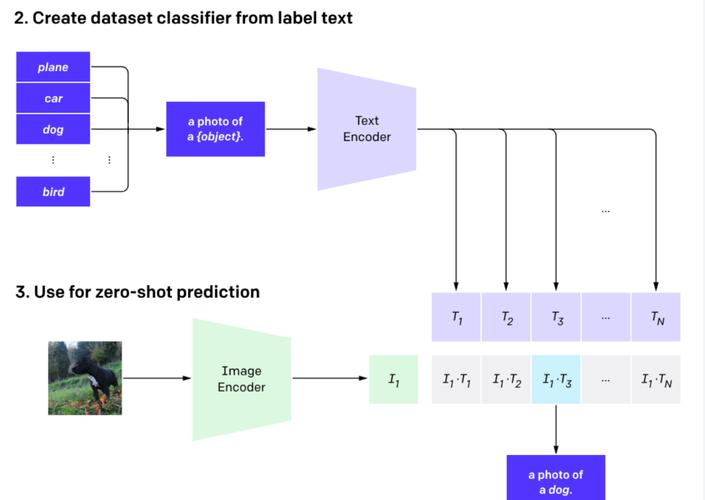
其Zero-Shot分类的原理非常简洁,核心是利用预训练好的文本-图像特征对齐能力,将“分类任务”转化为“文本-图像相似度匹配任务”,具体步骤仅需两步,可直接落地:
-
构建类别描述文本:针对具体下游分类任务的所有类别,按照固定模板`A photo of {label}`(如分类任务为动物识别,类别为“猫”“狗”,则构建文本为“A photo of a cat”“A photo of a dog”)生成每个类别的描述文本;将所有类别描述文本输入Text Encoder,得到与类别数量相等的文本特征向量(假设类别数为K,则得到K个文本特征);
-
图像分类预测:将要预测的图像输入Image Encoder,得到该图像的特征向量;计算该图像特征与所有类别文本特征的缩放余弦相似度(与CLIP训练过程中的相似度计算方式完全一致);相似度最高的文本所对应的类别,即为该图像的预测类别;若需得到预测概率,可将所有相似度值送入softmax函数,输出每个类别的概率分布。
Zero-Shot分类的核心优势在于“泛化性强”——CLIP通过4亿规模的文本-图像对预训练,学习到了海量的语义关联(如“猫”对应猫的图像特征、“奔跑”对应动态的图像特征),无需针对具体任务调整,即可适配各类分类场景,这也是CLIP能够在计算机视觉领域广泛应用的关键原因。
附:一些常见问题
1. CLIP 的损失函数为什么采用对称交叉熵(Symmetric Cross Entropy)?
CLIP 并非单向分类任务,而是图文跨模态双向对齐任务,因此损失函数由图像→文本、文本→图像两部分对称构成:
- 图像到文本损失:
:保证给定图像能匹配到最相关的文本描述
- 文本到图像损失:
:保证给定文本能检索到最对应的图像
总损失为两者均值:
若仅使用单向损失,模型会出现单向偏移,图文特征空间无法在两个模态同时具备判别性,双向对称约束才能让图文特征实现均衡对齐。
2. CLIP 为什么需要极大 Batch Size(32768)?算力不足如何优化?
CLIP 属于对比学习框架,模型判别能力高度依赖负样本数量:
- Batch Size 越大,同一批次内互为负样本的图文对越多,对比任务难度越高
- 更难的优化目标迫使模型学习更细粒度、更具判别性的跨模态特征
低算力优化方案:
- 引入 MoCo 动量队列机制,通过外部队列扩充负样本数量,不依赖大 Batch
- 使用 GradCache 等显存优化技术,降低大批次训练的显存占用
3. CLIP 可学习温度参数 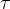 的作用?
的作用?
温度参数 用于缩放图文特征点积得到的相似度分数。
直接控制 Softmax 分布陡峭程度:
CLIP 将 设置为可学习参数,让模型自适应学习最优缩放比例,适配不同 Batch Size 与数据分布。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)